
Impact of Training Set Size and Lead Time on Early Tomato Crop Mapping Accuracy

 ,
,  ,
,
Abstract
:
1. Introduction
2. Materials and Methods
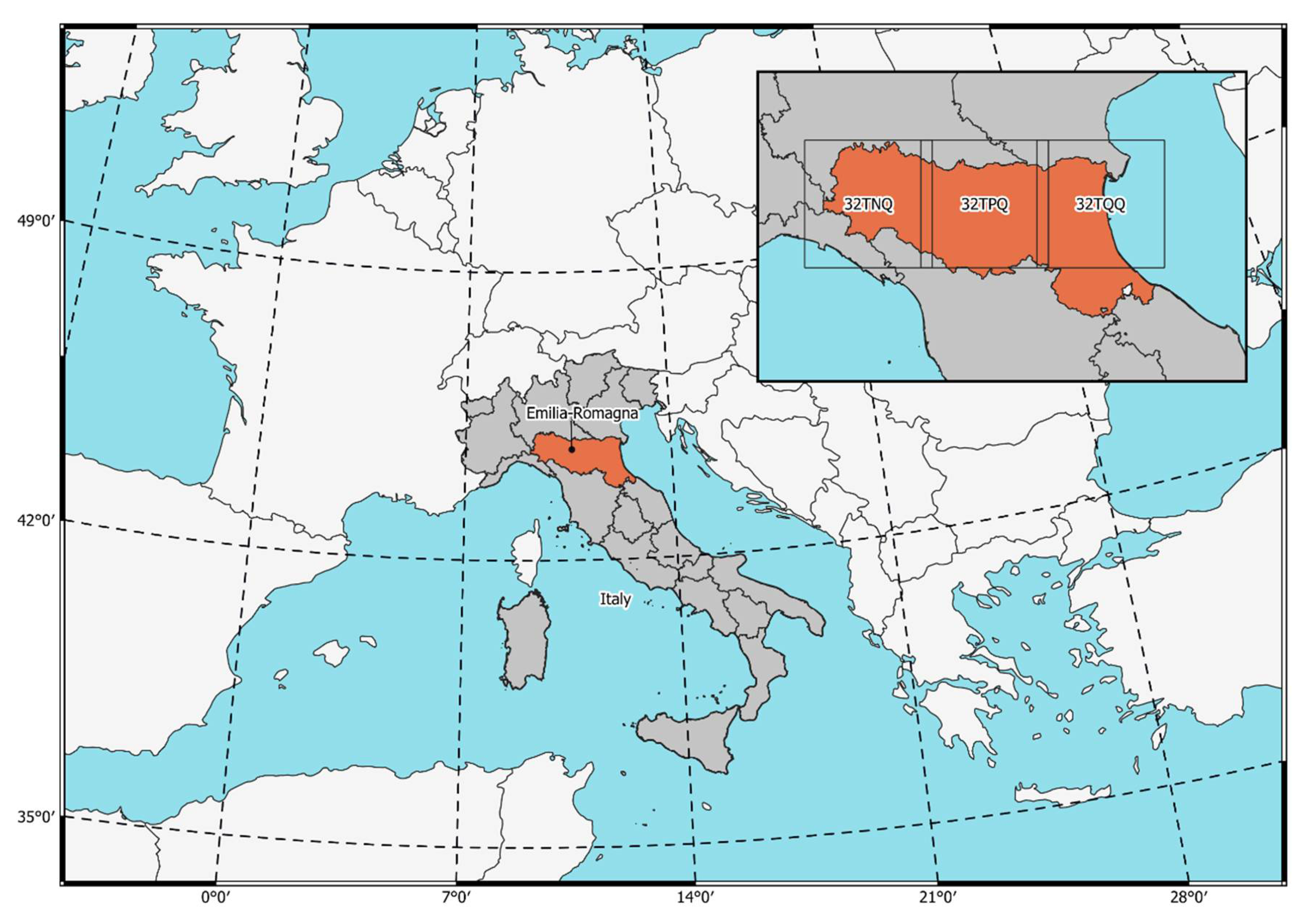
2.1. Study Area
2.2. Reference Data
2.3. Satellite Data Acquisition and Processing
2.4. Feature Set Devolpment
2.5. Experimental Design
2.6. Training and Test Samples
2.7. Machine Learning Workflow
2.7.1. Machine Learning Classifiers
2.7.2. Model Evaluation
3. Results
3.1. Simulation Results
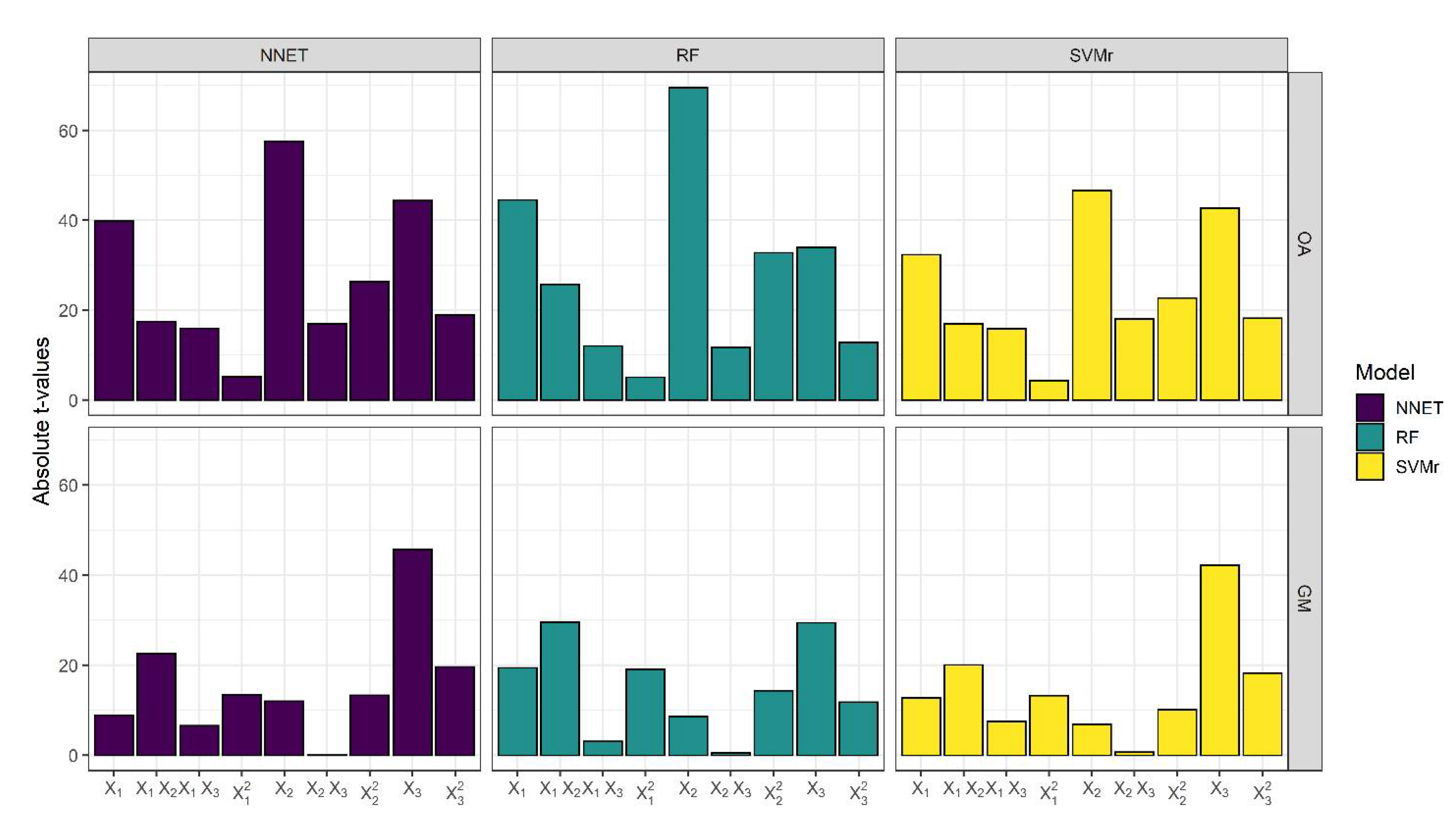
3.2. RSM Models
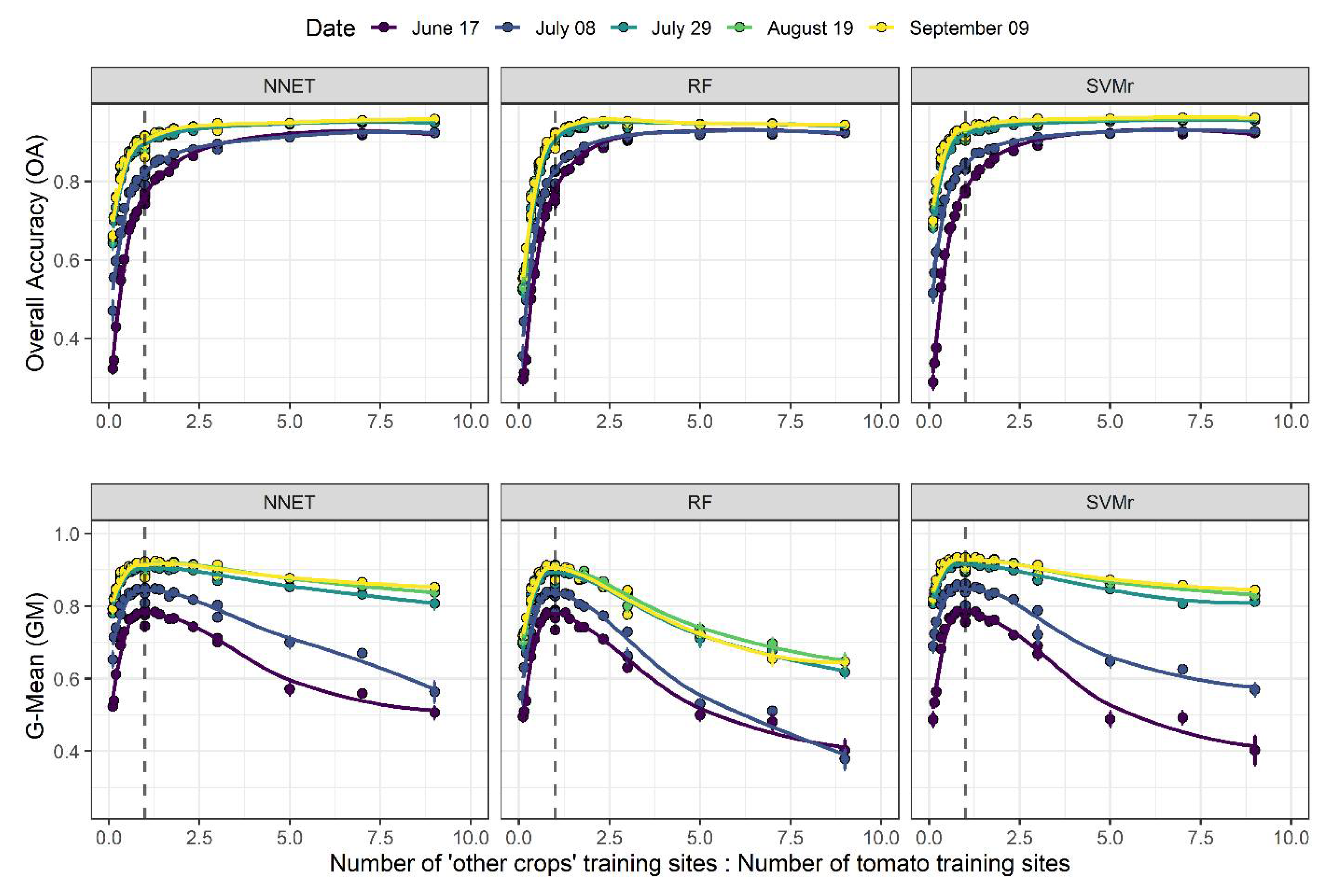
3.3. Effect of Training Set Size and Lead Time
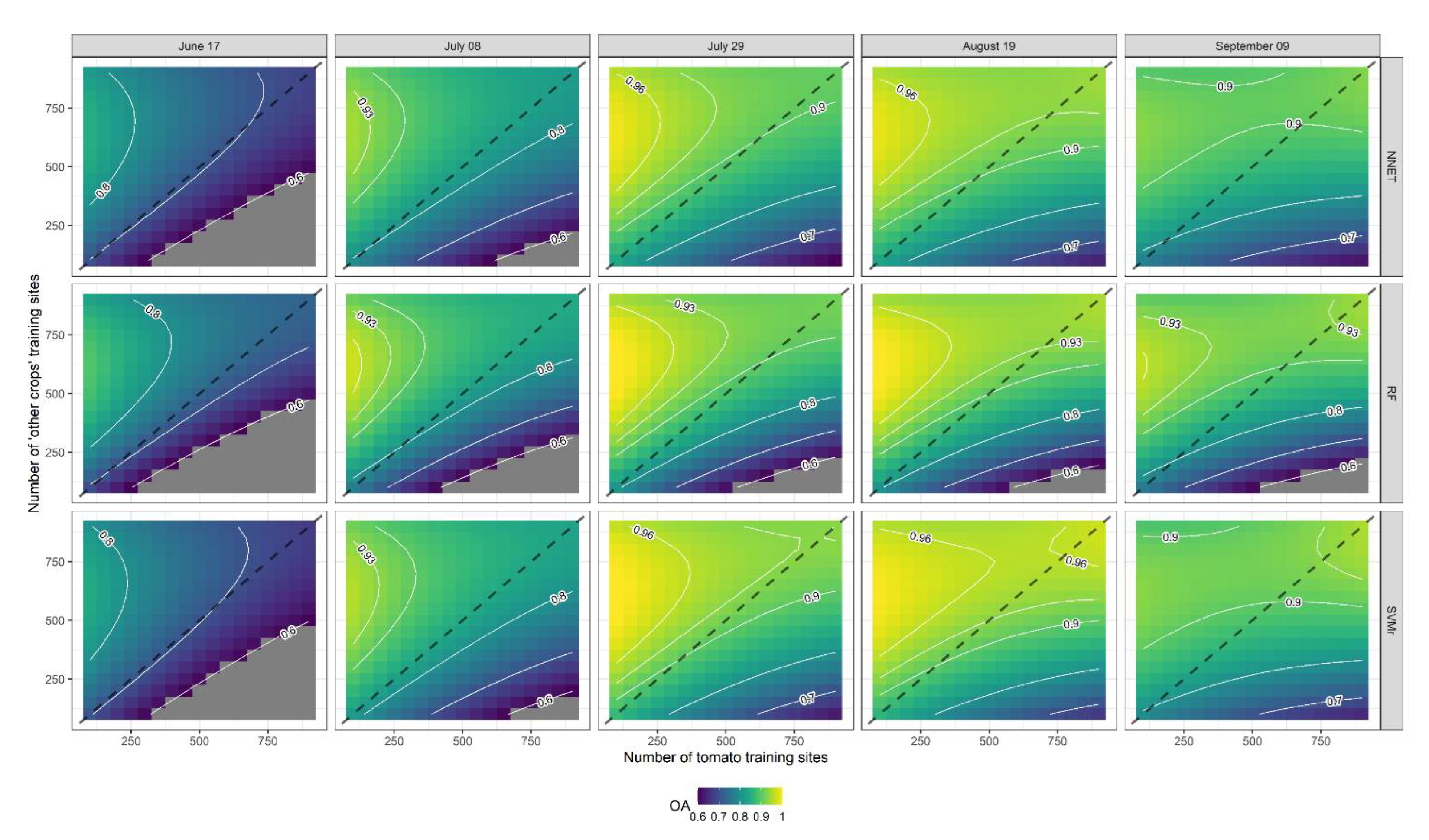
3.4. Optimization Using RSM
4. Discussion
4.1. Effect of Lead Time
4.2. Effect of Training Set Size
4.3. Tomato Crop Mapping Optimization
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gallego, F.J.; Kussul, N.; Skakun, S.; Kravchenko, O.; Shelestov, A.; Kussul, O. Efficiency Assessment of Using Satellite Data for Crop Area Estimation in Ukraine. Int. J. Appl. Earth Obs. Geoinf. 2014, 29, 22–30. [Google Scholar] [CrossRef]
- Craig, M.; Atkinson, D. A Literature Review of Crop Area Estimation; FAO Publication: Rome, Italy, 2013. [Google Scholar]
- Miranda, J.; Ponce, P.; Molina, A.; Wright, P. Sensing, Smart and Sustainable Technologies for Agri-Food 4.0. Comput. Ind. 2019, 108, 21–36. [Google Scholar] [CrossRef]
- Lezoche, M.; Hernandez, J.E.; Alemany Díaz, M.D.M.E.; Panetto, H.; Kacprzyk, J. Agri-Food 4.0: A Survey of the Supply Chains and Technologies for the Future Agriculture. Comput. Ind. 2020, 117, 103187. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First Experience with Sentinel-2 Data for Crop and Tree Species Classifications in Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good Practices for Estimating Area and Assessing Accuracy of Land Change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Kavats, O.; Khramov, D.; Sergieieva, K.; Vasyliev, V. Monitoring of Sugarcane Harvest in Brazil Based on Optical and {SAR} Data. Remote Sens. 2020, 12, 4080. [Google Scholar] [CrossRef]
- Kavats, O.; Khramov, D.; Sergieieva, K.; Vasyliev, V. Monitoring Harvesting by Time Series of Sentinel-1 {SAR} Data. Remote Sens. 2019, 11, 2496. [Google Scholar] [CrossRef]
- Gao, F.; Zhang, X. Mapping Crop Phenology in Near Real-Time Using Satellite Remote Sensing: Challenges and Opportunities. J. Remote Sens. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Meroni, M.; d’Andrimont, R.; Vrieling, A.; Fasbender, D.; Lemoine, G.; Rembold, F.; Seguini, L.; Verhegghen, A. Comparing Land Surface Phenology of Major European Crops as Derived from {SAR} and Multispectral Data of Sentinel-1 and -2. Remote Sens. Environ. 2021, 253, 112232. [Google Scholar] [CrossRef]
- Kamir, E.; Waldner, F.; Hochman, Z. Estimating Wheat Yields in Australia Using Climate Records, Satellite Image Time Series and Machine Learning Methods. ISPRS J. Photogramm. Remote Sens. 2020, 160, 124–135. [Google Scholar] [CrossRef]
- Meroni, M.; Waldner, F.; Seguini, L.; Kerdiles, H.; Rembold, F. Yield Forecasting with Machine Learning and Small Data: What Gains for Grains? Agric. For. Meteorol. 2021, 308–309, 108555. [Google Scholar] [CrossRef]
- FAO; IFAD; IMF; OECD; UNCTAD; WFP; World Bank; WTO; IFPRI; United Nations High Level Task Force on Global Food and Nutrition. Price Volatility in Food and Agricultural Markets: Policy Responses; World Bank: Washington, DC, USA, 2011. [Google Scholar]
- Azar, R.; Villa, P.; Stroppiana, D.; Crema, A.; Boschetti, M.; Brivio, P.A. Assessing In-Season Crop Classification Performance Using Satellite Data: A Test Case in Northern Italy. Eur. J. Remote Sens. 2016, 49, 361–380. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A.; Sanchez-Hernandez, C.; Boyd, D.S. Training Set Size Requirements for the Classification of a Specific Class. Remote Sens. Environ. 2006, 104, 1–14. [Google Scholar] [CrossRef]
- Ramezan, C.A.; Warner, T.A.; Maxwell, A.E.; Price, B.S. Effects of Training Set Size on Supervised Machine-Learning Land-Cover Classification of Large-Area High-Resolution Remotely Sensed Data. Remote Sens. 2021, 13, 368. [Google Scholar] [CrossRef]
- Foody, G.M.; Arora, M.K. An Evaluation of Some Factors Affecting the Accuracy of Classification by an Artificial Neural Network. Int. J. Remote Sens. 1997, 18, 799–810. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A. A Relative Evaluation of Multiclass Image Classification by Support Vector Machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1335–1343. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Foody, G.M. Status of Land Cover Classification Accuracy Assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Foody, G.M.; McCulloch, M.B.; Yates, W.B. The Effect of Training Set Size and Composition on Artificial Neural Network Classification. Int. J. Remote Sens 1995, 16, 1707–1723. [Google Scholar] [CrossRef]
- Millard, K.; Richardson, M. On the Importance of Training Data Sample Selection in Random Forest Image Classification: A Case Study in Peatland Ecosystem Mapping. Remote Sens. 2015, 7, 8489–8515. [Google Scholar] [CrossRef]
- Qian, Y.; Zhou, W.; Yan, J.; Li, W.; Han, L. Comparing Machine Learning Classifiers for Object-Based Land Cover Classification Using Very High Resolution Imagery. Remote Sens 2015, 7, 153–168. [Google Scholar] [CrossRef]
- Heydari, S.S.; Mountrakis, G. Effect of Classifier Selection, Reference Sample Size, Reference Class Distribution and Scene Heterogeneity in per-Pixel Classification Accuracy Using 26 Landsat Sites. Remote Sens. Environ. 2018, 204, 648–658. [Google Scholar] [CrossRef]
- Noi, P.T.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2018, 18, 18. [Google Scholar]
- Myburgh, G.; van Niekerk, A. Effect of Feature Dimensionality on Object-Based Land Cover Classification: A Comparison of Three Classifiers. South Afr. J. Geomat. 2013, 2, 13–27. [Google Scholar]
- Dean, A.; Voss, D.; Draguljić, D. Response Surface Methodology. In Springer Texts in Statistics; Springer International Publishing: Cham, Switzerland, 2017; pp. 565–614. [Google Scholar]
- Peel, M.C.; Finlayson, B.L.; McMahon, T.A. Updated World Map of the Köppen-Geiger Climate Classification. Hydrol. Earth Syst. Sci. Discuss. 2007, 4, 439–473. [Google Scholar] [CrossRef]
- Drusch, M.; del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- THEIA Value-Adding Products and Algorithms for Land Surfaces. Available online: https://www.theia-land.fr/ (accessed on 20 January 2021).
- Lonjou, V.; Desjardins, C.; Hagolle, O.; Petrucci, B.; Tremas, T.; Dejus, M.; Makarau, A.; Auer, S. MACCS-ATCOR Joint Algorithm (MAJA). In Proceedings of the Remote Sensing of Clouds and the Atmosphere XXI; Comerón, A., Kassianov, E.I., Schäfer, K., Eds.; SPIE: Washington, DC, USA, 2016. [Google Scholar]
- GDAL Documentation. Available online: www.gdal.org (accessed on 20 December 2021).
- Griffiths, P.; Nendel, C.; Hostert, P. Intra-Annual Reflectance Composites from Sentinel-2 and Landsat for National-Scale Crop and Land Cover Mapping. Remote Sens. Environ. 2019, 220, 135–151. [Google Scholar] [CrossRef]
- Rouse, J.W.; Hass, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with ERTS. NASA ERTS Symp. 1973, 1, 309–313. [Google Scholar]
- Gitelson, A.; Merzlyak, M.N. Quantitative Estimation of Chlorophyll-a Using Reflectance Spectra: Experiments with Autumn Chestnut and Maple Leaves. J. Photochem. Photobiol. B 1994, 22, 247–252. [Google Scholar] [CrossRef]
- Gao, B.-C. NDWI—A Normalized Difference Water Index for Remote Sensing of Vegetation Liquid Water from Space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Louhaichi, M.; Borman, M.M.; Johnson, D.E. Spatially Located Platform and Aerial Photography for Documentation of Grazing Impacts on Wheat. Geocarto Int. 2001, 16, 65–70. [Google Scholar] [CrossRef]
- Vincini, M.; Frazzi, E.; D’Alessio, P. A Broad-Band Leaf Chlorophyll Vegetation Index at the Canopy Scale. Precis. Agric. 2008, 9, 303–319. [Google Scholar] [CrossRef]
- Gitelson, A.A. Wide Dynamic Range Vegetation Index for Remote Quantification of Biophysical Characteristics of Vegetation. J. Plant Physiol. 2004, 161, 165–173. [Google Scholar] [CrossRef] [PubMed]
- Lenth, R.V. Response-Surface Methods InR, Usingrsm. J. Stat. Softw. 2009, 32, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Murtagh, F. Multilayer Perceptrons for Classification and Regression. Neurocomputing 1991, 2, 183–197. [Google Scholar] [CrossRef]
- Vapnik, V. The Support Vector Method of Function Estimation. In Nonlinear Modeling; Springer US: Boston, MA, USA, 1998; pp. 55–85. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2019. [Google Scholar]
- Arlot, S.; Celisse, A. A Survey of Cross-Validation Procedures for Model Selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Ramezan, C.A.; Warner, T.A.; Maxwell, A.E. Evaluation of Sampling and Cross-Validation Tuning Strategies for Regional-Scale Machine Learning Classification. Remote Sens. 2019, 11, 185. [Google Scholar] [CrossRef]
- Picard, R.R.; Cook, R.D. Cross-Validation of Regression Models. J. Am. Stat. Assoc. 1984, 79, 575. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Waldner, F.; Chen, Y.; Lawes, R.; Hochman, Z. Needle in a Haystack: Mapping Rare and Infrequent Crops Using Satellite Imagery and Data Balancing Methods. Remote Sens. Environ. 2019, 233, 111375. [Google Scholar] [CrossRef]
- Fowler, J.; Waldner, F.; Hochman, Z. All Pixels Are Useful, but Some Are More Useful: Efficient in Situ Data Collection for Crop-Type Mapping Using Sequential Exploration Methods. ITC J. 2020, 91, 102114. [Google Scholar] [CrossRef]
- Waldner, F.; Jacques, D.C.; Löw, F. The Impact of Training Class Proportions on Binary Cropland Classification. Remote Sens. Lett. 2017, 8, 1122–1131. [Google Scholar] [CrossRef]
- Maponya, M.G.; van Niekerk, A.; Mashimbye, Z.E. Pre-Harvest Classification of Crop Types Using a Sentinel-2 Time-Series and Machine Learning. Comput. Electron. Agric. 2020, 169, 105164. [Google Scholar] [CrossRef]
- Veloso, A.; Mermoz, S.; Bouvet, A.; le Toan, T.; Planells, M.; Dejoux, J.F.; Ceschia, E. Understanding the Temporal Behavior of Crops Using Sentinel-1 and Sentinel-2-like Data for Agricultural Applications. Remote Sens. Environ. 2017, 199, 415–426. [Google Scholar] [CrossRef]
- Zhu, Z.; Gallant, A.L.; Woodcock, C.E.; Pengra, B.; Olofsson, P.; Loveland, T.R.; Jin, S.; Dahal, D.; Yang, L.; Auch, R.F. Optimizing Selection of Training and Auxiliary Data for Operational Land Cover Classification for the LCMAP Initiative. ISPRS J. Photogramm. Remote Sens. 2016, 122, 206–221. [Google Scholar] [CrossRef]
- Shang, M.; Wang, S.-X.; Zhou, Y.; Du, C. Effects of Training Samples and Classifiers on Classification of Landsat-8 Imagery. J. Ind. Soc. Remote Sens. 2018, 46, 1333–1340. [Google Scholar] [CrossRef]
- Zheng, B.; Myint, S.W.; Thenkabail, P.S.; Aggarwal, R.M. A Support Vector Machine to Identify Irrigated Crop Types Using Time-Series Landsat NDVI Data. ITC J. 2015, 34, 103–112. [Google Scholar] [CrossRef]
- Van Niel, T.G.; McVicar, T.R. Determining Temporal Windows for Crop Discrimination with Remote Sensing: A Case Study in South-Eastern Australia. Comput. Electron. Agric. 2004, 45, 91–108. [Google Scholar] [CrossRef]
- Matton, N.; Canto, G.; Waldner, F.; Valero, S.; Morin, D.; Inglada, J.; Arias, M.; Bontemps, S.; Koetz, B.; Defourny, P. An Automated Method for Annual Cropland Mapping along the Season for Various Globally-Distributed Agrosystems Using High Spatial and Temporal Resolution Time Series. Remote Sens. 2015, 7, 13208–13232. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vegetation Indices | Abbreviation | Equation | Reference |
|---|---|---|---|
| Normalized Difference Vegetation Indices | NDVI | [34] | |
| Normalized Difference Red-Edge | NDRE | [35] | |
| Normalized Difference Water Index | NDWI | [36] | |
| Green Normalized Difference Vegetation Index | GNDVI | [37] | |
| Chlorophyll Vegetation Index | CVI | [38] | |
| Green Wide Dynamic Range Vegetation Index | greenWDRVI | [39] |
| Variables | Range and Levels | |||||
|---|---|---|---|---|---|---|
| Coded Variable | −2.0 | −1.0 | 0.0 | +1.0 | +2.0 | |
| Number of tomato training sites | X1 | 100 | 300 | 500 | 700 | 900 |
| Number of ‘other crops’ training sites | X2 | 100 | 300 | 500 | 700 | 900 |
| Lead time (DOY) | X3 | 168 (17 June) | 189 (8 July) | 210 (29 July) | 231 (19 August) | 252 (9 September) |
| Nr | Crops | % | Nr | Crops | % |
|---|---|---|---|---|---|
| 1 | Maize | 42.99 | 7 | Legume | 4.89 |
| 2 | Sorghum | 19.76 | 8 | Potato | 2.49 |
| 3 | Sugar beet | 9.22 | 9 | Onion | 1.79 |
| 4 | Sunflower | 6.20 | 10 | Melon | 0.53 |
| 5 | Forage | 6.16 | 11 | Watermelon | 0.29 |
| 6 | Soybean | 5.69 |
| Acronym | ML Algorithm | Hyperparameter | Values Tested | N |
|---|---|---|---|---|
| SVMr | Support vector machines radial basis function | Cost function parameter c; Margin of error tolerance ɛ | c: From 1 to 10 by step 1; ɛ: From 0.005 to 1.5 by step 0.1 | 150 |
| RF | Random forest | Number of variables available at each node | 2, 3, 5, 10, 20, 30, 50 | 7 |
| NNET | Single-layer perceptron feedforward neural networks | Number of neurons in the hidden layer (size) and decay weight | size: From 2 to 30 by step of 5; decay: From 0.1 to 20 by step of 0.5 | 240 |
| ML Classifier | Response Variable | Equation | R2 | Adj. R2 |
|---|---|---|---|---|
| SVMr | OA | 0.914 − 0.034X1 + 0.049X2 + 0.045X3 + 0.012X1X2 + 0.011X1X3 − 0.013X2X3 + 0.003X12 − 0.020X22 − 0.016X32 | 0.917 | 0.916 |
| GM | 0.924 + 0.016X1 + 0.008X2 + 0.053X3 + 0.018X1X2 − 0.006X1X3 − 0.0006X2X3 − 0.014X12 − 0.010X22 − 0.019X32 | 0.833 | 0.830 | |
| RF | OA | 0.884 − 0.047X1 + 0.074X2 + 0.036X3 + 0.019X1X2 + 0.009X1X3 − 0.008X2X3 + 0.004X12 − 0.029X22 − 0.011X32 | 0.943 | 0.9420 |
| GM | 0.891 + 0.027X1 + 0.012X2 + 0.041X3 + 0.029X1X2 − 0.003X1X3 − 0.0005X2X3 − 0.022X12 − 0.017X22 − 0.014X32 | 0.826 | 0.823 | |
| NNET | OA | 0.892 − 0.036X1 + 0.052X2 + 0.040X3 + 0.011X1 X2 + 0.010X1 X3 − 0.011X2X3 + 0.0039X12 − 0.020X22 − 0.014X32 | 0.935 | 0.934 |
| GM | 0.911 + 0.009X1 + 0.012X2 + 0.047X3 + 0.016X1X2 − 0.004 X1X3 − 0.00002X2X3 − 0.011X12 − 0.011X22 − 0.017X32 | 0.854 | 0.852 |
| ML Classifier | Response Variable | Y | X1 | X2 | X3 |
|---|---|---|---|---|---|
| SVMr | OA | 0.952 | 660 | 710 | 236 |
| GM | 0.970 | 721 | 756 | 234 | |
| RF | OA | 0.938 | 684 | 769 | 239 |
| GM | 0.951 | 832 | 854 | 236 | |
| NNET | OA | 0.931 | 720 | 749 | 237 |
| GM | 0.953 | 702 | 749 | 235 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Croci, M.; Impollonia, G.; Blandinières, H.; Colauzzi, M.; Amaducci, S. Impact of Training Set Size and Lead Time on Early Tomato Crop Mapping Accuracy. Remote Sens. 2022, 14, 4540. https://doi.org/10.3390/rs14184540
Croci M, Impollonia G, Blandinières H, Colauzzi M, Amaducci S. Impact of Training Set Size and Lead Time on Early Tomato Crop Mapping Accuracy. Remote Sensing. 2022; 14(18):4540. https://doi.org/10.3390/rs14184540
Chicago/Turabian StyleCroci, Michele, Giorgio Impollonia, Henri Blandinières, Michele Colauzzi, and Stefano Amaducci. 2022. "Impact of Training Set Size and Lead Time on Early Tomato Crop Mapping Accuracy" Remote Sensing 14, no. 18: 4540. https://doi.org/10.3390/rs14184540