1. Introduction
Remote sensing images are generated by various types of satellite sensors, such as the Moderate Resolution Imaging Spectroradiometer (MODIS), Landsat-equipped sensors, and Sentinel. MODIS sensors are usually installed on Terra and Aqua satellites, which can circle the earth in half a day or one day, and the data obtained by them have superior time resolution. However, the spatial resolution of MODIS data (i.e., rough image) is very low, and accuracy can reach only 250–1000 m [
1]. By contrast, data (fine image) acquired by Landsat have higher spatial resolution (15–30 m) and capture sufficient surface-detail information, but temporal resolution is very low because it takes 16 days to circle the earth [
1]. In practical applications, we often need remote sensing images with high temporal and spatial resolution. For example, images with high temporal and spatial resolutions can be used for research in the fields of heterogeneous regional surface change [
2,
3], vegetation seasonal monitoring [
4], real-time natural disaster mapping [
5], and land-cover changes [
6]. Unfortunately, current technical and cost constraints, coupled with the existence of such noise as cloud cover in some areas, make it challenging to directly obtain remote sensing products with high temporal and spatial resolution, and a single high-resolution image cannot meet practical needs. In order to meet these lacunae, spatiotemporal fusion has attracted considerable attention. In spatiotemporal fusion, two types of images are fused together, with the aim of obtaining images with high spatiotemporal resolution [
7,
8].
Existing spatiotemporal fusion methods can generally be subdivided into four categories: unmixing-based, reconstruction-based, dictionary pair learning-based, and deep learning-based.
Unmixing-based methods unmix the spectral information at the predicted moment, and then use the unmixed result to predict the unknown high spatial and temporal resolution image. Multi-sensor multi-resolution image fusion (MMFN) [
9] was the first fusion method to apply the idea of unmixing. MMFN reconstructs the MODIS and Landsat images separately: first, the MODIS image is spectrally unmixed, and then the mixed result is spectrally reset on the Landsat image to obtain the final reconstruction result. Wu et al. considered the issue of nonlinear time-varying similarity and spatial variation in spectral unmixing, improved MMFN, and obtained a new spatiotemporal fusion method, STDFA [
10], which also achieved good fusion results. A variable spatiotemporal data-fusion algorithm, FSDAF [
11], has also been proposed, which combines the unmixing method, spatial interpolation, and spatiotemporal adaptive fusion algorithm (STARFM) to create a new algorithm that is computationally inexpensive, fast, and accurate, and performs well in heterogeneous regions.
The core idea of the reconstruction-based algorithm is to calculate the weights of similar adjacent pixels in the spectral information in the input and then add them. STARFM was the first method to be used for reconstruction for fusion [
8]. In STARFM, the reflection changes of pixels between the rough image and the fine image should be continuous, and the weights of adjacent pixels can be calculated to reconstruct a surface-reflection image with high spatial resolution. In light of STARFM’s large number of computations and the need to improve the reconstruction effect for heterogeneous regions, Zhu et al. made improvements and proposed an enhanced version of STARFM called ESTARFM [
12]. They use two different coefficients to deal with the weights of adjacent pixels in homogeneous and heterogeneous regions, achieving a better effect. Inspired by STARFM, the spatiotemporal adaptive algorithm for mapping reflection changes (STAARCH) [
13] also achieves good results. Overall, the difference between these algorithms lies in how the weights of adjacent pixels are calculated. Although these algorithms generally have good results, they are unsuitable for data that change too much too quickly.
Dictionary learning-based methods mainly learn the correspondence between two types of remote sensing images to perform prediction. The sparse representation-based spatiotemporal reflection fusion method (SPSTFM) [
14] may be the first fusion method to successfully apply dictionary learning. In SPSTFM, the coefficients of low-resolution images and high-resolution images should be the same, and the super-resolution ideas in the field of natural images are introduced into spatiotemporal fusion. Images are reconstructed by establishing correspondences between low-resolution images. However, in practical situations, the same coefficients may not be applicable to some of the data obtained under the existing conditions [
15]. Wei et al. studied the explicit mapping between low-resolution images and proposed a new fusion method based on dictionary learning and utilizing compressive sensing theory, called compressive sensing spatiotemporal fusion (CSSF) [
16], which improves the accuracy of the prediction results noticeably, but the training time also increases considerably, while the efficiency decreases. In this regard, Liu et al. proposed an extreme learning machine called ELM-FM for spatiotemporal fusion [
17], which considerably reduces time and improves efficiency.
As deep learning has gradually been applied in various fields in recent years, deep learning-based spatiotemporal fusion methods of remote sensing have also advanced. For example, Song et al. proposed STFDCNN [
18] for spatiotemporal fusion using a convolutional neural network. In STFDCNN, the image-reconstruction process is considered a super-resolution and nonlinear mapping problem. A super-resolution network and a nonlinear mapping network are constructed through an intermediate resolution image, and the final fusion result is obtained through high-pass modulation. STFDCNN achieved good results. Liu et al. proposed a two-stream CNN, StfNet [
19], for spatiotemporal fusion. They effectively extracted and fused spatial details and temporal information using spatial consistency and temporal dependence, and achieved good results. On the basis of spatial consistency and time dependence, Chen et al. introduced a multiscale mechanism for feature extraction and proposed a spatiotemporal remote sensing image-fusion method based on multiscale two-stream CNN (STFMCNN) [
20]. Jia et al. proposed a new deep learning-based two-stream convolutional neural network [
21], which fuses the temporal variation information with the spatial detail information by weight, which enhances its robustness. Furthermore, Jia et al. adopted various prediction methods for phenological change and land-cover change, and proposed a spatiotemporal fusion method based on hybrid deep learning to combine satellite images with differing resolutions [
22]. Tan et al. proposed DCSTFN [
23] to derive high spatiotemporal remote sensing images using CNNs based on the methods of convolution and deconvolution combined with the fusion method of STARFM. However, in light of the loss of information in the reconstruction process of the deconvolution fusion method, Tan et al. increased the input of the a priori moment and added a residual coding block, using a composite loss function to improve the learning ability of the network, and an enhanced convolutional neural network EDCSTFN [
24] was proposed for spatiotemporal fusion. In addition, CycleGAN-STF [
25] introduces other ideas in the visual field into spatiotemporal fusion. It achieves spatiotemporal fusion through image generation of CycleGAN. CycleGAN is used to generate a fine image at the predicted time, the real image is used at the predicted time to select the closest generated image, and finally FSDAF is used for fusion. Other fusion methods are applied in specific scenarios. For example, STTFN [
26], a CNN-based model for spatiotemporal fusion of surface-temperature changes, uses a multiscale CNN to establish a nonlinear mapping relationship and a spatiotemporal continuity weight strategy for fusion, achieving good results. DenseSTF [
27], a deep learning-based spatiotemporal data-fusion algorithm, uses a block-to-point modeling strategy and model comparison to provide rich texture details for each target pixel to deal with heterogeneous regions, and achieves very good results. Furthermore, with the development of transformer models [
28] in the natural language field, many researchers have introduced the concept into the vision field as well, e.g., vision transformer (ViT) [
29], data-efficient image transformer (DeiT) [
30], conditional position encoding visual transformer (CPVT) [
31], transformer-in-transformer (TNT) [
32], and convolutional vision transformer (CvT) [
33] can be used for image classification. In addition, there are the Swin transformer [
34] for image classification, image segmentation, and object detection, and texture transformer [
35] for general image superclassification. These variants have been gradually introduced into the spatiotemporal fusion of remote sensing. For example, MSNet [
36] is a new method obtained by introducing the original transformer and ViT into spatiotemporal fusion, learning the global temporal correlation information of the image through the transformer structure, using the convolutional neural network to establish the relationship between input and output, and finally obtain a good effect. SwinSTFM [
37] is a new method that introduces the Swin transformer and combines linear spectral mixing theory, which finally improves the quality of generated images. There is also MSFusion [
38], which introduces texture transformer into spatiotemporal fusion, which has also achieved quite good results on multiple datasets.
Existing spatiotemporal fusion algorithms perform a certain amount of information extraction and noise processing during the fusion process, but there remain certain lacunae. First, the acquisition and processing of suitable datasets is not easy. Owing to the existence of noise, the data that can be directly used for research are insufficient. In deep learning, the size of the dataset affects the learning ability during reconstruction: achieving good reconstruction with small datasets is a major challenge. Second, the same fusion model can have different prediction performance on different datasets, and the model is not robust. Furthermore, the features extracted only by the CNN are not sufficient, and an increase of the network depth will also result in potential feature loss.
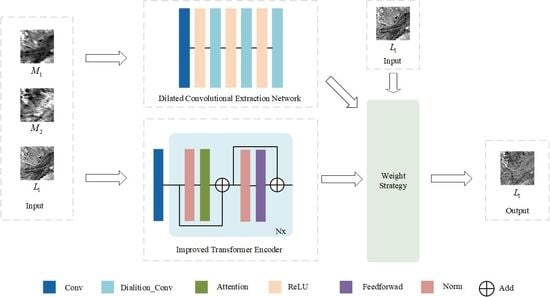
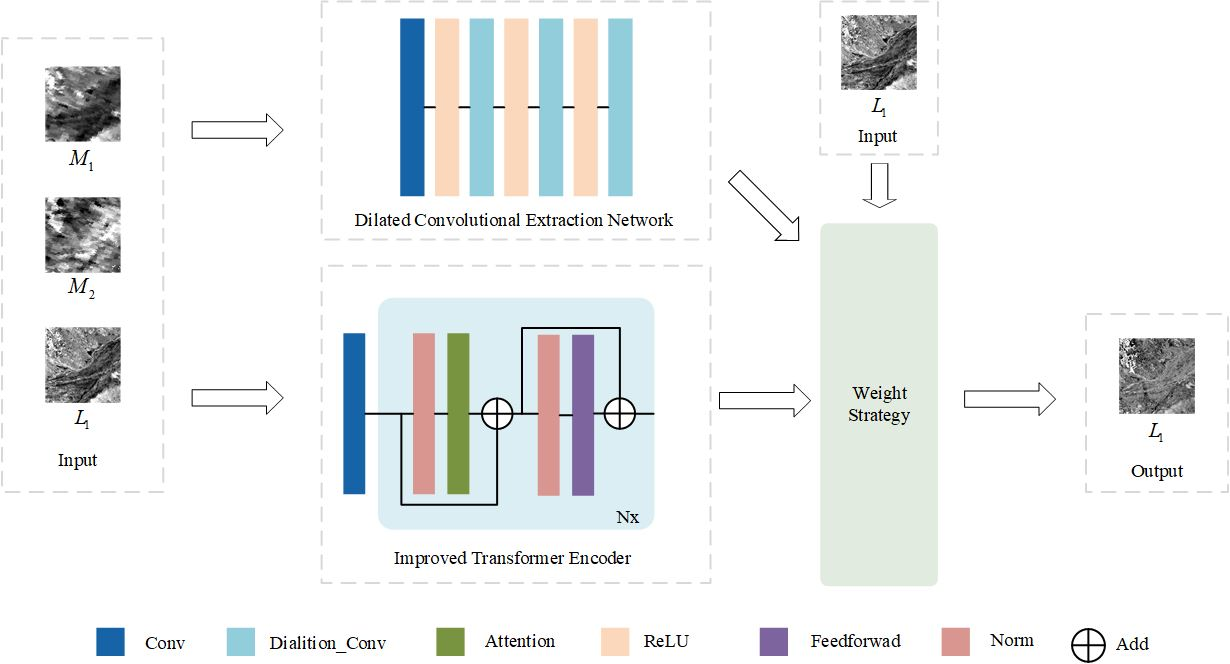
In order to address the aforementioned challenges, this study improves MSNet and proposes an enhanced version of the spatiotemporal fusion method of multi-stream remote sensing images called EMSNet. In EMSNet, the input image adopts the original scale size, and the rough image is no longer scaled to fully extract the temporal information and reduce the loss. The main contributions of this paper are summarized as follows.
- (1)
The number of prior input images required by the model is reduced from five to three, which achieves better results with less input, so that even a dataset with a small amount of data can reconstruct images with better effects.
- (2)
The transformer encoder structure is introduced and its projection method improved to obtain the improved transformer encoder (ITE), which adapts the remote sensing spatiotemporal fusion, effectively learns the relationship between local and global information in rough and fine images, and effectively extracts temporal and spatial information.
- (3)
Dilated convolution is used to extract temporal information, which expands the receptive field while keeping the parameter quantity unchanged and fully extracts a large amount of temporal feature information contained in the rough image.
- (4)
A new feature-fusion strategy is used to fuse the features extracted by the ITE and dilated convolution based on their differences from real predicted images in order to avoid introducing noise.
The rest of the article has the following structure. The overall structure of EMSNet and its internal specific modules and weight strategies are introduced in
Section 2. Experimental results are described in
Section 3, along with the datasets used.
Section 4 dis-cusses the performance of EMSNet. Finally, conclusions are provided.
4. Discussion
Through the experiments, it can be seen that whether it is on the CIA dataset with phenological changes in regular areas or on the AHB dataset with phenological changes with a large number of irregular areas and a large number of heterogeneous areas, our proposed method is better at prediction. Similarly, for LGC datasets, which are mainly land cover-type changes, the proposed method is better at prediction than traditional methods and other deep learning-based methods in the processing of temporal information and high-frequency spatial details. The time information and high-frequency file texture information are processed more appropriately because of the combination of ITE and dilated convolution in EMSNet. More importantly, the refined ITE can further expand the range of learning in the remote sensing field, and can fully extract the spatiotemporal information contained in the input image.
It is worth noting that for datasets with different amounts of data and different characteristics, the depth of the improved transformer encoder (ITE) should also be different to better fit the datasets.
Table 4 lists the average evaluation values of the prediction results obtained without the ITE and with the ITE with different depths, where the optimal value is shown in bold. The depth being 0 indicates that the ITE has not been introduced. It can be seen that when the depth is not introduced, the experimental results are relatively poor. As the depth changes, the results obtained vary. The best experimental results are obtained when the depth of the CIA dataset is 20, the depth of the LGC dataset is 5, and the depth of the AHB dataset is 20.
In addition, the difference between the original linear projection method of the transformer encoder and the improved convolution projection method was also determined.
Table 5 lists the global indicators and average evaluation values of the prediction results obtained under various projection methods, where the optimal value is shown in bold. It can be seen that on the three datasets, the convolutional projection method is selected, and the ITE after position encoding is removed achieves better results.
Furthermore, the last six layers of the network for extracting time information in
Figure 3 include three layers of dilated convolution and three layers of ReLU. This paper also conducts a comparative experiment on the three layers of dilated convolution operations.
Table 6 lists the different result evaluations obtained when using convolution and dilated convolution. Among them, “conv” in the difference column means to replace the above-mentioned three layers of dilated convolution with three layers of convolution; “conv_dia” means that the above-mentioned three layers of dilated convolution remain unchanged, and “conv&conv_dia” means that the abovementioned three layers of dilated convolution are replaced by a three-layer alternating operation of convolution, dilated convolution and convolution. It can be seen that when the subsequent operations of extracting time information are all dilated convolutions, the implementation effect is better.
Although the proposed method has achieved good results, there are issues worthy of further exploration. First, in order to fully expand the learnable range of the ITE, the original input of a larger MODIS image has been used. Although dilated convolution is used to reduce the number of parameters, compared with MSNet, the number of parameters in this study is quite high.
Table 7 presents the fusion model of deep learning and the number of parameters that the proposed method needs to learn. It can be seen that the proposed method needs the largest number of parameters, which means that compared with other methods, it requires more training time and equipment with larger memory during training. Considering the cost of learning, a way to obtain better results with a smaller model is a direction worthy of future research. Second, the refined ITE shows very good performance, but further improvements to adapt it to remote sensing spatiotemporal fusion can be researched in future. Furthermore, improving the fusion effect while avoiding the fusion strategy introduced by noise is also worthy of further study.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}