


A Two-Step Machine Learning Approach for Crop Disease Detection Using GAN and UAV Technology


Abstract
:1. Introduction
1.1. Related Work
1.2. Our Contributions
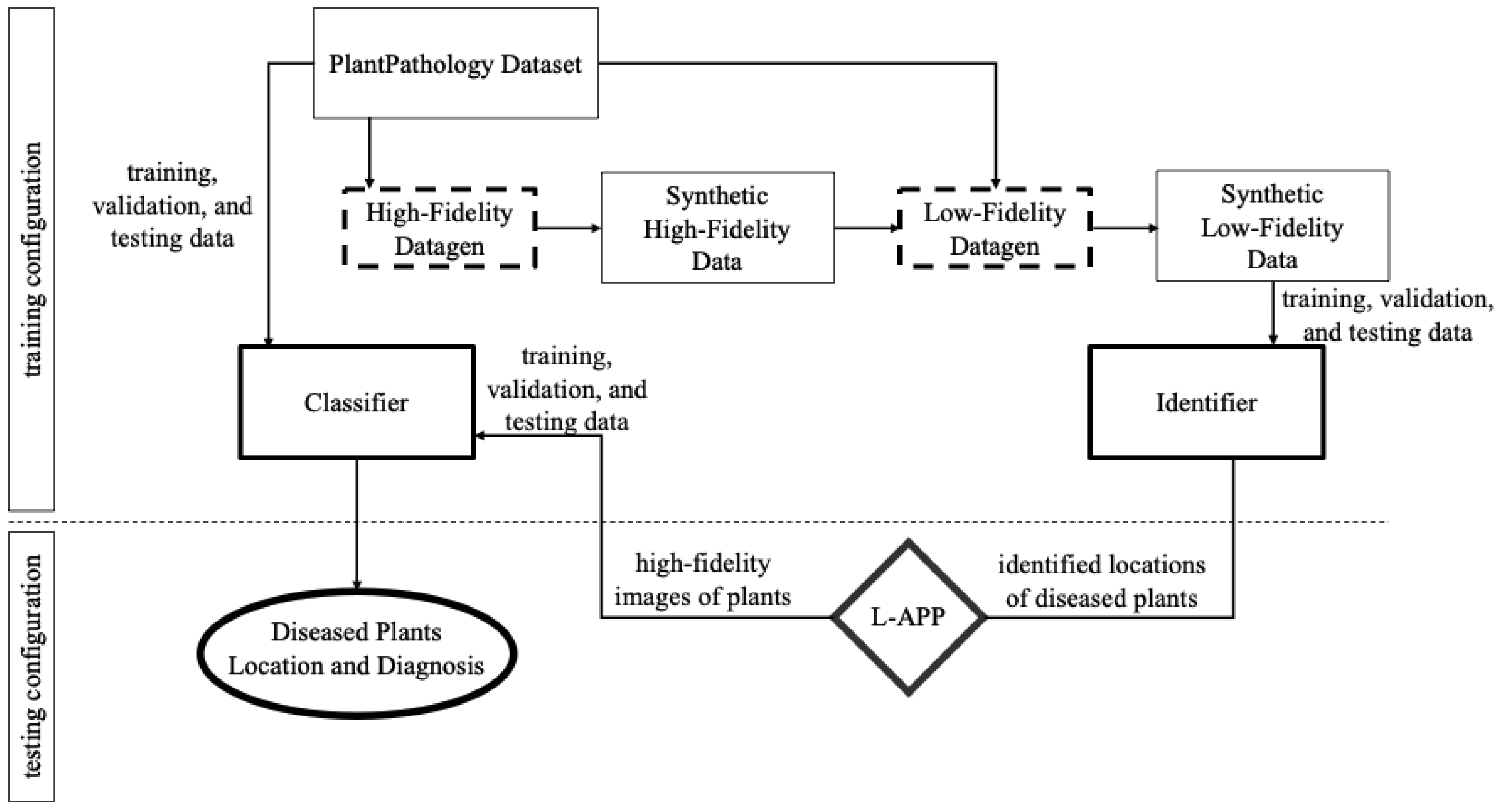
2. Materials and Methods
2.1. Data Generation: High-Fidelity Datagen and Low-Fidelity Datagen
2.1.1. High-Fidelity Data Generation
2.1.2. Low-Fidelity Data Generation
2.2. Modeling Pipeline: Identifier and Classifier
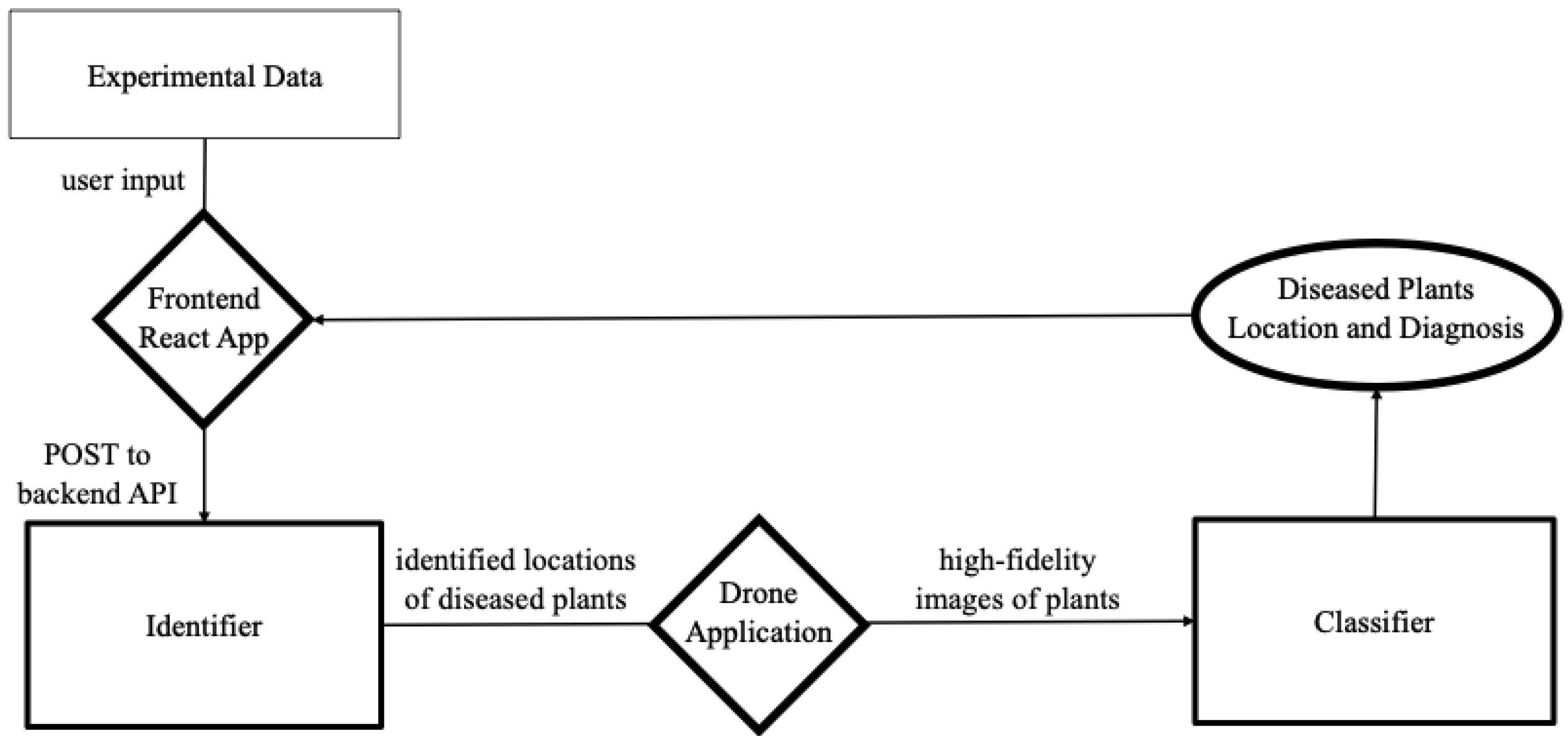
2.3. A Tech Stack Overview
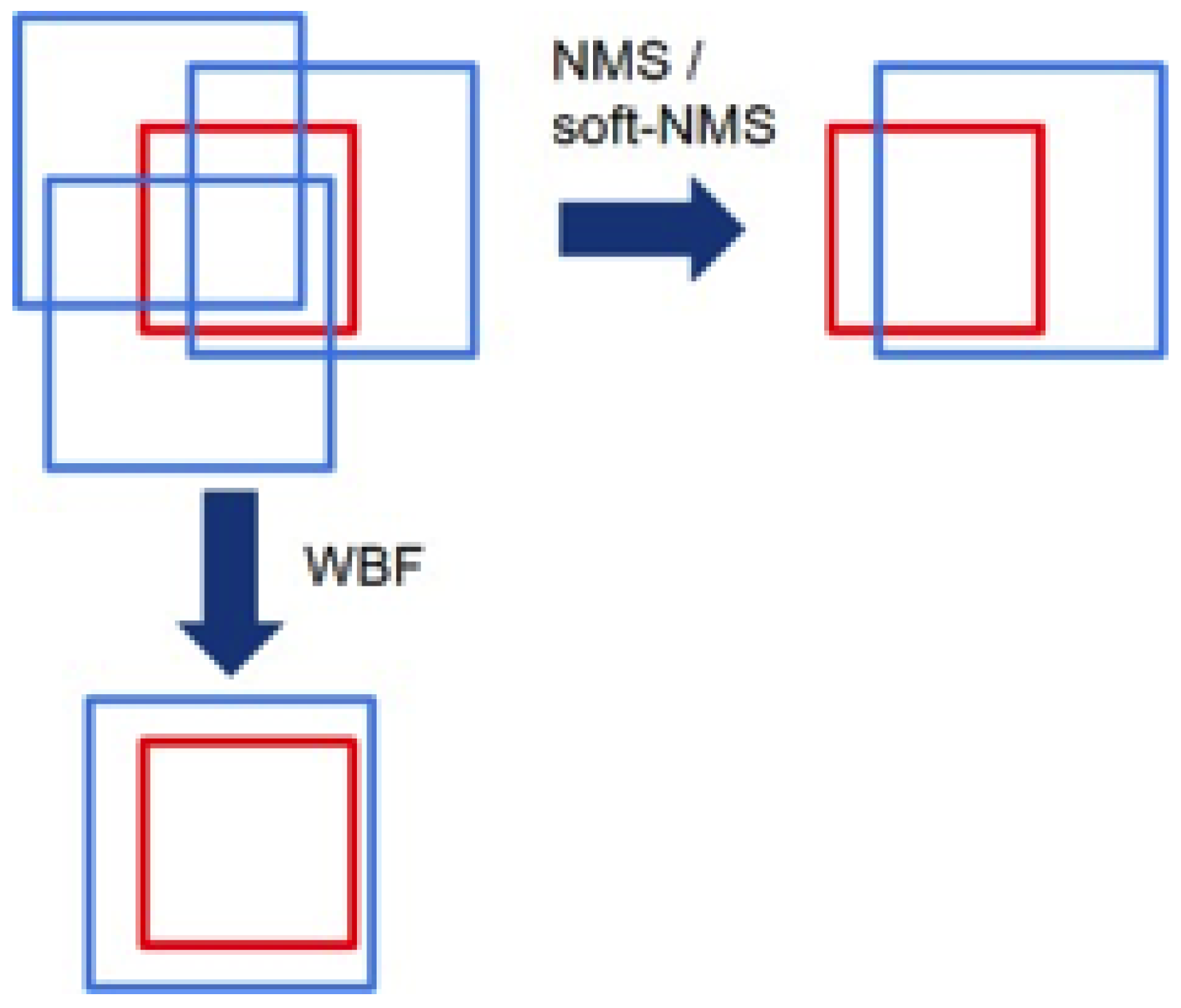
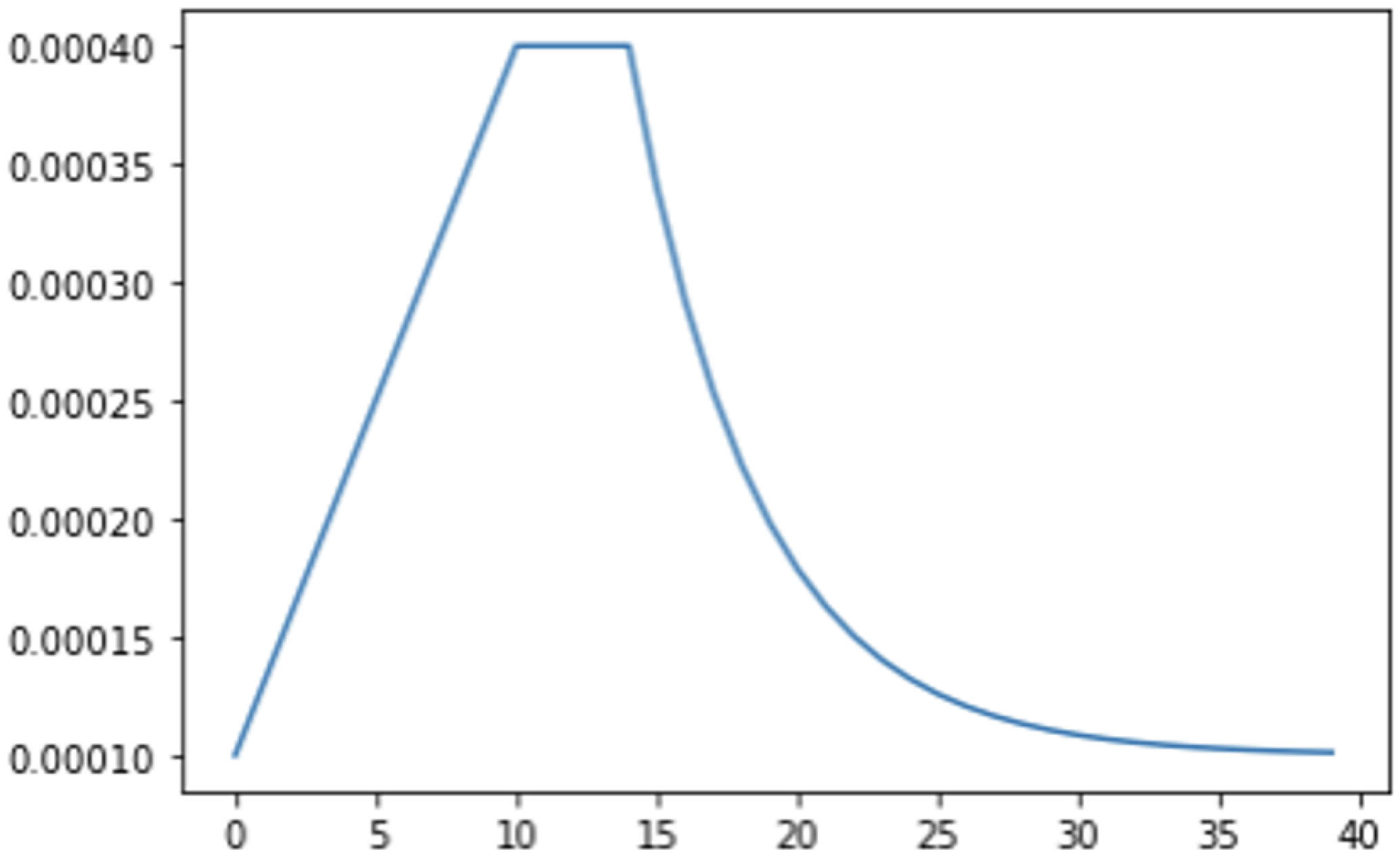
2.4. Computer Vision Tools
3. Results
3.1. Datasets and Experimental Setup
3.2. Experimental Results
4. Discussion
- The first is to address the possibility that the model is relying too heavily on unnatural artifacts present in the low-fidelity synthetic data. Some ways we could accustom the model for this dataset are: (1) more accurately labeling boxes around images so that they do not overlap; (2) the contribution of the pixels at the border of the original image could be increased by adding layers of zeros to the original image (padding) and this would help preserve the information at the borders, recognizing the lack of padding within the low-fidelity data, which we could fix by predicting smaller boxes; and (3) using the classifier to confirm or deny the bounding-box predictions within the identifier.
- The second big hindrance to the identifier was simply the size of the data. Even optimizing with a GPU, it took around 16 h to run through around 2000 images. This meant we were unable to iterate through a higher-lever optimization of the model including identifying optimal hyperparameters and arrangements of the data augmentation steps. This would have to be addressed through rigorous code optimization because runtime issues are common throughout much of the identifier’s code, especially in places that deal with data.
- Finally, tests in this paper were conducted on only one crop, apples. For a more complete evaluation of the gains achievable by our framework, it would have to be trained and tested on other major crops. In the present paper, our far-field, low-resolution test data were artificially constructed from real images of diseased and healthy plants. The next step in the direction of obtaining an estimate of the model’s performance in the field with true drone data would be first to collect both far-field low-fidelity drone images of crops and close-up high-fidelity images of both healthy and diseased plants in the low-fidelity drone images. A small set of such images could be augmented to a larger training dataset to train a field model, which would then be tested on a smaller hold-out set of the far-field and associated high-fidelity images. Admittedly, this process would require investment of time and money to generate labeled data, but as demonstrated in this paper, the data requirements of our model are very modest, which would keep training costs minimal.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- FAO. Food and Agriculture Organization of the United Nations: International Plant Protection Convention. Available online: https://www.fao.org/plant-health-2020/about/en (accessed on 17 September 2022).
- Barbedo, J.G.A. A review on the use of unmanned aerial vehicles and imaging sensors for monitoring and assessing plant stresses. Drones 2019, 3, 40. [Google Scholar] [CrossRef]
- Bock, C.H.; Barbedo, J.G.; Del Ponte, E.M.; Bohnenkamp, D.; Mahlein, A.K. From visual estimates to fully automated sensor-based measurements of plant disease severity: Status and challenges for improving accuracy. Phytopathol. Res. 2020, 2, 9. [Google Scholar] [CrossRef]
- Del Ponte, E.M.; Pethybridge, S.J.; Bock, C.H.; Michereff, S.J.; Machado, F.J.; Spolti, P. Standard area diagrams for aiding severity estimation: Scientometrics, pathosystems, and methodological trends in the last 25 years. Phytopathology 2017, 107, 1161–1174. [Google Scholar] [CrossRef] [PubMed]
- Duarte-Carvajalino, J.M.; Alzate, D.F.; Ramirez, A.A.; Santa-Sepulveda, J.D.; Fajardo-Rojas, A.E.; Soto-Suárez, M. Evaluating late blight severity in potato crops using unmanned aerial vehicles and machine learning algorithms. Remote Sens. 2018, 10, 1513. [Google Scholar] [CrossRef]
- Sugiura, R.; Tsuda, S.; Tamiya, S.; Itoh, A.; Nishiwaki, K.; Murakami, N.; Shibuya, Y.; Hirafuji, M.; Nuske, S. Field phenotyping system for the assessment of potato late blight resistance using RGB imagery from an unmanned aerial vehicle. Biosyst. Eng. 2016, 148, 1–10. [Google Scholar] [CrossRef]
- Singh, D.; Jackson, G.; Hunter, D.; Fullerton, R.; Lebot, V.; Taylor, M.; Iosefa, T.; Okpul, T.; Tyson, J. Taro leaf blight—A threat to food security. Agriculture 2012, 2, 182–203. [Google Scholar] [CrossRef]
- Gao, D.; Sun, Q.; Hu, B.; Zhang, S. A framework for agricultural pest and disease monitoring based on internet-of-things and unmanned aerial vehicles. Sensors 2020, 20, 1487. [Google Scholar] [CrossRef] [PubMed]
- Fasoula, D.A. Nonstop selection for high and stable crop yield by two prognostic equations to reduce yield losses. Agriculture 2012, 2, 211–227. [Google Scholar] [CrossRef]
- Thapa, R.; Snavely, N.; Belongie, S.; Khan, A. The plant pathology 2020 challenge dataset to classify foliar disease of apples. arXiv 2020, arXiv:2004.11958. [Google Scholar]
- Hughes, D.; Salathé, M. An open access repository of images on plant health to enable the development of mobile disease diagnostics. arXiv 2015, arXiv:1511.08060. [Google Scholar]
- Nazki, H.; Yoon, S.; Fuentes, A.; Park, D.S. Unsupervised image translation using adversarial networks for improved plant disease recognition. Comput. Electron. Agric. 2020, 168, 105117. [Google Scholar] [CrossRef]
- Joshi, C. Generative Adversarial Networks (GANs) for Synthetic Dataset Generation with Binary Classes. 2020. Available online: https://datasciencecampus.ons.gov.uk/projects/generative-adversarial-networks-gans-for-synthetic-dataset-generation-with-binary-classes/ (accessed on 22 September 2022).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Wang, G.; Sun, Y.; Wang, J. Automatic image-based plant disease severity estimation using deep learning. Comput. Intell. Neurosci. 2017, 2017, 2917536. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Wightman, R. Genetic Efficient Nets for PyTorchs. 2021. Available online: https://github.com/rwightman/efficientdet-pytorch (accessed on 22 September 2022).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| id | bbox | Class Label |
|---|---|---|
| Train_1609.jpg | [64, 0, 64, 43] | 1 |
| Train_1028.jpg | [128, 0, 64, 43] | 1 |
| Train_354.jpg | [192, 0, 64, 43] | 1 |
| Train_1082.jpg | [256, 0, 64, 43] | 0 |
| Train_10.jpg | [320, 0, 64, 43] | 1 |
| Train_1280.jpg | [384, 0, 64, 43] | 1 |
| Train_463.jpg | [448, 0, 64, 43] | 1 |
| Train_1178.jpg | [512, 0, 64, 43] | 1 |
| Image_id | # Healthy | # Multiple_Diseases | # Rust | # Scab |
|---|---|---|---|---|
| Train_0.jpg | 0 | 0 | 0 | 1 |
| Train_1.jpg | 0 | 1 | 0 | 0 |
| Train_2.jpg | 1 | 0 | 0 | 0 |
| Train_3.jpg | 0 | 0 | 1 | 0 |
| Train_4.jpg | 1 | 0 | 0 | 0 |
| Train_5.jpg | 1 | 0 | 0 | 0 |
| Train_6.jpg | 0 | 1 | 0 | 0 |
| Train_7.jpg | 0 | 0 | 0 | 1 |
| Train_8.jpg | 0 | 0 | 0 | 1 |
| Train_9.jpg | 1 | 0 | 0 | 0 |
| Train_10.jpg | 0 | 0 | 1 | 0 |
| Test | Average Positive | Average Negative | Accuracy |
|---|---|---|---|
| Summary Loss | Confidence on Test Data | Confidence on Test Data | On Test Data |
| 1.89142 | 0.54998 | 0.20468 | 0.75466 |
| Healthy (p) | Rust (p) | Scab (p) | Multiple Diseases (p) | Sum | |
|---|---|---|---|---|---|
| Healthy (a) | 47 | 0 | 0 | 0 | 47 |
| Rust (a) | 1 | 55 | 0 | 0 | 56 |
| Scab (a) | 0 | 0 | 52 | 1 | 53 |
| Multiple diseases (a) | 1 | 2 | 1 | 4 | 8 |
| Precision | Recall | -Score | Support | |
|---|---|---|---|---|
| Healthy | 0.96 | 1.00 | 0.98 | 47 |
| Rust | 0.96 | 0.98 | 0.97 | 56 |
| Scab | 0.98 | 0.98 | 0.98 | 53 |
| Multiple diseases | 0.80 | 0.50 | 0.62 | 8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prasad, A.; Mehta, N.; Horak, M.; Bae, W.D. A Two-Step Machine Learning Approach for Crop Disease Detection Using GAN and UAV Technology. Remote Sens. 2022, 14, 4765. https://doi.org/10.3390/rs14194765
Prasad A, Mehta N, Horak M, Bae WD. A Two-Step Machine Learning Approach for Crop Disease Detection Using GAN and UAV Technology. Remote Sensing. 2022; 14(19):4765. https://doi.org/10.3390/rs14194765
Chicago/Turabian StylePrasad, Aaditya, Nikhil Mehta, Matthew Horak, and Wan D. Bae. 2022. "A Two-Step Machine Learning Approach for Crop Disease Detection Using GAN and UAV Technology" Remote Sensing 14, no. 19: 4765. https://doi.org/10.3390/rs14194765
APA StylePrasad, A., Mehta, N., Horak, M., & Bae, W. D. (2022). A Two-Step Machine Learning Approach for Crop Disease Detection Using GAN and UAV Technology. Remote Sensing, 14(19), 4765. https://doi.org/10.3390/rs14194765