
Blind Restoration of Atmospheric Turbulence-Degraded Images Based on Curriculum Learning

Abstract
:1. Introduction
- (1)
- For the tightly coupled priors of additive noise and blur, a noise suppression-based neural network model is designed for restoration of turbulence-degraded images. It achieves image deconvolution while suppressing additive noise to benefit the restoration of turbulence-degraded images.
- (2)
- A local-to-global and easy-to-difficult curriculum learning strategy is proposed to ensure that the proposed neural network first focuses on noise suppression and then removes blur to achieve the reconstruction of turbulence-degraded images.
- (3)
- A multi-scale fusion module and a non-local attention-based noise suppression module are designed and used in the NSRN so that the proposed network denoises through multi-scale and multi-level non-local information fusion while preserving the image’s intrinsic information.
- (4)
- The back-projection idea [39] is introduced and combined with the U-NET for the final refined reconstruction of the image.
2. Related Work
2.1. Model-Based Image Restoration
2.2. End-to-End CNN-Based Methods
2.3. Plug-and-Play with Deep CNN Denoiser
3. Proposed Method
3.1. Motivation
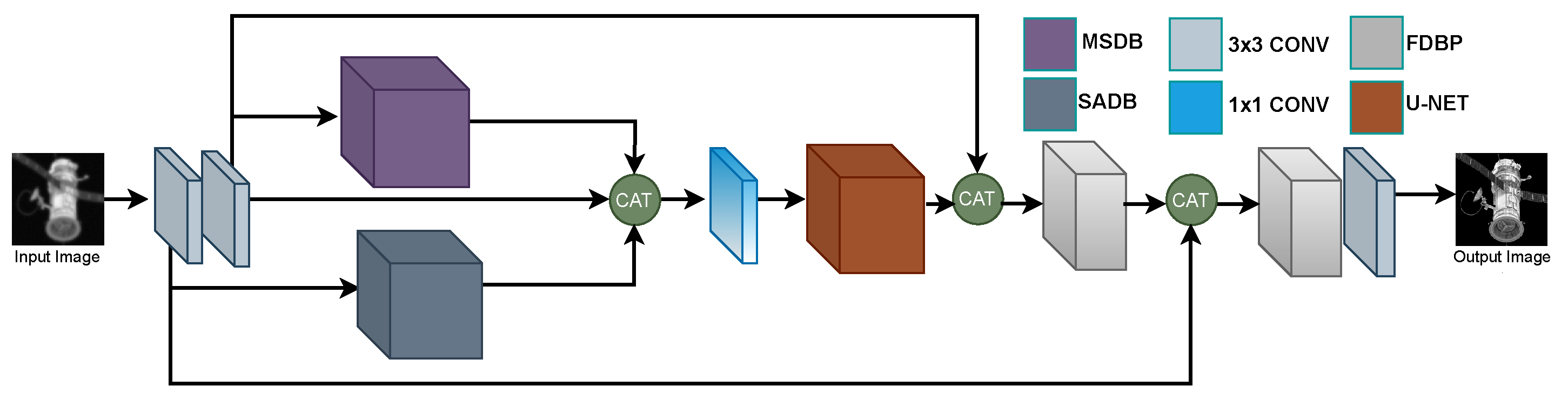
3.2. Proposed Network Model
3.2.1. MSDB
3.2.2. SADB
3.2.3. AU-NET
3.2.4. FDBP
3.3. Curriculum Learning Strategy
3.3.1. Local-to-Global Network Learning
3.3.2. Easy-to-Difficult Data Curriculum Learning
| Algorithm 1 Systematic curriculum learning algorithm for NSRN | ||
| Require: | ||
| B: number of MSDB and SADB training; | ||
| : NSRN training set; | ||
| : weight initialization. | ||
| Ensure: | ||
| NSRN(w): parameters of NSRN. | ||
| 1: | Begin: | |
| /* local-to-global learning */ | ||
| 2: | MSDB learning: , where is the parameter of MSDB | |
| 3: | SADB learning: , where is the parameter of SADB | |
| /* easy-to-difficult learning */ | ||
| 4: | Initialize MSDB in NSRN with | |
| 5: | Initialize SADB in NSRN with | |
| 6: | for each do | |
| 7: | NSRN learning: NSRN | |
| 8: | end for | |
| 9: | Initialize NSRN with | |
| 10: | Train NSRN with all training data D | |
| 11: | Output: NSRN | |
4. Experiments and Discussions
4.1. Dataset
4.2. Metrics for Evaluation and Methods for Comparison
4.3. Ablation Experiment
4.4. Experiments and Comparative Analysis of Simulated Images
- (1)
- Model for mild degradation
- (2)
- Model for moderate degradation
- (3)
- Model for severe degradation
4.5. Experiments and Comparative Analysis of Real Images
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jefferies, S.M.; Hart, M. Deconvolution from wave front sensing using the frozen flow hypothesis. Opt. Express 2011, 19, 1975–1984. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z.; Shen, C.; Xie, C. Stacked convolutional auto-encoders for single space target image blind deconvolution. Neurocomputing 2018, 313, 295–305. [Google Scholar] [CrossRef]
- Mourya, R.; Denis, L.; Becker, J.M.; Thiébaut, E. A blind deblurring and image decomposition approach for astronomical image restoration. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; IEEE: New York, NY, USA, 2015; pp. 1636–1640. [Google Scholar]
- Yan, L.; Jin, M.; Fang, H.; Liu, H.; Zhang, T. Atmospheric-turbulence-degraded astronomical image restoration by minimizing second-order central moment. IEEE Geosci. Remote Sens. Lett. 2012, 9, 672–676. [Google Scholar]
- Zhu, X.; Milanfar, P. Removing atmospheric turbulence via space-invariant deconvolution. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 157–170. [Google Scholar] [CrossRef]
- Xie, Y.; Zhang, W.; Tao, D.; Hu, W.; Qu, Y.; Wang, H. Removing turbulence effect via hybrid total variation and deformation-guided kernel regression. IEEE Trans. Image Process. 2016, 25, 4943–4958. [Google Scholar] [CrossRef]
- Gilles, J.; Dagobert, T.; De Franchis, C. Atmospheric Turbulence Restoration by Diffeomorphic Image Registration and Blind Deconvolution. In Advanced Concepts for Intelligent Vision Systems; Springer: Berlin/Heidelberg, Germany, 2008; pp. 400–409. [Google Scholar]
- Jin, M.; Meishvili, G.; Favaro, P. Learning to extract a video sequence from a single motion-blurred image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6334–6342. [Google Scholar]
- Xu, X.; Pan, J.; Zhang, Y.J.; Yang, M.H. Motion blur kernel estimation via deep learning. IEEE Trans. Image Process. 2017, 27, 194–205. [Google Scholar] [CrossRef]
- Zhou, C.; Lin, S.; Nayar, S.K. Coded aperture pairs for depth from defocus and defocus deblurring. Int. J. Comput. Vis. 2011, 93, 53–72. [Google Scholar] [CrossRef]
- Vasu, S.; Maligireddy, V.R.; Rajagopalan, A. Non-blind deblurring: Handling kernel uncertainty with cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3272–3281. [Google Scholar]
- Zhang, J.; Pan, J.; Lai, W.S.; Lau, R.W.; Yang, M.H. Learning fully convolutional networks for iterative non-blind deconvolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3817–3825. [Google Scholar]
- Schuler, C.J.; Hirsch, M.; Harmeling, S.; Schölkopf, B. Learning to deblur. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1439–1451. [Google Scholar] [CrossRef]
- Zhang, Y.; Lau, Y.; Kuo, H.w.; Cheung, S.; Pasupathy, A.; Wright, J. On the global geometry of sphere-constrained sparse blind deconvolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4894–4902. [Google Scholar]
- Dai, C.; Lin, M.; Wu, X.; Zhang, D. Single hazy image restoration using robust atmospheric scattering model. Signal Process. 2020, 166, 107257. [Google Scholar] [CrossRef]
- Hu, D.; Tan, J.; Zhang, L.; Ge, X.; Liu, J. Image deblurring via enhanced local maximum intensity prior. Signal Process. Image Commun. 2021, 96, 116311. [Google Scholar] [CrossRef]
- Zhang, H.; Wipf, D.; Zhang, Y. Multi-image blind deblurring using a coupled adaptive sparse prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1051–1058. [Google Scholar]
- Xu, L.; Zheng, S.; Jia, J. Unnatural l0 sparse representation for natural image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1107–1114. [Google Scholar]
- Rostami, M.; Michailovich, O.; Wang, Z. Image Deblurring Using Derivative Compressed Sensing for Optical Imaging Application. IEEE Trans. Image Process. 2012, 21, 3139–3149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, R.; Wang, Z.; Fan, Y.; Fengg, D. Atmospheric turbulence mitigation based on turbulence extraction. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 1442–1446. [Google Scholar] [CrossRef]
- Li, D.; Mersereau, R.M.; Simske, S. Atmospheric Turbulence-Degraded Image Restoration Using Principal Components Analysis. IEEE Geosci. Remote Sens. Lett. 2007, 4, 340–344. [Google Scholar] [CrossRef]
- Krishnan, D.; Fergus, R. Fast image deconvolution using hyper-Laplacian priors. Adv. Neural Inf. Process. Syst. 2009, 22, 1033–1041. [Google Scholar]
- Perrone, D.; Favaro, P. Total variation blind deconvolution: The devil is in the details. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2909–2916. [Google Scholar]
- Pan, J.; Hu, Z.; Su, Z.; Yang, M.H. Deblurring text images via L0-regularized intensity and gradient prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2901–2908. [Google Scholar]
- Mou, C.; Zhang, J. Graph Attention Neural Network for Image Restoration. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; IEEE: New York, NY, USA, 2021; pp. 1–6. [Google Scholar]
- Anwar, S.; Barnes, N.; Petersson, L. Attention-Based Real Image Restoration. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Yu, K.; Wang, X.; Dong, C.; Tang, X.; Loy, C.C. Path-restore: Learning network path selection for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7078–7092. [Google Scholar] [CrossRef]
- Chen, G.; Gao, Z.; Wang, Q.; Luo, Q. U-net like deep autoencoders for deblurring atmospheric turbulence. J. Electron. Imaging 2019, 28, 053024. [Google Scholar] [CrossRef]
- Liu, B.; Shu, X.; Wu, X. Demoiréing of Camera-Captured Screen Images Using Deep Convolutional Neural Network. arXiv 2018, arXiv:1804.03809. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Tian, C.; Xu, Y.; Li, Z.; Zuo, W.; Fei, L.; Liu, H. Attention-guided CNN for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar] [CrossRef]
- Retraint, F.; Zitzmann, C. Quality factor estimation of jpeg images using a statistical model. Digit. Signal Process. 2020, 103, 102759. [Google Scholar] [CrossRef]
- Sim, H.; Kim, M. A deep motion deblurring network based on per-pixel adaptive kernels with residual down-up and up-down modules. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, H.; Dai, Y.; Li, H.; Koniusz, P. Deep stacked hierarchical multi-patch network for image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5978–5986. [Google Scholar]
- Mao, Z.; Chimitt, N.; Chan, S.H. Accelerating Atmospheric Turbulence Simulation via Learned Phase-to-Space Transform. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14759–14768. [Google Scholar]
- Zhang, K.; Li, Y.; Zuo, W.; Zhang, L.; Van Gool, L.; Timofte, R. Plug-and-play image restoration with deep denoiser prior. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6360–6376. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Chen, G.; Gao, Z.; Wang, Q.; Luo, Q. Blind de-convolution of images degraded by atmospheric turbulence. Appl. Soft Comput. 2020, 89, 106131. [Google Scholar] [CrossRef]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1664–1673. [Google Scholar]
- Chatterjee, M.R.; Mohamed, A.; Almehmadi, F.S. Secure free-space communication, turbulence mitigation, and other applications using acousto-optic chaos. Appl. Opt. 2018, 57, C1–C13. [Google Scholar] [CrossRef] [PubMed]
- Ramos, A.A.; de la Cruz Rodríguez, J.; Yabar, A.P. Real-time, multiframe, blind deconvolution of solar images. Astron. Astrophys. 2018, 620, A73. [Google Scholar] [CrossRef]
- Zha, Z.; Wen, B.; Yuan, X.; Zhou, J.; Zhu, C. Image restoration via reconciliation of group sparsity and low-rank models. IEEE Trans. Image Process. 2021, 30, 5223–5238. [Google Scholar] [CrossRef]
- Zha, Z.; Yuan, X.; Zhou, J.; Zhu, C.; Wen, B. Image restoration via simultaneous nonlocal self-similarity priors. IEEE Trans. Image Process. 2020, 29, 8561–8576. [Google Scholar] [CrossRef] [PubMed]
- Venkatakrishnan, S.V.; Bouman, C.A.; Wohlberg, B. Plug-and-play priors for model based reconstruction. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; IEEE: New York, NY, USA, 2013; pp. 945–948. [Google Scholar]
- Wei, K.; Aviles-Rivero, A.; Liang, J.; Fu, Y.; Schönlieb, C.B.; Huang, H. Tuning-free plug-and-play proximal algorithm for inverse imaging problems. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 10158–10169. [Google Scholar]
- Nair, P.; Gavaskar, R.G.; Chaudhury, K.N. Fixed-point and objective convergence of plug-and-play algorithms. IEEE Trans. Comput. Imaging 2021, 7, 337–348. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Hradiš, M.; Kotera, J.; Zemcık, P.; Šroubek, F. Convolutional neural networks for direct text deblurring. In Proceedings of the BMVC, Swansea, UK, 7–10 September 2015; Volume 10. [Google Scholar]
- Mao, X.; Shen, C.; Yang, Y.B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. Adv. Neural Inf. Process. Syst. 2016, 29, 2810–2818. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- Song, G.; Sun, Y.; Liu, J.; Wang, Z.; Kamilov, U.S. A new recurrent plug-and-play prior based on the multiple self-similarity network. IEEE Signal Process. Lett. 2020, 27, 451–455. [Google Scholar] [CrossRef]
- Asim, M.; Shamshad, F.; Ahmed, A. Blind image deconvolution using deep generative priors. IEEE Trans. Comput. Imaging 2020, 6, 1493–1506. [Google Scholar] [CrossRef]
- Dong, W.; Wang, P.; Yin, W.; Shi, G.; Wu, F.; Lu, X. Denoising prior driven deep neural network for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2305–2318. [Google Scholar] [CrossRef]
- Sun, Y.; Wu, Z.; Xu, X.; Wohlberg, B.; Kamilov, U.S. Scalable plug-and-play ADMM with convergence guarantees. IEEE Trans. Comput. Imaging 2021, 7, 849–863. [Google Scholar] [CrossRef]
- Terris, M.; Repetti, A.; Pesquet, J.C.; Wiaux, Y. Enhanced convergent pnp algorithms for image restoration. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: New York, NY, USA, 2021; pp. 1684–1688. [Google Scholar]
- Gao, S.; Zhuang, X. Rank-One Network: An Effective Framework for Image Restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 3224–3238. [Google Scholar] [CrossRef]
- Jung, H.; Kim, Y.; Min, D.; Jang, H.; Ha, N.; Sohn, K. Learning Deeply Aggregated Alternating Minimization for General Inverse Problems. IEEE Trans. Image Process. 2020, 29, 8012–8027. [Google Scholar] [CrossRef]
- Ryu, E.; Liu, J.; Wang, S.; Chen, X.; Wang, Z.; Yin, W. Plug-and-play methods provably converge with properly trained denoisers. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5546–5557. [Google Scholar]
- Geman, D.; Yang, C. Nonlinear image recovery with half-quadratic regularization. IEEE Trans. Image Process. 1995, 4, 932–946. [Google Scholar] [CrossRef]
- Chen, G.; Gao, Z.; Zhou, B.; Zuo, C. Optimization and regularization of complex task decomposition for blind removal of multi-factor degradation. J. Vis. Commun. Image Represent. 2022, 82, 103384. [Google Scholar] [CrossRef]
- Wu, J.; Di, X. Integrating neural networks into the blind deblurring framework to compete with the end-to-end learning-based methods. IEEE Trans. Image Process. 2020, 29, 6841–6851. [Google Scholar] [CrossRef]
- Anwar, S.; Barnes, N. Real image denoising with feature attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3155–3164. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Zhong, B.; Fu, Y. Residual non-local attention networks for image restoration. arXiv 2019, arXiv:1903.10082. [Google Scholar]
- He, W.; Yao, Q.; Li, C.; Yokoya, N.; Zhao, Q.; Zhang, H.; Zhang, L. Non-local meets global: An integrated paradigm for hyperspectral image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2089–2107. [Google Scholar] [CrossRef]
- Graves, A.; Bellemare, M.G.; Menick, J.; Munos, R.; Kavukcuoglu, K. Automated curriculum learning for neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1311–1320. [Google Scholar]
- Jiang, L.; Zhou, Z.; Leung, T.; Li, L.J.; Fei-Fei, L. Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2304–2313. [Google Scholar]
- Yang, L.; Shen, Y.; Mao, Y.; Cai, L. Hybrid Curriculum Learning for Emotion Recognition in Conversation. arXiv 2021, arXiv:2112.11718. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Caijuan, Z. STK and its application in satellite sys-tem simulation. Radio Commun. Technol. 2007, 33, 45–46. [Google Scholar]
- Kuzmin, I.A.; Maksimovskaya, A.I.; Sviderskiy, E.Y.; Bayguzov, D.A.; Efremov, I.V. Defining of the Robust Criteria for Radar Image Focus Measure. In Proceedings of the 2019 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), Saint Petersburg/Moscow, Russia, 28–30 January 2019; IEEE: New York, NY, USA, 2019; pp. 2022–2026. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Large Images | Number of Image Patches | ||
|---|---|---|---|
| Training set | mild | 1358 | 117,300 |
| moderate | 1358 | 117,300 | |
| severe | 1358 | 117,300 | |
| Validation set | mild | 100 | / |
| moderate | 100 | / | |
| severe | 100 | / | |
| Simulated test set | mild | 56 | / |
| moderate | 56 | / | |
| severe | 56 | / | |
| Real test set | / | 17 | / |
| Model1 | Model2 | Model3 | Model4 | Model5 | Model6 | ||
|---|---|---|---|---|---|---|---|
| U-Net | √ | √ | √ | √ | √ | √ | |
| MSDB | √ | √ | √ | √ | |||
| SADB | √ | √ | √ | √ | |||
| FDBP | √ | √ | |||||
| TNRS | √ | ||||||
| PSNR | mild | 29.2092 | 29.8803 | 29.8666 | 30.0160 | 30.0587 | 30.1817 |
| moderate | 27.9264 | 28.2895 | 28.0992 | 28.2989 | 28.3944 | 28.6400 | |
| severe | 25.9631 | 27.2224 | 27.1046 | 27.6352 | 27.8129 | 28.0169 | |
| SSIM | mild | 0.8889 | 0.8923 | 0.8869 | 0.9001 | 0.8911 | 0.9035 |
| moderate | 0.8430 | 0.8649 | 0.8757 | 0.8685 | 0.8701 | 0.8732 | |
| severe | 0.7052 | 0.8363 | 0.8218 | 0.8325 | 0.8341 | 0.8545 | |
| Methods | PSNR | SSIM |
|---|---|---|
| Gao | 27.5423 | 0.8337 |
| Chen | 28.0156 | 0.8431 |
| Mao | 29.3903 | 0.8387 |
| MemNet | 27.8413 | 0.8295 |
| CBDNet | 29.4395 | 0.8596 |
| ADNet | 29.7430 | 0.8828 |
| DPDNN | 30.0122 | 0.8999 |
| DPIR | 29.7316 | 0.8932 |
| Ours | 30.1817 | 0.9035 |
| Methods | PSNR | SSIM |
|---|---|---|
| Gao | 25.8558 | 0.7643 |
| Chen | 26.9923 | 0.8297 |
| Mao | 28.3321 | 0.8446 |
| MemNet | 26.4702 | 0.7480 |
| CBDNet | 27.7382 | 0.7817 |
| ADNet | 28.1007 | 0.8472 |
| DPDNN | 28.3600 | 0.8766 |
| DPIR | 28.3519 | 0.8284 |
| Ours | 28.6400 | 0.8732 |
| Methods | PSNR | SSIM |
|---|---|---|
| Gao | 26.7512 | 0.7934 |
| Chen | 27.1416 | 0.8250 |
| Mao | 27.1224 | 0.8190 |
| MemNet | 26.1868 | 0.7288 |
| CBDNet | 27.4253 | 0.8471 |
| ADNet | 27.1676 | 0.8346 |
| DPDNN | 27.8129 | 0.8431 |
| DPIR | 27.6249 | 0.8376 |
| Ours | 28.0169 | 0.8545 |
| Method | Brenner (xe6) | Laplacian | SMD (xe4) | Variance (xe7) | Energy (xe6) | Vollath (xe7) | Entropy |
|---|---|---|---|---|---|---|---|
| ADNet | 27.36 | 346.52 | 53.9847 | 17.477 | 19.42 | 17.05 | 2.58 |
| CBDNet | 23.07 | 310.00 | 49.80 | 17.42 | 16.85 | 17.06 | 2.51 |
| Chen | 27.62 | 419.92 | 56.31 | 17.57 | 19.92 | 17.13 | 2.68 |
| Gao | 24.45 | 231.94 | 52.34 | 17.41 | 16.53 | 17.05 | 2.61 |
| Mao | 16.71 | 220.832 | 43.61 | 16.83 | 12.48 | 16.58 | 2.32 |
| MemNet | 21.23 | 314.55 | 48.71 | 16.41 | 15.96 | 16.08 | 2.52 |
| Zhang | 19.26 | 242.84 | 46.14 | 17.85 | 13.90 | 17.55 | 2.49 |
| DPDNN | 15.65 | 183.75 | 42.31 | 16.31 | 11.29 | 16.07 | 2.57 |
| Ours | 32.54 | 493.77 | 58.98 | 18.13 | 23.47 | 17.61 | 2.41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shu, J.; Xie, C.; Gao, Z. Blind Restoration of Atmospheric Turbulence-Degraded Images Based on Curriculum Learning. Remote Sens. 2022, 14, 4797. https://doi.org/10.3390/rs14194797
Shu J, Xie C, Gao Z. Blind Restoration of Atmospheric Turbulence-Degraded Images Based on Curriculum Learning. Remote Sensing. 2022; 14(19):4797. https://doi.org/10.3390/rs14194797
Chicago/Turabian StyleShu, Jie, Chunzhi Xie, and Zhisheng Gao. 2022. "Blind Restoration of Atmospheric Turbulence-Degraded Images Based on Curriculum Learning" Remote Sensing 14, no. 19: 4797. https://doi.org/10.3390/rs14194797