1. Introduction
The synthetic aperture radar (SAR) is an active observation system that can transmit microwaves under all-weather, day and night conditions and use the reflected microwaves from objects to generate high-resolution images, while acquiring data from targets in multi-polarization, multi-band and multi-view angles. With the development of detection technology, the application field of SAR ship detection is also expanding. In the military field, it can complete the task of target detection and identification to provide strong protection for the safety of country [
1].In the civilian field, it is widely used in marine fisheries management and marine resources exploration [
2].
At present, the amount of obtained SAR image data is increasing, and the requirements for the accuracy and real-time performance of the algorithm are further improved. In addition, with the improvement of SAR image resolution and the development of ship size diversification, greater challenges have been posed towards detection methods for multi-scale tasks and high-speed requirements [
3]. Currently, the existing methods for SAR ship target detection could be summarized into two categories: traditional methods and deep learning-based methods.
The traditional method in the target detection based on gray features is the constant false alarm rate (CFAR) [
4] method. The CFAR completes the detection of the target pixel by comparing the gray value of a single pixel with the discrimination threshold. Under the premise of a certain false alarm rate, the discrimination threshold is determined by the statistical characteristics of the background clutter. Traditional SAR image target detection relies on experts’ priori knowledge and feature mainly through manual design, which makes it difficult to obtain obvious and effective features of the targets, resulting in poor robustness of traditional methods for target detection [
5].
The deep learning-based methods can be divided into two types: one is the two-stage detection method based on region proposals, and the representative methods are R-CNN [
6], Fast R-CNN [
7], Faster R-CNN [
8], etc.; the other type is the single-stage detection method based on target regression from the whole image, and the typical methods are SSD [
9], YOLO [
10] and FCOS [
11], etc. Single-stage detection methods are generally faster, but less accurate than two-stage methods.
The multi-scale detection problem of SAR ship targets has always been the focus of research. Li et al. [
12] used convolution with different dilation rates to adaptively enhance the detection ability of multi-scale targets. Jimin Yu et al. [
13] added a channel attention mechanism in the feature pyramid networks (FPN) structure to enhance the multi-scale information association in different channels. Xi Yang et al. [
14] proposed the receptive field increased module (RFIM), which uses pooling operations of different convolution kernel sizes for splicing, and combines the structure of the self-attention mechanism to enhance the expression of multi-scale feature information. Guo et al. [
15] proposed a CenterNet++ detection model based on the feature pyramid fusion module (FPFM), which uses deformable convolution in the cross-layer connection and the downsampling part to enhance the extraction of target features. Sun et al. [
16] proposed the bi-directional feature fusion module (Bi-DFFM) and is added after backbone based on YOLO. Bi-DFFM uses both top-down and bottom-up paths for feature extraction, which improves the detection performance of multi-scale ship targets. Xiong et al. [
17] combined the 2-D singularity power spectrum (SPS) and the 2-D pseudo-Wigner–Ville distribution (PWVD) to enhance spatial information extraction and have high detection accuracy even at low signal–noise ratios (SNR).
In addition, with the increasing real-time requirements in practical scenarios, the lightweight detection model is also an important topic of recent research. Sun et al. [
18] proposed a lightweight fully-connected backbone network in the form of channel shuffle and group convolution, which enhanced the connection between different groups while reducing the parameters of the network. Li et al. [
12] redesigned the feature extraction network in Faster-RCNN using the inception structure, reducing the depth and parameter amount of the network and increasing the fusion effect of multi-scale features. Miao et al. [
19] improved the Resnet-50 by using Ghost Convolution module instead of the standard convolution module to build lightweight backbone. Chen et al. proposed a lightweight ship detector based on YOLOv3 (Tiny YOLO-Lite) and adopted network pruning and knowledge distillation for less model volume [
20].
Although deep learning-based methods have better performance when compared to traditional methods, there are still some problems to be solved before it can be better put into practical applications [
21]. The main challenges are as follows. Firstly, the detection of ship targets under complex backgrounds has been a difficult problem. Due to the imaging mechanism of SAR, a certain amount of speckle noise will be generated, which has great impact on targets (especially for near-shore ship targets and side-by-side docking targets), resulting in more serious cases of missed detection and false alarms [
22]. Secondly, the ship targets in real scenes have multi-scale characteristics due to the volume size factor of the ship itself and the influence of different SAR imaging resolutions. Especially, the detection of small targets is more difficult for the reason that the small targets occupy fewer pixel blocks, and the feature pixels with target information are easily ignored in the down-sampling feature extraction after several times, which eventually leads to high miss detection rate [
23]. Thirdly, deep learning-based SAR detection method has become more and more popular, but few works have considered the problem of practical application. Although many scholars have introduced lightweight models based on YOLO, few have tested them on mobile platforms with limited computing power. In real-world scenarios, where computing power is limited, deep learning-based mobile development boards can simulate real-world usage scenarios, so the results of testing with development boards are more meaningful. Our algorithm will run on the mobile development board instead of the high performance server. The complexity of the model directly affects the detection efficiency [
24]. Therefore, designing a lightweight detection algorithm with high-performance on mobile development boards is extremely important for solving practical application problems.
Using the above issues into consideration, in this paper a lightweight multi-scale ship detection algorithm (LMSD-YOLO) with excellent performance is proposed. First, the DBA module is designed as a general lightweight unit to build the entire network model. The DBA module has lighter structure and better convergence performance. Second, Mobilenet with stem block (S-Mobilenet) is constructed as an improved backbone better feature extraction with fewer parameters. Meanwhile, the depthwise separable adaptively spatial feature fusion (DSASFF) module is proposed to adaptively calculate the weights of the output feature layer with fewer parameters and enhance the detection of multi-scale targets (especially for small targets). Finally, combined with the regression of angle regression and distance loss, the loss function has been redesigned for better performance.
The main objectives of this paper are summarized as follows:
- (1)
We propose a single-stage detection model LMSD-YOLO with smaller model size and better performance in both detection speed and accuracy, and complete the deployment of real-time detection on the NVIDIA Jetson AGX Xavier development board.
- (2)
In order to construct a lightweight detection model, we propose the DBA module, as a basic lightweight feature extraction unit, for reducing the amounts of parameters and accelerating model convergence.
- (3)
In order to enhance the detection performance of multi-scale ship targets, we propose the DSASFF module for achieving feature fusion between different scale layers with less calculation in convolution operations.
- (4)
In order to obtain more accurate regression anchors, we adopt the SIoU as a loss of function for the training of the LMSD-YOLO. A benefit by the improvement of angle regression and distance loss, is that the SIoU has a faster speed and better accuracy in the convergence process of model training.
- (5)
We compare the LMSD-YOLO with six state-of-the-art detection models on three datasets of SSDD, HRSID and GFSDD, the experimental results show the proposed model is lighter and more accurate.
The following parts of the article are arranged as follows.
Section 2 gives a detailed introduction to our proposed model.
Section 3 introduces the experimental detail.
Section 4 presents the ablation experiments for each module.
Section 5 completes the comparison experiments with other state-of-the-art detection models.
Section 6 concludes the paper with a summary.
2. Methodology
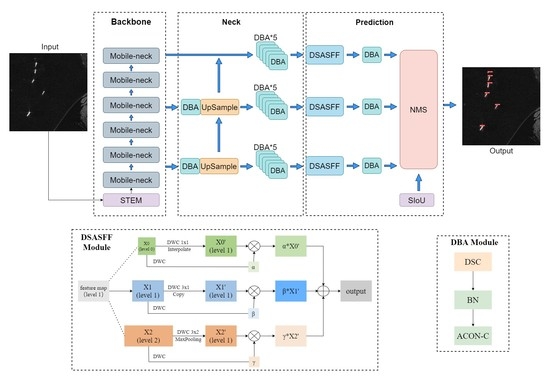
The overview of the proposed LMSD-YOLO is shown in
Figure 1 and includes three parts: backbone, neck and prediction. Firstly, the backbone network is composed of Mobile-neck modules and the stem block is placed in front of the backbone. Then, in the neck part, since the path aggregation feature pyramid network (PAFPN) structure can convey the semantic and location information of targets, the extraction ability of multi-scale targets is strengthened. Finally, in order to enhance the multi-scale feature fusion, the DSASFF module is added before the prediction head.
2.1. DBA Module
Traditional convolution blocks usually adopt convolution (Conv) batch normalization (BN) operation and the Leaky Relu (CBL) module for feature extraction, as shown in
Figure 2a. In order to obtain a more lightweight network model, we propose a lightweight DBA module as a basic computing unit. The DBA module consists of depthwise separable convolution(DSC)module, BN operation and activate or not (ACON) activation function [
25], where the main source of computation is the convolution of the image features, while the BN and activation function have very few parameters. The structure of DBA module is shown in
Figure 2b.
We replace the CBL module with the DBA module as a lightweight basic unit in the backbone and neck of the model. Compared with the traditional CBL module, the DBA module proposed in this paper is more lightweight. The DSC module is used to reduce the overall computational load of the module, and the ACON family functions can effectively prevent neuron death in the process of large gradient propagation. The structure of the DSC module is shown in
Figure 3.
Compared with the traditional standard convolution operation, the DSC module decomposes the entire convolution operation into two parts: depthwise convolution (DWC) [
26] and pointwise convolution (PWC) [
27]. The calculation equation of DSC module is denoted as:
where
represents the input features of each channel,
represents the combination of the feature maps in the channel dimension. Moreover, 3 × 3 and 1 × 1 represent the size of the convolution kernel size used in calculating DWC and PWC, respectively.
In the DWC process, one convolution kernel is responsible for one channel, and one channel is only convolved by one convolution kernel. The number of feature map channels generated by this process is exactly the same as the number of input channels. The operation of PWC is very similar to the traditional convolution operation, using a 1 × 1 × C convolution kernel. Therefore, the PWC operation will perform a weighted summation of the feature map in the depth direction, and compress the feature map in the channel dimension to generate new feature maps.
The Relu [
28] activation function is widely used by most neural networks because of its excellent non-saturation and sparsity. However, since the Relu activation function only has a single form, it is difficult to converge the lightweight model during the training stage. In this paper, we adopt a new activation function, ACON activation function, to enhance the fitting and convergence of the model. The classification of ACON family activation functions is shown in
Table 1.
Table 1.
Summary of the ACON family.
Table 1.
Summary of the ACON family.
| ACON Family | Function Expression |
|---|
| , 0 | ACON-A | |
| ACON-B | |
| ACON-C | |
where , represent the linear function factor. , and represent the change coefficient of the linear function, denotes the sigmoid activation function and denotes the connection coefficient of the two linear function factors.
In order to accurately describe the linear and nonlinear control of neurons in the ACON activation function, the linear parameters
and
, and the connection coefficient
are added as learnable parameters to adaptively learn and update the activation function. ACON-C avoids preventing neuronal necrosis by controlling the upper and lower bounds of the activation function. The first derivative of
is:
Equation (3) calculates the magnitude of the upper and lower bounds of the first-order derivative of ACON-C. When tends to positive infinity, the gradient is . While x tends to negative infinity, the gradient is .
Then, calculating the second derivative of
is shown as follows:
By making Equation (4) equal to 0, the upper and lower bounds of the first derivative are calculated as follows:
As can be seen by Equation (5), the upper and lower bounds for ACON are both related to
and
. Since
and
are the learnable parameters, a better performing activation function can be obtained during network learning. In this paper, ACON-C is adopted as the activation function, and the implementation process is shown in
Table 2:
2.2. Improved Mobilenetv3 Network
In LMSD-YOLO, the backbone of CSPDarknet53 [
29] in standard YOLOv5s is replaced by S-Mobilenet. Compared with the CSPdarknet53, the S-Mobilenet has fewer parameters (only 6.2% parameters of the CSPdarknet53) and better feature extraction performance. The structure and parameter settings of S-Mobilenet are shown in
Table 3.
The detailed structure of the stem block consists of maxpooling and convolution operations, shown as
Figure 4. Convolution operation can only obtain the local feature information of the target, which reduces the description of the input global features. Therefore, a new branch of maxpooling (the kernel size and the stride are both set to 2) is added to enhance the extraction of global feature information without producing new parameters. In order to completely retain the global and local information, the feature maps of the two branches are concatenated in the channel dimension, meanwhile 1 × 1 Conv is adopted to fuse the spatial information and adjust the output channels.
The MobileNet network is a popular lightweight network proposed by Google in 2017 [
30], which has been widely used in the field of computer vision as a mainstream lightweight network, and has achieved excellent results. Mobilenetv3 [
31] was proposed by A. G. Howard et al. in 2019. The Mobilenetv3 network consists of a stacked set of block modules, and the structure of the Mobile-neck block is shown in
Figure 5.
In
Figure 5, the DSC module is adopted to reduce the computational complexity of the model, so that the number of groups in the network is equal to the number of channels. Mobilenetv3 adopts an inverted residual structure after the depthwise filter structure. Since the SE structure introduces a certain number of parameters and increases the detection time, Howard et al. [
31] reduced the channel of the expansion layer to 1/4 of its original size. In this way, the authors of Mobilenetv3 found the accuracy is improved without increasing the time consumption. In the last layer of the block, 1 × 1 Conv is used to fuse the feature layers of different channels to enhance the utilization of feature information in the spatial dimension. At the same time, ACON-C is used instead of the h-swish function, which further reduces the computational cost.
2.3. DSASFF Module
Generally, the detection performance of the target is improved by constructing complex fusion mechanisms and strategies, such as the dense structure, but the complex structure also brings more parameters, resulting in low detection efficiency [
32]. In addition, feature layers of different scales have different contribution weights during fusion. At present, most multi-scale feature fusion strategies are 1:1 fusion according to the output, thus ignoring the difference of target features at different scales, and increasing unnecessary computational overhead.
In order to improve the detection ability of multi-scale targets, the DSASFF module is introduced to enhance the feature expression ability of multi-scale targets. The structure of the DSASFF module is shown in the
Figure 6.
The DSASFF module is embedded between the neck and prediction part, and the three scale feature outputs of the neck part are used as the input of the module. The input feature map is set to level
according to the scale, and its corresponding feature layer is named
. In this paper, according to the size of input images and the SAR ship targets, level 0, level 1 and level 2 are set to 128, 256 and 512, respectively. For the up-sampling operation on
, first we use the DSC operation with a kernel size 1 × 1 to compress the number of feature map channels to the same as
, and then double the size of the feature map by interpolation. A downsampling operation is performed on the feature layer of
, using a two-dimensional maximum pooling (MaxPool2d) operation, and then the number of channels is unified by adopting a DSC operation with the kernel size 3 × 3 and the stride 2. The output of DSASFF module is denoted as:
where
represents the output feature map of the
level,
,
,
correspond to the learnable weight parameters in the feature maps of the
,
and
layers, respectively, which are obtained by applying DSC module as follows.
The range of these parameters is compressed between [0, 1] by SoftMax, and the relationship between the three parameters is satisfied by Equations (8) and (9):
The definitions of three parameters , and in Equation (9) can be obtained by computing the parameters in SoftMax when updating the network by back propagation method. The strategy of the DSC module makes the convolution process more efficient. Meanwhile, the DSASFF module not only has multi-scale feature extraction capability, but also reduces a lot of repeated redundant computation.
2.4. Loss Function
SCYLLA-IoU (SIoU) [
33] is used as the loss function for bounding box regression. Compared with CIoU, DIoU and GIoU, SIoU considers the matching angle direction and it makes the box regress to the nearest axis (x or y) faster. SIoU loss is defined as:
where
is box regression loss,
is focal loss, and
,
represent box and classification loss weights respectively.
The
is further defined as:
where
represents intersection over union loss,
and
denote distance loss and shape loss, respectively. The
loss represents the intersection ratio of the predicted box and the ground truth, which is defined by:
The mechanism of angle regression is introduced in SIoU and the schematic diagram of border regression is shown in
Figure 7.
Where and are the predicted bounding box and ground-truth box. , are the angles with the horizontal and vertical directions, respectively. represents the distance between the center of and . and denotes the length and width.
The direction of the regression of the prediction box is determined by the size of the angles. In order to achieve this purpose, we adopt the following strategy for optimizing the angle parameter
,
The angle loss (
) is calculated by Equations (14)–(17):
Combined with the
above, the distance loss
is redefined and calculated by Equations (18)–(21):
where
,
represent the normalized distance errors in the x or y directions respectively.
is also positively related to the size of
. Considering that the shape of the prediction box also affects the accuracy of the matching,
is calculated as:
where
,
represent the normalization coefficients in the horizontal and vertical directions, respectively, and their definition is expressed as Equations (23) and (24).
θ is used to control how much attention is paid in the shape cost. In this paper,
θ is set as 4 on three datasets by referring to Gevorgyan’s suggestion [
33] and our own experimental analysis results.
2.5. Network Complexity Analysis
Time complexity and space complexity can be used to evaluate and analyze the network model. Time complexity represents the time cost to run the model and is usually measured in floating point operations ().
The time complexity of the convolutional neural network (
) can be obtained by:
where
represents the size of the output feature map of the
layer, and
represents the area of the convolution kernel.
is the depth of the network, and
is the number of current convolutional layers.
represents the number of output channels of the
layer.
The time complexity determines the training and testing time of the model and is the main factor for the real-time performance. Space complexity refers to the total amount of forward propagation and memory exchange completed by the network model, which can be measured by the total number of model parameters (
). The space complexity of the network model can be divided into two parts: the weight parameters (
) and the output feature parameters (
) by each layer, i.e.,
The
represents the sum of the weight parameters corresponding to each layer in the model. The
refers to the computational parameters caused by the input feature map. The calculation process of
and
are shown in Equations (27) and (28).
Convolution is an essential operation for the network to complete feature extraction, and the calculation amount (
) of the standard convolution module can be expressed as:
where
is the number of input channels and
is the number of convolution output by the module. DSC can reduce parameters compared with standard convolution operation, especially in the backbone network that uses a large number of standard convolution, the effect of reducing parameters is more obvious. The calculation amount of the DSC (
) operation can be calculated by Equation (30):
The ratio of the computational effort of DSC operation and standard convolution is calculated by Equation (31):
When we process the input image, the number of input channels (
) is generally relatively much larger than kernel size (
), so the ratio of the
and
is further reduced. In addition, we perform a computational analysis of the proposed DSASFF module. Two convolution operations are used for the input features to complete the feature extraction and the corresponding weight value calculation respectively. Then the input feature map is multiplied with the weight values to obtain the output features. Therefore, the calculation amount of DSASFF module (only considering the complex calculation effect brought by the convolution operation) can be expressed as
where
and
represent the calculation amount of feature extraction and the calculation amount of weight value, respectively, and both of are calculated by the DSC module.
Compared with the standard ASFF module [
34], the DSASFF module proposed in this paper can reduce the calculation amount of each layer when the convolution kernel size remains unchanged, which greatly reduces the overall calculation complexity of the model.
5. Discussion
In order to evaluate the performance of LMSD-YOLO, the six indicators: Params, FLOPs, FPS, P, R, AP, were considered on three datasets: SSDD, HRSID and GFSSD. The input images of three datasets were adjusted to 640 × 640. The Params and FLOPs were obtained on the computer with 1080ti GPU, while FPS can be calculated on the NVIDIA Jetson AGX Xavier development board.
Table 9 compared the experience results of LMSD-YOLO with six other state-of-the-art methods.
As shown in
Table 9, the proposed LMSD-YOLO method has the least model parameters and weight volume and obtains the fastest detection speed (reached 68.3 FPS) in real-time detection. Compared with the baseline method, the LMSD-YOLO has a great improvement in AP (from 96.3% to 98.0% on SSDD, from 92.6% to 93.9% on HRSID and from 89.0% to 91.7% on GFSSD) while the model parameters are only half of the YOLOv5s. The improvement in detection accuracy is attributed to the stem block and DSASFF module in LMSD-YOLO, which strengthen the extraction of multi-scale ship target features and reduce a large number of false alarm rates.
The effectiveness of the proposed LMSD-YOLO for small and multi-scale ship targets in real scenes is verified on SSDD and HRSID datasets. We conducted comparison experiments with the three methods: Faster-RCNN, SSD and YOLOv5s, and the results are shown in
Figure 10 and
Figure 11.
Figure 10 shows the detection results in two scenarios selected from the SSDD dataset, where scenario 1 contains inshore ship targets and scenario 2 includes small ship targets. The green anchors represent the ground truth of ship targets, the purple anchors denote the results by Faster-RCNN, the yellow anchors represent the results by SSD, the blue anchors represent the results by YOLOv5s and the red anchors indicate the detection results by LMSD-YOLO.
As shown in scenario 1 (a1) of
Figure 10, compared with other models, the LMSD-YOLO can accurately detect inshore and small ship targets which are hidden between ships with a higher confidence. In scenario 2 (a2) of
Figure 10, the detection results based on Fast-RCNN (b2) and SSD (c2) cannot accurately detect the multi-scale ship targets and produce false alarm targets at the edge of the land. In the detection results of YOLOv5s (d2), although the targets are accurately detected, the method proposed in this paper (e2) has higher confidence in all targets, with an average improvement of 6% and a maximum improvement of 10%.
Figure 11 shows the detection results in two scenarios selected from the HRSID dataset, where scenario 3 consists of multi-scale offshore ship targets with pure sea background and scenario 4 includes small inshore ship targets in river course.
In scenario 3 (a1) of
Figure 11, the results show our proposed model can detect all targets accurately, while all the other three models have missed detections for small targets. In scenario 4, because of complex background and small ship targets, one ship target is missed at the edge of the whole image and one small ship target failed detection in
Figure 11(b2,c2,d2). The confidence of the detected targets is low using the other three methods (including Fast-RCNN, Fast-RCNN and YOLOv5s). However, the proposed model in this paper has no missed or failed detection and has higher confidence than other methods.
6. Conclusions
In order to solve problems of multi-scale SAR ship target detection and inefficient operation of deployment on the mobile devices, this paper proposed a lightweight algorithm for the fast and accurate detection of multi-scale ship targets. The proposed algorithm was deployed on the NVIDIA Jetson AGX Xavier development board and the ability of real-time detection was also evaluated. Specifically, the DBA module is used as the basic unit of the model to construct the entire model structure, and strengthen the convergence capabilities of the lightweight model with fewer parameters. Meanwhile, the S-Mobilenet module is proposed as the backbone to compress the amount of model parameters and improve the feature extraction ability. In view of the multi-scale characteristics of ship targets, the DSASFF module was proposed and added before the prediction head to learn the different scale features’ information adaptively with fewer parameters. Experiment results on SSDD, HRSID and GFSSD datasets show that the LMSD-YOLO can achieve the highest accuracy with the smallest model parameters when compared with other state-of-the-art methods. In addition, the LMSD-YOLO can meet the requirements of real-time detection.
Our algorithm is currently tested on small scene slices, and there are still difficulties in implementing target detection directly from large-scale SAR images. In the future, an end-to-end lightweight target detection algorithm will be designed in combination with the SAR image segmentation algorithm to enhance the applicability.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










