1. Introduction
The classification of LULC using remote sensing imagery has grown in importance in a number of applications in recent years [
1]. The data are especially important for maintaining sustainable growth and transport systems due to their spatial features [
2,
3]. One of the vital information sets for urban planning in describing the complex nature of the urban environment is LULC categorization maps. Because they offer up-to-date data for metropolitan environments, remote sensing systems have been increasingly popular for this purpose subsequently [
4]. The primary methods for generating LULC maps for urban areas using remote sensing products are image classification techniques [
5]. Every urban-related analysis requires the most recent data since urban surroundings are dynamic. So, in order to collect spatio-temporal information for the urban environment that is not only connected to the current condition but also to the previous, sustainable and effective urban planning organizations require creative concepts and methodologies [
6]. The majority of this data is now taken from any kind of geographical data that already exists and is gathered through statistics, surveys, mapping, and digitizing from aerial photos [
7]. Although, for big metropolitan contexts, the statistical data is typically coarse at both the spatial and temporal scales. Additionally, measuring and modeling are expensive and time-consuming, particularly for urban planning indicators that need to be updated frequently. The development of satellite observations and the improvement of computerized automation classifiers have significantly increased the accuracy and efficacy of vegetation remote sensing classification [
8]. The dependability of land cover products should be assessed in order to provide reliable information regarding land cover [
9]. The LULC classification seeks to uniformly classify landforms at different scales. This classification is crucial to the development of standardized maps that aid in the formulation of plans and decisions. Estimates have been made using LULC maps’ agricultural output research into identifying urban change [
10].
The image classification is conducted using parametric methods [
11] such as Maximum Likelihood (ML) and non-parametric methods such as Random Forests and Support Vector Machines (SVM) (RF), and thorough per-pixel testing has been performed with Artificial Neural Networks (ANN) Image classification exercises [
12]. The current remote sensing images have two primary problems: The first includes measuring or assessing smaller areas; remote sensing is an expensive research method. Secondarily, a special type of training is required to evaluate the remote sensing images [
13]. Therefore, deploying remote sensing technology over an extended period of time is expensive since device operators must acquire more training data. Researchers in LULC classification have developed numerous machine learning strategies to deal with these issues [
14]. Existing deep learning techniques in the classification of LULC have suffered from irrelevant feature selection. Irrelevant features selected in the model have biased towards misclassification [
15]. Some of the visual features of the images of various classes in LULC are highly similar. Some classes commonly share the similar features that tend to misclassification [
16,
17]. The over-fitting problem occurs in deep learning models due to irrelevant feature selection and more training of the model. Optimal and adaptive feature selection helps to highly reduce the overfitting problem in classification [
18]. mLSTM has demonstrated an encouraging outcome in the classification of land use in light of recent advancements in the space sector and the expansion of satellite image reliability [
19]. The best features are then chosen using the IMO algorithm, which consist of a quick convergence rate and is simple to use in grassland, barren land, and tress [
20]. The main contributions of this research are specified as follows:
After collecting the images from Sat 4, Sat 6, and Eurosat datasets, the feature vectors are extracted from pre-processed images that significantly decrease the semantic space between the feature subsets, which helps to achieve better classification.
Next, the feature selection is accomplished using the IMO algorithm to select the discriminative features, wherein this mechanism significantly decreases the complexity and computational time.
The selected features are given to the Multiplicative LSTM (mLSTM) network to classify the event types. The effectiveness of the mLSTM network is validated by means of precision, accuracy, and recall.
The structure of this research is specified as follows:
Section 2 represents the literature review based on satellite image classification.
Section 3 explains the proposed method along with the mathematical equations.
Section 4 represents the simulation results of the proposed method and its comparative analysis with existing methods. Finally, the conclusion is stated in
Section 5.
2. Literature Review
Several techniques have been established by scholars in the field of satellite image classification. Here, detailed surveys about some significant contributions to conventional studies are demonstrated.
An LULC classification with U-Net has been proved by Jonathan V. Solórzano et al. [
21] to increase accuracy. The goal was to assess U-nets for Sentinel-1 and 2 images to provide a thorough LULC classification in a tropical region of southern Mexico. Additionally, this assessment compares the outcomes of the U-net and Random Forests (RF) algorithms and evaluates the influence of image input on classification accuracy. Since only spectral characteristics are used in LULC classification, the U-net concludes both spatial and spectral features. Additionally, natural forests and crops have different spatial configurations; the coupling of Synthetic Aperture Radar (SAR) and Multi-Spectral (MS) including U-net aids in the distinction between the pair.
The Eurosat Dataset with Deep Learning Benchmark for LULC classification was given by Helber et al. [
22]. The proposed deep Convolution Neural Networks (CNN) offer values for this innovative database with the spectrum portions. Total classification performance was improved using the proposed approach dataset. The classification scheme offers the door to a variety of Earth observation technologies. Furthermore, deep CNN has been used to identify patterns in LULC, as well as improve the geometrical parameters. The map failed to include a large portion of the office buildings that were affected by environmental issues.
Deep AlexNet with minimal amount of trainable variables for satellite image classification has been proven by Unnikrishnan et al. [
23]. The accuracy of spatial and spectral data was examined using deep learning algorithms in conjunction with CNN. The AlexNet design was developed with two-band data and a limited portion of filters, and high-level characteristics from the tested model were able to categorize distinct LC classes in the database. In remote sensing studies, the proposed structure with fewer training data reduced the current four-band CNN to frequency groups and decreases the number of filters. Large receptive fields present in the network make it difficult to scan for all characteristics, resulting in low performances.
To improve classification accuracy, Deep Transfer Learning for LULC classification has been demonstrated in [
24]. In this study, transfer learning methods such as Visual Geometry Group (VGG16) and Wide Residual Networks (WRNs) were used for LULC classification, utilizing red–green–blue form of the Eurosat data. Additionally, data augmentation has been exploited to assess and validate the efficiency and computational complexity. The limited-data problem was overcome through the recommended manner, and maximum accuracy was accomplished. In spite of utilizing similar data augmentation methods, it exposed that the Wide ResNet-50 generated improved outcomes when compared with VGG16. The class predictability was the only variation observed in the accuracy, apart from that, Wide ResNet-50 provided maximum scores, and its learning patterns were equivalent.
Jayanthi and Vennila [
25] presented an adaptable supervised multi-resolution technique for satellite image categorization using the Landsat dataset. The mechanisms of satellite image processing are developed to identify the various objects in satellite images. The suggested versatile supervision is a multi-resolution selection that improves precision and accuracy by using a technique of exploitation and trial samples. Here, large amounts of satellite data accurately transferred quickly but still pose a significant difficulty in this procedure because of moving components, and no sensor has combined the best spectral, geographical, and temporal resolutions.
LC Dataset with CNN for satellite image classification was provided by Emparanza et al. [
26] to improve precision, accuracy, and recall. The suggested model was created by an aggregation of two CNN classifiers that specialize in recognizing water areas. This new methodology has shown to be substantially faster and more effective across the board. However, in order to achieve higher accuracy for land cover classification, CNN needs large amounts of training samples, highly dependent land cover features, prediction quality, and dataset reliability. Due to those factors, certain small classification errors have been identified.
For satellite image categorization, Zhang et al. [
27] introduced the CNN-Capsule Network (CapsNet) with the UC Merced and AID dataset. The innovative CapsNet design employs the capsule to substitute the neuron in the standard network that was suggested to maintain the geospatial data from the CNN. In addition, the capsule is a vector that may be used to understand part–whole relationships within an image by representing internal attributes. While using the fully connected layer after the classification algorithm reduces the two-dimensional extracted features into a one-dimensional feature map, it takes considerably too long to identify the subclasses.
Multi-spectral satellite data on land cover categorization based on deep learning approaches have been proven by He and Wang [
28]. A spectral–texture categorization classifier was developed utilizing wavelet transform’s exceptional texture collection capabilities to acquire relevant details to enhance the spectral feature set, paired with deep learning for feature extraction and selection. For the assessment, multi-spectral imaging satellite data and field measured data were employed. Research findings demonstrate that the suggested approach outperforms exploratory factor analysis, regression methods, and neural networks in terms of improving multi-spectral picture classification accuracy. According to the findings, the various formations of the classed regions generated using the suggested arrangement are well-formed. However, this approach falls short in characterizing how changes in land cover relate to a rise or fall in ecosystem function. Furthermore, the evaluation index fails to capture the scope and rate of change effectively.
From the overall literature works, still, there is a significant need for information about the environment and natural resources; many maps and digital databases that are already in existence were not especially created to fulfil the needs of different users. The kind of classification or legend employed to explain fundamental facts such as land cover and land use is one of the primary causes, while being typically underappreciated. Many of the current classifications are either focused on a single project or use a sectoral approach, and they are generally not comparable with one another. Although there are numerous categorization systems in use around the globe, no single one is universally recognized as the best way to categorize land use or cover. In order to overcome this, this research created a new land cover classification system name called IMO-mLSTM. The suggested methodology is extensive in that it can easily handle any identifiable land cover found anywhere in the world and is applicable at any size. Additionally, the system can be used to evaluate the coherence of current categories, which is clearly described in the following sections.
3. Proposed Method
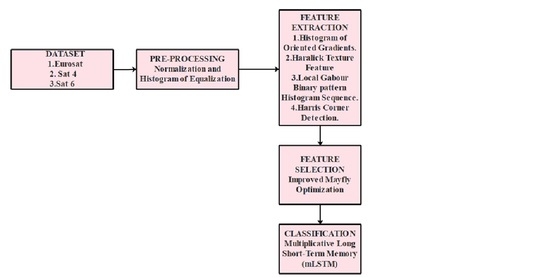
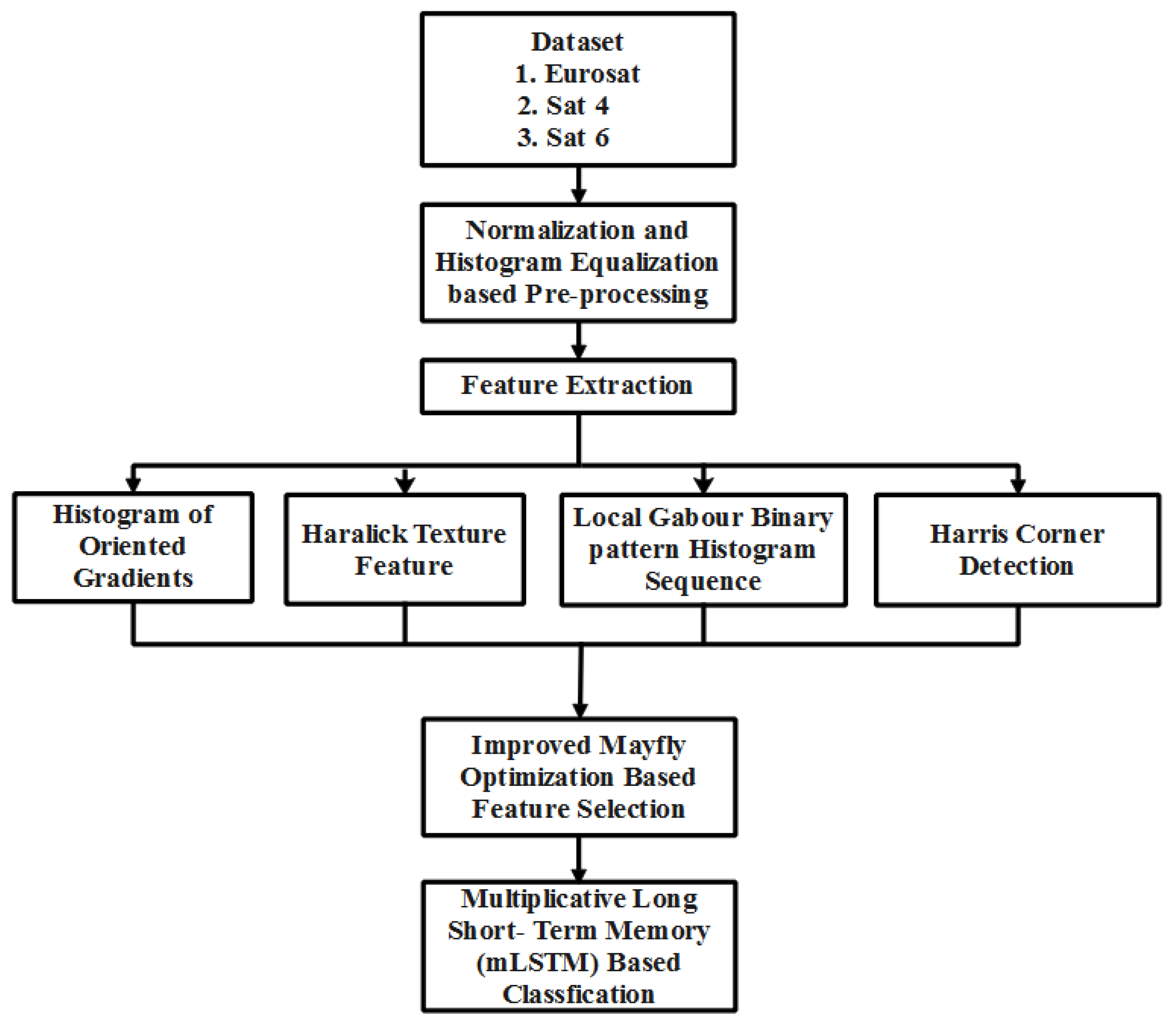
In this research, the elements or features that are found on the Earth’s surface are referred to as land usage and land cover. The Sat 4, Sat 6, and Eurosat are used in this work for experimental research. After gathering the satellite images, pre-processing is conducted using normalization and histogram equalization, which are used to enhance image quality. After normalizing the collected satellite images, feature extraction is carried out to extract the feature vectors from the images utilizing the HOG, LGBPHS, HCD, and Haralick texture features. Using the Improved Mayfly Optimization (IMO) algorithm, feature selection is carried out after the feature vectors are extracted. After extracting the optimal features, the Multiplicative Long Short-Term Memory (mLSTM) network is exploited for classifying the LULC classes. The general process of the satellite image classification is depicted in
Figure 1.
3.1. Image Collection
The statistical investigation is applied using the Sat 4, Sat 6, and Eurosat databases to distinguish objects in farming environments. Sat 4 contains 500,000 remote sensing data divided into four categories. Every spatial data image is divided into six LC types.
Figure 2 shows an example image from Sat 4 and Sat 6 [
23,
29].
The satellite data were acquired in European cities and scattered across thirty-four nations. Data are obtained with 27,000 annotated and geo-linked texture features, each of which is
images in size. The Eurosat database is divided into ten classes, each of which comprises 2000–3000 images. Commercial establishments, motorways, and residential complexes are LULC-type data.
Figure 3 displays a sample image of the Eurosat database [
22,
30].
3.2. Image Pre-Processing
To increase the image quality, min–max [
31] and z-score normalization procedures are used once the satellite data are collected. Equations (1) and (2) offer general formulas for normalization procedures.
where,
are declared as a minimum and maximum intensity standard; the image following the normalization is stated by
,
is stated as an actual satellite image, and the maximum and minimum intensity value is represented as
, which ranges from 0 to 255. In z-score normalization, the data are normalized with respect to their mean (
) and standard deviation (
). For z-score, a normal distribution is often assumed. The distribution to the left and right of the origin line has not been equal if the data are unbalanced. Therefore,
is specified in Equation (2),
This normalizing method relies on a mean and standard deviation of the data that might change over time. These normalization methods are helpful for maintaining the linkages between the original input data. Normalization is the finest method for image enhancement since it improves image quality without losing image information [
32].
3.3. Feature Extraction
The excellent discriminative strength and partial invariance to color and grayscale images are two significant advantages of feature extraction methods. After normalizing the acquired satellite images, the next are utilized to extract features from the images: Histogram of Oriented Gradients (HOG), LGBPHS, and Haralick texture features such as brightness, coherence, frequency, homogeneous, variance, angular second-moment feature, and Harris Corner Detection (HCD). Since satellite images often cover a significantly bigger area, they have more extensive scientific uses. Airborne images are more suitable for smaller-scale applications such as advertising and marketing since they are captured from a lower height and therefore cover a smaller region. The high-resolution spatial data are collected from airborne imaging, which is frequently employed in this research. Almost any area of the Earth’s surfaces may be imaged in great detail at any time using airborne platforms, which also make it easier to gather data. These airborne images are converted into gray scale for further processing.
HOG: The HOG feature descriptor effectively captures the gradient and edge structure of the objects in satellite images. However, the HOG feature descriptor operates on localized cells, maintaining object orientation as an exception to photometric and geometric invariance. This action aids in identifying changes that appear in vast spatial regions. This classifier effectively preserves the gradient in satellite images, in which the vectors are not aligned properly. This process aids in the detection of changes in wide spatial areas. HOG is usually focused on the gradient direction that builds up over images of a small spatial region, such as a cell. The local 1-D histogram is collected by the HOG descriptor in each cell. The previous procedure involved gathering the local histogram over a large geographic area, usually a block of cells, then using the information to normalize every cell in the block. In this instance, the detection window is positioned high above the grid.
LGBPHS: Using various orientation and scale Gabor filters, the pre-processed satellite images are first modified to create numerous Gabor Magnitude Pictures (GMPs). Each GMP is then transformed into a Local GMP (LGMP), which is further divided into rectangular areas with distinct histograms and sizes. Thus, to create final histogram sequences, the LGMPs of every LGMO map are summarized. Every Local Gabor Binary Pattern (LGBP) map is then further divided into non-overlapping rectangle areas to precise specifications, and histograms are calculated for every region. Finally, the LGBP histograms of every LGBP map are aggregated to produce the image.
Haralick Texture: In terms of contrast, energy, entropy, homogeneity, correlation, and angular second moment, the Haralick features are 2nd order statistics, which depict the overall average degree of correlation between the pixels. This illustrates several measurable textural properties generated from GLCM, a well-liked and widely used statistical measure of textures based on the spatial interdependence of gray images. It frequently results in precise extraction that is resilient in different rotations. The spatial gray-level distribution is represented in two dimensions by the GLCM. The gray-level histogram is used to obtain the features after creating the co-occurrence matrices. The resulting feature vector is created by the calculated features.
Harris Corner Detection (HCD): These HCD features are exploited to divide the background and foreground data. With each configuration, moving the window along a corner point would result in a noticeable change in luminance. In the front of the fingerprints, Harris’ point is significantly more intense than it is in the background. This HCD uses the gray disparity of images to extract corner points as a modification or expansion of the Moravec corner detection. A grayscale image and window are assumed to be deliberated through movements of in -direction and in -direction.
3.4. Feature Selection
This procedure is deliberated to be an issue of global combinatorial optimization that tries to remove unnecessary, noisy, and redundant data and number of features and produce standard classification accuracy. Once the feature extraction is complete, the process of feature selection is deliberated using the IMO algorithm. Traditionally, the brute-force algorithm attempts to provide systematic relation among presented candidates, and outlier data instances have less relation with other features, but the problem concerned in this technique was higher computational time during the large datasets. During Sequential Forward Selection (SFS), features are consecutively included to a vacant candidate set till the features do not reduce the standard. Contextual Bandit with Adaptive Feature Extraction is a cluster-based model that is usually applied for unlabeled data or unsupervised classification. In supervised learning, applying Contextual Bandit with Adaptive Feature Extraction tends to result in the loss of information in network learning. This research is supervised classification or based on labeled data, so the Contextual Bandit with Adaptive Feature Extraction of cluster technique is not required for this model. These existing feature selection methods do not adaptively select features and tend to select many irrelevant features for classification. So, an optimization algorithm called Improved Mayfly Optimization is introduced in this research that learns the features adaptively and selects the relevant features. Similarly, IMO is less complex compared with the SFS, brute-force algorithm, and Bandit with Adaptive Feature Extraction. All potential combinations of attributes selected from the dataset make up the discrete search space. Considering the low number of features, it could be probable to arrange all the possible feature subsets. In order to determine its own behavior, the improved mayfly uses more group information that confirms the group diversity, thus progressing the stability among exploration and exploitation to improve efficiency.
3.4.1. Mayfly Optimization Algorithm
For the MO approach, mayflies should be separated into male and female entities. Additionally, because male mayflies are always strong, they will perform better in augmentation. The MO uses equivalent parameters as PSO, adjusting their positions depending on the current position
and velocity
at the current iteration count. To update their positions, all males and females apply Equation (3). As an alternative, their velocity is updated in different manners.
The velocity is modified based on current fitness and best fitness in previous actions is stated as .
, the male mayflies update their current velocities, and their preceding actions are stated in below Equation (4):
where
is stated as a variable count.
are exploited as constants. The Cartesian spacing is defined as
. The array’s distance is the Cartesian distance that is represented below in Equation (5):
Alternatively,
, the male mayflies could modernize their quickness from the current location through a dance coefficient
, which is represented in Equation (6).
where
and
represent the indiscriminate amount in the distribution and are identified within a range [–1, 1]. As an outcome in the
female mayfly,
, Equation (7) is stated as:
where
is referred to as an alternative constant that is applied to stabilize the rapidity. Cartesian distance in the middle of them is represented as
.
, the female mayflies adjust their velocities until the previous runout in the course of supplementary dance coefficients
, which are expressed as Equation (8).
Their kids progress arbitrarily from their moms, as seen in Equations (9) and (10), respectively.
is declared as subjective data in Gauss distribution.
3.4.2. Improved MO Algorithm
According to the previous equations, Candidates vary their velocities randomly in particular environments. In complex circumstances, efficient systems might be used to adjust the velocities. The global best candidate is chosen by comparing the present velocities and additional weighted distance to modify specific velocities. In addition, Equation (11) determines whether the balanced distance’s halves appear as follows:
If the distance between the
and
individuals is prolonged, it seems that
is superior. Consequently, if
is distant from
, it updates its velocity with a lesser magnitude, while
is near to
, it updates with a large magnitude. Thus, Equation (11) should be changed according to the circumstance, as indicated in Equation (12):
Table 1 shows the extracted and selected feature vectors after exploiting the IMO method. While referring to
Table 1, from the available datasets, the outcomes (features) are extracted. Those features are extracted based on a filtered process which depends on the dataset’s general properties (some measure such as correlation), such as correlation with the multi-variate regression. IMO-based feature selection techniques remove the redundant and noisy data to choose a subset of appropriate features by means of Improved Mayfly Optimization algorithms to improve classification outcomes, which are usually quicker, more effective, and minimize overfitting.
By analyzing
Table 1, it clearly shows that the proposed IMO-based feature selection reduces the number of extracted features from the collected dataset (Eurosat, Sat 4 and Sat 6) when compared with MO-based feature selection.
Table 1 denotes that the proposed IMO selected 9000 images with 43 lengths of features in the Eurosat dataset; wherein the Sat 4 dataset, 5000 images with 27 lengths of features were selected, and in the Sat 6 dataset, 8700 images with 40 lengths of features were selected.
3.5. Classification
LSTM is a type of deep learning model for image classification which has been shown to achieve the highest level of accuracy [
33]. An LSTM network can be used to train a deep neural network to categorize system data. In LSTM, IMO-selected features are used as inputs, and the number of classes is considered as output. LSTMs perform considerably better since they are skilled at remembering particular patterns. As they pass through each layer, the relevant data are saved and the irrelevant data are eliminated in each and every cell. The default behavior of the multiplicative LSTM classifier is to recollect relevant data for an extended period. To achieve a better result in LULC classification, more remote sensing data must be processed. The mLSTM classifier is the preferred place for LULC classification when this factor is taken into account. The mLSTM classifier, in particular, is made up of a succession of mLSTM units that contain quasi-periodic information for extracting long- and short-term relationships. The supervised classification approach exploited in this research is the mLSTM classifier. The theory behind supervised classification is that a user can select testing image values that are reflective of some classes present in these images and can then inform the data visualization tools to use certain training data as references for categorizing all other images. Multiplicative LSTM models appear to gain embedding matching for secondary operational motifs to improve the quality.
3.5.1. Process of LSTM
The data flow in and out of the internal positions of system is managed by a sequence of multiplicative gates in the widely used RNN design, which is known as LSTM. There are a number of marginally distinct LSTM variants employed in the trials. The hidden state obtains the inputs from the input layer, which is stated as
, and its previous hidden state is represented as
, which is formulated in Equation (13)
The LSTM consists of 3 gating units—one is input gate
, second is output gate
, and third is forget gate
for recurrent and feed-forward networks, which are expressed in Equations (14)–(16):
Here, the logistic sigmoid function is stated as
.
decides the quantity of prior internal state
that is kept, while
manages the quantity of input to every hidden unit to internal state vector
. With the help of
, the network is able to decide if the data ought to be stored and rewritten during every time interval. Updating the internal state is performed through Equation (17),
The amount of every unit’s activation is conserved and determined by the output gate. It enables the LSTM cell to store data that may become important in the future but is not necessary for the current output. The concealed state’s final output is represented by Equation (18).
The capacity of the LSTM to regulate how data are stored in every unit was generally effective.
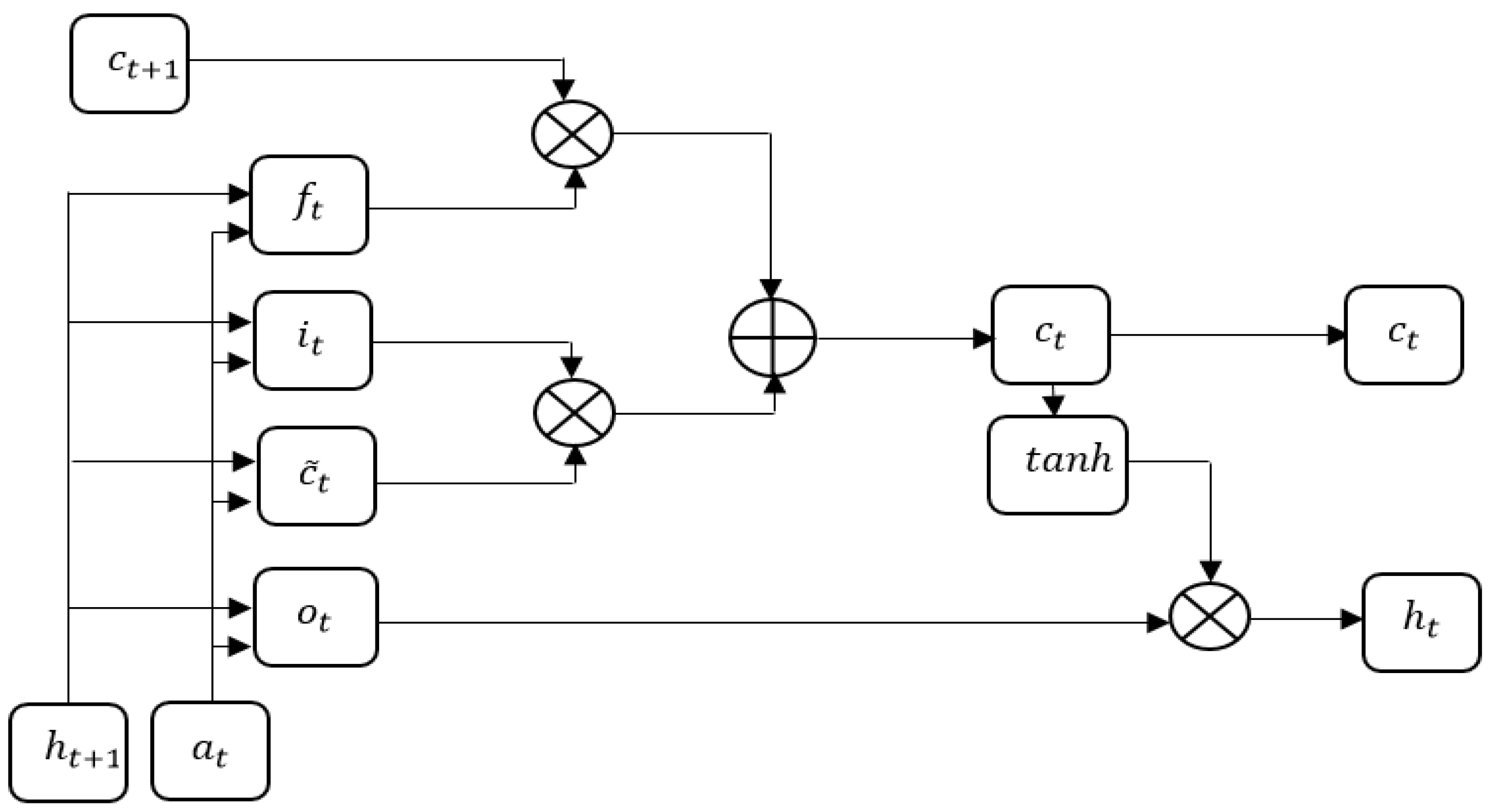
3.5.2. Multiplicative LSTM
Like any other NN, mLSTM has the potential to have several hidden layers. The following hyper-parameters are used in MLSTM. They are, initial learning rate (0.001), Neurons (100), Layers (10), and Epoch (100) with Adam optimizer. The mLSTM, a hybrid design which integrates the hidden-to-hidden transition of RNNs by the LSTM gating framework, is suggested for controlling the over-fitting problem. By connecting each gating unit in the LSTM to the intermediate state
of the RNN, the conventional RNN and LSTM designs can be merged to create the following Equations (19)–(23).
Set
and
dimensions to be the same for all the trials. A network with 1.25 times as many recurrent weights as LSTM for identical hidden layers is produced by choosing to share
over every LSTM unit category. This architecture aims to combine the extended time lag and overall functioning of LSTMs with the adaptable input-dependent transitions of RNNs. It might be simpler to control the transitions that arise from the factorized hidden weight matrix. More adaptable input-dependent transition patterns than conventional LSTM and RNNs are made possible by the supplementary sigmoid input and
, which are present in multiplicative LSTM.
Figure 4 shows the graphical depiction of multiplicative LSTM.
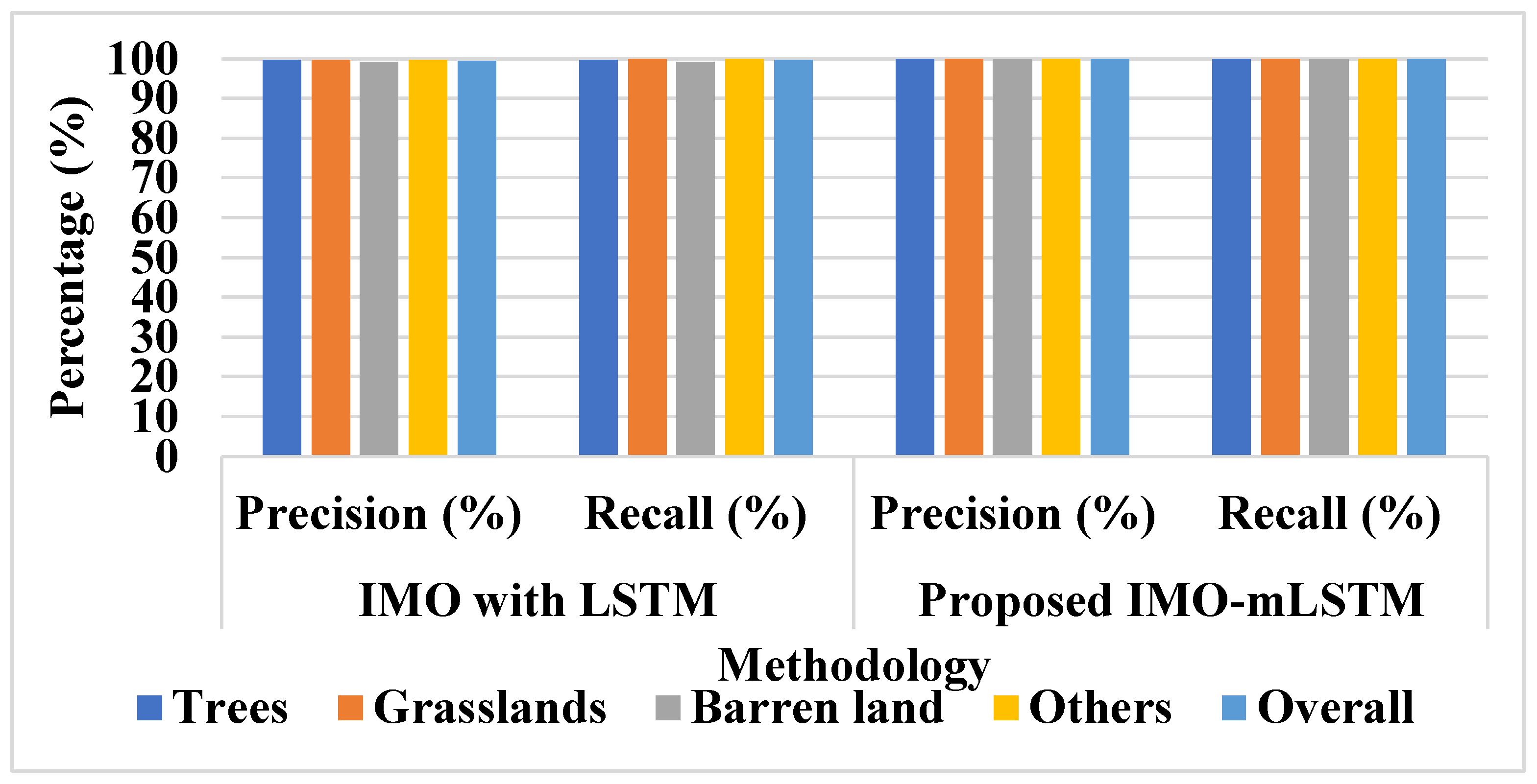
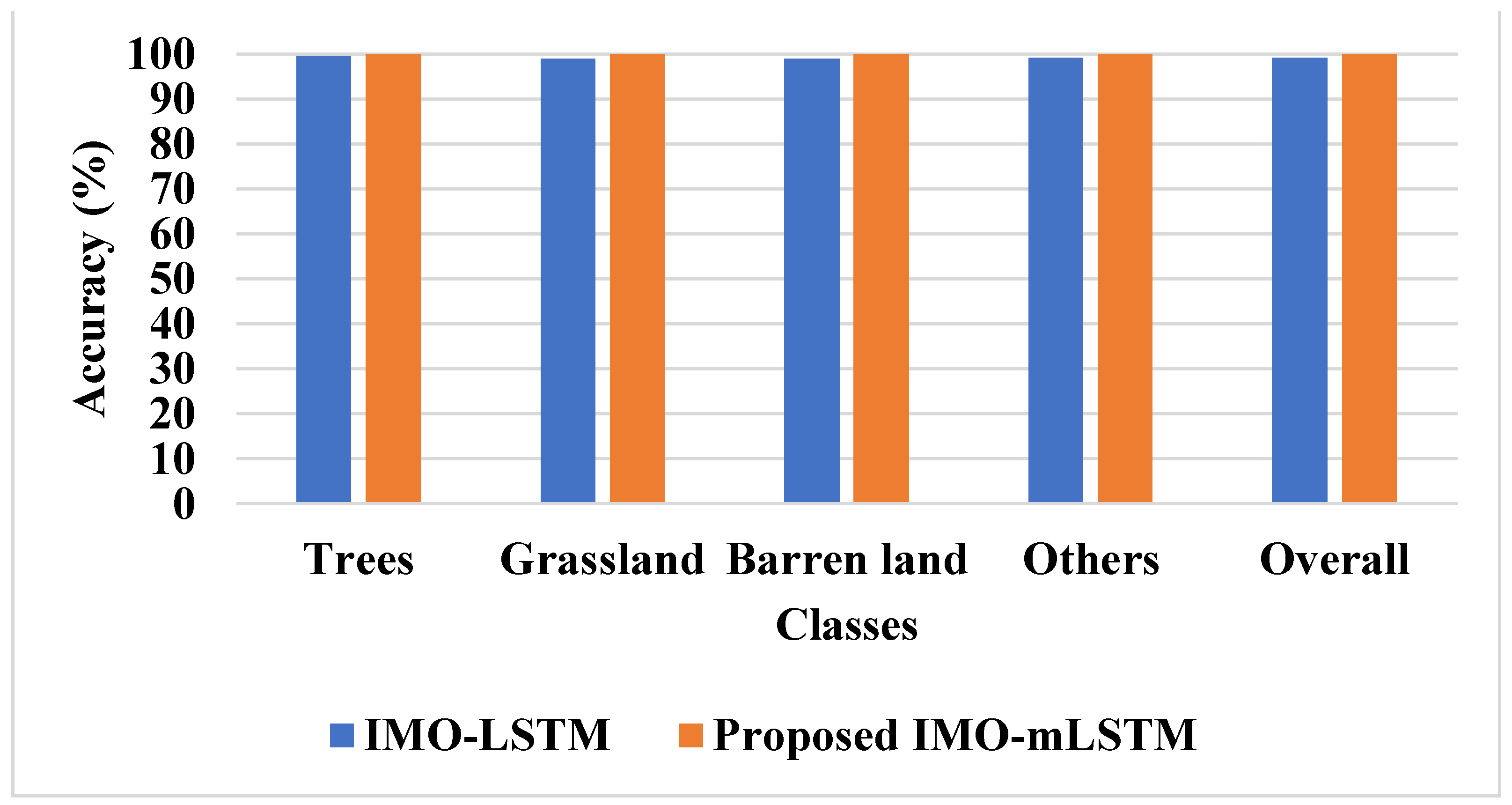
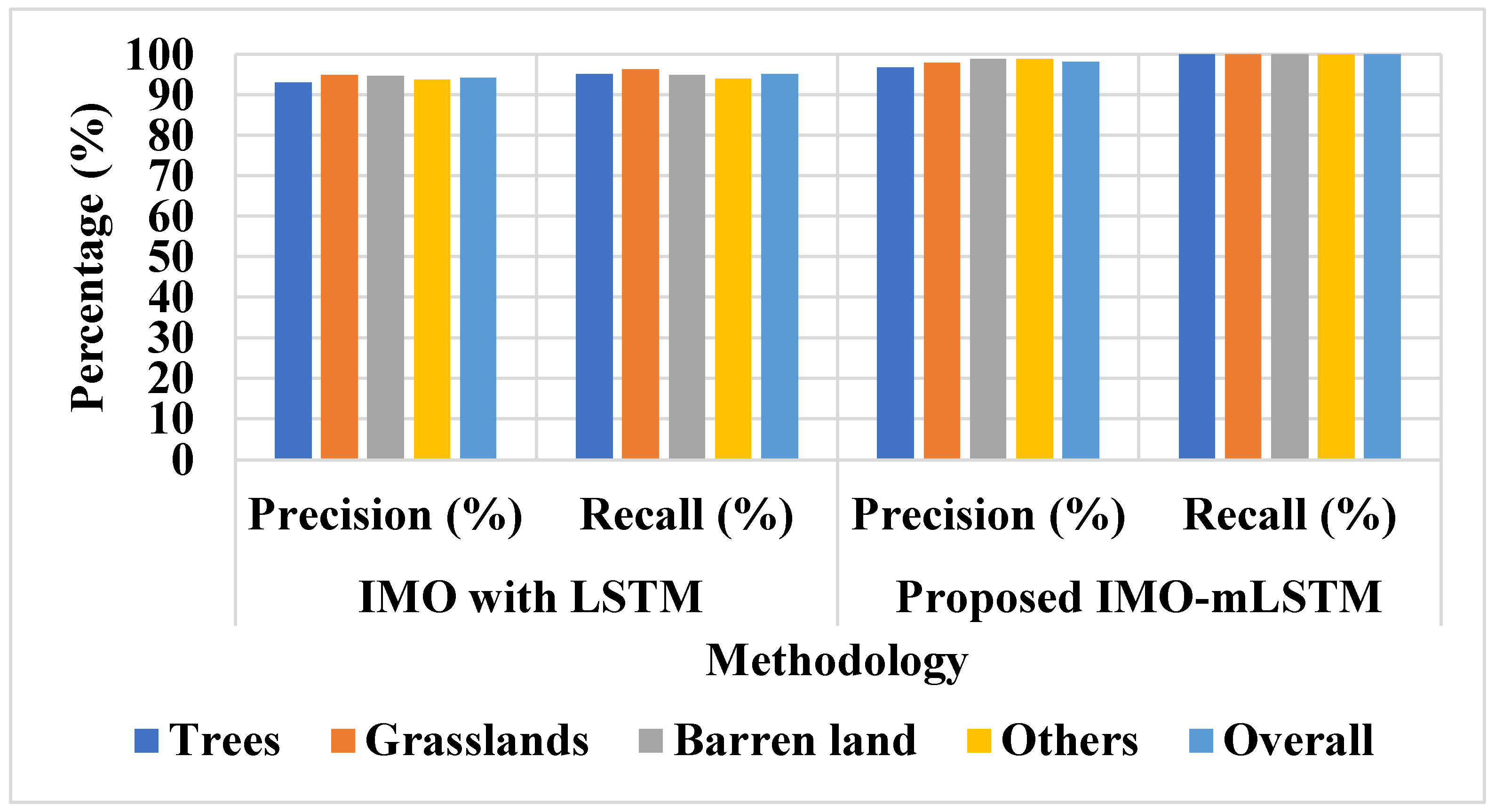
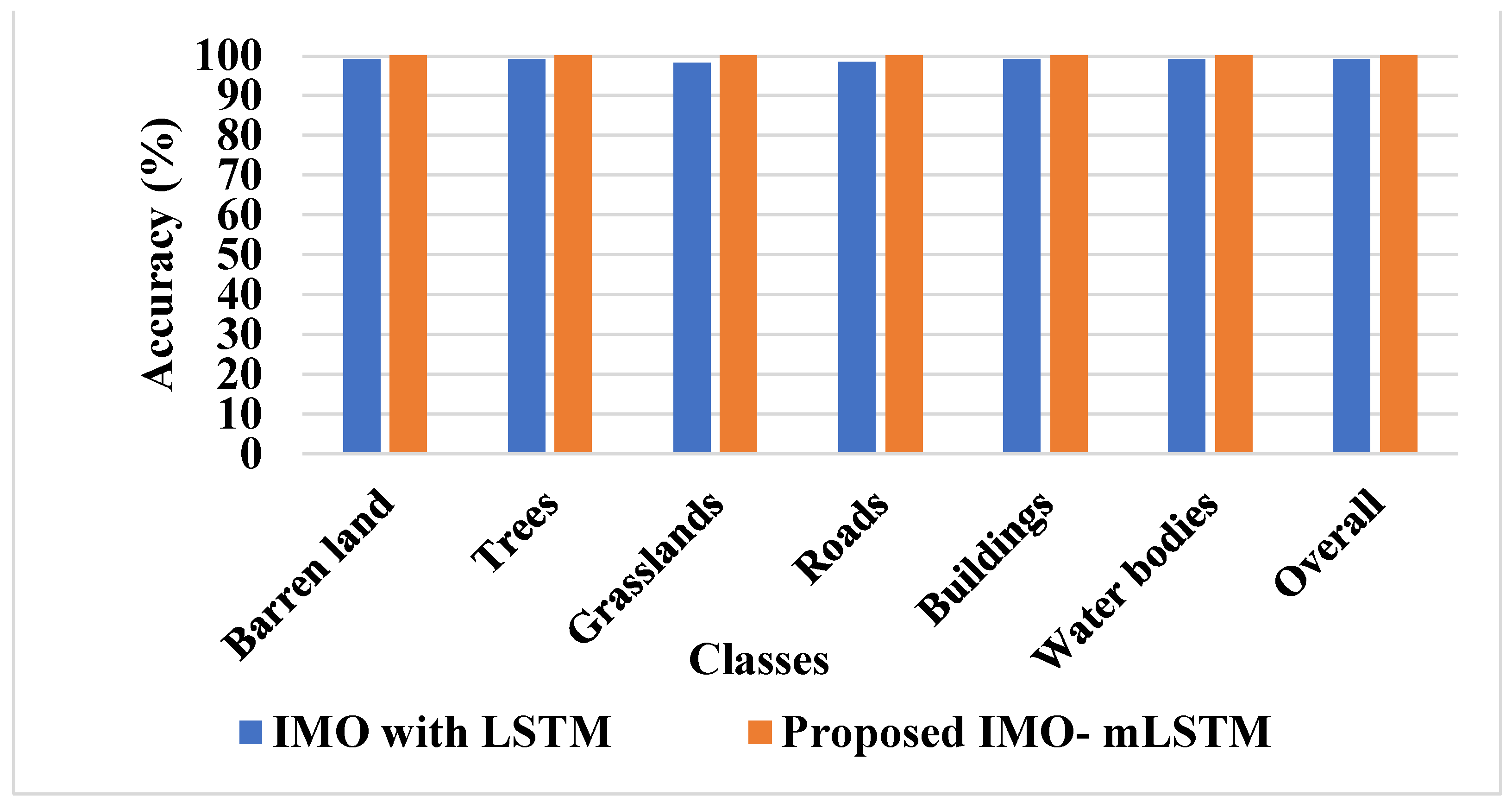
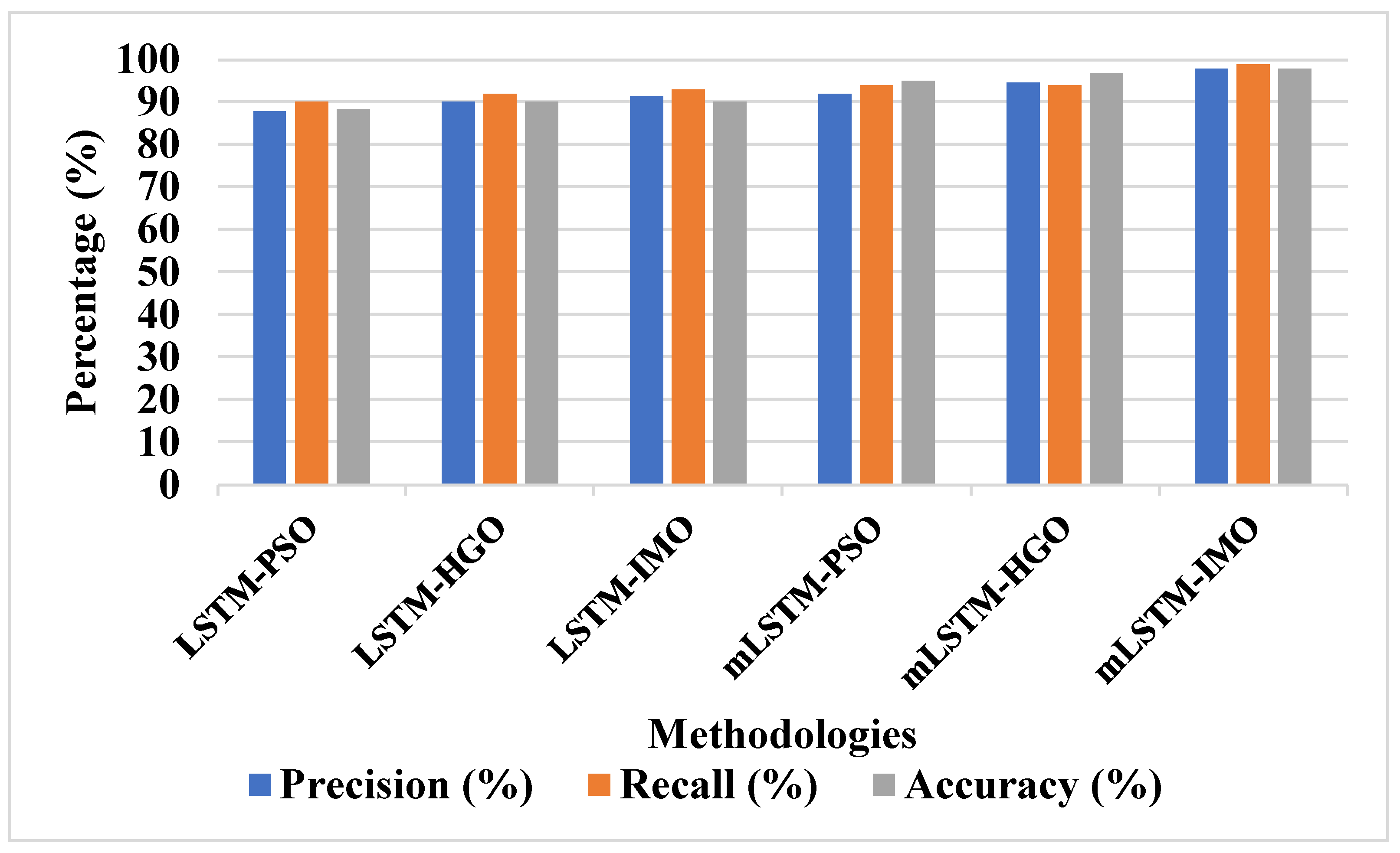
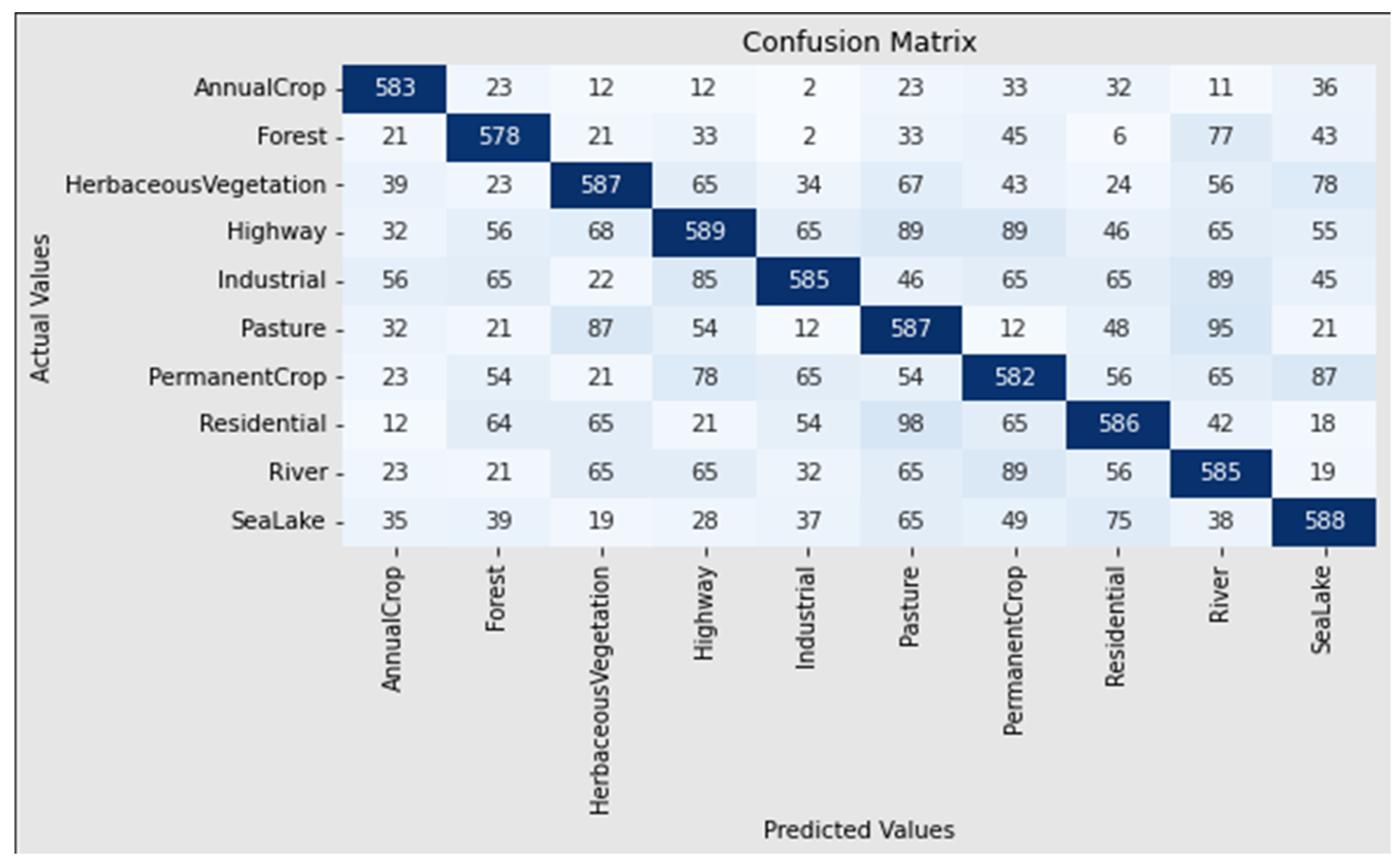
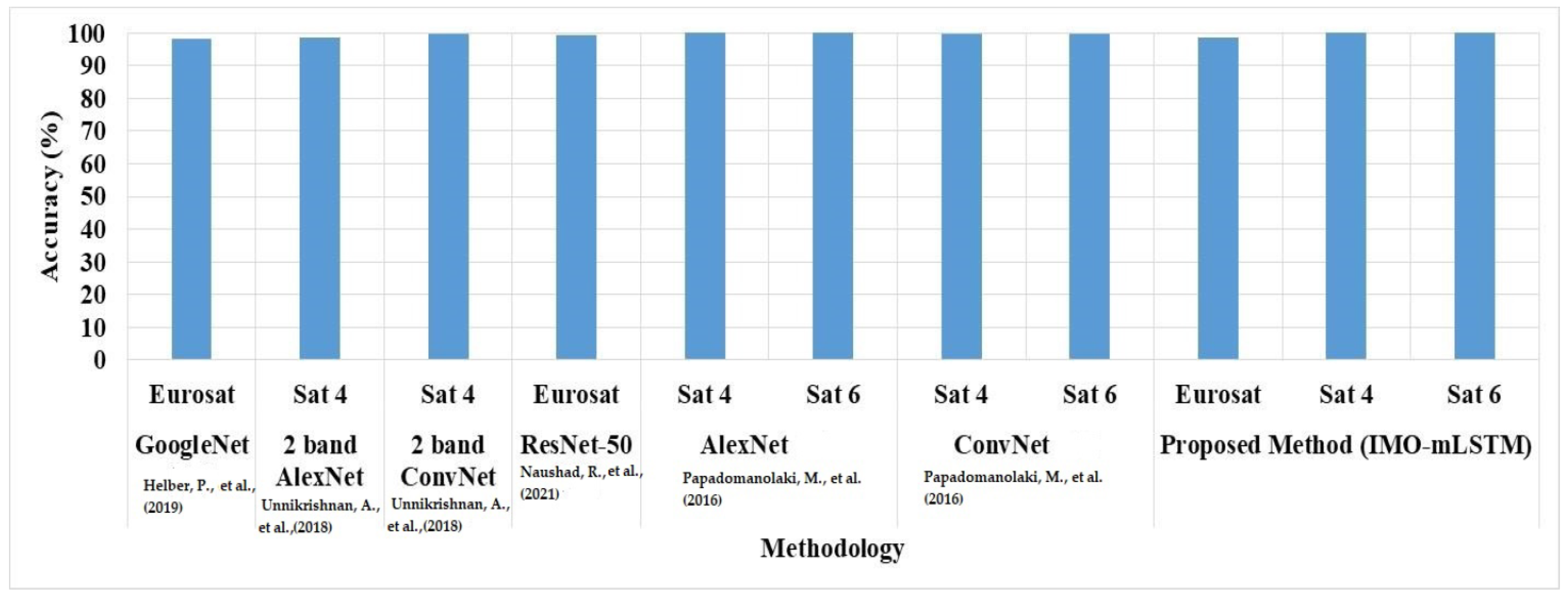
Landscape metrics for LULC classification are a less-explored aspect of spatial analysis and image classification. This study demonstrates how several shape- and size-associated landscape measurements may be used as input layers in the categorization process. Precision, recall, and accuracy are used to assess the suggested model’s performance in this study. Equations (24)–(26) represent the mathematical formulations of accuracy, recall, and precision.
where
is stated as true negative,
is specified as false negative,
is signified as true positive, and
is signified as a false positive.


 ,
, 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}