Abstract
Hyperspectral image (HSI) analysis generally suffers from issues such as high dimensionality, imbalanced sample sets for different classes, and the choice of classifiers for artificially balanced datasets. The existing conventional data imbalance removal techniques and forest classifiers lack a more efficient approach to dealing with the aforementioned issues. In this study, we propose a novel hybrid methodology ADASYN-enhanced subsampled multi-grained cascade forest (ADA-Es-gcForest) which comprises four folds: First, we extracted the most discriminative global spectral features by reducing the vast dimensions, i.e., the redundant bands using principal component analysis (PCA). Second, we applied the subsampling-based adaptive synthetic minority oversampling method (ADASYN) to augment and balance the dataset. Third, we used the subsampled multi-grained scanning (Mg-sc) to extract the minute local spatial–spectral features by adaptively creating windows of various sizes. Here, we used two different forests—a random forest (RF) and a complete random forest (CRF)—to generate the input joint-feature vectors of different dimensions. Finally, for classification, we used the enhanced deep cascaded forest (CF) that improvised in the dimension reduction of the feature vectors and increased the connectivity of the information exchange between the forests at the different levels, which elevated the classifier model’s accuracy in predicting the exact class labels. Furthermore, the experiments were accomplished by collecting the three most appropriate, publicly available his landcover datasets—the Indian Pines (IP), Salinas Valley (SV), and Pavia University (PU). The proposed method achieved 91.47%, 98.76%, and 94.19% average accuracy scores for IP, SV, and PU datasets. The validity of the proposed methodology was testified against the contemporary state-of-the-art eminent tree-based ensembled methods, namely, RF, rotation forest (RoF), bagging, AdaBoost, extreme gradient boost, and deep multi-grained cascade forest (DgcForest), by simulating it numerically. Our proposed model achieved correspondingly higher accuracies than those classifiers taken for comparison for all the HS datasets.
1. Introduction
The spatial–spectral resolution of HSI has substantially improved with the speedy expansion of earth-observation technologies. Over the past two decades, they have been used in several applications for the advancement of humanity, such as the management of the environment [1], agricultural precision [2], plantation and forest-related issues [3], geological surveys [4], and national and international military defense [5]. The images taken over specific earth surfaces are referred to as the scene, containing various landcover classes such as flora, constructions, water bodies, etc. Because each related landcover occupies a varied surface area region, the number of pixels representing each class varies. Noise, quality, the quantity of labeled data, dimensionality, and imbalance in categorical samples are all challenges related to HS data [6]. The excellent strategy provided by machine learning (ML) and deep learning (DL) has eased the way to deal with the dataset’s embedded concerns [7].
Imbalanced data refer to classification challenges in which the classes are not equally represented; the main class is the most common, while the minor class is the rarest [8]. The HSI dataset is imbalanced since insufficient data instances belong to either of the class labels due to their different land-area coverage. Imbalanced classifications complicate predictive modeling because most ML algorithms for classification were created with an equal number of samples per class in consideration. As a result, classification errors are more likely to occur in the minor class than in the major class [9]. The possible solution to the imbalanced data problem is resampling, which segregates into oversampling and undersampling [10]. Previous research on HSI imbalance primarily deals with oversampling techniques followed by a suitable model to train the dataset. ADASYN has recently been extensively used in biomedical applications for imbalanced data classification. For example, Satapathy et al. [11] proposed ADASYN to remove the imbalance in the electroencephalograph (EEG) dataset, which is further grouped into three disjoint sets. The artificial bee colony (ABC) strategy optimized radial basis function network (RBFN) is used as the classifier. However, the method falls weak for the multi-class problem. The same dataset is used by Alhudhaif et al. [12], who intended to incorporate ADASYN with a one-against-all (OVA) approach with an RF classifier. This work can be extended to explore more multi-class datasets. In [13], Khan et al. suggested using ADASYN for dealing with the class imbalance problem in Breast Imaging-Reporting and Data System (BI-RADS) datasets, containing eight classes ranging from benign to malignant.
In recent times, deep ensemble learning classification techniques have gained popularity [14]. The goal is to create a powerful ensemble by combining multiple weak models [15] or fusion with a DL paradigm. Zhou and Feng [16] introduced a deep-learning-based forest technique called DgcForest, a deep ensembled prototype consisting of decision trees (DT), as an alternative to DL. Because of its cascade structure and Mg-sc scanning for high-dimensional data, the DgcForest approach has a significant representation learning capacity. The number of cascade levels required to build the DgcForest can be decided by self-adjustment, allowing it to operate well on various data even with a modest quantity of training samples. Furthermore, DgcForest is built with numerous DTs, has minimal hyperparameters required to be adjusted, and is simple to study conceptually. For example, Yin et al. [17] proposed DF consisting of DTs that use PCA to reduce the dimension and extract the spectral features. They did not include the spatial characteristics and trained with limited samples. Cao et al. [18] proposed a DF with RoF as its base trees, where each layer’s output probability is used as a supplement feature in the next layer. The model uses a limited number of samples to train. Liu et al. [19] suggested a DgcForest that simultaneously extracts spatial and spectral features. The framework suffers from redundant features generated from the processed HS dataset and non-optimized hyperparameters. In [20], Liu et al. proposed a technique that extracts the morphological attribute profile cube (MAPC) from the HS dataset and employs deep RF, which is advantageous in parameter setting and processing the data into several neural line-like channels. This model yields good results with randomly selected limited training samples.
Our study proposes a novel hybrid approach ADA-Es-gcForest to address three operational issues of HS data. The methodology we deployed in this paper is distributed into four parts: First, we used PCA to identify the most discriminative global spectral features by minimizing the enormous dimensions, i.e., redundant bands. Second, we augmented the data and balanced the samples that belong to the minor class to equal the sample count of the major classes using the adaptive synthetic minority oversampling approach (ADASYN). Third, we adaptively created windows of varying widths using subsampled Mg-sc to extract minute local spatial–spectral characteristics. Here, we used two different forests—an RF and a CRF—to produce the input joint-feature vectors of different dimensions. Finally, we employed the enhanced deep CF for classification, which improved the accuracy of the classifier model by reducing the vast dimensions of the feature vectors and boosting the connectivity of the information flow between the forests at different levels. The trials were also carried out by gathering the three most relevant, publicly available HSI datasets: IP, SV, and PU. Its validity was proven by computationally simulating the proposed methodology against various state-of-the-art notable tree-based ensembled methods, such as RF, RoF, bagging, AdaBoost, extreme gradient boost, and DgcForest.
The key contributions of this study, as per our belief, are summarized below:
- The modified version of ADASYN with an adaptive sampling ratio and subsampling tactics is proposed to balance the dataset’s major and minor class samples. In this study, we applied the ADASYN on similar pixel-wise subsets of the dataset instead of using it on the whole. Therefore, we faced no spectral information loss;
- More minute local spatial–spectral features constitute the input feature vectors using the subsampling strategy. Subsampling transformation instances reduced the computational parameters and computational hazards of our model. In addition, the model’s concurrent processing of RF might further minimize memory requirements and time costs, improving the model’s training speed;
- The uniqueness of the retrieved features can be improved by using multi-grained and multi-window scanning. Furthermore, using two distinct RFs enhances the variability of characteristics even more;
- The enhanced deep CF has far fewer hyperparameters than other deep neural networks and TECs on small-scale HS data. It performs better on biased and unbiased HS data. In addition, the hyperparameters of the algorithm are extremely robust on diverse HS data;
- Our proposed hybrid model, ADA-Es-gcForest, combines all the advantages of its individual components, has a low training cost, and does not require a large number of processing resources. Moreover, its efficiency is much higher than TECs, as shown in Section 3.
The remaining organization of this study is arranged in the following manner: Section 2 represents the methodology for our research work, Section 3 depicts the evaluation and validation of our model with performance test results. Finally, Section 4 provides the conclusions and the limitations and the future opportunities of our research work.
2. Methodology
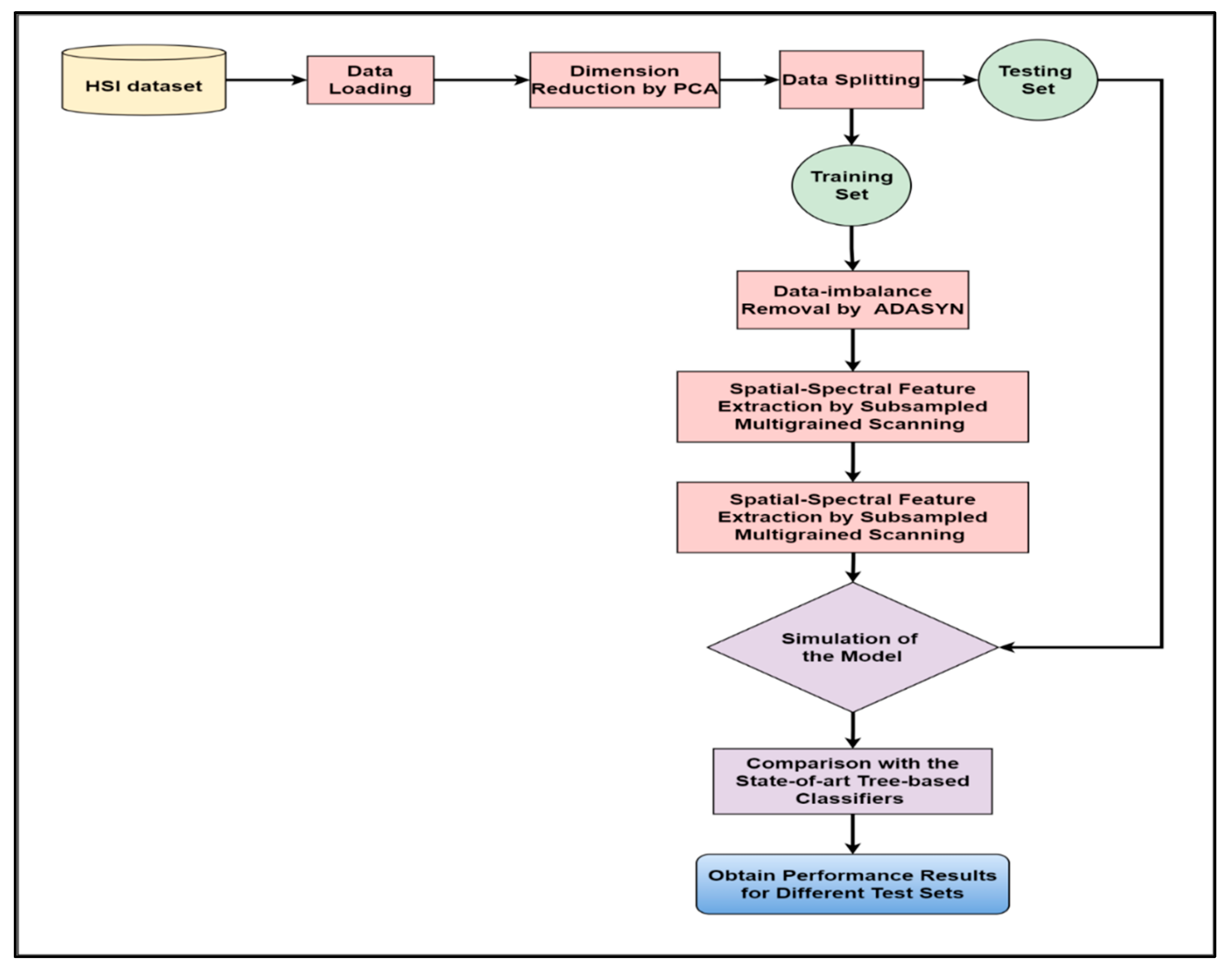
Figure 1 displays the framework of our proposed approach for improving HSI categorization by coping with sample imbalance. Our research begins with collecting the HSI datasets available in the public domain. Then, the data were loaded into our programming environment using suitable code fragments. As a result, we obtained the false-color images of the datasets taken as inputs (Figure 2, Figure 3 and Figure 4). We used PCA to reduce the vast dimensions of the input images as preprocessing, then split the data into training and testing sets. The dataset for training was further used for training the model. The train set was first applied with ADASYN to overpopulate the minor class samples to match with the major class samples. The balanced dataset was then subsampled using multiple fixed-sized sliding masks (grains) to extract the spatial–spectral features embedded in each window. Then the collected features constructed the input vector to feed the classifier, i.e., enhanced deep CF. The whole process trained the model with deterministic components to simulate and evaluate the test datasets. The test results of our model were compared with other tree-based classifiers in similar conditions, and the performance analysis was recorded.
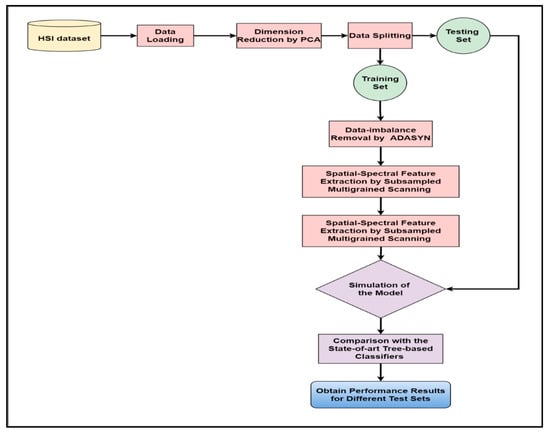
Figure 1.
The workflow diagram of our proposed model ADA-Es-gcForest.
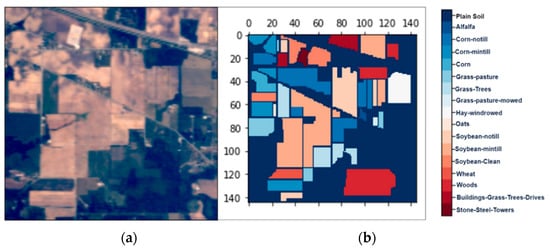
Figure 2.
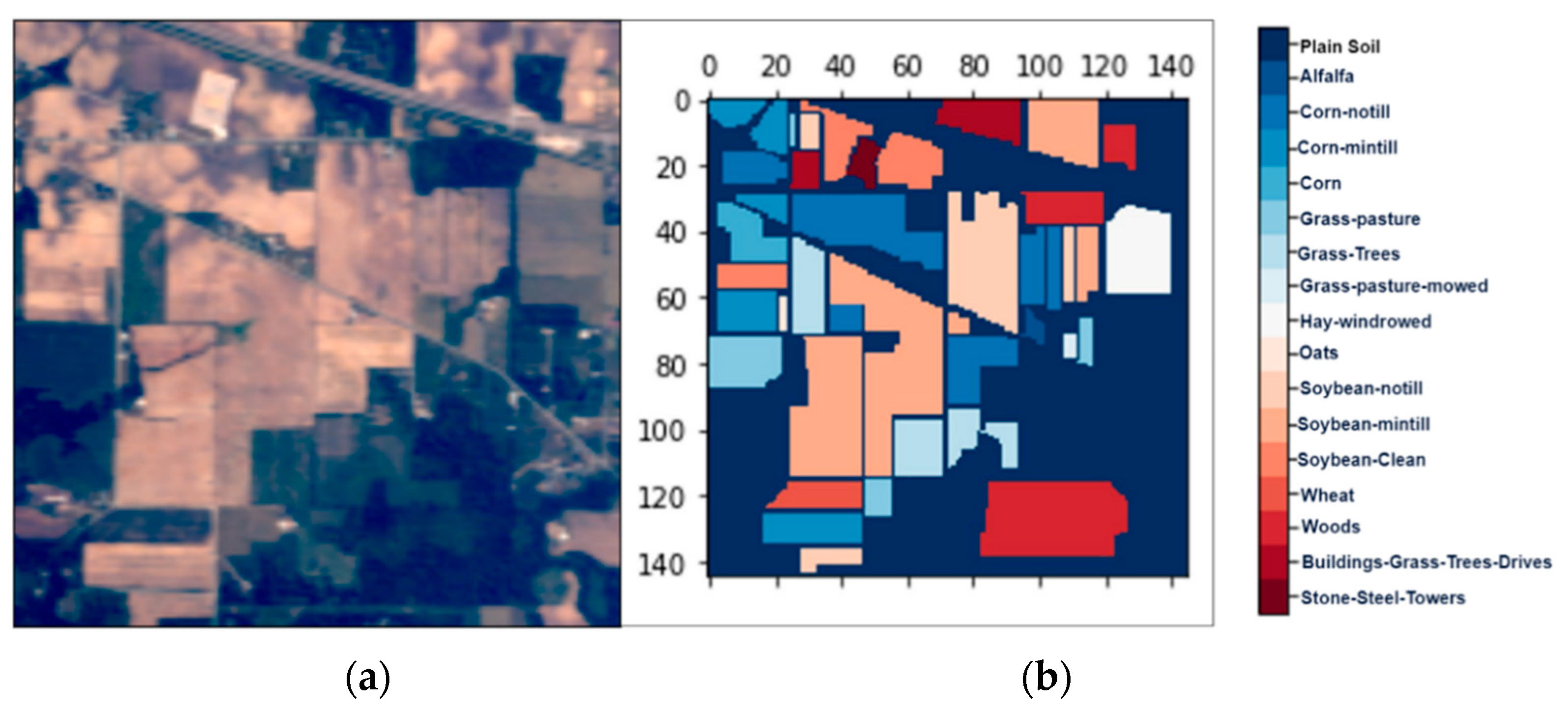
The hyperspectral datasets: Indian Pines (IP): (a) the color composite image, (b) the false-color image.
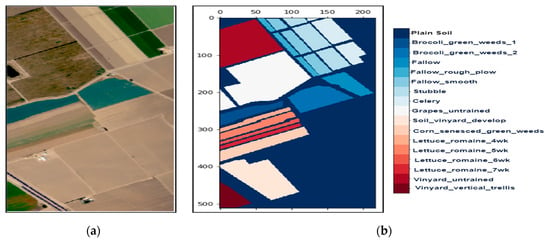
Figure 3.
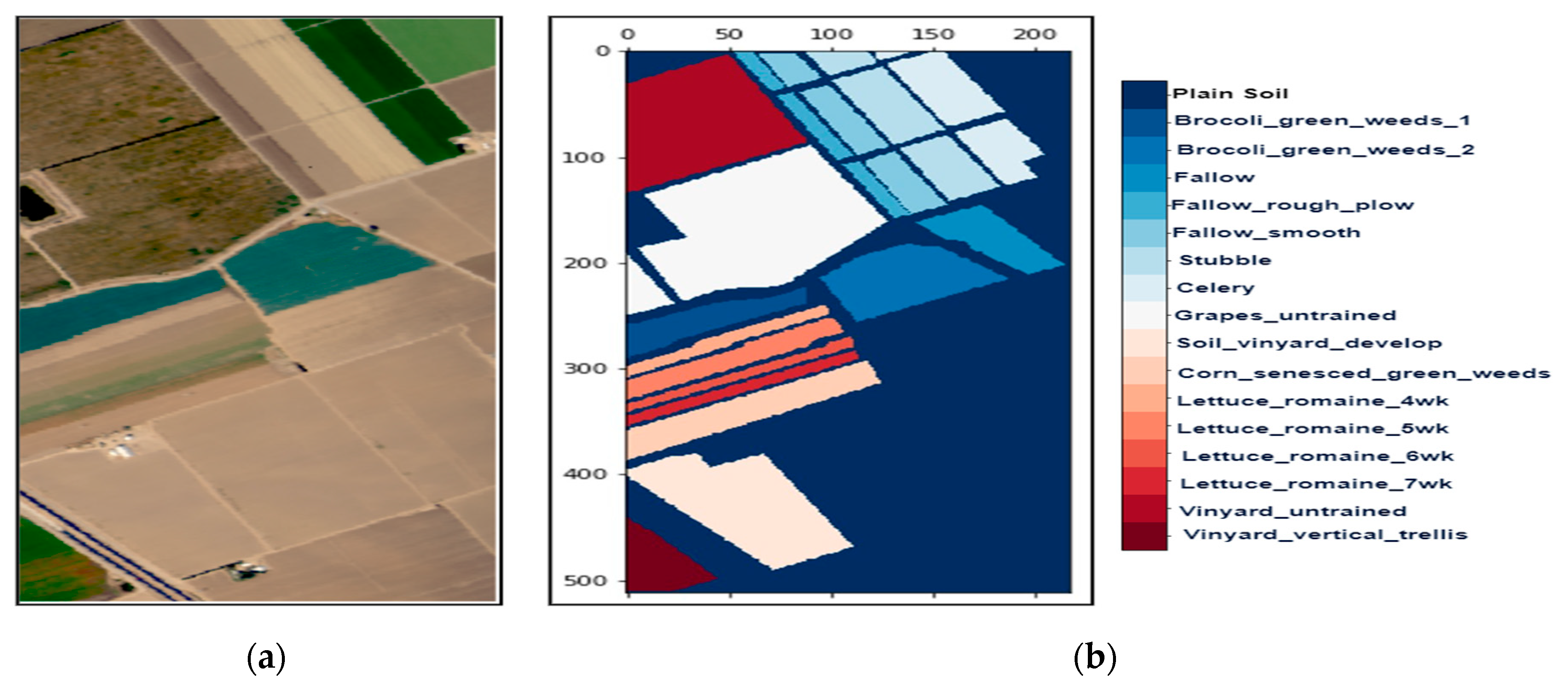
The hyperspectral datasets: Salinas Valley (SV): (a) The color composite image, (b) the false-color image.
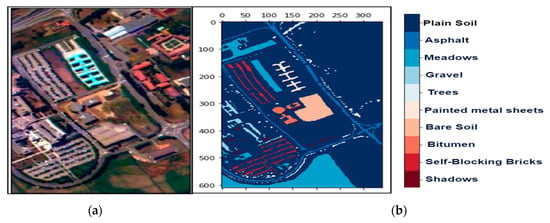
Figure 4.
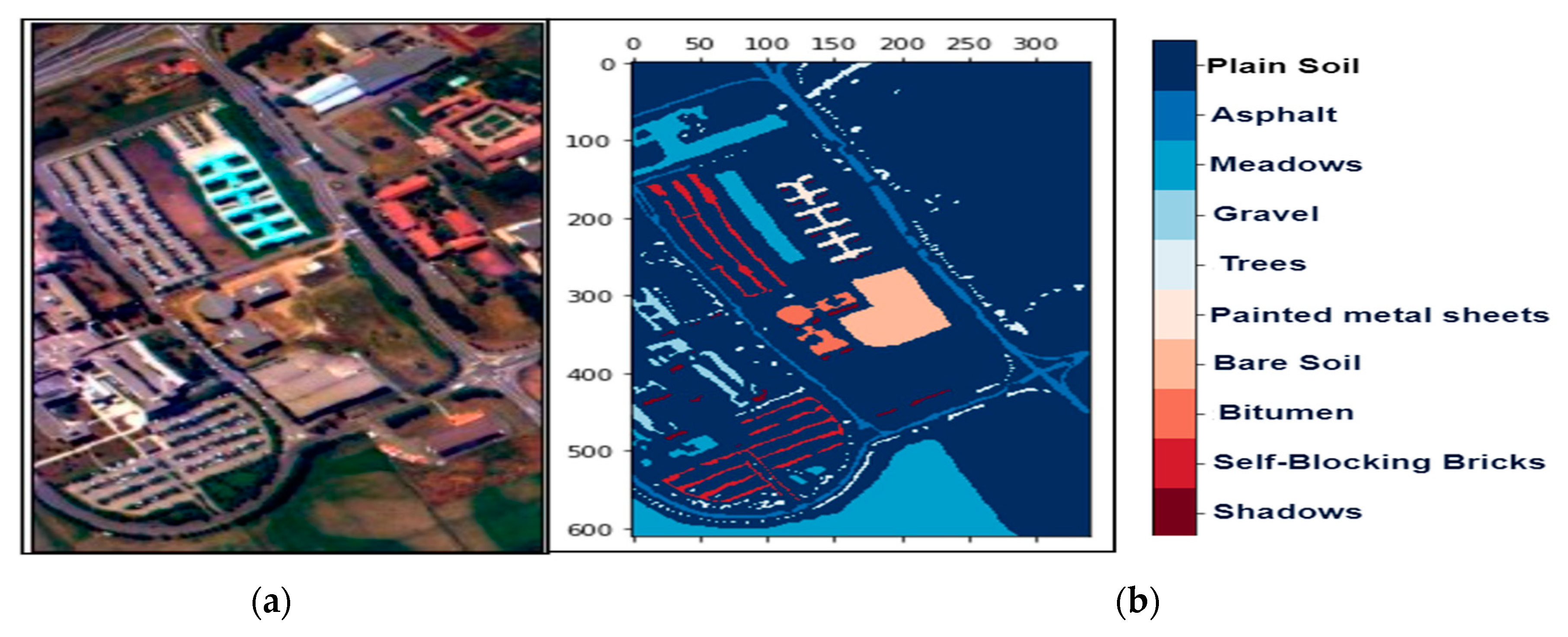
The hyperspectral datasets: Pavia University (PU): (a) The color composite image, (b) the false-color image.
2.1. Datasets
We collected three mostly explored HS datasets available in the public domain [21] with significant applicability. The datasets were: (a) the AVIRIS Indian Pines (IP) site in Northwestern Indiana with 145 × 145 pixels with 200 working spectral reflectance bands and a class imbalance ratio of 73.6. The scene has 16 different landcover classes, as shown in Figure 2. The second dataset was: (b) the AVIRIS Salinas Valley (SV) site in California, USA, with 512 × 217 pixels with 204 working spectral reflectance bands and a class imbalance ratio of 12.51. The scene has 16 different landcover classes, as shown in Figure 3. The third dataset was: (c) the ROSIS-03 Pavia University (PU) site in Italy, with 610 × 340 pixels with 103 working spectral reflectance bands and a class imbalance ratio of 19.83. The scene has 9 different landcover classes, as shown in Figure 4. The ground data description of all the datasets is provided in Table 1.

Table 1.
The ground truth for the HSI datasets: IP, SV, and PU.
The datasets were imported as hypercubes and translated to a 3D format that could be processed. The 3D images were then transformed into a 2D format that machines could read. The data were divided into training and testing datasets with varying train-to-test ratios. We used 40%, 50%, and 60% of the original datasets to train our proposed model and the models to be compared. The rest of the data was held aside for testing and confirmation. The training dataset was processed further, whereas the testing dataset was left intact.
2.2. Removing Data Imbalance in HSIs
Imbalance in a dataset was measured by a metric called the ‘class imbalance ratio’, which is defined as the ratio between the total number of instances belonging to the major and minor classes. Generally, we defined 25% and 75% of the class as having the highest number of instances as the threshold for discriminating between minor and major classes. For example, classes 1, 4, 5, 7, 9, 12, 13, and 16 were the minor classes for the IP dataset, and class 11 was the major class. In our proposed model, we used ADASYN for data augmentation by generating synthetic minor samples, which balanced the number of samples belonging to each category the dataset was divided into. In addition, we used SMOTE, another efficient oversampling technique, to compare our work. He et al. [22] introduced ADASYN as a generalized and extended version of the method—SMOTE. This algorithm also proposed to oversample the minor class by generating artificial samples, using a weighted distribution for different minor class samples based on their level of learning difficulties. As a result, additional synthetic data were generated for minor class samples that were harder to learn than the minor class examples that were easier to learn. As a result, the ADASYN improved data distribution learning in two ways: (1) by reducing bias caused by class imbalance, and (2) by changing the classification decision boundary in the direction of complex cases.
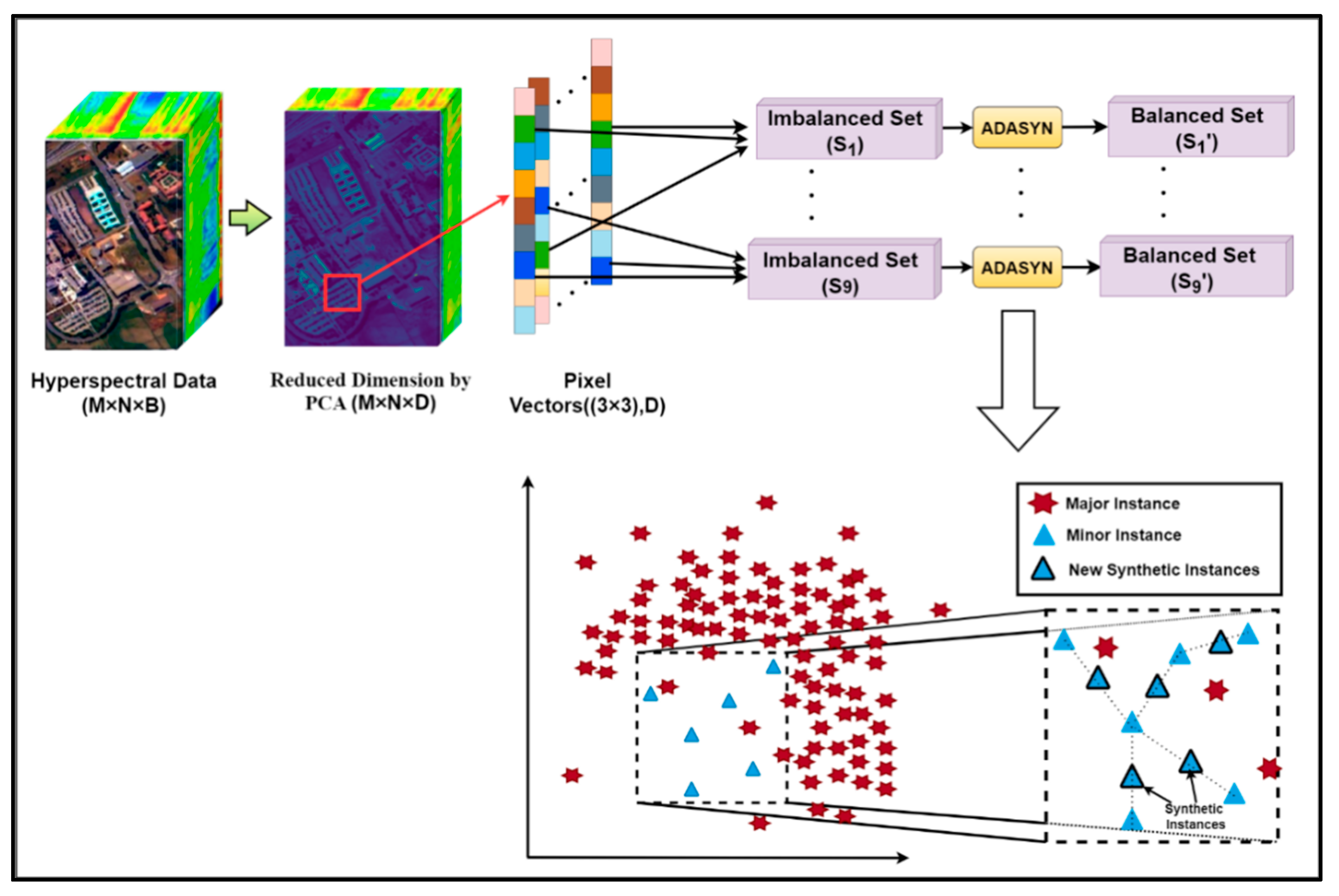
Suppose the original HSI dataset was of dimensions M × N × B, where M and N denote the length and width of the 3D hypercube and B represents the number of spectral bands. Each band consisted of a total of (M × N) pixels. PCA was employed to reduce the influence of redundant information for dimensionality reduction on the entire original image containing labeled and unlabeled pixels, as illustrated in Figure 5. The new size of the dimension-reduced HSI dataset was M × N × D, where D represents the number of principal components and D < B. The most significant spectral features of the entire HSI dataset lie with D bands. Next, we reshaped each of the D numbers of bands into a 1D data structure containing spatial characteristics represented by the (M × N) number of pixels. Every imbalanced 1D band is oversampled using ADASYN, as diagrammatically shown in Figure 5. In order to achieve the spatial–spectral information of the dimension-reduced dataset, a sliding window of size 3 × 3 × D with stride step 1 was run all over the dataset. Thus, the total number of instances/pixel vectors obtained was K = (M − 2) × (N − 2), with eight neighboring pixels for each central sample of the window, as shown in Figure 5. Since each sample is generally similar to its spatial neighbors due to the spatial similarity, possessing the same class label. Thus, we obtained the imbalanced dataset with subsets as S = {S1,···,S9} by collecting and extracting the pixels from the corresponding locations from every patch. Next, ADASYN oversampled each imbalance dataset based on the proportion of majority class occurrences to minority class instances based on the red ‘*’s as major samples and blue triangles as minor samples, respectively (Figure 5), denoted as S’ = {S’1,···,S’9}.
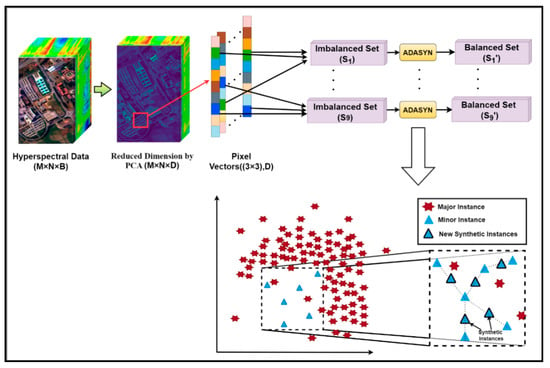
Figure 5.
The preprocessing and spectral feature extraction unit for HSI.
2.3. Tree-Based Ensembled Classifier Enhanced Deep Subsampled Multi-Grained Cascaded Forest (Es-gcForest)
DgcForest [21] is a DL approach consisting of an ensemble of DTs at the lower hierarchy and RF and CRF at the upper. The RF is a dataset of multiple DTs—some DTs may show the accurate output while others may not—however, all trees anticipate the appropriate result. DTs choose an algorithm to determine nodes and sub-nodes; a node can be split into two or more sub-nodes; another homogeneous sub-node is created by generating sub-nodes. The split is done with the highest information in the initial place, and the procedure is repeated until all of the child nodes contain consistent data. A CRF is an RF whose nodes are complete on every level and contain symmetrical information. The candidate feature space is the major distinction between the two types of forests. The CRF chooses features to split at random in the entire feature space, whereas the ordinary RF chooses split nodes in a random feature subspace based on the Gini coefficient. The DgcForest algorithm is based on the DNN algorithm, which has the superpower of handling feature connections and the complex depth model. It includes two parts: CF, a deep procedure, and Mg-sc, which regulates feature relationships and improves CF. These two aspects are described in depth in the following sections.
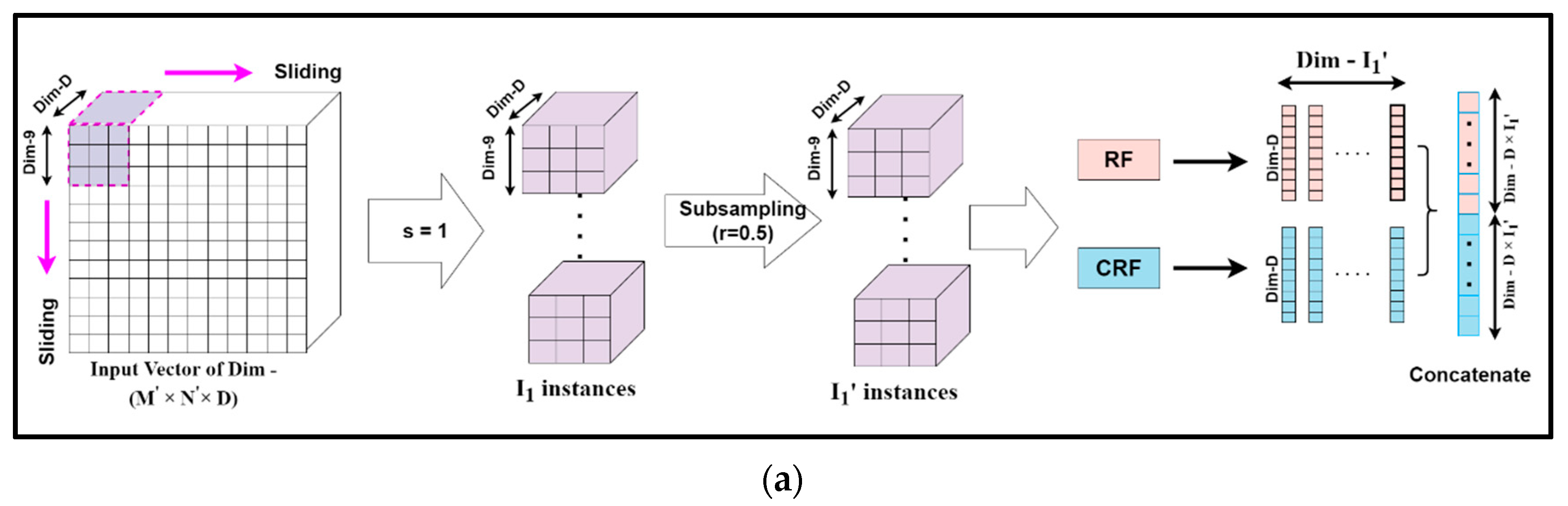
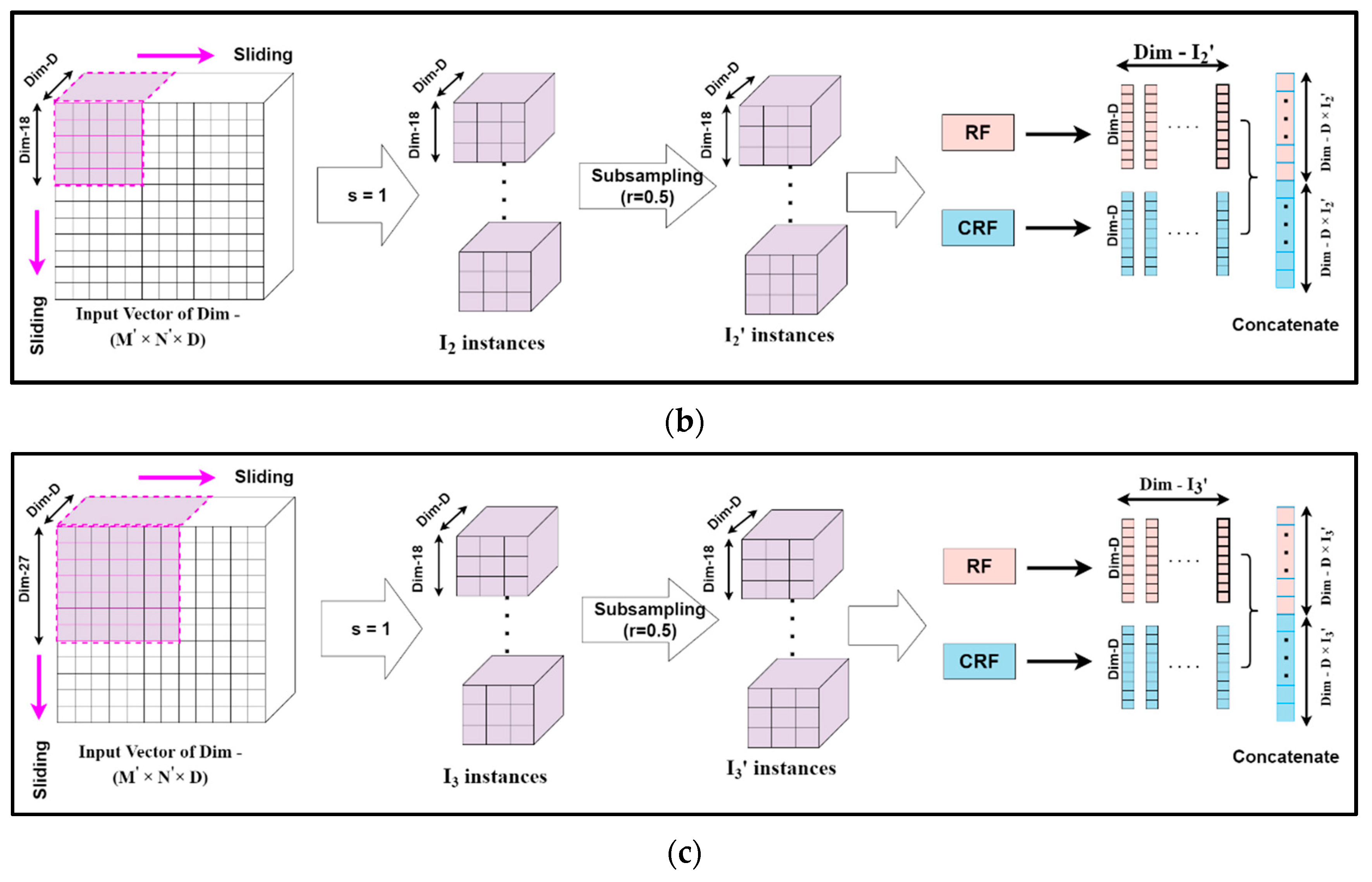
2.3.1. Subsampled Multi-Grained Scanning
Mg-sc is a crucial feature of DgcForest that helps improve the representational learning ability when inputs have a lot of dimensionalities, making it ideal for HSI classification. A sliding window was used to scan raw features in order to build numerous feature vectors in Mg-sc. Then, a CRF and an RF were used to train the instances corresponding to these feature vectors. After that, the class vectors were created, and transformed features were concatenated. The data that the sliding window traverses every time were selected as a sample in Mg-sc. From the original input, the sliding operation can learn the feature vector of the input information. Then, we used the class probability vectors output by the two RFs as the features of the new sample, and input them into two RFs, one general and the other a CRF. The subsampled Mg-sc was elaborately described with the help of Figure 6 and the following mathematical expressions [23].
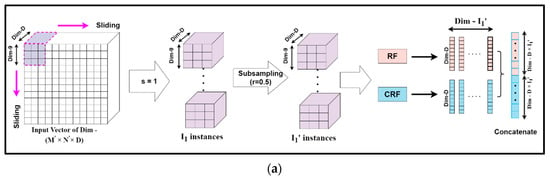
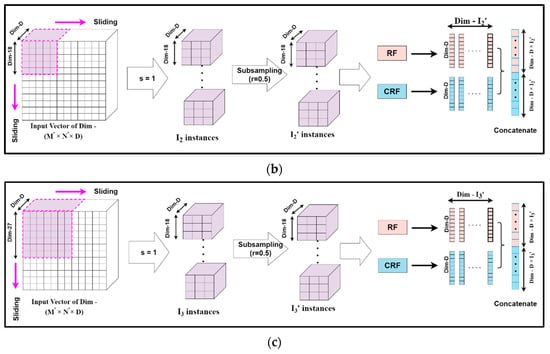
Figure 6.
The feature extraction unit for the subsampled multi-grained scanning: subsampling schema for sliding window or granularity size (a) 9 × 9, (b) 18 × 18, (c) 27 × 27.
Assuming the new dimension of the input HS dataset to be (M′, N′, D), we chose the dimension of each sliding window, i.e., the size of the subsampled set for Mg-sc as m1 × m1 × D, m2 × m2 × D, and m3 × m3 × D, respectively. Here, m1, m2, and m3 are all less than M′ and N′, representing the size of each particle.
The number of instances I was obtained when a sliding window of m1 granularity slid through a stride step of s, as:
We considered the sampling rate of the subsampling to be r, and the number of subsampled instances, denoted by I′, became:
Our algorithm set I′ as the input data to two different forest structures, namely, RF and CRF. The distinction between the RF and the CRF was in the tree feature selection. The RF selected √N features, N being the count of the input features, at random before segmenting the feature with the best Gini coefficient. The CRF, on the other hand, chose a feature for segmentation at random as the split node of the split tree and then grew until each leaf node. Thus, first, the class probability vectors of I′ numbers were obtained. Then, a new feature vector was generated, for example Y1, as a linear combination achieved from the forests mentioned above of dimension d, which is expressed as:
Thus, the complete set of input feature vector Y = { Y1, Y2, Y3} for the deep CF is given by:
where denote the number of instances for different granularities to obtain the set feature vectors Y.
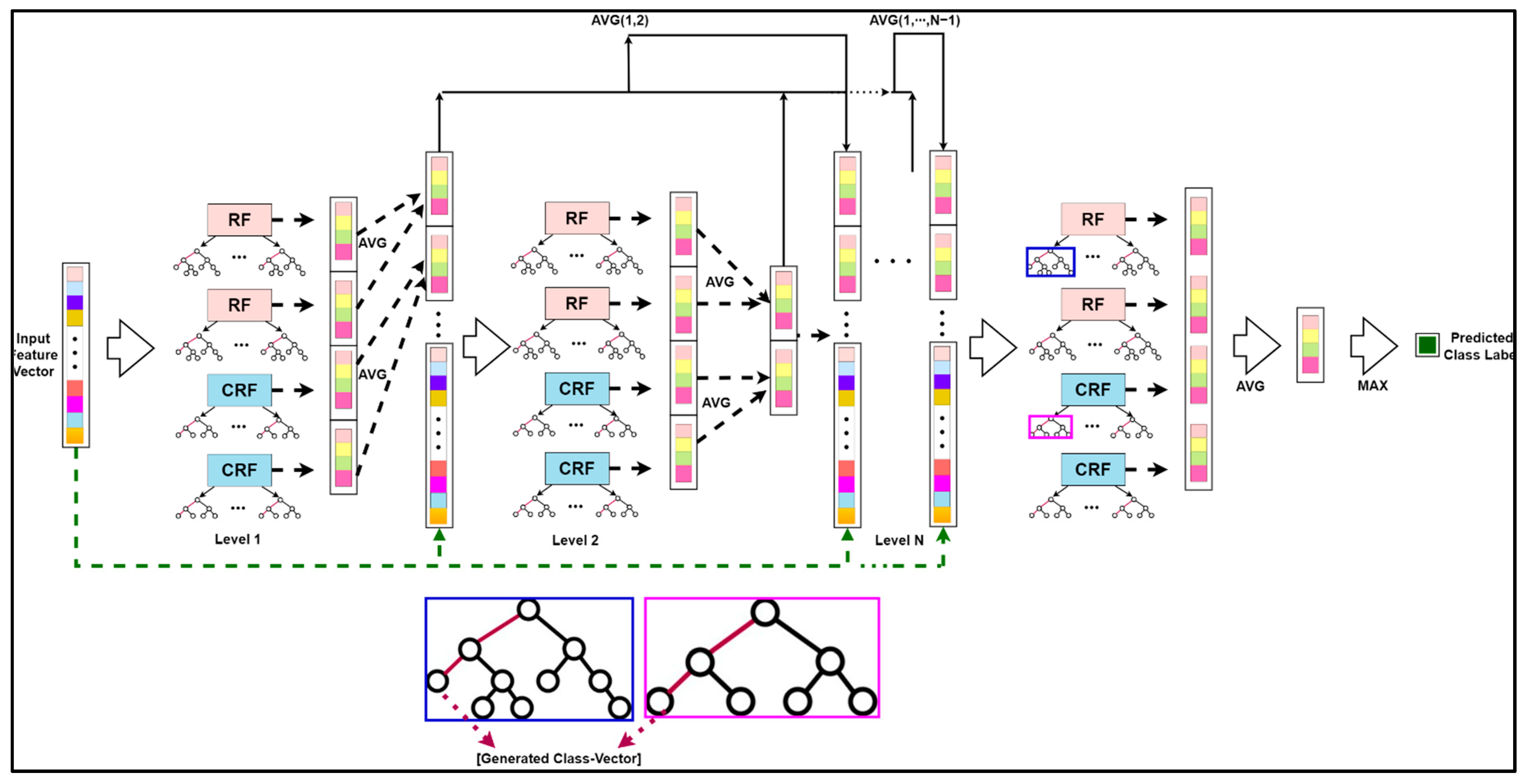
2.3.2. Deep Cascaded Forest
CF works on a level-by-level basis, similar to how DNNs work on a layer-by-layer basis. Each level of a CF receives the feature information from the previous level’s processing and sends the feature information to the next level. Each level contains two types of forests: RFs and CRFs, each having an F-number of forests, to encourage the diversity needed for ensemble formation. F is a hyperparameter that can be specified in various ways depending on the situation. There are Ft trees in both CRF and RF. Each tree leaf node develops until it includes just the same class of instances or no more than ten examples. The method uses Mg-sc to build its matching altered feature representation before going through a multi-level cascade to generate high abstract feature vectors. It outputs the instance’s class distribution to the next level at each level of a CF. The DTs are categorized by the leaf node into which the input instance falls, forming a CF’s foundation. The leaf node may contain training samples from the same or separate classes. The proportion of the total number of samples of the leaf node that each category includes is computed for the leaf node into which the instance falls and then takes the average of all decision-making leaf nodes in the same forest. The output of the forest in each level cascade is a class vector used by the forest in each level cascade to process information, for instance. The outcomes of all forests in each level’s class vectors are concatenated, and the output to the next level is mixed with the original input vector.
The basic deep CF structure can be depicted mathematically with the help of the following illustration [24] and diagrammatically with the assistance of Figure 7. Let the denotations be as follows:
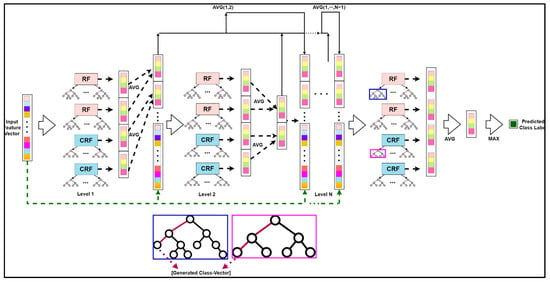
Figure 7.
The classification unit for HSI: The schematic structure for the enhanced deep CF.
K: the total number of DTs belonging to every level of the deep CF;
F: the total number of forests included in each level of the deep CF;
V: the total number of CF levels in the deep model;
L: the specific class label of any sample.
The probability that every subtree predicts for any sample z belonging to class l is expressed as:
where k ∈ K, k denotes the kth DT.
The estimated class distribution for sample z obtained by each forest in F is equated as:
where f ∈ F, f denotes the fth forest.
For all forests in the said level, we obtained the estimated class distribution as:
where v ∈ V, v denotes the vth cascade level.
Thus, the predicted class label for the sample z is formulated as:
where max(*) and avg(*) functions represent the maximum and average operators, respectively.
The original feature vector of the sample was intertwined with the estimated class distribution in this level as the input feature for the next level of the forest, which is represented as:
Analogically, the training was halted once the classification accuracy of the two-level verification subset before and after the CF no longer rose.
DgcForest suffers from the sparse connectivity problem, as proposed by Wang et al. [25]. The greater the forest levels, the greater the degradation of the information embedded in the feature vectors. In addition, more deepening of the cascade levels leads to a considerable increment in the dimension due to the growth in input feature vectors, which adversely affects the classification outcomes. Consequently, our study proposed an enhanced deep subsampled multi-grained CF where the initial feature vector was updated as the input vector of each level of the Es-gcForest cascade layer. The average value of the previous forest output of each level was combined. Each forest built its class distribution estimation vector by considering each level using the RF and the CRF. As a result, an improved class distribution estimate vector could be created by averaging the output vectors of the same forest type, and the output vector could be doubled. The improved technique considers the impact of previous forest classification results at each level, which reduces the dimensions of the input features at each level and keeps the classification results’ feature information and beginning feature vectors.
3. Experimental Results with Analysis
This section represents the analytical description of the experimental outcomes along with the tools and techniques with its parameters and assessment metrics, which are divided and elaborated in the following subsections.
3.1. Experimental Setup
All program codes were implemented using high-end machinery and Python language with its latest versions of embedded packages. The complete hardware and software specification information is provided in Table 2.
Table 2.
Complete hardware/software specification information.
In order to establish that our proposed PCA-ADASYN-based ADA-Es-gcForest was more advantageous, we completed the following steps: (1) We took 20, 40, 50, and 60 global spectral features selected by PCA to evaluate each model’s performance. (2) We included the eminent oversampling methods and applied them to remove the imbalance in the HSI datasets. Thus, we considered SMOTE to compare with the results obtained by ADASYN. (3) Six tree-based standard ensemble classifiers were chosen, i.e., RF, RoF, bagging, AdaBoost, XGBoost, and DgcForest. These comparison algorithms are being novelly used for HS datasets. (4) We tested on the same preprocessing environment with our proposed model to produce a comparative statistical analysis of classification performance (different ensemble tree-based classifiers obtained the accuracy). (5) We obtained the classification maps of all three datasets taken in our experiments for better comprehensibility. (6) We made a training time comparison between the TECs and our model to depict their time complexities.
3.2. Metrics of Assessment
The overall accuracy (OA) is frequently used to evaluate traditional ML classification methods since it can convey the classifier’s overall classification efficiency. However, suppose there is a significant imbalance between the classes of the data. In that case, the classification model may be heavily biased in favor of the majority classes, resulting in poor recognition of minority classes. As a result, OA is not the best metric to use to assess the model because it could lead to incorrect conclusions [26]. Consequently, to execute the entire procedure, we used five effective measures to analyze our model’s performance: precision, recall, F-score, CoheN′s kappa, and average accuracy, in addition to overall accuracy. The following are the details: Let us denote M = the total number of class labels in the dataset, cii = true estimate of ith class, cji = false estimate of ith class, and cij = false estimate of ith class into jth class.
a. Precision Score: Precision is used to evaluate the classification accuracy of each class in the unbalanced data. For a superior classifier, the precision score should be high. The Prec Score percent precision score evaluates the testing prediction rate of all samples and is defined as follows:
b. Recall Score: The percentage of accurately identified occurrences is known as the recall or true positive rate. The recall is particularly well suited to evaluating classification algorithms that deal with a large number of skewed data classes. The higher the recall value, the better the classifier’s performance. The following calculation gives the Rec Score percent:
c. F_Score: The F-measure, an assessment index generated by integrating precision and recall, has been frequently used in the classification of imbalanced data. The F-measure combines the two, and the higher the F-measure, the better the performance of the classifier. The formula for calculating F_Score percent is as follows:
Ri and Pi signify the precision score and recall score of class i, respectively.
d. Cohen_Kappa_Score: CoheN′s kappa is a statistic that assesses the predictability of results and decides whether they are truly random. The higher the Cohen kappa, the better the classification accuracy. The percent kappa score is calculated as follows:
where qi and qI′ denote the original and predicted sample sizes of class i, respectively.
e. Average Accuracy: Average accuracy (AA), being a performance metric, assigns a similar weight to every of the data types, regardless of their number of instances. The mathematical identity for AA is according to the following expression:
f. Overall Accuracy: The probability that an experiment on any particular testing sample will successfully categorize to the correct class label is known as the overall accuracy (OA). The following is a definition of OA:
3.3. Configuration of Model Hyperparameters
Our proposed model ADA-Es-gcForest is a super-hybridization of four eminent techniques addressing three prominent issues in operating and analyzing HSIs, which are, (1) PCA for dimensionality reduction and global spectral feature extraction, (2) ADASYN for balancing the data and augmentation, (3) subsampled Mg-sc for local feature extraction, and (4) improved deep CF for classification. In addition, we chose SMOTE to compare ADASYN and the several latest TECs. Their performances are significant for identifying the correct categories for the data samples to compare our proposed model ADA-Es-gcForest. Therefore, we configured each technique’s hyperparameters validly to execute all the methods mentioned above. Setting the optimal hyperparameters similarly plays a vital role in the model simulation for all datasets.
3.3.1. Hyperparameter Tuning for PCA
The hyperparameter setting for the PCA is depicted in Table 3. The aim is to find the near-optimal number of global spatial features. The ‘number of components’ here signifies the number of global spatial features obtained as preprocessing by PCA of the raw image. Whiten = ’True’ removes some information from the modified signal, but it can increase the predicted accuracy of subsequent estimators by forcing their data to follow specific difficult constraints. ‘SVD’ (singular value decomposition) is used for feature reduction.
Table 3.
The hyperparameter configuration of PCA.
3.3.2. Hyperparameter Tuning for SMOTE and ADASYN
We use the two most efficient oversampling techniques to remove imbalance from the datasets, i.e., SMOTE and ADASYN. They both share the same parameters, as represented in Table 4.
Table 4.
The hyperparameter configuration of SMOTE and ADASYN.
The ‘sampling strategy’ signifies whether we want to operate on major samples or minor. ‘k’ is the number of neighbors we consider to generate new synthetic data in the vicinity. For ADASYN, ‘µ’ signifies the desired level of balance in generating the synthetic samples. By default, its value is set to 1, meaning it will generate fully balanced data making the dataset huge and computationally complex. Hence, we set the value µ = 0.5 to provide a balance between the chosen major and minor class samples, leading to better classification accuracy, as shown in Section 3.4.2. Here, we used the traditional k-NN algorithm where a pre-defined k value was applied as the hyperparameter to all classes, irrespective of the sample class distributions of the training set. This is because big classes would overwhelm the small ones if k was set too large, while if k was set too small, the algorithm would not be able to utilize the information in the training data effectively [27]. Furthermore, employing the cross-validation approach on a retrospective validation set, the optimal or substantially optimal value of k was frequently obtained. However, we did not always seem to be able to attain such an appropriate k value before processing such large voluminous HSI datasets. Thus, by studying a few works of literature [28] that took five NNs (k = 5) for the calculation of the new synthetic samples for their experience with oversampling, we chose the same for our proposed technique.
3.3.3. Hyperparameter Tuning for Subsampled Multi-Grained Scanning
The local features were extracted by the subsampling strategy used in Mg-sc. The number of DTs taken for each RF and CRF was 100 in each level of Mg-sc. The hyperparameters for the subsampling and the resulting feature generation are statistically shown in Table 5. Here, the granularity size, stride step size, and sampling rate were the tuned hyperparameters, whereas the last three attributes in the table represent the features generated at each level.
Table 5.
The hyperparameter configuration and feature generation of subsampled multi-grained scanning.
3.3.4. Hyperparameter Tuning for Enhanced Deep Cascaded Forest
The hyperparameters for the deep CF were tuned, as stated in Table 6, in a way that they could produce more accurate findings than other algorithms and be used as a benchmark in future comparison tests.
Table 6.
The hyperparameter configuration of improved deep cascade forest.
The classifiers considered for comparison were also tuned with standard hyperparameters; the rest were tuned to default. All of them were set with 500 trees and the split criterion as ‘GinI′.
3.4. Comparative Analysis of Model Performance
This subsection illustrates the comparisons between our proposed model and the other contemporary state-of-the-art techniques on a three-fold basis: spectral feature sets, forest-based classifiers, and time elapsed for execution of training the models.
3.4.1. Spectral Feature-Based Comparison
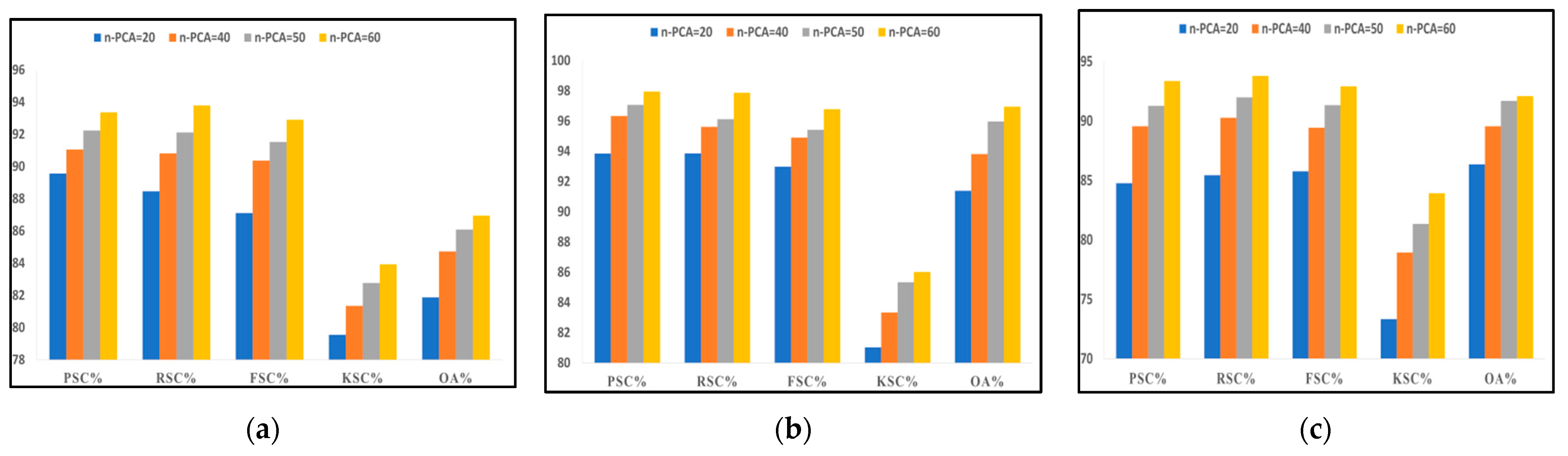
Once the data were acquired and transformed into a machine-readable 3D matrix format, PCA reduced the dimension and obtained the most significant and discriminative spectral features for further processing. Next, we removed the imbalance from each dataset with the selected spectral bands using ADASYN. The preprocessed data were provided to the classifier DgcForest to classify the embedded landcover in those HS scenes. This spectral feature-based comparison aims to determine the maximum number of principal components required to obtain the best classification results with an appropriate time constraint. The classification metrics used in this comparison were precision, recall, f-score, kappa score, and overall accuracy. We considered four cases with the number of principal components (n-PCA) 20, 40, 50, and 60 for each HSI dataset. Figure 8 represents a graphical illustration of the performance of our model ADA-Es-gcForest for the datasets IP, SV, and PU, respectively, concerning the different n-PCA or distinct spectral features. From the figures, the variation of all classification metrics must be maximum at the leap of n-PCA = 20 to 40 for all three datasets. With the further increment in n-PCA, the metrics also increase slightly by decimal points. Thus, we considered 60 fixed global spectral features to proceed in our experiments further. In addition, the number of optimal cascade layers for the different datasets for various n-PCA is given in Table 7. The higher the number of layers, the more the accuracy of the classifiers drops, leading to early stopping to be applied to fit the model to the training set [29].
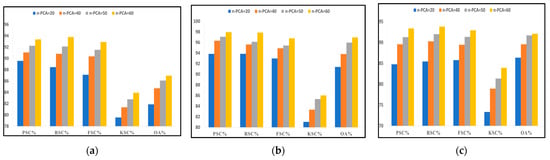
Figure 8.
The comparison of precision, recall, F_Score, kappa score, and overall accuracy achieved by our proposed model ADA-Es-gcForest for different principal components for (a) IP dataset, (b) SV dataset, (c) PU dataset.
Table 7.
The summarization of the variation of cascade layer count with the number of PCA components for the HSI datasets.
3.4.2. Classifier-Based Comparison
The original HSI datasets were split into training and testing sets by three categories: (i) Training sample, 40%, test sample, 60%; (ii) training sample, 50%, test sample, 50%; and (iii) training sample, 60%, test sample, 40%. In order to make a comparison, we kept the number of features fixed as stated in the previous sub-section, i.e., n-PCA = 60. The TECs RF, RoF, bagging, AdaBoost, XGBoost, and DgcForest were used to compare the performance of our proposed model ADA-Es-gcForest. In addition, we took the most widely used oversampling technique, SMOTE, to compare with the method we explored, i.e., ADASYN, to assess and compare their outcomes for the HSI datasets.
For Indian Pines Dataset
This dataset acquired a class imbalance ratio of 73.6, which was exceptionally high. In addition, this dataset’s dimension was comparatively lower than others, leading to a limited number of labeled datasets to train the classifier models. The classification accuracies for each class in the dataset are shown in Table 8, Table 9 and Table 10 against different testing sets. Both the accuracy measures, OA% and AA%, were highest for our model compared to others for the lowest test datasets, i.e., 89.7% and 91.47%, respectively, for the 40% test samples. It achieved 2.69% and 2.52% higher OA and AA, respectively, compared to the classic DgcForest with fewer variation rates. In addition, our model’s best OA% and AA% were 4.12% and 5.32% more than the same model executed with SMOTE instead of ADASYN, as shown in Table 8. It is imperative from Table 8, Table 9 and Table 10 that the OA% and AA% decrease with the increase in the testing sample volume. The decrement in OA% was 2.41% and 4.37%, and in AA% it was 1.88% and 3.55% for the 50% and 60% test samples, respectively.
Table 8.
The result in terms of classification accuracies (%) for the IP dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 73.6 and 40% of testing samples.
Table 9.
The result in terms of classification accuracies (%) for the IP dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 73.6 and 50% of testing samples.
Table 10.
The result in terms of classification accuracies (%) for the IP dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 73.6 and 60% of testing samples.
For Salinas Valley Dataset
This dataset acquired a class imbalance ratio of 12.51, which was moderate. In addition, the dimension of this dataset was comparatively higher than IP but lower than PU. We attained a fair number of labeled datasets to train the classifier models. The classification accuracies for each class in the dataset are shown in Table 11, Table 12 and Table 13 against different testing sets. Both the accuracy measures, OA% and AA%, were highest for our model compared to others, i.e., 97.54% and 98.76%, respectively, for the 40% test samples. It achieved 2.52% and 2.27% higher OA and AA, respectively, compared to the classic DgcForest with fewer variation rates. In addition, our model’s best OA% and AA% were 1.96% and 1.72% more than the same model executed with SMOTE instead of ADASYN, as shown in Table 11. It is imperative from Table 11, Table 12 and Table 13 that the OA% and AA% decrease with the increase in the testing sample volume. The decrement in OA% was 2.17% and 4.36%, and in AA% it was 1.97% and 3.87% for the 50% and 60% test samples, respectively.
Table 11.
The result in terms of classification accuracies (%) for the SV dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 12.51 and 40% of testing samples.
Table 12.
The result in terms of classification accuracies (%) for the SV dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 12.51 and 50% of testing samples.
Table 13.
The result in terms of classification accuracies (%) for the SV dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 12.51 and 60% of testing samples.
For Pavia University Dataset
This dataset acquired a class imbalance ratio of 19.83, which was moderate. In addition, the dimension of this dataset was comparatively higher than others, which led to a relatively higher number of labeled datasets to train the classifier models. The classification accuracies for each class in the dataset are shown in Table 14, Table 15 and Table 16 against different testing sets. Both the accuracy measures, OA% and AA%, were highest for our model compared to others, i.e., 92.91% and 94.19%, respectively, for the 40% test samples. It achieved 2.62% and 2.81% higher OA and AA, respectively, compared to the classic DgcForest with fewer variation rates. In addition, our model’s best OA% and AA% were 1.51% and 2.0% more than the same model executed with SMOTE instead of ADASYN, as shown in Table 14. It is imperative from Table 14, Table 15 and Table 16 that the OA% and AA% decrease with the increase in the testing sample volume. The decrement in OA% was 1.06% and 2.17%, and in AA% it wass 1.27% and 3.75% for the 50% and 60% test samples, respectively.
Table 14.
The result in terms of classification accuracies (%) for the PU dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 19.83 and 40% of testing samples.
Table 15.
The result in terms of classification accuracies (%) for the PU dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 19.83 and 50% of testing samples.
Table 16.
The result in terms of classification accuracies (%) for the PU dataset obtained by the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed ADA-Es-gcForest along with their combination with the oversampling technique SMOTE with the class imbalance ratio 19.83 and 60% of testing samples.
3.4.3. Computational Time Comparison
The TECs—RF, RoF, bagging, AdaBoost, XGBoost, DgcForest—and our proposed were also tested for their time complexities in terms of the total time elapsed (TTE). TTE was defined as the total time of execution, i.e., the difference between the start time and the end time of the program code in the machine, which included testing with different train–test ratios. Table 17, Table 18 and Table 19 depict the tabular depiction of the various classifiers used in our work. These classifiers were assisted by n-PCA = 60 and ADASYN as the oversampling technique. The outlook of all three tables made us reach the inference that AdaBoost acquired the lowest TTE, whereas RoF required the highest. In addition, the highest in dimension, the PU dataset obtained the end result in the largest amount of TTE. Our proposed model ADA-Es-gcForest took a fair amount of time to execute, but its TTE was remarkably lower than the DgcForest. Thus, the larger the training set volume, the higher the TTE for all datasets.
Table 17.
The total time elapsed (TTE in seconds) for the IP dataset for the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest training sets by taking 40%, 50%, and 60% respectively, of the original data as training sets.
Table 18.
The total time elapsed (TTE in seconds) for the SV dataset for the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest training sets by taking 40%, 50%, and 60% respectively, of the original data as training sets.
Table 19.
The total time elapsed (TTE in seconds) for the PU dataset for the ensemble classifiers: RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest training sets by taking 40%, 50%, and 60% respectively, of the original data as training sets.
3.5. Summarized Comprehensive Discussion
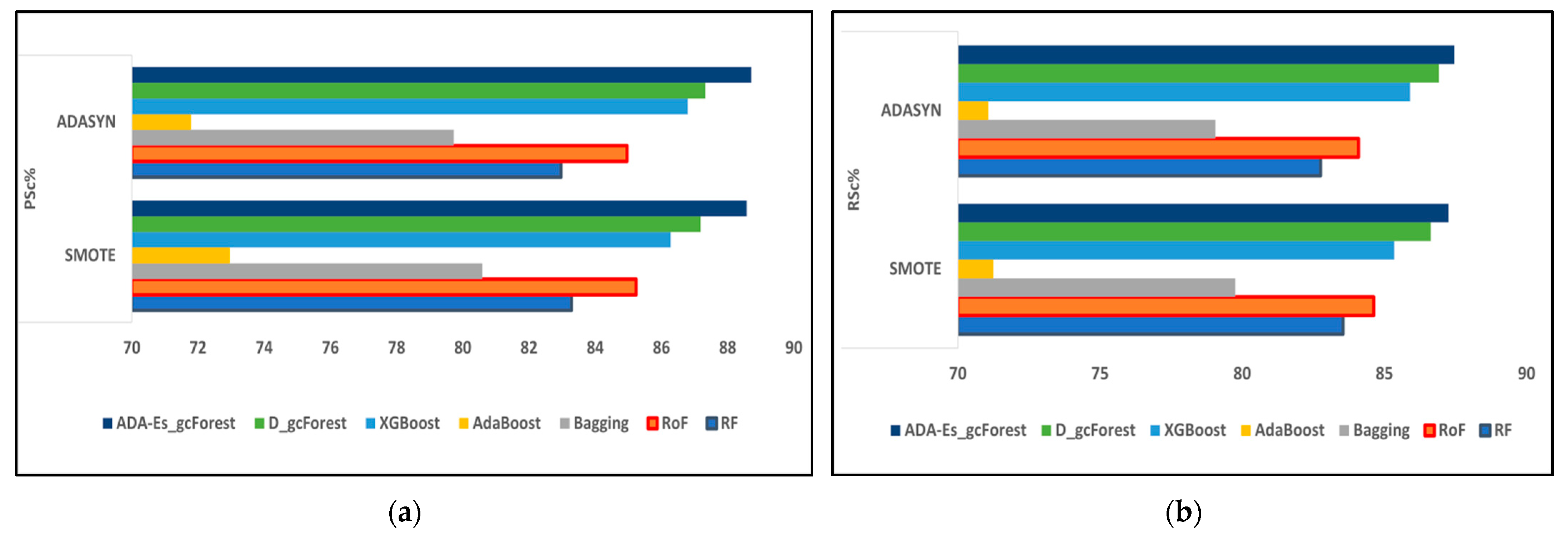
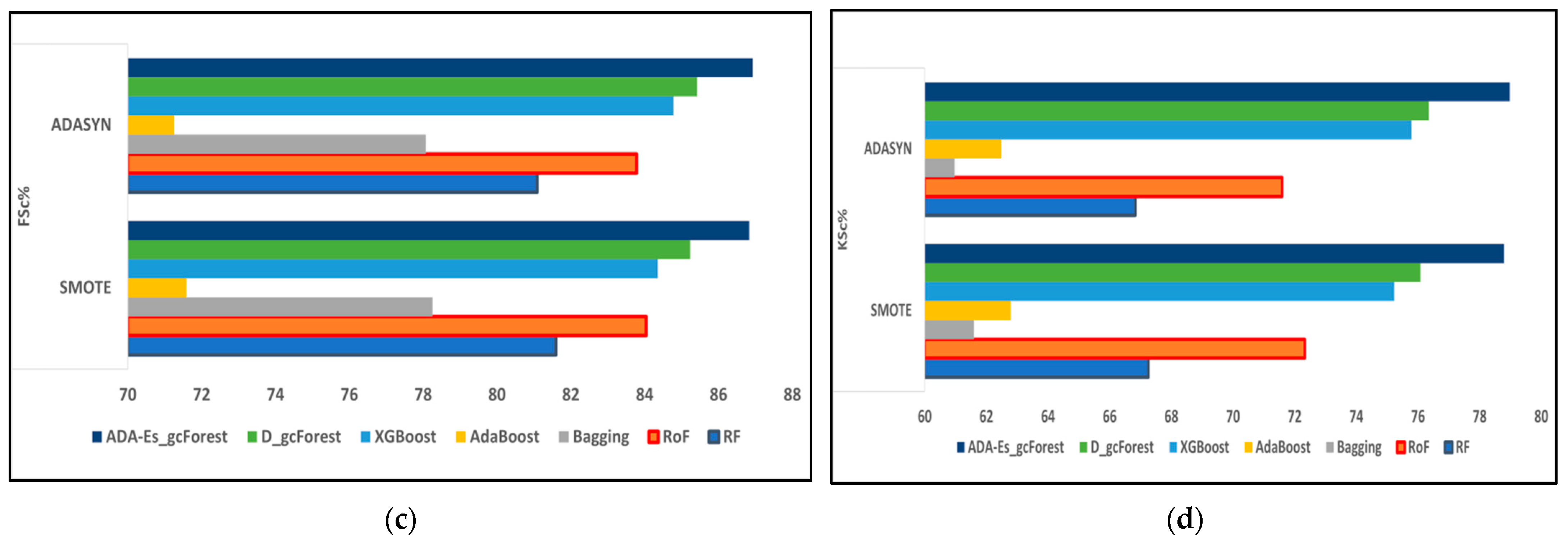
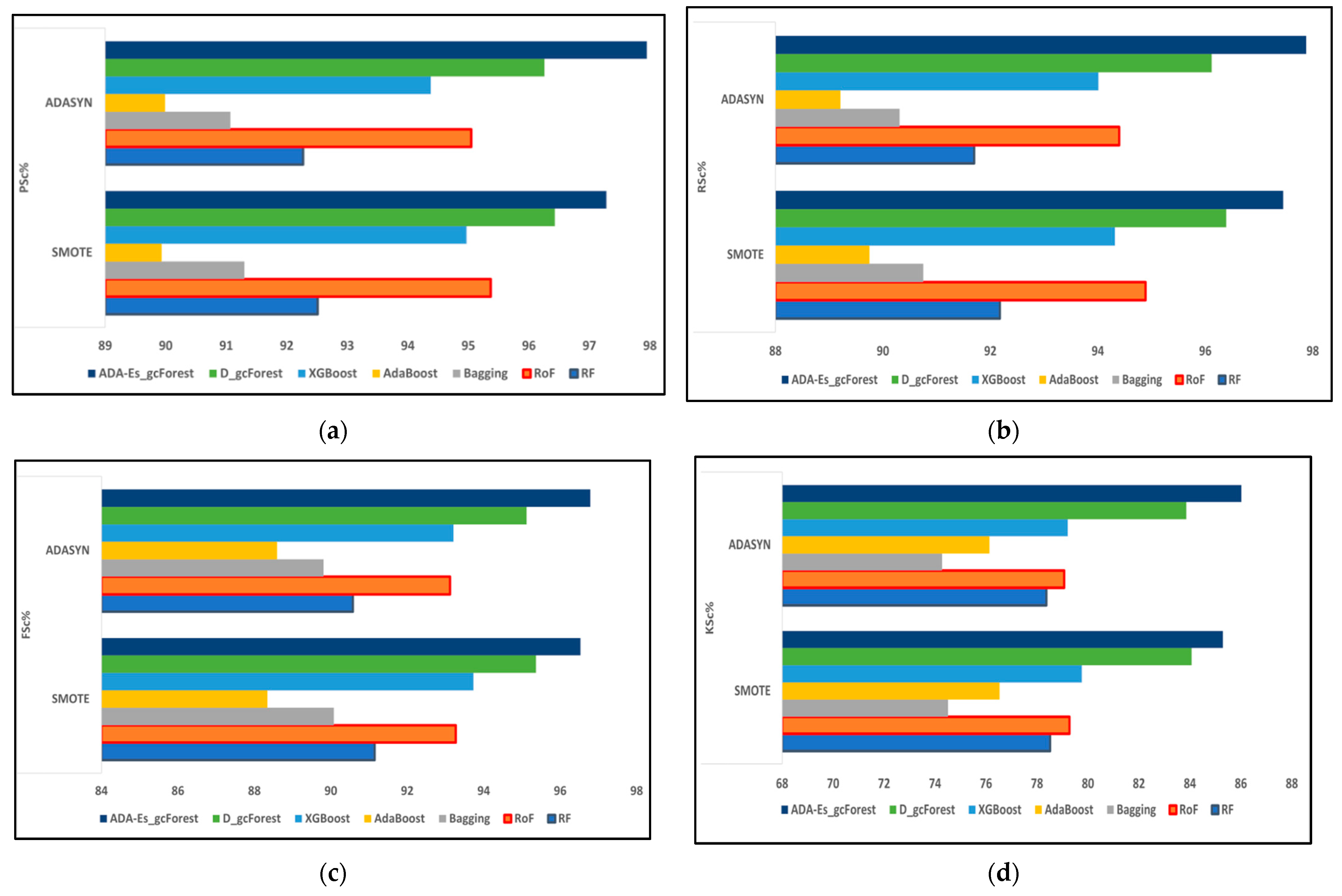
This study proposed a novel method of using ADASYN instead of the most frequently used SMOTE as the oversampling technique for the first time for HSI datasets. In addition, we enhanced the classic DgcForest that blends the DL ideology with the forest decision techniques. We also produced a novel comparative model using several efficient TECs by creating a similar environment for all of them to make a fair comparison. The total number of landcover pixels in each band of the IP, SV, and PU datasets were 10,249, 54,129, and 42,776, respectively. In addition, SV represents a valley scene, whereas the others represent urban sites. Certain inferences can be drawn from Table 8, Table 9, Table 10, Table 11, Table 12, Table 13, Table 14, Table 15 and Table 16 and Figure 9, Figure 10 and Figure 11, where the red and blue curves represent the ADASYN and SMOTE data for different assessment metrics. For all three datasets, it can be conjectured from Figure 9, Figure 10 and Figure 11 that all four performance metrics included in this study for assessment acquired the lowest data for the classifier AdaBoost. The best metrics were obtained by our model ADA-Es-gcForest, whereas the classifiers that obtained metrics close to our model were classic DgcForest, XGBoost, and RoF. From Figure 9, it can be seen that XGBoost outperformed RoF, but the reverse happened for the SV and PU datasets, as shown in Figure 10 and Figure 11. In addition, it can be inferred that ADASYN performed better than SMOTE for deep forests, i.e., DgcForest and enhanced DgcForest, but the opposite outcome was obtained for the other classifiers. The same scenario was acquired for the accuracy metrics, i.e., OA and AA, as shown in Table 8, Table 9, Table 10, Table 11, Table 12, Table 13, Table 14, Table 15 and Table 16. We used a restricted number of samples to train our model: As the count of testing samples increased, the metric assessment values lowered for all datasets and all the classifiers. The dataset IP had the lowest accuracy, i.e., 86.95% OA, among the three due to its low spectral resolution and less prominent features with 16 overlapping landcover classes and the highest imbalance ratio. Contrastively, SV had the most increased dimensions of them all, ensuring more embedded and discriminative spectral features with 16 non-overlapping landcover classes, the lowest imbalance ratio, and the least inter-class similarity that led to the highest accuracy values, i.e., 96.37% OA. The PU dataset had a moderate imbalance ratio and entrenched spectral features that obtained 92.09% OA. The TTE of the models was also affected by the dimensions of the datasets. The overall time consumed to train the model increased with the increment in the training set. The time complexities in the decreasing order for the datasets were SV > PU > IP and for the classifiers RoF > DgcForest > bagging > ADA-Es-gcForest > RF > XGBoost > AdaBoost.
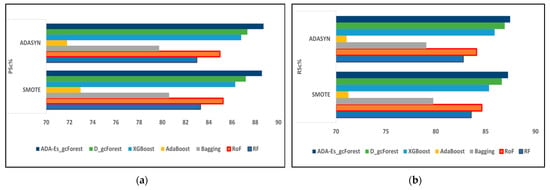
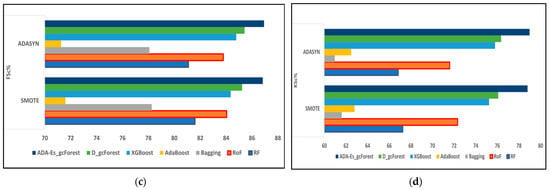
Figure 9.
The comparison of assessment metrics between the classifier models RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest for 40% IP test sets: (a) PSc%, (b) RSc%, (c) FSc%, and (d) KSc%.
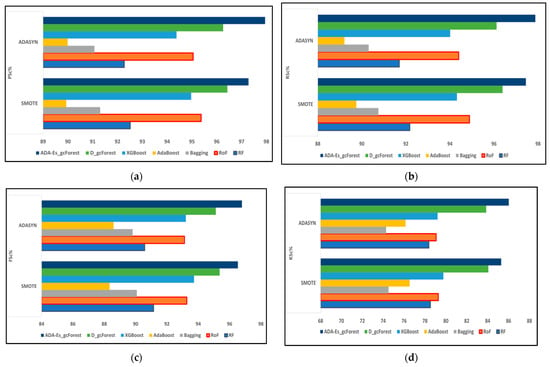
Figure 10.
The comparison of assessment metrics between the classifier models RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest for 40% SV test sets: (a) PSc%, (b) RSc%, (c) FSc%, and (d) KSc%.
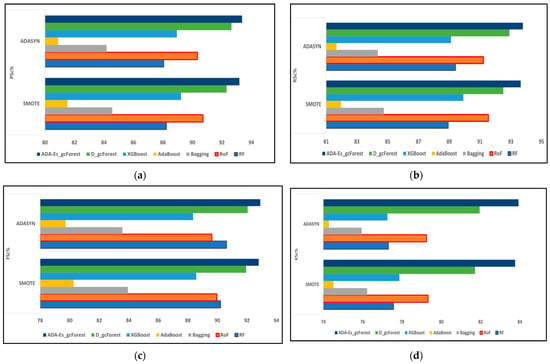
Figure 11.
The comparison of assessment metrics between the classifier models RF, RoF, bagging, AdaBoost, XGBoost, DgcForest, and our proposed model ADA-Es-gcForest for 40% PU test sets: (a) PSc%, (b) RSc%, (c) FSc%, and (d) KSc%.
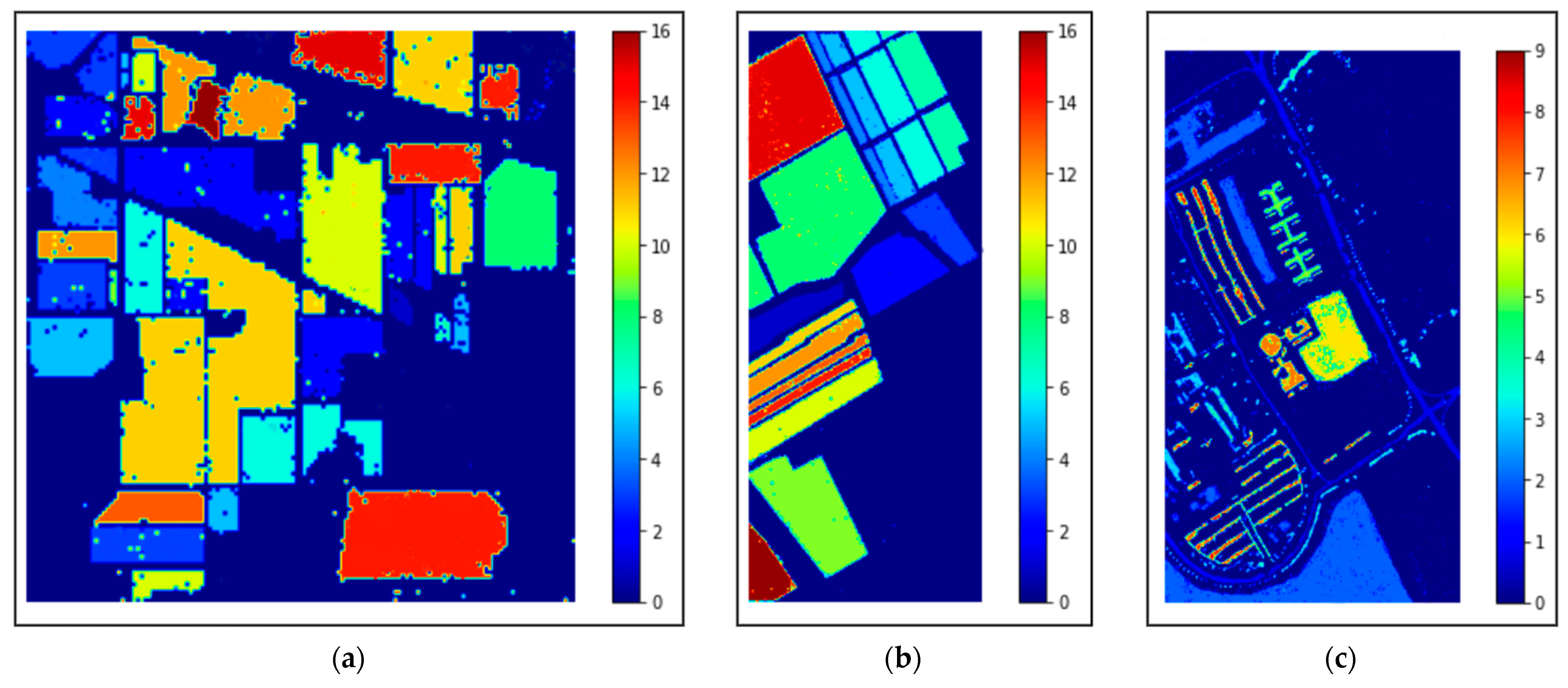
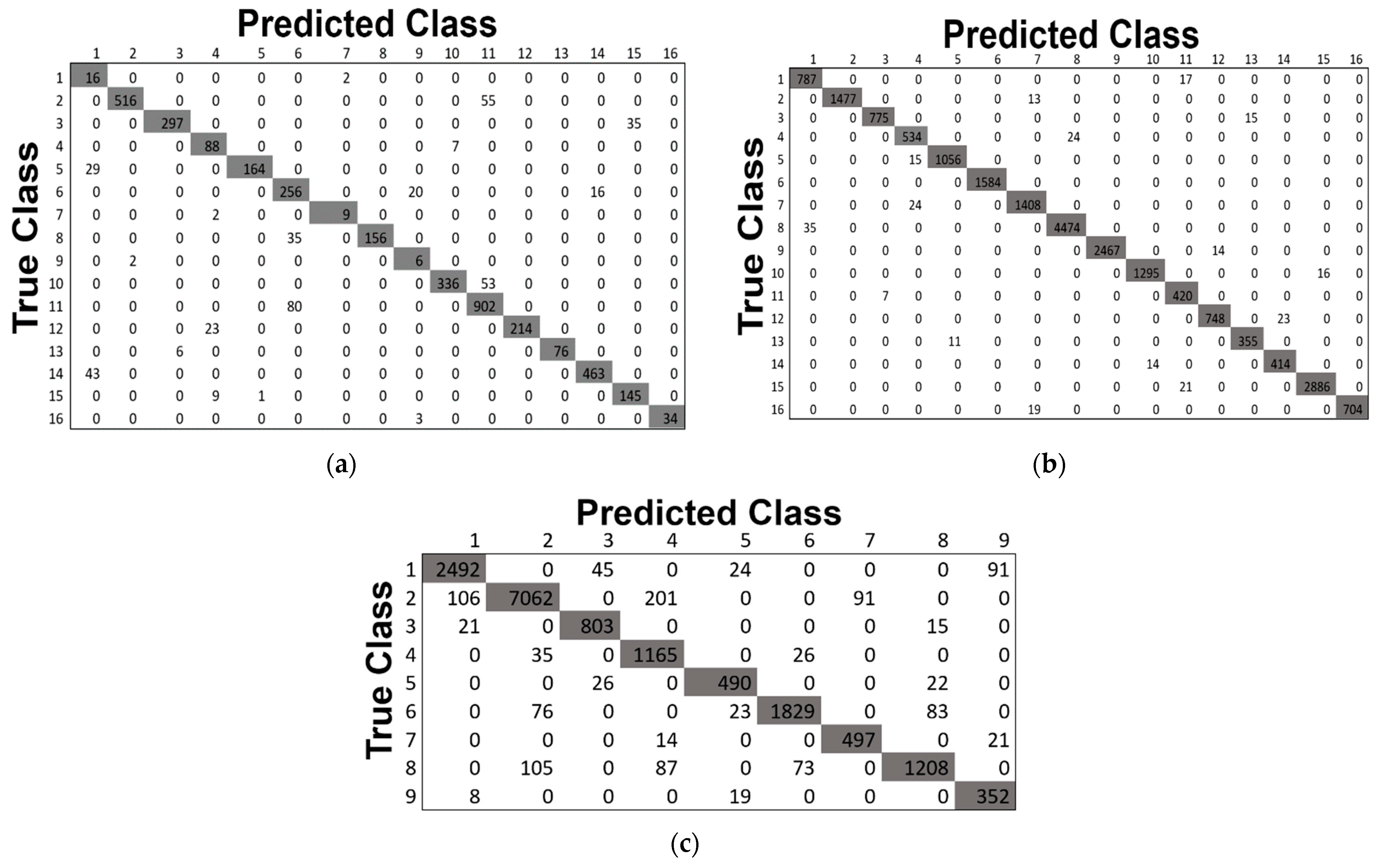
This study also includes the classification maps for the three datasets represented in Figure 12. The classification maps provided better visual comprehensibility to the readers/researchers about the classification accuracy, i.e., our proposed model’s correct prediction of each category in the HS scene. In addition, to those maps, the confusion matrices for the three 40% testing datasets obtained by our proposed method are depicted in Figure 13. The matrices provided better comprehensibility for OA% achieved by ADA-Es-gcForest and the classified sample scenario for each major and minor class for all the datasets. For example, Figure 13a shows that classes 9, 7, 1, and 16 were the classes of the IP dataset with fewer instances, but they remarkably obtained the ‘true positive’ values. On the other hand, the most major class instances, such as 11, 2, 14, etc., were also placed in the correct place in the matrix. The same scenario can be observed for the SV and PU datasets in Figure 13b,c, respectively.
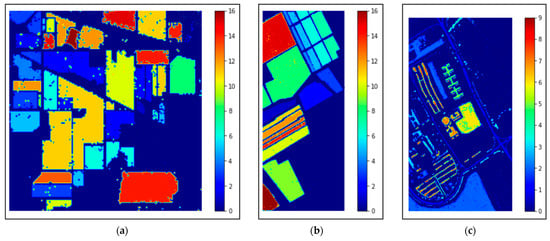
Figure 12.
The classification maps obtained by our proposed model ADA-Es-gcForest for the HSI datasets: (a) IP, (b) SV, and (c) PU.
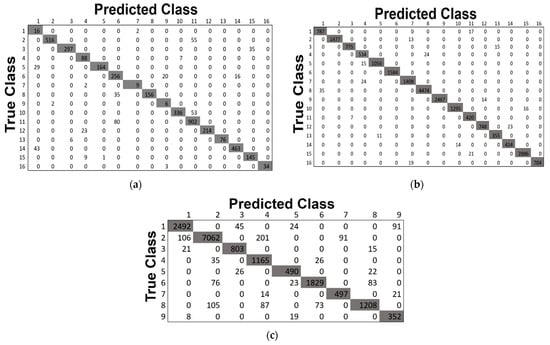
Figure 13.
The confusion matrices obtained by our proposed model ADA-Es-gcForest for the HSI datasets: (a) IP, (b) SV, and (c) PU.
4. Conclusions
The HS scenes contain different numbers of landcover classes leading to an imbalance between them. In this paper, we proposed a novel framework addressing three fundamental issues in high-dimensional HSI data analytics. First, PCA was applied as a preprocessing tool, reducing the high dimensionality caused by the burden of spectral channels. It also reduced the redundant features and selected the constructive and discriminative global spectral features from the original dataset. Second, the imbalance was removed using an improvised and adaptive version of ADASYN. Instead of using the whole dataset to create synthetic samples, we used similar pixel-wise subsampling where the ADASYN with a dynamic sampling ratio was enabled to create more accurate augmentation. Third, the multi-grained subsampling method reduced the redundant features and gained more accurate spatial–spectral information, lowering the feature dimension and highlighting the data’s representational potential. Finally, the processed data were given as the input to the enhanced deep CF, which perfectly blended the technological advancements of DL with decision-based forest classifiers. The Mg-sc deep CF considers the impact of previous forest classification, that is, the average values at each level, which reduced the dimensions of the input features at each level and kept the classification results’ feature information. Thus, the approach improved identification accuracy by increasing the function of information flow between different layers of the forest. We investigated the impact of the hyperparameters of our model on the classification results, finding that it was not hyperparameter-sensitive and outperformed previous tree-based HSI classification algorithms. The combination of PCA-ADASYN as the data preprocessors enhanced the overall performance of DgcForest. This combination is capable of utilizing the crucial spectral and spatial features in the datasets.
We deployed several parameters for various state-of-the-art ensemble tree-based classifiers to represent our proposed model’s classification performance advantage. In addition, we tested our model against different numbers of spectral features and the different counts of test samples while training our model with minimal data samples. We considered the time consumption of the model to be implemented and executed for each HS dataset to make it more robust and reliable than the classic DgcForest. Section 3 illustrates the overall achievement of our model aimed for HSI classification. For the 40% testing samples, the OA% and AA% were the highest for our model compared to others, i.e., 89.7% and 91.47% for IP, 98.76% and 97.54% for SV, and 92.19% and 94.19%, respectively. It achieved 2.69% and 2.52%, 2.52% and 2.27%, and 0.62% and 0.81% higher OA and AA, respectively, for IP, SV, and PU datasets compared to the classic DgcForest. The robustness of this technique allows it to be applied not only to other remote sensing images but also to various datasets with high-resolution imbalanced data issues.
Despite our method performing well in terms of performance metrics compared to other state-of-the-art methods on the HSI categorization, there is still a lot of research to be done in the future. Our work has certain limitations: (1) The work might not provide the optimal set of spatial–spectral features; (2) the features produced by Mg-sc were larger and redundant; (3) the hyperparameter tuning requires optimality; (4) the other recently introduced oversampling techniques are not used for comparison; (5) only TECs are considered for comparison; and (6) ablation experiments were not included. These limitations open up a broad space for additional research, which can be addressed in the future. Our proposed model can be further compared to other state-of-the-art DL techniques such as convolutional neural networks, deep belief networks, etc., and the other current approaches in oversampling such as borderline-SMOTE ADASYN-k-NN, etc. More information-enriched spectral features can be included, along with spatial features and information about the ablation to enhance the performance of our proposed model. In addition, we will use different dimension reduction, feature extraction, and classification techniques. Finally, we can analyze the hyperparameters to assign the classifier more optimally.
Author Contributions
Data collection, A.V.N.R. and M.A.A.A.-q.; Formal analysis, P.K.M., M.A.M. and A.S.A.; Funding acquisition, A.S.A.; Investigation, P.K.M. and M.M.J.; Methodology, D.D. and M.A.M.; Project administration, M.A.M.; Resources, M.M.J. and M.A.A.A.-q.; Supervision, P.K.M. and A.V.N.R.; Writing—original draft, D.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
We collected three mostly explored HS datasets available in the public domain [21] with significant applicability.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviation
| Acronym | Expanded Form | Acronym | Expanded Form |
| ADASYN | Adaptive Synthetic Minority Oversampling Technique | ML | Machine Learning |
| CF | Cascaded Forest | NB | Naïve Bayes |
| DgcForest | Deep Multi-Grained Cascade Forest | NN | Nearest Neighbor |
| DL | Deep Learning | PCA | Principal Component Analysis |
| HS | Hyperspectral | RF | Random Forest |
| HSI | Hyperspectral Image | RoF | Rotation Forest |
| IP | Indian Pines | SMOTE | Synthetic Minority Oversampling Technique |
| k-NN | k-Nearest Neighbor | SV | Salinas Valley |
| LR | Logistic Regression | SVM | Support Vector Machine |
| Mg-sc | Multi-Grained Scanning | TEC | Tree-Based Ensembled Classifiers |
| UP | University Of Pavia |
References
- Han, Y.; Li, J.; Zhang, Y.; Hong, Z.; Wang, J. Sea ice detection based on an improved similarity measurement method using hyperspectral data. Sensors 2017, 17, 1124. [Google Scholar] [CrossRef] [PubMed]
- Mahesh, S.; Jayas, D.S.; Paliwal, J.; White, N.D.G. Hyperspectral imaging to classify and monitor quality of agricultural materials. J. Stored Products Res. 2015, 61, 17–26. [Google Scholar] [CrossRef]
- Peerbhay, K.Y.; Mutanga, O.; Ismail, R. Random forests unsupervised classification: The detection and mapping of solanum mauritianum infestations in plantation forestry using hyperspectral data. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2015, 8, 3107–3122. [Google Scholar] [CrossRef]
- Acosta, I.C.C.; Khodadadzadeh, M.; Tusa, L.; Ghamisi, P.; Gloaguen, R. A machine learning framework for drill-core mineral mapping using hyperspectral and high-resolution mineralogical data fusion. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 4829–4842. [Google Scholar] [CrossRef]
- El-Sharkawy, Y.H.; Elbasuney, S. Hyperspectral imaging: A new prospective for remote recognition of explosive materials. Remote Sens. Appl. Soc. Environ. 2019, 13, 31–38. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. Deep learning classifiers for hyperspectral imaging: A review. ISPRS J. Photogramm. Remote Sens. 2019, 158, 279–317. [Google Scholar] [CrossRef]
- Signoroni, A.; Savardi, M.; Baronio, A.; Benini, S. Deep Learning Meets Hyperspectral Image Analysis: A Multidisciplinary Review. J. Imaging 2019, 5, 52. [Google Scholar] [CrossRef]
- Li, Y.; Guo, H.; Xiao, L.; Yanan, L.; Jinling, L. Adapted ensemble classification algorithm based on multiple classifier system and feature selection for classifying multi-class imbalanced data. Knowl.-Based Syst. 2016, 94, 88–104. [Google Scholar] [CrossRef]
- Madasamy, K.; Ramaswami, M. Data Imbalance and Classifiers: Impact and Solutions from a Big Data Perspective. Int. J. Comput. Intell. Res. 2017, 13, 2267–2281. [Google Scholar]
- Datta, D.; Mallick, P.K.; Shafi, J.; Choi, J.; Ijaz, M.F. Computational Intelligence for Observation and Monitoring: A Case Study of Imbalanced Hyperspectral Image Data Classification. Comput. Intell. Neurosci. 2022, 8735201, 23. [Google Scholar] [CrossRef]
- Satapathy, S.K.; Mishra, S.; Mallick, P.K.; Chae, G. ADASYN and ABC-optimized RBF convergence network for classification of electroencephalograph signal. Pers. Ubiquitous Comput. 2021, 1–17. [Google Scholar] [CrossRef]
- Alhudhaif, A. A novel multi-class imbalanced EEG signals classification based on the adaptive synthetic sampling (ADASYN) approach. PeerJ. Comput. Sci. 2021, 7, e523. [Google Scholar] [CrossRef]
- Khan, T.M.; Xu, S.; Khan, Z.G.; Uzair Chishti, M. Implementing Multilabeling, ADASYN, and ReliefF Techniques for Classification of Breast Cancer Diagnostic through Machine Learning: Efficient Computer-Aided Diagnostic System. J. Healthc. Eng. 2021, 5577636. [Google Scholar] [CrossRef]
- Datta, D.; Mallick, P.K.; Bhoi, A.K.; Ijaz, M.F.; Shafi, J.; Choi, J. Hyperspectral Image Classification: Potentials, Challenges, and Future Directions. Comput. Intell. Neurosci. 2022, 2022, 3854635. [Google Scholar] [CrossRef] [PubMed]
- Pathak, D.K.; Kalita, S.K.; Bhattacharya, D.K. Classification of Hyperspectral Image using Ensemble Learning methods:A comparative study. In Proceedings of the 2020 IEEE 17th India Council International Conference (INDICON), New Delhi, India, 10–13 December 2020; pp. 1–6. [Google Scholar]
- Zhou, Z.H.; Feng, J. Deep forest: Towards an alternative to deep neural networks. In Proceedings of the 26th International Conference on Artificial Intelligence and Statistics, Melbourne, Australia, 19–25 August 2017; pp. 3553–3559. [Google Scholar]
- Yin, X.; Wang, R.; Liu, X.; Cai, Y. Deep Forest-Based Classification of Hyperspectral Images. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 10367–10372. [Google Scholar]
- Cao, X.; Wen, L.; Ge, Y.; Zhao, J.; Jiao, L. Rotation-Based Deep Forest for Hyperspectral Imagery Classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1105–1109. [Google Scholar] [CrossRef]
- Liu, X.; Wang, R.; Cai, Z.; Cai, Y.; Yin, X. Deep Multigrained Cascade Forest for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8169–8183. [Google Scholar] [CrossRef]
- Liu, B.; Guo, W.; Chen, X.; Gao, K.; Zuo, X.; Wang, R.; Yu, A. Morphological Attribute Profile Cube and Deep Random Forest for Small Sample Classification of Hyperspectral Image. IEEE Access 2020, 8, 117096–117108. [Google Scholar] [CrossRef]
- Available online: http://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes#:~:text=Groundtruth%20classes%20for,93 (accessed on 15 February 2020).
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Xia, M.; Wang, Z.; Han, F.; Kang, Y. Enhanced Multi-Dimensional and Multi-Grained Cascade Forest for Cloud/Snow Recognition Using Multispectral Satellite Remote Sensing Imagery. IEEE Access 2021, 9, 131072–131086. [Google Scholar] [CrossRef]
- Gao, W.; Wai, R.-J.; Chen, S.-Q. Novel PV Fault Diagnoses via SAE and Improved Multi-Grained Cascade Forest with String Voltage and Currents Measures. IEEE Access 2020, 8, 133144–133160. [Google Scholar] [CrossRef]
- Wang, H.; Tang, Y.; Jia, Z.; Ye, F. Dense adaptive cascade forest: A self- adaptive deep ensemble for classification problems. Soft Comput 2020, 24, 2955–2968. [Google Scholar] [CrossRef]
- Fernández, A.; López, V.; Galar, M.; del Jesus, M.J.; Herrera, F. Analysing the classification of imbalanced datasets with multiple classes: Binarization techniques and ad-hoc approaches. Knowl. Based Syst. 2013, 42, 97–110. [Google Scholar] [CrossRef]
- Samanta, S.R.; Mallick, P.K.; Pattnaik, P.K.; Mohanty, J.R.; Polkowski, Z. (Eds.) Cognitive Computing for Risk Management; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Bhagat, R.C.; Patil, S.S. Enhanced SMOTE algorithm for classification of imbalanced big-data using Random Forest. In Proceedings of the 2015 IEEE International Advance Computing Conference (IACC), Bangalore, India, 12–13 June 2015; pp. 403–408. [Google Scholar]
- Mukherjee, A.; Singh, A.K.; Mallick, P.K.; Samanta, S.R. Portfolio Optimization for US-Based Equity Instruments Using Monte-Carlo Simulation. In Cognitive Informatics and Soft Computing. Lecture Notes in Networks and Systems; Mallick, P.K., Bhoi, A.K., Barsocchi, P., de Albuquerque, V.H.C., Eds.; Springer: Singapore, 2022; Volume 375. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).