



Cloud and Snow Identification Based on DeepLab V3+ and CRF Combined Model for GF-1 WFV Images
Abstract
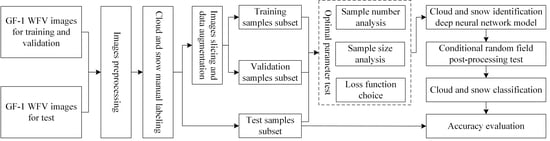
:
1. Introduction
2. Data and Methodology
2.1. GF-1 WFV Data
2.2. Sample Labeling
2.3. DeepLab V3+ Model
2.4. Loss Function
2.5. Conditional Random Field
2.6. Evaluation Indicators
2.7. Experimental Environment
3. Experiments and Results
3.1. Sample Number Analysis
3.2. Sample Size Analysis
3.3. Selection of Loss Function
3.4. Conditional Random Field Post-Processing
4. Discussion
5. Conclusions
- (1)
- The DeepLab v3+ model is used to identify cloud and snow in a GF-1 WFV image. When the number of samples is 10,000, the sample size is 256 × 256, and the loss function is the Focal function, the model has the optimal accuracy and strong stability, where the MIoU and the MPA reach 0.816 and 0.918, respectively.
- (2)
- For the cloud and snow identification, CRF post-processing can significantly improve the misclassification problems such as blurred boundaries, slicing traces and isolated small patches caused by the semantic segmentation of neural network model. Compared with the prediction maps without post-processing, the prediction accuracy after CRF post-processing is effectively improved. The MIoU and MPA are improved to 0.836 and 0.941, respectively, which proves the effectiveness of the post-processing method.
- (3)
- The DeepLab v3+ and CRF combined model for cloud and snow identification in a high-resolution remote sensing image has high accuracy and strong feasibility. The conclusions can provide a technical reference for the application of deep learning algorithms in high-resolution snow mapping and hydrological application.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shi, Y.; Cheng, G. The Cryosphere and Global Change. Bull. Chin. Acad. Sci. 1991, 4, 287–291. [Google Scholar] [CrossRef]
- Qin, D.; Zhou, B.; Xiao, C. Progress in studies of cryospheric changes and their impacts on climate of China. Acta Meteorol. Sin. 2014, 72, 869–879. [Google Scholar] [CrossRef]
- Yao, T.; Qin, D.; Shen, Y.; Zhao, L.; Wang, N.; Lu, A. Cryospheric changes and their impacts on regional water cycle and ecological conditions in the Qinghai-Tibetan Plateau. Chin. J. Nat. 2013, 35, 179–186. [Google Scholar]
- Wu, H. Research of Cloud and Snow Discrimination from Multispectral High-Resolution Satellite Images. Master’s Thesis, Wuhan University, Wuhan, China, 2018. [Google Scholar]
- Ying, Q.; Yang, Y.; Xu, W. Research on Distinguishing between Cloud and Snow with NOAA Images. Plateau Meteorol. 2002, 21, 526–528. [Google Scholar]
- Ding, H.; Ma, L.; Li, Z.; Tang, L. Automatic Identification of Cloud and Snow based on Fractal Dimension. Remote Sens. Technol. Appl. 2013, 28, 52–57. [Google Scholar]
- Joshi, P.P.; Wynne, R.H.; Thomas, V.A. Cloud detection algorithm using SVM with SWIR2 and tasseled cap applied to Landsat 8. Int. J. Appl. Earth Obs. Geoinf. 2019, 82, 101898. [Google Scholar] [CrossRef]
- Ghasemian, N.; Akhoondzadeh, M. Introducing two Random Forest based methods for cloud detection in remote sensing images. Adv. Space Res. 2018, 62, 288–303. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 55, 645–657. [Google Scholar] [CrossRef]
- Liu, W. Cloud and Snow Classification in Plateau Area Based on Deep Learning Algorithms. Master’s Thesis, Nanjing University of Information Science and Technology, Nanjing, China, 2019. [Google Scholar]
- Wang, J.; Li, J.; Zhou, H.; Zhang, X. Typical element extraction method of remote sensing image based on Deeplabv3+ and CRF. Comput. Eng. 2019, 45, 260–265, 271. [Google Scholar] [CrossRef]
- Guo, X.; Chen, Y.; Liu, X.; Zhao, Y. Extraction of snow cover from high-resolution remote sensing imagery using deep learning on a small dataset. Remote Sens. Lett. 2020, 11, 66–75. [Google Scholar] [CrossRef]
- Wang, Y.; Su, J.; Zhai, X.; Meng, F.; Liu, C. Snow Coverage Mapping by Learning from Sentinel-2 Satellite Multispectral Images via Machine Learning Algorithms. Remote Sens. 2022, 14, 782. [Google Scholar] [CrossRef]
- Zhang, G.; Gao, X.; Yang, Y.; Wang, M.; Ran, S. Controllably Deep Supervision and Multi-Scale Feature Fusion Network for Cloud and Snow Detection Based on Medium- and High-Resolution Imagery Dataset. Remote Sens. 2021, 13, 4805. [Google Scholar] [CrossRef]
- Nambiar, K.G.; Morgenshtern, V.I.; Hochreuther, P.; Seehaus, T.; Braun, M.H. A Self-Trained Model for Cloud, Shadow and Snow Detection in Sentinel-2 Images of Snow- and Ice-Covered Regions. Remote Sens. 2022, 14, 1825. [Google Scholar] [CrossRef]
- Park, J.; Shin, C.; Kim, C. PESSN: Precision Enhancement Method for Semantic Segmentation Network. In Proceedings of the 2019 IEEE International Conference on Big Data and Smart Computing (BigComp), Tokyo, Japan, 4 April 2019; pp. 1–4. [Google Scholar]
- Jeong, H.G.; Jeong, H.W.; Yoon, B.H.; Choi, K.S. Image Segmentation Algorithm for Semantic Segmentation with Sharp Boundaries using Image Processing and Deep Neural Network. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics—Asia (ICCE-Asia), Seoul, Korea, 1 November 2020; pp. 1–4. [Google Scholar]
- Sun, X.; Shi, A.; Huang, H.; Mayer, H. BAS4Net: Boundary-Aware Semi-Supervised Semantic Segmentation Network for Very High Resolution Remote Sensing Images. IEEE J. Sel. Top. in Appl. Earth Obs. Remote Sens. 2020, 13, 5398–5413. [Google Scholar] [CrossRef]
- Li, K. Semi-supervised Classification of Hyperspectral Images Combined with Convolutional Neural Network and Conditional Random Fields. Master’s Thesis, China University of Geosciences, Beijing, China, 2021. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schrof, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhu, Z.; Liu, C.; Yang, D.; Yuille, A.; Xu, D. V-NAS: Neural Architecture Search for Volumetric Medical Image Segmentation. In Proceedings of the 2019 IEEE International Conference on 3D Vision (3DV), Québec City, QC, Canada, 16–19 September 2019; pp. 240–248. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Lafferty, J.; Mccallum, A.; Pereira, F. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML ‘01), San Francisco, CA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. In Proceedings of the 24th International Conference on Neural Information Processing Systems (NIPS’11), Red Hook, NY, USA, 12–15 December 2011; pp. 109–117. [Google Scholar]
- Alberto, G.G.; Sergio, O.E.; Sergiu, O.; Victor, V.M.; Jose, G.R. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Jing, Z.W.; Guan, H.Y.; Peng, D.F.; Yu, Y.T. Survey of Research in Image Semantic Segmentation Based on Deep Neural Network. Comput. Eng. 2020, 46, 1–17. [Google Scholar] [CrossRef]
- Tian, X.; Wang, L.; Ding, Q. Review of image semantic segmentation based on deep learning. J. Softw. 2019, 30, 440–468. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Meng, J.; Zhang, L.; Cao, Y.; Zhang, L.; Song, Q. Research on optimization of image semantic segmentation algorithms based on Deeplab v3+. Laser Optoelectron. Prog. 2022, 59, 161–170. [Google Scholar]
- Yan, Q.; Liu, H.; Zhang, J.; Sun, X.; Xiong, W.; Zou, M.; Xia, Y.; Xun, L. Cloud Detection of Remote Sensing Image Based on Multi-Scale Data and Dual-Channel Attention Mechanism. Remote Sens. 2022, 14, 3710. [Google Scholar] [CrossRef]
- Zhao, W.; Li, M.; Wu, C.; Zhou, W.; Chu, G. Identifying Urban Functional Regions from High-Resolution Satellite Images Using a Context-Aware Segmentation Network. Remote Sens. 2022, 14, 3996. [Google Scholar] [CrossRef]
- Wieland, M.; Li, Y.; Martinis, S. Multi-sensor cloud and cloud shadow segmentation with a convolutional neural network. Remote Sens. Environ. 2019, 230, 111203. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B.B. Fmask 4.0: Improved cloud and cloud shadow detection in Landsats 4–8 and Sentinel-2 imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]
- Zhu, Q.; Li, Z.; Zhang, Y.; Li, J.; Du, Y.; Guan, Q.; Li, D. Global-Local-Aware conditional random fields based building extraction for high spatial resolution remote sensing images. Natl. Remote Sens. Bull. 2021, 25, 1422–1433. [Google Scholar]
- He, Q.; Zhao, L.; Kuang, G. SAR airport runway extraction method based on semantic segmentation model and conditional random field. Mod. Radar. 2021, 43, 91–100. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Band | Band Range (μm) | Radiometric Resolution (Bit) | Spatial Resolution (m) |
|---|---|---|---|---|
| Wide Field View (WFV) | 1 | 0.45~0.52 | 10 | 16 |
| 2 | 0.52~0.59 | |||
| 3 | 0.63~0.69 | |||
| 4 | 0.77~0.89 |
| Number | Sensor | Scene Serial Number | Imaging Time | Remarks |
|---|---|---|---|---|
| 1 | WFV1 | 6013180 | 22 January 2019 | Model training and validation images |
| 2 | WFV3 | 8348146 | 31 October 2020 | |
| 3 | WFV4 | 6252997 | 29 March 2019 | |
| 4 | WFV3 | 5848541 | 8 December 2018 | |
| 5 | WFV4 | 5416209 | 16 August 2018 | |
| 6 | WFV3 | 7050682 | 5 November 2019 | |
| 7 | WFV2 | 8155402 | 16 September 2020 | |
| 8 | WFV1 | 4330375 | 13 November 2017 | Model test images |
| 9 | WFV3 | 6658981 | 18 July 2019 | |
| 10 | WFV1 | 4314475 | 9 November 2017 |
| Sample Number | Snow IoU | Cloud IoU | MIoU | Snow PA | Cloud PA | MPA |
|---|---|---|---|---|---|---|
| 2000 | 0.761 | 0.647 | 0.756 | 0.827 | 0.760 | 0.845 |
| 5000 | 0.766 | 0.619 | 0.750 | 0.808 | 0.810 | 0.857 |
| 10,000 | 0.804 | 0.757 | 0.816 | 0.891 | 0.934 | 0.918 |
| Sample Size | Snow IoU | Cloud IoU | MIoU | Snow PA | Cloud PA | MPA |
|---|---|---|---|---|---|---|
| 64 × 64 | 0.761 | 0.630 | 0.754 | 0.866 | 0.795 | 0.862 |
| 128 × 128 | 0.764 | 0.599 | 0.748 | 0.877 | 0.691 | 0.838 |
| 256 × 256 | 0.804 | 0.757 | 0.816 | 0.891 | 0.934 | 0.918 |
| Loss Function | Snow IoU | Cloud IoU | MIoU | Snow PA | Cloud PA | MPA |
|---|---|---|---|---|---|---|
| CE | 0.759 | 0.595 | 0.741 | 0.846 | 0.683 | 0.827 |
| Dice | 0.777 | 0.763 | 0.803 | 0.845 | 0.917 | 0.899 |
| Focal | 0.805 | 0.757 | 0.816 | 0.891 | 0.934 | 0.918 |
| Model | Snow IoU | Cloud IoU | MIoU | Snow PA | Cloud PA | MPA |
|---|---|---|---|---|---|---|
| DeepLab v3+ | 0.805 | 0.757 | 0.816 | 0.891 | 0.934 | 0.918 |
| DeepLab v3+ and CRF | 0.829 | 0.787 | 0.836 | 0.890 | 0.997 | 0.941 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Fan, B.; Tu, Z.; Li, H.; Chen, D. Cloud and Snow Identification Based on DeepLab V3+ and CRF Combined Model for GF-1 WFV Images. Remote Sens. 2022, 14, 4880. https://doi.org/10.3390/rs14194880
Wang Z, Fan B, Tu Z, Li H, Chen D. Cloud and Snow Identification Based on DeepLab V3+ and CRF Combined Model for GF-1 WFV Images. Remote Sensing. 2022; 14(19):4880. https://doi.org/10.3390/rs14194880
Chicago/Turabian StyleWang, Zuo, Boyang Fan, Zhengyang Tu, Hu Li, and Donghua Chen. 2022. "Cloud and Snow Identification Based on DeepLab V3+ and CRF Combined Model for GF-1 WFV Images" Remote Sensing 14, no. 19: 4880. https://doi.org/10.3390/rs14194880