1. Introduction
With the flourish of space exploration, the number of resident space objects (RSOs) orbiting the Earth is rapidly increasing, as is the possibility of collision. Initial orbit determination (IOD), which uses limited observations to characterize the orbital motion, can give a preliminary estimate of the state as the foundation for subsequent operations, thus gaining great attention from the astrodynamic community. In practice, measurements of ever-increasing RSOs are produced by surveillance systems with mixed and limited capabilities, which often result in very short arcs (VSAs). On the other hand, the optical sky survey campaign, the primary data source for RSOs, only generates a series of observation angles and their epoch times as input to the IOD process. When only VSAs consisting of angle observations are available, the too short arcs (TSAs) problem [
1], of which the measurement cannot provide enough information for a complete orbit determination, appears, which makes excellent challenges to position solutions and their accuracy of RSOs.
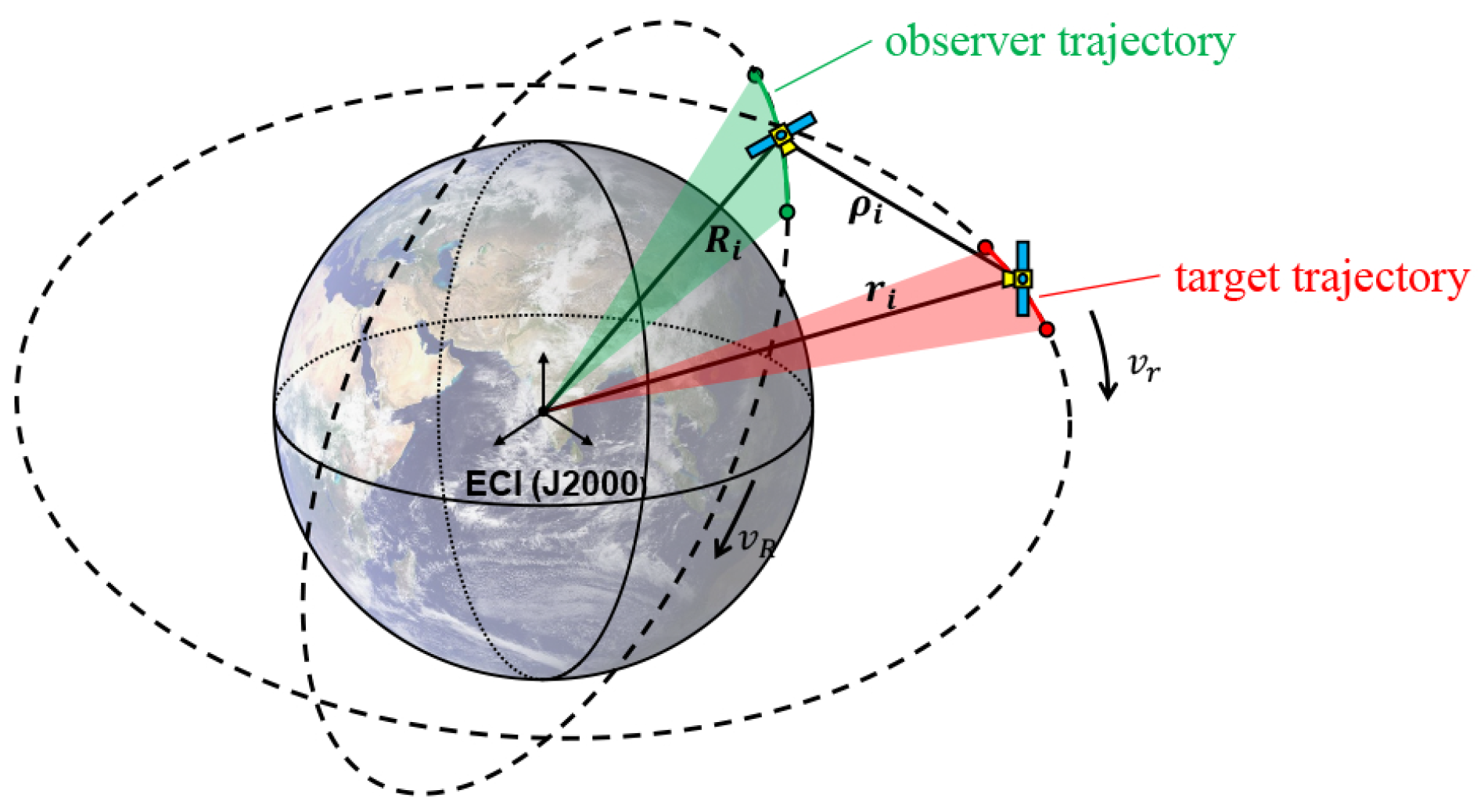
Recently, the passive optical sensors deployed on space platforms have become a promising alternative for space tracking as it eliminates the restrictions on weather and terrain compared with the ground-based telescope. Space platforms have shorter distances to targets than ground facilities, and the apparent angular velocity from the observer to the target may be higher. Therefore, the space-based optical measurement is a typical scenario of too short arcs and has been chosen as the focus of this paper.
Initial orbit determination from optical measurements, otherwise known as angle-only IOD, is built upon two-body dynamics. Previous approaches tackled the IOD problem in different ways, mainly falling into two categories: direct methods and iterative-based techniques [
2]. Given the geometric relations and fundamental dynamical assumptions, the direct methods construct and solve polynomial equations to obtain feasible orbits. With three-angle observations, Laplace and Gauss [
3] achieved the estimation for the orbits of natural celestial bodies. Together with their work, a number of articles detailing the theory and application of these two methods have been published. Rather than using the Lagrange’ formula for the line-of-sight (LOS) vector and its derivative as the classical Laplace’s method, Ref. [
4] chose higher order unit sphere-constrained interpolation to build the terms of polynomial equations and achieved significant performance improvements. In addition, based on Charlier’s theory, [
5,
6] provides a geometric interpretation of the occurrence of multiple solutions in direct methods, which is useful to understand when there are multiple solutions and where they are located. With the advent of the space age, computer-based algorithms with iterative nature have been developed. Iterative algorithms make guesses on some dynamic terms and have them modified by an iterative process. When the residual between the propagated measurements and the actual ones approaches zero, an orbit solution is obtained. The double-r method, proposed in [
3], iterates around estimates of the magnitudes of the radius vectors, while Gooding’s algorithm [
7] implements its iteration based on slant ranges of two measurement epochs. Recently, three techniques of
,
[
8], and
[
9] are also proven to be candidates for the iterative IOD methods. Many reviews and comparisons of these classical methods are made [
2,
10]. It shows that every method has its scope of application, but there are cases that do not perform particularly well under any IOD approach.
Moreover, to deal with the problem of TSAs, there are some works that have been proposed recently. One of the most valuable methods is the one based on the constrained admissible region (AR). Milani et al. [
1,
11] introduced the attributable, containing all the significant information in short arc measurements, and constrained all the possible orbit solutions on a (
) compact subset, known as the admissible region. Motivated by this significant contribution, Tommei [
12] first used the admissible region, a definition of heliocentric astronomy, to address the track association problem of space debris orbiting the Earth and then perform a full orbit determination based on the associated data. DeMars [
13] developed a probabilistic approach based on an admissible region to ensure the inspiring accuracy of IOD, only with the angle rate information added. Furthermore, considering the uncertainty on the solution within the admissible region, Pirovano [
14] refers to the multiple orbits that comply with the TSA observations as an orbit set (OS), and combines two or more OSs to determine a common solution [
14]. On the other hand, the method based on the conservation laws of Kepler’s problem has recently been investigated by Gronchi et al. for the computation of preliminary orbits. The authors derived algebraic equations using the first integrals of Kepler’s motion, and developed the elimination step based elementary calculations, resulting in a univariate polynomial equation of degree 9 in the radial distance [
15,
16,
17,
18]. The Kepler Integral (KI) method has been tested with both synthetic and real data of asteroids and can enable the linkage of VSAs even when they are separated in time by a few years [
19].
Evolutionary algorithms (EAs) are a class of population-based heuristic search approaches that have been successfully applied in many engineering fields to solve various optimization problems [
20,
21]. Recently, because of its ease of implementation and guaranteed convergency, some researchers have also introduced evolutionary algorithms to solve IOD problems. Ansalone [
22] is the first one using an evolutionary algorithm to deal with the TSA problem. Using slant distances of two observation times as optimization variables, the author performed orbit determination for every guess in the framework of the Lambert problem. The simulation experiment on space-based observation of 60 s arcs achieved superior performance. Following this, Hinagawa[
23] transferred the technique to the IOD of geostationary satellites based on true observation from the ground telescope, further verifying the effectiveness of EA-based IOD. In addition, there exist studies of directly using orbital elements as optimization variables [
24]. This approach avoids the Lambert solver’s computation consumption that Ansalone used.
The solving process of EAs is essentially an iterative searching process within the parameter space. Individuals in the parameter space are mapped to the fitness space by a cost function and then guided to evolve to a better location based on the information feedback from the fitness landscape. Thus, the implemented optimization method and the understanding of the fitness space are the keys to a good result. Due to the sparsity of observations and noise interference, the IOD optimization problem may have more than one best solution and hence is a multimodal problem, which is ignored by current works. In this paper, we introduce an improved differential evolution (DE) algorithm to solve the IOD problem from the perspective of multimodal optimization. The main contribution of this paper is as follows:
- 1.
In this paper, based on the analysis of IOD parameter space, a multimodal optimization strategy for IOD is proposed for the first time to enhance the success rate and the accuracy of the IOD solution;
- 2.
A multimodal differential evolution with niching, convergence detection, and archiving strategy, termed as DE-NBA, is proposed in this paper. Considering the importance of evolution state for the computational resource allocation, a convergence detector based on the Boltzmann Entropy is designed as a component of the DE-NBA;
- 3.
The proposed method in this paper achieves competitive performance in 20 problems of the CEC2013 multimodal competition, against 11 common algorithms, which verifies its ability for a multimodal problem;
- 4.
Three space-based scenarios of a 60 s short arc observation are simulated to test the proposed multimodal algorithm for initial orbit determination. With 100 Monte Carlo experiments, the proposed algorithm is compared with the classical Gauss method, the single-mode DE, and the recent multimodal FBK-DE. The results show the applicability and accuracy of our method. Moreover, performance tests under different noise levels are conducted to estimate the availability of the proposed IOD method in practice.
The rest of this paper is organized as follows:
Section 2 introduces the formulations of the EA-based IOD, and illustrates the multimodal phenomenon of IOD optimization problems. The developed DE-NBA is described component-by-component in
Section 3. Two experiment cases and their results are presented in
Section 4. The discussion and conclusions are shown in
Section 5 and
Section 6, respectively.
3. Proposed Method
Motivated by the multimodal phenomena of the IOD problem of space-based measurement, this paper introduces an improved differential evolution algorithm with multimodal characteristics to solve the TSA challenge. Three functional components are implemented in the following sections, including the basic differential evolution driver, a coarse-to-fine niching strategy, and a convergence detector based on Boltzmann entropy.
3.1. Differential Evolution
Differential evolution (DE) is a powerful searching method for solving optimization problems over continuous space, which is widely used in a variety of engineering application. As a classical single-modal evolutionary algorithm, DE tries to evolve the population toward the optimum with the greedy strategy. Its implementation mainly includes four parts:
Initialization. Given the lower bound,
, and upper bound,
, of the individual, the initial population, size of
, are randomly sampled in the parameter space according to a uniform distribution,
:
where
represents the
j th dimensional value of the
i th individual at
g th generation; subscripts
i and
j are in the range
and
, where
D represents the dimension of the problem.
Mutation. The original DE generates offspring individuals by adding weighted reference vectors, made of the difference between two individuals, to a third.
where the subscripts
and
are randomly picked from {
}∖{
i} and mutually exclusive; the scale factor
F weights the contribution of the difference vectors to control the mutation step.
Crossover. After mutation, DE generally exchanges some components from
and
to form a trial vector
, which is the binomial crossover operation:
where
represents the crossover rate, which is usually set to a fixed value lying in the range
;
is the dimension index, randomly selected from {
} to make sure that there must be one dimension where the value comes from
.
Selection. The selection operator is utilized to choose the best individual from
and
into the next generation. It is given as follows:
where
represents the fitness function of the optimization problem.
In addition, given the changing fitness landscape in different problems and evolving stages, the adaptive adjustment strategy [
26] of
F and
is utilized in the optimization progress, shown in Equation (
9).
F and
are sampled from Gaussian distribution and Cauchy distribution, respectively. In addition, they are updated by maintaining a historical memory for successful
F and
, that is, every time the offspring generated by
and
has better fitness than its paired solution, the
and
will be recorded into
and
, respectively, shown in Equation (
10):
where
represents the percentage of fitness improvement obtained by
ith successful mutation to all fitness improvements.
Multimodal evolutionary algorithms with superior performance must find as many optima as possible in each iteration while keeping them evolving. Combining the above components, how to modify the DE for multimodal search capabilities becomes the focus in this paper. Following the works of the niching technique [
27] and the convergence detection [
28,
29], we design two strategies to enhance the DE for solving the multimodal problem, which are described in
Section 3.2 and
Section 3.3.
3.2. Two-Layer Niching Method
Multimodal evolutionary algorithms seek to simultaneously locate and maintain a large number of global optima, which is heavily dependent on the population diversity. Niching techniques are one of the most widely used multimodal strategies, mainly including
fitness sharing,
crowding,
speciation,
clearing [
30,
31], and
clustering [
32]. Based on these niching techniques, recent DE variants (such as the
CDE [
33],
SDE [
34],
NCDE, and
NSDE [
35]) have shown excellent performance in multimodal problems. Notably, many niching methods need to adjust parameters for various problems, and it has become a significant barrier in their application [
27].
The Nearest-Better Clustering (NBC) [
36] is a niching method that divides the population to form species that evolve simultaneously. It only needs one scalar parameter to control the sizes of various species, thus becoming popular in solving multimodal problems [
37]. However, the traditional NBC cannot handle it well when the distribution of optima in the parameter space is uneven, that is, the distances between peaks vary greatly. Individuals who belong to different peak regions may be assigned to the same species. In this section, we propose a strategy of two-layer nearest-better clustering (TLNBC) to distinguish all peak regions and reasonably allocate resources to those areas, and its implementation is given in Algorithm
Section 3.2.
| Algorithm 1 Two-layer nearest-better-clustering with minimize size (TLNBC) |
| Input: Population: P; Minimal number of individuals in various species: minsize; Scalar factor: , . |
| Output: Species: S. |
| 1: Divide P using the big : . |
| 2: Set individuals better than others in the same species as seeds, . |
| 3: Perform local search around . |
| 4: Set the number of all individuals as N. |
| 5: Set the number of species as |
| 6: Calculate a modest capacity of species: |
| 7: for each species in do |
| 8: |
| 9: if then |
| 10: Discard the worst individuals in by fitness value. |
| 11: else |
| 12: Sample individuals by and add them to . |
| 13: end if |
| 14: end for |
| 15: if ( then |
| 16: Select () species randomly, adding one individual to each species. |
| 17: end if |
| 18: Divide the updated P using the small : . |
In detail, in order to obtain a discriminative clustering on peak regions, we perform NBC procedure twice. A coarse clustering is first performed in the population using a big scalar factor to determine the major peak regions. The size of the resulting species would be large, which may make different peaks overlap within the same species. The local optima in species are regarded as seeds of those areas. One local search [
38] on the seeds is then performed to advance their dominance. Then, the size deformation (Lines 7–14) is made to balance the computation resources allocated to different peak regions, which enables the vast majority of potential regions to continue their exploration when some individuals enter a prematurely convergent state. Finally, the second mNBC is performed to obtain the highly recognizable peak species.
The primary component of TLNBC adopts the mNBC, an NBC variant proposed in [
39], to identify the basin attraction. It enforces a constraint on the minimal number of individuals in species so that it enables basic mutation within every peak region. Algorithm 2 presents the details of the mNBC: the
controls the size of the resulting species adaptively, and the
minsize gives the lower bound of number for species individual.
| Algorithm 2 Nearest-better clustering with minsize [39] |
| Input: Population: P; Minimal number of individuals in various species: minsize; Scalar factor: . |
| Output: Species: S. |
| 1: Sort P by the fitness value in descending order. |
| 2: Calculate the distances between each pair of individuals. |
| 3: Create an empty tree T. |
| 4: for each individual in P do |
| 5: Obtain the individual set in which each element is better than . |
| 6: Find the nearest individual in to , termed . |
| 7: Create an edge between and and add it to T. |
| 8: end for |
| 9: Calculate the mean distance of all edges in T, termed . |
| 10: for each in T do |
| 11: if then |
| 12: Set to the subtree rooted at the follower individual of . |
| 13: Set to the subtree containing the follower individual of . |
| 14: if the node number of is more than minsizethe node number of is still more than minsize after is cut then |
| 15: Cut off . |
| 16: end if |
| 17: end if |
| 18: end for |
| 19: S ← All independent subtrees that do not share edges with others.
|
3.3. Convergence Detection Based on Boltzmann Entropy
The multimodal algorithm seeks to locate and preserve as many optima as possible. Due to the asynchronous development levels in the different subregions of the fitness space, some high-potential individuals around one peak would be attracted to premature ones, resulting in the omission of optima in some subregions. A useful scheme is to divide the evolution into exploration and exploitation stages based on the behavior of the evolving population. In the exploration stage, the individuals tend to exchange information between niches to find more feasible regions. In the exploitation stage, the subregions focus on the inner-niches refinement to build more precise solutions. A strategy to distinguish evolving status is the convergence detection.
A good detector can efficiently identify the occurrence of the potential niches, both in any parameter and fitness space. This section proposes a convergence detection strategy based on the Boltzmann Entropy [
40,
41,
42]. The traditional detector would respond to the convergence happening in the parameter or fitness space independently; one intuitive idea is whether one convergence indicator can simultaneously reflect parameter and fitness space changes. Algorithm 3 gives a procedure to implement coarse-to-fine convergence detection over all parameter dimensions.
| Algorithm 3 Convergence detection for the population in the domain of distance and fitness |
| Input: Population: P; Scalar factor:; Threshold: . |
| Output: Convergence flag: Go. |
| 1: Create a historical record of BE value, S. |
| 2: |
| 3: while not reach the max generation do |
| 4: Construct a slice set of the heatmap based on the individual distribution in P using . |
| 5: Calculate the absolute Boltzmann Entropy and add it to S. |
| 6: = mean(last elements of S), = mean(last elements of S). |
| 7: if then |
| 8: |
| 9: end if |
| 10: end while |
First, a slice set of the heatmap is built based on the individual distribution in the dimensions of parameter and fitness. The distance and fitness value domain is divided into a block diagram by the scalar parameter
. The number of individuals falling into blocks becomes the pixel value of the heatmap, which is shown in
Figure 4.
It is apparent that controls the resolution of the ith heatmap in the slice set and accordingly decides the sensitivity of the convergence criterion. At the early evolving stage, individuals at most dimensions are random, we set the with initial value , which is the square root of the numbers of the population; and the increases two as soon as the convergence is detected in the i th heatmap.
Second, a hierarchy-based approach [
42] is adopted to compute the Boltzmann Entropy (
) of those heatmaps for identifying the evolution stage of the population. The original BE calculation is expressed through two notions, namely macrostate and microstate. By determining the number of possible microstates (
W) corresponding to the same macrostate, the BE value can be calculated with the following equation:
where
is the Boltzmann constant (
J/K).
In [
40,
42], Gao et al. regard the abstract representation of an image as the macrostate, and all the possible images satisfying the patterns of the macrostate mask as the microstate. As shown in
Figure 5, a hierarchical downsampling repeats until the image degenerates to a pixel. With the constraints on the minimum, maximum and mean for the underlying patch, every aggregated pixel in the
nth level (macrostate unit) corresponds to
microstates, and total
will be obtained in this level. By an inverse image reconstruction from the highest level to the lowest, we can obtain different relative BE value (
) using Equation (
11), and the absolute BE value (
) equals the sum of all
.
Finally, a convergence criterion is set based on the change of resulting Boltzmann Entropy: after fixed generations for exploration in every evolving round, if the mean of in the last continuous two duration fluctuates within a limited range, it can be judged that convergence has been detected.
3.4. DE-NBA
Algorithm 4 shows the proposed DE algorithm, termed DE-NBA, based on the niching strategy, convergence detector, and a trick of external archive. The algorithm starts with the initialization of population. Due to the distribution of the first generation population is random, the algorithm divides the individuals into multiple species by the mNBC with a large scalar factor,
. Then, a niche-level optimization strategy proposed in [
26] is implemented in the DE-NBA. It decides whether the recombination occurs within the same niche or between the species by the probability
, shown in Equation (
13). In each population optimization, the individual with high-potential tends to exploit while the low potential individual is possible to explore:
where
represents the average fitness in
i th species,
represents the fitness of the seed of
i th species, and
is the potential value of the current species, indicating the diversity of the corresponding subpopulation.
and
represent the minimum and maximum potential value among all species; the resulting
is the probability that decides whether the recombination occurs within the same species or between different species.
Once the convergence state is detected, the TLNBC performs coarse-to-fine niching and makes the optimized seeds archived. The archive, as the supporting individuals, will merge with the basis population into next evolution. Finally, the archive individuals will perform a local search to improve their accuracy. The whole computation resources are divided into two parts, one for the global optimization and another for the local search: the percentage is 7:3.
| Algorithm 4 The Proposed DE-NBA |
| Input: P, , , , , , , , , , . |
| Output:A. |
| 1: Initiate the population P. |
| 2: 0.5, 0.5. |
| 3: A ← []. |
| 4: S ← mNBC(P, minsize, ). |
| 5: 1. |
| 6: while numEval < maxLS do |
| 7: P ← DE(P, A, , ). |
| 8: Calculate the Boltzmann entropy and add it to the history record . |
| 9: if mod(g,20)==0 then |
| 10: if The convergence is detected then |
| 11: S ← TLNBC(P, minsize, ). |
| 12: Select the seeds among S into A. |
| 13: if nums(A)> then |
| 14: Drop out the oldest (nums(A)>) elements in A. |
| 15: end if |
| 16: end if |
| 17: end if |
| 18: . |
| 19: end while |
| 20: while numEval < maxFES do |
| 21: A ← NelderMead(A). |
| 22: end while |
5. Discussion
In
Section 4, two experiments are designed to assess the performance of the proposed algorithm. The first experiment is conducted to evaluate the performance of the proposed multimodal evolution algorithm on the CEC2013 multimodal benchmark problems. The results are described in
Section 4.1. The second experiment is designed to assess the accuracy and applicability of the IOD method which employs the proposed multimodal evolution algorithm as the core component. The test results are shown in
Section 4.2. In this section, the two experimental results are discussed.
5.1. Competition Analysis of CEC 2013
Finding and maintaining global or local solutions as much as possible in the evolutionary process is a key step in an efficient multimodal optimization algorithm, and the SR and PR are usually used as evaluation criteria in the experiments. On the CEC2013 multimodal optimization competition, the performance of DE-NBA ranks third in 20 optimization problems; the first is FBK-DE, and the second is MOMMOP.
It is worth noting that the DE-NBA finds all the peaks on optimization problems F1–F6 and F10, and locates almost all the peak regions in problems F7–F10. Compared with FBK-DE, the PR improvement of DE-NBA is up to 0.1 in F7, F8, and F9, which proves the peak discrimination ability of the proposed TLNBC. In the low-dimensional composition problems F11–F15, the performance of DE-NBA outperforms MOMMOP on these problems, and ranks first on F12 and F15, while it is worse than FBK-DE on the other three problems. For the high-dimensional composition problems F16–F20, the performance of DE-NBA is becoming worse as the dimension improves, the global optimal solution cannot be efficiently found on the 20D problem F20 and the 10D problems F18 and F19, demonstrating that the DE-NBA has disadvantages in dealing with high dimension problems.
In summary, the performance of DE-NBA outperforms other state-of-the-art algorithms on average (DE-NBA: 0.9158; FBK-DE: 0.9082; MOMMOP: 0.9071) in terms of the low-dimensional problems F1–F15. While the IOD problem is corresponding to a 3D optimization problem in practical applications, the DE-NBA therefore has significant application potential in IOD problems.
5.2. Simulation Analysis of Space-Based Short Arc IOD
In order to verify the performance of the DE-NBA on the space-based short arc IOD, three typical space-based short arc observation scenarios (including LEO-LEO, LEO-MEO, and LEO-GEO) are simulated. With the deviation of the semi-major axis as the performance criteria in experiments, the proposed algorithm is compared against the Gauss method, the DE algorithm with single-modal, and the multimodal FBK-DE algorithm under the simulated data. All approaches are run 100 times for statistical comparison.
Figure 7 presents the IOD performance of each algorithm in these three different observation scenarios. It can be seen that the Gauss method cannot obtain effective solutions in the LEO-LEO and LEO-MEO scenario but obtain the best results in the LEO-GEO scenario, which is consistent with the conclusion that the Gauss method is suitable for the case of planetary observation. On the other hand, the EA-based IOD methods obtain effective solutions in all three scenarios. Specifically, under the threshold of 0.01, the proposed DE-NBA has a success percentage of over 0.6 on all conditions and achieves its best result of 0.99 in the LEO-GEO, which proves the applicability of DE-NBC in orbiting application. The accuracy of Gauss’ method under the LEO-GEO is at the level of
, while that of the DE-NBA is at the level of
, which implies that there is much improvement space for our approach.
Regarding the success percentage results, DE obtains a score of 0.61, 0.10, and 0.88 in the LEO-LEO, LEO-MEO, and LEO-GEO, respectively, FBK-DE obtains 1, 0, 0.34, while DE-NBA obtains 0.68, 0.60, 0.99. The performance of the single-modal DE and the multimodal FBK-DE is unstable. In the visualization of the orbit element distributions, the semi-major axis distributions of FBK-DE in both LEO-LEO and LEO-MEO are very concentrated, but the lines of the corresponding true value in
Figure 8 and
Figure 9 both fall beyond its range. It implies that the FBK-DE may have located the major convex regions in the fitness landscape but have not completely exploited the local peak areas, which emphasizes the importance of the capability of locating precise peaks and full exploitation. Moreover, the statistical results on the mean, medium, and the best solution show that the DE-NBA becomes closest to the true value, further verifying its superiority in solving the IOD problem to the DE and the FBK-DE.
The performance test experiment in different noise levels is conducted to evaluate the robustness of the proposed approach in practice.
Figure 11 shows that the algorithm performance decreases as the noise increases until it fails after reaching a specific limit. To be specific, the DE-NBA can work under the noise level of
in LEO-LEO,
in LEO-MEO, and
in LEO-GEO.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}