1. Introduction
Over the past few years, deep neural networks have achieved state-of-the-art performance in computer vision [
1,
2,
3,
4], natural language processing [
5,
6,
7], reinforcement learning [
8,
9,
10], and various other fields [
11,
12,
13]. However, with the increasing depth, as well as the width of the network, for example from the shallow LeNet to the wider Inception structure in GoogLeNet and deeper Resnet convolutional architecture, as well as the currently popular transformer architecture, the number of parameters of the deep model is constantly growing, which in turn, leads to a series of problems such as the redundancy of network parameters, more rigorous hardware requirements, and difficulty in training the model, and large deep models severely limit their applications in low-memory or high-real-time conditions. In recent years, the research [
14,
15] to develop faster and smaller models based on the idea of knowledge distillation to solve the above problems has been developing rapidly. In the traditional knowledge-distillation-based model compression methods [
16,
17,
18,
19], the smaller student network is typically guided by a larger teacher network. The primary purpose is to enable the student network to achieve competitive and even superior task performance by learning the prior knowledge of the teacher network. The key to achieving this goal is mainly related to two aspects: on the one hand, how to design the network structure of the teacher–student model; on the other hand, how to transfer important features from the large-sized teacher model to the small-sized student model in a more efficient way.
We observed the following phenomenon when performing model optimization with the standard knowledge distillation methodology:
I. When we trained a small-sized student network independently, it was usually more difficult to find the ideal model parameters to meet the relevant task requirements.
II. Compared with training a small-sized student network independently, when a large-sized teacher network was trained independently, although better task performance can be gained, the model parameters of the teacher network were not optimal due to the presence of a significant amount of parameter redundancy in the teacher network.
III. When jointly training teacher–student models, the parameter redundancy present in the teacher model was usually detrimental to the optimization of the student model, which may have a negative effect on the optimization of the student model.
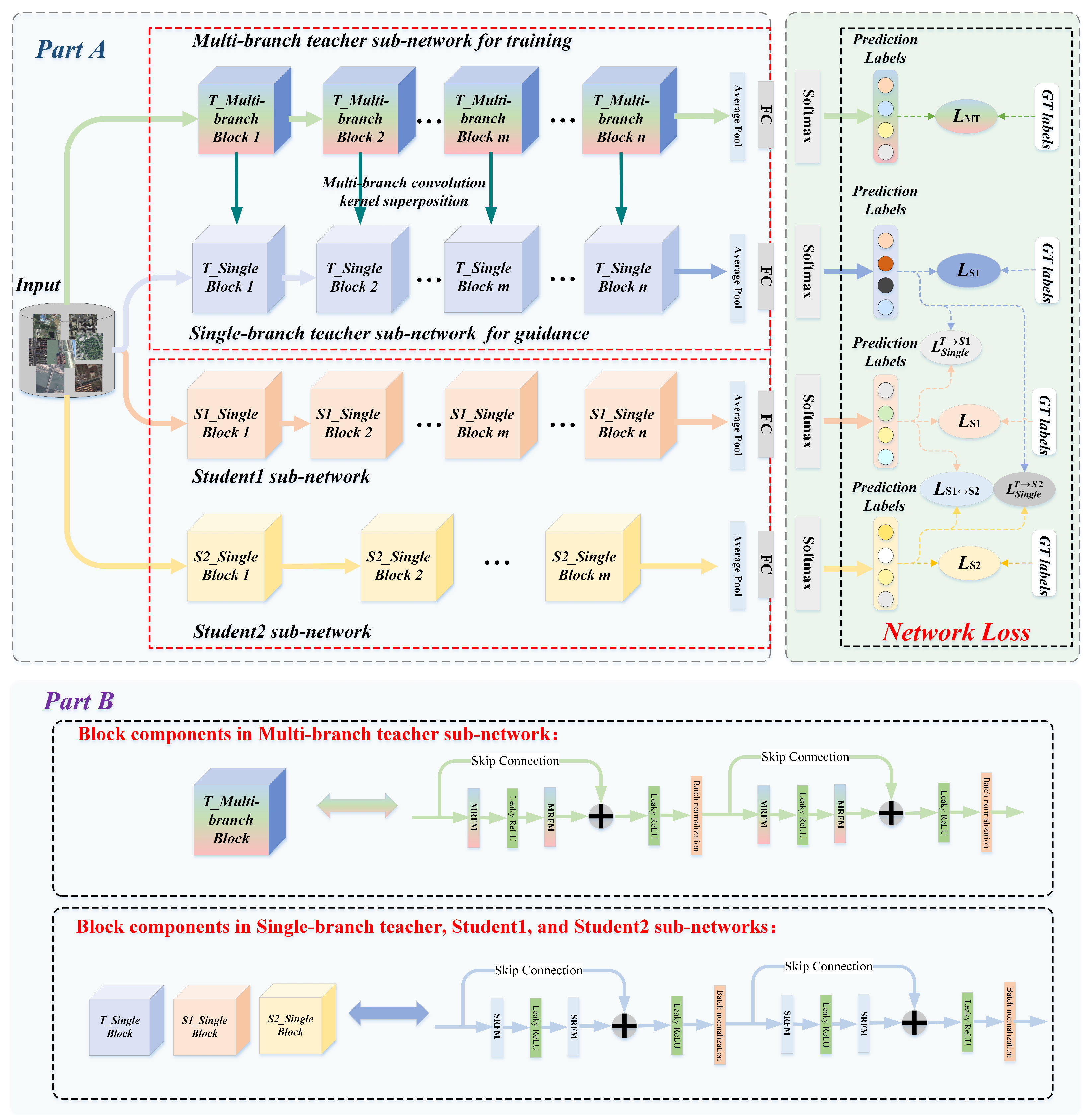
In this paper, considering that current high-precision remote sensing image classification models require high-performance hardware devices, which are difficult to deploy on embedded devices with low performance, our goal was to solve the parameter redundancy problem in the teacher–student model and obtain a small deep neural network with powerful feature extraction capabilities that can be easily deployed on lower-performance hardware devices and meet the accuracy requirements for remote sensing image classification. To address these issues, we propose a collaborative consistency knowledge distillation framework.
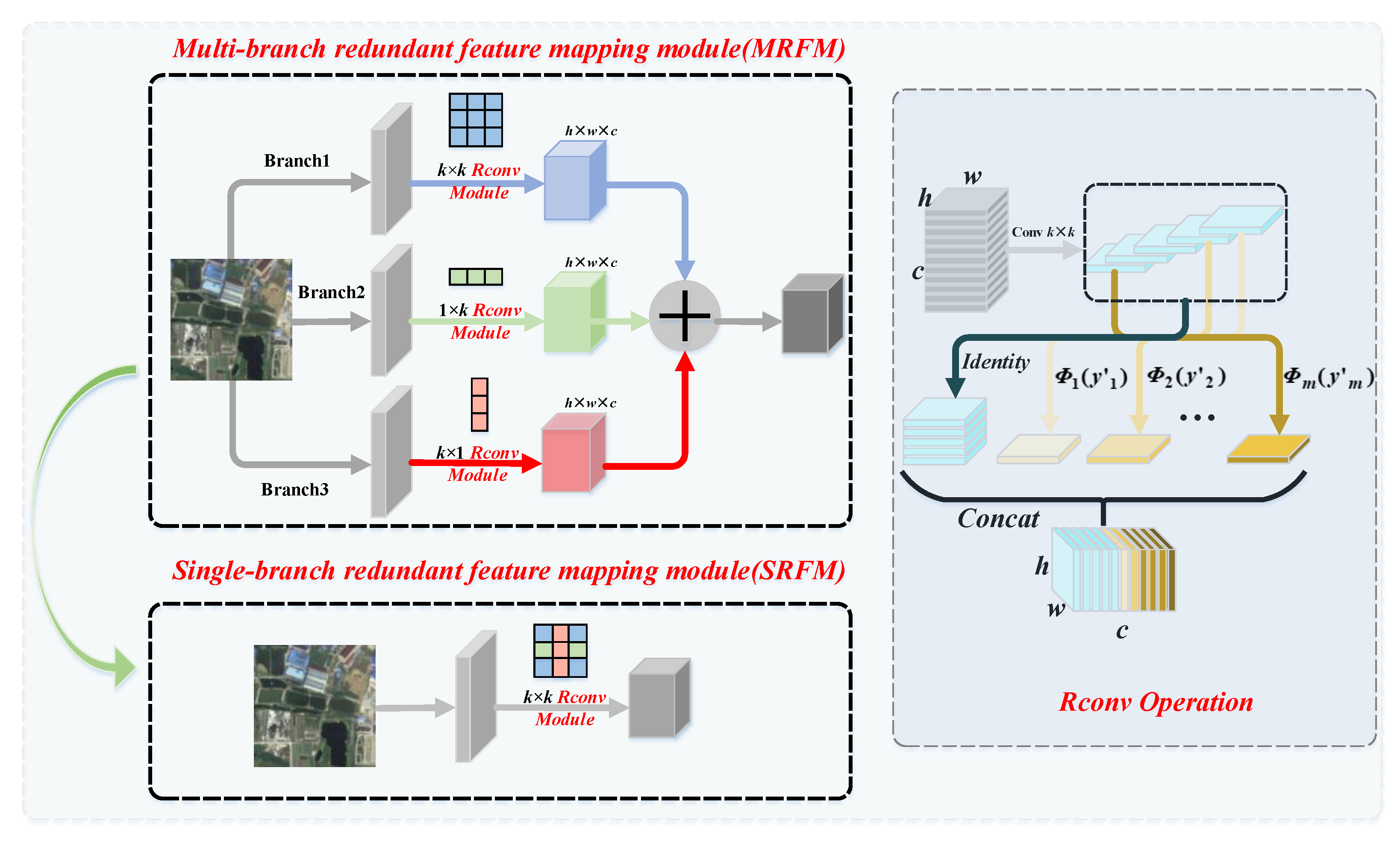
Firstly, different from the previous convolutional neural networks, a plug-and-play redundant feature mapping module was designed for the redundant parameters in the teacher–student model. Specifically, this module contains both multi-branch feature extraction and fusion components, as well as redundant mapping convolution components. On the one hand, we can obtain an equivalent convolution kernel with stronger feature extraction capability with multi-branch feature extraction and fusion and utilize this equivalent convolution kernel to extract richer task-related high-level semantic information. On the other hand, the redundant mapping convolution component was used to generate the intrinsic feature maps of the inputs, and the redundant feature maps were further obtained by a series of low-cost linear operations, which greatly reduced the redundant parameters of the network.
Secondly, our CKD framework starts with a powerful and pre-trained teacher network and performs a one-way prior knowledge transfer to two untrained student sub-networks of different depths. In addition, for both student sub-networks, we propose that the student sub-networks not only absorb prior knowledge derived from the teacher, but also extract high-level semantic features that the other possesses via mutual supervised learning. The experimental results showed that the student sub-networks obtained by training in this way have better task-relevant model parameters.
In summary, our contributions are summarized as follows:
- ⏵
To reduce the parameter redundancy of remote sensing image classification models and facilitate their deployment on embedded devices with low performance, we propose a plug-and-play multi-branch fused redundant feature mapping module. The equivalent convolutional kernel obtained by this module has a more powerful feature extraction capability and can more effectively optimize the parameter redundancy of the network.
- ⏵
We propose a collaborative consistent knowledge distillation framework to obtain a more robust backbone network. In contrast to the traditional knowledge distillation framework, we guided a pair of student sub-networks of different depths through a teacher model, where the student sub-networks not only learn prior knowledge deriving from the teacher network, but also acquire prior knowledge possessed by them by the way of mutual supervised learning.
- ⏵
The experimental results on two benchmark datasets (SIRI-WHU, NWPU-RESISC45) showed that our approach provided a significant improvement over a series of existing depth models and the state-of-the-art knowledge distillation networks on the relevant remote sensing image scene classification task. In addition, the student sub-network obtained based on the CKD framework had a more powerful feature extraction capability, as well as a lower number of parameters, which can be widely used as a feature extraction network in various embedded devices.
4. Experimentation and Results Discussion
In this section, we perform several sets of comparative experiments and rigorously analyze the experimental results of the CKD framework on NWPU-RESISC45 [
44] and SIRI-WHU [
45].
4.1. Datasets
NWPU-RESISC45: The NWPU-RESISC45 dataset contains a total of 45 remote sensing scenes, and each scene consists of 700 images with a size of 256 × 256 pixels. The NWPU-RESISC45 dataset exhibits rich variation in appearance, spatial resolution, illumination, background, and occlusion.
SIRI-WHU: The SIRI-WHU dataset is composed of 12 categories of remote sensing scene images, with a total of 2400 images, and each category consists of 200 images with a size of 200 × 200 pixels. The data were obtained from Google Earth and mainly cover urban areas in China.
4.2. Implementation Details
We developed our proposed collaborative consistent distillation framework based on Pytorch and conducted the related experiments with 6 NVIDIA GeForce GTX 3080Ti GPUs. In our experiments, we used the Adam optimizer [
46] to optimize the parameters of the network, setting the initial learning rate to 0.01, the momentum factor to 0.9, the weight decay rate to
, and the batch size to 256. The model was trained for a total of 300 epochs, and the learning rate decreased to 1/10 of the previous learning rate for each 60 epoch iteration.
Since the fully connected layer in the convolutional neural network restricts the input image size, therefore it is necessary to pre-process the images in the dataset when the relevant model is trained on the NWPU-RESISC45 and SIRI-WHU datasets. For the training set, firstly, the input images based on NWPU-RESISC45 dataset were randomly cropped to after mirror filling to standardize the size of the input images. It is worth noting that for the remote sensing image size in the SIRI-WHU dataset, we still kept . Secondly, in order to enrich the training set and improve the generalization ability of the model, a simple random left–right flip operation was performed on the training set. Finally, the images were processed by normalization. For the testing set, the input images were center cropped, and the size was set to , which unified the size of the input image between the training set and the testing set. Similarly, the normalization operation was performed on the testing set images.
4.3. Comparison of Remote Sensing Image Scene Classification Methods on SIRI-WHU and NWPU-RESISC45 Datasets
To evaluate the remote sensing image scene classification performance of the CKD student sub-networks, the network model was compared with other deep learning models based on the SIRI-WHU and NWPU-RESISC45 datasets. The average classification accuracy in the experiments and a series of other evaluation metrics are shown in
Table 1. The CKD student sub-networks proposed in this paper had the highest classification accuracy of 0.916 for the NWPU-RESISC45 dataset and 0.943 for the SIRI-WHU dataset.
4.4. Comparison with the State-of-the-Art Knowledge Distillation Methods on the NWPU-RESISC45 and SIRI-WHU Datasets
To more comprehensively evaluate our CKD framework, we also compared CKD with recent state-of-the art knowledge distillation methods reported on the SIRI-WHU and NWPU-RESISC45 datasets in
Table 2 and
Table 3. We used two baselines to evaluate the classification performance of our CKD-RPO framework. Specifically, the first type of baseline employs a series of offline distillation methods, including KD [
19], FN [
32], AE-KD [
33], LKD [
31], RKD [
29], and CRD [
30]. The second kind of the baseline is the online knowledge distillation methods, which were DML [
35], ONE [
34], DCM [
36], and PCL [
37].
The experimental results are reported in
Table 2, where the best results are marked in bold. Experimental results on the SIRI-WHU and NWPU-RESISC45 datasets showed that the proposed CKD achieved the best performance not only on offline distillation methods, but also on online knowledge distillation methods compared to other state-of-the-art methods. It also demonstrates that our CKD was capable of enhancing classification tasks. Despite the fact that the experimental setup in these references varied slightly, it appears that our strategy outperformed previous state-of-the-art methods.
When using the larger student sub-network the Resnet110, as shown in
Table 3, we performed relevant comparison experiments on the SIRI-WHU and NWPU-RESISC45 datasets in order to further evaluate the performance of the CKD framework by the top-1 accuracy. We can obviously observe that our model exhibited significant advantages against the state-of-the-art methods. With the CKD framework, Resnet110 continued to be able to achieve an appreciable performance improvement for classification tasks.
4.5. Comparison of the Number of Parameters among CKD Student Sub-Networks and Resnet Networks
The parameters’ variability between different student sub-networks in the CKD framework for the backbone networks Resnet20, Rconv_Res20, Resnet32, Rconv_Res32, Resent 56, Rconv_Res56, Resnet110, and Rconv_Res110 is compared in this section. The number of parameters of different student sub-networks is shown in
Table 4.
From
Table 4, we can find that the Rconv_Res-series student sub-networks maintained comparatively fewer parameters. As the depth of the network deepened, the number of parameters in the Resnet-series student sub-networks increased more significantly compared to the Rconv_Res-series student sub-networks. This also demonstrates that the redundancy parameters of the Resnet-series student sub-networks increased dramatically with the increasing depth of the student sub-networks. In contrast, the Rconv_Res-series student sub-networks in the CKD framework were able to effectively eliminate redundant parameters.
4.6. Ablation Experimental
4.6.1. The Performance of the Student Sub-Networks with Different Depths in CKD Based on the SIRI-WHU Dataset
The backbone networks that we employed in our experiments included typical student-level backbone networks: Resnet20 [
47], Resnet32, Resnet56, and Resnet110 and large-scale backbone networks at the teacher level: Resnet110 and Densenet121 [
48].
Table 5 compares the top-1 accuracy [
49] on the SIRI-WHU dataset obtained by various architectures under the two-student sub-network condition. We can observe the following conclusions from
Table 5:
- (1)
For Student Sub-networks 1 and 2, the collaborative consistency distillation algorithm (CKD) significantly improved the classification accuracy of each student sub-network, and the gain values indicate the gains of each student sub-network.
- (2)
Although Rconv_Res110 is a much larger backbone network than Rconv_Res32, it still benefited from being trained with a smaller student sub-network.
- (3)
The smaller student sub-networks can usually gain more from the collaborative consistency distillation algorithm.
4.6.2. The Effectiveness of Each Component in the Redundant Feature Mapping Operation
To more comprehensively evaluate our CKD framework, we conducted ablation studies to analyze the correlation between different components in the redundant feature mapping operation. The redundant feature mapping operation of the CKD framework mainly involves three components: Rconv module, MRFM, and SRFM. To investigate the impact of each component on the redundancy mapping module on the CKD framework, based on Resnet, we set a series of student sub-networks of different depths and their corresponding variants and compared the performance between the student sub-networks of different depths and the corresponding variants.
Resnet: A series of image classification models was constructed based on Resnet20, Resnet32, Resnet56, and Resnet110.
Resnet with Rconv module: Only the Rconv module was applied to a series of image classification models.
Resnet with MRFM: A series of classification models was reconstructed based on the MRFM module to predict the categories of remote sensing image scenes in the SIRI-WHU and NWPU-RESISC45 datasets.
Resnet with SRFM: First, we obtained the SRFM module through the MRFM module. Then, based on the SRFM module, a series of classification models was redesigned to predict the categories of remote sensing image scenes in the SIRI-WHU and NWPU-RESISC45 datasets.
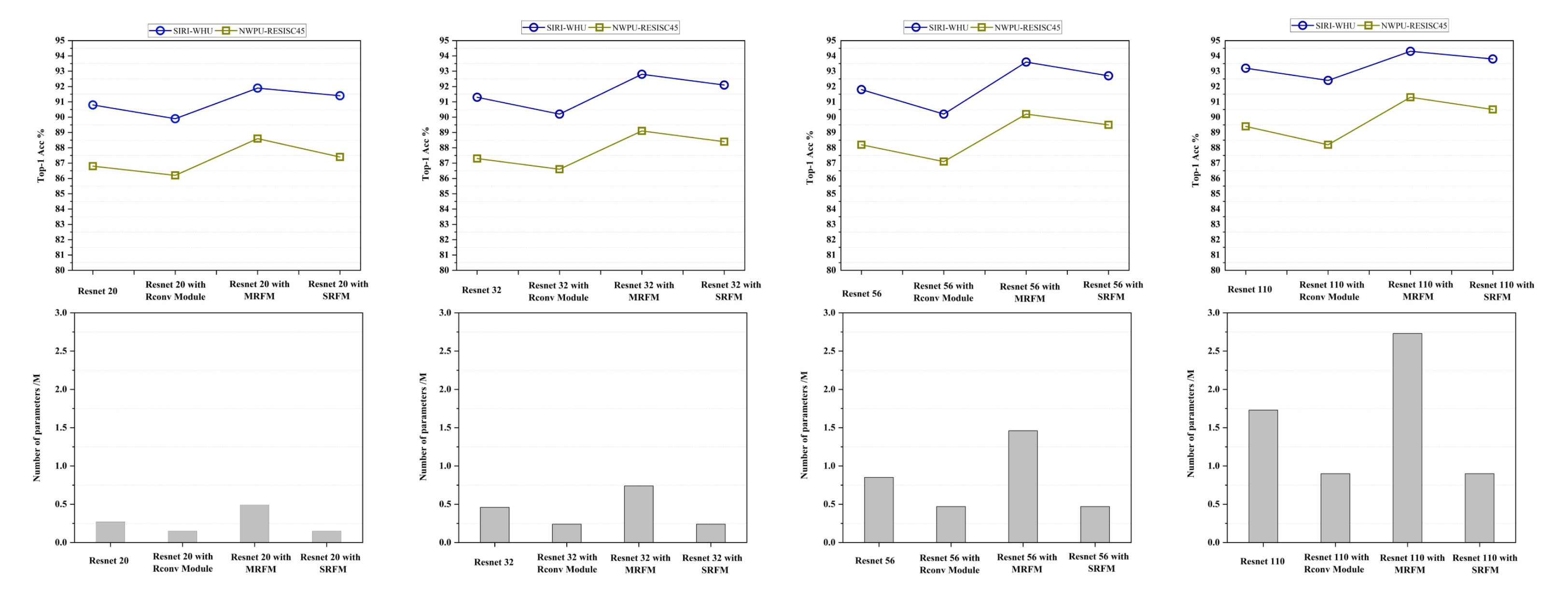
The results of the ablation experiments of the redundant feature mapping operation in the CKD framework are shown in
Figure 3.
From
Figure 3, we can draw the following conclusions:
- (1)
Resnet with the Rconv module showed the worst classification performance among the methods for all datasets. This shows that reconstructing the Resent model with only the simple Rconv module, although it can reduce the parameter redundancy of the networks, can also lead to a degradation of the model classification performance.
- (2)
Resnet with MRFM achieved the best classification performance. However, the number of parameters of the models was relatively more compared to Resnet with SRFM. At the same time, the improvement in classification accuracy of the models was insignificant, and we believe that it is not worthwhile to gain a slight improvement in the classification performance through such a scale of the number of parameters.
- (3)
With the number of parameters keeping consistent, Resnet with SRFM possessed better classification performance compared to Resnet with the Rconv module. This indicates that the equivalent convolutional kernel obtained by the multi-branch fusion operation exhibited a more powerful feature extraction ability, which effectively improved the classification performance of the model.








{kind=link}
{kind=link}
{kind=link}