

Convolutional Neural Network Chemometrics for Rock Identification Based on Laser-Induced Breakdown Spectroscopy Data in Tianwen-1 Pre-Flight Experiments
 , , ,
, , ,
Abstract
:1. Introduction
2. Background and Methods
2.1. Mission Background and Scientific Goals
2.2. LIBS Experiments and Data Preprocessing
2.3. CNN Construction
2.4. Alternative Methods for Comparison
2.5. Data Partition and Model Evaluation
3. Results and Discussion
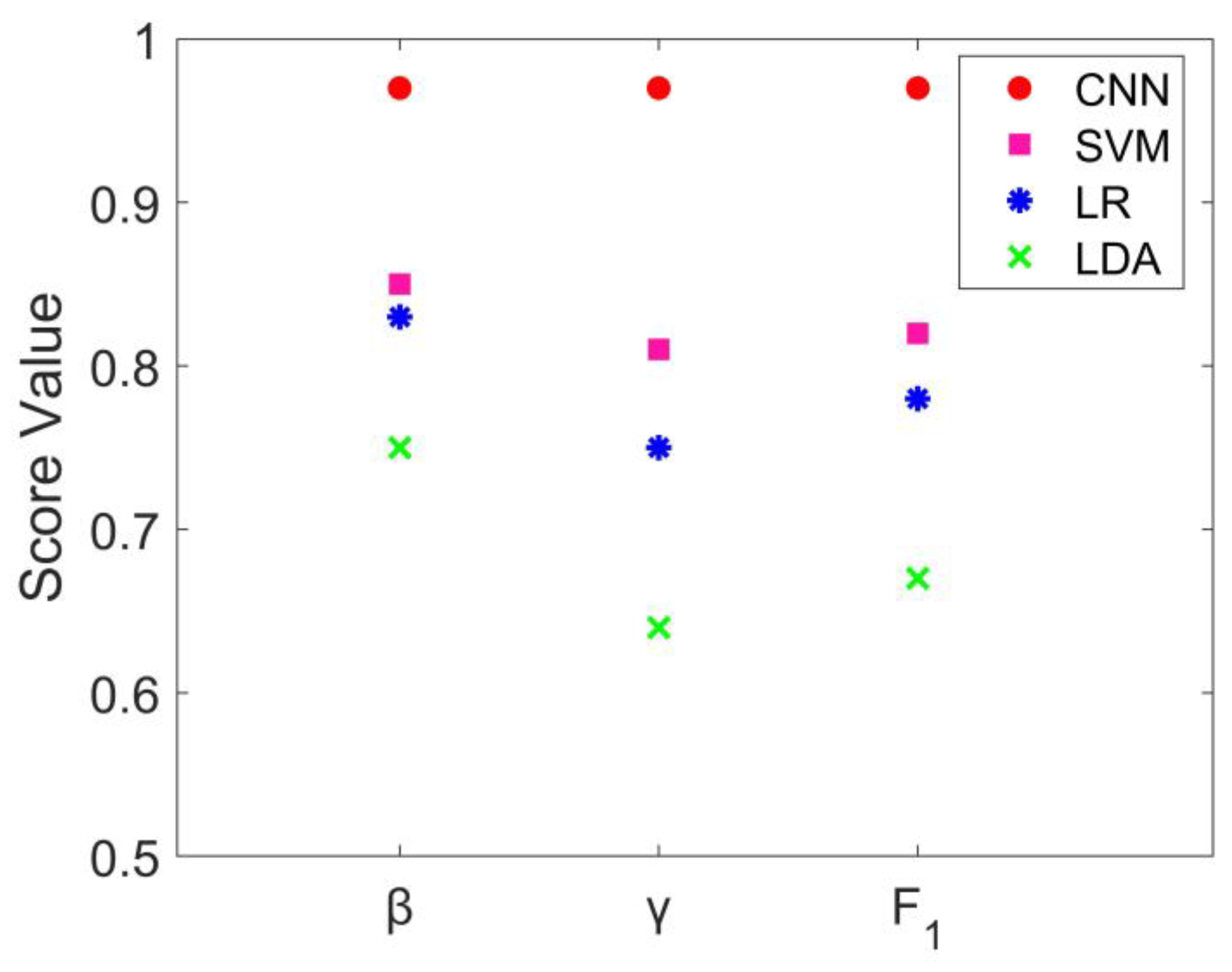
3.1. Classification Results and Performance Comparison
3.2. Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rusak, D.A.; Castle, B.C.; Smith, B.W.; Winefordner, J.D. Fundamentals and applications of laser-induced breakdown spectroscopy. Crit. Rev. Anal. Chem. 1997, 27, 257–290. [Google Scholar] [CrossRef]
- Harmon, R.S.; Remus, J.; McMillan, N.J.; McManus, C.; Collins, L.; Gottfried, J.L., Jr.; DeLucia, F.C.; Miziolek, A.W. LIBS analysis of geomaterials: Geochemical fingerprinting for the rapid analysis and discrimination of minerals. Appl. Geochem. 2009, 24, 1125–1141. [Google Scholar] [CrossRef]
- Gaudiuso, R.; Ewusi-Annan, E.; Melikechi, N.; Sun, X.Z.; Liu, B.Y.; Campesato, L.F.; Merghoub, T. Using LIBS to diagnose melanoma in biomedical fluids deposited on solid substrates: Limits of direct spectral analysis and capability of machine Learning. Spectrochim. Acta Part B At. Spectrosc. 2018, 146, 106–114. [Google Scholar] [CrossRef]
- Werheit, P.; Fricke-Begemann, C.; Gesing, M.; Noll, R. Fast single piece identification with a 3D scanning LIBS for aluminium cast and wrought alloys recycling. J. Anal. At. Spectrom. 2011, 26, 2166–2174. [Google Scholar] [CrossRef]
- Senesi, G.S.; Dell’Aglio, M.; Gaudiuso, R.; De Giacomo, A.; Zaccone, C.; De Pascale, O.; Miano, T.M.; Capitelli, M. Heavy metal concentrations in soils as determined by laser-induced breakdown spectroscopy (LIBS), with special emphasis on chromium. Environ. Res. 2009, 109, 413–420. [Google Scholar] [CrossRef]
- Liu, X.D.; Feng, X.P.; He, Y. Rapid discrimination of the categories of the biomass pellets using laser-induced breakdown spectroscopy. Renew. Energy 2019, 143, 176–182. [Google Scholar] [CrossRef]
- Burger, M.; Skrodzki, P.J.; Finney, L.A.; Nees, J.; Jovanovic, I. Remote Detection of Uranium Using Self-Focusing Intense Femtosecond Laser Pulses. Remote Sens. 2020, 12, 1281. [Google Scholar] [CrossRef] [Green Version]
- Shi, Q.; Niu, G.H.; Lin, Q.Y.; Xu, T.; Li, F.J.; Duan, Y.X. Quantitative analysis of sedimentary rocks using laser-induced breakdown spectroscopy: Comparison of Support Vector Regression and Partial Least Squares Regression Chemometric Methods. J. Anal. At. Spectrom. 2015, 30, 2384–2393. [Google Scholar] [CrossRef]
- Chatterjee, S.; Singh, M.; Biswal, B.P.; Sinha, U.K.; Patbhaje, S.; Sarkar, A. Application of laser-induced breakdown spectroscopy (LIBS) coupled with PCA for rapid classification of soil samples in geothermal areas. Anal. Bioanal. Chem. 2019, 411, 2855–2866. [Google Scholar] [CrossRef]
- Wiens, R.C.; Maurice, S.; Barraclough, B.; Saccoccio, M.; Barkley, W.C.; Bell, J.F., III; Bender, S.; Bernardin, J.; Blaney, D.; Blank, J.; et al. The ChemCam Instrument Suite on the Mars Science Laboratory (MSL) Rover: Body Unit and Combined System Tests. Space Sci. Rev. 2012, 170, 167–227. [Google Scholar] [CrossRef]
- Wiens, R.C.; Maurice, S.; Lasue, J.; Forni, O.; Anderson, R.B.; Clegg, S.; Bender, S.; Blaney, D.; Barraclough, B.; Cousin, A.; et al. Pre-flight calibration and initial data processing for the ChemCam laser-induced breakdown spectroscopy instrument on the Mars Science Laboratory rover. Spectrochim. Acta Part B At. Spectrosc. 2013, 82, 1–27. [Google Scholar] [CrossRef]
- Maurice, S.; Wiens, R.C.; Saccoccio, M.; Barraclough, B.; Gasnault, O.; Forni, O.; Mangold, N.; Baratoux, D.; Bender, S.; Berger, G.; et al. The ChemCam Instrument Suite on the Mars Science Laboratory (MSL) Rover: Science Objectives and Mast Unit Description. Space Sci. Rev. 2012, 170, 95–166. [Google Scholar] [CrossRef]
- Sautter, V.; Fabre, C.; Forni, O.; Toplis, M.J.; Cousin, A.; Ollila, A.M.; Meslin, P.Y.; Maurice, S.; Wiens, R.C.; Baratoux, D.; et al. Igneous mineralogy at Bradbury Rise: The first ChemCam campaign at Gale crater. J. Geophys. Res. Planets 2014, 119, 30–46. [Google Scholar] [CrossRef] [Green Version]
- Boucher, T.F.; Ozanne, M.V.; Carmosino, M.L.; Dyar, M.D.; Mahadevan, S.; Breves, E.A.; Lepore, K.H.; Clegg, S.M. A study of machine learning regression methods for major elemental analysis of rocks using laser-induced breakdown spectroscopy. Spectrochim. Acta Part B At. Spectrosc. 2015, 107, 1–10. [Google Scholar] [CrossRef]
- Schröder, S.; Meslin, P.-Y.; Gasnault, O.; Maurice, S.; Cousin, A.; Wiens, R.C.; Rapin, W.; Dyar, M.; Mangold, N.; Forni, O.; et al. Hydrogen detection with ChemCam at Gale crater. Icarus 2015, 249, 43–61. [Google Scholar] [CrossRef]
- Nachon, M.; Mangold, N.; Forni, O.; Kah, L.C.; Cousin, A.; Wiens, R.C.; Anderson, R.; Blaney, D.; Blank, J.; Calef, F.; et al. Chemistry of diagenetic features analyzed by ChemCam at Pahrump Hills, Gale crater, Mars. Icarus 2017, 281, 121–136. [Google Scholar] [CrossRef]
- Rivera-Hernández, F.; Sumner, D.Y.; Mangold, N.; Stack, K.M.; Forni, O.; Newsom, H.; Williams, A.; Nachon, M.; L’Haridon, J.; Gasnault, O.; et al. Using ChemCam LIBS data to constrain grain size in rocks on Mars: Proof of concept and application to rocks at Yellowknife Bay and Pahrump Hills, Gale crater. Icarus 2019, 321, 82–98. [Google Scholar] [CrossRef]
- Wiens, R.C.; Maurice, S.; McCabe, K.; Cais, P.; Anderson, R.B.; Beyssac, O.; Bonal, L.; Clegg, S.; Deflores, L.; Dromart, G.; et al. The SuperCam Remote Sensing Instrument Suite for Mars 2020. In Proceedings of the 47th Lunar and Planetary Science Conference, The Woodlands, TX, USA, 21–25 March 2016. [Google Scholar]
- Manrique, J.A.; Lopez-Reyes, G.; Cousin, A.; Rull, F.; Maurice, S.; Wiens, R.C.; Madsen, M.B.; Madariaga, J.M.; Gasnault, O.; Aramendia, J.; et al. SuperCam Calibration Targets: Design and Development. Space Sci. Rev. 2020, 216, 138. [Google Scholar] [CrossRef]
- Maurice, S.; Wiens, R.C.; Bernardi, P.; Caïs, P.; Robinson, S.; Nelson, T.; Gasnault, O.; Reess, J.-M.; Deleuze, M.; Rull, F.; et al. The SuperCam Instrument Suite on the Mars 2020 Rover: Science Objectives and Mast-Unit Description. Space Sci. Rev. 2021, 217, 47. [Google Scholar] [CrossRef]
- Wiens, R.C.; Maurice, S.; Robinson, S.H.; Nelson, A.E.; Cais, P.; Bernardi, P.; Newell, R.T.; Clegg, S.; Sharma, S.K.; Storms, S.; et al. The SuperCam Instrument Suite on the NASA Mars 2020 Rover: Body Unit and Combined System Tests. Space Sci. Rev. 2021, 217, 4. [Google Scholar] [CrossRef]
- Anderson, R.B.; Forni, O.; Cousin, A.; Wiens, R.C.; Clegg, S.M.; Frydenvang, J.; Gabriel, T.S.; Ollila, A.; Schröder, S.; Beyssac, O.; et al. Post-landing major element quantification using SuperCam laser induced breakdown spectroscopy. Spectrochim. Acta Part B At. Spectrosc. 2022, 188, 106347. [Google Scholar] [CrossRef]
- Xu, W.M.; Liu, X.F.; Yan, Z.X.; Li, L.N.; Zhang, Z.Q.; Kuang, Y.W.; Jiang, H.; Yu, H.; Yang, F.; Liu, C.; et al. The MarSCoDe Instrument Suite on the Mars Rover of China’s Tianwen-1 Mission. Space Sci. Rev. 2021, 217, 64. [Google Scholar] [CrossRef]
- Cousin, A.; Sautter, V.; Payré, V.; Forni, O.; Mangold, N.; Gasnault, O.; Le Deit, L.; Johnson, J.; Maurice, S.; Salvatore, M.; et al. Classification of igneous rocks analyzed by ChemCam at Gale crater, Mars. Icarus 2017, 288, 265–283. [Google Scholar] [CrossRef]
- Yang, G.; Qiao, S.; Chen, P.; Ding, Y.; Tian, D. Rock and soil classification using PLS-DA and SVM combined with a laser-induced breakdown spectroscopy library. Plasma Sci. Technol. 2015, 17, 656–663. [Google Scholar] [CrossRef]
- Vítková, G.; Novotný, K.; Prokeš, L.; Hrdlička, A.; Kaiser, J.; Novotný, J.; Malina, R.; Prochazka, D. Fast identification of biominerals by means of stand-off laser-induced breakdown spectroscopy using linear discriminant analysis and artificial neural networks. Spectrochim. Acta Part B At. Spectrosc. 2012, 73, 1–6. [Google Scholar] [CrossRef]
- Yelameli, M.; Thornton, B.; Takahashi, T.; Weerkoon, T.; Ishii, K. Classification and statistical analysis of hydrothermal seafloor rocks measured underwater using laser-induced breakdown spectroscopy. J. Chemometr. 2019, 33, e3092. [Google Scholar] [CrossRef]
- Bi, Y.; Zhang, Y.; Yan, J.; Wu, Z.; Li, Y. Classification and discrimination of minerals using laser induced breakdown spectroscopy and Raman spectroscopy. Plasma Sci. Technol. 2015, 17, 923–927. [Google Scholar] [CrossRef] [Green Version]
- D’Andrea, E.; Pagnotta, S.; Grifoni, E.; Lorenzetti, G.; Legnaioli, S.; Palleschi, V.; Lazzerini, B. An artificial neural network approach to laser-induced breakdown spectroscopy quantitative analysis. Spectrochim. Acta Part B At. Spectrosc. 2014, 99, 52–58. [Google Scholar] [CrossRef]
- Campanella, B.; Grifoni, E.; Legnaioli, S.; Lorenzetti, G.; Pagnotta, S.; Sorrentino, F.; Palleschi, V. Classification of wrought aluminum alloys by Artificial Neural Networks evaluation of Laser Induced Breakdown Spectroscopy spectra from aluminum scrap samples. Spectrochim. Acta Part B At. Spectrosc. 2017, 134, 52–57. [Google Scholar] [CrossRef]
- Liu, J.C.; Osadchy, M.; Ashton, L.; Foster, M.; Solomone, C.J.; Gibson, S.J. Deep convolutional neural networks for Raman spectrum recognition: A unified solution. Analyst 2017, 142, 4067–4074. [Google Scholar] [CrossRef]
- Acquarelli, J.; van Laarhoven, T.; Gerretzen, J.; Tran, T.N.; Buydens, L.M.C.; Marchiori, E. Convolutional neural networks for vibrational spectroscopic data analysis. Anal. Chim. Acta 2017, 954, 22–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, C.X.; Wang, B.; Jiang, X.P.; Zhang, J.N.; Niu, K.; Yuan, Y.W. Detection of K in soil using time-resolved laser-induced breakdown spectroscopy based on convolutional neural networks. Plasma Sci. Technol. 2019, 21, 034014. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Li, L.N.; Liu, X.F.; Xu, W.M.; Wang, J.Y.; Shu, R. A laser-induced breakdown spectroscopy multi-component quantitative analytical method based on a deep convolutional neural network. Spectrochim. Acta Part B At. Spectrosc. 2020, 169, 105850. [Google Scholar] [CrossRef]
- Yang, F.; Li, L.N.; Xu, W.M.; Liu, X.F.; Cui, Z.C.; Jia, L.C.; Liu, Y.; Xu, J.H.; Chen, Y.W.; Xu, X.S.; et al. Laser-induced breakdown spectroscopy combined with a convolutional neural network: A promising methodology for geochemical sample identification in Tianwen-1 Mars mission. Spectrochim. Acta Part B At. Spectrosc. 2022, 192, 106417. [Google Scholar] [CrossRef]
- Wan, W.X.; Wang, C.; Li, C.L.; Wei, Y. China’s first mission to Mars. Nat. Astron. 2020, 4, 721. [Google Scholar] [CrossRef]
- Weitz, N.; Zanetti, M.; Osinski, G.R.; Fastook, J.L. Modeling concentric crater fill in Utopia Planitia, Mars, with an ice flow line model. Icarus 2018, 308, 209–220. [Google Scholar] [CrossRef]
- Head, J.W.; Kreslavsky, M.A.; Pratt, S. Northern lowlands of Mars: Evidence for widespread volcanic flooding and tectonic deformation in the Hesperian period. J. Geophys. Res. 2002, 107, 5003. [Google Scholar] [CrossRef]
- Soare, J.; Osinski, G.R.; Roehm, C.L. Thermokarst lakes and ponds on Mars in the very recent (late Amazonian) past. Earth Planet. Sc. Lett. 2008, 272, 382–393. [Google Scholar] [CrossRef]
- Lefort, A.; Russell, P.S.; Thomas, N.; McEwen, A.S.; Dundas, C.M.; Kirk, R.L. Observations of periglacial landforms in Utopia Planitia with the High Resolution Imaging Science Experiment (HiRISE). J. Geophys. Res. 2009, 114, E04005. [Google Scholar] [CrossRef]
- Morgenstern, A.; Hauber, E.; Reiss, D.; Gasselt, S.V.; Grosse, G.; Schirrmeister, L. Deposition and degradation of a volatile-rich layer in Utopia Planitia, and implications for climate history on Mars. J. Geophys. Res. 2007, 112, E06010. [Google Scholar] [CrossRef] [Green Version]
- Ulrich, M.; Morgenstern, A.; Günther, F.; Reiss, D.; Bauch, K.E.; Hauber, E.; Rössler, S.; Schirrmeister, L. Thermokarst in Siberian ice-rich permafrost: Comparison to asymmetric scalloped depressions on Mars. J. Geophys. Res. 2010, 115, E10009. [Google Scholar] [CrossRef] [Green Version]
- Clark, B.C.; Baird, A.K.; Rose, H.J.; Priestley, T.; Keil, K.; Castro, A.J.; Kelliher, W.C.; Rowe, C.D.; Evans, P.H. Inorganic analyses of Martian surface samples at the Viking landing sites. Science 1976, 194, 1283–1288. [Google Scholar] [CrossRef] [PubMed]
- Bandfield, J.L.; Hamilton, V.E.; Christensen, P.R. A global view of Martian surface compositions from MGS-TES. Science 2000, 287, 1626–1630. [Google Scholar] [CrossRef] [Green Version]
- Brennetot, R.; Lacour, J.L.; Vors, E.; Rivoallan, A.; Vailhen, D.; Maurice, S. Mars Analysis by Laser-Induced Breakdown Spectroscopy (MALIS): Influence of Mars Atmosphere on Plasma Emission and Study of Factors Influencing Plasma Emission with the use of Doehlert Designs. Appl. Spectrosc. 2003, 57, 744–752. [Google Scholar] [CrossRef]
- Liu, C.; Ling, Z.; Zhang, J.; Wu, Z.; Bai, H.; Liu, Y. A Stand-Off Laser-Induced Breakdown Spectroscopy (LIBS) System Applicable for Martian Rocks Studies. Remote Sens. 2021, 13, 4773. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. Proc. ICML 2013, 30, 3. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
- Peng, C.J.; Lee, K.L.; Ingersoll, G.M. An Introduction to Logistic Regression Analysis and Reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Tharwat, A.; Gaber, T.; Ibrahim, A.; Hassanien, A.E. Linear discriminant analysis: A detailed tutorial. AI Commun. 2017, 30, 169–190. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Powers, D.M.W. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Gerds, T.A.; Cai, T.; Schumacher, M. The performance of risk prediction models. Biom. J. 2008, 50, 457–479. [Google Scholar] [CrossRef] [PubMed]
- Clegg, S.M.; Wiens, R.C.; Anderson, R.; Forni, O.; Frydenvang, J.; Lasue, J.; Cousin, A.; Payré, V.; Boucher, T.; Dyar, M.D.; et al. Recalibration of the Mars Science Laboratory ChemCam instrument with an expanded geochemical database. Spectrochim. Acta Part B At. Spectrosc. 2017, 129, 64–85. [Google Scholar] [CrossRef]
- Cui, Z.; Jia, L.; Li, L.; Liu, X.; Xu, W.; Shu, R.; Xu, X. A Laser-Induced Breakdown Spectroscopy Experiment Platform for High-Degree Simulation of MarSCoDe In Situ Detection on Mars. Remote Sens. 2022, 14, 1954. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Laser pulse width | 4 ns |
| Laser pulse energy | 9 mJ |
| Laser wavelength | 1064 nm |
| Laser repetition rate | 1 Hz, 2 Hz, 3 Hz |
| Overall spectral range | 240–850 nm |
| Number of spectral channels | 3 |
| Pixels per spectral channel | 1800 |
| Detection distance | 1.6–7 m |
| No. | Rock Type | SiO2 | Al2O3 | Fe2O3 | CaO | MgO | K2O | Na2O |
|---|---|---|---|---|---|---|---|---|
| 1 | Andesite | 60.62 | 16.17 | 4.9 | 5.2 | 1.72 | 1.89 | 3.86 |
| 2 | Dolomite | 0.021 | 0.017 | 0.224 | 32.11 | 20.37 | 0.0011 | 0.023 |
| 3 | Opal | 68.98 | × | × | × | × | × | × |
| 4 | Kaolinite | 43.41 | 34.77 | 1.5 | 0.038 | 0.069 | 0.78 | 0.045 |
| 5 | Potash feldspar | 66.26 | 18.63 | 0.19 | 0.76 | 0.054 | 9.6 | 3.69 |
| 6 | Montmorillonite | 77.89 | 13.78 | × | 2.81 | 1.4 | × | 0.28 |
| 7 | Diopside | 53.40 | 1.38 | 0.43 | 24.40 | 18.31 | 0.15 | 0.26 |
| 8 | Basalt | 44.64 | 13.83 | 13.4 | 8.81 | 7.77 | 2.32 | 3.38 |
| 9 | Hematite | 9.82 | 0.48 | 61.73 | 0.11 | 0.055 | 0.056 | 0.0056 |
| 10 | Olivine | 40.73 | × | 8.67 | 0.04 | 50.05 | × | × |
| 11 | Albite | 67.96 | 19.62 | 0.1 | 0.48 | 0.015 | 0.098 | 11.26 |
| 12 | Gypsum | 7.21 | 1.92 | 0.63 | 28.5 | 4.92 | 0.38 | 0.021 |
| Dataset | Dataset Ⅰ | Dataset Ⅱ | |
|---|---|---|---|
| Training Set | Validation Set | Testing Set | |
| Spectrum quantity | 660 | 60 | 720 |
| Rock Type | CNN | LR | SVM | LDA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| β | γ | F1 | β | γ | F1 | β | γ | F1 | β | γ | F1 | |
| 1 | 0.78 | 1 | 0.88 | 0.33 | 0.74 | 0.46 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0.95 | 0.98 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 3 | 0.90 | 1 | 0.95 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 | 1 | 0.5 | 0.67 | 1 | 0.5 | 0.67 | 1 | 1 | 1 |
| 5 | 0.97 | 0.98 | 0.97 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 1 | 0.92 | 0.96 | 1 | 0.92 | 0.96 | 1 | 0.51 | 0.67 | 1 | 0.37 | 0.54 |
| 7 | 0.95 | 0.90 | 0.93 | 1 | 1 | 1 | 1 | 0.97 | 0.98 | 1 | 1 | 1 |
| 8 | 1 | 0.98 | 0.99 | 0.88 | 0.6 | 0.72 | 1 | 1 | 1 | 1 | 0.98 | 0.99 |
| 9 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 10 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 11 | 1 | 0.88 | 0.94 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0.78 | 0.88 |
| 12 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0.5 | 0.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, F.; Xu, W.; Cui, Z.; Liu, X.; Xu, X.; Jia, L.; Chen, Y.; Shu, R.; Li, L. Convolutional Neural Network Chemometrics for Rock Identification Based on Laser-Induced Breakdown Spectroscopy Data in Tianwen-1 Pre-Flight Experiments. Remote Sens. 2022, 14, 5343. https://doi.org/10.3390/rs14215343
Yang F, Xu W, Cui Z, Liu X, Xu X, Jia L, Chen Y, Shu R, Li L. Convolutional Neural Network Chemometrics for Rock Identification Based on Laser-Induced Breakdown Spectroscopy Data in Tianwen-1 Pre-Flight Experiments. Remote Sensing. 2022; 14(21):5343. https://doi.org/10.3390/rs14215343
Chicago/Turabian StyleYang, Fan, Weiming Xu, Zhicheng Cui, Xiangfeng Liu, Xuesen Xu, Liangchen Jia, Yuwei Chen, Rong Shu, and Luning Li. 2022. "Convolutional Neural Network Chemometrics for Rock Identification Based on Laser-Induced Breakdown Spectroscopy Data in Tianwen-1 Pre-Flight Experiments" Remote Sensing 14, no. 21: 5343. https://doi.org/10.3390/rs14215343