

Unlocking Large-Scale Crop Field Delineation in Smallholder Farming Systems with Transfer Learning and Weak Supervision


Abstract
:Highlights
- We develop a method for accurate, scalable field delineation in smallholder systems.
- Fields are delineated with state-of-the-art deep learning and watershed segmentation.
- Transfer learning and weak supervision reduce training labels needed by 5× to 10×
- 10,000 new crop field boundaries are generated in India and publicly released.
Abstract
1. Introduction
2. Datasets
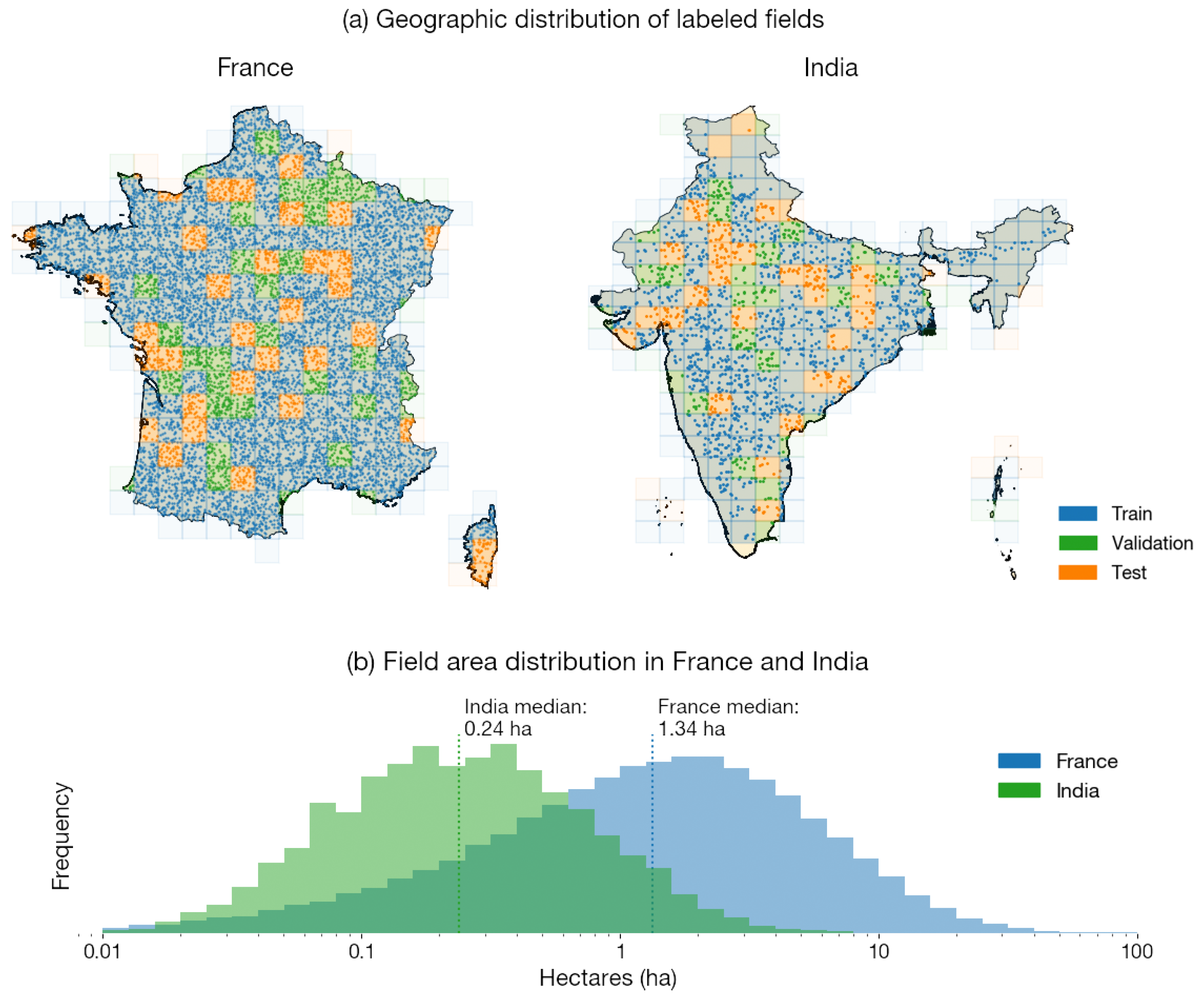
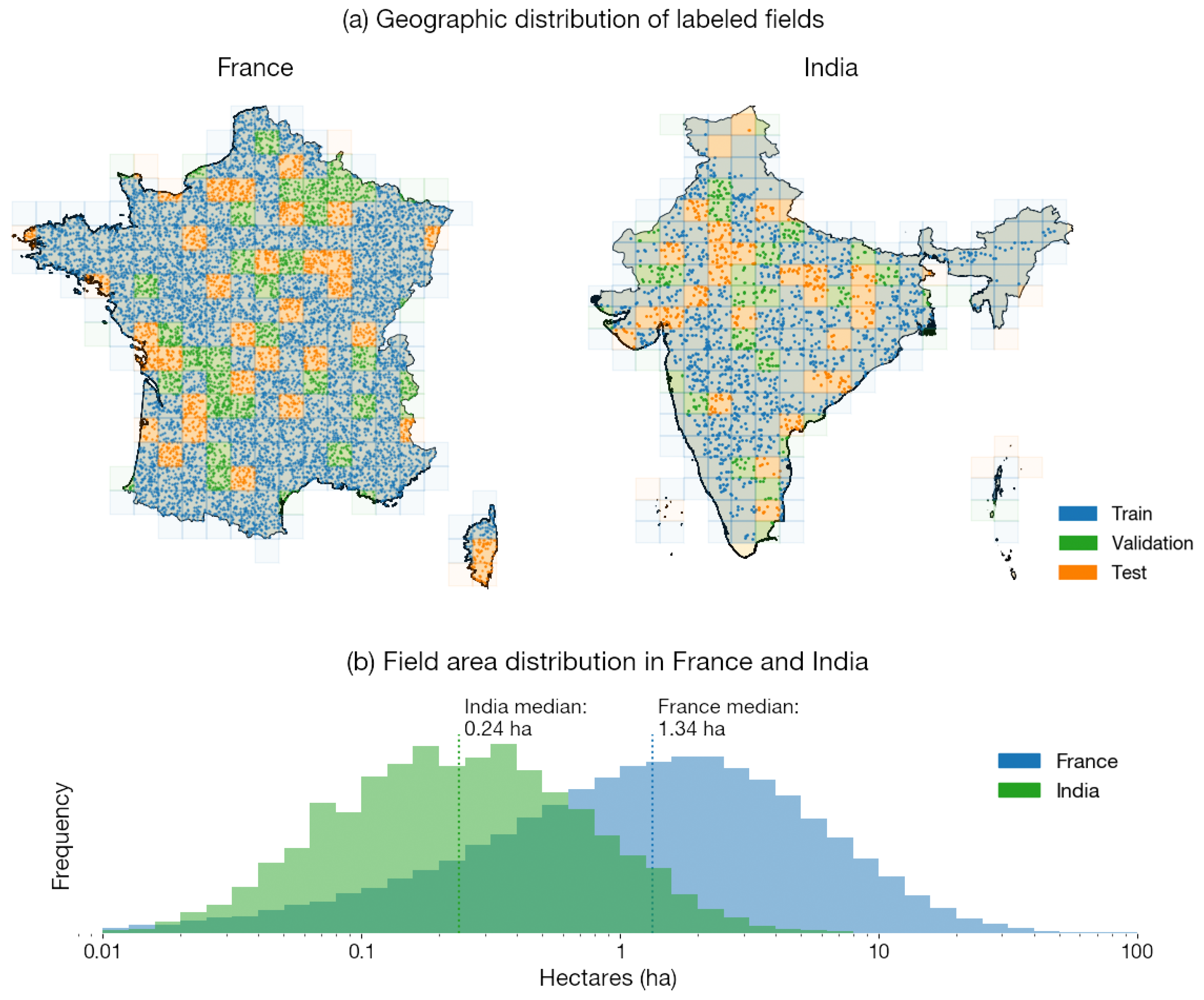
2.1. Sampling Locations for Datasets
2.1.1. India
2.1.2. France
2.2. Satellite Imagery
2.2.1. Annual Airbus OneAtlas Basemap
2.2.2. Monthly PlanetScope Visual Basemaps
2.3. Field Boundary Labels
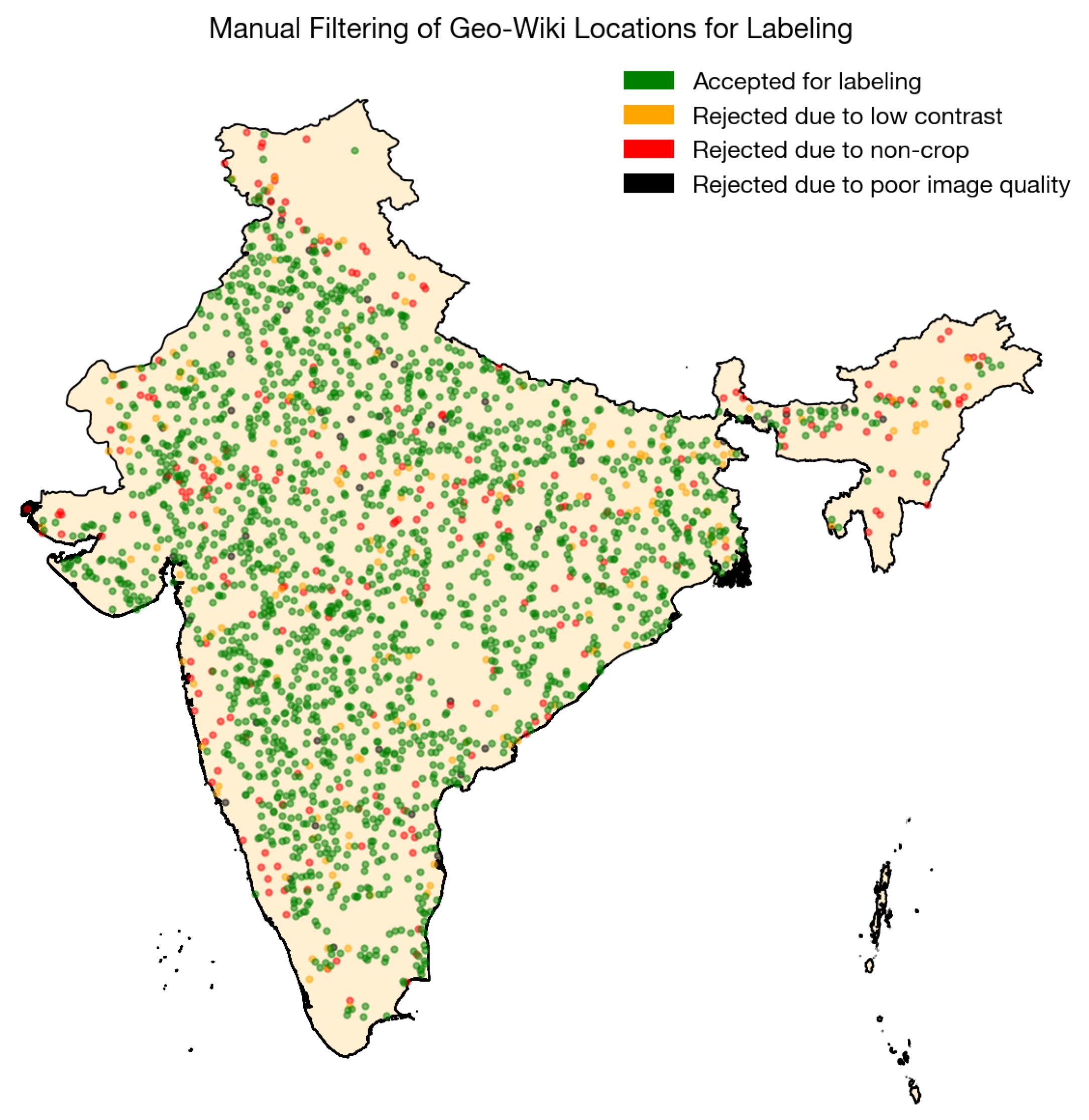
2.3.1. Creating Field Boundary Labels in India
2.3.2. Registre Parcellaire Graphique
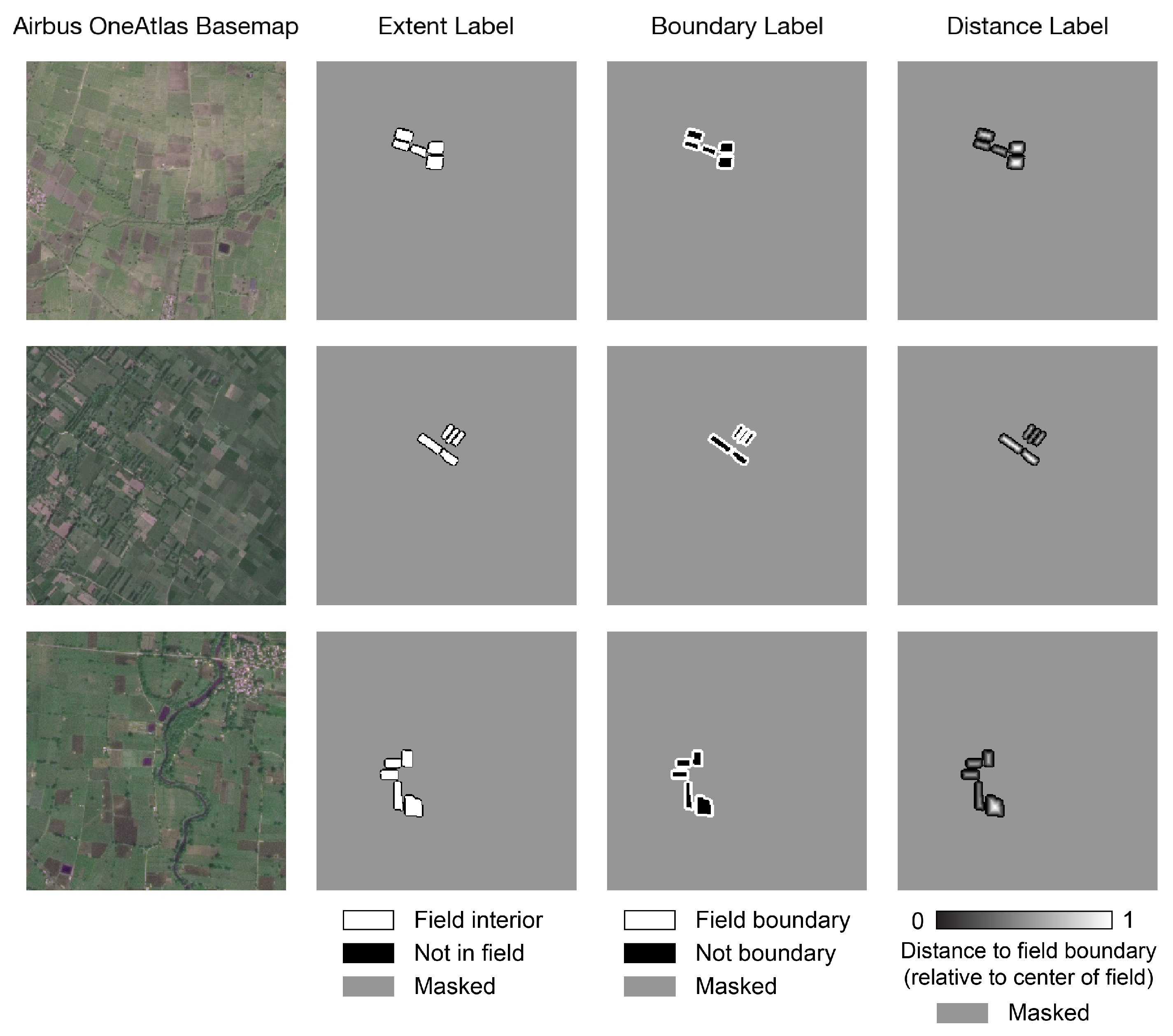
2.3.3. Rasterizing Polygons to Create Labels
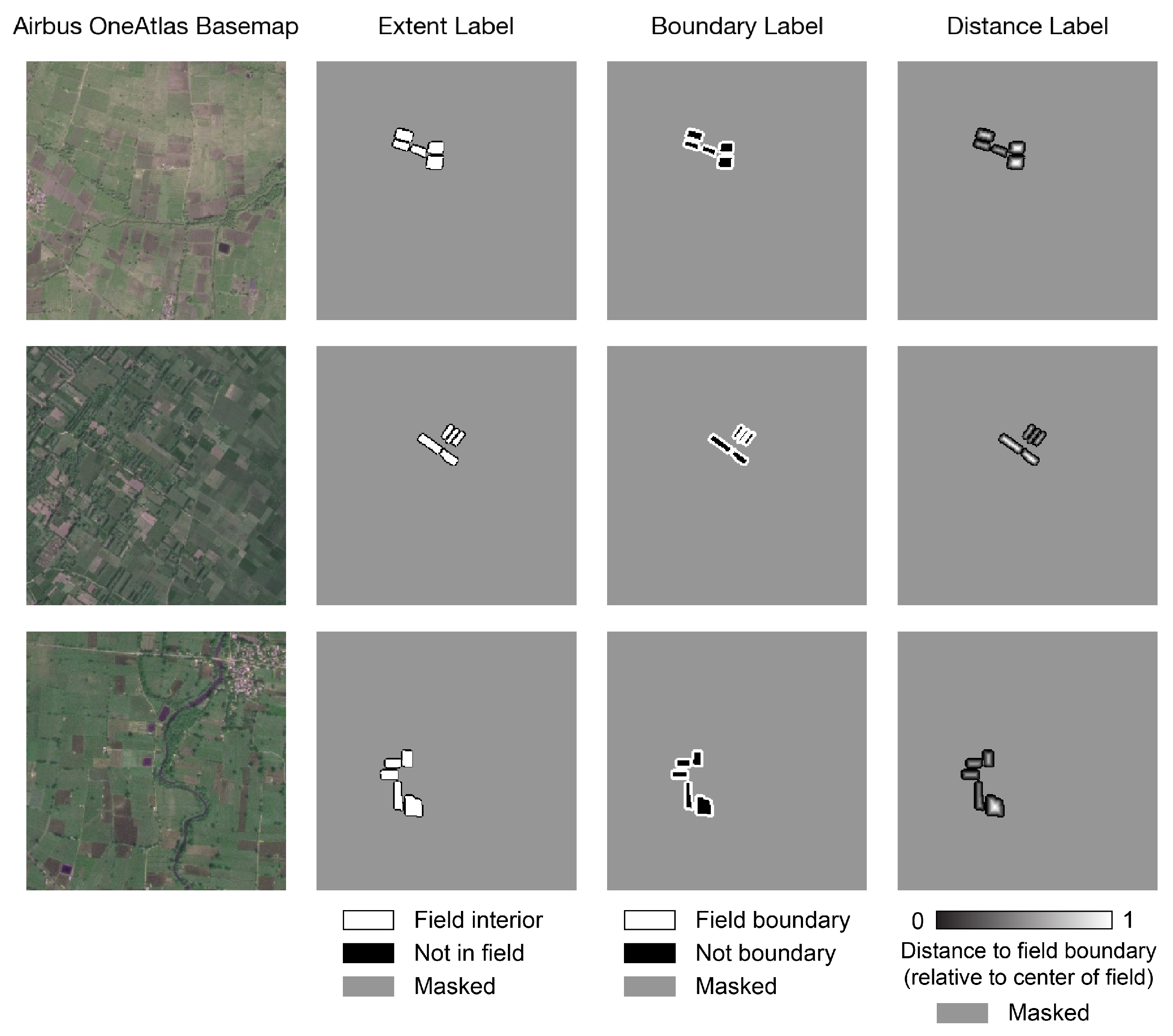
- The “extent label” describes whether each pixel in the image is inside a crop field. Pixels inside a crop field have value 1, while pixels outside have value 0.
- The “boundary label” describes whether each pixel is on the boundary of a field. Pixels on the boundary (two pixels thick) have value 1; other pixels have value 0.
- The “distance label” describes the distance of pixels inside fields to the nearest field boundary. Values are normalized by dividing each field’s distances by the maximum distance within that field to the boundary. All values therefore fall between 0 and 1; pixels not inside fields take the value 0.
3. Methods
3.1. Neural Network Implementation
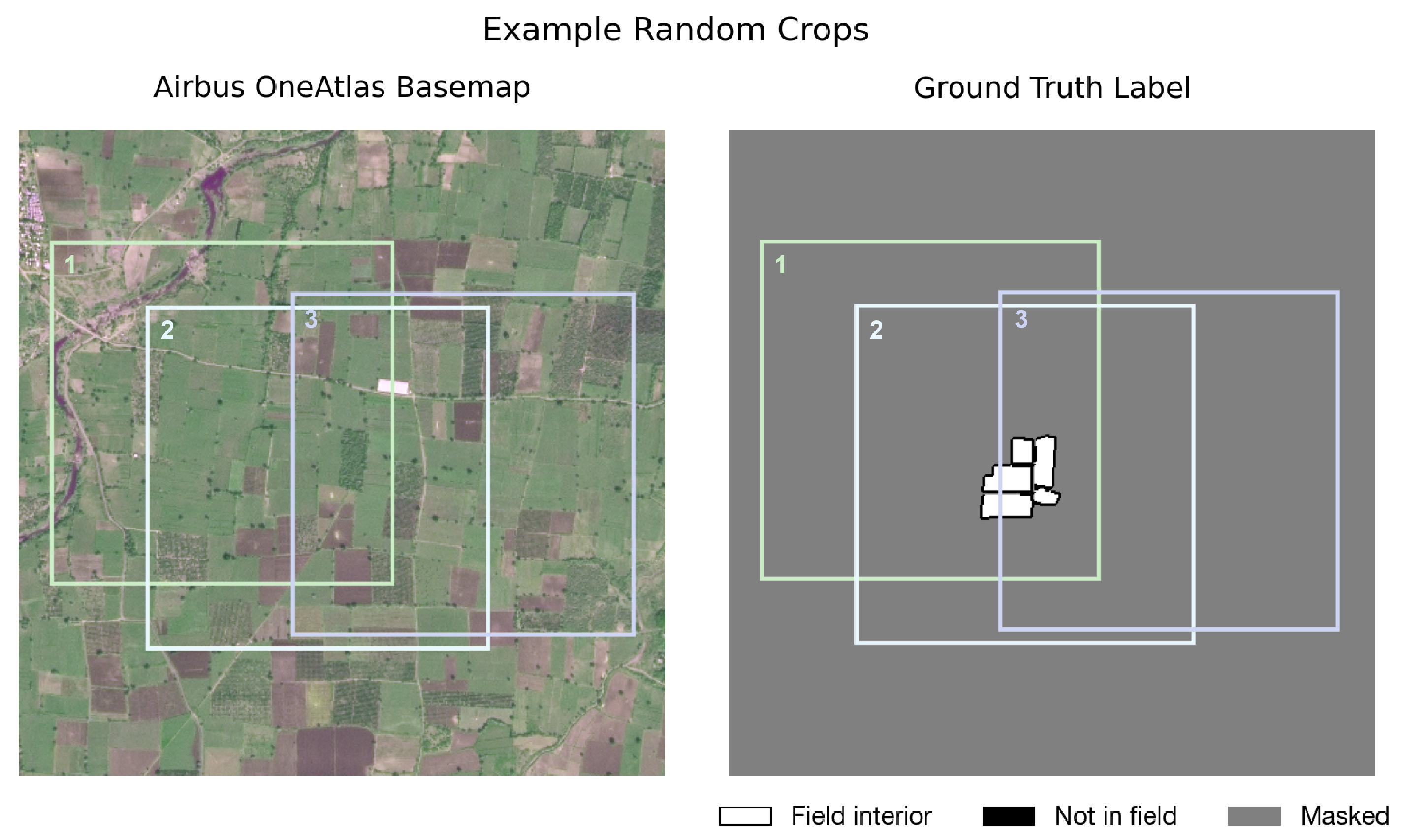
3.2. Training on Partial Labels
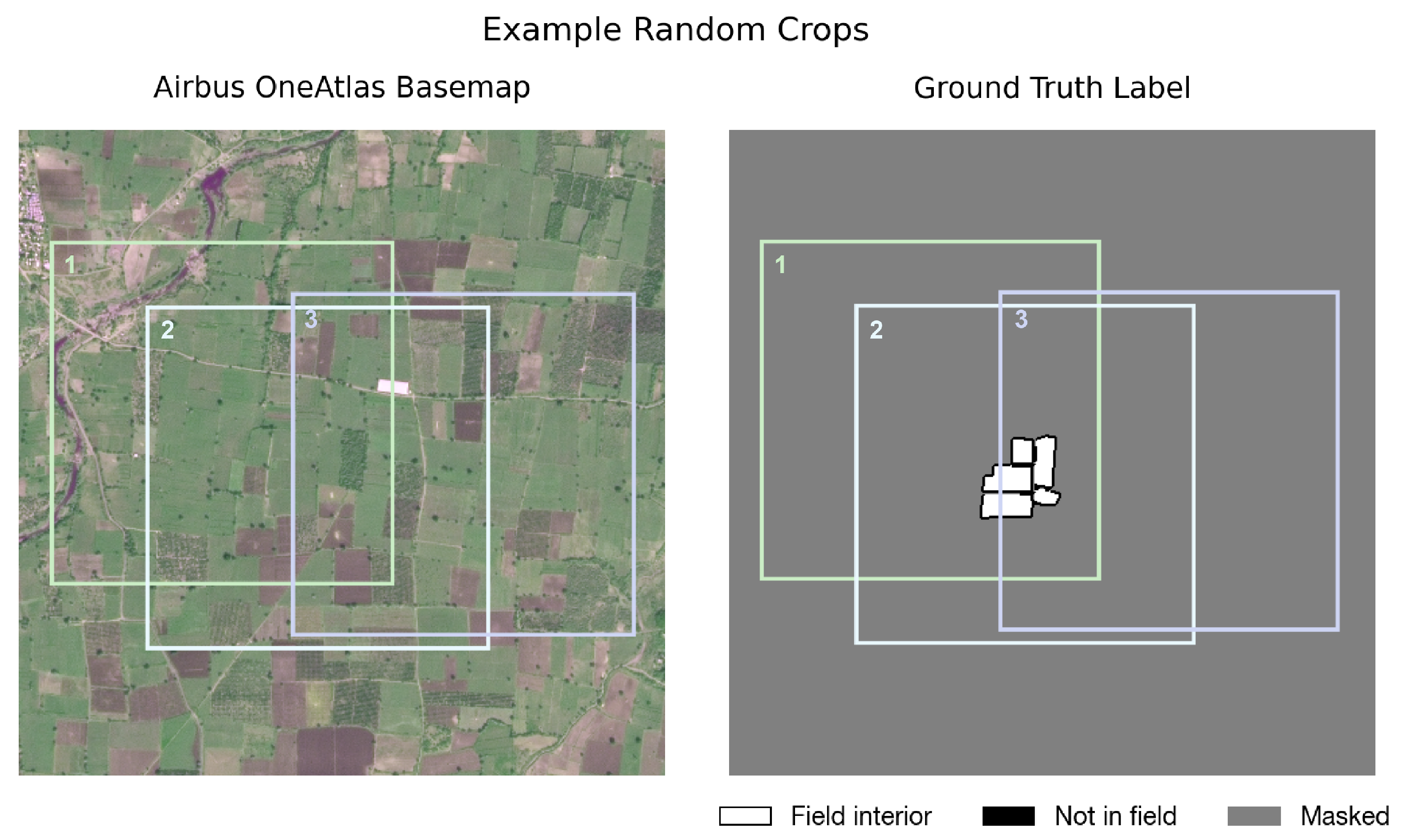
- Masking out unlabeled areas
- Varying fields labeled per image
3.3. Post-Processing Predictions to Obtain Field Instances
3.4. Evaluation Metrics
- Semantic segmentation metrics
- Instance segmentation metrics
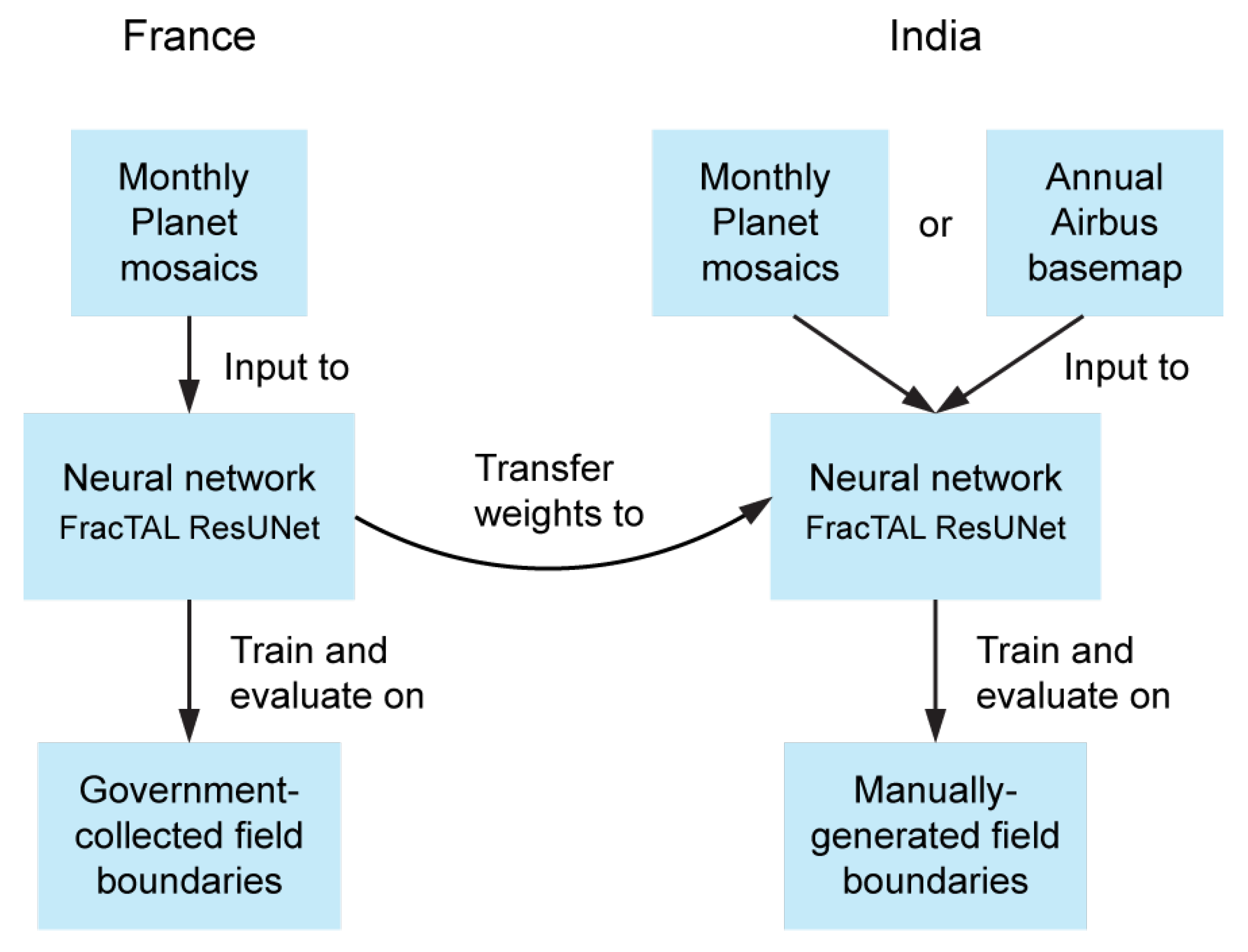
3.5. Field Delineation Experiments
- PlanetScope vs. Airbus OneAtlas imagery
- Combining multi-temporal imagery
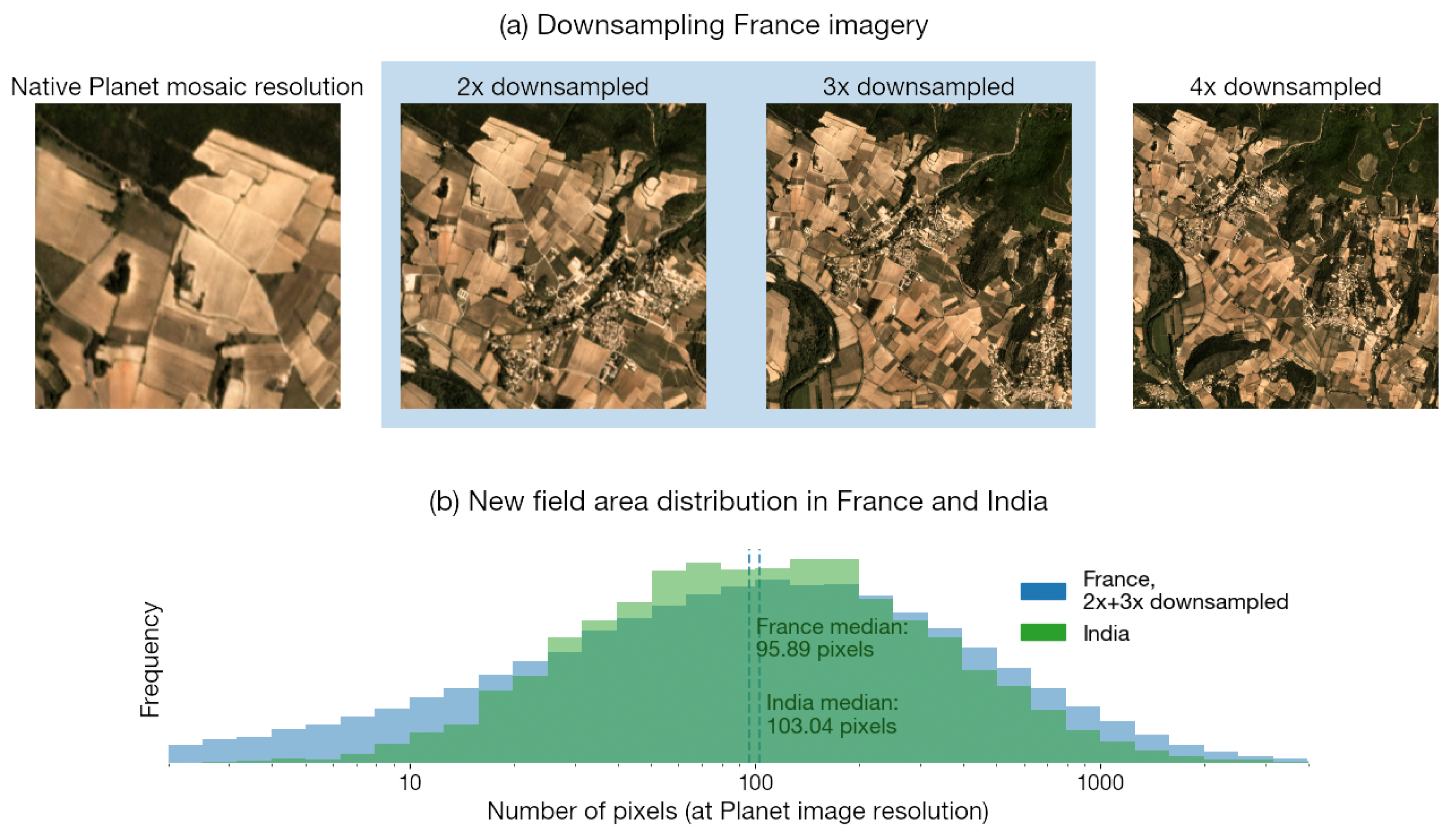
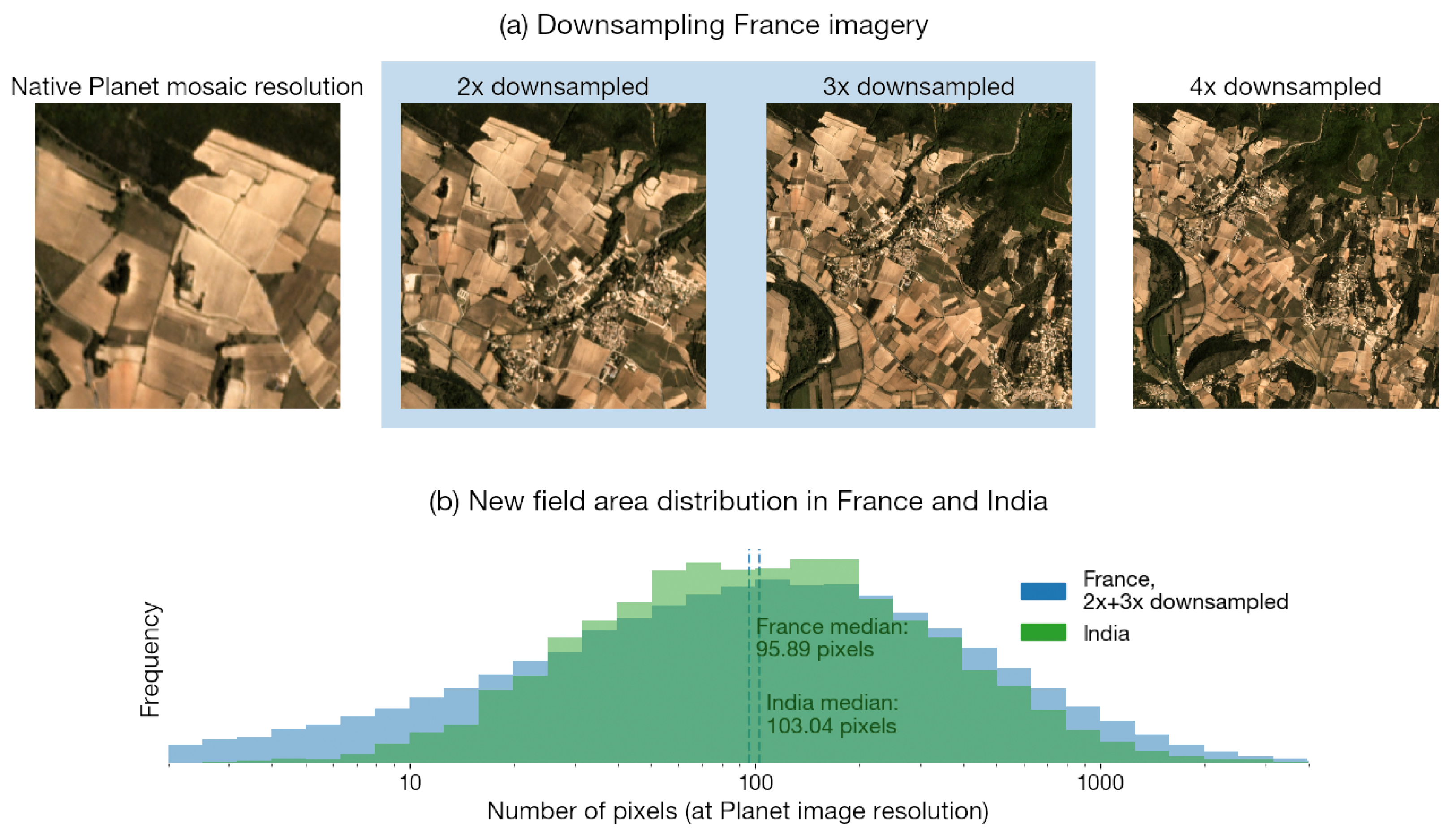
- Downsampling France imagery
- Training from scratch vs. transfer learning
- A model trained on original-resolution PlanetScope imagery and fully-segmented field labels in France
- A model trained on original-resolution PlanetScope imagery and partial labels in France
- A model trained on 2x- and 3x-downsampled PlanetScope imagery and partial labels in France
- A model pre-trained on PlanetScope imagery and partial labels in France, then fine-tuned on PlanetScope/Airbus SPOT imagery and partial labels in India
- A model trained “from scratch”—i.e., without pre-training, starting from randomly initialized neural network weights—on PlanetScope/Airbus SPOT imagery and partial labels in India
4. Results
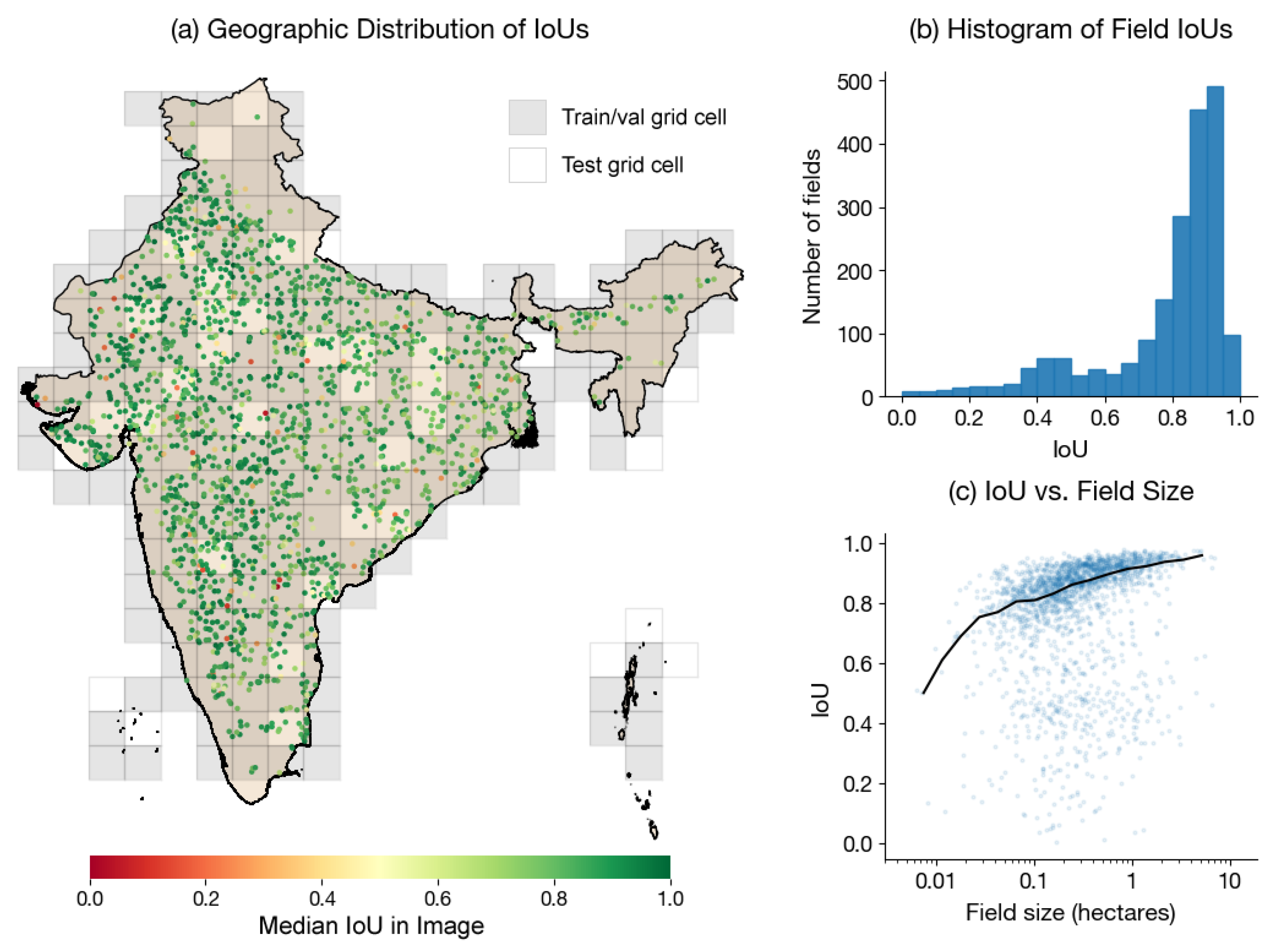
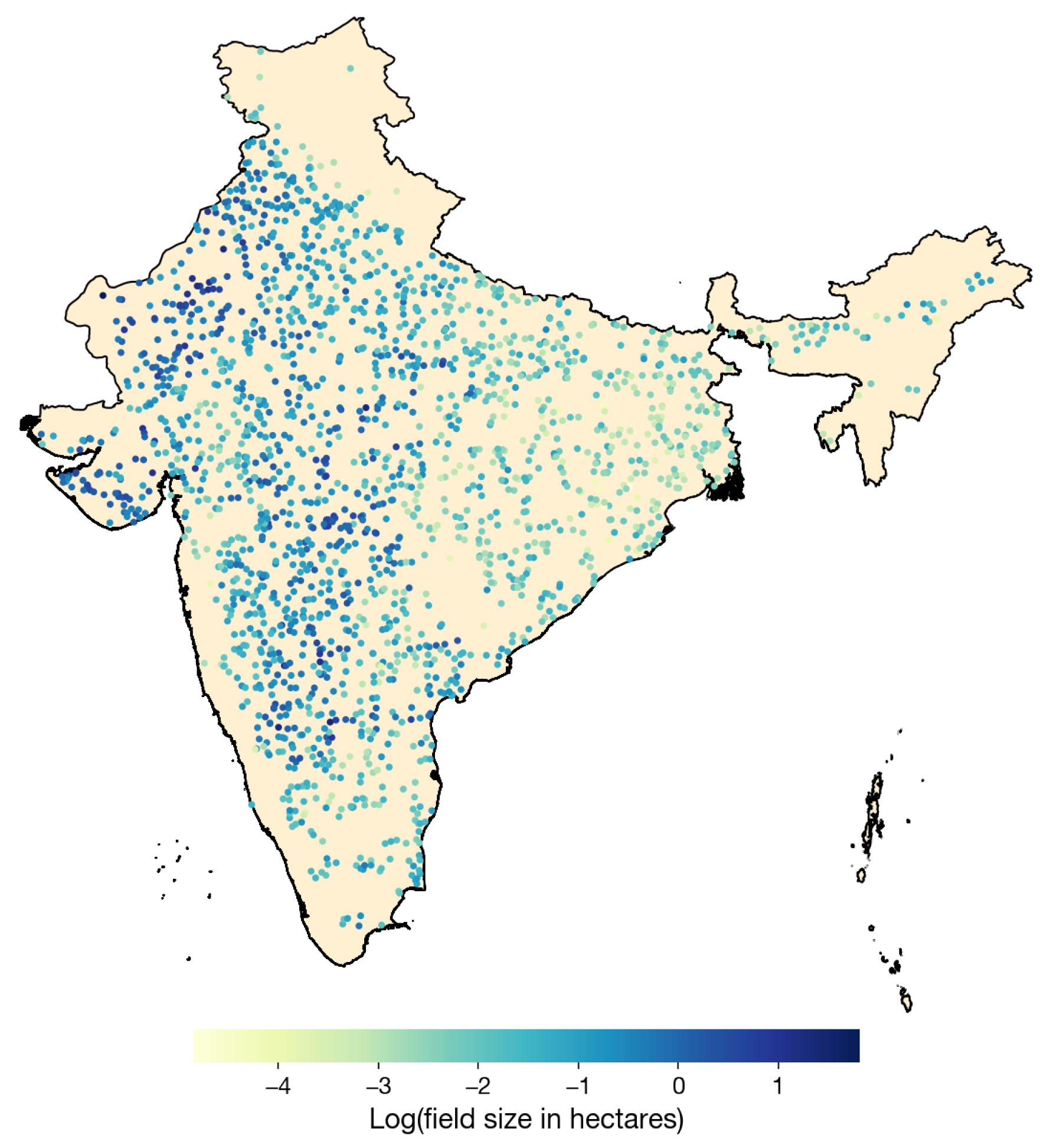
4.1. Field Statistics in India
4.2. Interpreting Partial Label Results
4.3. Optimizing Partial Label Collection
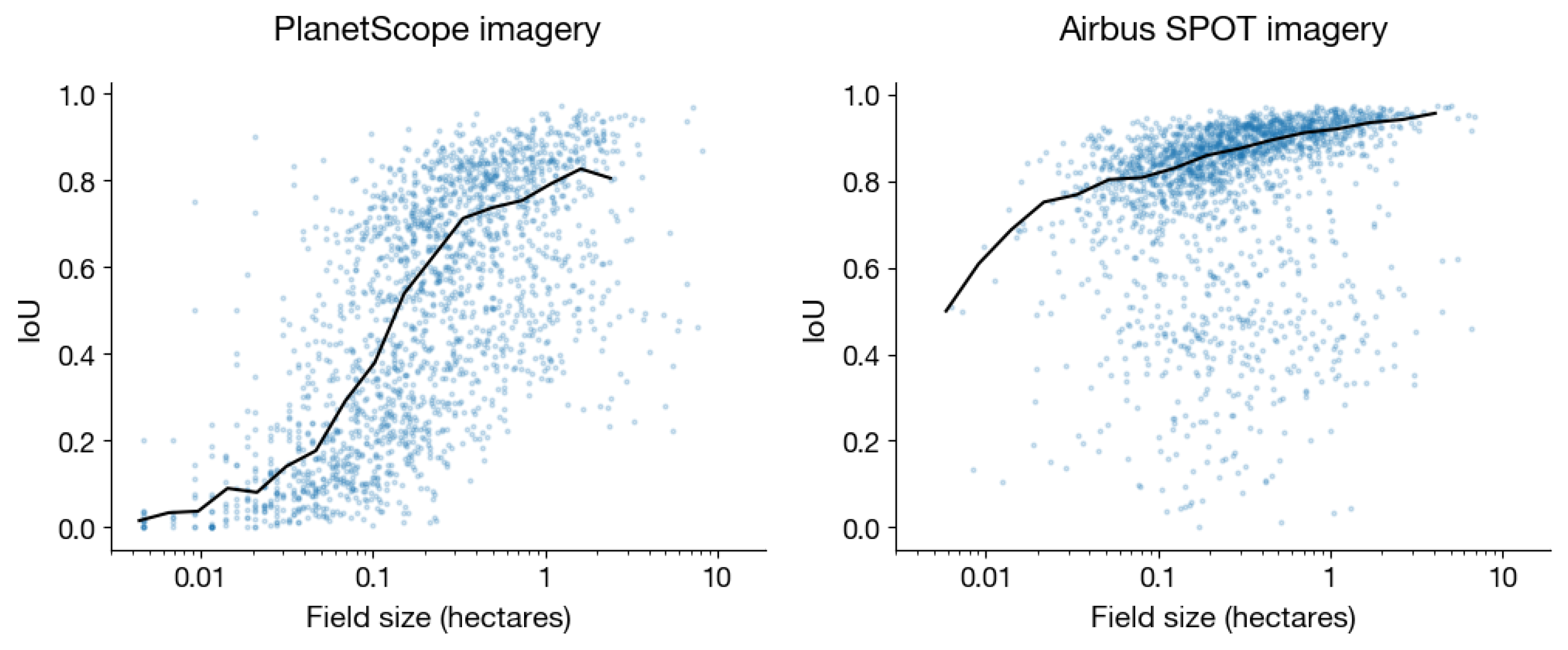
4.4. PlanetScope vs. Airbus OneAtlas imagery
4.5. Transfer Learning from France to India
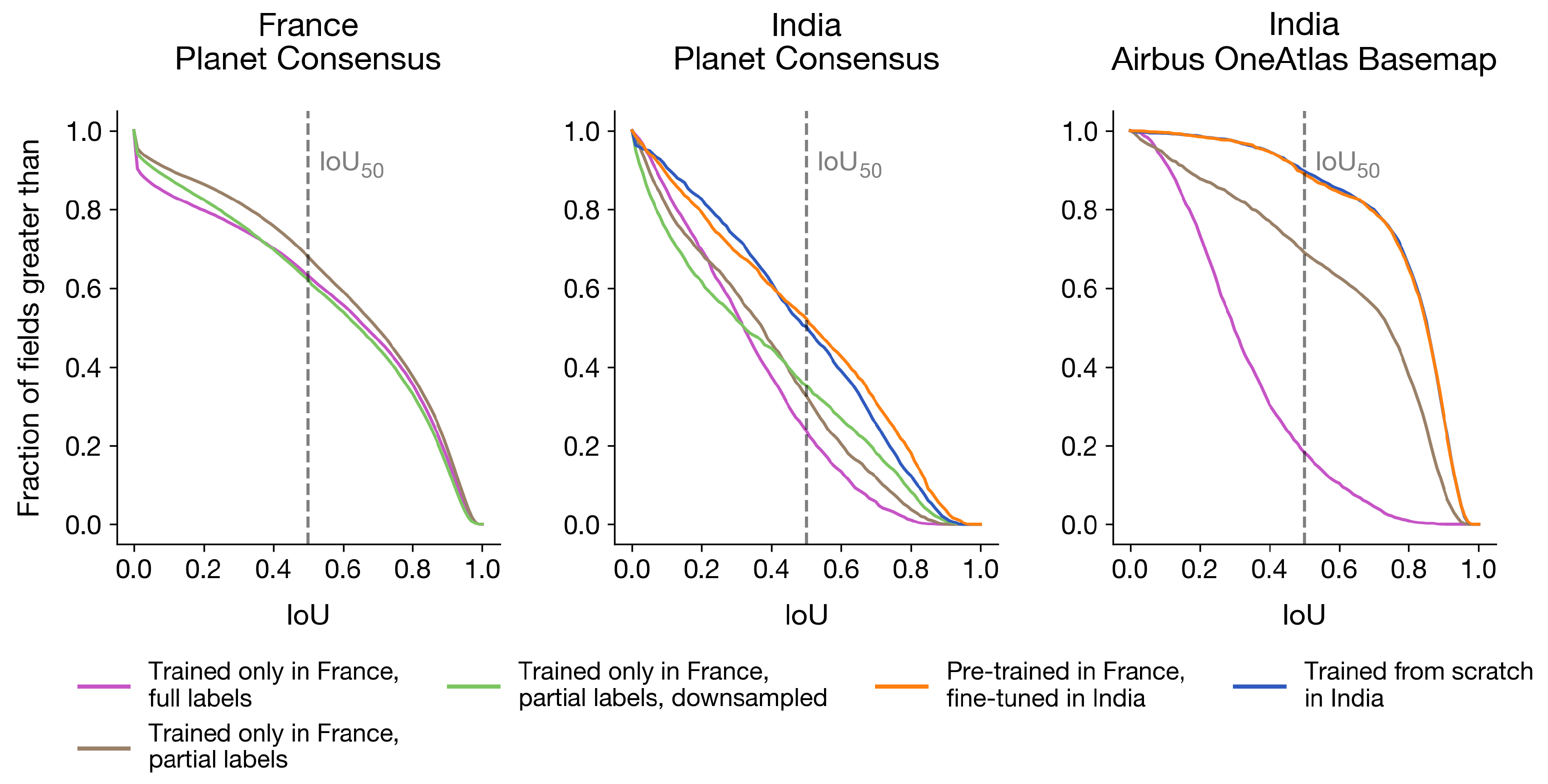
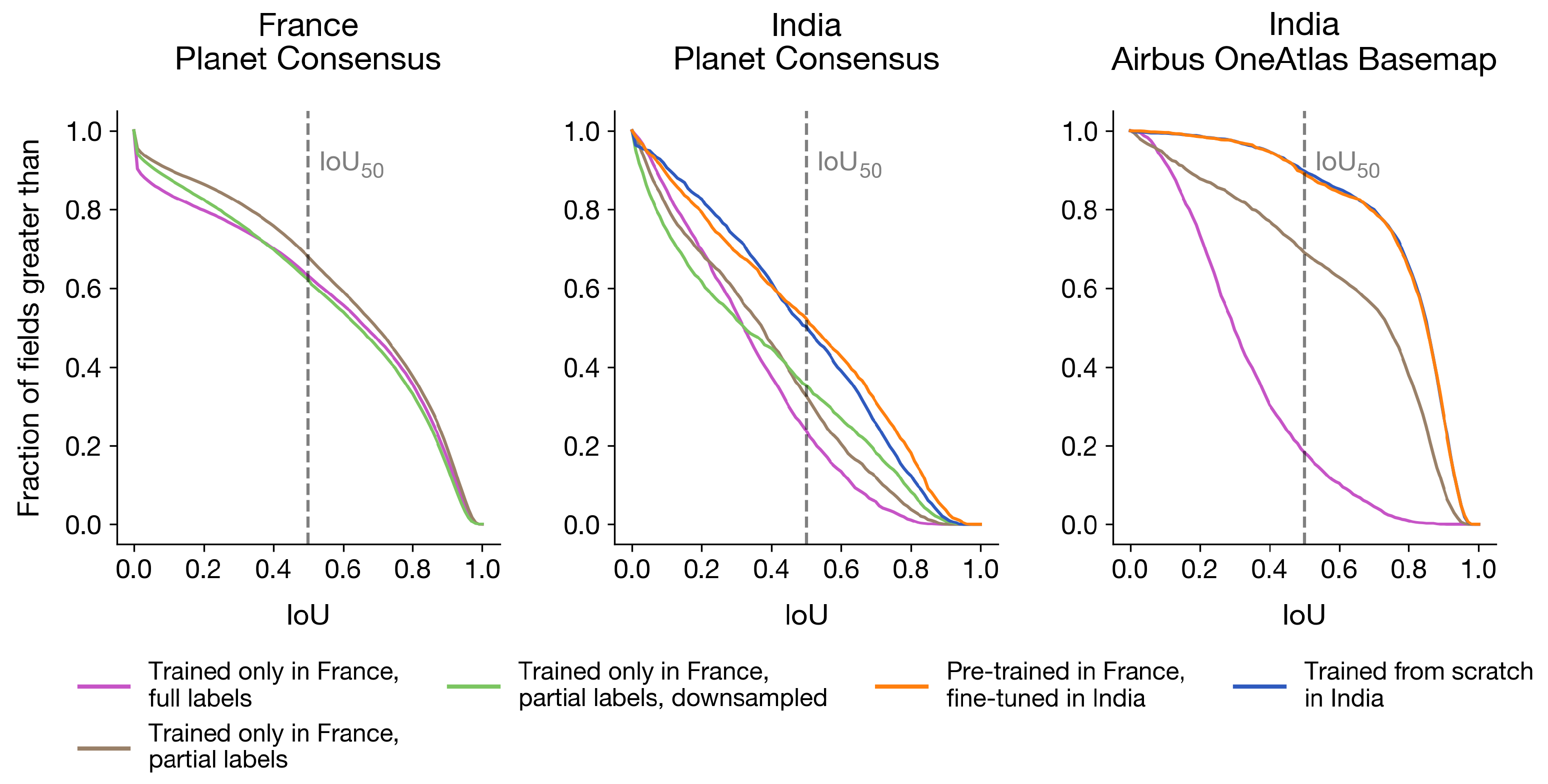
4.5.1. Training on Fully-Segmented France Labels Transfers Poorly to India
4.5.2. Changing to Partial France Labels Enables Transfer
4.5.3. Training on Partial India Labels Improves Performance
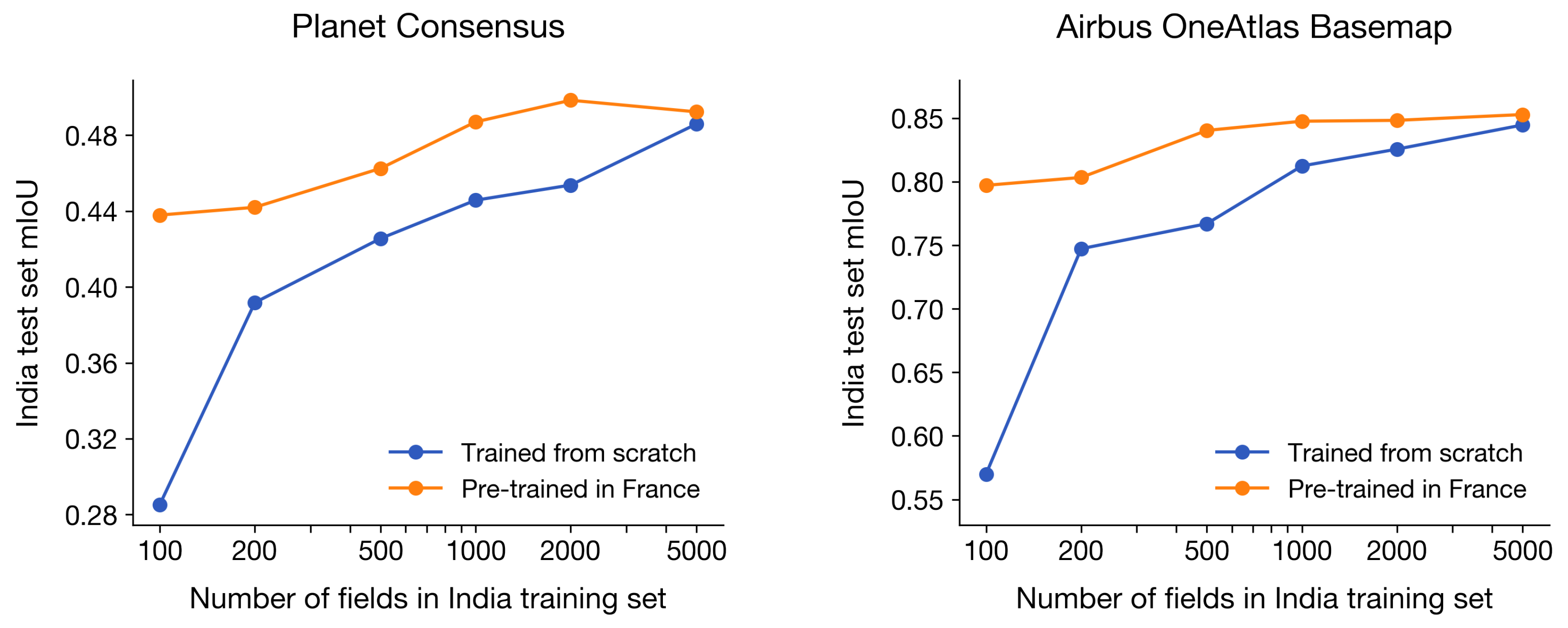
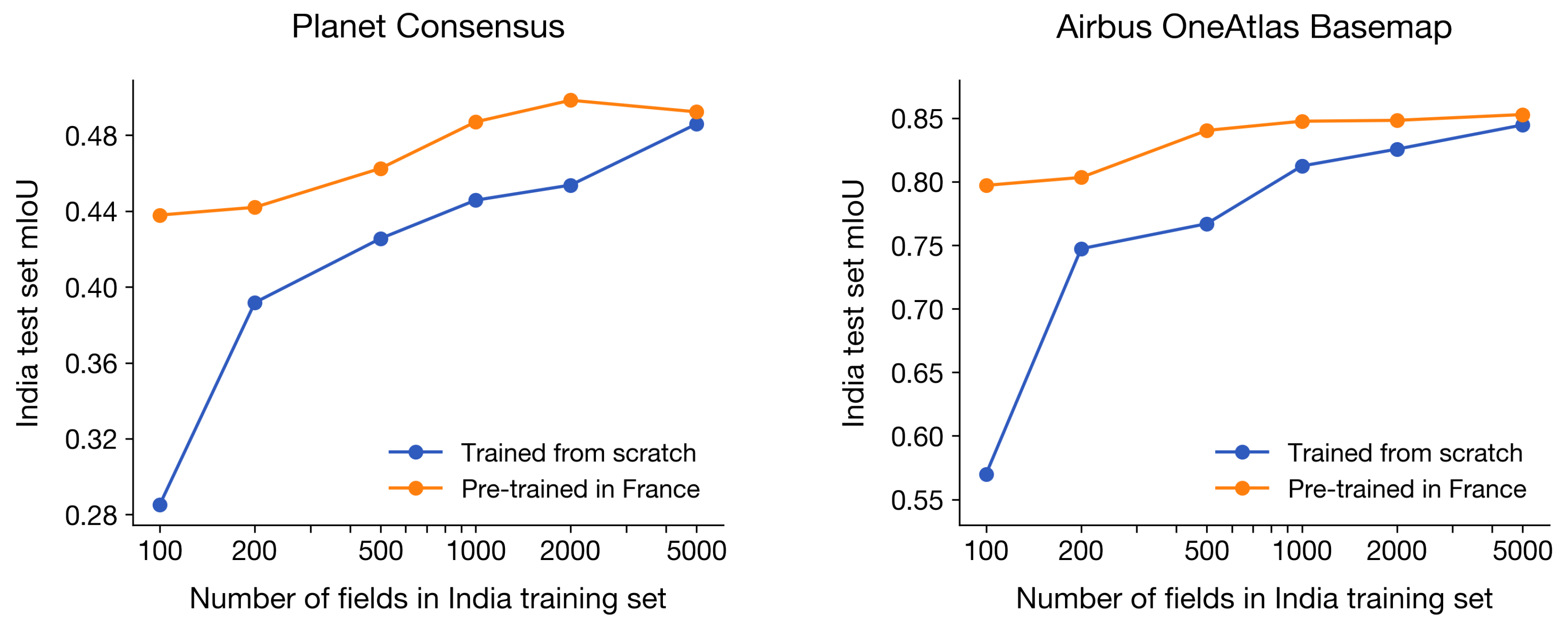
4.5.4. Pre-Training in France Improves Performance When India Datasets Are Small
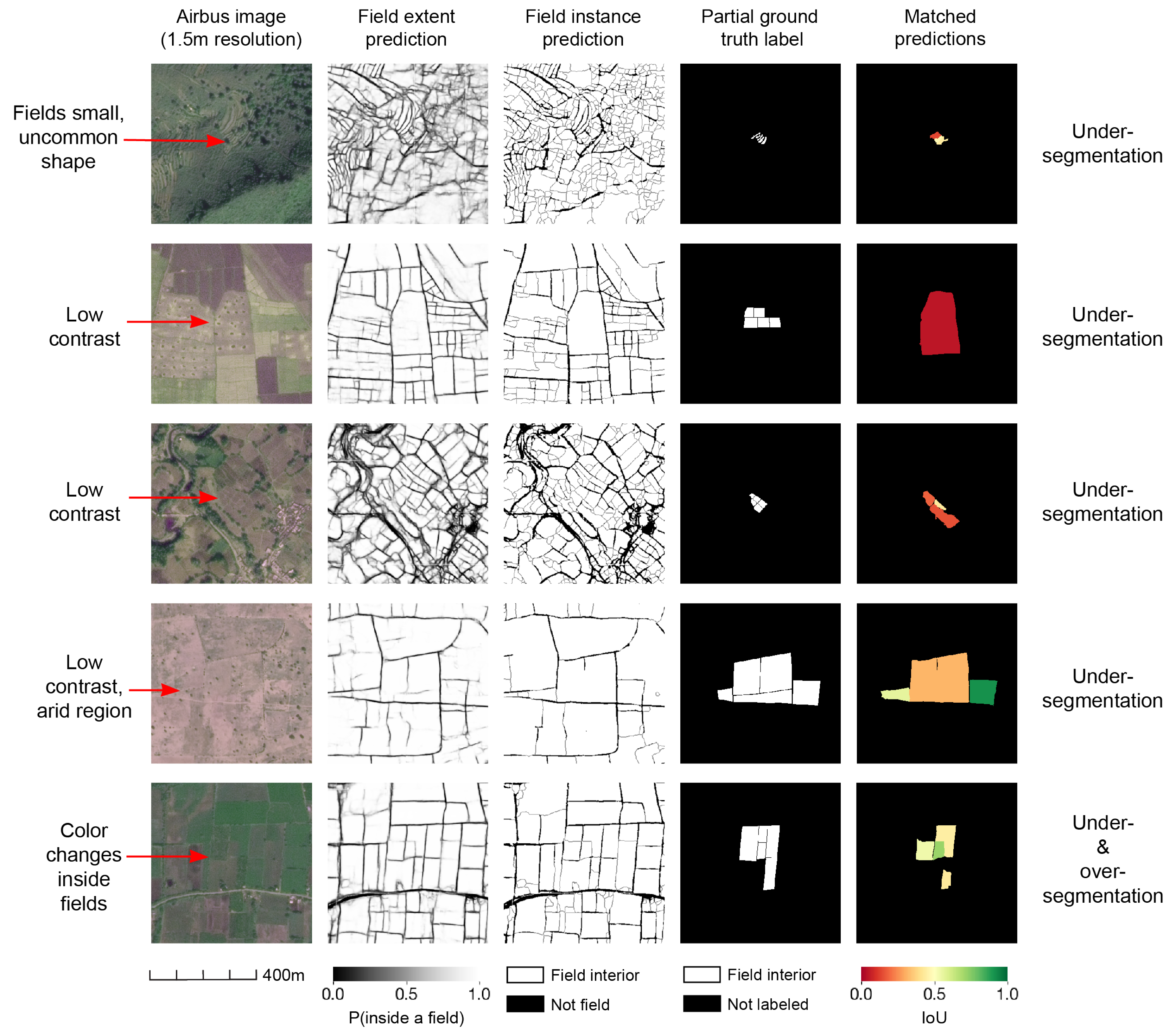
4.5.5. Most Errors Are Under-Segmentation Due to Low Image Contrast
5. Discussion
- Pre-train a FracTAL-ResUNet neural network on source-region imagery and partial field boundaries.
- Obtain remote sensing imagery of the appropriate resolution to resolve fields accurately in the target region.
- Create partial labels for a representative sample of fields across the target region.
- Fine-tune the neural network on a training set of labels in the target region.
- Evaluate the neural network on a test set of labels in the target region. Repeat Steps 3 and 4 until model performance is satisfactory.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Details about Airbus Imagery




Appendix A.2. Interpreting Pixel-Level Metrics
- Accuracy and F1-score appear to be high (values ) because of class imbalance. Most pixels in our sampled images are inside a crop field rather than on the boundary, so just by predicting that all pixels are inside a field one can achieve a high accuracy or F1-score. In our results (Table 3 and Table 4), an overall accuracy of 0.82 and F1-score of 0.89 correspond to a low IoU of 0.52 (Planet imagery in India). Since class imbalance is likely to exist in most field delineation problems globally, we caution against the use of accuracy and F1-score to interpret field delineation results.
- MCC is deflated when evaluated on partial labels instead of full labels; as a consequence, MCC values in this work appear lower than MCC values reported in prior work ([23,31]). Instance-level assessments, such as median IoU, do not suffer from this issue. For example, our FracTAL-ResUNet achieves an MCC of 0.73 when trained and evaluated on full field labels in France (Table 3), which is comparable to recent operationalized field delineation in Australia [31]. However, the same model trained and evaluated on partial field labels achieves an MCC of 0.50. In both cases, median IoU across fields is 0.70 (Table 4). The decrease in MCC is because full labels evaluate performance over non-crop area as well, and non-crop is easier to classify than field boundaries.
- Empirically, differences in accuracy, F1-score, and MCC reflect relative performance among experiments using the same imagery and labels. However, they do not capture the magnitude of differences in IoU when comparing across experiments using different imagery and labels. For example, in Table 3, the best Planet model achieves an accuracy of 0.82, F1-score of 0.89, and MCC of 0.52 in India. The best Airbus model achieves an accuracy of 0.90, F1-score of 0.95, and MCC of 0.51 in India. Comparing pixel-level metrics alone, the two models do not appear extremely different. However, the Planet model achieves an mIoU of 0.52 and the Airbus model achieves an mIoU of 0.85. The Airbus model is significantly better. To investigate why this might happen, we visualize images where MCC is higher on Planet imagery than Airbus imagery, but IoU is lower (Figure A8). One can see that MCC treats all pixels in an image equally, whereas watershed segmentation is highly affected by lines within a field. A thin line inside a field may only decrease pixel-level metrics slightly, but it can decrease IoU dramatically by breaking one field into two. Differences in label resolution may also play a role; Planet labels are lower in resolution than Airbus labels and our results suggest this may bias pixel-level metrics upward.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Imagery | India | |
|---|---|---|
| mIoU | IoU | |
| Airbus full resolution (1.5 m) | 0.85 | 0.90 |
| Airbus 2× downsampled (3.0 m) | 0.80 | 0.88 |
| Airbus 3× downsampled (4.5 m) | 0.65 | 0.73 |
References
- Fritz, S.; See, L.; McCallum, I.; You, L.; Bun, A.; Moltchanova, E.; Duerauer, M.; Albrecht, F.; Schill, C.; Perger, C.; et al. Mapping global cropland and field size. Glob. Chang. Biol. 2015, 21, 1980–1992. [Google Scholar] [CrossRef]
- Yan, L.; Roy, D. Conterminous United States crop field size quantification from multi-temporal Landsat data. Remote Sens. Environ. 2016, 172, 67–86. [Google Scholar] [CrossRef] [Green Version]
- Wit, A.J.W.D.; Clevers, J.G.P.W. Efficiency and accuracy of per-field classification for operational crop mapping. Int. J. Remote Sens. 2004, 25, 4091–4112. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Wang, S.; Azzari, G.; Lobell, D.B. Crop type mapping without field-level labels: Random forest transfer and unsupervised clustering techniques. Remote Sens. Environ. 2019, 222, 303–317. [Google Scholar] [CrossRef]
- Lambert, M.J.; Traoré, P.C.S.; Blaes, X.; Baret, P.; Defourny, P. Estimating smallholder crops production at village level from Sentinel-2 time series in Mali’s cotton belt. Remote Sens. Environ. 2018, 216, 647–657. [Google Scholar] [CrossRef]
- Lobell, D.B.; Thau, D.; Seifert, C.; Engle, E.; Little, B. A scalable satellite-based crop yield mapper. Remote Sens. Environ. 2015, 164, 324–333. [Google Scholar] [CrossRef]
- Maestrini, B.; Basso, B. Predicting spatial patterns of within-field crop yield variability. Field Crops Res. 2018, 219, 106–112. [Google Scholar] [CrossRef]
- Kang, Y.; Özdoğan, M. Field-level crop yield mapping with Landsat using a hierarchical data assimilation approach. Remote Sens. Environ. 2019, 228, 144–163. [Google Scholar] [CrossRef]
- Donohue, R.J.; Lawes, R.A.; Mata, G.; Gobbett, D.; Ouzman, J. Towards a national, remote-sensing-based model for predicting field-scale crop yield. Field Crops Res. 2018, 227, 79–90. [Google Scholar] [CrossRef]
- Schwalbert, R.A.; Amado, T.; Corassa, G.; Pott, L.P.; Prasad, P.; Ciampitti, I.A. Satellite-based soybean yield forecast: Integrating machine learning and weather data for improving crop yield prediction in southern Brazil. Agric. For. Meteorol. 2020, 284, 107886. [Google Scholar] [CrossRef]
- Al-Gaadi, K.A.; Hassaballa, A.A.; Tola, E.; Kayad, A.G.; Madugundu, R.; Alblewi, B.; Assiri, F. Prediction of Potato Crop Yield Using Precision Agriculture Techniques. PLoS ONE 2016, 11, e0162219. [Google Scholar] [CrossRef] [Green Version]
- Bramley, R.G.V.; Ouzman, J. Farmer attitudes to the use of sensors and automation in fertilizer decision-making: Nitrogen fertilization in the Australian grains sector. Precis. Agric. 2019, 20, 157–175. [Google Scholar] [CrossRef]
- Carter, M.R. Identification of the Inverse Relationship between Farm Size and Productivity: An Empirical Analysis of Peasant Agricultural Production. Oxf. Econ. Pap. 1984, 36, 131–145. [Google Scholar] [CrossRef]
- Chand, R.; Prasana, P.A.L.; Singh, A. Farm Size and Productivity: Understanding the Strengths of Smallholders and Improving Their Livelihoods. Econ. Political Wkly. 2011, 46, 5–11. [Google Scholar]
- Rada, N.E.; Fuglie, K.O. New perspectives on farm size and productivity. Food Policy 2019, 84, 147–152. [Google Scholar] [CrossRef]
- Segoli, M.; Rosenheim, J.A. Should increasing the field size of monocultural crops be expected to exacerbate pest damage? Agric. Ecosyst. Environ. 2012, 150, 38–44. [Google Scholar] [CrossRef]
- Schaafsma, A.; Tamburic-Ilincic, L.; Hooker, D. Effect of previous crop, tillage, field size, adjacent crop, and sampling direction on airborne propagules of Gibberella zeae/Fusarium graminearum, fusarium head blight severity, and deoxynivalenol accumulation in winter wheat. Can. J. Plant Pathol. 2005, 27, 217–224. [Google Scholar] [CrossRef]
- Fahrig, L.; Girard, J.; Duro, D.; Pasher, J.; Smith, A.; Javorek, S.; King, D.; Lindsay, K.F.; Mitchell, S.; Tischendorf, L. Farmlands with smaller crop fields have higher within-field biodiversity. Agric. Ecosyst. Environ. 2015, 200, 219–234. [Google Scholar] [CrossRef]
- Šálek, M.; Hula, V.; Kipson, M.; Daňková, R.; Niedobová, J.; Gamero, A. Bringing diversity back to agriculture: Smaller fields and non-crop elements enhance biodiversity in intensively managed arable farmlands. Ecol. Indic. 2018, 90, 65–73. [Google Scholar]
- Persello, C.; Tolpekin, V.; Bergado, J.; de By, R. Delineation of agricultural fields in smallholder farms from satellite images using fully convolutional networks and combinatorial grouping. Remote Sens. Environ. 2019, 231, 111253. [Google Scholar] [CrossRef] [PubMed]
- Agence de Services et de Paiement. Registre Parcellaire Graphique (RPG): Contours des Parcelles et îlots Culturaux et Leur Groupe de Cultures Majoritaire. 2019. Available online: https://www.data.gouv.fr/en/datasets/registre-parcellaire-graphique-rpg-contours-des-parcelles-et-ilots-culturaux-et-leur-groupe-de-cultures-majoritaire/ (accessed on 1 July 2021).
- Waldner, F.; Diakogiannis, F.I. Deep learning on edge: Extracting field boundaries from satellite images with a convolutional neural network. Remote Sens. Environ. 2020, 245, 111741. [Google Scholar] [CrossRef]
- Vlachopoulos, O.; Leblon, B.; Wang, J.; Haddadi, A.; LaRocque, A.; Patterson, G. Delineation of Crop Field Areas and Boundaries from UAS Imagery Using PBIA and GEOBIA with Random Forest Classification. Remote Sens. 2020, 12, 2640. [Google Scholar] [CrossRef]
- North, H.C.; Pairman, D.; Belliss, S.E. Boundary Delineation of Agricultural Fields in Multitemporal Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 237–251. [Google Scholar] [CrossRef]
- Yan, L.; Roy, D. Automated crop field extraction from multi-temporal Web Enabled Landsat Data. Remote Sens. Environ. 2014, 144, 42–64. [Google Scholar] [CrossRef] [Green Version]
- Rahman, M.S.; Di, L.; Yu, Z.; Yu, E.G.; Tang, J.; Lin, L.; Zhang, C.; Gaigalas, J. Crop Field Boundary Delineation using Historical Crop Rotation Pattern. In Proceedings of the 2019 8th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Istanbul, Turkey, 16–19 July 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Aung, H.L.; Uzkent, B.; Burke, M.; Lobell, D.; Ermon, S. Farm Parcel Delineation Using Spatio-Temporal Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Masoud, K.M.; Persello, C.; Tolpekin, V.A. Delineation of Agricultural Field Boundaries from Sentinel-2 Images Using a Novel Super-Resolution Contour Detector Based on Fully Convolutional Networks. Remote Sens. 2020, 12, 59. [Google Scholar] [CrossRef] [Green Version]
- Rydberg, A.; Borgefors, G. Integrated method for boundary delineation of agricultural fields in multispectral satellite images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2514–2520. [Google Scholar] [CrossRef]
- Waldner, F.; Diakogiannis, F.I.; Batchelor, K.; Ciccotosto-Camp, M.; Cooper-Williams, E.; Herrmann, C.; Mata, G.; Toovey, A. Detect, Consolidate, Delineate: Scalable Mapping of Field Boundaries Using Satellite Images. Remote Sens. 2021, 13, 2197. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, M.; Wang, Y.; Shang, J.; Liu, X.; Li, B.; Song, A.; Li, Q. Automated delineation of agricultural field boundaries from Sentinel-2 images using recurrent residual U-Net. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102557. [Google Scholar] [CrossRef]
- Estes, L.D.; Ye, S.; Song, L.; Luo, B.; Eastman, J.R.; Meng, Z.; Zhang, Q.; McRitchie, D.; Debats, S.R.; Muhando, J.; et al. High Resolution, Annual Maps of Field Boundaries for Smallholder-Dominated Croplands at National Scales. Front. Artif. Intell. 2022, 4, 744863. [Google Scholar] [CrossRef]
- O’Shea, T. Universal access to satellite monitoring paves the way to protect the world’s tropical forests. 2021. Available online: https://www.planet.com/pulse/universal-access-to-satellite-monitoring-paves-the-way-to-protect-the-worlds-tropical-forests (accessed on 1 July 2022).
- Airbus. Airbus OneAtlas Basemap. 2021. Available online: https://oneatlas.airbus.com/service/basemap (accessed on 3 January 2022).
- Descartes Labs. Airbus OneAtlas SPOT V2. 2022. Available online: https://descarteslabs.com/datasources/ (accessed on 1 November 2022).
- Laso Bayas, J.C.; Lesiv, M.; Waldner, F.; Schucknecht, A.; Duerauer, M.; See, L.; Fritz, S.; Fraisl, D.; Moorthy, I.; McCallum, I.; et al. A global reference database of crowdsourced cropland data collected using the Geo-Wiki platform. Sci. Data 2017, 4, 170136. [Google Scholar] [CrossRef] [PubMed]
- Planet Labs, Inc. Visual Basemaps. 2021. Available online: https://developers.planet.com/docs/data/visual-basemaps/ (accessed on 1 July 2022).
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P. Looking for Change? Roll the Dice and Demand Attention. Remote Sens. 2021, 13, 3707. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. Available online: https://link.springer.com/chapter/10.1007/978-3-319-24574-4_28 (accessed on 10 July 2020).
- Zhou, Z.H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2017, 5, 44–53. Available online: https://academic.oup.com/nsr/article/5/1/44/4093912 (accessed on 10 July 2020). [CrossRef] [Green Version]
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly Supervised Deep Learning for Segmentation of Remote Sensing Imagery. Remote Sens. 2020, 12, 207. [Google Scholar]
- Buchhorn, M.; Lesiv, M.; Tsendbazar, N.E.; Herold, M.; Bertels, L.; Smets, B. Copernicus Global Land Cover Layers—Collection 2. Remote Sens. 2020, 12, 1044. [Google Scholar] [CrossRef] [Green Version]
- Watkins, B.; van Niekerk, A. A comparison of object-based image analysis approaches for field boundary delineation using multi-temporal Sentinel-2 imagery. Comput. Electron. Agric. 2019, 158, 294–302. [Google Scholar] [CrossRef]
- Najman, L.; Cousty, J.; Perret, B. Playing with Kruskal: Algorithms for morphological trees in edge-weighted graphs. In Proceedings of the International Symposium on Mathematical Morphology; Hendriks, C.L., Borgefors, G., Strand, R., Eds.; Springer: Uppsala, Sweden, 2013; Volume 7883, Lecture Notes in Computer Science. pp. 135–146. Available online: https://hal.archives-ouvertes.fr/hal-00798621 (accessed on 1 December 2020).
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [Green Version]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zanaga, D.; Van De Kerchove, R.; De Keersmaecker, W.; Souverijns, N.; Brockmann, C.; Quast, R.; Wevers, J.; Grosu, A.; Paccini, A.; Vergnaud, S.; et al. ESA WorldCover 10m 2020 v100. 2021. Available online: https://zenodo.org/record/5571936#.Y3w5nvdByUk (accessed on 1 July 2020). [CrossRef]





| Country | Number of Images | Number of Fields | ||||
|---|---|---|---|---|---|---|
| Train | Val | Test | Train | Val | Test | |
| France | 6759 | 1546 | 1568 | 1,973,553 | 459,512 | 430,462 |
| India | 1281 | 300 | 399 | 6421 | 1500 | 1996 |
| Number of Images | Number of Fields per Image | MCC |
|---|---|---|
| 125 | 80 | 0.563 |
| 200 | 50 | 0.585 |
| 500 | 20 | 0.596 |
| 1000 | 10 | 0.597 |
| 2000 | 5 | 0.601 |
| 5000 | 2 | 0.601 |
| Model | France | India | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Planet Imagery Consensus(Apr, Jul, Oct) | Planet Imagery Consensus(Oct, Dec, Feb) | Airbus Imagery | |||||||
| OA | F1 | MCC | OA | F1 | MCC | OA | F1 | MCC | |
| Trained in France (full labels, native Planet resolution) | 0.89 | 0.88 | 0.78 | 0.74 | 0.83 | 0.32 | 0.84 | 0.91 | 0.17 |
| Trained in France (partial labels, native Planet resolution) | 0.91 | 0.95 | 0.50 | 0.79 | 0.87 | 0.35 | 0.87 | 0.92 | 0.38 |
| Trained in France (partial labels, downsampled Planet) | 0.89 | 0.93 | 0.62 | 0.76 | 0.84 | 0.39 | - | - | - |
| Pre-trained in France, fine-tuned in India (partial labels) | - | - | - | 0.82 | 0.89 | 0.52 | 0.90 | 0.95 | 0.51 |
| Trained from scratch in India (partial labels) | - | - | - | 0.81 | 0.88 | 0.48 | 0.91 | 0.95 | 0.50 |
| Model | France | India | ||||
|---|---|---|---|---|---|---|
| Planet Imagery Consensus(Apr, Jul, Oct) | Planet Imagery Consensus(Oct, Dec, Feb) | Airbus Imagery | ||||
| Median IoU | Median IoU | Median IoU | ||||
| Trained in France (full labels, native Planet resolution) | 0.67 | 0.63 | 0.32 | 0.24 | 0.30 | 0.18 |
| Trained in France (partial labels, native Planet resolution) | 0.70 | 0.68 | 0.37 | 0.33 | 0.74 | 0.69 |
| Trained in France (partial labels, downsampled Planet) | 0.65 | 0.62 | 0.32 | 0.35 | - | - |
| Pre-trained in France, fine-tuned in India (partial labels) | - | - | 0.52 | 0.52 | 0.85 | 0.89 |
| Trained from scratch in India (partial labels) | - | - | 0.50 | 0.50 | 0.85 | 0.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Waldner, F.; Lobell, D.B. Unlocking Large-Scale Crop Field Delineation in Smallholder Farming Systems with Transfer Learning and Weak Supervision. Remote Sens. 2022, 14, 5738. https://doi.org/10.3390/rs14225738
Wang S, Waldner F, Lobell DB. Unlocking Large-Scale Crop Field Delineation in Smallholder Farming Systems with Transfer Learning and Weak Supervision. Remote Sensing. 2022; 14(22):5738. https://doi.org/10.3390/rs14225738
Chicago/Turabian StyleWang, Sherrie, François Waldner, and David B. Lobell. 2022. "Unlocking Large-Scale Crop Field Delineation in Smallholder Farming Systems with Transfer Learning and Weak Supervision" Remote Sensing 14, no. 22: 5738. https://doi.org/10.3390/rs14225738
APA StyleWang, S., Waldner, F., & Lobell, D. B. (2022). Unlocking Large-Scale Crop Field Delineation in Smallholder Farming Systems with Transfer Learning and Weak Supervision. Remote Sensing, 14(22), 5738. https://doi.org/10.3390/rs14225738