
Interpretable Deep Learning Applied to Rip Current Detection and Localization



Abstract
:1. Introduction
- Lack of consideration to classify the amorphous structure of rip currents,
- AI-model interpretability, to understand whether the model is learning the correct features of a rip current and whether there are deficiencies within a model,
- Alternative data augmentation methods to enhance the generalization of an AI-model, and
- Building trust in the AI-based model predictions.
2. Methods
2.1. Training Data
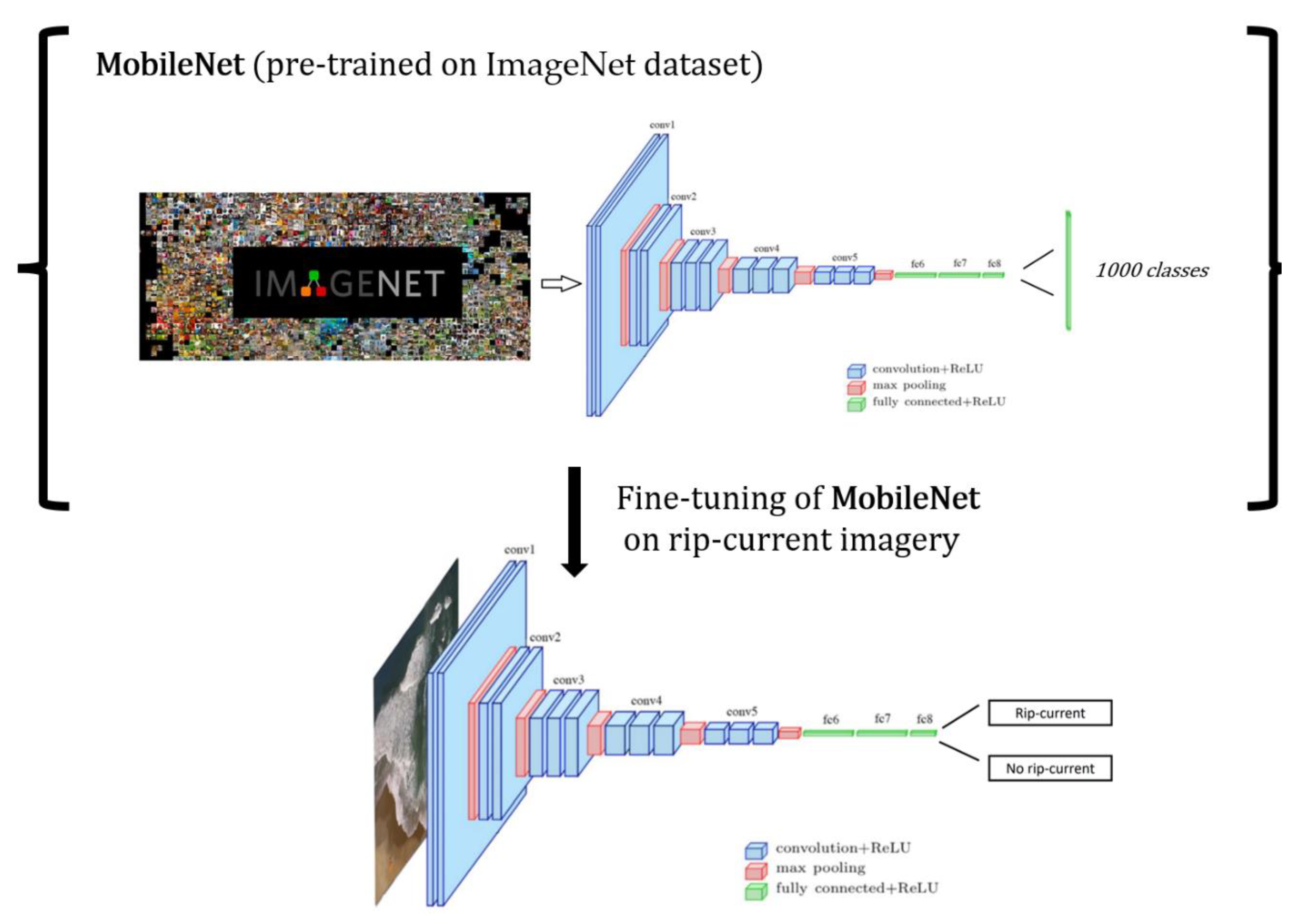
2.2. Model Architecture and Training
- The MobileNet classification head, which predicts 1000 different categories, is replaced with a new classification head consisting of only two categories—rip current and no rip current.
- Weights in the MobileNet model are frozen, and thus many layers and their corresponding weights are not trainable. Weights in deeper layers of the network are only made trainable.
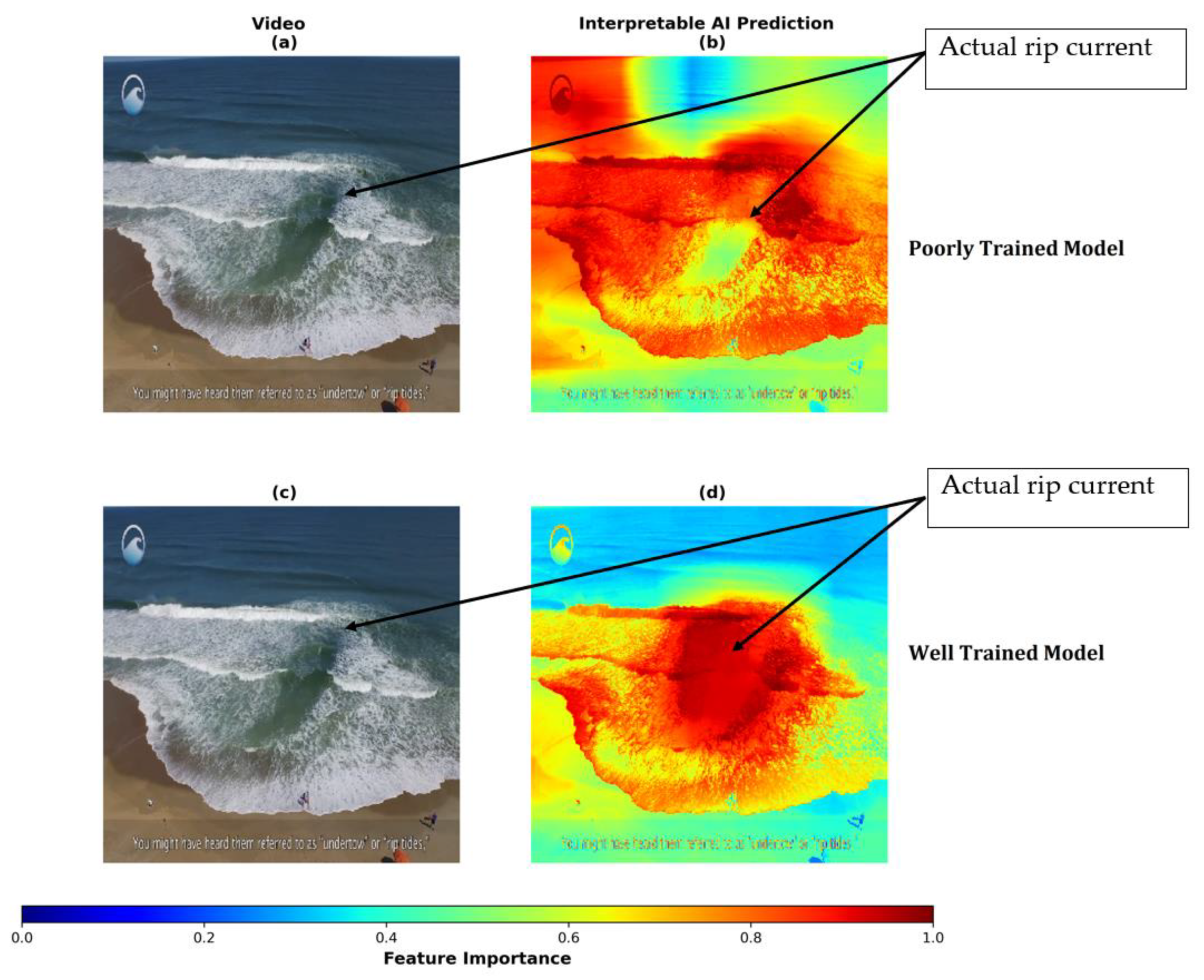
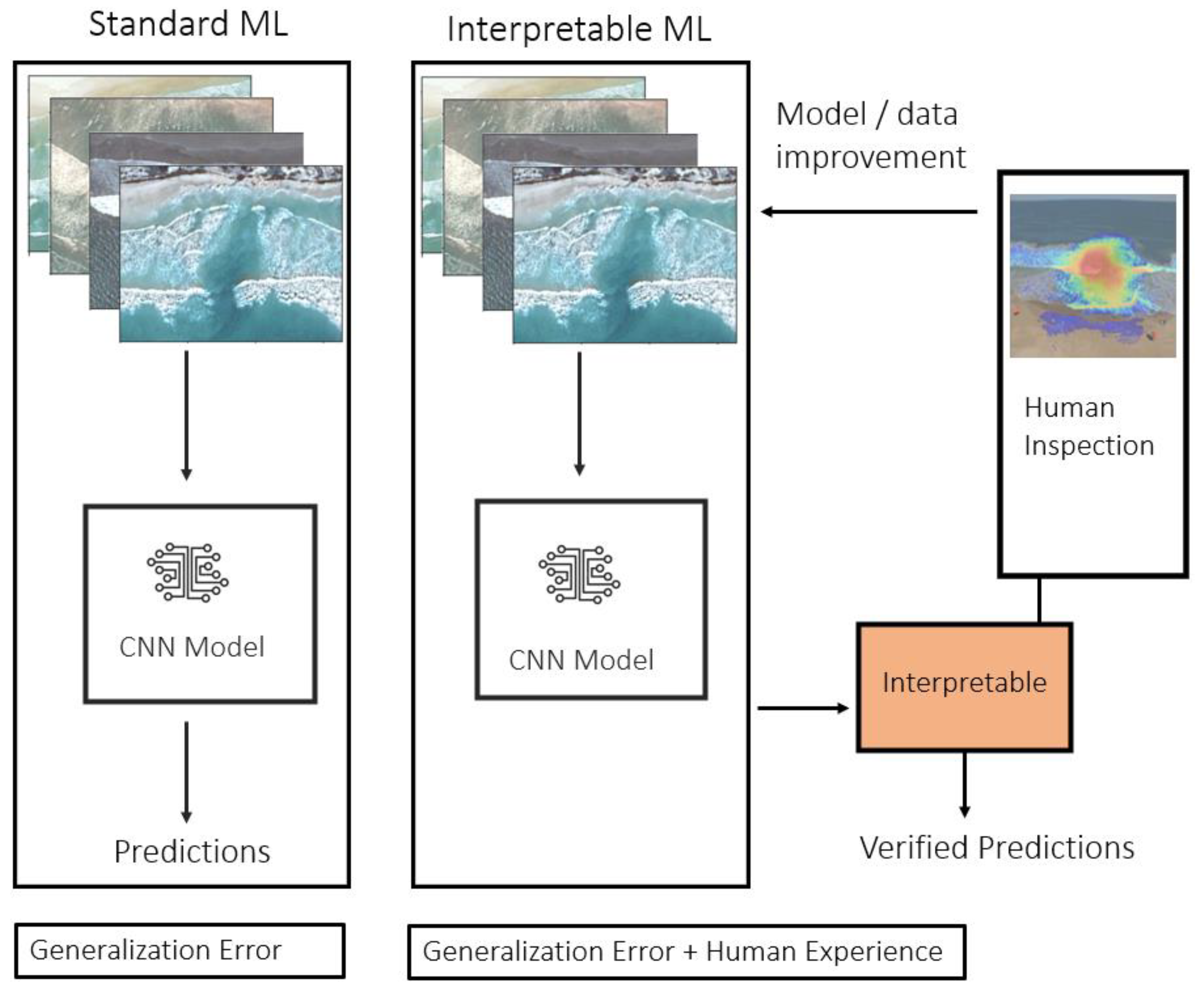
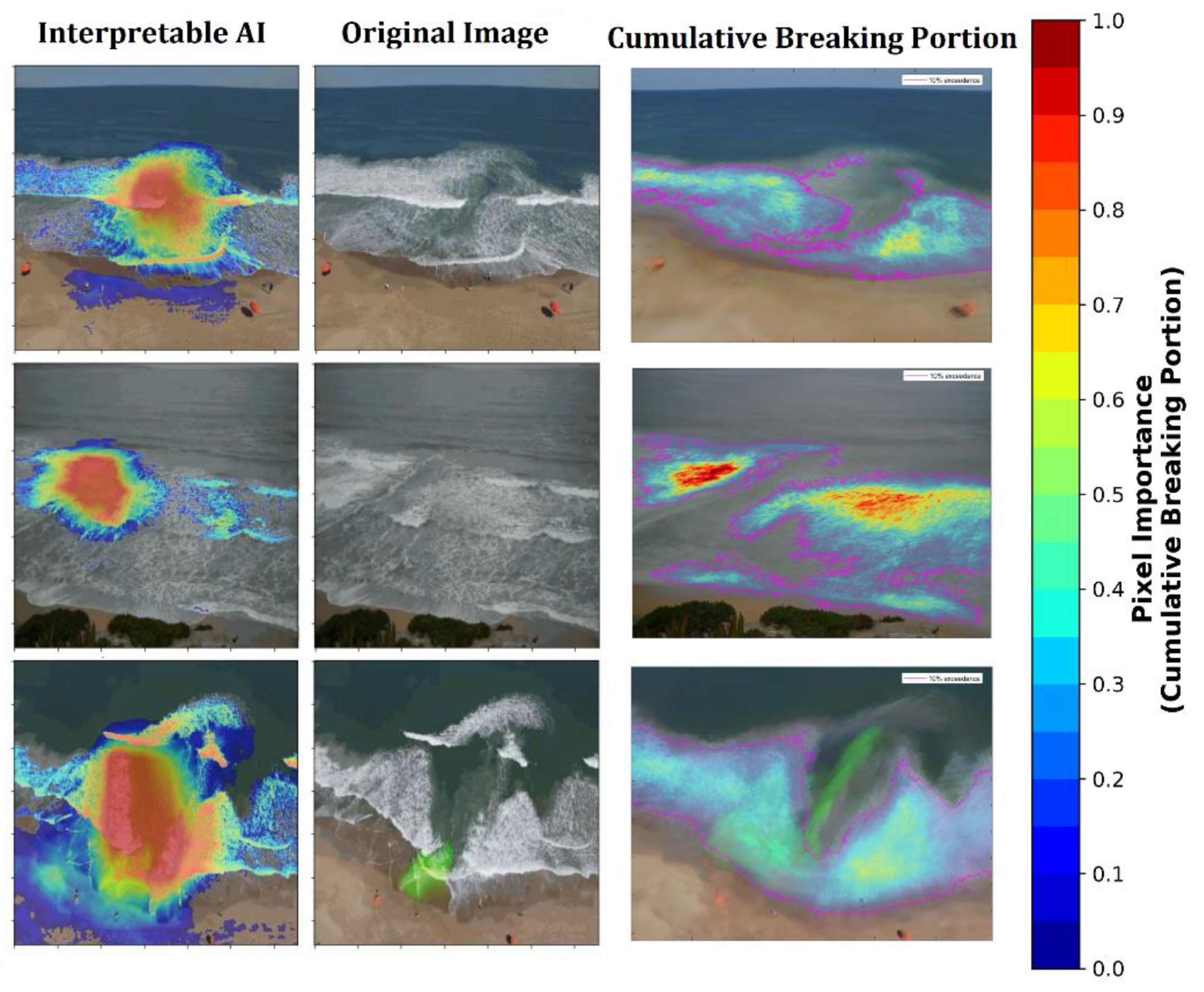
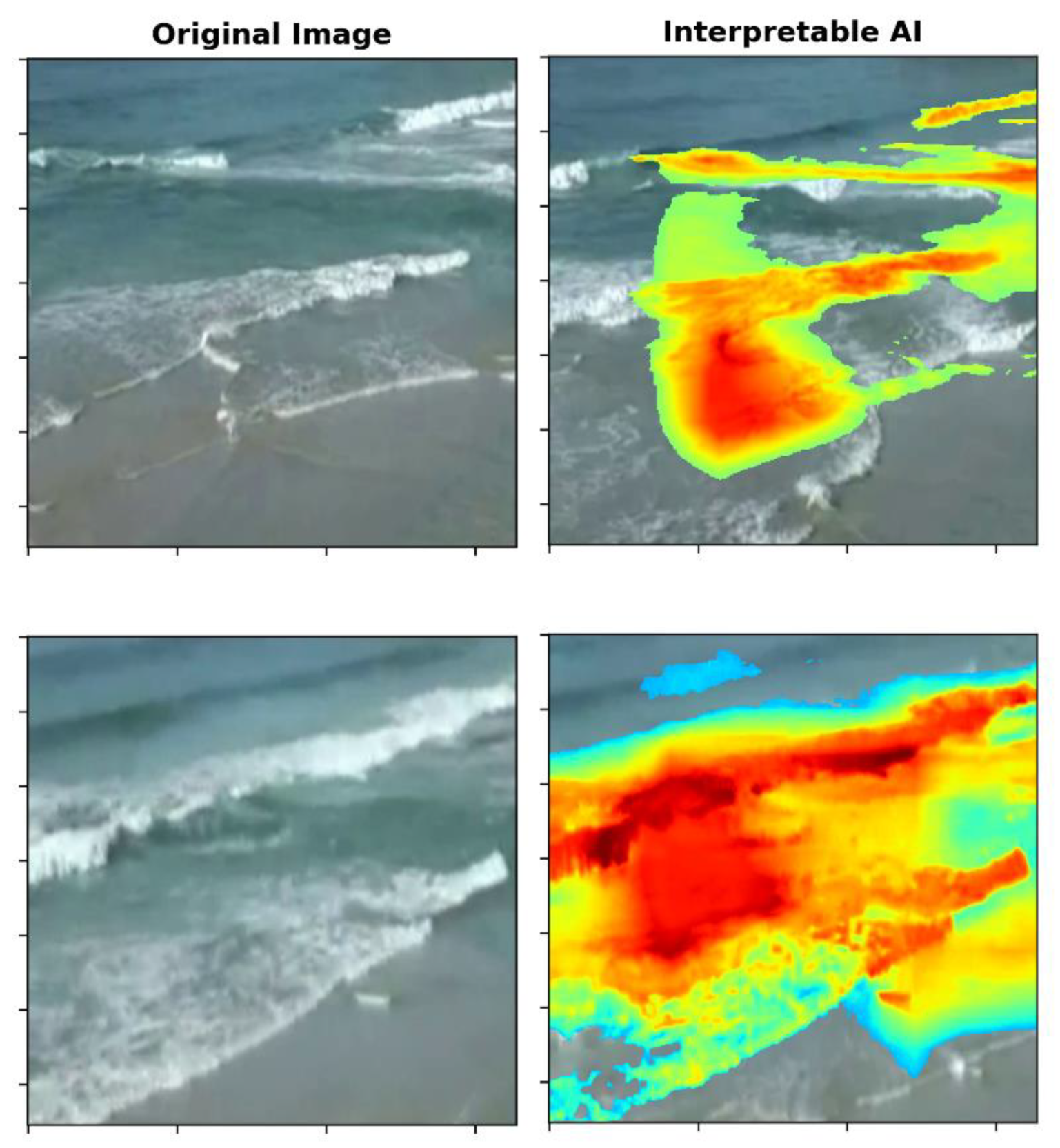
2.3. Interpretable AI
2.3.1. Model Development
- (1)
- Train AI-based model initially on training dataset (images of rip currents),
- (2)
- Evaluate traditional performance metrics (e.g., accuracy score) and Grad-CAM heatmaps for each prediction,
- (3)
- Predictions from the AI-based model (Grad-CAM) are thoroughly screened to identify whether there are systematic issues in the model (e.g., is Grad-CAM performing more poorly in some videos than others),
- (4)
- Devise a data augmentation scheme to mitigate these systematic issues.
3. Results
4. Discussion
Method Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Name | (de Silva, Mori et al. 2021) | This Study | ||
|---|---|---|---|---|
| Video Name | Human | F-RCNN | F-RCNN + FA | MobileNet |
| rip_01.mp4 | 0.976 | 0.966 | 1.000 | 1.000 |
| rip_02.mp4 | 0.700 | 0.776 | 0.860 | 0.840 |
| rip_03.mp4 | 0.231 | 0.831 | 0.950 | 0.340 |
| rip_04.mp4 | 0.757 | 0.939 | 0.970 | 1.000 |
| rip_05.mp4 | 0.883 | 0.834 | 0.957 | 0.920 |
| rip_06.mp4 | 0.881 | 0.753 | 0.890 | 0.550 |
| rip_08.mp4 | 0.492 | 0.860 | 0.850 | 1.000 |
| rip_11.mp4 | 0.824 | 0.930 | 0.951 | 1.000 |
| rip_12.mp4 | 1.000 | 1.000 | 1.000 | 1.000 |
| rip_15.mp4 | 0.967 | 0.760 | 0.870 | 0.350 |
| rip_16.mp4 | 0.614 | 0.820 | 0.920 | 0.980 |
| rip_17.mp4 | 1.000 | 0.980 | 1.000 | 1.000 |
| rip_18.mp4 | 0.563 | 0.790 | 0.890 | 1.000 |
| rip_21.mp4 | 0.901 | 0.940 | 1.000 | 1.000 |
| rip_22.mp4 | 0.583 | 0.880 | 0.974 | 1.000 |
| Rip Scene Average | 0.760 | 0.870 | 0.940 | 0.870 |
| no_rip_01.mp4 | 0.986 | 0.813 | 1.000 | 1.000 |
| no_rip_02.mp4 | 1.000 | 0.807 | 1.000 | 1.000 |
| no_rip_03.mp4 | 0.919 | 0.984 | 1.000 | 1.000 |
| no_rip_04.mp4 | 0.952 | 0.835 | 1.000 | 1.000 |
| no_rip_05.mp4 | 0.903 | 0.833 | 1.000 | 0.870 |
| no_rip_06.mp4 | 1.000 | 0.875 | 1.000 | 0.650 |
| no_rip_07.mp4 | 0.983 | 0.875 | 1.000 | 1.000 |
| no_rip 11.mp4 | 0.988 | 0.924 | 1.000 | 1.000 |
| No Rip Scene Average | 0.966 | 0.868 | 1.000 | 0.940 |
| Average | 0.830 | 0.870 | 0.960 | 0.890 |

References
- Castelle, B.; Scott, T.; Brander, R.W.; McCarroll, R.J. Rip current types, circulation and hazard. Earth Sci. Rev. 2016, 163, 1–21. [Google Scholar] [CrossRef]
- Dusek, G.; Seim, H. A Probabilistic Rip Current Forecast Model. J. Coast. Res. 2013, 29, 909–925. [Google Scholar] [CrossRef]
- Arun Kumar, S.V.V.; Prasad, K.V.S.R. Rip current-related fatalities in India: A new predictive risk scale for forecasting rip currents. Nat. Hazards 2014, 70, 313–335. [Google Scholar] [CrossRef]
- Mucerino, L.; Carpi, L.; Schiaffino, C.F.; Pranzini, E.; Sessa, E.; Ferrari, M. Rip current hazard assessment on a sandy beach in Liguria, NW Mediterranean. Nat. Hazards 2021, 105, 137–156. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, W.; Liu, X.; Zhang, C.; Xu, G.; Wang, B. Rip current hazard at coastal recreational beaches in China. Ocean. Coast. Manag. 2021, 210, 105734. [Google Scholar] [CrossRef]
- de Silva, A.; Mori, I.; Dusek, G.; Davis, J.; Pang, A. Automated rip current detection with region based convolutional neural networks. Coast. Eng. 2021, 166, 103859. [Google Scholar] [CrossRef]
- Voulgaris, G.; Kumar, N.; Warner, J.C. Methodology for Prediction of Rip Currents Using a Three-Dimensional Numerical, Coupled, Wave Current Model; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Brander, R.; Dominey-Howes, D.; Champion, C.; del Vecchio, O.; Brighton, B. Brief Communication: A new perspective on the Australian rip current hazard. Nat. Hazards Earth Syst. Sci. 2013, 13, 1687–1690. [Google Scholar] [CrossRef]
- Moulton, M.; Dusek, G.; Elgar, S.; Raubenheimer, B. Comparison of Rip Current Hazard Likelihood Forecasts with Observed Rip Current Speeds. Weather Forecast. 2017, 32, 1659–1666. [Google Scholar] [CrossRef]
- Carey, W.; Rogers, S. Rip Currents—Coordinating Coastal Research, Outreach and Forecast Methodologies to Improve Public Safety. In Proceedings of the Solutions to Coastal Disasters Conference 2005, Charleston, SC, USA, 8–11 May 2005; pp. 285–296. [Google Scholar]
- Brander, R.; Bradstreet, A.; Sherker, S.; MacMahan, J. Responses of Swimmers Caught in Rip Currents: Perspectives on Mitigating the Global Rip Current Hazard. Int. J. Aquat. Res. Educ. 2016, 5, 11. [Google Scholar] [CrossRef] [Green Version]
- Pitman, S.J.; Thompson, K.; Hart, D.E.; Moran, K.; Gallop, S.L.; Brander, R.W.; Wooler, A. Beachgoers’ ability to identify rip currents at a beach in situ. Nat. Hazards Earth Syst. Sci. 2021, 21, 115–128. [Google Scholar] [CrossRef]
- Brander, R.; Scott, T. Science of the rip current hazard. In The Science of Beach Lifeguarding; Tipton, M., Wooler, A., Eds.; Taylor & Francis Group: Boca Raton, FL, USA, 2016; pp. 67–85. [Google Scholar]
- Austin, M.J.; Scott, T.M.; Russell, P.E.; Masselink, G. Rip Current Prediction: Development, Validation, and Evaluation of an Operational Tool. J. Coast. Res. 2012, 29, 283–300. [Google Scholar]
- Smit, M.W.J.; Aarninkhof, S.G.J.; Wijnberg, K.M.; González, M.; Kingston, K.S.; Southgate, H.N.; Ruessink, B.G.; Holman, R.A.; Siegle, E.; Davidson, M.; et al. The role of video imagery in predicting daily to monthly coastal evolution. Coast. Eng. 2007, 54, 539–553. [Google Scholar] [CrossRef]
- Lippmann, T.C.; Holman, R.A. Quantification of sand bar morphology: A video technique based on wave dissipation. J. Geophys. Res. Ocean. 1989, 94, 995–1011. [Google Scholar] [CrossRef]
- Holman, R.A.; Lippmann, T.C.; O’Neill, P.V.; Hathaway, K. Video estimation of subaerial beach profiles. Mar. Geol. 1991, 97, 225–231. [Google Scholar] [CrossRef]
- Holman, R.A.; Stanley, J. The history and technical capabilities of Argus. Coast. Eng. 2007, 54, 477–491. [Google Scholar] [CrossRef]
- Bogle, J.A.; Bryan, K.R.; Black, K.P.; Hume, T.M.; Healy, T.R. Video Observations of Rip Formation and Evolution. J. Coast. Res. 2001, 117–127. [Google Scholar]
- Taborda, R.; Silva, A. COSMOS: A lightweight coastal video monitoring system. Comput. Geosci. 2012, 49, 248–255. [Google Scholar] [CrossRef]
- Nieto, M.A.; Garau, B.; Balle, S.; Simarro, G.; Zarruk, G.A.; Ortiz, A.; Tintoré, J.; Álvarez-Ellacuría, A.; Gómez-Pujol, L.; Orfila, A. An open source, low cost video-based coastal monitoring system. Earth Surf. Process. Landf. 2010, 35, 1712–1719. [Google Scholar] [CrossRef]
- Brignone, M.; Schiaffino, C.F.; Isla, F.I.; Ferrari, M. A system for beach video-monitoring: Beachkeeper plus. Comput. Geosci. 2012, 49, 53–61. [Google Scholar] [CrossRef]
- Simarro, G.; Ribas, F.; Álvarez, A.; Guillén, J.; Chic, Ò.; Orfila, A. ULISES: An Open Source Code for Extrinsic Calibrations and Planview Generations in Coastal Video Monitoring Systems. J. Coast. Res. 2017, 33, 1217–1227. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, C.H. Lifeguarding Operational Camera Kiosk System (LOCKS) for flash rip warning: Development and application. Coast. Eng. 2019, 152, 103537. [Google Scholar] [CrossRef]
- Mori, I.; de Silva, A.; Dusek, G.; Davis, J.; Pang, A. Flow-Based Rip Current Detection and Visualization. IEEE Access 2022, 10, 6483–6495. [Google Scholar] [CrossRef]
- Rashid, A.H.; Razzak, I.; Tanveer, M.; Hobbs, M. Reducing rip current drowning: An improved residual based lightweight deep architecture for rip detection. ISA Trans. 2022, in press. [Google Scholar] [CrossRef]
- Maryan, C.C. Detecting Rip Currents from Images. Ph.D. Thesis, University of New Orleans, New Orleans, LA, USA, 2018. [Google Scholar]
- Stringari, C.E.; Harris, D.L.; Power, H.E. A novel machine learning algorithm for tracking remotely sensed waves in the surf zone. Coast. Eng. 2019, 147, 149–158. [Google Scholar] [CrossRef]
- Sáez, F.J.; Catalán, P.A.; Valle, C. Wave-by-wave nearshore wave breaking identification using U-Net. Coast. Eng. 2021, 170, 104021. [Google Scholar] [CrossRef]
- Liu, B.; Yang, B.; Masoud-Ansari, S.; Wang, H.; Gahegan, M. Coastal Image Classification and Pattern Recognition: Tairua Beach, New Zealand. Sensors 2021, 21, 7352. [Google Scholar] [CrossRef] [PubMed]
- Dérian, P.; Almar, R. Wavelet-Based Optical Flow Estimation of Instant Surface Currents From Shore-Based and UAV Videos. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5790–5797. [Google Scholar] [CrossRef]
- Radermacher, M.; de Schipper, M.A.; Reniers, A.J.H.M. Sensitivity of rip current forecasts to errors in remotely-sensed bathymetry. Coast. Eng. 2018, 135, 66–76. [Google Scholar] [CrossRef] [Green Version]
- Anderson, D.; Bak, A.S.; Brodie, K.L.; Cohn, N.; Holman, R.A.; Stanley, J. Quantifying Optically Derived Two-Dimensional Wave-Averaged Currents in the Surf Zone. Remote Sens. 2021, 13, 690. [Google Scholar] [CrossRef]
- Rodríguez-Padilla, I.; Castelle, B.; Marieu, V.; Bonneton, P.; Mouragues, A.; Martins, K.; Morichon, D. Wave-Filtered Surf Zone Circulation under High-Energy Waves Derived from Video-Based Optical Systems. Remote Sens. 2021, 13, 1874. [Google Scholar] [CrossRef]
- Ellenson, A.N.; Simmons, J.A.; Wilson, G.W.; Hesser, T.J.; Splinter, K.D. Beach state recognition using argus imagery and convolutional neural networks. Remote Sens. 2020, 12, 3953. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Qin, Z.; Zhang, Z.; Chen, X.; Wang, C.; Peng, Y. Fd-Mobilenet: Improved Mobilenet with a Fast Downsampling Strategy. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar]
- Wu, Z.; Shen, C.; van den Hengel, A. Wider or Deeper: Revisiting the ResNet Model for Visual Recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems—Volume 1, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Rampal, N.; Gibson, P.B.; Sood, A.; Stuart, S.; Fauchereau, N.C.; Brandolino, C.; Noll, B.; Meyers, T. High-resolution downscaling with interpretable deep learning: Rainfall extremes over New Zealand. Weather. Clim. Extrem. 2022, 38, 100525. [Google Scholar] [CrossRef]
- Montavon, G.; Binder, A.; Lapuschkin, S.; Samek, W.; Müller, K.-R. Layer-wise relevance propagation: An overview. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer: Cham, Switzerland, 2019; pp. 193–209. [Google Scholar]
- Xu, F.; Uszkoreit, H.; Du, Y.; Fan, W.; Zhao, D.; Zhu, J. Explainable AI: A brief survey on history, research areas, approaches and challenges. In Proceedings of the 8th CCF International Conference on Natural Language Processing and Chinese Computing, Dunhuang, China, 9–14 October 2019; Springer: Cham, Switzerland. [Google Scholar] [CrossRef]
- Meudec, R. tf-explain. 2021. Available online: https://github.com/sicara/tf-explain (accessed on 25 August 2022).
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Bailey, D.G.; Shand, R.D. Determining large scale sandbar behaviour. In Proceedings of the 3rd IEEE International Conference on Image Processing, Lausanne, Switzerland, 19 September 1996. [Google Scholar]
- Shand, T.; Quilter, P. Surfzone Fun, v1.0 [Source Code]. 2021. Available online: https://doi.org/10.24433/CO.5658154.v1 (accessed on 25 August 2022).







| Classification Model | Architecture | Parameters (1,000,000 s) |
|---|---|---|
| Convolutional Neural Network (CNN) | 3-layer CNN with Max Pooling. Batch normalization and Dropout Regularization. | ~1 |
| Mobile Net | 28-layer CNN, Residual Blocks, Max Pooling, Batch Normalization and Dropout Regularization. | ~4 |
| Criteria for Training Dataset | Examples | Augmentation Strategy |
|---|---|---|
| Diverse range of coastlines | Rocky outcrops, continuous coastlines, buildings, forested areas, cliffs, and people. | Histogram normalization of image, channel perturbation and channel shuffling. |
| Diverse range of tidal conditions | Low, medium, and high tides. Surf and wave conditions can vary as a function to tide. | Not addressed in this work. |
| Diverse range of environmental conditions | Fog, rainfall, storms surges, sun glint, shadows, and calm weather. | Synthetic generation of fog, rainfall, sun glint, and shadows. |
| Diverse range of camera angles | Oblique, aerial, zoomed, and wide angle. | Perspective transformation, rotations, image shearing, and random image zooming. |
| Classification Model | Transfer Learning | Transfer Learning and Augmentation | Augmentation Only | No Augmentation and Transfer Learning |
|---|---|---|---|---|
| 3-layer CNN | 0.75 (0.69) | 0.59 (0.51) | ||
| MobileNet | 0.70 (0.62) | 0.89 (0.85) | 0.68 (0.56) | 0.51 (0.48) |
| Confusion Matrix | Observed | |
|---|---|---|
| Predicted | No rip current | Rip current |
| No rip current | 0.93 | 0.07 |
| Rip current | 0.12 | 0.87 |
| Approach | Example | Advantages | Disadvantages |
|---|---|---|---|
| Observation |  Source: Surflifesaving.org.nz Source: Surflifesaving.org.nz |
|
|
| Instrument deployment (i.e., drifters or dye) |  |
|
|
| Image processing–pixel intensity |  |
|
|
| Image processing–particle image velocimetry |  |
|
|
| Image processing-AI |  |
|
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rampal, N.; Shand, T.; Wooler, A.; Rautenbach, C. Interpretable Deep Learning Applied to Rip Current Detection and Localization. Remote Sens. 2022, 14, 6048. https://doi.org/10.3390/rs14236048
Rampal N, Shand T, Wooler A, Rautenbach C. Interpretable Deep Learning Applied to Rip Current Detection and Localization. Remote Sensing. 2022; 14(23):6048. https://doi.org/10.3390/rs14236048
Chicago/Turabian StyleRampal, Neelesh, Tom Shand, Adam Wooler, and Christo Rautenbach. 2022. "Interpretable Deep Learning Applied to Rip Current Detection and Localization" Remote Sensing 14, no. 23: 6048. https://doi.org/10.3390/rs14236048
APA StyleRampal, N., Shand, T., Wooler, A., & Rautenbach, C. (2022). Interpretable Deep Learning Applied to Rip Current Detection and Localization. Remote Sensing, 14(23), 6048. https://doi.org/10.3390/rs14236048