1. Introduction
Recently, Unmanned Aerial Vehicles (UAVs), commonly known as drones, have attracted much attention [
1,
2]. Drones can be deployed rapidly at a relatively low cost, in various emerging applications, e.g., aerial photography and video surveillance [
3,
4]. Intelligent processing of images or videos captured by drones is very demanding, which combines the advancements in computer vision and drones closely. Taking advantage of advances in Deep Neural Networks (DNNs) in remote sensing image processing, remarkable advances have been achieved in drone-view object detection, which aims to detect instances of objects from images captured by drones.
Existing methods focus on extracting robust features to distinguish foreground targets which contain very limited number of pixels, from the background clutter [
5,
6,
7]. There are three main types of drone-view detectors: context-based methods [
8,
9,
10], super-resolution-based (SR-based) methods [
11,
12,
13], and multi-scale representation-based (MR-based) methods [
14,
15,
16]. Despite their success in detecting objects from images captured by drones, the deployment of these detectors on drones in the real-world can be challenging. A major reason is the conflict between these models’ high computational costs and the very limited onboard computational resources. Existing drone-view detectors typically consist of complicated modules for super-resolution or context collection of Regions of Interest (RoIs) to achieve maximum accuracy. They typically involve prohibitively high computational costs.
We argue that there are large redundant computations because the existing drone-view detectors [
12,
17,
18] perform inference in a static manner. They infer all inputs with a fixed computational graph, and, thus, can not adapt to the varying complexity of the input during inference.
Figure 1 shows an example where statically and dynamically configured detectors infer easy and hard inputs by using a module for context collection. In many real-life scenes, only a small portion of inputs require the module to be specially designed for super-resolving RoIs or encoding context information. Consequently, it becomes highly desirable to design a drone-view detector with a dynamic architecture, which improves its computational efficiency through input-aware inference.
In this work, we present
Dynamic
Context
Collection
Network (DyCC-Net), a drone-view detector supporting input-aware inference. DyCC-Net can perform input-aware inference to offer a balanced trade-off between computational costs and accuracy. It can skip or execute a Context Collector module [
19] during inference, depending on the complexity of the inputs. Specifically, DyCC-Net can skip the Context Collector module to reduce the computational cost for easy inputs that can be correctly recognized without context information. Meanwhile, it can obtain high accuracy by effectively recognizing small objects in hard inputs by executing context collection. Furthermore, since the weakly supervised learning strategy for computational resource allocation lacks supervision, training the model with detection loss only may cause that it selects the context collector even for easy images. We present a
Pseudo-label-based semi-supervised
Learning strategy “Pseudo Learning”, which uses the generated pseudo labels as supervised signals to allocate appropriate computation resources effectively, depending on the inputs.
The key contributions can be summarized as follows:
- (1)
We present a drone-view detector supporting input-aware inference, called “DyCC-Net”, which skips or executes a Context Collector module depending on inputs’ complexity. Thus, it improves the inference efficiency by minimizing unnecessary computation. To the best of our knowledge, this work is the first study exploring dynamic neural networks on a drone-view detector.
- (2)
We design a core dynamic context collector module and adopt the Gumbel–Softmax function to address the issue of training networks with discrete variables.
- (3)
We propose a pseudo-labelling-based semi-supervised learning strategy, called “Pseudo Learning”, which guides the process of allocating appropriate computation resources on diverse inputs, to achieve the speed-accuracy trade-off.
We evaluate our DyCC-Net on two widely used public datasets for drone-view object detection, i.e., VisDrone2021 and UAVDT. We compare DyCC-Net with 10 state-of-the-art (SOTA) methods and find that the proposed DyCC-Net reduces the inference time of SOTA models by over 30 percent. In addition, we also find that DyCC-Net outperforms the previous models by over in .
The rest of the paper is organized as follows: First, we review the current development on drone-view object detection and give a summary of related works in
Section 2.
Section 3 introduces the preliminaries of DyCC-Net, including Feature Pyramid Network and Context Collector.
Section 4 gives details of our DyCC-Net.
Section 5 shows experiment results of DyCC-Net. Finally, the paper concludes in
Section 6.
3. Preliminaries
In this work, we adopt the Feature Pyramid Network (FPN) [
44] to extract multi-scale representations and use Context Collector [
19] to collect contextual information. In this section, for the integrity of this paper, we briefly introduce FPN and Context Collector as background knowledge.
3.1. Feature Pyramid Network
FPN [
44] can effectively build multi-scale representations from different layers in a backbone and improve the network’s performance.
Figure 2 shows that FPN utilizes the top–down pathway and lateral connections (shown with red arrows) to aggregate the detailed spatial representations from low-level layers and the rich semantic representations from high-level layers.
Mathematically, let
be the
i-th top-down layer of the FPN and
be the
i-th lateral connection of the FPN. FPN outputs a set of feature maps
, where
S is the number of FPN stages. The output
is defined as:
where
are the inputs of FPN, and
.
The lateral connection
is employed to increase or reduce the number of feature channels for the subsequent operation of feature concatenation in Equation (
1). However, the features adjusted by
generally lack contextual information, especially for tiny objects, as the size of the convolution filter is fixed and small.
Recently, a Context Collector module [
19], specially designed for drone-view detectors, was developed to improve the model’s representation capability of small-size targets. The Context Collector has improved the model’s performance in detecting small-size targets by collecting both local and global contextual cues. However, this is achieved at the cost of increased overall computation, especially for easy cases containing mostly large objects that can be detected without executing the context collector. Thus, in this paper, we develop a dynamic context collector, which dynamically adapts its structure to inputs of different complexities and perform input-aware inference. Next, we briefly introduce the Context Collector before illustrating our methodology in details.
3.2. Context Collector
Figure 3 [
19] illustrates the structure of Context Collector (CC). As it shows, CC consists of three components: a
convolutional filter, a dilated convolution for local contextual information, and a global average pooling layer for global contextual information. For the first branch, the
convolutional filter
is adopted to regulate the number of the input features
. For the second branch, a few
atrous convolution filters
with the dilation rate of
are adopted to extract local contextual features. For the last branch, a Global Average Pooling layer
is utilized to collect global context information. Then, features generated from the above branches are concatenated to obtain the final features. The above procedure can be formulated as:
The Context Collector improves the expressive power of small-size targets’ representations by collecting contextual information surrounding the targets. However, this is achieved as the cost of the increased overall computational costs, not desirable for drone-view detectors. Moreover, for some UAV images, the operation of context collection is not necessarily required to detect objects in the images. For example, when a flying drone is close to the ground the objects appear to be relatively large in the image captured by the drone. The network architecture of the detectors needs to be adaptive to the inputs, dynamically. Inspired by the success on DyNNs, we propose to integrate the dynamic mechanism into CC and design a dynamic context collector to achieve a better efficiency-accuracy trade-off.
4. Methodology
4.1. Overview
We first give the overview of the pipeline of the proposed DyCC-Net in
Figure 2. The extra core module of our DyCC-Net is the dynamic context collector module “DyCC”, in addition to the commonly used Backbone for extracting features, the standard Head for predicting the bounding box position and classification score, and a top–down pathway to obtain multi-scale representations.
Intuitively, some easy images, mainly containing large objects, can be recognized correctly without requiring rich contextual information. Therefore, a static design equipped with a contextual information collector contains computation redundancy. To alleviate such redundancy, we propose a dynamic architecture, Dynamic Context Collector (DyCC), which can skip or execute the CC module to avoid unnecessary computation for easy inputs.
DyCC aims to reduce computational costs by evaluating input images and allowing easy image to skip the Context Collector module. During training, the computational cost of DyCC-Net does not decrease because both Light and Heavy paths are executed for either easy or hard images. During inference, its computational cost decreases by executing the Light path instead of the Heavy path for easy inputs. As detailed in the lower part of
Figure 2, DyCC contains three components, i.e., a Dynamic Gate, a Heavy Path, and a Light Path. The Dynamic Gate (detailed next in
Section 4.2) is responsible for predicting a gate signal, which determines the appropriate path for different inputs, i.e., the Heavy or Light Path. The Heavy Path uses the Context Collector [
19] to perform context collection and
convolution for hard images, whereas the Light Path is a simple
convolutional layer that regulates the shapes of extracted features by a top–down pathway.
4.2. Dynamic Gate
The Dynamic Gate is designed to learn to produce a gate signal based on the feature maps of the input images. The signal is an approximate one-hot vector, which is approximately equal to a value of when selecting the Heavy Path and when selecting the Light Path. In the training stage, the two elements are multiplied by the output of the two paths, respectively. In the testing stage, the Heavy Path is bypassed and the Light Path is executed if the output of the Dynamic Gate is approximately equal to . The Dynamic Gate consists of a Gating Network and a Gating Activation Function, as detailed below.
4.2.1. Designs of Gating Network
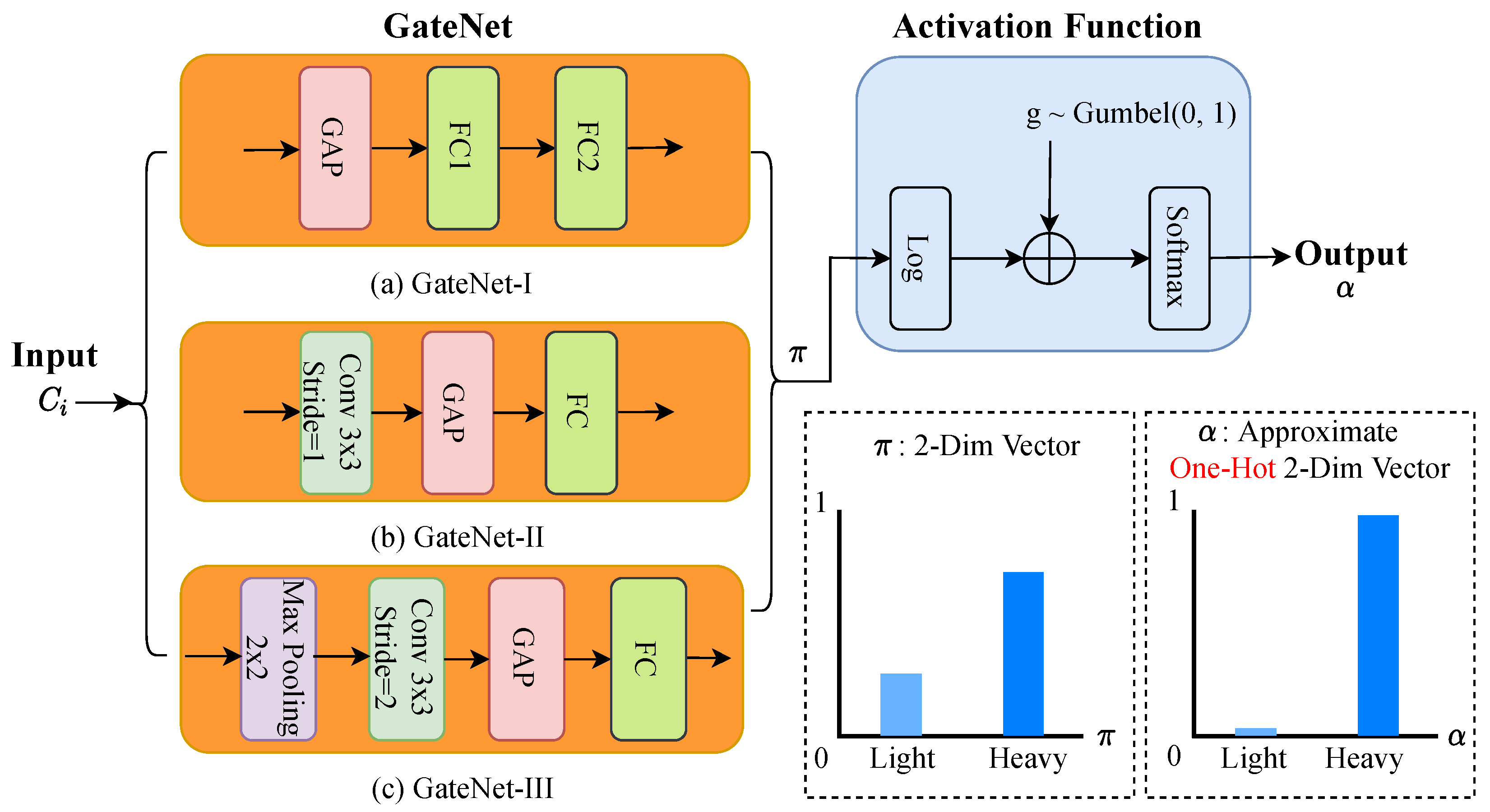
The Gating Network (GateNet) is expected to not only accurately select which path to execute and but also to be computationally inexpensive. We investigated three different designs of GateNet structures, as shown in
Figure 4. The first Gating Network, denoted by “GateNet-I” (as shown in
Figure 4a) is formed by a Global Average Pooling layer
, two fully-connected (FC) layers
, and a ReLU layer
which outputs a two-dimensional vector. Mathematically, the output of GateNet-I, denoted by
, can be defined as:
where
is the input at the
i-th layer of FPN. Let the shape of the input feature of GateNet be
and the shape of its output feature be
, the computational cost of GateNet-I is about
of the Light Path. Although its computational cost is almost negligible, the features extracted by GateNet-I lack contextual information because the direct
layer on
utilizes a
value to represent a
feature map.
A convolutional layer is utilized to enrich contextual information contained in the features.
Figure 4b compares the second design of the Gating Network “GateNet-II”, which adopts a
convolutional layer
for contextual information collection. Then, following the convolutional layer, a Global Average Pooling layer
captures the context information at image level. Finally, a fully connected layer
is adopted to calculate a two-dimensional vector. Thus, the output of GateNet-II
can be mathematically formulated:
As a less computationally expensive alternative,
Figure 4c presents the Gating Network (GateNet-III), which consists of a
Max pooling layer
, a
convolutional layer
using a stride of 2,
and
. Similarly, the output of GateNet-III
can be mathematically formulated as:
The computational cost of the GateNet-III is similar to that of the Light Path. Hence, in our experiments, we use GateNet-III to determine the gate signal.
4.2.2. Gumbel–Softmax Gating Activation Function
An appropriate path, either Heavy or Light Path, is to be selected according to the probability distribution estimated by the Gating Network. The selection process is discrete and thus non-differentiable, which poses a new challenge for training DyCC-Net.
As a natural approximation, a Softmax function is widely used by existing approaches to make soft decisions in the training stage and then to revert the soft decisions to a hard version during inference. In the hard decision version, a hard threshold is required to be set during inference. While the softmax approximation method can train the DyNNs with gradients, it leads to degraded prediction accuracy (∼40% drop [
27]) because the network with soft decisions is not trained for the hard gating in the inference stage. The Gumbel–Softmax function [
45] is adopted as the gate activation function to train the model parameters for the non-differentiable decision.
As shown in
Figure 4, Gumbel–Softmax function is utilized as a continuous, differentiable function on class probabilities
and predicts a
k-dimensional one-hot vector
:
where
,
are
i.i.d. samples drawn from Gumbel (0, 1) (The Gumbel (0, 1) distribution can be sampled using inverse transform sampling by drawing
and computing
), and
is a temperature parameter. The output of this activation function approximates a one-hot vector for a low
and converges to a uniform distribution as
increases. The Gumbel–Softmax function is a partial derivative function for the continuous distribution
. The re-parameterization trick enables gradients to flow from
to
during backward propagation.
4.3. Pseudo Learning
The loss functions of DyCC-Net includes a classification loss for estimating objects’ categories and a regression loss for estimating objects’ positions. In particular, the binary cross entropy (BCE) loss is utilized for classification, which can be expressed as:
where
y is the label of a sample, and
is the predicted probability of the sample.
GIoU [
46] is utilized for the regression of bounding boxes to address the weakness of
IoU that its value is equal to zero for non-overlapping case.
GIoU can be expressed as followed.
where
A is a position of a predicted bounding box, and
B is a position of a ground truth bounding box, and
C is the smallest convex set of
. If only the detection loss is utilized to optimize DyCC-Net, DyCC would be encouraged to take the Heavy Path as much as possible, which better minimizes the detection loss, and fail to perform input-aware inference to reduce the overall computational costs.
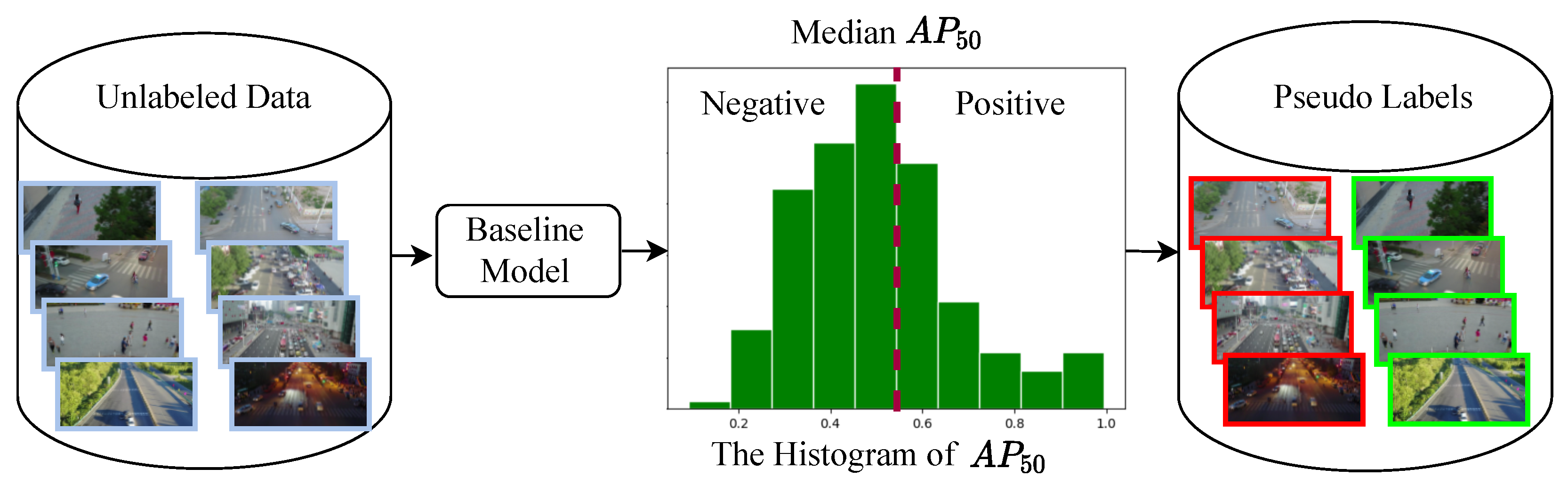
To address this issue, we propose a Pseudo-label-based semi-supervised Learning strategy for path selection. The training data used for the semi-supervised learning consist of automatically pseudo-labelled positive and negative image samples. Positive image samples refer to images, in which objects can be easily recognized by existing detectors, and, hence, “easy”. Negative image samples refer to images in which objects are hard to recognize with existing detectors and, hence, “hard”.
Figure 5 illustrates the process of the pseudo label generation. We firstly run a well-trained baseline object detection model on all images and then evaluate each image’s detection result against the median detection precision of the whole set. In this work,
is adopted to evaluate the prediction precision of each image. Images whose
scores are higher than the median
score of the whole set are labeled as positive image samples, also known as easy images, and images whose
scores are lower than the median
score are labeled as negative image samples, also known as hard images. Thus, we can generate pseudo labels for all images, which are used to train the DyCC-Net to determine whether to take the Light Path or the Heavy Path given an input image.
Some examples of positive and negative image samples are presented in
Section 5.3.4. Compared with unsupervised learning, our GateNet trained with Pseudo Learning can make a more accurate selection of the appropriate path, to obtain a better efficiency–accuracy trade-off.
Additionally, note that DyCC-Net is trained with both the generated pseudo-labels (“easy” or “hard”) and the original object detection annotations (bounding boxes and object classes) of the images to achieve high-accuracy and high-efficiency object detection from drone-view images.
6. Conclusions
In this paper, we have proposed DyCC-Net, which can perform input-aware inference for effective UAV object detection by dynamically adapting its structure to the input image. Our DyCC-Net can reduce the computational cost by input-aware inference without sacrificing prediction accuracy. To address the non-differentiability of path selection, we have introduced Gumbel–Softmax to perform gradient backpropagation during training. Moreover, we have proposed Pseudo Learning to make a more robust and accurate selection of paths based on diverse inputs.
We have evaluated DyCC-Net on two drone-captured datasets and compared DyCC-Net with 10 SOTA models. Experiment results have demonstrated that the proposed DyCC-Net has achieved high time efficiency while preserving the original accuracy. Compared with the SOTA drone-view detectors, the proposed DyCC-Net has achieved comparable accuracy with less inference time costs. Moreover, extensive ablation studies have further demonstrated the effectiveness of each module of DyCC-Net. Our DyCC-Net offers the potential to reduce computational cost and can be efficiently deployed on drones. Finally, to further address the issue that large inputs bring large computation cost, we plan to investigate spatial-wise DyNNs to explore “spatially dynamic” computation to further reduce the computational cost by processing a fraction of pixels or regions in an image.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}