1. Introduction
Hyperspectral images can capture subtle differences in reflectance of features in hundreds of narrow spectral bands, offering the possibility of accurate identification of features with comparable color and texture [
1]. Therefore, hyperspectral image classification is the cornerstone of many applications requiring high classification granularity, such as agricultural yield estimation [
2], tree species identification [
3], natural resource survey [
4], and disaster monitoring [
5], and have long been a research hotspot in the field of remote sensing. Nowadays, deep learning methods represented by 3D-CNN are capable of automatically extracting joint spatial-spectral features, and have been extensively investigated and applied in hyperspectral remote sensing applications in recent years [
6,
7,
8]. However, the raw hyperspectral data have a high redundancy, and it is difficult to obtain sufficient manually labeled samples [
9]. The available training samples in real-world hyperspectral classification tasks are often scarce and contain considerable noise. Therefore, effective dimension reduction for hyperspectral images without losing crucial spatial-spectral features and achieving satisfactory classification accuracy with as few samples as possible is still very challenging [
10,
11].
Feature extraction and representation are key steps in hyperspectral image classification tasks [
12,
13]. Prior to the widespread applications of deep learning methods, hyperspectral classification relied on hand-crafted features. The shallow features extracted by such methods could not effectively handle complex situations with inter-class nuance and large intra-class variation, and the generalization ability to various datasets with variable spatial resolution and spectral signatures was insufficient [
14,
15]. Recently, deep learning methods have been extensively investigated in hyperspectral classification due to their capability of extracting deep hierarchical features from raw images in an end-to-end learning manner and the classification accuracy has been greatly boosted compared with traditional methods [
16,
17]. 2D-CNN and 3D-CNN are two commonly used methods for extracting spatial features and spatial-spectral features from pixels to be classified and their fixed neighborhood, respectively [
18,
19,
20,
21]. Although CNN models are currently the mainstream methods for hyperspectral classification, their black-box nature leads to a lack of clear connection between classification results and spectral physical significance. To this end, Makantasis et al. proposed a novel tensor-based learning method for hyperspectral data analysis, which significantly reduces the model parameter number and clearly interprets model coefficients on the classification results [
22,
23].
In order to improve the robustness of features learned by CNN models and accelerate network training, the residual learning method inspired by ResNet [
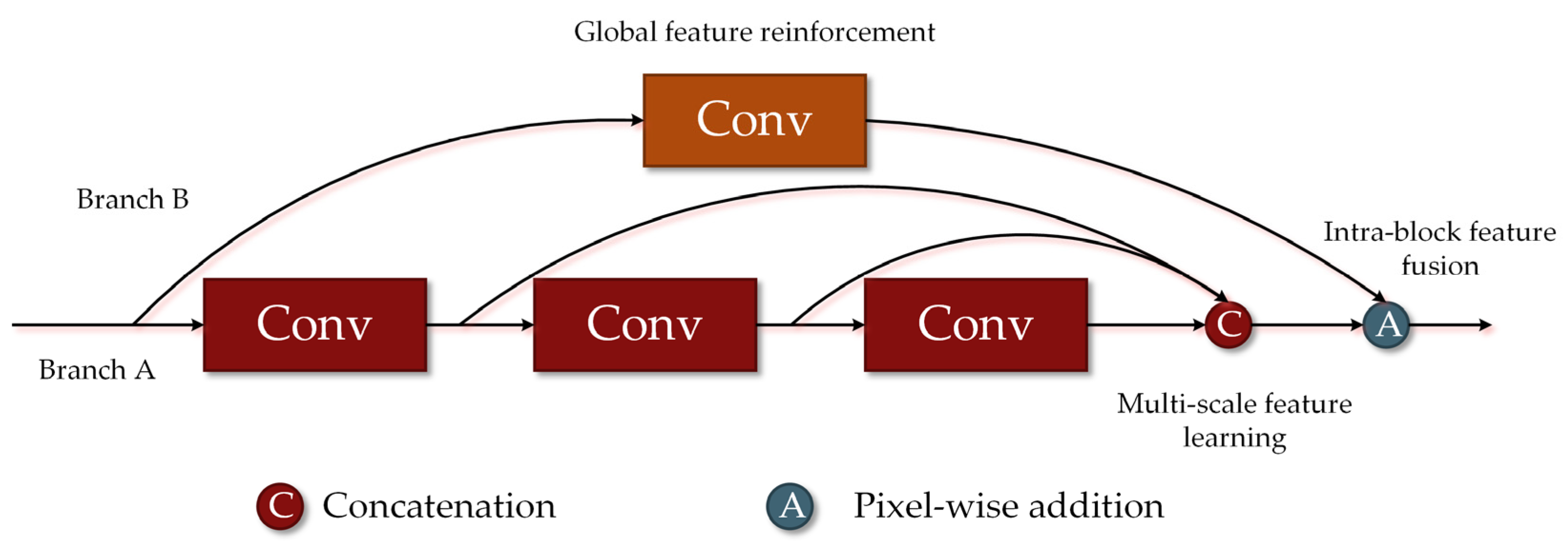
24] is widely utilized for hyperspectral classification model construction. Lee et al. proposed Contextual CNN, which first learns contextual features through parallel
,
and
convolutional kernels, and then introduces residual learning in subsequent
convolution sequences to improve classification accuracy [
25]. Liu et al. introduced residual learning in a continuous 3D convolutional sequence and constructed a deep Res-3D-CNN to learn hierarchical spatial-spectral features, which improves classification accuracy compared to shallow 3D-CNN [
26]. Song et al. proposed DFFN and deep residual learning was adopted to achieve intra-block feature fusion. The low-level, middle-level, and high-level features learned by different network parts were further fused to achieve inter-block feature fusion [
27]. Dense connections, which was proposed by Huang et al., can be viewed as an extreme version of a residual connection that the output features of all the previous layers are concatenated and sent to the next layer for feature re-using [
28]. Dense feature fusion patterns were then adopted to hyperspectral classification tasks and achieved success [
29,
30,
31]. Residual learning and dense connectivity, which are served as the core approaches of feature fusion, have profoundly influenced the designed patterns of hyperspectral classification networks. However, the literature [
32] indicated that frequent feature map concatenations based on existing deep learning frameworks could cause excessive memory consumption. Therefore, an effective and efficient feature learning pattern needs further investigation. Recently, attention-based spatial-spectral feature learning models for hyperspectral classification have gained enormous popularity and might be a solution to the above-mentioned feature learning problem [
33,
34,
35].
Hyperspectral images are characterized by high dimensionality, and it is difficult to effectively filter redundancy when features are extracted with 3D-CNN under small sample conditions. In addition, to learn features from raw hyperspectral data, nested pooling layers are often required in 3D-CNN to reduce the feature map dimension and control the network parameter scale. However, the pre-defined pooling size may be detrimental to feature extraction. To address this problem, 3D-CNN and 2D-CNN are fused to extract spatial-spectral features from the down-scaled hyperspectral images. Roy et al. proposed HybridSN, which is a mixed 3D-2D-CNN model. The principal component analysis (PCA) was firstly adopted for down-scaling, and then the pipelined stacking 3D convolutional layers and 2D convolutional layers were used to extract spatial-spectral features, effectively improving the classification accuracy compared to networks with a single type of convolution [
36]. Feng et al. proposed R-HybridSN based on residual learning and depth separable convolution, which effectively improved the obtained classification accuracy of hyperspectral images under small sample conditions [
37]. Based on R-HybridSN, Feng et al. proposed M-HybridSN of which the core feature extraction module is a combination of three densely connected
convolutional layers and one
convolutional layer for global information enhancement; Zhang et al. proposed AD-HybridSN based on dense connectivity and two attention modules with the aim of spatial-spectral feature refinement. The above two models can be viewed as improved versions of R-HybridSN, and they both improved the network’s ability to learn robust spatial-spectral features [
38,
39]. How to make better use of the features extracted by CNN is another key issue. Aiming at the limitations of existing CNN models using global average pooling or fully connected layers, Zheng et al. proposed a method of classifying the features extracted from convolutional networks by mining covariance information and designed a covariance pooling-based mixed CNN model (MCNN-CP) [
40]. The combination of mixed CNN models and dimensionality reduction algorithms will attract continuous attention due to their high classification accuracy and low computational cost.
The above residual learning and mixed CNN models are served as network optimization methods and are aimed to facilitate small sample hyperspectral classification at the network level. The training process can benefit from a large number of unlabeled samples with the help of semi-supervised learning methods, which is focused on the intra-dataset level [
41,
42,
43]. Wu et al. proposed a semi-supervised deep learning framework based on pseudo labels [
44]. A clustering method called a constrained Dirichlet process mixture model (C-DPMM) was adopted to generate pseudo labels. A classic pre-training and fine-tuning scheme was utilized to further improve the classification performance of the two convolutional recurrent neural networks (CRNN). Liu et al. proposed a deep active learning method using a densely connected CNN model [
45]. Several branches of this network formed a loss prediction model, and those samples with large predicted losses were manually labeled and re-involved in the training process. Liu et al. proposed a deep few-shot learning method (DFSL) and built a connection between an HSI domain (called target domain) with very few labeled data and another HSI domain (called source domain) with enough labeled data. The DFSL was focused on the inter-dataset level, and a deep residual 3D-CNN was adopted to learn a metric space [
46]. The well-trained network can be viewed as an embedding tool and the classification of unlabeled data can be achieved by another simple distance-based classifier. Recently, inspired by the success of DFSL, several novel few-shot learning methods have been proposed for small sample hyperspectral classification, such as deep relation network-based few-shot learning methods [
47] and deep cross domain few-shot learning methods [
48]. Few-shot learning methods have changed the paradigm of classification using features extracted by convolutional layers and opened up a promising research field for small sample hyperspectral classification. In addition, network-level optimization is of non-negligible significance. On the one hand, supervised learning methods are easy to be implemented and applied in real-world remote sensing applications, since only network-related hyperparameters need to be fine-tuned. On the other hand, advanced CNN models with a discriminative feature learning ability can be combined with the above novel learning patterns and obtain a better classification accuracy.
Based on the above observations, we proposed a mixed spatial-spectral features cascade fusion network (MSSFN) to facilitate small sample hyperspectral classification. Factor analysis is combined with our model and it can analyze the covariance structure of hyperspectral data and realize effective dimensionality reduction to improve inter-class separability. The MSSFN adopts two 3D multiple spatial-spectral residual blocks and one 2D separable multiple residual block to extract mixed spatial-spectral features. A cascade feature pattern composed of intra-block feature fusion and inter-block feature fusion was proposed to make the learned features more robust to different kinds of hyperspectral datasets. The second-order pooling is designed to further mine the higher-order statistical information of the cascade fusion features. Extensive experiments were conducted on three real-world hyperspectral datasets, and the classification accuracy of MSSFN was far better than that of the contrast models.
3. Experimental Results and Analysis
3.1. Experimental Datasets
Three real-world hyperspectral datasets with different spatial and spectral resolutions, Indian Pines (IP), Houston (HU), and University of Pavia (PU), were used for verifying the effectiveness of MSSFN. The basic information of the three datasets is shown in
Table 3. For the IP and PU datasets, the number of bands after denoising is given in
Table 3. It should be noted that the HU dataset was originally released during the 2013 Data Fusion Contest by the Image Analysis and Data Fusion Technical Committee of the IEEE Geoscience and Remote Sensing Society, so it is also named “2013_IEEE_GRSS_DF_Contest”.
In our experiments, the labeled samples of the three datasets were randomly divided into the training set, validation set and test set. In order to investigate the performance of our proposed model under small sample conditions, only 5%, 3%, and 1% of labeled samples of IP, HU, PU were used to train the model. The validation set, which has the same proportion of samples as the training set, is not involved in training and is only used to obtain the well-trained model. For the three datasets of IP, HU, and PU, the number of training samples of each class of ground object was small at the rate of 5%, 3%, and 1%, respectively. For example, some classes of the IP dataset only contain one to two training samples. The detailed distribution of training, validation, and testing samples for IP, HU, and PU datasets is shown in
Table 4,
Table 5 and
Table 6.
3.2. Contrast Models and Experimental Settings
The experimental hardware environment is R7 5800H CPU; RTX3060 graphics card with 6G video memory; 32G RAM. The software environment is Tensorflow 2.4, Python 3.7. To verify the effectiveness of MSSFN, Res-3D-CNN [
26], M-HybridSN [
38], AD-HybridSN [
39], DFFN [
27] and MCNN-CP [
40] mentioned above are selected as the contrast models for the experiments. The convolution type, number of parameters, and input data size of each model are shown in
Table 7. The input data size is expressed as the product of the input data length, width, and number of bands, taking the number of bands in the IP dataset as an example. The number of parameters and the input data size reflects the complexity of the model to a certain extent. The number of parameters of the MSSFN proposed in this paper is much less than the contrast models, and the input data size is moderate.
The various settings of the contrast models in the experiments are kept consistent with the corresponding papers. The MSSFN proposed in this paper uses Adam as the optimizer, with the learning rate set to 0.001 and the number of training epochs set to 100. The classification accuracy of the validation set is monitored during training, and the model with the highest accuracy in the validation set is saved within the specified number of training epochs.
3.3. Experimental Results
The following three widely adopted evaluation indices are used to quantitatively evaluate the performance of MSSFN and the contrast models.
- (1)
Overall accuracy (OA). It is an overall evaluation index of the classifier and it is calculated by the number of correctly classified pixels divided by the total number of pixels.
- (2)
Average accuracy (AA). This index refers to the average accuracy of all types of ground objects and it will be greatly affected by a small number of hard samples.
- (3)
Kappa coefficient. The Kappa is an index based on the confusion matrix. It is thought to be a more robust evaluation metric and it can reflect the degree of agreement between the ground truth map and the predicted map [
56].
Table 8,
Table 9 and
Table 10 show the classification results of each model for IP, HU, and PU, containing the classification accuracy of each class and the results of the three overall indicators OA, AA, and Kappa. Ten consecutive experiments were conducted using each model for each dataset, and the average accuracy was given in the three tables. For the three overall indicators, OA, AA, and Kappa, standard deviations were shown after ±. The bold format in the tables represents the best result.
From
Table 8,
Table 9 and
Table 10, it can be seen that the classification accuracy of Res-3D-CNN is significantly lower than other methods. The biggest difference is that Res-3D-CNN does not adopt prior dimensionality reduction. It is speculated that hyperspectral data redundancy has a greater adverse effect on classification accuracy when the training samples are very limited, and 2 × 2 × 4 max-pooling layer alone is not enough to remove data redundancy. The OA of DFFN using only 2D convolution outperformed the Res-3D-CNN by 9.86%, 4.38%, and 7.79% in the three datasets, IP, HU, and PU, respectively. Moreover, in IP and PU datasets, the OA of DFFN is even higher than the simpler structured mixed convolutional network, MCNN-CP. The above observations verify the importance of deep feature fusion.
The three improved mixed CNN models, M-HybridSN, AD-HybridSN, and MSSFN outperform other models, among which MSSFN proposed in this paper achieves the best OA in all datasets. For example, in the IP dataset, the OA of MSSFN was 11.42%, 1.53%, 1.41%, 1.56%, and 1.65% higher than that of Res-3D-CNN, M-HybridSN, AD-HybridSN, DFFN, and MCNN-CP, respectively; the OA of MSSFN in the PU dataset is 9.45%, 1.18%, 0.85%, 1.66%, and 1.66 higher than Res-3D-CNN, M-HybridSN, AD-HybridSN, DFFN, and MCNN-CP, respectively. In the HU datasets, although the proposed MSSFN significantly outperforms all the contrast models, all models perform poorly in this dataset. This is presumably due to the large size of the dataset, as well as the small number of available samples and the large intra-class variation. Although MSSFN achieved the highest classification accuracy in all datasets, its classification accuracy of class 9 in the IP dataset was significantly lower than the other methods. No similar phenomenon was observed in other classes or other datasets. At present, the reason behind this phenomenon is not clear, and we will pay continued attention to the issue in the future.
Figure 5,
Figure 6 and
Figure 7 show the false-color image, the ground truth, and the predicted map of each contrast model and MSSFN in IP, HU, and PU. The visual comparison results in
Figure 5,
Figure 6 and
Figure 7 and quantitative evaluation results in
Table 7,
Table 8 and
Table 9 lead to a similar conclusion. Generally speaking, there is less noise and better homogeneity in the classification result maps obtained by MSSFN for the three datasets, which are closer to the real-world distribution maps. The above results validate the effectiveness of MSSFN. The proposed classification framework composed of factor analysis, mixed spatial-spectral feature cascade fusion, and second-order pooling can learn the spatial-spectral features with stronger discriminative power.
4. Discussion
4.1. Comparison with Other Dimension Reduction Methods
In order to further explore the applicability of different dimensionality reduction (DR) methods combined with MSSFN for hyperspectral classification, PCA, sparse PCA (SPCA), Gaussian random projection (GRP), and sparse random projection (SRP) were chosen to compare with FA. The PCA is the widely adopted DR method, and the SPCA is its variant, which aims to extract the sparse components that best represent the data. GRP and SRP are two simple and computationally efficient DR methods. The dimensions and distribution of random projection matrices are controlled to preserve the pairwise distances between any two samples of the dataset. The GRP relies on a normal distribution to generate the random matrix, and the SRP relies on a sparse random matrix. Furthermore, the FA with two rotation methods, which are named FA-varimax and FA-quartimax corresponding to the maximum of variance and the quartic variance, are also adopted to compare with the original FA. The experimental settings were kept consistent with
Section 3.3. The experimental results are shown in
Table 11.
From the experimental results shown in
Table 11, it is clear that FA significantly outperforms other DR methods in the IP dataset, and the OA improves 0.40%, 0.56%, 1.02%, and 1.16% compared with PCA, SPCA, GRP, and SRP, respectively. In the HU dataset, the OA obtained by the FA method is 0.31% higher than that of PCA. The above experimental results verified the effectiveness of covariance information for hyperspectral classification. The two rotation methods of FA have a negative impact on the classification accuracy, and it is speculated that the interpretability and the discriminability of the extracted factors for the hyperspectral images are to some extent contradictory. The accuracy of SPCA is lower than that of PCA, and it varies widely in different datasets, indicating that its robustness for feature extraction of different hyperspectral data is insufficient. GRP and SRP, as random projection methods, also lack robustness for classification hyperspectral using few labeled samples, and the accuracy varies widely in IP and SA compared with other DR methods. The above results verify the effectiveness of the combination of FA and MSSFN for small sample hyperspectral classification.
4.2. Model Ablation Experiments
The MSSFN proposed in this paper is based on cascade fusion of mixed spatial-spectral features, and the higher-order statistical information of the fused features is extracted using second-order pooling. To further verify the effectiveness of the above designs, ablation experiments are conducted in this section. Four ablation models are made for this experiment, and they are named as model 1, model 2, model 3, and model 4. The description of each model and the experimental results are shown in
Table 12.
The experimental results in
Table 12 indicated that MSSFN has the best overall classification accuracy in the three datasets, verifying the effectiveness of cascade fusion and second-order pooling. The OA of MSSFN has improved by 0.40% and 0.25% over model 1 in the IP and HU datasets, respectively. It is indicated that for mixed spatial-spectral features, using pixel-by-pixel addition will cause some information loss, which is unfavorable for classification. The classification accuracy of model 2 and model 3 is lower than that of MSSFN, and the accuracy of model 2 is significantly better than that of model 3, indicating the effectiveness of the cascade feature fusion pattern consisting of inter-block feature fusion and intra-block feature fusion. The OA of MSSFN is significantly higher than that of model 4 in IP and HU datasets. Meanwhile, model 4 and MSSFN have approximately equal OA in the PU dataset, and it is presumed that the first-order statistical features are sufficient to distinguish features for the PU dataset. Since the original channel features are included in the SOP calculation process, the classification accuracy is not degraded, and the above results verify the effectiveness of SOP for hyperspectral small sample classification. However, how to better integrate the first-order features and second-order features to improve the classification accuracy for different types of hyperspectral datasets on the basis of convolutional extracted features needs further study.
4.3. The Performance of MSSFN under Extreme Small Sample Cases
The work in this paper revolves around the problems in small sample hyperspectral classification tasks, and the effectiveness of the related designs have been verified in
Section 4.1 and
Section 4.2, respectively. To further verify the applicability of MSSFN under small sample conditions, two extreme small sample cases will be considered in this section.
- (1)
Fixed small training sample ratio case. Since the training sample number of some ground objects in the IP dataset has been reduced to one at the 5% ratio, the PU and HU datasets are chosen for the fixed small sample ratio case experiments. The training sample ratios of PU and HU are further reduced to 0.75%, 0.5%, 0.25%, and 2.25%, 1.5%, 0.75% of the total number of labeled samples, respectively.
- (2)
Balanced small training sample number case. This means the training sample number of every class is equal. HU dataset with relatively low classification accuracy in
Section 3 was selected for the balanced small training sample number case experiments, and the sample number of each class is set to 10, 20 and 30, respectively.
The other experimental settings remained the same as in
Section 3. The experimental results of the above two cases are shown in
Table 13 and
Table 14, respectively.
By analyzing the above experimental results, the following conclusions can be drawn.
- (1)
MSSFN achieved the highest classification accuracy in both extreme small sample cases. Furthermore, the advantage of MSSFN over other methods enlarges with the decreasing sample size. Therefore, the experimental results in this section further validate the effectiveness of our proposed methods in the extreme small sample cases.
- (2)
The classification accuracy of all models degrades when the number of training samples decreases. The relative ranking relationships between the classification accuracy of each model remain the same. Meanwhile, the accuracy gap gradually enlarges. In general, the three improved mixed CNN models, namely M-HybridSN, AD-HybridSN, and MSSFN, have obvious advantages compared with other models in extreme small sample cases. It can be inferenced that the superiority in terms of low parameter number and network structure is stable in small sample hyperspectral classification tasks. The lower the sample size is, the more noticeable this advantage is compared with other models.
- (3)
The sample distribution has a significant influence on classification accuracy. In the balanced small training sample number case, the AA values of all models are larger than the OA. In the fixed small training sample ratio case, this is the other way round. In the real-world hyperspectral classification tasks, we believe that the fixed training sample ratio case is more common, since there exist giant variabilities in the difficulty of labeling different kinds of ground objects. Since AA is a vital evaluation metric, the active learning strategy can be adopted to manually label valuable samples. The sample distribution and active learning need further investigation.
4.4. Computional Time
The computational time of most current 3D-CNN-based spatial-spectral methods for hyperspectral classification is very long and affects its practicability in real-world hyperspectral classification tasks. Therefore, computational time has had considerable attention paid to it in our research from the very beginning. Many factors affect the running time of the model, such as hardware environment, model parameters, frequency of residual connections usage, structural complexity, etc. In this section, the lightweight design of MSSFN will be introduced, and the running time of MSSFN and the contrast models will be discussed and analyzed.
The parameter scale of MSSFN is much smaller than the contrast models, and due to this, the convolutional kernels in MSSFN are designed in a spatial-spectral separable manner. For example, the 7 × 7 × 7 convolutional kernel is divided into two 7 × 7 × 1 and 1 × 1 × 7 kernels for the two 3D multiple residual blocks. The above spatial-spectral separable manner will significantly reduce the parameter number and computation time. The depth-separable convolutional layers are adopted in our model, and they are computationally efficient.
Table 15 shows the training time and testing time of MSSFN and each contrast model in the IP dataset, which has the largest training sample number (512) and the longest training time. The running time results in the table are the average running time of ten experiments.
Res-3D-CNN focuses on analyzing the raw hyperspectral data and extracting spatial-spectral features using continuous 3 × 3 × 3 convolutional layers; DFFN improves classification accuracy by stacking 2D residual blocks, and it has far more layers than other models. The running time of Res-3D-CNN and DFFN is much longer than the other models, indicating that excessive usage of the 3D convolutional layer and deep network has a negative influence on the running time. As for the four mixed CNN models, M-HybridSN, AD-HybridSN, MCNN-CP, and MSSFN, it seems that the complexity of the network structure has a great influence on the running time. MCNN-CP, with the simplest structure, has the shortest running time, but its classification accuracy is not ideal in our experiments.
M-HybridSN and AD-HybridSN do not adopt a global feature fusion scheme, and the features learned by the shallow layers of the network cannot directly affect the final classification. On the contrary, our proposed MSSFN adopts a cascade feature fusion pattern and improves the hyperspectral classification accuracy under small sample conditions. The running time of MSSFN is shorter than that of Res-3D-CNN and DFFN. As an improved mixed convolutional network model, MSSFN has prominent lightweight characteristics compared with 3D-CNN with a similar layer number and deeper 2D-CNN. However, the running time of MSSFN is longer than that of M-HybridSN and AD-HybridSN, which can be seen as the cost of model complexity. Frequent feature fusions result in intermediate results that must be saved and taken into account when calculating gradients. This case will increase the training time. We believe that the computational time of MSSFN is moderate and acceptable, but we will continue to pay attention to this issue, look for a more lightweight network design scheme, and strive to improve the classification accuracy without increasing the running time.
4.5. Comparison with Other Methods Which Are Not Focused on CNN Architectures
Some advanced CNN-based models have been compared with MSSFN, and in-depth analysis of MSSFN has been provided in terms of ablation experiments, running time, and extreme small sample cases in the above sections. As discussed in the introduction, many researchers have proposed some novel methods which are not focused on CNN architectures for small sample hyperspectral classification. Aiming at clearly locating the meaning and value of MSSFN in the field of hyperspectral classification, some recently released and advanced methods have been investigated and will be compared with MSSFN near the end of this paper. The additional contrast methods are Rank-1 FNN [
22], SS-LSTM [
57], S-DMM [
58], and A-SPN [
59]. A brief introduction to the above methods is as follows, and they are not focused on CNN architectures.
- (1)
Rank-1 FNN. The Rank-1 FNN is a tensor-based method, and the weight parameters satisfy the rank-1 canonical decomposition property. The parameters required to train the classifier have been significantly reduced, and this method can provide a clear explanation of hyperspectral classification results.
- (2)
SS-LSTM. The SS-LSTM was based on Long Short-Term Memory (LSTM) networks, and it has two branches. Spatial-spectral feature learning is reflected in the different ways of organizing hyperspectral input data in each branch.
- (3)
S-DMM. This method is based on deep metric learning. A simple 2D-CNN was adopted as the feature embedding tool, and a distance-based classifier, KNN, was used for classifying the unseen data.
- (4)
A-SPN. PCA, Batch Normalization, L2 normalization are adopted to extract first-order features. The spatial attention and second-order pooling are combined to extract higher-order features. This pure attention-based method abandons complex hyperparameters of convolutional layer and has obvious lightweight characteristics.
We have trained the A-SPN model from scratch, during which we used some public available codes which can be found at
https://github.com/ZhaohuiXue/A-SPN-release (accessed on 13 January 2022). As for the other methods, the experimental results reported in the literature [
10,
22] will be used for comparison. The experimental dataset is PU. 10, 50, and 100 samples for every class will be randomly selected as the training set, respectively. The comparison results are shown in
Table 16.
By analyzing the above experimental results, the following conclusions can be drawn.
- (1)
The OA comparison with some advanced methods which are not focused on CNN architectures further verify the effectiveness and research value of MSSFN.
- (2)
A-SPN can obtain competitive classification accuracies. Considering that it is a classification framework only consisting of PCA, normalization technologies, and attention-based second-order pooling, such a performance is very impressive. The pure attention-based models will have continued attention paid to them in our future research.
- (3)
The S-DMM, which is based on deep metric learning, can obtain a good accuracy under small sample conditions. However, when the training sample is increased from 50 to 100, the increase in accuracy is not significant. It is speculated that the feature learning ability of the feature embedding model is not sufficient. Our proposed model will be considered to combine with metric learning to further improve the classification accuracy.
Based on the above observations, we will keep studying how to further optimize the structure of MSSFN on the one hand, and explore how to break through the limitations of CNN-based methods and how to effectively integrate CNN with other methods on the other hand.
5. Conclusions
In order to facilitate the small sample hyperspectral classification, the mixed spatial-spectral feature fusion network, MSSFN, is proposed based on factor analysis, mixed spatial-spectral feature cascade fusion, and second-order pooling. First, the covariance structure of hyperspectral data is modeled by factor analysis, and the raw data is downscaled. Then, the mixed spatial-spectral features are extracted by two 3D multi-residual modules and one 2D multi-residual module, and the features extracted by the three modules are concatenated. Finally, the second-order statistical features of the fused features are extracted by second-order pooling, and classification is achieved by the fully connected layer. In the experiments with three real-world hyperspectral datasets with different spatial resolutions and spectral characteristics, IP, HU, and PU, with very few samples, MSSFN achieves the best classification accuracy compared with other models. The extensive experimental results verify the effectiveness of MSSFN in the small sample hyperspectral classification tasks.
Although MSSFN has an ideal performance in small sample hyperspectral classification, the improvement of second-order pooling in some datasets is not so obvious. How to better integrate the first-order and second-order features to improve the classification accuracy for different types of hyperspectral datasets needs further study. In our research, FA is used for dimension reduction, and its effectiveness has been verified through ablation experiments. In our future research, dimensionality reduction methods that can be effectively paired with a mixed CNN model will receive continued attention. Furthermore, deep few-shot learning and deep active learning will be paid more attention and our proposed MSSFN can be used as a baseline model. In addition, MSSFN contains some modular, highly re-usable designs, and they can be improved or applied in other remote sensing image classification tasks. We hope that the above designs will be inspiring to other researchers and the ideas behind our proposed MSSFN can be further expanded.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}