
Air-Ground Multi-Source Image Matching Based on High-Precision Reference Image


Abstract
:1. Introduction
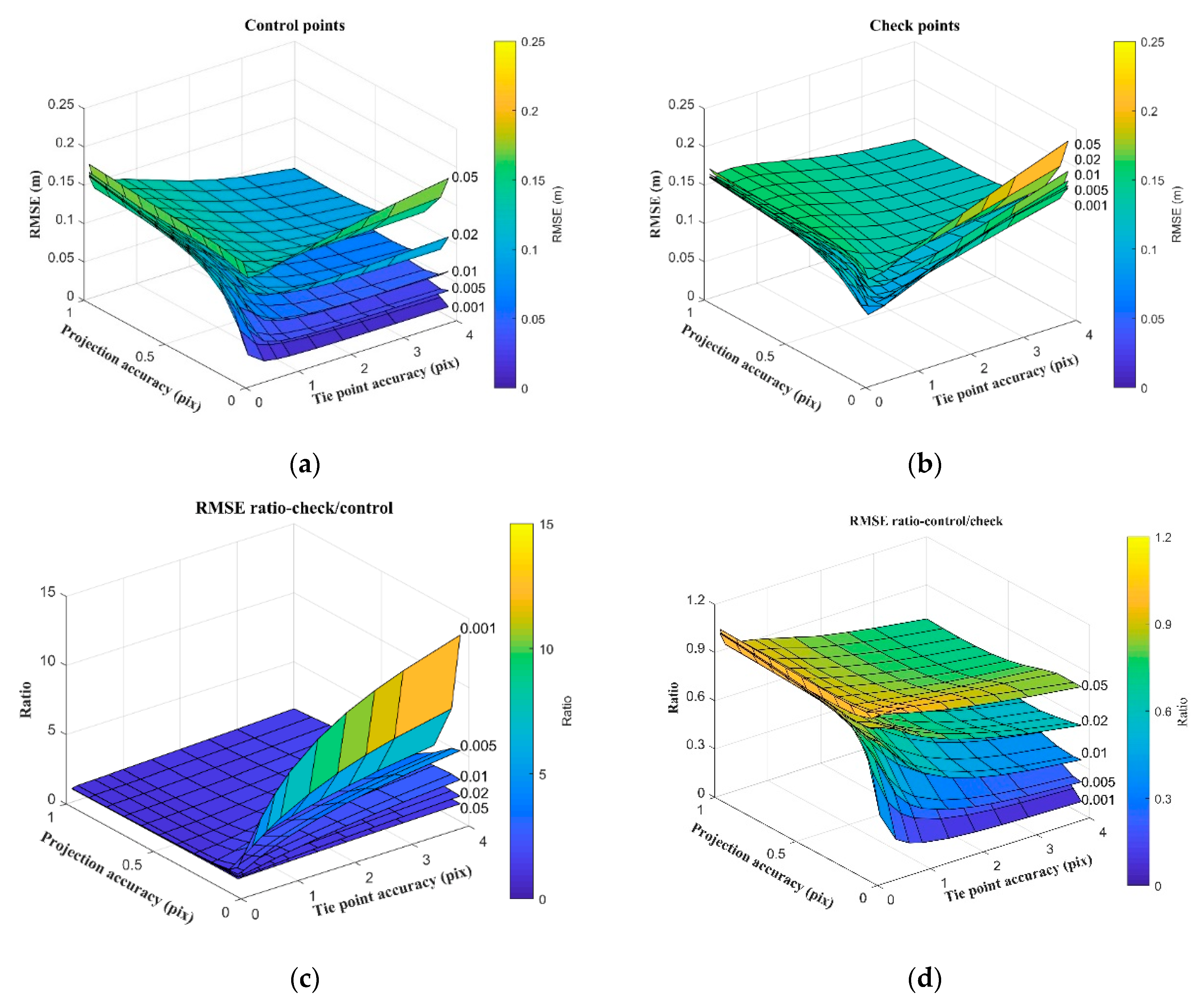
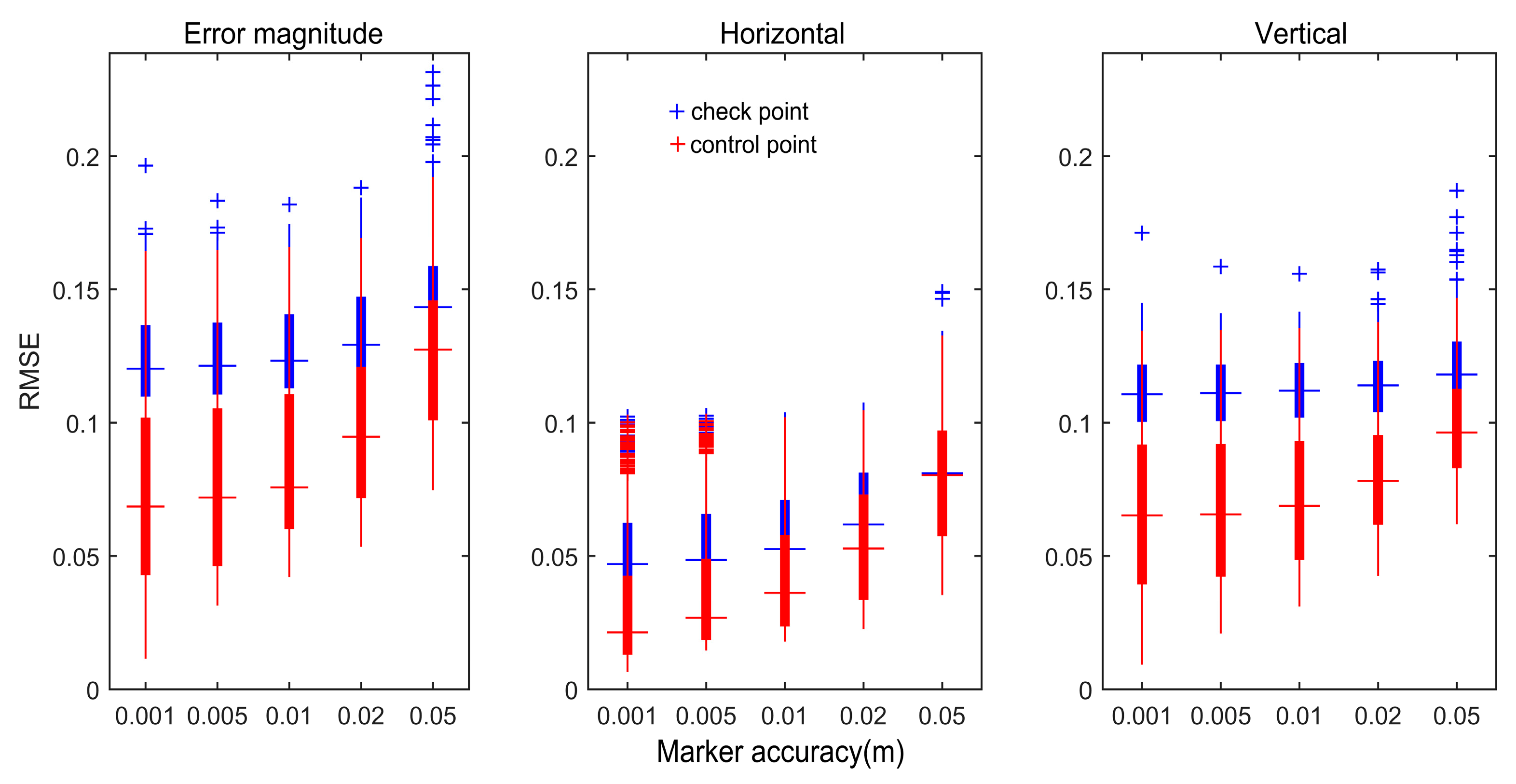
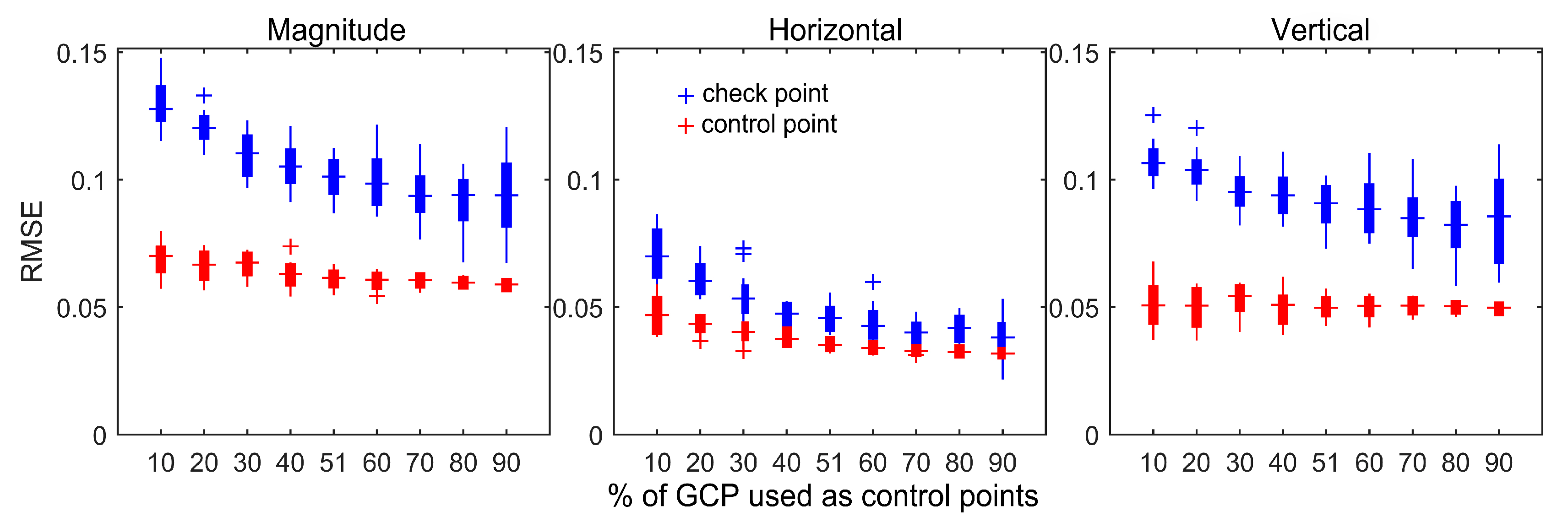
- For the generation of reference images, the different projection precision of control points and tie points applied to bundle adjustment were comprehensively compared based on the SFM method. The correlation between root means square error (RMSE) of control points and checkpoints, and the variability of spatial point precision was analyzed. Fifty percent of the ground control points (GCPs) were randomly selected as control points and 50% were used as checkpoints. The horizontal and vertical RMSEs of various GCPs and the overall RMSE were selected as control points for further analysis. Finally, the effect of the number and quality of control points on the bundle adjustment results was analyzed. These three methods were used to improve and optimize the accuracy of the DOM and DSM obtained by the UAV, and also to further improve the reliability and robustness of matching the UAV image and reference image under various complex conditions;
- We used transfer learning to fine-tune the pre-trained model to effectively represent deep features in air-ground multi-source images. Based on the pre-trained ResNet50 model and the high-precision experimental area reference image obtained using the SFM algorithm, a method was proposed to match UAV images and reference images by integrating multi-scale local deep features. Matching experiments were performed under various conditions, such as at various scales, viewpoints, lighting conditions, and seasons images to explore the difference in corresponding feature points between UAV images and the reference image under various complex conditions. Compared with some classic hand-crafted computer vision and deep learning methods, the proposed method provides a new solution for exploring the immediate and effective positioning of the UAV itself and ground target in GPS-denied environments.
2. Materials and Methods
2.1. Process Workflow
2.2. Reference Image Generation
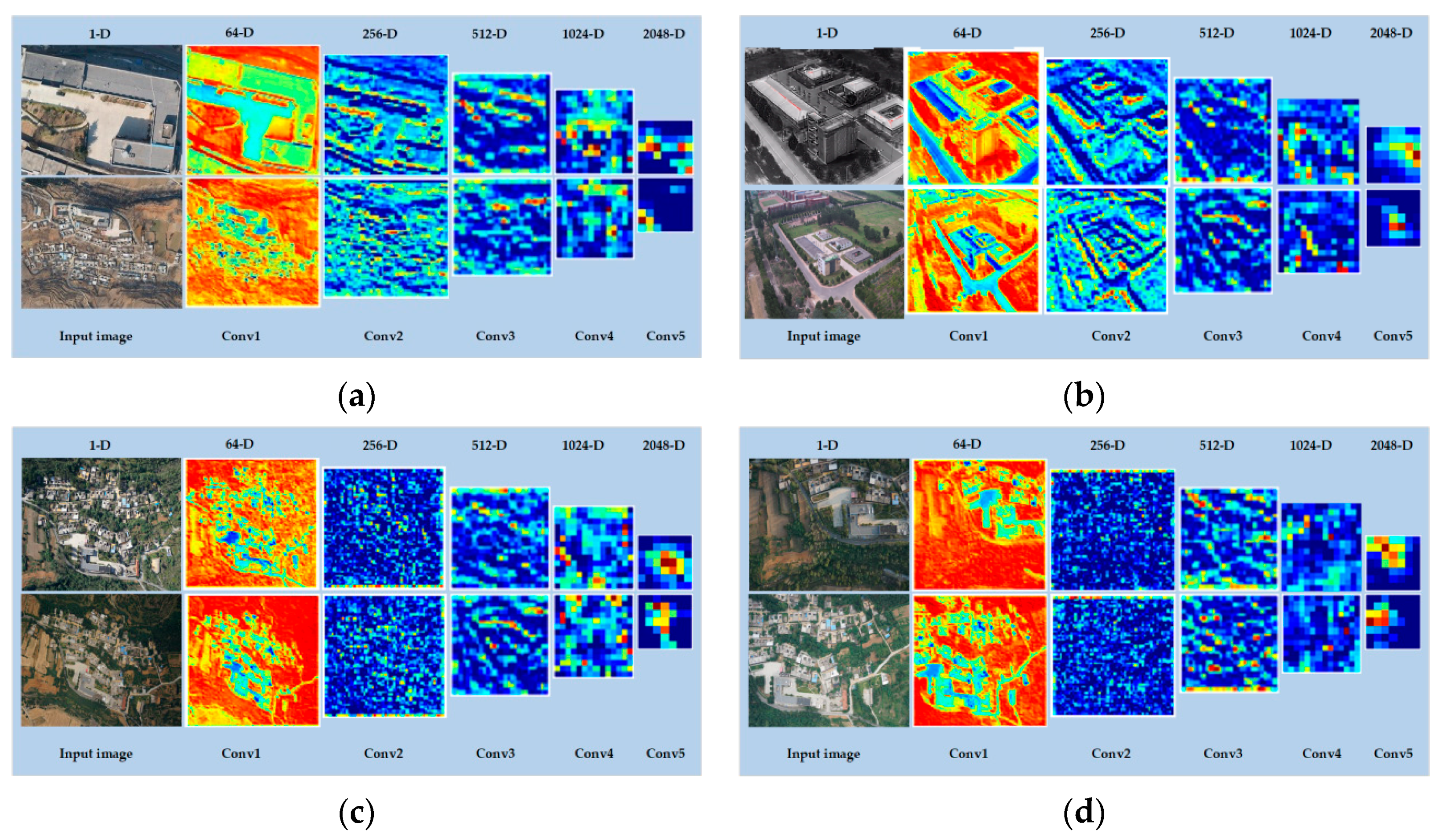
2.3. Image Deep Feature Extraction
2.4. Image Matching Process
3. Experiments and Analysis
3.1. Data Source
3.2. Experiment Platform
3.3. UAV Reference Image
3.4. Deep Feature Visualization
3.5. Matching Results and Analysis
3.5.1. Matching Results Based on UAV Reference Image
3.5.2. Matching Results Based on Google Reference Image
3.6. Matching Performance Analysis
3.7. Matching Performance Comparison
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, D.; Nam, W.; Lee, S. A Robust Matching Network for Gradually Estimating Geometric Transformation on Remote Sensing Imagery. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 3889–3894. [Google Scholar]
- Gruen, A. Development and Status of Image Matching in Photogrammetry. Photogramm. Rec. 2012, 27, 36–57. [Google Scholar] [CrossRef]
- Liu, Y.; Mo, F.; Tao, P. Matching Multi-Source Optical Satellite Imagery Exploiting a Multi-Stage Approach. Remote Sens. 2017, 9, 1249. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; van Gool, L. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G.R. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE features. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 214–227. [Google Scholar]
- Wu, Y.; Di, L.; Ming, Y.; Lv, H.; Tan, H. High-Resolution Optical Remote Sensing Image Registration via Reweighted Random Walk Based Hyper-Graph Matching. Remote Sens. 2019, 11, 2841. [Google Scholar] [CrossRef] [Green Version]
- Bruce, L.M.; Koger, C.H.; Li, J. Dimensionality reduction of hyperspectral data using discrete wavelet transform feature extraction. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2331–2338. [Google Scholar] [CrossRef]
- Zabalza, J.; Ren, J.; Yang, M.; Zhang, Y.; Wang, J.; Marshall, S.; Han, J. Novel folded-PCA for improved feature extraction and data reduction with hyperspectral imaging and SAR in remote sensing. ISPRS J. Photogramm. Remote Sens. 2014, 93, 112–122. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Han, J. A Survey on Object Detection in Optical Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2016, 177, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Jégou, H.; Douze, M.; Schmid, C. Improving Bag-of-Features for Large Scale Image Search. Int. J. Comput. Vis. 2010, 87, 316–336. [Google Scholar] [CrossRef] [Green Version]
- Fan, D.; Dong, Y.; Zhang, Y. Satellite Image Matching Method Based on Deep Convolutional Neural Network. J. Geod. Geoinf. Sci. 2019, 2, 90–100. [Google Scholar]
- Xiao, X.; Guo, B.; Li, D.; Li, L.; Yang, N.; Liu, J.; Zhang, P.; Peng, Z. Multi-View Stereo Matching Based on Self-Adaptive Patch and Image Grouping for Multiple Unmanned Aerial Vehicle Imagery. Remote Sens. 2016, 8, 89. [Google Scholar] [CrossRef] [Green Version]
- Yuan, W.; Yuan, X.; Xu, S.; Gong, J.; Shibasaki, R. Dense Image-Matching via Optical Flow Field Estimation and Fast-Guided Filter Refinement. Remote Sens. 2019, 11, 2410. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Zhang, Y.; Zhang, Z.; Lai, G. A Coarse-to-Fine Registration Strategy for Multi-Sensor Images with Large Resolution Differences. Remote Sens. 2019, 11, 470. [Google Scholar] [CrossRef] [Green Version]
- Ling, X.; Huang, X.; Zhang, Y.; Zhou, G. Matching Confidence Constrained Bundle Adjustment for Multi-View High-Resolution Satellite Images. Remote Sens. 2020, 12, 20. [Google Scholar] [CrossRef] [Green Version]
- Swaroop, A.; Aman, A.R.; Giri, A.; Gothwal, H. Content-Based Image Retrieval: A Comprehensive Study. Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 2019, 5, 1073–1081. [Google Scholar]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1717–1724. [Google Scholar]
- Guo, Y.; Shi, H.; Kumar, A.; Grauman, K.; Rosing, T.; Feris, R. SpotTune: Transfer learning through adaptive fine-tuning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4805–4814. [Google Scholar]
- Al-Ruzaiqi, S.K.; Dawson, C.W. Optimizing Deep Learning Model for Neural Network Topology. In Intelligent Computing—Proceedings of the Computing Conference, London, UK, 16–17 July 2019; Arai, K., Bhatia, R., Kapoor, S., Eds.; Springer: Cham, Switzerland, 2019; pp. 785–795. [Google Scholar]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [Green Version]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. (NIPS) 2014, 27, 3320–3328. [Google Scholar]
- Lucey, S.; Goforth, H. GPS-Denied UAV Localization using Pre-existing Satellite Imagery. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Nassar, A.; Amer, K.; ElHakim, R.; ElHelw, M. A Deep CNN-Based Framework For Enhanced Aerial Imagery Registration with Applications to UAV Geolocalization. In Proceedings of the Computer Vision & Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image Matching from Handcrafted to Deep Features: A Survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- James, M.R.; Robson, S.; d’Oleire-Oltmanns, S.; Niethammer, U. Optimising UAV topographic surveys processed with structure-from-motion: Ground control quality, quantity and bundle adjustment. Geomorphology 2017, 280, 51–66. [Google Scholar] [CrossRef] [Green Version]
- Alismail, H.; Browning, B.; Lucey, S. Photometric bundle adjustment for vision-based slam. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 324–341. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Noh, H.; Araujo, A.; Sim, J.; Weyand, T.; Han, B. Large-Scale Image Retrieval with Attentive Deep Local Features. In Proceedings of the 2017 International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, J.; Hu, Q.; Ai, M. RIFT: Multi-Modal Image Matching Based on Radiation-Variation Insensitive Feature Transform. IEEE Trans. Image Process. 2020, 29, 3296–3310. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, J.; Zhou, H.; Zhao, J.; Guo, X. Guided locality preserving feature matching for remote sensing image registration. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4435–4447. [Google Scholar] [CrossRef]
- Revaud, J.; Weinzaepfel, P.; Souza, C.D.; Pion, N. R2D2: Repeatable and Reliable Detector and Descriptor. In Proceedings of the Thirty-third Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Nouwakpo, S.K.; James, M.R.; Weltz, M.A.; Huang, C.-H.; Chagas, I.; Lima, L. Evaluation of structure from motion for soil microtopography measurement. Photogramm. Rec. 2014, 29, 297–316. [Google Scholar] [CrossRef]
- James, M.R.; Robson, S. Mitigating systematic error in topographic models derived from UAV and ground-based image networks. Earth Surf. Process. Landf. 2014, 39, 1413–1420. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Chen, M.; Chen, T.; Li, D. Matching of Remote Sensing Images with Complex Background Variations via Siamese Convolutional Neural Network. Remote Sens. 2018, 10, 355. [Google Scholar] [CrossRef] [Green Version]
- Dong, Y.; Jiao, W.; Long, T.; Liu, L.; He, G.; Gong, C.; Guo, Y. Local Deep Descriptor for Remote Sensing Image Feature Matching. Remote Sens. 2019, 11, 430. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Camera Parameter | Calibrate Values |
|---|---|
| Model | DSC-RX1RM2 |
| Image size | 7952 × 5304 pixels |
| Focal length | 35 mm |
| Pixel size | 4.53 μm |
| Principal distance | 7507.03 ± 11.41 pixels |
| and | 7752.36 ± 17.65 mm |
| (7.05 ± 0.94, −43.71 ± 2.04) mm | |
| −0.04 ± 0.05 | |
| −0.22 ± 0.57 | |
| 0.33 ± 0.22 |
| Survey Parameters | Values | |
|---|---|---|
| Flight plan | Altitude | 350 m |
| Image overlap | 80% forward 60% side | |
| Camera orientations | Position (X, Y, Z; m) | [0.029, 0.032, 0.025] |
| Rotation (roll, pitch, yaw; mdeg.) | [0.005, 0.004, 0.002] | |
| Processing | Number of images processed | 327 |
| GCPs (as control, [as check]) | 82 [12] | |
| GCP image precision (pix) | 0.1 | |
| Tie point image precision (pix) | 0.75 | |
| GCP RMS discrepancies | Control points (X, Y, Z; m) | [1.772, 1.603, 0.054] |
| Check points (X, Y, Z; m) | [0.758, 0.186, 0.388] | |
| Point coordinate RMS discrepancies | Mean for all points (X, Y, Z; mm) | 0.72 |
| Std. deviation all points (X, Y, Z; mm) | 0.57 | |
| Image Pair | Indicators | ||||
|---|---|---|---|---|---|
| EC | CC | Precision | Time(s) | ||
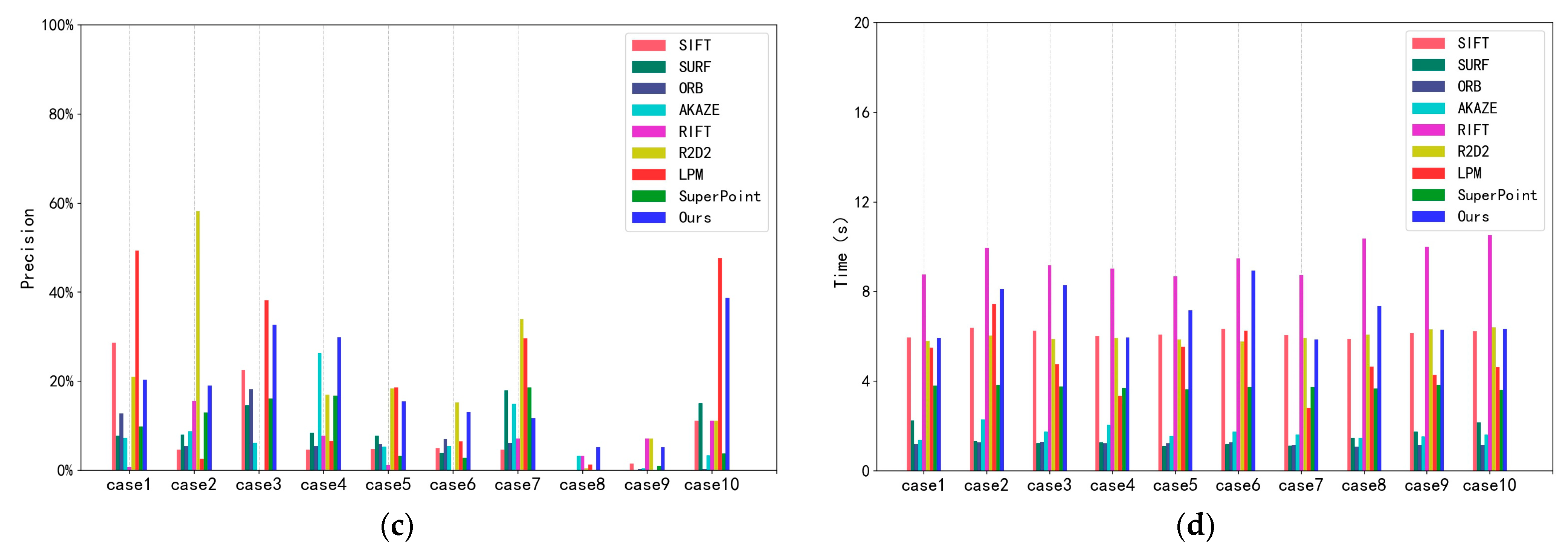
| Figure 7 | case1 | 1060 | 215 | 20.3% | 5.925 |
| case2 | 1040 | 199 | 19.1% | 8.128 | |
| case3 | 241 | 79 | 32.7% | 8.281 | |
| case4 | 471 | 141 | 29.9% | 5.956 | |
| case5 | 484 | 75 | 15.5% | 7.163 | |
| case6 | 383 | 50 | 13.1% | 8.934 | |
| case7 | 1178 | 138 | 11.7% | 5.863 | |
| Figure 8 | case8 | 1655 | 87 | 5.3% | 7.371 |
| case9 | 2157 | 140 | 6.5% | 6.301 | |
| case10 | 2448 | 949 | 38.7% | 7.359 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Ma, G.; Wu, J. Air-Ground Multi-Source Image Matching Based on High-Precision Reference Image. Remote Sens. 2022, 14, 588. https://doi.org/10.3390/rs14030588
Zhang Y, Ma G, Wu J. Air-Ground Multi-Source Image Matching Based on High-Precision Reference Image. Remote Sensing. 2022; 14(3):588. https://doi.org/10.3390/rs14030588
Chicago/Turabian StyleZhang, Yongxian, Guorui Ma, and Jiao Wu. 2022. "Air-Ground Multi-Source Image Matching Based on High-Precision Reference Image" Remote Sensing 14, no. 3: 588. https://doi.org/10.3390/rs14030588
APA StyleZhang, Y., Ma, G., & Wu, J. (2022). Air-Ground Multi-Source Image Matching Based on High-Precision Reference Image. Remote Sensing, 14(3), 588. https://doi.org/10.3390/rs14030588