
Mapping Sugarcane in Central India with Smartphone Crowdsourcing

 , ,
, ,
Abstract
:1. Introduction
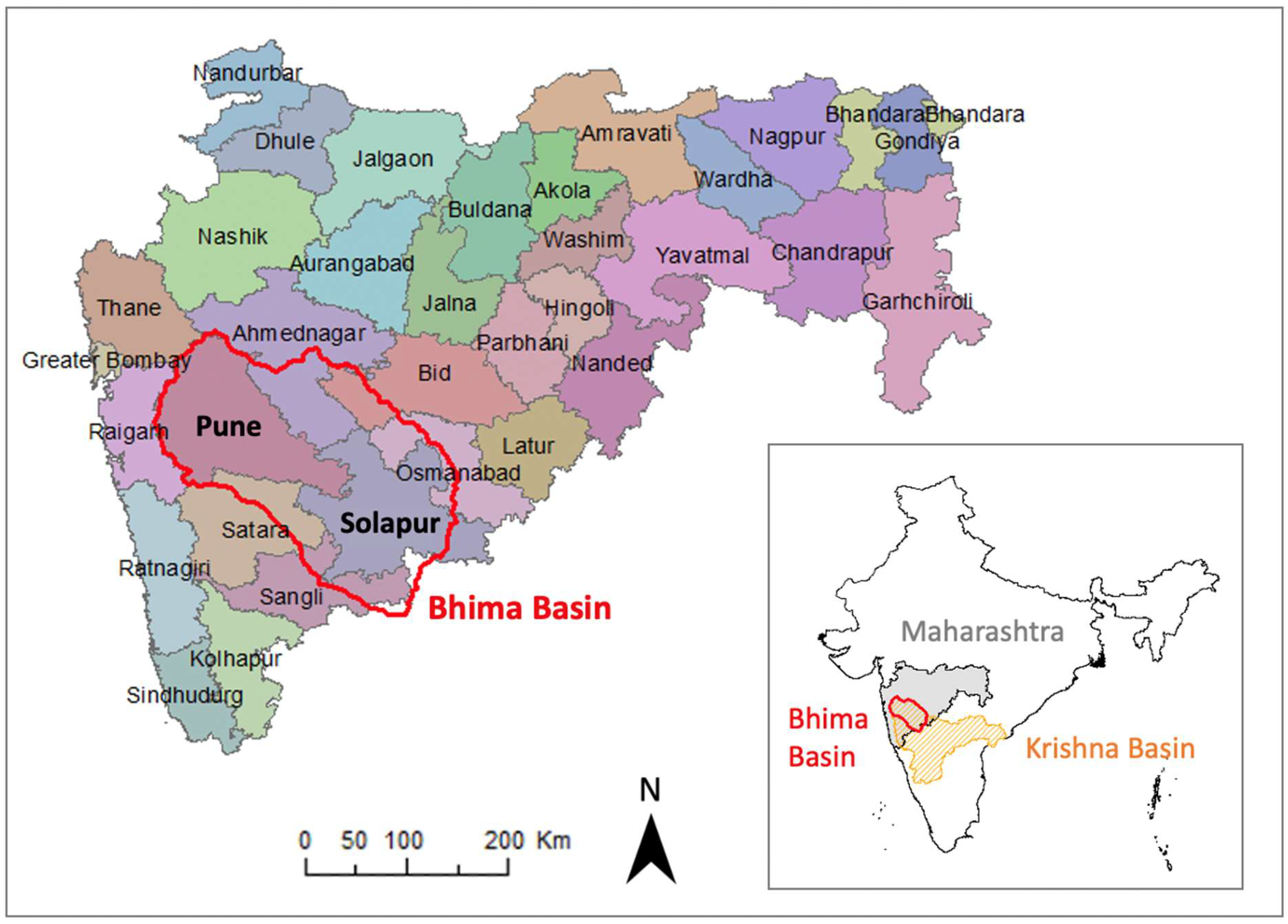
2. Study Area
2.1. Sugarcane Phenology
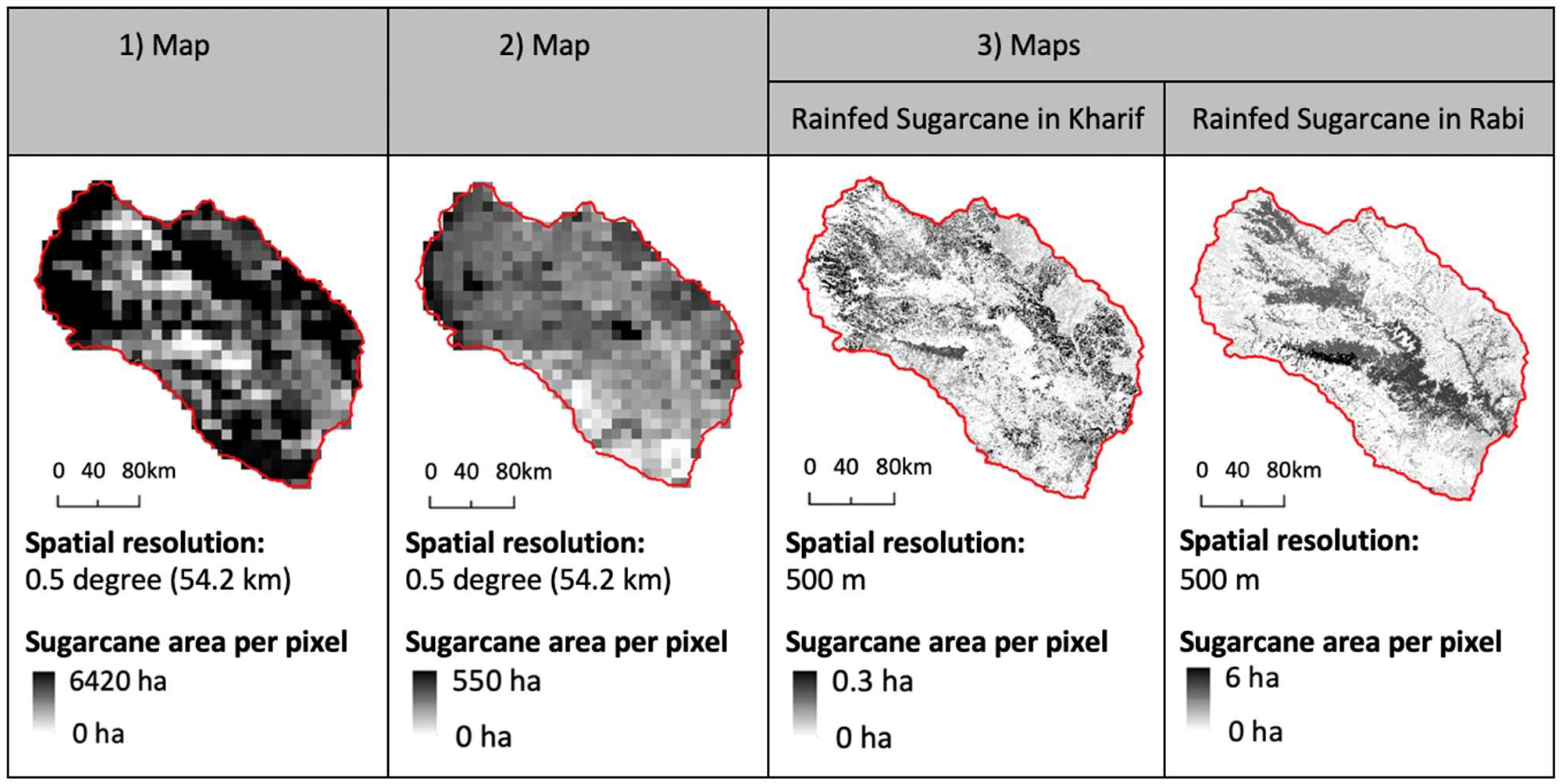
2.2. Existing Sugarcane Maps and Data
3. Data
3.1. Crowdsourced Data
3.2. Remote Sensing Data
3.2.1. For Masking out Non-Agricultural Areas
3.2.2. For Supervised Classification
3.2.3. For Unsupervised Classification
3.2.4. Google Static Map and Airbus Images
3.3. Government Statistics on Sugarcane Area
4. Method
4.1. Constructing Training and Test Sets
- We removed submissions whose GPS accuracies, as assigned by the Plantix app’s Android platform, were highly inaccurate. The exact GPS accuracy thresholds we used were different between the training and test sets; we describe them below.
- The Sentinel-2 pixel data at the submission location were classified as “in field”, “more than half in field”, “less than half in field”, and “not in field” by a separate CNN trained on in-field labels generated by human labelers and Google Static Map imagery (Figure S3). We used only the Plantix submissions that were “in field” or “more than half in field” for our training and test sets.
4.2. Supervised Classification
4.3. Unsupervised Classification
- Single crop: Single NDVI peak (>0.4) between June and November and low NDVI (<0.4) after November.
- Double crop: Two NDVI peaks (>0.4), one between June and November and the other between December and March; the NDVI drops to less than <0.4 between the two peaks.
- Perennial crop (sugarcane): High NDVI (>0.4) throughout a year with two exceptions: 1) NDVI below 0.4 between June and October is acceptable due to noises in Sentinel-2 data during monsoon; and 2) NDVI below 0.4 up to two months between November and May is acceptable due to possible harvest in the period.
- Barren land/shrub: Low NDVI (<0.4) throughout a year.
4.4. Utilizing Both Methods in Combination
4.5. Validation, Evaluation, and Comparison
5. Results
5.1. Training and Test Sets from Plantix Data
5.2. Sugarcane Maps and Validation Results
5.3. Qualitative Evaluation of Sugarcane Maps
5.4. Comparison to Government Statistics
6. Discussion
6.1. Performance of Sugarcane Mapping Methods
6.2. Potential of High-Resolution Image Classification for Sugarcane Mapping
6.3. Government Underestimation of Sugarcane Area
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. More Details on Supervised Classification Method

Appendix A.2. Spectral Signatures of Unsupervised Classes

References
- Food and Agriculture Organization’s Statistical Database (FAOSTAT). Country-Wise Sugarcane Area and Production Data from 2019. Available online: http://www.fao.org/faostat/en/#data/QC (accessed on 1 November 2021).
- Lee, J.Y.; Naylor, R.L.; Figueroa, A.J.; Gorelick, S.M. Water-Food-Energy challenges in India: Political economy of the sugar industry. Environ. Res. Lett. 2020, 15, 084020. [Google Scholar] [CrossRef]
- Commission for Agricultural Costs and Prices (CACP); Ministry of Agriculture; Government of India. Price Policy for Sugarcane: The 2020-21 Sugar Season. 2019. Available online: http://cacp.dacnet.nic.in/ViewQuestionare.aspx?Input=2&DocId=1&PageId=41&KeyId=709 (accessed on 1 November 2021).
- Ministry of Statistics & Programme Implementation (MOSPI); Government of India. Review of Crop Statistics System in India, 2017–2018. 2019. Available online: http://mospi.nic.in/sites/default/files/publication_reports/AISR_2017_18_20jan21.pdf (accessed on 1 November 2021).
- Ministry of Statistics & Programme Implementation (MOSPI); Government of India. Consolidated Results of Crop Estimation Survey on Principal Crops, 2016–2017. 2019. Available online: http://mospi.nic.in/sites/default/files/publication_reports/CES_2016_17_20jan21.pdf (accessed on 1 November 2021).
- Food and Agriculture Organization (FAO). Guidelines on Improving and Using Administrative Data in Agricultural Statistics. 2018. Available online: http://www.fao.org/3/ca6413en/ca6413en.pdf (accessed on 1 November 2021).
- World Bank and Global Facility for Disaster Reduction and Recovery. Enhancing Crop Insurance in India. 2011. Available online: https://www.gfdrr.org/sites/default/files/publication/Enhancing%20Crop%20Insurance%20in%20India%20%281%29.pdf (accessed on 1 November 2021).
- Molijn, R.A.; Iannini, L.; Vieira Rocha, J.; Hanssen, R.F. Sugarcane productivity mapping through C-band and L-band SAR and optical satellite imagery. Remote Sens. 2019, 11, 1109. [Google Scholar] [CrossRef] [Green Version]
- Bégué, A.; Arvor, D.; Bellon, B.; Betbeder, J.; De Abelleyra, D.; PD Ferraz, R.; Lebourgeois, V.; Lelong, C.; Simoes, M.; Verón, S.R. Remote sensing and cropping practices: A review. Remote Sens. 2018, 10, 99. [Google Scholar] [CrossRef] [Green Version]
- Som-ard, J.; Atzberger, C.; Izquierdo-Verdiguier, E.; Vuolo, F.; Immitzer, M. Remote sensing applications in sugarcane cultivation: A review. Remote Sens. 2021, 13, 4040. [Google Scholar] [CrossRef]
- Manjunath, K.R.; More, R.S.; Jain, N.K.; Panigrahy, S.; Parihar, J.S. Mapping of rice-cropping pattern and cultural type using remote-sensing and ancillary data: A case study for South and Southeast Asian countries. Int. J. Remote Sens. 2015, 36, 6008–6030. [Google Scholar] [CrossRef]
- Xiao, X.; Boles, S.; Frolking, S.; Li, C.; Babu, J.Y.; Salas, W.; Moore III, B. Mapping paddy rice agriculture in South and Southeast Asia using multi-temporal MODIS images. Remote Sens. Environ. 2006, 100, 95–113. [Google Scholar] [CrossRef]
- Bégué, A.; Lebourgeois, V.; Bappel, E.; Todoroff, P.; Pellegrino, A.; Baillarin, F.; Siegmund, B. Spatio-temporal variability of sugarcane fields and recommendations for yield forecast using NDVI. Int. J. Remote Sens. 2010, 31, 5391–5407. [Google Scholar] [CrossRef] [Green Version]
- Shashikant, V.; Mohamed Shariff, A.R.; Wayayok, A.; Kamal, M.R.; Lee, Y.P.; Takeuchi, W. Utilizing TVDI and NDWI to Classify Severity of Agricultural Drought in Chuping, Malaysia. Agronomy 2021, 11, 1243. [Google Scholar] [CrossRef]
- Wu, F.; Wu, B.; Zhang, M.; Zeng, H.; Tian, F. Identification of Crop Type in Crowdsourced Road View Photos with Deep Convolutional Neural Network. Sensors 2021, 21, 1165. [Google Scholar] [CrossRef]
- Hegarty-Craver, M.; Polly, J.; O’Neil, M.; Ujeneza, N.; Rineer, J.; Beach, R.H.; Lapidus, D.; Temple, D.S. Remote crop mapping at scale: Using satellite imagery and UAV-acquired data as ground-truth. Remote Sens. 2020, 12, 1984. [Google Scholar] [CrossRef]
- Wang, S.; Di Tommaso, S.; Faulkner, J.; Friedel, T.; Kennepohl, A.; Strey, R.; Lobell, D.B. Mapping crop types in southeast india with smartphone crowdsourcing and deep learning. Remote Sens. 2020, 12, 2957. [Google Scholar] [CrossRef]
- Zhou, N.; Siegel, Z.D.; Zarecor, S.; Lee, N.; Campbell, D.A.; Andorf, C.M.; Nettleton, D.; Lawrence-Dill, C.J.; Ganapathysubramanian, B.; Kelly, J.W.; et al. Crowdsourcing image analysis for plant phenomics to generate ground truth data for machine learning. PLoS Comput. Biol. 2018, 14, e1006337. [Google Scholar] [CrossRef] [Green Version]
- See, L.; McCallum, I.; Fritz, S.; Perger, C.; Kraxner, F.; Obersteiner, M.; Deka Baruah, U.; Mili, N.; Kalita, N.R. Mapping cropland in Ethiopia using crowdsourcing. Int. J. Geosci. 2013, 4, 6–13. [Google Scholar] [CrossRef] [Green Version]
- Larrañaga, A.; Álvarez-Mozos, J.; Albizua, L. Crop classification in rain-fed and irrigated agricultural areas using Landsat TM and ALOS/PALSAR data. Can. J. Remote. Sens. 2011, 37, 157–170. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Conrad, C. Crop type classification using a combination of optical and radar remote sensing data: A review. Int. J. Remote Sens. 2019, 40, 6553–6595. [Google Scholar] [CrossRef]
- Hong, G.; Zhang, A.; Zhou, F.; Brisco, B. Integration of optical and synthetic aperture radar (SAR) images to differentiate grassland and alfalfa in Prairie area. Int. J. Appl. Earth Obs. Geoinf. 2014, 28, 12–19. [Google Scholar] [CrossRef]
- Mohammady, M.; Moradi, H.R.; Zeinivand, H.; Temme, A.J.A.M. A comparison of supervised, unsupervised and synthetic land use classification methods in the north of Iran. Int. J. Environ. Sci. Technol. 2015, 12, 1515–1526. [Google Scholar] [CrossRef] [Green Version]
- Rozenstein, O.; Karnieli, A. Comparison of methods for land-use classification incorporating remote sensing and GIS inputs. Appl. Geogr. 2011, 31, 533–544. [Google Scholar] [CrossRef]
- Cechim Junior, C.; Johann, J.A.; Antunes, J.F. Mapping of sugarcane crop area in the Paraná State using Landsat/TM/OLI and IRS/LISS-3 images. Rev. Bras. Eng. Agríc. Ambient. 2017, 21, 427–432. [Google Scholar] [CrossRef] [Green Version]
- Scarpare, F.V.; Hernandes, T.A.D.; Ruiz-Corrêa, S.T.; Picoli, M.C.A.; Scanlon, B.R.; Chagas, M.F.; Duft, D.G.; de Fátima Cardoso, T. Sugarcane land use and water resources assessment in the expansion area in Brazil. J. Clean. Prod. 2016, 133, 1318–1327. [Google Scholar] [CrossRef]
- Adami, M.; Mello, M.P.; Aguiar, D.A.; Rudorff, B.F.T.; Souza, A.F.D. A web platform development to perform thematic accuracy assessment of sugarcane mapping in South-Central Brazil. Remote Sens. 2012, 4, 3201–3214. [Google Scholar] [CrossRef] [Green Version]
- Vieira, M.A.; Formaggio, A.R.; Rennó, C.D.; Atzberger, C.; Aguiar, D.A.; Mello, M.P. Object based image analysis and data mining applied to a remotely sensed Landsat time-series to map sugarcane over large areas. Remote Sens. Environ. 2012, 123, 553–562. [Google Scholar] [CrossRef]
- Rudorff, B.F.T.; Aguiar, D.A.; Silva, W.F.; Sugawara, L.M.; Adami, M.; Moreira, M.A. Studies on the rapid expansion of sugarcane for ethanol production in São Paulo State (Brazil) using Landsat data. Remote Sens. 2010, 2, 1057–1076. [Google Scholar] [CrossRef] [Green Version]
- Jiang, H.; Li, D.; Jing, W.; Xu, J.; Huang, J.; Yang, J.; Chen, S. Early season mapping of sugarcane by applying machine learning algorithms to Sentinel-1A/2 time series data: A case study in Zhanjiang City, China. Remote Sens. 2019, 11, 861. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Liu, Z.; Baig, M.H.A.; Wang, Y.; Li, Y.; Chen, Y. Mapping sugarcane in complex landscapes by integrating multi-temporal Sentinel-2 images and machine learning algorithms. Land Use Policy 2019, 88, 104190. [Google Scholar] [CrossRef]
- Zhou, Z.; Huang, J.; Wang, J.; Zhang, K.; Kuang, Z.; Zhong, S.; Song, X. Object-oriented classification of sugarcane using time-series middle-resolution remote sensing data based on AdaBoost. PLoS ONE 2015, 10, e0142069. [Google Scholar] [CrossRef] [Green Version]
- Singh, R.; Patel, N.R.; Danodia, A. Mapping of sugarcane crop types from multi-date IRS-Resourcesat satellite data by various classification methods and field-level GPS survey. Remote Sens. Appl. Soc. Environ. 2020, 19, 100340. [Google Scholar] [CrossRef]
- Verma, A.K.; Garg, P.K.; Prasad, K.H. Sugarcane crop identification from LISS IV data using ISODATA, MLC, and indices based decision tree approach. Arab. J. Geosci. 2017, 10, 16. [Google Scholar] [CrossRef]
- Agricultural Census Online Database, Ministry of Agriculture and Farmers Welfare. Available online: http://agcensus.dacnet.nic.in/ (accessed on 1 November 2021).
- Virnodkar, S.S.; Pachghare, V.K.; Patil, V.C.; Jha, S.K. Application of Machine Learning on Remote Sensing Data for Sugarcane Crop Classification: A Review. In ICT Analysis and Applications. Lecture Notes in Networks and Systems; Fong, S., Dey, N., Joshi, A., Eds.; Springer: Singapore, 2020; Volume 93, pp. 539–555. [Google Scholar] [CrossRef]
- Portmann, F.T.; Siebert, S.; Döll, P. MIRCA2000—Global Monthly Irrigated and Rainfed Crop Areas around the Year 2000: A New High-Resolution Data Set for Agricultural and Hydrological Modeling. Glob. Biogeochem. Cycles. 2010, 24, GB1011. Available online: https://www.uni-frankfurt.de/45218031/Data_download_center_for_MIRCA2000 (accessed on 1 November 2021). [CrossRef]
- Monfreda, C.; Ramankutty, N.; Foley, J.A. Farming the planet: 2. Geographic distribution of crop areas, yields, physiological types, and net primary production in the year 2000. Glob. Biogeochem. Cycles. 2008, 22, GB1022. [Google Scholar] [CrossRef]
- Zhao, G.; Siebert, S. Season-Wise Irrigated and Rainfed Crop Areas for India around Year 2005 (GEOSHARE Project). MyGeoHUB 2015. Available online: https://mygeohub.org/publications/11/1 (accessed on 1 November 2021). [CrossRef]
- Area and Production Statistics (APS) Online Database, Ministry of Agriculture and Farmers Welfare. Available online: https://aps.dac.gov.in/APY/Public_Report1.aspx (accessed on 1 November 2021).
- Water Resources Department; Government of Maharashtra. Draft River Basin Plan for the Bhima Basin (2015). Available online: https://wrd.maharashtra.gov.in/Site/Upload/PDF/short%20note-Upper%20Bhima.pdf (accessed on 1 November 2021).
- Gumma, M.K.; Thenkabail, P.S.; Nelson, A. Mapping irrigated areas using MODIS 250 meter time-series data: A study on Krishna River Basin (India). Water 2011, 3, 113–131. [Google Scholar] [CrossRef] [Green Version]
- Immerzeel, W.W.; Gaur, A.; Zwart, S.J. Integrating remote sensing and a process-based hydrological model to evaluate water use and productivity in a south Indian catchment. Agric. Water Manag. 2008, 95, 11–24. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Vina, A.; Ciganda, V.; Rundquist, D.C.; Arkebauer, T.J. Remote estimation of canopy chlorophyll content in crops. Geophys. Res. Lett. 2005, 32, L08403. [Google Scholar] [CrossRef] [Green Version]
- Myneni, R.B.; Hall, F.G.; Sellers, P.J.; Marshak, A.L. The interpretation of spectral vegetation indexes. IEEE Trans. Geosci. Remote Sens. 1995, 33, 481–486. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Google. Google Maps for Business Imagery. Available online: http://www.fao.org/faostat/en/#data/QC (accessed on 1 November 2021).
- Airbus. One Atlas Basemap. Available online: https://oneatlas.airbus.com/service/basemap (accessed on 1 November 2021).
- Chen, Y.; Feng, L.; Mo, J.; Mo, W.; Ding, M.; Liu, Z. Identification of sugarcane with NDVI time series based on HJ-1 CCD and MODIS fusion. J. Indian Soc. Remote Sens. 2020, 48, 249–262. [Google Scholar] [CrossRef] [Green Version]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for multi-class classification: An overview. arXiv Prepr. 2020, arXiv:2008.05756. Available online: https://arxiv.org/pdf/2008.05756.pdf (accessed on 1 November 2021).
- Buckland, M.; Gey, F. The relationship between recall and precision. J. Am. Soc. Inf. Sci. Technol. 1994, 45, 12–19. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sugarcane Area (‘000 ha) | Bhima Basin | Pune District | Solapur District |
|---|---|---|---|
| Area and Production Statistics (APS) [35] | - | 118 | 183 |
| Agricultural Census [40] | 556 * | 182 | 280 |
| Draft River Basin Plan for Bhima Basin [41] | 666 | - | - |
| Type | Source (and Resolution) | Use |
|---|---|---|
| Crowdsourced data | Plantix (point) |
|
| Satellite data | Sentinel-2 (10–60 m) |
|
| SRTM * (90 m), MODIS ** IGBP *** (250 m), MODIS water mask (250 m), Copernicus Global Land Service (100 m) |
| |
| Google Static Map (0.3 m) |
| |
| Airbus (1.5 m) |
| |
| District-level statistics on sugarcane area | Indian Government (district-level) |
|
| Crop | Training Dataset for Maharashtra * | Test Dataset for Maharashtra * | Test Dataset for Bhima Basin * |
|---|---|---|---|
| Sugarcane | 103 (2018) 27 (2019) 852 (2020) | 130 (2020) | 42 (2020) |
| Other crops ** | 1330 (2018) 134 (2019) 8899 (2020) | 130 (2020) | 42 (2020) |
| 2019–2020 Sugarcane Area (‘000 ha) | |||
|---|---|---|---|
| Pune District | Solapur District | ||
| From government sources [35] | APS *: Raw “harvested” area | 110 | 97 |
| APS *: Derived “cropped” area | 130 | 114 | |
| From our results ** | Conservative estimate: High-confidence map | 165 (+27%) | 148 (+30%) |
| Best estimate: Supervised map | 271 (+108%) | 234 (+105%) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.Y.; Wang, S.; Figueroa, A.J.; Strey, R.; Lobell, D.B.; Naylor, R.L.; Gorelick, S.M. Mapping Sugarcane in Central India with Smartphone Crowdsourcing. Remote Sens. 2022, 14, 703. https://doi.org/10.3390/rs14030703
Lee JY, Wang S, Figueroa AJ, Strey R, Lobell DB, Naylor RL, Gorelick SM. Mapping Sugarcane in Central India with Smartphone Crowdsourcing. Remote Sensing. 2022; 14(3):703. https://doi.org/10.3390/rs14030703
Chicago/Turabian StyleLee, Ju Young, Sherrie Wang, Anjuli Jain Figueroa, Rob Strey, David B. Lobell, Rosamond L. Naylor, and Steven M. Gorelick. 2022. "Mapping Sugarcane in Central India with Smartphone Crowdsourcing" Remote Sensing 14, no. 3: 703. https://doi.org/10.3390/rs14030703
APA StyleLee, J. Y., Wang, S., Figueroa, A. J., Strey, R., Lobell, D. B., Naylor, R. L., & Gorelick, S. M. (2022). Mapping Sugarcane in Central India with Smartphone Crowdsourcing. Remote Sensing, 14(3), 703. https://doi.org/10.3390/rs14030703