
AGNet: An Attention-Based Graph Network for Point Cloud Classification and Segmentation



Abstract
:1. Introduction
- We propose a novel feature extraction module based on an attention pooling strategy called AGM, which constructs a topology structure in the local region and aggregates the important features by the novel and effective attention pooling operation;
- We constructed a high-performing network called AGNet based on our attention graph module. The network can be used for point cloud analysis tasks including object classification and segmentation;
- We conducted extensive experiments and analyses on the benchmark datasets and compared with the current best algorithm, which proved that we achieved results close to the state-of-the-art.
2. Related Work
2.1. Projection-Based Methods
2.2. Voxel-Based Methods
2.3. PointNets
2.4. Graph Convolution and Attention Mechanism
3. Methods
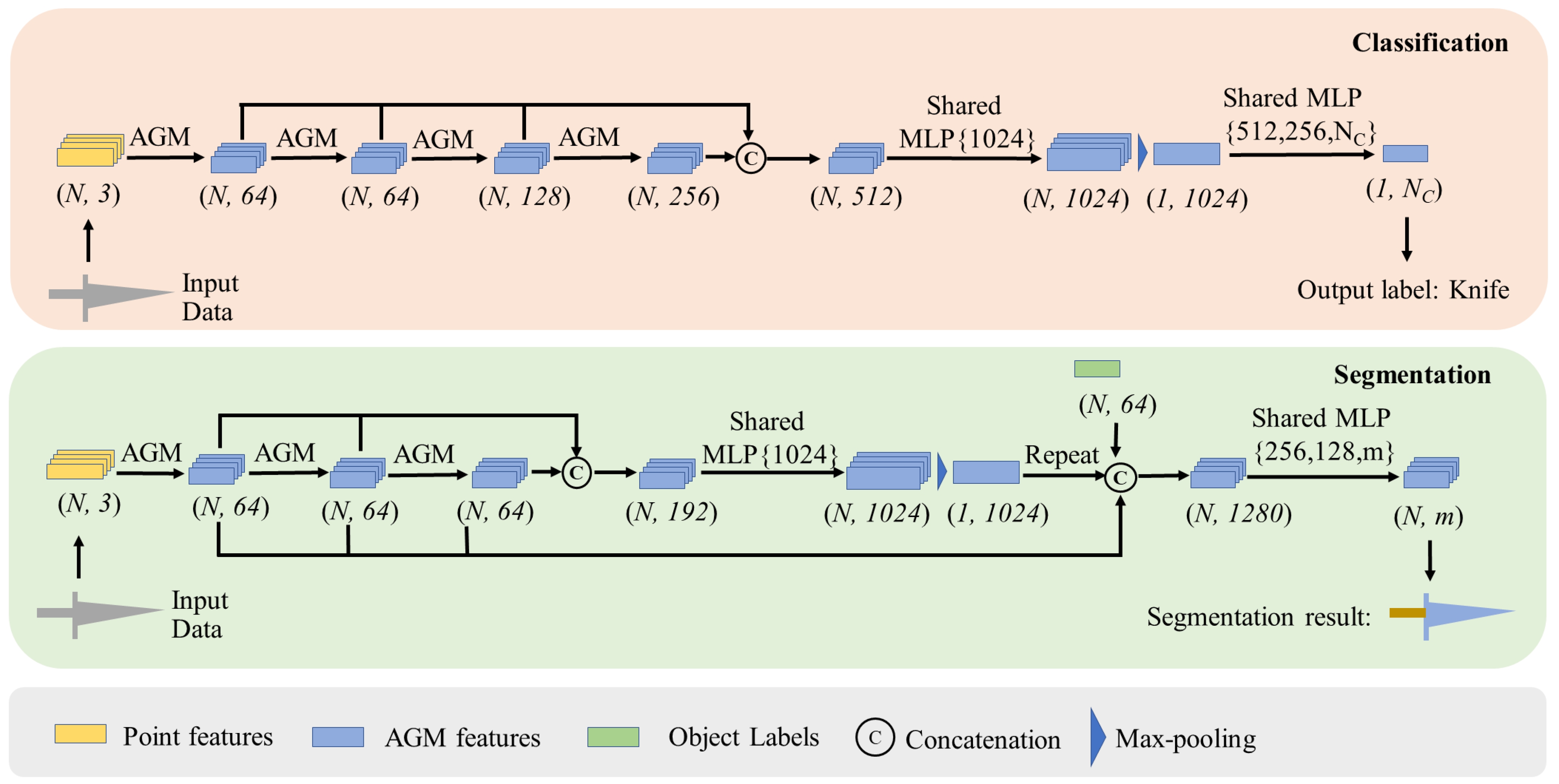
3.1. Network Architectures
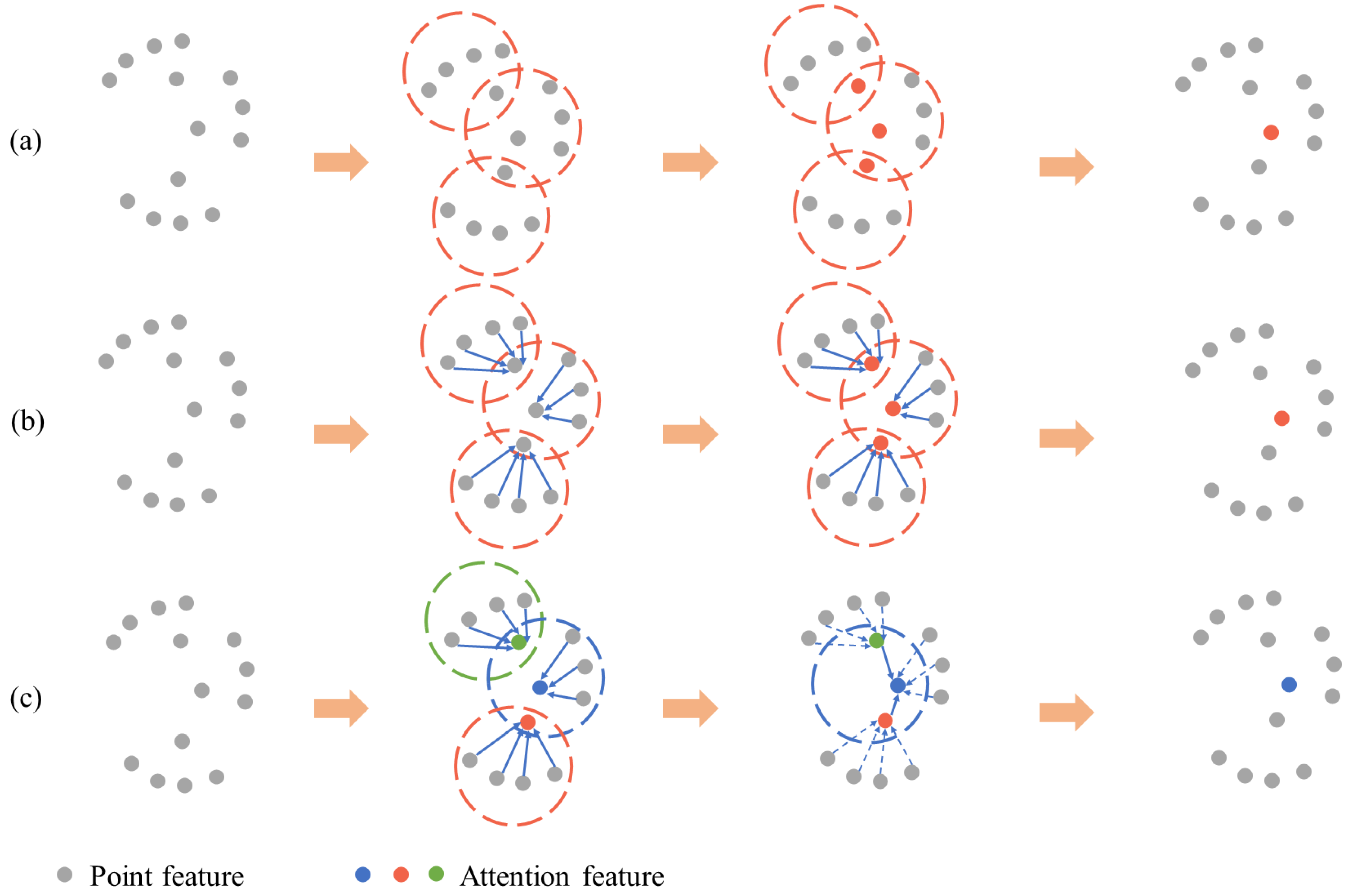
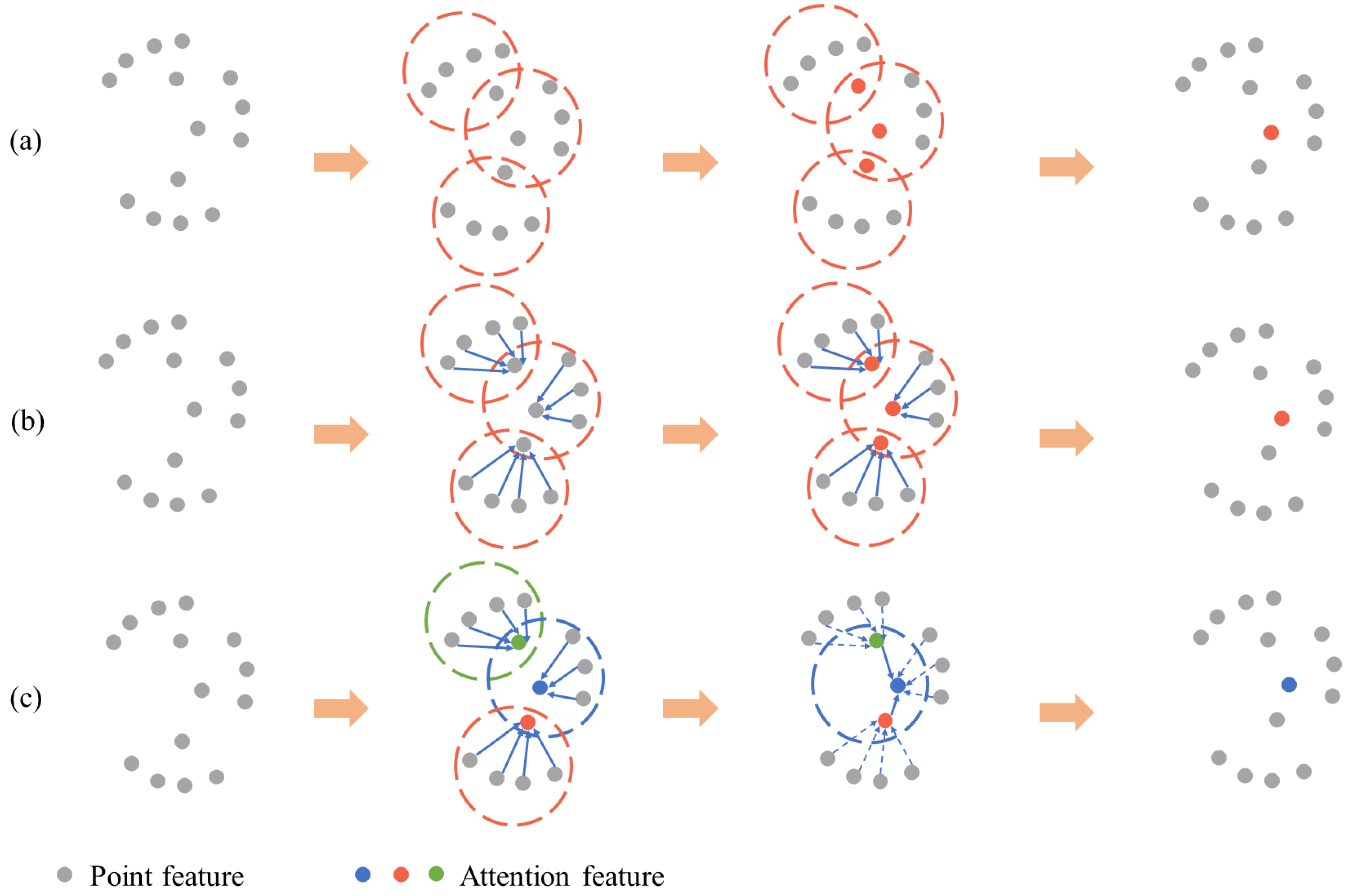
3.2. Attention Graph Module
3.2.1. Attention Graph Convolution
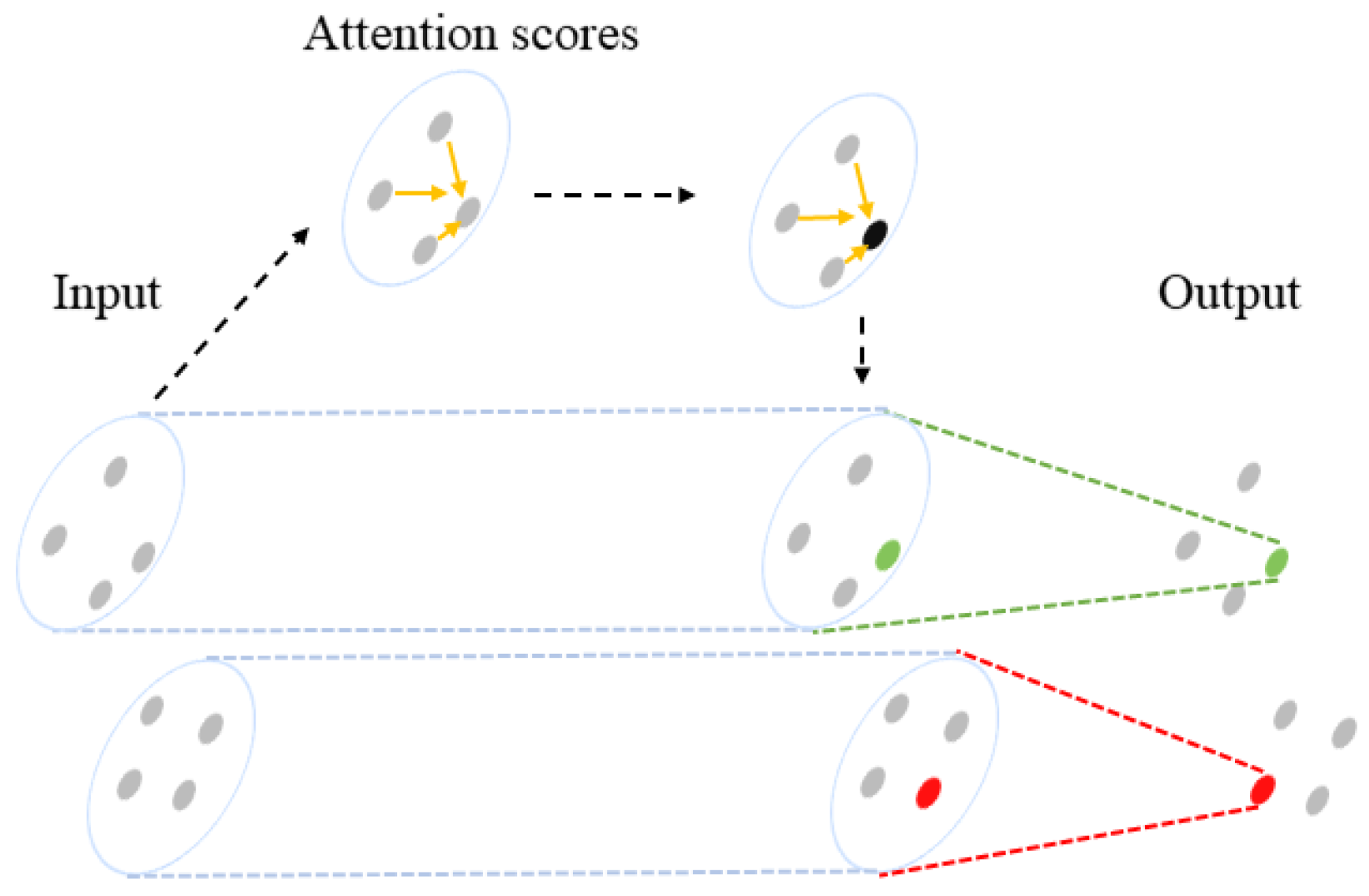
3.2.2. Attention Pooling
4. Results
4.1. Object Classification
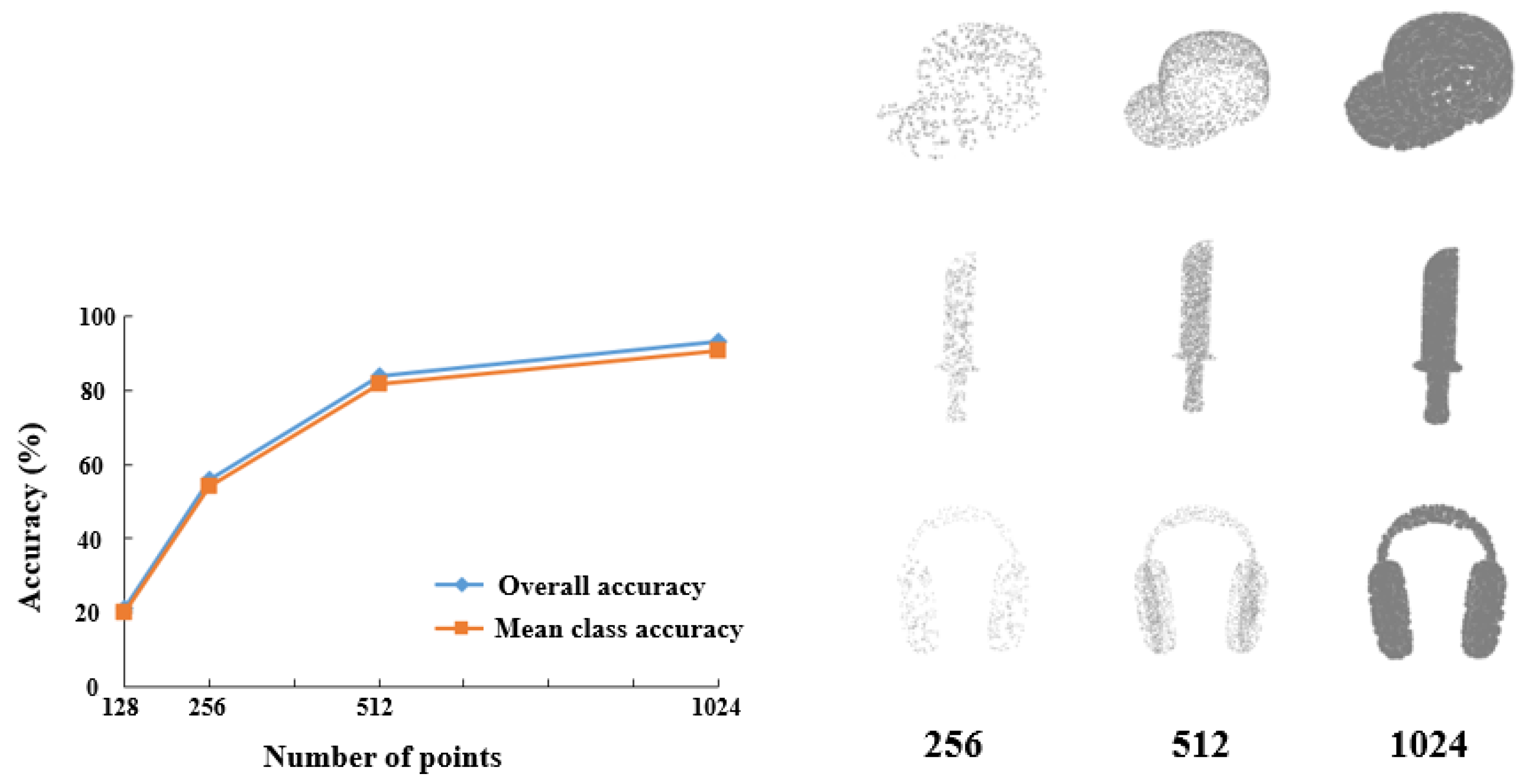
4.1.1. Data
4.1.2. Implementation
4.1.3. Analysis
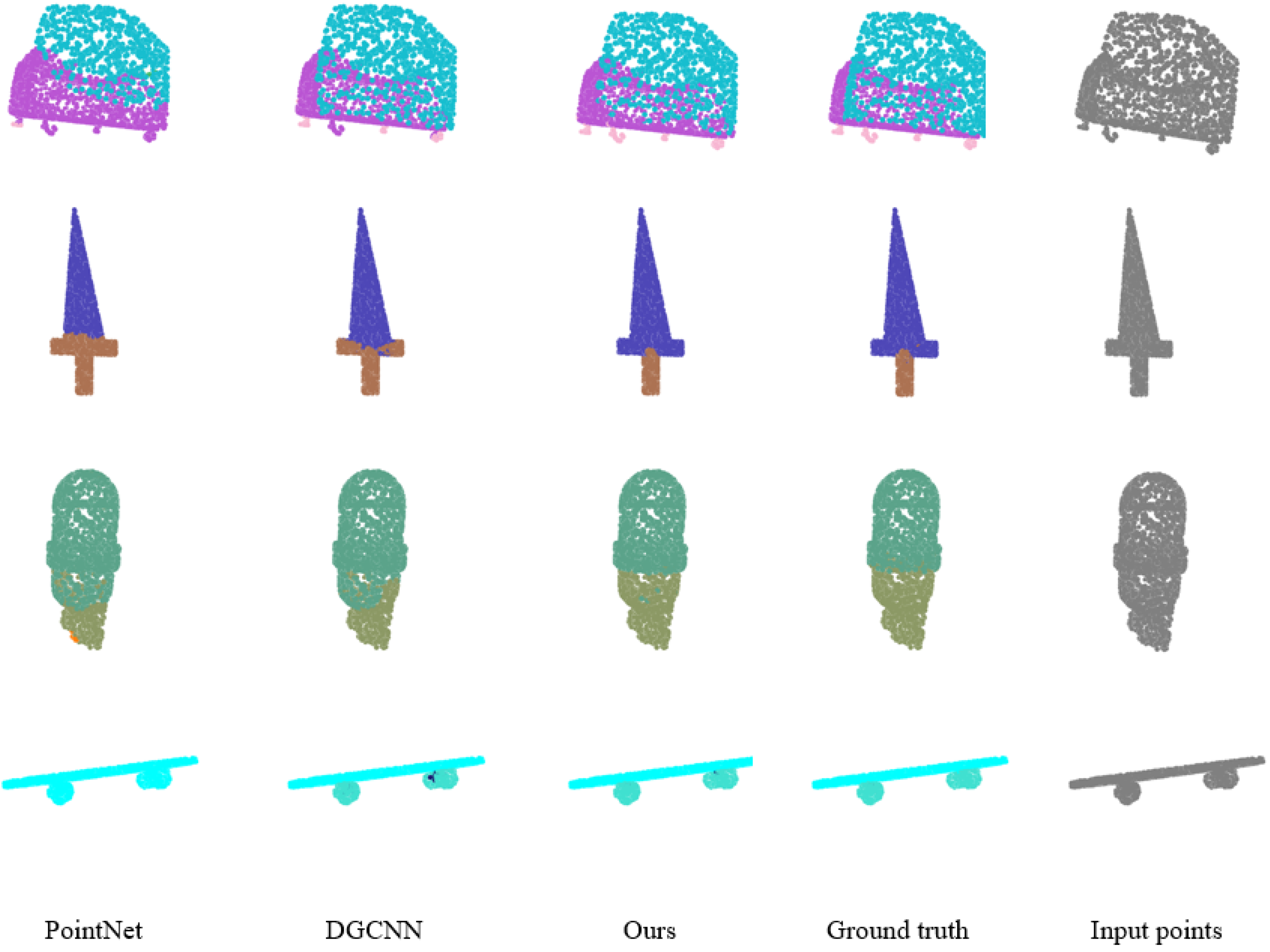
4.2. Shape Part Segmentation
4.2.1. Data
4.2.2. Implementation
4.2.3. Analysis
4.3. Semantic Segmentation
4.3.1. Data
4.3.2. Implementation
4.3.3. Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Blais, F. Review of 20 years of range sensor development. J. Electron. Imaging 2004, 13, 231–243. [Google Scholar] [CrossRef]
- Wan, J.; Xie, Z.; Xu, Y.; Zeng, Z.; Yuan, D.; Qiu, Q. DGANet: A Dilated Graph Attention-Based Network for Local Feature Extraction on 3D Point Clouds. Remote Sens. 2021, 13, 3484. [Google Scholar] [CrossRef]
- Štular, B.; Eichert, S.; Lozić, E. Airborne LiDAR Point Cloud Processing for Archaeology. Pipeline and QGIS Toolbox. Remote Sens. 2021, 13, 3225. [Google Scholar] [CrossRef]
- Cai, S.; Xing, Y.; Duanmu, J. Extraction of DBH from Filtering out Low Intensity Point Cloud by Backpack Laser Scanning. For. Eng. 2021, 37, 12–19. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a LiDAR point cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Dewi, C.; Chen, R.C.; Yu, H.; Jiang, X. Robust detection method for improving small traffic sign recognition based on spatial pyramid pooling. J. Ambient. Intell. Humaniz. Comput. 2021, 1–18. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of LiDAR data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Reitberger, J.; Schnörr, C.; Krzystek, P.; Stilla, U. 3D segmentation of single trees exploiting full waveform LIDAR data. ISPRS J. Photogramm. Remote Sens. 2009, 64, 561–574. [Google Scholar] [CrossRef]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Rusu, R.B.; Marton, Z.C.; Blodow, N.; Dolha, M.; Beetz, M. Towards 3D point cloud based object maps for household environments. Robot. Auton. Syst. 2008, 56, 927–941. [Google Scholar] [CrossRef]
- Lin, Y.; Yan, Z.; Huang, H.; Du, D.; Liu, L.; Cui, S.; Han, X. Fpconv: Learning local flattening for point convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4293–4302. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. Shapenet: An information-rich 3d model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Wang, F.; Zhuang, Y.; Zhang, H.; Gu, H. Real-time 3-d semantic scene parsing with LiDAR sensors. IEEE Trans. Cybern. 2020, 1–13. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3d. net: A new large-scale point cloud classification benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar]
- Li, X.; Li, C.; Tong, Z.; Lim, A.; Yuan, J.; Wu, Y.; Tang, J.; Huang, R. Campus3d: A photogrammetry point cloud benchmark for hierarchical understanding of outdoor scene. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 238–246. [Google Scholar]
- Hu, Q.; Yang, B.; Khalid, S.; Xiao, W.; Trigoni, N.; Markham, A. Towards semantic segmentation of urban-scale 3d point clouds: A dataset, benchmarks and challenges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4977–4987. [Google Scholar]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J. 3D object recognition in cluttered scenes with local surface features: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2270–2287. [Google Scholar] [CrossRef] [PubMed]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 922–928. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. (Tog) 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Yi, L.; Kim, V.G.; Ceylan, D.; Shen, I.-C.; Yan, M.; Su, H.; Lu, C.; Huang, Q.; Sheffer, A.; Guibas, L. A scalable active framework for region annotation in 3d shape collections. ACM Trans. Graph. (Tog) 2016, 35, 1–12. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1534–1543. [Google Scholar]
- Xu, Y.; Xie, Z.; Chen, Z.; Xie, M. Measuring the similarity between multipolygons using convex hulls and position graphs. Int. J. Geogr. Inf. Sci. 2021, 35, 847–868. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Liu, Y.T.; Jiang, X.; Hartomo, K.D. Yolo V4 for advanced traffic sign recognition with synthetic training data generated by various GAN. IEEE Access 2021, 9, 97228–97242. [Google Scholar] [CrossRef]
- Zhang, B.; Ni, H.; Hu, X.; Qi, D. Research on Tree lmage Segmentation Based on U-Net Network. For. Eng. 2021, 37, 67–73. [Google Scholar]
- Guerry, J.; Boulch, A.; Le Saux, B.; Moras, J.; Plyer, A.; Filliat, D. Snapnet-r: Consistent 3d multi-view semantic labeling for robotics. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 669–678. [Google Scholar]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. Segcloud: Semantic segmentation of 3d point clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar]
- Zhou, H.; Feng, Y.; Fang, M.; Wei, M.; Qin, J.; Lu, T. Adaptive Graph Convolution for Point Cloud Analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 19–25 June 2021; pp. 4965–4974. [Google Scholar]
- Lin, Z.H.; Huang, S.Y.; Wang, Y.C.F. Convolution in the cloud: Learning deformable kernels in 3d graph convolution networks for point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1800–1809. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Los Angeles, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Tao, Z.; Zhu, Y.; Wei, T.; Lin, S. Multi-Head Attentional Point Cloud Classification and Segmentation Using Strictly Rotation-Invariant Representations. IEEE Access 2021, 9, 71133–71144. [Google Scholar] [CrossRef]
- Song, H.; Yang, W. GSCCTL: A general semi-supervised scene classification method for remote sensing images based on clustering and transfer learning. Int. J. Remote Sens. 2022, 1–25. [Google Scholar] [CrossRef]
- Fan, R.; Wang, H.; Wang, Y.; Liu, M.; Pitas, I. Graph attention layer evolves semantic segmentation for road pothole detection: A benchmark and algorithms. IEEE Trans. Image Process. 2021, 30, 8144–8154. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Fragonara, L.Z.; Tsourdos, A. GAPointNet: Graph attention based point neural network for exploiting local feature of point cloud. Neurocomputing 2021, 438, 122–132. [Google Scholar] [CrossRef]
- Lin, H.; Zheng, W.; Peng, X. Orientation-Encoding CNN for Point Cloud Classification and Segmentation. Mach. Learn. Knowl. Extr. 2021, 3, 601–614. [Google Scholar] [CrossRef]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph attention convolution for point cloud semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10296–10305. [Google Scholar]
- Feng, M.; Zhang, L.; Lin, X.; Gilani, S.Z.; Mian, A. Point attention network for semantic segmentation of 3D point clouds. Pattern Recognit. 2020, 107, 107446. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 16259–16268. [Google Scholar]
- Chen, M.; Feng, A.; Hou, Y.; McCullough, K.; Prasad, P.B.; Soibelman, L. Ground material classification and for UAV-based photogrammetric 3D data A 2D-3D Hybrid Approach. arXiv 2021, arXiv:2109.12221. [Google Scholar]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and multi-view cnns for object classification on 3d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. Generative and discriminative voxel modeling with convolutional neural networks. arXiv 2016, arXiv:1608.04236. [Google Scholar]
- Simonovsky, M.; Komodakis, N. Dynamic edge-conditioned filters in convolutional neural networks on graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3693–3702. [Google Scholar]
- Klokov, R.; Lempitsky, V. Escape from cells: Deep kd-networks for the recognition of 3d point cloud models. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 863–872. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. Adv. Neural Inf. Process. Syst. 2018, 31, 820–830. [Google Scholar]
- Atzmon, M.; Maron, H.; Lipman, Y. Point convolutional neural networks by extension operators. arXiv 2018, arXiv:1803.10091. [Google Scholar] [CrossRef] [Green Version]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Yan, X.; Zheng, C.; Li, Z.; Wang, S.; Cui, S. Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5589–5598. [Google Scholar]
- Ma, X.; Qin, C.; You, H.; Ran, H.; Fu, Y. Rethinking Network Design and Local Geometry in Point Cloud: A Simple Residual MLP Framework. In Proceedings of the International Conference on Learning Representations, Virtual, 25 April 2022. [Google Scholar]
- Wu, W.; Qi, Z.; Fuxin, L. Pointconv: Deep convolutional networks on 3d point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9621–9630. [Google Scholar]
- Liu, Y.; Fan, B.; Meng, G.; Lu, J.; Xiang, S.; Pan, C. Densepoint: Learning densely contextual representation for efficient point cloud processing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5239–5248. [Google Scholar]
- Shen, Y.; Feng, C.; Yang, Y.; Tian, D. Neighbors do help: Deeply exploiting local structures of point clouds. arXiv 2017, arXiv:1712.06760. [Google Scholar]
- Xie, S.; Liu, S.; Chen, Z.; Tu, Z. Attentional shapecontextnet for point cloud recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4606–4615. [Google Scholar]
- Xu, Y.; Fan, T.; Xu, M.; Zeng, L.; Qiao, Y. Spidercnn: Deep learning on point sets with parameterized convolutional filters. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 87–102. [Google Scholar]
- Li, J.; Chen, B.M.; Lee, G.H. So-net: Self-organizing network for point cloud analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9397–9406. [Google Scholar]
- Te, G.; Hu, W.; Zheng, A.; Guo, Z. Rgcnn: Regularized graph cnn for point cloud segmentation. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 746–754. [Google Scholar]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R.; Hu, S.M. Pct: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Liu, K.; Gao, Z.; Lin, F.; Chen, B.M. FG-Net: Fast Large-Scale LiDAR Point CloudsUnderstanding Network Leveraging CorrelatedFeature Mining and Geometric-Aware Modelling. arXiv 2020, arXiv:2012.09439. [Google Scholar]
- Engelmann, F.; Kontogianni, T.; Hermans, A.; Leibe, B. Exploring spatial context for 3d semantic segmentation of point clouds. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 716–724. [Google Scholar]
- Mao, J.; Wang, X.; Li, H. Interpolated convolutional networks for 3d point cloud understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1578–1587. [Google Scholar]
- Hamdi, A.; Giancola, S.; Ghanem, B. MVTN: Multi-View Transformation Network for 3D Shape Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 19–25 June 2021; pp. 1–11. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Input Type | Points | mA (%) | OA (%) |
|---|---|---|---|---|
| 3DShapeNets [25] | (x, y, z) | 1k | 77.3 | 84.7 |
| VoxNet [21] | (x, y, z) | 1k | 83.0 | 85.9 |
| Subvolume [45] | (x, y, z) | - | 86.0 | 89.2 |
| VRN (single view) [46] | (x, y, z) | - | 88.98 | - |
| ECC [47] | (x, y, z) | 1k | 83.2 | 87.4 |
| PointNet [22] | (x, y, z) | 1k | 86.0 | 89.2 |
| PointNet++ [23] | (x, y, z) | 1k | - | 90.7 |
| KD-net [48] | (x, y, z) | 1k | - | 90.6 |
| PointCNN [49] | (x, y, z) | 1k | 88.1 | 92.2 |
| PCNN [50] | (x, y, z) | 1k | - | 92.3 |
| DGCNN [24] | (x, y, z) | 1k | 90.2 | 92.9 |
| KPConv [51] | (x, y, z) | 1k | - | 92.9 |
| PointASNL [52] | (x, y, z) | 1k | - | 92.9 |
| PointMLP [53] | (x, y, z) | 1k | - | 94.5 |
| Ours | (x, y, z) | 1k | 90.7 | 93.4 |
| Ours | (x, y, z) | 2k | 90.9 | 93.6 |
| PointNet++ [23] | (x, y, z), normal | 5k | - | 91.9 |
| PointConv [54] | (x, y, z), normal | 1k | - | 92.5 |
| DensePoint [55] | (x, y, z), voting | 1k | - | 93.2 |
| Method | mIoU | Air Plane | Bag | Cap | Car | Chair | Ear Phone | Guitar | Knife | Lamp | Laptop | Motor Bike | Mug | Pistol | Rocket | Skate Board | Table |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| # shapes | 2690 | 76 | 55 | 898 | 3758 | 69 | 787 | 392 | 1547 | 451 | 202 | 184 | 283 | 66 | 152 | 5271 | |
| PointNet [22] | 83.7 | 83.4 | 78.7 | 82.5 | 74.9 | 89.6 | 73.0 | 91.5 | 85.9 | 80.8 | 95.3 | 65.2 | 93.0 | 81.2 | 57.9 | 72.8 | 80.6 |
| PointNet++ [23] | 85.1 | 82.4 | 79.0 | 87.7 | 77.3 | 90.8 | 71.8 | 91.0 | 85.9 | 83.7 | 95.3 | 71.6 | 94.1 | 81.3 | 58.7 | 76.4 | 82.6 |
| KD-Net [48] | 82.3 | 80.1 | 74.6 | 74.3 | 70.3 | 88.6 | 73.5 | 90.2 | 87.2 | 81.0 | 94.9 | 57.4 | 86.7 | 78.1 | 51.8 | 69.9 | 80.3 |
| LocalFeatureNet [56] | 84.3 | 86.1 | 73.0 | 54.9 | 77.4 | 88.8 | 55.0 | 90.6 | 86.5 | 75.2 | 96.1 | 57.3 | 91.7 | 83.1 | 53.9 | 72.5 | 83.8 |
| PCNN [50] | 85.1 | 82.4 | 80.1 | 85.5 | 79.5 | 90.8 | 73.2 | 91.3 | 86.0 | 85.0 | 95.7 | 73.2 | 94.8 | 83.3 | 51.0 | 75.0 | 81.8 |
| A-SCN [57] | 84.6 | 83.8 | 80.8 | 83.5 | 79.3 | 90.5 | 69.8 | 91.7 | 86.5 | 82.9 | 96.0 | 69.2 | 93.8 | 82.5 | 62.9 | 74.4 | 80.8 |
| SpiderCNN [58] | 85.3 | 83.5 | 81.0 | 87.2 | 77.5 | 90.7 | 76.8 | 91.1 | 87.3 | 83.3 | 95.8 | 70.2 | 93.5 | 82.7 | 59.7 | 75.8 | 82.8 |
| SO-Net [59] | 84.6 | 81.9 | 83.5 | 84.8 | 78.1 | 90.8 | 72.2 | 90.1 | 83.6 | 82.3 | 95.2 | 69.3 | 94.2 | 80.0 | 51.6 | 72.1 | 82.6 |
| DGCNN [24] | 85.2 | 84.0 | 83.4 | 86.7 | 77.8 | 90.6 | 74.7 | 91.2 | 87.5 | 82.8 | 95.7 | 66.3 | 94.9 | 81.1 | 63.5 | 74.5 | 82.6 |
| RGCNN [60] | 84.3 | 80.2 | 82.8 | 92.6 | 75.3 | 89.2 | 73.7 | 91.3 | 88.4 | 83.3 | 96.0 | 63.9 | 95.7 | 60.9 | 44.6 | 72.9 | 80.4 |
| PCT [61] | 86.4 | 85.0 | 82.4 | 89.0 | 81.2 | 91.9 | 71.5 | 91.3 | 88.1 | 86.3 | 95.8 | 64.6 | 95.8 | 83.6 | 62.2 | 77.6 | 83.7 |
| KPConv [51] | 86.4 | 84.6 | 86.3 | 87.2 | 81.1 | 91.1 | 77.8 | 92.6 | 88.4 | 82.7 | 96.2 | 78.1 | 95.8 | 85.4 | 69.0 | 82.0 | 83.6 |
| FG-Net [62] | 86.6 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| Ours | 85.4 | 84.1 | 83.2 | 86.0 | 78.8 | 90.6 | 76.9 | 91.9 | 88.4 | 82.3 | 96.0 | 65.5 | 93.7 | 84.2 | 64.2 | 76.8 | 80.6 |
| Method | mIoU (%) | OA (%) |
|---|---|---|
| PointNet (baseline) [22] | 20.1 | 53.2 |
| PointNet [22] | 47.6 | 78.5 |
| G + RCU [63] | 49.7 | 81.1 |
| MS + CU (2) [63] | 47.8 | 79.2 |
| SegCloud [32] | 48.9 | - |
| ShapeContextNet [57] | 52.7 | 81.6 |
| DGCNN [24] | 56.1 | 84.1 |
| KPConv [51] | 69.6 | - |
| Ours | 59.6 | 85.9 |
| Number of Nearest Neighbors (k) | mA (%) | OA (%) |
|---|---|---|
| 1 | 84.6 | 90.2 |
| 2 | 85.2 | 90.5 |
| 5 | 89.1 | 92.4 |
| 10 | 89.8 | 93.0 |
| 20 | 90.7 | 93.4 |
| 40 | 90.4 | 93.1 |
| Method | Input | #Params | Processing Time | OA (%) |
|---|---|---|---|---|
| PointNet [22] | 1 k | 3.5 M | 13.2 ms | 89.2 |
| PointNet++ [23] | 1 k | 1.48 M | 34.8 ms | 90.7 |
| KPConv [51] | 1 k | 15.2 M | 33.5 ms | 92.9 |
| InterpCNN [64] | 1 k | 12.5 M | 28.2 ms | 93.0 |
| DGCNN [24] | 1 k | 1.81 M | 86.2 ms | 92.9 |
| MVTN [65] | - | 3.5 M | 50.2 ms | 93.8 |
| Ours | 1 k | 2.03 M | 92.4 ms | 93.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jing, W.; Zhang, W.; Li, L.; Di, D.; Chen, G.; Wang, J. AGNet: An Attention-Based Graph Network for Point Cloud Classification and Segmentation. Remote Sens. 2022, 14, 1036. https://doi.org/10.3390/rs14041036
Jing W, Zhang W, Li L, Di D, Chen G, Wang J. AGNet: An Attention-Based Graph Network for Point Cloud Classification and Segmentation. Remote Sensing. 2022; 14(4):1036. https://doi.org/10.3390/rs14041036
Chicago/Turabian StyleJing, Weipeng, Wenjun Zhang, Linhui Li, Donglin Di, Guangsheng Chen, and Jian Wang. 2022. "AGNet: An Attention-Based Graph Network for Point Cloud Classification and Segmentation" Remote Sensing 14, no. 4: 1036. https://doi.org/10.3390/rs14041036
APA StyleJing, W., Zhang, W., Li, L., Di, D., Chen, G., & Wang, J. (2022). AGNet: An Attention-Based Graph Network for Point Cloud Classification and Segmentation. Remote Sensing, 14(4), 1036. https://doi.org/10.3390/rs14041036