
Data-Driven Selection of Land Product Validation Station Based on Machine Learning

 , , , , and
, , , , and
Abstract
:
1. Introduction
2. Data
2.1. Evaluation Indicator
2.2. Machine Learning Dataset
2.3. Data Preprocessing
3. Methods
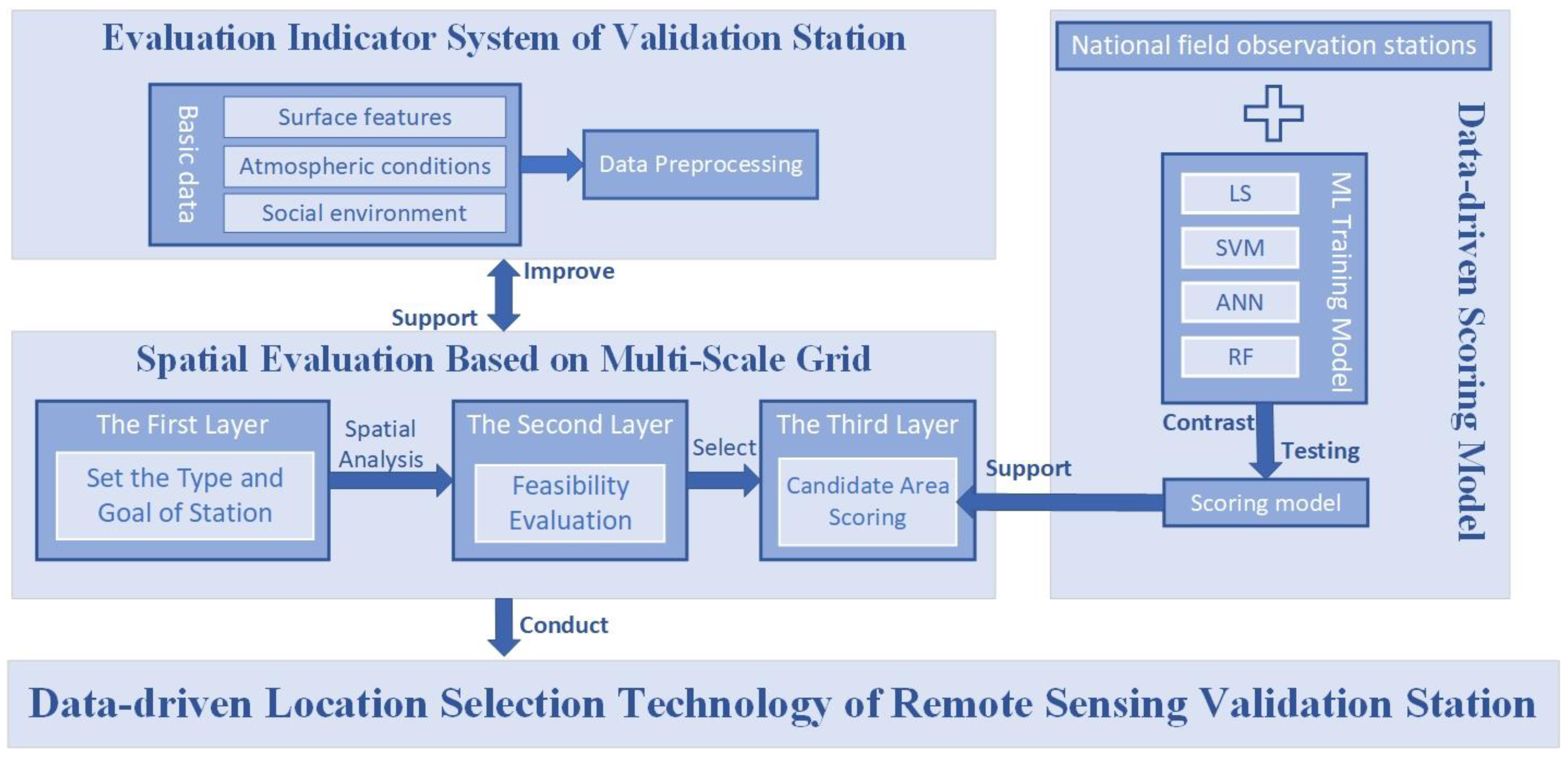
3.1. Constructing the Evaluation Indicator System
3.2. Spatial Evaluation Based on Multi-Scale Grid
3.3. Constructing the Data-Driven Scoring Model Based on Machine Learning
3.4. Evaluation Approach
3.4.1. Correlation Evaluation
3.4.2. Percentage Deviation
4. Results
4.1. Comparison of DSS-LPV Models Based on Four Machine Learning Methods
4.2. Analysis of DSS-LPV Model Based on Random Forest
4.2.1. Accuracy Verification of DSS-LPV Model
4.2.2. Correlation Analysis of Evaluation Indicators and Score in the Third-Layer Grid
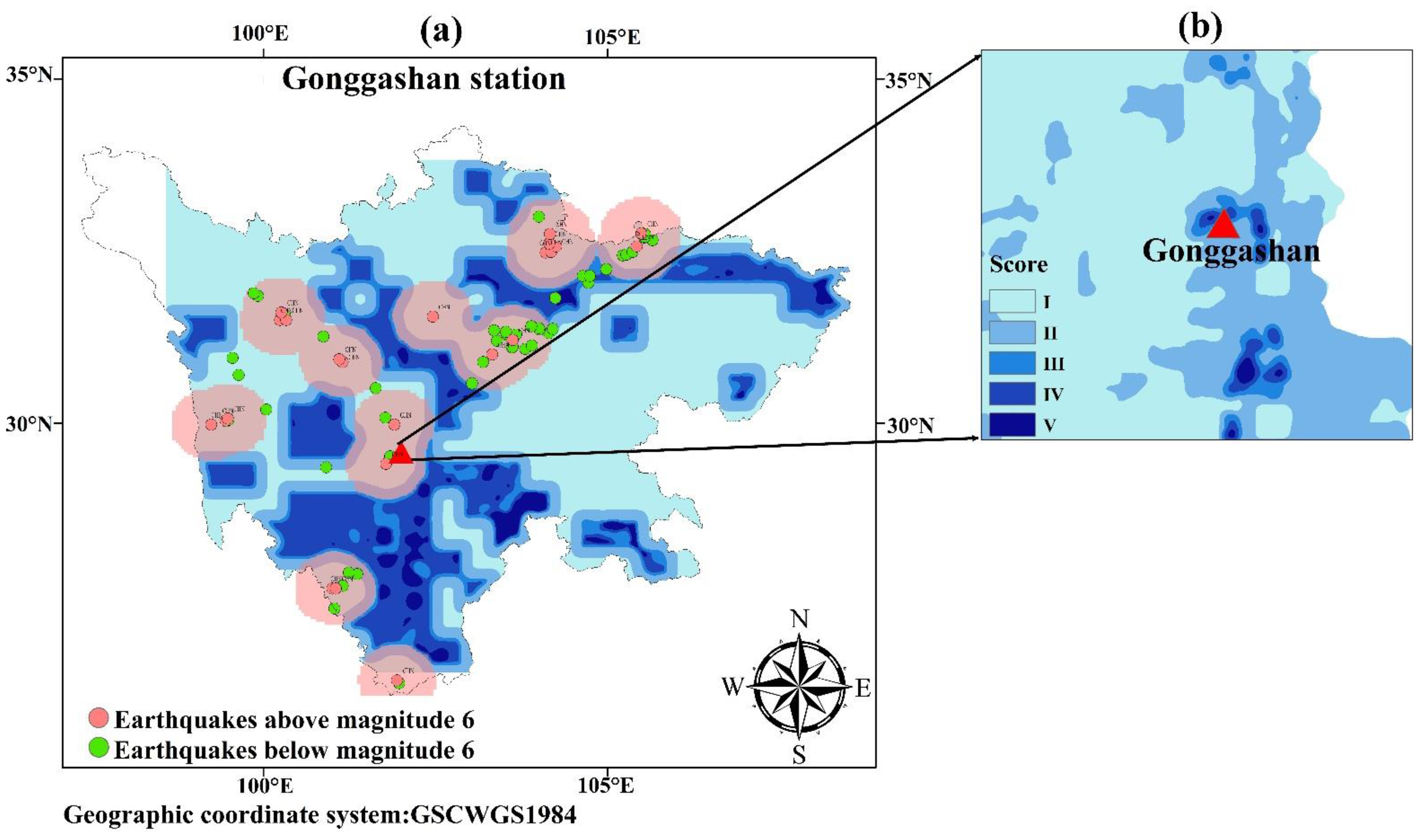
4.2.3. Reliability Analysis of DSS-LPV Model Based on Score Density Map
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liang, S. Quantitative Remote Sensing of Land Surfaces; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2003. [Google Scholar]
- Li, G.; Zhang, H.; Zhang, L.; Wang, Y.; Tian, C. Development and trend of Earth observation data sharing. J. Remote Sens. 2016, 20, 979–990. [Google Scholar]
- Xu, G.; Liu, Q.; Chen, L.; Liu, L. Remote sensing for China’s sustainable development: Opportunities and challenges. J. Remote Sens. 2016, 20, 679–688. [Google Scholar]
- Liang, S.; Fang, H.; Chen, M.; Shuey, C.J.; Walthall, C.; Daughtry, C.; Morisette, J.; Schaaf, C.; Strahler, A. Validating MODIS land surface reflectance and albedo products: Methods and preliminary results. Remote Sens. Environ. 2002, 83, 149–162. [Google Scholar] [CrossRef]
- Justice, C.; Belward, A.; Morisette, J.; Lewis, P.; Privette, J.; Baret, F. Developments in the ‘validation’ of satellite sensor products for the study of the land surface. Int. J. Remote Sens. 2000, 21, 3383–3390. [Google Scholar] [CrossRef]
- Morisette, J.T.; Privette, J.L.; Justice, C.O. A framework for the validation of MODIS Land products. Remote Sens. Environ. 2002, 83, 77–96. [Google Scholar] [CrossRef]
- Zhang, R.; Tian, J.; Li, Z.; Su, H.; Chen, S. Principles and methods for the validation of quantitative remote sensing products. Sci. Sin. (Terrae) 2010, 40, 211–222. [Google Scholar] [CrossRef]
- Wu, X.; Xiao, Q.; Wen, J.; You, D.; Hueni, A. Advances in quantitative remote sensing product validation: Overview and current status. Earth-Sci. Rev. 2019, 196, 102875. [Google Scholar] [CrossRef]
- Morisette, J.T.; Baret, F.; Privette, J.L.; Myneni, R.B. Validation of global moderate-resolution LAI products: A framework proposed within the CEOS land product validation subgroup. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1804–1817. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Y.; Li, J.; Liu, Q. Review article: Global LAI ground validation dataset and product validation framework. Adv. Earth Sci. 2012, 27, 165–174. [Google Scholar]
- Bai, J.H.; Xiao, Q.; Liu, Q.H.; Wen, J.G. The research of construction the target ranges to validate remote sensing products. Remote Sens. Technol. Appl. 2015, 30, 573–578. [Google Scholar]
- Council, N. Review of the WATERS Network Science Plan; National Academies Press: Washington, DC, USA, 2010. [Google Scholar]
- Jia, Z.; Liu, S.; Xu, Z.; Chen, Y.; Zhu, M. Validation of remotely sensed evapotranspiration over the Hai River Basin, China. J. Geophys. Res. Atmos. 2012, 117, D13113. [Google Scholar] [CrossRef]
- Liu, S.M.; Xu, Z.W.; Zhu, Z.L.; Jia, Z.Z.; Zhu, M.J. Measurements of evapotranspiration from eddy-covariance systems and large aperture scintillometers in the Hai River Basin, China. J. Hydrol. Amst. 2013, 487, 24–38. [Google Scholar] [CrossRef]
- Song, Y.; Wang, J.; Yang, K.; Ma, M.; Xin, L.; Zhang, Z.; Wang, X. A revised surface resistance parameterisation for estimating latent heat flux from remotely sensed data. Int. J. Appl. Earth Obs. Geoinf. 2012, 17, 76–84. [Google Scholar] [CrossRef]
- Li, R.; Zhou, X.; Lv, T.; Tao, Z.; Wang, J.; Xie, F. Optimal sampling strategy for authenticity test in heterogeneous vegetated areas. Trans. Chin. Soc. Agric. Eng. 2021, 37, 177–186. [Google Scholar]
- Ma, M.; Che, T.; Li, X.; Xiao, Q.; Zhao, K.; Xin, X. A Prototype Network for Remote Sensing Validation in China. Remote Sens. 2015, 7, 5187–5202. [Google Scholar] [CrossRef] [Green Version]
- Running, S.W.; Baldocchi, D.D.; Turner, D.P.; Gower, S.T.; Bakwin, P.S.; Hibbard, K.A. A Global Terrestrial Monitoring Network Integrating Tower Fluxes, Flask Sampling, Ecosystem Modeling and EOS Satellite Data. Remote Sens. Environ. 1999, 70, 108–127. [Google Scholar] [CrossRef]
- Baret, F.; Morissette, J.T.; Fernandes, R.; Champeaux, J.L. Evaluation of the Representativeness of Networks of Sites for the Global Validation and Intercomparison of Land Biophysical Products: Proposition of the CEOS-BELMANIP. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1794–1803. [Google Scholar] [CrossRef]
- Wang, J.; Che, T.; Zhang, L.; Jin, R.; Wang, W. The cold regions hydrological remote sensing and ground-based synchronous observation experiment in the upper reaches of Heihe river. J. Glaciol. Geocryol. 2009, 31, 189–197. [Google Scholar]
- Ma, M.; Liu, Q.; Yan, G.; Chen, E.; Xiao, Q. Simultaneous remote sensing and ground-based experiment in the Heihe river basin: Experiment of forest hydrology and arid region hydrology in the middle reaches. Adv. Earth Sci. 2009, 24, 681–695. [Google Scholar]
- Jia, S.; Ma, M.; Yu, W. Validation of the LAI produce in Heihe river basin. Remote Sens. Technol. Appl. 2014, 29, 1037–1045. [Google Scholar]
- Li, X.; Chen, G.; Liu, S.; Xiao, Q. Heihe Watershed Allied Telemetry Experimental Research (HiWATER): Scientific Objectives and Experimental Design. Bull. Am. Meteorol. Soc. 2013, 94, 1145–1160. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Li, Z.; Wang, J.; Ma, M. Progresses on the Watershed Allied Telemetry Experimental Research (WATER). Remote Sens. Technol. Appl. 2012, 27, 637–649. [Google Scholar]
- Jin, R.; Li, X.; Ma, M.; Ge, Y.; Liu, S. Key methods and experiment verification for the validation of quantitative remote sensing products. Adv. Earth Sci. 2017, 32, 630–642. [Google Scholar]
- Hakimi, S.L. Optimum Locations of Switching Centers and the Absolute Centers and Medians of a Graph. Oper. Res. 1964, 12, 450–459. [Google Scholar] [CrossRef]
- Hale, T.S.; Moberg, C.R. Location Science Research: A Review. Ann. Oper. Res. 2003, 123, 21–35. [Google Scholar] [CrossRef]
- Li, H.; Yu, L.; Cheng, E.W.L. A GIS-based site selection system for real estate projects. Constr. Innov. 2005, 5, 231–241. [Google Scholar]
- Owen, S.H.; Daskin, M.S. Strategic facility location: A review. Eur. J. Oper. Res. 1998, 111, 423–447. [Google Scholar] [CrossRef]
- Norat, R.T.; Amparo, B.P.; Juan, B.V.; Francisco, M.V. The retail site location decision process using GIS and the analytical hierarchy process. Appl. Geogr. 2013, 40, 191–198. [Google Scholar]
- Vlachopoulou, M.; Silleos, G.; Manthou, V. Geographic information systems in warehouse site selection decisions. Int. J. Prod. Econ. 2001, 71, 205–212. [Google Scholar] [CrossRef]
- Jacek, M. GIS-based multicriteria decision analysis: A survey of the literature. Int. J. Geogr. Inf. Sci. 2006, 20, 703–726. [Google Scholar]
- Nas, B.; Cay, T.; Iscan, F.; Berktay, A. Selection of MSW landfill site for Konya, Turkey using GIS and multi-criteria evaluation. Environ. Monit. Assess. 2010, 160, 491–500. [Google Scholar] [CrossRef] [PubMed]
- Noorollahi, Y.; Yousefi, H.; Mohammadi, M. Multi-criteria decision support system for wind farm site selection using GIS. Sustain. Energy Technol. Assess. 2016, 13, 38–50. [Google Scholar] [CrossRef]
- Ozturk, D.; Kl, F. GIS-based multi-criteria decision analysis for parking site selection. Kuwait J. Sci. 2020, 47, 2–15. [Google Scholar]
- Shao, M.; Han, Z.; Sun, J.; Xiao, C.; Zhang, S.; Zhao, Y. A review of multi-criteria decision making applications for renewable energy site selection. Renew. Energy 2020, 157, 377–403. [Google Scholar] [CrossRef]
- Wang, J.; Jing, Y.; Zhang, C.; Zhao, J. Review on multi-criteria decision analysis aid in sustainable energy decision-making. Renew. Sustain. Energy Rev. 2009, 13, 2263–2278. [Google Scholar] [CrossRef]
- Chen, Y.; Yu, J.; Khan, S. The spatial framework for weight sensitivity analysis in AHP-based multi-criteria decision making. Environ. Model. Softw. 2013, 48, 129–140. [Google Scholar] [CrossRef]
- Wang, G.; Qin, L.; Li, Q.; Chen, L. Landfill site selection using spatial information technologies and AHP: A case study in Beijing, China. J. Environ. Manag. 2009, 90, 2414–2421. [Google Scholar] [CrossRef]
- Messaoudi, D.; Settou, N.; Negrou, B.; Rahmouni, S.; Settou, B.; Mayou, I. Site selection methodology for the wind-powered hydrogen refueling station based on AHP-GIS in Adrar, Algeria. Energy Procedia 2019, 162, 67–76. [Google Scholar] [CrossRef]
- Othman, A.A.; Al-Maamar, A.F.; Al-Manmi, D.A.M.A.; Liesenberg, V.; Hasan, S.E.; Obaid, A.K.; Al-Quraishi, A.M.F. GIS-Based Modeling for Selection of Dam Sites in the Kurdistan Region, Iraq. ISPRS Int. J. Geo-Inf. 2020, 9, 244. [Google Scholar] [CrossRef] [Green Version]
- Rahmat, Z.G.; Niri, M.V.; Alavi, N.; Goudarzi, G.; Babaei, A.A.; Baboli, Z.; Hosseinzadeh, M. Landfill site selection using GIS and AHP: A case study: Behbahan, Iran. KSCE J. Civ. Eng. 2017, 21, 111–118. [Google Scholar] [CrossRef]
- Şener, Ş.; Şener, E.; Nas, B.; Karagüzel, R. Combining AHP with GIS for landfill site selection: A case study in the Lake Beyşehir catchment area (Konya, Turkey). Waste Manag. 2010, 30, 2037–2046. [Google Scholar] [CrossRef] [PubMed]
- Uyan, M. GIS-based solar farms site selection using analytic hierarchy process (AHP) in Karapinar region, Konya/Turkey. Renew. Sustain. Energy Rev. 2013, 28, 11–17. [Google Scholar] [CrossRef]
- Uyan, M. MSW landfill site selection by combining AHP with GIS for Konya, Turkey. Environ. Earth Sci. 2014, 71, 1629–1639. [Google Scholar] [CrossRef]
- Ma, C.; Yang, Y.; Wang, J.; Chen, Y.; Yang, D. Determining the Location of a Swine Farming Facility Based on Grey Correlation and the TOPSIS Method. Trans. ASABE 2017, 60, 1281. [Google Scholar] [CrossRef]
- Zhang, X.H.; Wang, W.B.; Zhang, S.M.; Zhu, Y.Q. Research on Location of Integrating Village Migration in Coal Mining Areas Based on AHP-Grey Correlation. Appl. Mech. Mater. 2013, 2546, 1851–1855. [Google Scholar] [CrossRef]
- Zolfani, S.H.; Yazdani, M.; Torkayesh, A.E.; Derakhti, A. Application of a Gray-Based Decision Support Framework for Location Selection of a Temporary Hospital during COVID-19 Pandemic. Symmetry 2020, 12, 886. [Google Scholar] [CrossRef]
- Chu, J.Y.; Su, Y.P. Comprehensive Evaluation Index System in the Application for Earthquake Emergency Shelter Site. Adv. Mater. Res. 2011, 1035, 79–83. [Google Scholar] [CrossRef]
- Qin, C.; Li, B.; Shi, B.; Qin, T.; Xiao, J.; Xin, Y. Location of substation in similar candidates using comprehensive evaluation method base on DHGF. Measurement 2019, 146, 152–158. [Google Scholar] [CrossRef]
- Jiang, X.; Li, Z.; Xi, X.; Li, X.; Li, Z. Basic frame of remote sensing validation system. Arid Land Geogr. 2008, 31, 567–571. [Google Scholar]
- Ali, I.; Greifeneder, F.; Stamenkovic, J.; Neumann, M.; Notarnicola, C. Review of Machine Learning Approaches for Biomass and Soil Moisture Retrievals from Remote Sensing Data. Remote Sens. 2015, 7, 16398–16421. [Google Scholar] [CrossRef] [Green Version]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef] [Green Version]
- Hengl, T.; de Jesus, J.M.; Heuvelink, G.B.M.; Gonzalez, M.R.; Kilibarda, M.; Blagotic, A.; Shangguan, W.; Wright, M.N.; Geng, X.Y.; Bauer-Marschallinger, B.; et al. SoilGrids250m: Global gridded soil information based on machine learning. PLoS ONE 2017, 12, e0169748. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Holloway, J.; Mengersen, K. Statistical Machine Learning Methods and Remote Sensing for Sustainable Development Goals: A Review. Remote Sens. 2018, 10, 1365. [Google Scholar] [CrossRef] [Green Version]
- Shirmard, H.; Farahbakhsh, E.; Muller, R.D.; Chandra, R. A review of machine learning in processing remote sensing data for mineral exploration. Remote Sens. Environ. 2022, 268, 112750. [Google Scholar] [CrossRef]
- Gong, J. Chances and Challenges for Development of Surveying and Remote Sensing in the Age of Artificial Intelligence. Geomat. Inf. Sci. Wuhan Univ. 2018, 43, 1788–1796. [Google Scholar]
- Shi, Z.; Lin, W.; Li, Z. Research on Site Selection of Radar Test Site Based on System Comprehensive Evaluation Method. In Proceedings of the 4th Annual Meeting of the Electronic Repair Group of the Chinese Society of Naval Architecture and Information Equipment Support Seminar, Chengdu, China, 1 October 2005; p. 5. [Google Scholar]
- Cherkassky, V. The nature of statistical learning theory. IEEE Trans. Neural Netw. 1997, 8, 1564. [Google Scholar] [CrossRef] [Green Version]
- Haykin, S. Neural Networks: A Comprehensive Foundation, 3rd ed.; Prentice Hall: Hoboken, NJ, USA, 2007. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Guan, H.Y.; Li, J.; Chapman, M.; Deng, F.; Ji, Z.; Yang, X. Integration of orthoimagery and lidar data for object-based urban thematic mapping using random forests. Int. J. Remote Sens. 2013, 34, 5166–5186. [Google Scholar] [CrossRef]
- Koreen, M.; Murray, R. On the Importance of Training Data Sample Selection in Random Forest Image Classification: A Case Study in Peatland Ecosystem Mapping. Remote Sens. 2015, 7, 8489–8515. [Google Scholar]
- Lawrence, R.L.; Wood, S.D.; Sheley, R.L. Mapping invasive plants using hyperspectral imagery and Breiman Cutler classifications (randomForest). Remote Sens. Environ. 2006, 100, 356–362. [Google Scholar] [CrossRef]
- Nitze, I.; Barrett, B.; Cawkwell, F. Temporal optimisation of image acquisition for land cover classification with Random Forest and MODIS time-series. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 136–146. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Schellhaas, H. A modified Kolmogorov-Smirnov test for a rectangular distribution with unknown parameters: Computation of the distribution of the test statistic. Stat. Pap. 1999, 40, 343. [Google Scholar] [CrossRef]
- Meddis, R. Statistics Using Ranks; Blackwell Pub: Oxford, UK, 1984. [Google Scholar]
- Senthilnathan, S. Usefulness of Correlation Analysis. SSRN Electron. J. 2019. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Indicator | Source | Extent | Spatial Resolution | Time |
|---|---|---|---|---|---|
| Surface features | Acreage | Satellite remote sensing image | Global | 30 m/8 m/2 m | 2011–2021 |
| Slope | TanDEM-X | Global | 3 arcseconds | 2010–2015 | |
| Altitude | |||||
| Earthquake prone area | China Earthquake Administration | China | 1900–2013 | ||
| Nature reserve | Resource and Environment Science and Data Center | China | 2018 | ||
| Land cover classification | GLC_FCS 30-2020 product | Global | 30 m | 2019–2020 | |
| Atmospheric conditions | Aerosol optical depth | MODIS/Terra | Global | 3 km | 2000–2021 |
| Aerosol cloud/water vapor | 1° | ||||
| Climate and weather | CEDA/WorldClim/NKN | Global | 0.5°/2.5′/1/24° | 1970–2018 | |
| Number of sunny days | |||||
| Social environment | Administrative divisions | GADM | Global | 2018 | |
| Traffic accessibility | Geofabrik | 2018 | |||
| Population density | WorldPop | 1 km | 2000–2020 | ||
| Power supply conditions | NOAA/NASA | 3 arcseconds/500 m | 1992–2013/2016 |
| Classification | Indicators | Processing Method |
|---|---|---|
| Target | Administrative divisions | Select attribute |
| Climatic regionalization | Select attribute | |
| Land cover classification | Select the type code | |
| Binary | Nature reserve | Clip raster based on vector |
| Earthquake prone area | Filter year/Calculate Euclidean distance/Buffer | |
| Spatial | Cloud | Calculate the annual average value |
| Precipitation | Calculate the annual average value | |
| Road network | Calculate Euclidean distance | |
| Urban area | Calculate Euclidean distance/Set threshold/Buffer | |
| Slope | Calculate slope | |
| Altitude | Take the absolute value | |
| Population density | Piecewise assign | |
| Night light | Piecewise assign | |
| Temporal | Number of sunny days | Piecewise assign |
| Observation time | Set threshold/Select |
| Grid | Indicators | Volume | Running Time |
|---|---|---|---|
| The first layer | Administrative divisions | 30.4 MB | 15.7 s |
| Climatic regionalization | 644 KB | ||
| Land cover classification | 11.4 GB | ||
| The second layer | Nature reserve | 612 KB | 11.6 s |
| Earthquake prone area | 276 KB | ||
| Cloud | 402 MB | ||
| Precipitation | 1.66 GB | ||
| The third layer | Road | 1.64 GB | 62.6 s |
| Urban distance | 11.4 GB | ||
| Slope | 32.2 GB | ||
| Altitude | 32.2 GB | ||
| Population density | 46.6 MB | ||
| Night light | 2.33 GB |
| Stations | Type | Score |
|---|---|---|
| Qianyanzhou | Agricultural | 0.8111 |
| Hailun | 0.6428 | |
| Yanting | 0.9142 | |
| Luancheng | 0.9170 | |
| Gonggashan | Forest | 0.9627 |
| Xishuangbanna | 0.7495 | |
| Dinghushan | 0.7179 | |
| Inner Mongolia | Grassland | 0.9163 |
| Guyuan | 0.8423 | |
| Average | 0.8304 |
| Indicator | Urban Distance | Road Distance | Slope | Altitude | Population Density | Night Light |
|---|---|---|---|---|---|---|
| 0.379 | 0.592 | −0.248 | 0.369 | −0.616 | −0.310 |
| Stations | Urban Distance | Road Distance | Slope | Altitude | Population Density | Night Light |
|---|---|---|---|---|---|---|
| Hailun | 46.80% | 60.27% | 9.44% | 11.25% | 18.73% | 15.16% |
| Xishuangbanna | 25.83% | 28.05% | 7.18% | 40.54% | 6.65% | 11.76% |
| Guyuan | 15.39% | 38.59% | 3.73% | 7.43% | 12.74% | 10.37% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, R.; Tao, Z.; Zhou, X.; Lv, T.; Wang, J.; Xie, F.; Zhai, M. Data-Driven Selection of Land Product Validation Station Based on Machine Learning. Remote Sens. 2022, 14, 813. https://doi.org/10.3390/rs14040813
Li R, Tao Z, Zhou X, Lv T, Wang J, Xie F, Zhai M. Data-Driven Selection of Land Product Validation Station Based on Machine Learning. Remote Sensing. 2022; 14(4):813. https://doi.org/10.3390/rs14040813
Chicago/Turabian StyleLi, Ruoxi, Zui Tao, Xiang Zhou, Tingting Lv, Jin Wang, Futai Xie, and Mingjian Zhai. 2022. "Data-Driven Selection of Land Product Validation Station Based on Machine Learning" Remote Sensing 14, no. 4: 813. https://doi.org/10.3390/rs14040813
APA StyleLi, R., Tao, Z., Zhou, X., Lv, T., Wang, J., Xie, F., & Zhai, M. (2022). Data-Driven Selection of Land Product Validation Station Based on Machine Learning. Remote Sensing, 14(4), 813. https://doi.org/10.3390/rs14040813