
Assessing the Accuracy and Potential for Improvement of the National Land Cover Database’s Tree Canopy Cover Dataset in Urban Areas of the Conterminous United States

 and
and
Abstract
:1. Introduction
2. Methods
2.1. Data
- (a)
- Surface temperature and NDVI. Tree cover has a negative correlation with surface temperature but a positive correlation with normalized difference vegetation index (NDVI) [29,30]. Therefore, we produced surface temperature and NDVI datasets from Landsat 8 images for each city or county (Table 1) as explanatory variables to evaluate NLCD-TC error. To produce these, we downloaded the four least cloud-covered summer images for the years 2013–2015. Considering the limited number of cloud-free images in humid parts of the US in the summertime, we judged four images per tile to provide sufficient variation and manageable computational demand. We calculated surface temperature using Landsat 8 band 10 and NDVI using bands 4 and 5 of the images based on USGS guidelines [31]. We extracted median values for surface temperature and NDVI for all four images in each scene.
- (b)
- Building footprints. In urban environments, trees and buildings create a heterogeneous environment, which makes tree detection using remotely sensed data challenging. To create a gradient of built density, we used the area of building footprints in each cell; this dataset is extracted from Microsoft building footprint data [32]. Microsoft reported that these data have 99.3% precision and 93.5% pixel recall accuracy. Heris et al. [33] evaluated the accuracy of this dataset and found it to detect 96, 93, and 94% of buildings over 100 m2 in Denver, CO, New York City, NY, and Los Angeles County, CA, respectively. We used three of the six summary datasets generated by Heris et al. [33]: (1) total building footprint coverage per cell (m2 per 900 m2 cell); (2) number of buildings that intersect each cell; and (3) area of the average building intersecting the cell (m2). These data have been converted into raster datasets that summarize building data for 30 m cells aligned with NLCD data, better meeting the needs of national-scale models. Because Microsoft used aerial photos from different years to generate this dataset, they did not provide a specific date for these data.
- (c)
- Urban density. We used an urban morphology classification produced by Heris [34], which is based on Census and impervious surface data for the years 2000 and 2010 (we used the 2010 product in this study). This classification is based on the neighborhood density of each 30 m cell for the conterminous US for five densities: high, medium, and low-density urban areas, urban fringe, and suburbs. This dataset helps to stratify the distribution of NLCD-TC error across different urban morphologies in built environments as well as natural (non-built) areas falling within cities or counties of interest. We also used this dataset to separate built and undeveloped areas. For undeveloped cells, we applied a query to exclude cells that have an impervious surface cover greater than 0%.
- (d)
- Climate data. To incorporate variation in climatic environments across cities, which helps explain differences in urban tree occurrence, in the NLCD-TC predictive model, we extracted the average annual high and low temperature and average annual precipitation for each city (1990–2018) from the US Climate Data website [35].
- (e)
- Year built of structures. We used the median year built of structures from the 2010 Census Block Group data [36] to incorporate the age of neighborhoods in our NLCD-TC predictive model assessment. This accounts for the fact that the maturity and size of urban tree canopies often correlate with the age of establishment of residential neighborhoods [37].
- (f)
- National Land Cover Database (NLCD) land cover. We used the most recent edition of the 2011 NLCD land cover [24] in the NLCD-TC predictive model.
2.2. Dependent and Independent Variables
2.3. Predictive Model
2.4. Validation of the Predictive Model
2.5. Use Case: Running Corrected Data vs. Native NLCD-TC for Two Ecosystem Accounting Models
2.6. Code Availability
3. Results
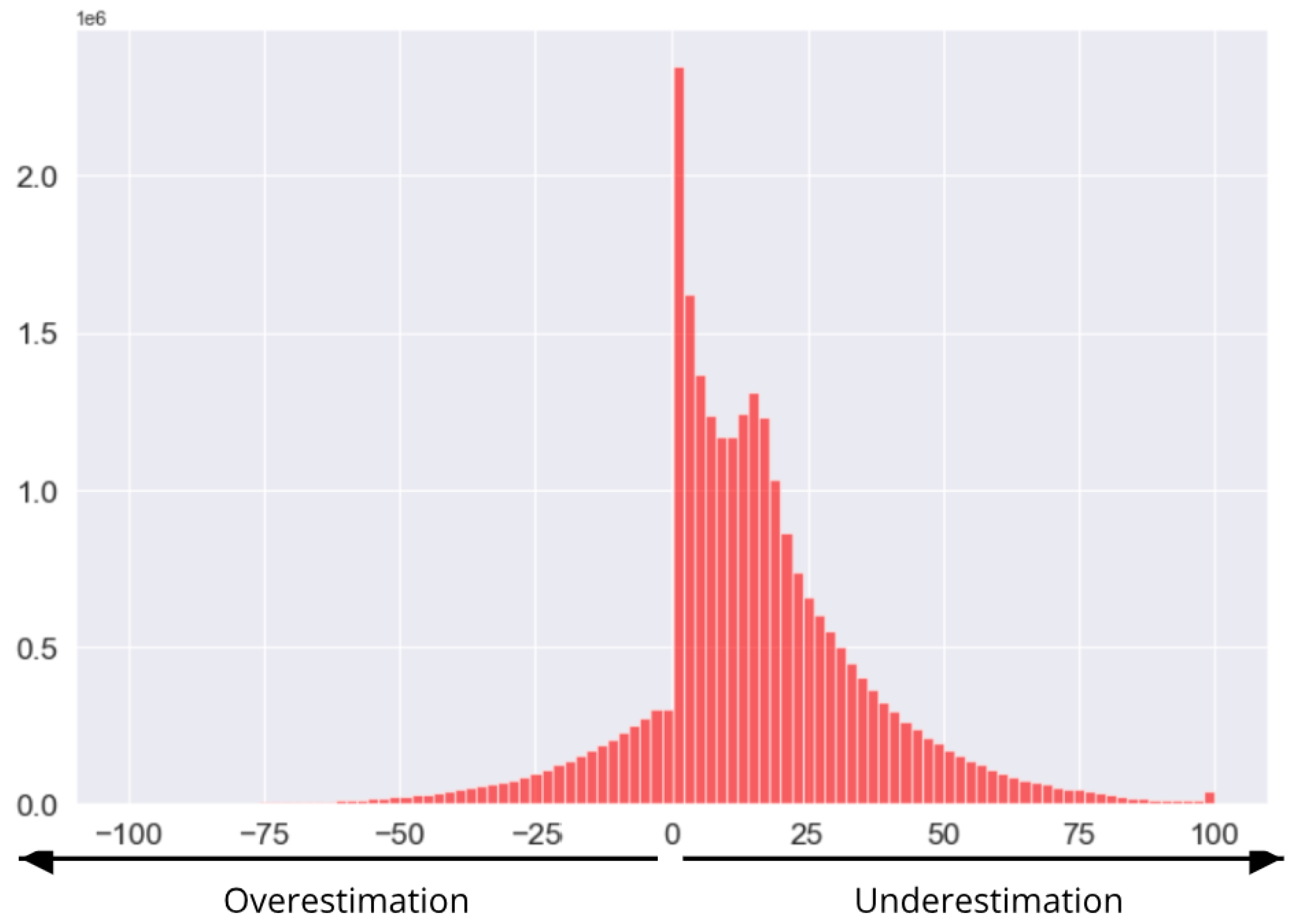
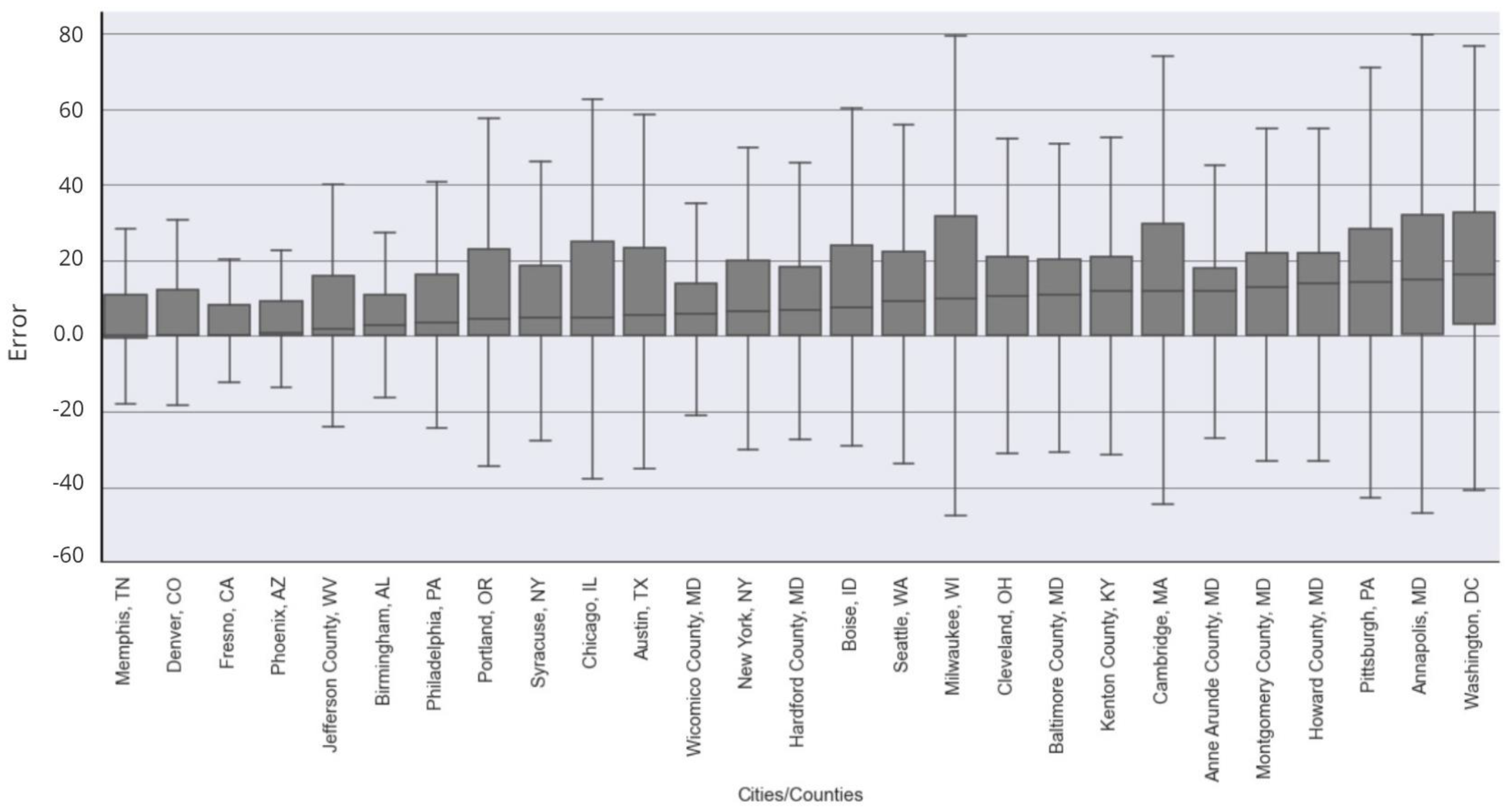
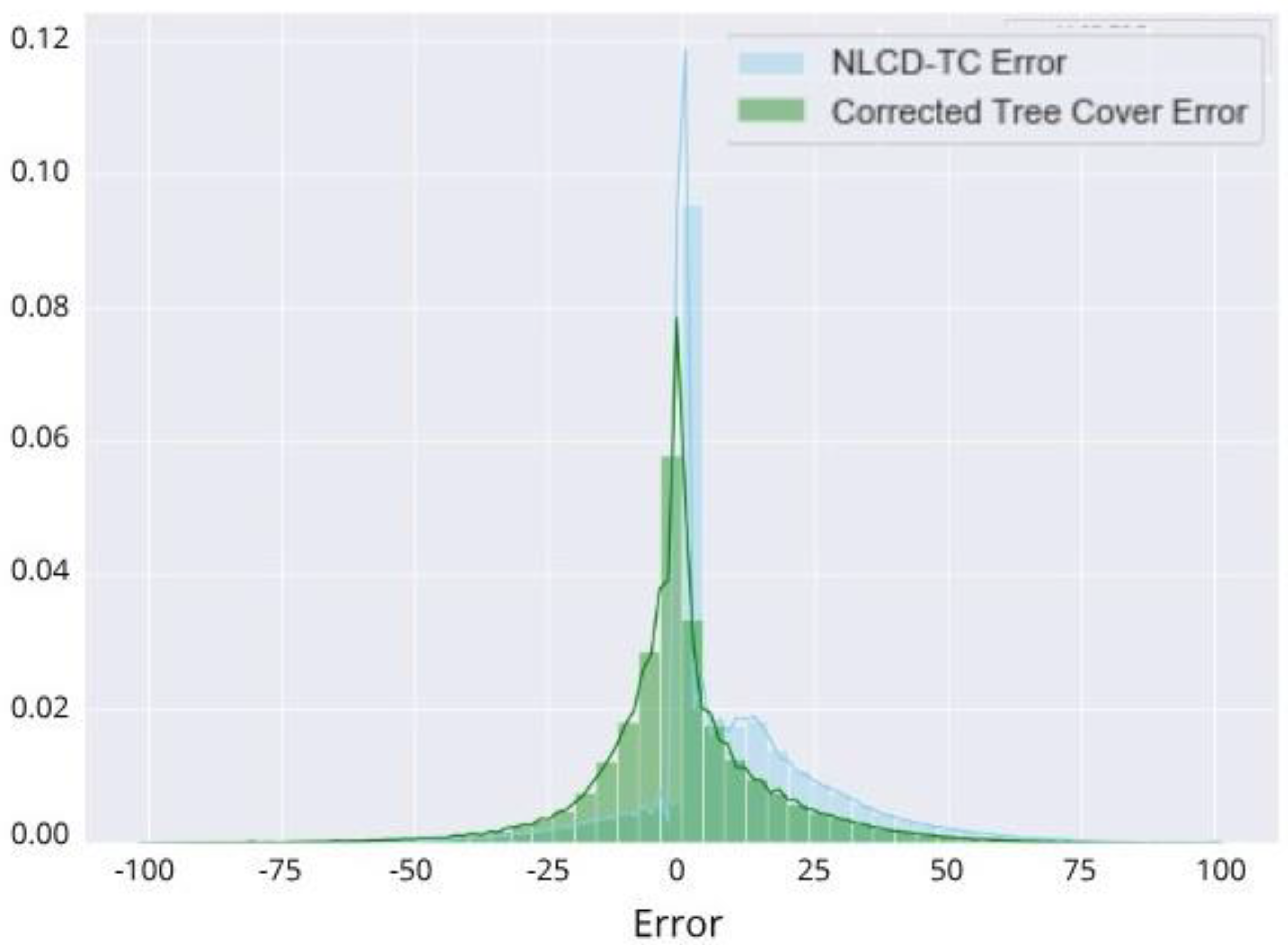
3.1. General Error Distribution
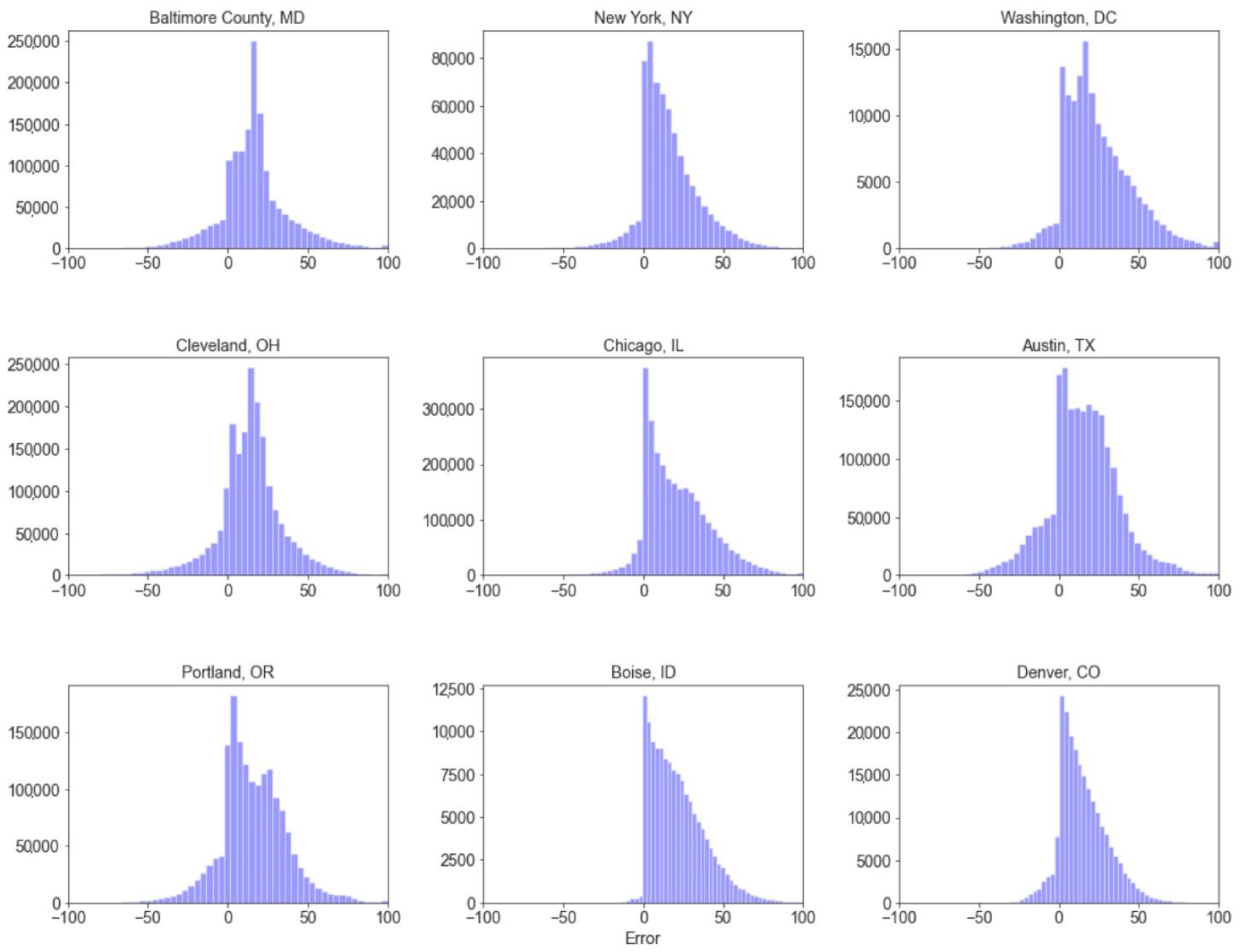
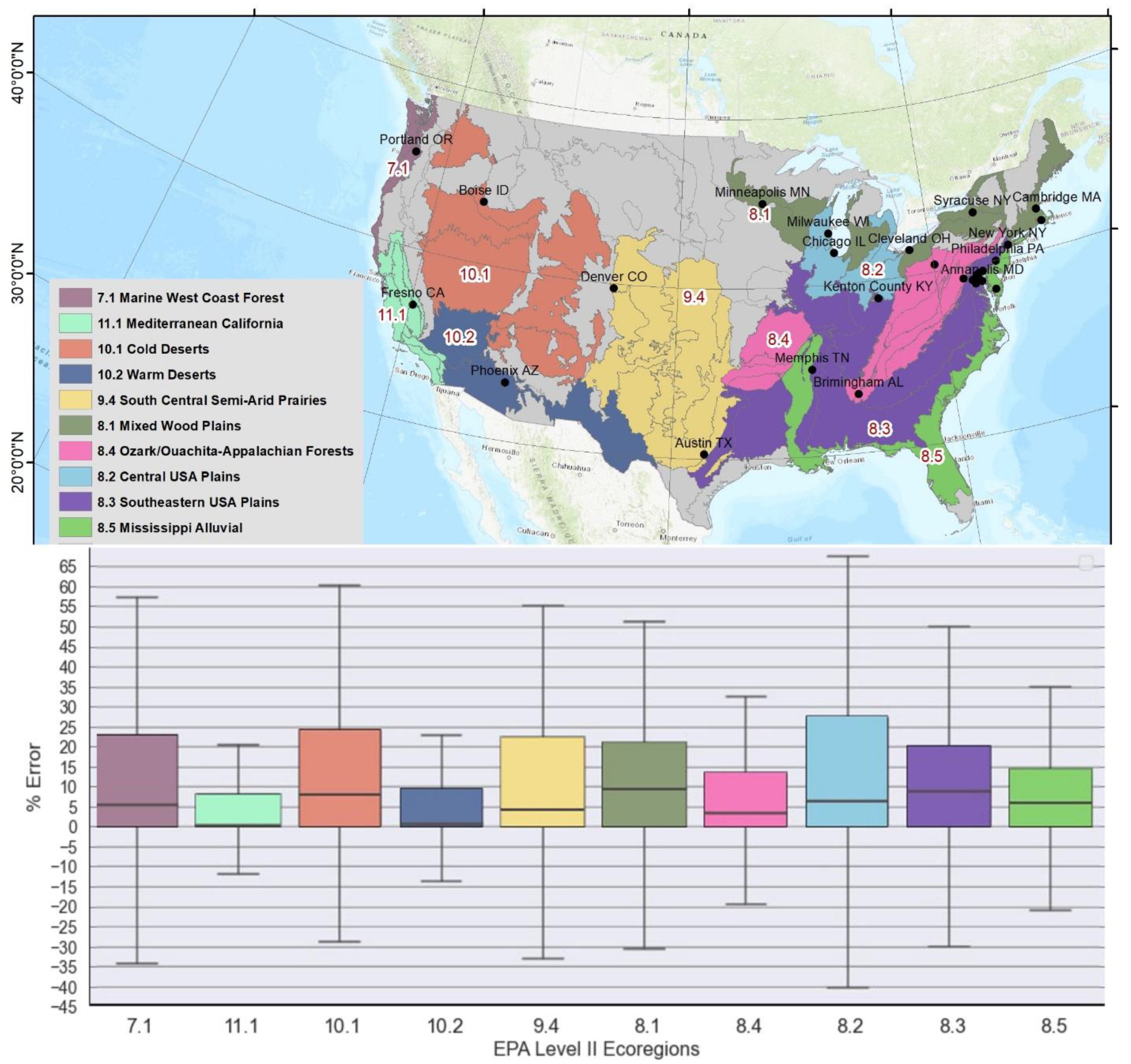
3.2. Error Distribution across Different Landscape Characteristics
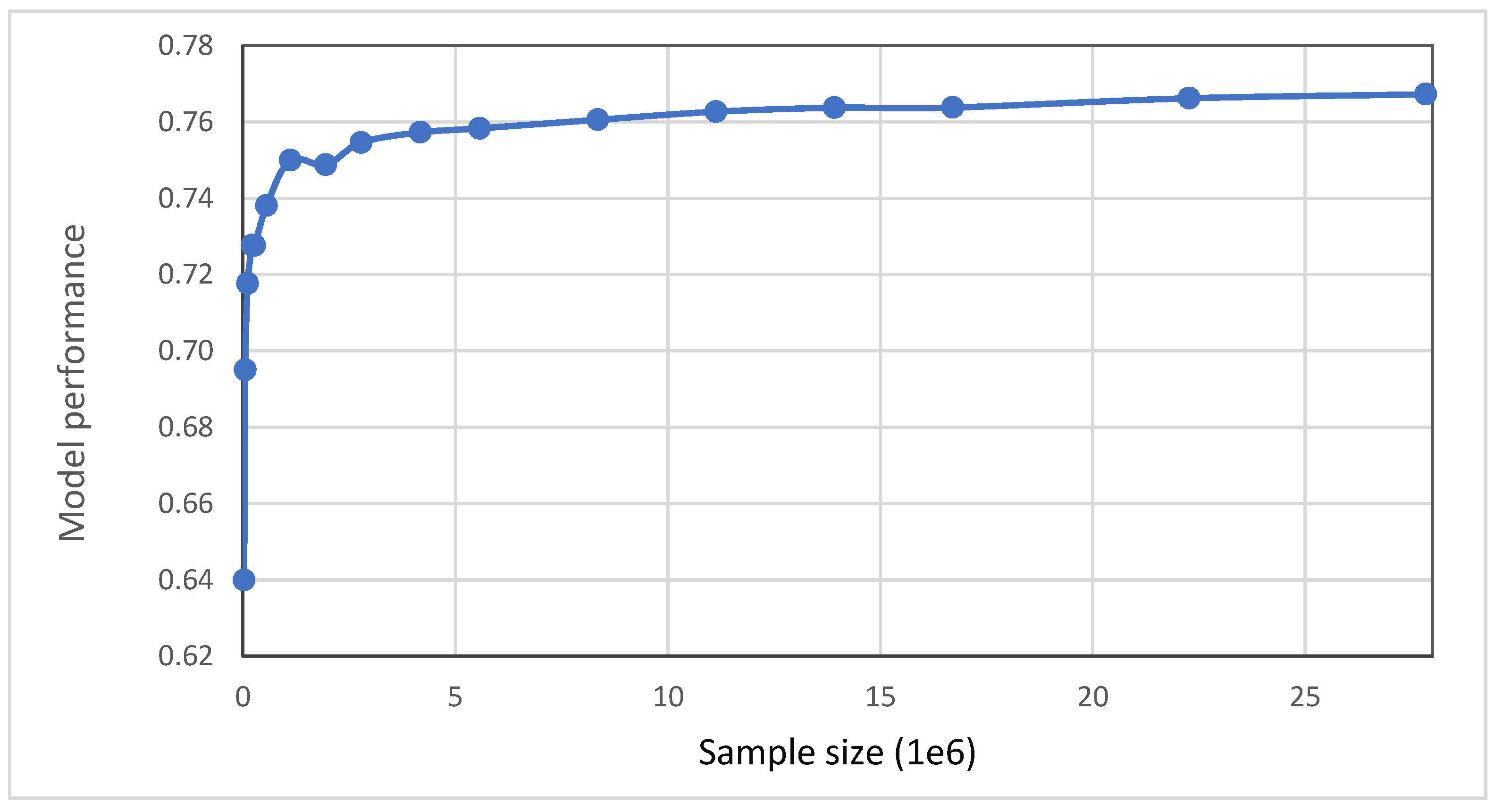
3.3. Predictive Model Performance
3.4. Validation of the Predictive Model in Denver, CO, and Seattle, WA, to Correct NLCD-TC Bias
3.5. NLCD-TC Data Correction: Effects on Ecosystem Accounting Model Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Multi-Resolution Land Characteristics (MRLC) Consortium|Multi-Resolution Land Characteristics (MRLC) Consortium. Available online: https://www.mrlc.gov/ (accessed on 15 January 2018).
- Wickham, J.D.; Stehman, S.V.; Gass, L.; Dewitz, J.; Fry, J.a.; Wade, T.G. Accuracy Assessment of NLCD 2006 Land Cover and Impervious Surface. Remote Sens. Environ. 2013, 130, 294–304. [Google Scholar] [CrossRef]
- Zhou, W.; Qian, Y.; Li, X.; Li, W.; Han, L. Relationships between Land Cover and the Surface Urban Heat Island: Seasonal Variability and Effects of Spatial and Thematic Resolution of Land Cover Data on Predicting Land Surface Temperatures. Landsc. Ecol. 2014, 29, 153–167. [Google Scholar] [CrossRef]
- Zhou, W.; Troy, A. Development of an Object-Based Framework for Classifying and Inventorying Human-Dominated Forest Ecosystems. Int. J. Remote Sens. 2009, 30, 6343–6360. [Google Scholar] [CrossRef]
- Wang, J.; Endreny, T.A.; Nowak, D.J. Mechanistic Simulation of Tree Effects in an Urban Water Balance Model 1. J. Am. Water Resour. Assoc. 2008, 44, 75–85. [Google Scholar] [CrossRef]
- Reistetter, J.A.; Russell, M. High-Resolution Land Cover Datasets, Composite Curve Numbers, and Storm Water Retention in the Tampa Bay, FL Region. Appl. Geogr. 2011, 31, 740–747. [Google Scholar] [CrossRef]
- Nowak, D.; Heisler, G.M. Air Quality Effects of Urban Trees and Parks. Natl. Recreat. Park Assoc. Res. Ser. 2010, 1–44. Available online: https://www.fs.usda.gov/treesearch/pubs/52881 (accessed on 29 November 2021).
- Kovacs, K.F.; Haight, R.G.; McCullough, D.G.; Mercader, R.J.; Siegert, N.W.; Liebhold, A.M. Cost of Potential Emerald Ash Borer Damage in U.S. Communities, 2009–2019. Ecol. Econ. 2010, 69, 569–578. [Google Scholar] [CrossRef]
- Zheng, D.; Ducey, M.J.; Heath, L.S. Assessing Net Carbon Sequestration on Urban and Community Forests of Northern New England, USA. Urban For. Urban Green. 2013, 12, 61–68. [Google Scholar] [CrossRef]
- Nowak, D.J.; Appleton, N.; Ellis, A.; Greenfield, E. Residential Building Energy Conservation and Avoided Power Plant Emissions by Urban and Community Trees in the United States. Urban For. Urban Green. 2017, 21, 158–165. [Google Scholar] [CrossRef] [Green Version]
- McRoberts, R.E.; Liknes, G.C.; Domke, G.M. Using a Remote Sensing-Based, Percent Tree Cover Map to Enhance Forest Inventory Estimation. For. Ecol. Manag. 2014, 331, 12–18. [Google Scholar] [CrossRef]
- Nowak, D.J.; Greenfield, E.J. Tree and Impervious Cover in the United States. Landsc. Urban Plan. 2012, 107, 21–30. [Google Scholar] [CrossRef] [Green Version]
- Boyd, J.W.; Bagstad, K.J.; Ingram, J.C.; Shapiro, C.D.; Adkins, J.E.; Casey, C.F.; Duke, C.S.; Glynn, P.D.; Goldman, E.; Grasso, M.; et al. The Natural Capital Accounting Opportunity: Let’s Really Do the Numbers. BioScience 2018, 68, 940–943. [Google Scholar] [CrossRef]
- Heris, M.; Bagstad, K.J.; Rhodes, C.; Troy, A.; Middel, A.; Hopkins, K.G.; Matuszak, J. Piloting Urban Ecosystem Accounting for the United States. Ecosyst. Serv. 2021, 48, 101226. [Google Scholar] [CrossRef]
- City of New York, Land Cover Raster Data (2017)–6in Resolution|NYC Open Data 2018; Accessed in May 2019. Available online: https://data.cityofnewyork.us/Environment/Land-Cover-Raster-Data-2017-6in-Resolution/he6d-2qns (accessed on 29 November 2021).
- Greenfield, E.J.; Nowak, D.J.; Walton, J.T. Assessment of 2001 NLCD Percent Tree and Impervious Cover Estimates. Photogramm. Eng. Remote Sens. 2009, 75, 1279–1286. [Google Scholar] [CrossRef]
- Nowak, D.J.; Greenfield, E.J. Evaluating The National Land Cover Database Tree Canopy and Impervious Cover Estimates Across the Conterminous United States: A Comparison with Photo-Interpreted Estimates. Environ. Manag. 2010, 46, 378–390. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sander, H.; Polasky, S.; Haight, R.G. The Value of Urban Tree Cover: A Hedonic Property Price Model in Ramsey and Dakota Counties, Minnesota, USA. Ecol. Econ. 2010, 69, 1646–1656. [Google Scholar] [CrossRef]
- Landry, S.M.; Koeser, A.K.; Northrop, R.J.; McLean, D.; Donovan, G.; Andreu, M.G.; Hilbert, D. City of Tampa Tree Canopy and Urban Forest Analysis 2016. 2018. Available online: https://waterinstitute.usf.edu/upload/documents/TampaUEA2016_FinalReport-lowres.pdf (accessed on 29 November 2021).
- Warnell, K.J.D.; Russell, M.; Rhodes, C.; Bagstad, K.J.; Olander, L.P.; Nowak, D.J.; Poudel, R.; Glynn, P.D.; Hass, J.L.; Hirabayashi, S.; et al. Testing Ecosystem Accounting in the United States: A Case Study for the Southeast. Ecosyst. Serv. 2020, 43, 101099. [Google Scholar] [CrossRef]
- Huang, C.; Yang, L.; Wylie, B.; Homer, C. A Strategy for Estimating Tree Canopy Density Using Landsat 7 ETM and High Resolution Images Over Large Areas. In Proceedings of the Third International Conference on Geospatial Information in Agriculture and Forestry, Denver, Colorado, 5–7 November 2001. [Google Scholar]
- Coulston, J.W.; Moisen, G.G.; Wilson, B.T.; Finco, M.V.; Cohen, W.B.; Brewer, C.K. Modeling Percent Tree Canopy Cover: A Pilot Study. Photogramm. Eng. Remote Sens. 2012, 78, 715–727. [Google Scholar] [CrossRef] [Green Version]
- Homer, C.; Dewitz, J.; Yang, L.; Jin, S.; Danielson, P.; Coulston, J.; Herold, N.; Wickham, J.; Megown, K. Completion of the 2011 National Land Cover Database for the Conterminous United States–Representing a Decade of Land Cover Change Information. Photogramm. Eng. 2015, 81, 345–354. [Google Scholar]
- Yang, L.; Jin, S.; Danielson, P.; Homer, C.; Gass, L.; Bender, S.M.; Case, A.; Costello, C.; Dewitz, J.; Fry, J.; et al. A New Generation of the United States National Land Cover Database: Requirements, Research Priorities, Design, and Implementation Strategies. ISPRS J. Photogramm. Remote Sens. 2018, 146, 108–123. [Google Scholar] [CrossRef]
- Homer, C.; Huang, C.; Yang, L.; Wylie, B.; Coan, M. Development of a 2001 National Land-Cover Database for the United States. Photogramm. Eng. Remote Sens. 2004, 70, 829–840. [Google Scholar] [CrossRef] [Green Version]
- U.S. EPA EnviroAtlas. Available online: https://www.epa.gov/enviroatlas (accessed on 15 February 2019).
- O’Neil-Dunne, J.P.M.; MacFaden, S.W.; Royar, A.R.; Pelletier, K.C. An Object-Based System for LiDAR Data Fusion and Feature Extraction. Geocarto Int. 2013, 28, 227–242. [Google Scholar] [CrossRef]
- US EPA Ecoregions. Available online: https://www.epa.gov/eco-research/ecoregions (accessed on 6 May 2019).
- Buyantuyev, A.; Wu, J. Urban Heat Islands and Landscape Heterogeneity: Linking Spatiotemporal Variations in Surface Temperatures to Land-Cover and Socioeconomic Patterns. Landsc. Ecol. 2010, 25, 17–33. [Google Scholar] [CrossRef]
- Rosenfeld, A.H.; Akbari, H.; Bretz, S.; Fishman, B.L.; Kurn, D.M.; Sailor, D.; Taha, H. Mitigation of Urban Heat Islands: Materials, Utility Programs, Updates. Energy Build. 1995, 22, 255–265. [Google Scholar] [CrossRef]
- U.S. Geological Survey. Landsat 8 (L8) Data Users Handbook: Version 4 2019; US Geological Survey: Sioux Falls, SD, USA, 2019.
- Microsoft. US Building Footprints; Microsoft: Redmond, WA, USA, 2018. [Google Scholar]
- Heris, M.P.; Foks, N.; Bagstad, K.J.; Troy, A. A National Dataset of Rasterized Building Footprints for the U.S; US Geological Survey: Reston, VI, USA, 2020. [CrossRef]
- Heris, M.P. Evaluating Metropolitan Spatial Development: A Method for Identifying Settlement Types and Depicting Growth Patterns. Reg. Stud. Reg. Sci. 2017, 4, 7–25. [Google Scholar] [CrossRef] [Green Version]
- Your Weather Service U.S. Climate Data (1990–2018). Available online: https://www.usclimatedata.com (accessed on 11 February 2019).
- Manson, S.; Schroeder, J.; Van Riper, D.; Ruggles, S. National Historical Geographic Information System: Version 14.0; IPUMS: Minneapolis, MN, USA, 2019. [Google Scholar] [CrossRef]
- Troy, A.R.; Grove, J.M.; O’Neil-Dunne, J.P.; Pickett, S.T.; Cadenasso, M.L. Predicting Opportunities for Greening and Patterns of Vegetation on Private Urban Lands. Environ. Manag. 2007, 40, 394–412. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- United Nations Department of Economic and Social Affairs Statistics Division. System of Environmental-Economic Accounting-Ecosystem Accounting: Final Draft; United Nations: New York, NY, USA, 2021. [Google Scholar]
- Heris, M.P. Accuracy Assessment of National Land Cover Dataset Tree Cover Code. Available online: https://github.com/mehdiheris/NLCD_Assessment (accessed on 29 November 2021).
- Wickham, J.; Stehman, S.V.; Neale, A.C.; Mehaffey, M. Accuracy Assessment of NLCD 2011 Percent Impervious Cover for Selected USA Metropolitan Areas. Int. J. Appl. Earth Obs. Geoinf. 2020, 84, 101955. [Google Scholar] [CrossRef]
- Keeler, B.L.; Hamel, P.; McPhearson, T.; Hamann, M.H.; Donahue, M.L.; Meza Prado, K.A.; Arkema, K.K.; Bratman, G.N.; Brauman, K.A.; Finlay, J.C.; et al. Social-Ecological and Technological Factors Moderate the Value of Urban Nature. Nat. Sustain. 2019, 2, 29–38. [Google Scholar] [CrossRef]
- Grafius, D.R.; Corstanje, R.; Warren, P.H.; Evans, K.L.; Hancock, S.; Harris, J.A. The Impact of Land Use/Land Cover Scale on Modelling Urban Ecosystem Services. Landsc. Ecol. 2016, 31, 1509–1522. [Google Scholar] [CrossRef] [Green Version]
- Rioux, J.-F.; Cimon-Morin, J.; Pellerin, S.; Alard, D.; Poulin, M. How Land Cover Spatial Resolution Affects Mapping of Urban Ecosystem Service Flows. Front. Environ. Sci. 2019, 7, 93. [Google Scholar] [CrossRef]
- Kerins, P.; Guzder-Williams, B.; Mackres, E.; Rashid, T.; Pietraszkiewicz, E. Mapping Urban Land Use in India and Mexico Using Remote Sensing and Machine Learning; World Resources Institute: Washington, DC, USA, 2021. [Google Scholar]
- Haberl, H.; Wiedenhofer, D.; Schug, F.; Frantz, D.; Virág, D.; Plutzar, C.; Gruhler, K.; Lederer, J.; Schiller, G.; Fishman, T.; et al. High-Resolution Maps of Material Stocks in Buildings and Infrastructures in Austria and Germany. Environ. Sci. Technol. 2021, 55, 3368–3379. [Google Scholar] [CrossRef]
- Jochem, W.C.; Tatem, A.J. Tools for Mapping Multi-Scale Settlement Patterns of Building Footprints: An Introduction to the R Package Foot. PLoS ONE 2021, 16, e0247535. [Google Scholar] [CrossRef] [PubMed]
- Microsoft Building Footprints. Available online: https://github.com/microsoft?q=building+footprints&type=&language= (accessed on 7 March 2021).
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- European Environment Agency. Copernicus Land Monitoring Service-High Resolution Layer Forest Product Specifications Document; Copernicus Team at EEA: Copenhagen, Denmark, 2017; p. 39.
- Nowak, D.J.; Greenfield, E.J. Declining Urban and Community Tree Cover in the United States. Urban For. Urban Green. 2018, 32, 32–55. [Google Scholar] [CrossRef]
- Treglia, M.L.; Acosta-Morel, M.; Crabtree, D.; Galbo, K.; Lin-Moges, T.; Van Slooten, A.; Maxwell, E.N. The State of the Urban Forest in New York City; Zenodo: New York City, NY, USA, 2021. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level II Ecoregion Code | Level II Ecoregion | City/County | Year |
|---|---|---|---|
| 7.1 | Marine West Coast Forest | ● Portland, OR | 2010 |
| 8.1 | Mixed Wood Plains | * Cambridge, MA | 2016 |
| * Cleveland, OH | 2011 | ||
| * New York, NY | 2011 | ||
| * Syracuse, NY | 2010 | ||
| 8.2 | Central USA Plains | * Chicago, IL | 2010 |
| ● Milwaukee, WI | 2010 | ||
| 8.3 | Southeastern USA Plains | * Annapolis, MD | 2007 |
| * Anne Arundel County, MD | 2007 | ||
| * Baltimore County, MD | 2007 | ||
| * Harford County, MD | 2011 | ||
| * Howard County, MD | 2007 | ||
| * Kenton County, KY | 2012 | ||
| ● Memphis, TN | 2010 | ||
| * Montgomery County, MD | 2014 | ||
| * Prince George County, MD | 2014 | ||
| * Philadelphia, PA | 2009 | ||
| * Washington, DC | 2011 | ||
| 8.4 | Ozark/Ouachita-Appalachian Forests | ● Birmingham, AL | 2011 |
| * Jefferson County, WV | 2011 | ||
| * Pittsburgh, PA | 2015 | ||
| 8.5 | Mississippi Alluvial and Southeast USA Coastal Plains | * Wicomico County, MD | 2011 |
| 9.4 | South Central Semiarid Prairies | ● Austin, TX | 2010 |
| * Denver, CO | 2014 | ||
| 10.1 | Cold Deserts | ● Boise, ID | 2010 |
| 10.2 | Warm Deserts | ● Phoenix, AZ | 2010 |
| 11.1 | Mediterranean California | ● Fresno, CA | 2010 |
| Model Parameters | Regression Results | |
|---|---|---|
| Model with NLCD-TC | Model without NLCD-TC | |
| Model performance | 0.765 | 0.681 |
| Explanatory variable importance | ||
| National Land Cover Database-Tree Canopy | 0.918 | Not included |
| NLCD land cover | 0.023 | 0.366 |
| Normalized Difference Vegetation Index | 0.014 | 0.518 |
| Average precipitation | 0.013 | 0.031 |
| Average high temperature | 0.012 | 0.037 |
| Building coverage | 0.009 | 0.010 |
| Urban density | 0.004 | 0.011 |
| Median year built | 0.003 | 0.009 |
| Surface temperature | 0.002 | 0.013 |
| Built/undeveloped | 0.002 | 0.004 |
| Metric | NLCD Tree Cover | Corrected Tree Cover |
|---|---|---|
| Mean error | 8.1% | −0.004% |
| Mean absolute error | 13.5% | 10.6% |
| Root mean squared error | 21.1 | 16.7 |
| Kolmogorov–Smirnov score | 0.25 | 0.27 |
| Ecosystem Accounting Area (EAA) | Ecosystem Service | Tree Cover Dataset (as the Input) | Ecosystem Types (Land Cover) | % of the High-Resolution Results | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Open Water | Developed-Open | Developed-Low | Developed-Medium | Developed-High | Barren | Deciduous Forest | Evergreen Forest | Mixed Forest | Scrub/Shrub | Grassland/Herbaceous | Pasture/Hay | Cultivated Crops | Woody Wetlands | Emergent Herbaceous Wetlands | Total | ||||
| Denver CO | Intercepted water (1000 m3) | Native NLCD-TC 2011 | 0 | 174 | 516 | 143 | 20 | 0 | 1 | 0 | 0 | 1 | 3 | 0 | 5 | 24 | 1 | 887 | 5% |
| Corrected NLCD-TC | 0 | 265 | 1450 | 287 | 62 | 0 | 5 | 1 | 0 | 2 | 5 | 1 | 11 | 79 | 1 | 2169 | 13% | ||
| High-Resolution Tree Cover | 32 | 3157 | 10,064 | 3172 | 432 | 2 | 7 | 4 | 1 | 4 | 37 | 3 | 37 | 222 | 5 | 17,178 | 100% | ||
| Energy Savings (mWh) | Native NLCD-TC 2011 | 0 | 6975 | 30,417 | 8983 | 1446 | 0 | 23 | 0 | 5 | 3 | 16 | 0 | 1 | 66 | 3 | 47,937 | 81% | |
| Corrected NLCD-TC | 0 | 7688 | 31,974 | 9807 | 1675 | 0 | 24 | 1 | 5 | 3 | 21 | 0 | 2 | 85 | 3 | 51,289 | 87% | ||
| High-Resolution Tree Cover | 0 | 6586 | 38,125 | 12,476 | 1881 | 0 | 14 | 0 | 2 | 4 | 6 | 0 | 3 | 41 | 2 | 59,140 | 100% | ||
| Seattle WA | Intercepted water (1000 m3) | Native NLCD-TC 2011 | 0 | 527 | 1391 | 713 | 48 | 18 | 316 | 163 | 183 | 16 | 5 | 1 | 0 | 82 | 9 | 3475 | 58% |
| Corrected NLCD-TC | 0 | 807 | 2147 | 1091 | 81 | 19 | 480 | 242 | 300 | 25 | 8 | 2 | 0 | 128 | 16 | 5354 | 89% | ||
| High-Resolution Tree Cover | 0 | 908 | 2363 | 1290 | 84 | 22 | 549 | 293 | 319 | 27 | 10 | 2 | 0 | 141 | 16 | 6035 | 100% | ||
| Energy Savings (mWh) | Native NLCD-TC 2011 | 0 | 19,082 | 12,767 | 883 | 17 | 231 | 513 | 254 | 49 | 0 | 0 | 0 | 55 | 6 | 572 | 34,428 | 67% | |
| Corrected NLCD-TC | 0 | 20,696 | 16,427 | 1136 | 22 | 289 | 590 | 308 | 58 | 0 | 0 | 0 | 69 | 9 | 675 | 40,280 | 78% | ||
| High-Resolution Tree Cover | 0 | 22,189 | 25,083 | 1504 | 406 | 210 | 577 | 354 | 71 | 0 | 0 | 0 | 100 | 11 | 838 | 51,345 | 100% | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pourpeikari Heris, M.; Bagstad, K.J.; Troy, A.R.; O’Neil-Dunne, J.P.M. Assessing the Accuracy and Potential for Improvement of the National Land Cover Database’s Tree Canopy Cover Dataset in Urban Areas of the Conterminous United States. Remote Sens. 2022, 14, 1219. https://doi.org/10.3390/rs14051219
Pourpeikari Heris M, Bagstad KJ, Troy AR, O’Neil-Dunne JPM. Assessing the Accuracy and Potential for Improvement of the National Land Cover Database’s Tree Canopy Cover Dataset in Urban Areas of the Conterminous United States. Remote Sensing. 2022; 14(5):1219. https://doi.org/10.3390/rs14051219
Chicago/Turabian StylePourpeikari Heris, Mehdi, Kenneth J. Bagstad, Austin R. Troy, and Jarlath P. M. O’Neil-Dunne. 2022. "Assessing the Accuracy and Potential for Improvement of the National Land Cover Database’s Tree Canopy Cover Dataset in Urban Areas of the Conterminous United States" Remote Sensing 14, no. 5: 1219. https://doi.org/10.3390/rs14051219
APA StylePourpeikari Heris, M., Bagstad, K. J., Troy, A. R., & O’Neil-Dunne, J. P. M. (2022). Assessing the Accuracy and Potential for Improvement of the National Land Cover Database’s Tree Canopy Cover Dataset in Urban Areas of the Conterminous United States. Remote Sensing, 14(5), 1219. https://doi.org/10.3390/rs14051219