
Robust Object Categorization and Scene Classification over Remote Sensing Images via Features Fusion and Fully Convolutional Network

 , , ,
, , ,
Abstract
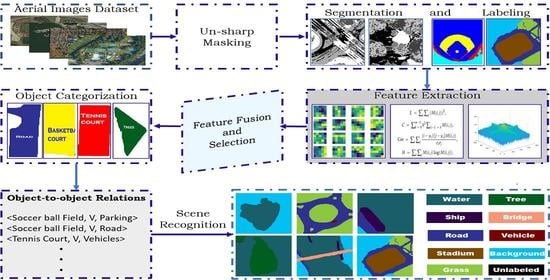
:
1. Introduction
- We employed MRF as a postprocessing and labeling technique after segmentation to avoid the challenges encountered during segmentation while using other segmentation techniques, i.e., accurate scene classification.
- CNN and classical features including Haralick features, spectral-spatial features, and super-pixel patterns are fused to improve the classification accuracy.
- MKL-based categorization significantly enhances the performance of object categorization.
- Probability-based OOR relations are introduced to contextually analyze the relationship between the objects present in the remote sensing scenes.
- After object categorization and OOR exploration, FCN is applied for the remote scene classification.
2. Related Work
2.1. Object Categorization
2.2. Scene Classification
3. Proposed System Methodology
3.1. Preprocessing Stage
3.2. Object Segmentation via Fuzzy C-Means
3.3. Labeling via Markov Random Field
3.4. Feature Extraction
3.4.1. CNN Features
3.4.2. Haralick Features
3.4.3. Spectral–Spatial Features (SSFs)
3.4.4. Super-Pixel Pattern
3.5. Feature Fusion
3.6. Object Categorization: Multiple Kernel Learning
3.7. Probability-Based Object-to-Object Relations (OORs)
3.8. Scene Recognition: Fully Convolutional Network
4. Experimental Results
4.1. Datasets Description
4.1.1. Aerial Images Dataset
4.1.2. RESISC45 Dataset
4.1.3. UCM Dataset
4.2. Experimental Evaluation
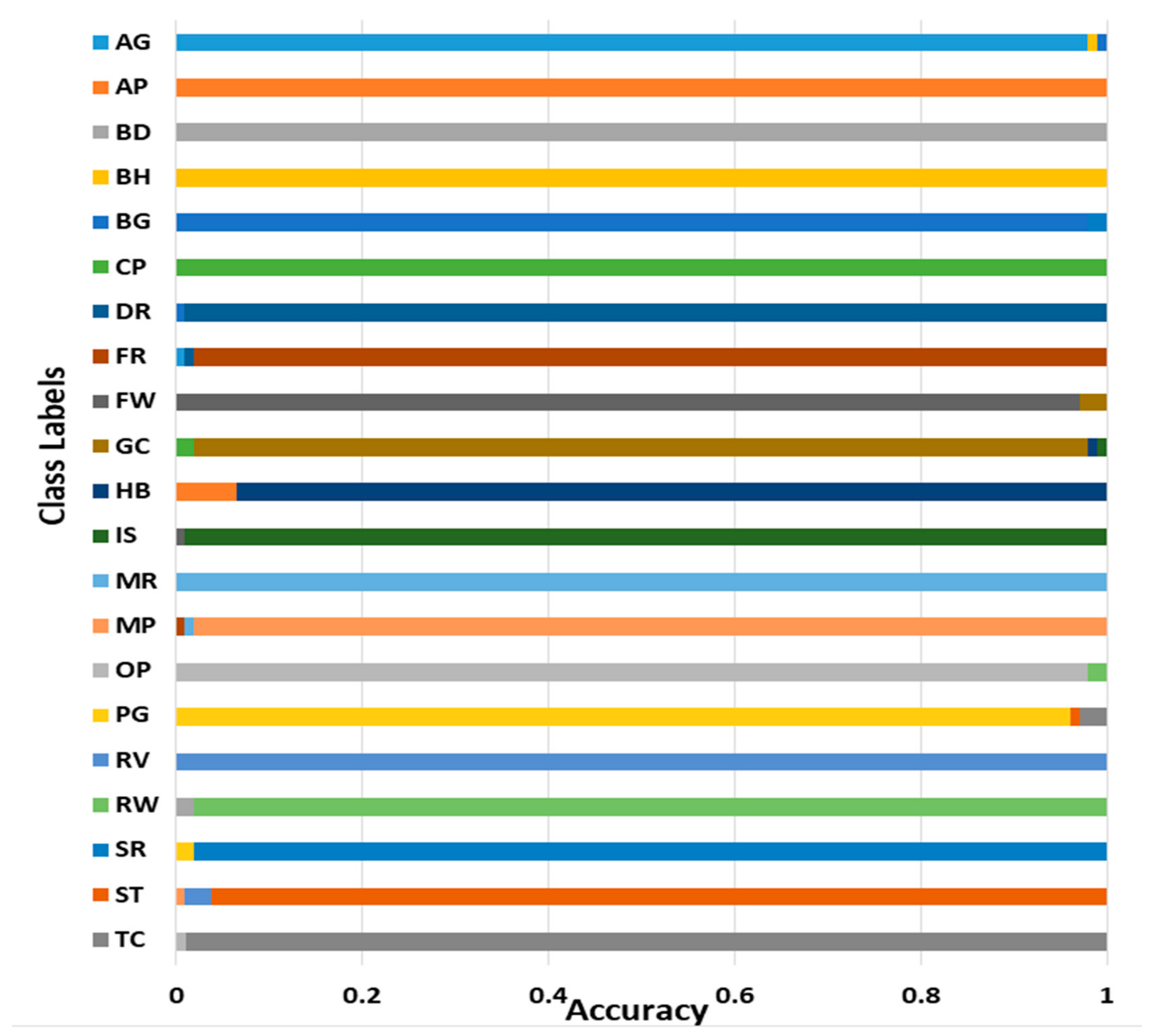
4.3. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Galleguillos, C.; Belongie, S. Context-based object categorization: A critical survey. Comput. Vis. Image Underst. 2010, 114, 712–722. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Ye, J.C.; Mueller, K.; Fessler, J.A. Image reconstruction is a new frontier of machine learning. IEEE T-MI 2018, 37, 1289–1296. [Google Scholar] [CrossRef] [PubMed]
- Saha, S.; Bovolo, F.; Bruzzone, L. Unsupervised deep change vector analysis for multiple-change detection in VHR images. IEEE TGRS 2019, 57, 3677–3693. [Google Scholar] [CrossRef]
- Srivastava, P.K.; Han, D.; Rico-Ramirez, M.A.; Bray, M.; Islam, T. Selection of classification techniques for land use/land cover change investigation. ASR 2012, 50, 1250–1265. [Google Scholar] [CrossRef]
- Jalal, A.; Ahmed, A.; Rafique, A.A.; Kim, K. Scene Semantic Recognition Based on Modified Fuzzy C-Mean and Maximum Entropy Using Object-to-Object Relations. IEEE Access 2021, 9, 27758–27772. [Google Scholar] [CrossRef]
- Manfreda, S.; McCabe, M.F.; Miller, P.E.; Lucas, R.; Pajuelo Madrigal, V.; Mallinis, G.; Dor, E.B.; Helman, D.; Estes, L.; Ciraolo, G.; et al. On the use of unmanned aerial systems for environmental monitoring. Remote Sens. 2018, 10, 641. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.A.; Sharif, M.; Akram, T.; Raza, M.; Saba, T.; Rehman, A. Hand-crafted and deep convolutional neural network features fusion and selection strategy: An application to intelligent human action recognition. Appl. Soft Comput. 2020, 87, 105986. [Google Scholar] [CrossRef]
- Guo, H.; Liu, J.; Xiao, Z.; Xiao, L. Deep CNN-based hyperspectral image classification using discriminative multiple spatial-spectral feature fusion. Remote. Sens. Lett. 2020, 11, 827–836. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Ding, L. Scene classification based on two-stage deep feature fusion. IEEE Geosci. Remote Sens. Lett. 2017, 15, 183–186. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Cao, L.; Zhang, L. Pre-trained alexnet architecture with pyramid pooling and supervision for high spatial resolution remote sensing image scene classification. Remote Sens. 2017, 9, 848. [Google Scholar] [CrossRef] [Green Version]
- Muhammad, U.; Wang, W.; Chattha, S.P.; Ali, S. Pre-trained VGGNet architecture for remote-sensing image scene classification. In Proceedings of the 2018 24th International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 1622–1627. [Google Scholar]
- Tang, P.; Wang, H.; Kwong, S. G-MS2F: GoogLeNet based multi-stage feature fusion of deep CNN for scene recognition. Neurocomputing 2017, 225, 188–197. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, X.; Niu, X.; Wang, F.; Zhang, X. Scene classification of high-resolution remotely sensed image based on ResNet. J. Geovisualization Spat. Anal. 2019, 3, 1–9. [Google Scholar] [CrossRef]
- Grzeszick, R.; Plinge, A.; Fink, G.A. Bag-of-features methods for acoustic event detection and classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1242–1252. [Google Scholar] [CrossRef]
- Martin, S. Sequential bayesian inference models for multiple object classification. In Proceedings of the 14th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; pp. 1–6. [Google Scholar]
- Bo, L.; Sminchisescu, C. Efficient match kernel between sets of features for visual recognition. Adv. Neural Inf. Process. Syst. 2009, 22, 135–143. [Google Scholar]
- Ahmed, A.; Jalal, A.; Kim, K. A novel statistical method for scene classification based on multi-object categorization and logistic regression. Sensors 2020, 20, 3871. [Google Scholar] [CrossRef]
- Wong, S.C.; Stamatescu, V.; Gatt, A.; Kearney, D.; Lee, I.; McDonnell, M.D. Track everything: Limiting prior knowledge in online multi-object recognition. IEEE Trans. Image Process. 2017, 26, 4669–4683. [Google Scholar] [CrossRef] [Green Version]
- Sumbul, G.; Cinbis, R.G.; Aksoy, S. Multisource region attention network for fine-grained object recognition in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4929–4937. [Google Scholar] [CrossRef]
- Mizuno, K.; Terachi, Y.; Takagi, K.; Izumi, S.; Kawaguchi, H.; Yoshimoto, M. Architectural study of HOG feature extraction processor for real-time object detection. In Proceedings of the 2012 IEEE Workshop on Signal Processing Systems, Ann Arbor, MI, USA, 5–8 August 2012; pp. 197–202. [Google Scholar]
- Penatti, O.A.; Valle, E.; Torres, R.D.S. Comparative study of global color and texture descriptors for web image retrieval. J. Vis. Commun. Image Represent. 2012, 23, 359–380. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Building the gist of a scene: The role of global image features in recognition. Prog. Brain Res. 2006, 155, 23–36. [Google Scholar]
- Rashid, M.; Khan, M.A.; Sharif, M.; Raza, M.; Sarfraz, M.M.; Afza, F. Object detection and classification: A joint selection and fusion strategy of deep convolutional neural network and SIFT point features. Multimed. Tools Appl. 2021, 2019, 15751–15777. [Google Scholar] [CrossRef]
- Jalal, A.; Nadeem, A.; Bobasu, S. Human Body Parts Estimation and Detection for Physical Sports Movements. In Proceedings of the 2019 2nd International Conference on Communication, Computing and Digital systems (C-CODE), Islamabad, Pakistan, 6–7 March 2019; pp. 104–109. [Google Scholar]
- Liu, B.D.; Meng, J.; Xie, W.Y.; Shao, S.; Li, Y.; Wang, Y. Weighted spatial pyramid matching collaborative representation for remote-sensing-image scene classification. Remote Sens. 2019, 11, 518. [Google Scholar] [CrossRef] [Green Version]
- Perronnin, F.; Sánchez, J.; Mensink, T. Improving the fisher kernel for large-scale image classification. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 143–156. [Google Scholar]
- Yu, J.; Zhu, C.; Zhang, J.; Huang, Q.; Tao, D. Spatial pyramid-enhanced NetVLAD with weighted triplet loss for place recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 661–674. [Google Scholar] [CrossRef] [PubMed]
- Mandal, M.; Vipparthi, S.K. Scene independency matters: An empirical study of scene dependent and scene independent evaluation for CNN-based change detection. IEEE Trans. Intell. Transp. Syst. 2020, 23, 2031–2044. [Google Scholar] [CrossRef]
- Studer, L.; Alberti, M.; Pondenkandath, V.; Goktepe, P.; Kolonko, T.; Fischer, A.; Liwicki, M.; Ingold, R. A comprehensive study of imagenet pre-training for historical document image analysis. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 720–725. [Google Scholar]
- Leksut, J.T.; Zhao, J.; Itti, L. Learning visual variation for object recognition. Image Vis. Comput. 2020, 98, 103912. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Feng, R.; Han, W.; Wang, L. High-resolution remote sensing image scene classification via key filter bank based on convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8077–8092. [Google Scholar] [CrossRef]
- Deng, G. A generalized unsharp masking algorithm. IEEE Trans. Image Process. 2010, 20, 1249–1261. [Google Scholar] [CrossRef]
- Kalist, V.; Ganesan, P.; Sathish, B.S.; Jenitha, J.M.M. Possiblistic-fuzzy C-means clustering approach for the segmentation of satellite images in HSL color space. Procedia Comput. Sci. 2015, 57, 49–56. [Google Scholar] [CrossRef] [Green Version]
- Thitimajshima, P. A new modified fuzzy c-means algorithm for multispectral satellite images segmentation. In Proceedings of the IGARSS 2000 IEEE 2000 International Geoscience and Remote Sensing Symposium. Taking the Pulse of the Planet: The Role of Remote Sensing in Managing the Environment, Honolulu, HI, USA, 24–28 July 2000; pp. 1684–1686. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. Detection-based object labeling in 3d scenes. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St. Paul, MN, USA, 14–19 May 2012; pp. 1330–1337. [Google Scholar]
- Zheng, C.; Zhang, Y.; Wang, L. Semantic segmentation of remote sensing imagery using an object-based Markov random field model with auxiliary label fields. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3015–3028. [Google Scholar] [CrossRef]
- Zhang, M.; Li, W.; Du, Q.; Gao, L.; Zhang, B. Feature extraction for classification of hyperspectral and LiDAR data using patch-to-patch CNN. IEEE Trans. Cybern. 2018, 50, 100–111. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Patil, N.K.; Malemath, V.S.; Yadahalli, R.M. Color and texture based identification and classification of food grains using different color models and Haralick features. Int. J. Comput. Sci. Eng. 2011, 3, 3669. [Google Scholar]
- Aptoula, E.; Lefèvre, S. A comparative study on multivariate mathematical morphology. Pattern Recognit. 2007, 40, 2914–2929. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, Q.; Du, B.; Huang, X.; Tang, Y.Y.; Tao, D. Simultaneous spectral-spatial feature selection and extraction for hyperspectral images. IEEE Trans. Cybern. 2016, 48, 16–28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ghamisi, P.; Benediktsson, J.A.; Cavallaro, G.; Plaza, A. Automatic framework for spectral-spatial classification based on supervised feature extraction and morphological attribute profiles. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2147–2160. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral image classification with deep feature fusion network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Yang, R.; Wang, Y.; Xu, Y.; Qiu, L.; Li, Q. Pedestrian Detection under Parallel Feature Fusion Based on Choquet Integral. Symmetry 2021, 13, 250. [Google Scholar] [CrossRef]
- Song, X.; Jiang, S.; Wang, B.; Chen, C.; Chen, G. Image representations with spatial object-to-object relations for RGB-D scene recognition. IEEE Trans. Image Process. 2019, 29, 525–537. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Kim, J.; Chi, M. SAFFNet: Self-Attention-Based Feature Fusion Network for Remote Sensing Few-Shot Scene Classification. Remote Sens. 2021, 13, 2532. [Google Scholar] [CrossRef]
- Xie, H.; Chen, Y.; Ghamisi, P. Remote sensing image scene classification via label augmentation and intra-class constraint. Remote Sens. 2021, 13, 2566. [Google Scholar] [CrossRef]
- Tang, X.; Ma, Q.; Zhang, X.; Liu, F.; Ma, J.; Jiao, L. Attention consistent network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2030–2045. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. A two-stream deep fusion framework for high-resolution aerial scene classification. Comput. Intell. Neurosci. 2018, 2018, 8639367. [Google Scholar] [CrossRef] [Green Version]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep feature fusion for VHR remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, Y.; Zhao, J.; Yao, R.; Liu, B.; Zheng, Y. Siamese convolutional neural networks for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1200–1204. [Google Scholar] [CrossRef]
- He, C.; Zhang, Q.; Qu, T.; Wang, D.; Liao, M. Remote sensing and texture image classification network based on deep learning integrated with binary coding and Sinkhorn distance. Remote Sens. 2019, 11, 2870. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Objects | Evaluation | Features | |||
|---|---|---|---|---|---|
| Contrast | Energy | Entropy | Correlation | ||
| Tennis Court | GT | 121,334 | 0.2151 | 0.2053 | 0.8905 |
| SG | 130,774 | 0.2108 | 0.2175 | 0.8917 | |
| ER | ±9440 | ±0.0043 | ±0.0122 | ±0.0012 | |
| Ship | GT | 191,428 | 0.1919 | 0.4401 | 0.7926 |
| SG | 191,854 | 0.1961 | 0.4458 | 0.7811 | |
| ER | ±426 | ±0.0042 | ±0.0057 | ±0.0115 | |
| Soccer Field | GT | 169,883 | 0.7205 | 0.3933 | 0.4577 |
| SG | 160,125 | 0.7163 | 0.3875 | 0.4612 | |
| ER | ±9758 | ±0.0042 | ±0.0058 | ±0.0035 | |
| Vehicles | GT | 102,657 | 0.4229 | 0.3166 | 0.5926 |
| SG | 108,941 | 0.4195 | 0.3192 | 0.5933 | |
| ER | ±6284 | ±0.0034 | ±0.0026 | ±0.0007 | |
| Classes | ANN | DBN | FCN (Ours) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | Precision | Recall | F1 Score | |
| AP | 0.768 | 0.732 | 0.75 | 0.811 | 0.855 | 0.832 | 0.901 | 0.977 | 0.937 |
| BL | 0.883 | 0.765 | 0.82 | 0.754 | 0.815 | 0.783 | 0.965 | 0.965 | 0.965 |
| BB | 0.691 | 0.813 | 0.747 | 0.688 | 0.755 | 0.72 | 0.824 | 0.972 | 0.892 |
| BH | 0.724 | 0.798 | 0.759 | 0.617 | 0.845 | 0.713 | 0.977 | 0.911 | 0.943 |
| BR | 0.817 | 0.841 | 0.829 | 0.754 | 0.933 | 0.834 | 0.899 | 0.931 | 0.917 |
| CC | 0.677 | 0.875 | 0.763 | 0.725 | 0.841 | 0.779 | 0.891 | 0.889 | 0.89 |
| CM | 0.755 | 0.839 | 0.795 | 0.697 | 0.798 | 0.744 | 0.915 | 0.787 | 0.846 |
| DR | 0.695 | 0.759 | 0.726 | 0.711 | 0.899 | 0.794 | 0.872 | 0.854 | 0.911 |
| DT | 0.786 | 0.698 | 0.739 | 0.695 | 0.884 | 0.778 | 0.928 | 0.971 | 0.949 |
| FL | 0.695 | 0.764 | 0.728 | 0.654 | 0.815 | 0.726 | 0.971 | 0.892 | 0.93 |
| FR | 0.754 | 0.856 | 0.802 | 0.632 | 0.856 | 0.727 | 0.915 | 0.977 | 0.945 |
| IN | 0.655 | 0.813 | 0.725 | 0.719 | 0.796 | 0.756 | 0.811 | 0.892 | 0.85 |
| MW | 0.771 | 0.792 | 0.781 | 0.705 | 0.862 | 0.776 | 0.913 | 0.928 | 0.92 |
| MR | 0.798 | 0.733 | 0.764 | 0.733 | 0.784 | 0.758 | 0.986 | 0.966 | 0.976 |
| MN | 0.699 | 0.795 | 0.744 | 0.826 | 0.698 | 0.757 | 0.897 | 0.937 | 0.917 |
| PK | 0.784 | 0.875 | 0.827 | 0.798 | 0.814 | 0.806 | 0.912 | 0.901 | 0.906 |
| PG | 0.789 | 0.839 | 0.813 | 0.771 | 0.761 | 0.766 | 0.977 | 0.887 | 0.93 |
| PD | 0.681 | 0.821 | 0.744 | 0.811 | 0.886 | 0.847 | 0.799 | 0.916 | 0.854 |
| PN | 0.719 | 0.788 | 0.752 | 0.631 | 0.818 | 0.712 | 0.855 | 0.891 | 0.873 |
| RS | 0.725 | 0.811 | 0.766 | 0.801 | 0.875 | 0.836 | 0.925 | 0.917 | 0.921 |
| RT | 0.774 | 0.859 | 0.814 | 0.783 | 0.836 | 0.809 | 0.936 | 0.977 | 0.956 |
| RV | 0.615 | 0.694 | 0.652 | 0.697 | 0.825 | 0.756 | 0.871 | 0.871 | 0.871 |
| SL | 0.664 | 0.851 | 0.746 | 0.665 | 0.851 | 0.747 | 0.995 | 0.951 | 0.973 |
| SR | 0.776 | 0.785 | 0.78 | 0.709 | 0.898 | 0.792 | 0.956 | 0.879 | 0.916 |
| SQ | 0.764 | 0.809 | 0.786 | 0.722 | 0.835 | 0.774 | 0.891 | 0.903 | 0.897 |
| SM | 0.687 | 0.717 | 0.702 | 0.715 | 0.746 | 0.73 | 0.819 | 0.916 | 0.865 |
| ST | 0.694 | 0.839 | 0.76 | 0.812 | 0.816 | 0.814 | 0.977 | 0.921 | 0.948 |
| VT | 0.639 | 0.775 | 0.7 | 0.789 | 0.857 | 0.822 | 0.887 | 0.911 | 0.899 |
| AP | 0.715 | 0.795 | 0.753 | 0.745 | 0.877 | 0.806 | 0.973 | 0.935 | 0.954 |
| BL | 0.636 | 0.699 | 0.666 | 0.781 | 0.798 | 0.789 | 0.985 | 0.905 | 0.943 |
| Mean | 0.728 | 0.794 | 0.758 | 0.732 | 0.831 | 0.776 | 0.914 | 0.921 | 0.916 |
| Classes | ANN | DBN | FCN (Ours) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | Precision | Recall | F1 Score | |
| AP | 0.611 | 0.874 | 0.719 | 0.622 | 0.717 | 0.666 | 0.901 | 0.977 | 0.937 |
| AT | 0.637 | 0.769 | 0.697 | 0.783 | 0.865 | 0.822 | 0.899 | 0.845 | 0.871 |
| BD | 0.712 | 0.825 | 0.764 | 0.759 | 0.786 | 0.772 | 0.995 | 0.951 | 0.973 |
| BC | 0.698 | 0.813 | 0.751 | 0.768 | 0.937 | 0.844 | 0.986 | 0.915 | 0.949 |
| BG | 0.672 | 0.749 | 0.708 | 0.651 | 0.831 | 0.757 | 0.967 | 0.903 | 0.934 |
| BH | 0.655 | 0.875 | 0.749 | 0.748 | 0.875 | 0.807 | 0.844 | 0.869 | 0.859 |
| BR | 0.751 | 0.839 | 0.793 | 0.879 | 0.831 | 0.854 | 0.871 | 0.839 | 0.855 |
| CL | 0.697 | 0.781 | 0.737 | 0.728 | 0.729 | 0.728 | 0.872 | 0.921 | 0.896 |
| CH | 0.743 | 0.829 | 0.784 | 0.688 | 0.866 | 0.767 | 0.886 | 0.938 | 0.911 |
| CF | 0.779 | 0.787 | 0.783 | 0.825 | 0.781 | 0.802 | 0.985 | 0.954 | 0.969 |
| CD | 0.702 | 0.854 | 0.771 | 0.716 | 0.698 | 0.707 | 0.901 | 0.977 | 0.937 |
| CA | 0.699 | 0.772 | 0.734 | 0.803 | 0.865 | 0.833 | 0.883 | 0.965 | 0.922 |
| DR | 0.785 | 0.801 | 0.793 | 0.776 | 0.758 | 0.767 | 0.995 | 0.951 | 0.973 |
| DT | 0.734 | 0.791 | 0.761 | 0.868 | 0.801 | 0.833 | 0.986 | 0.937 | 0.961 |
| FT | 0.709 | 0.767 | 0.737 | 0.689 | 0.774 | 0.729 | 0.967 | 0.903 | 0.934 |
| FW | 0.664 | 0.775 | 0.715 | 0.791 | 0.875 | 0.831 | 0.844 | 0.861 | 0.852 |
| GC | 0.637 | 0.739 | 0.684 | 0.711 | 0.839 | 0.770 | 0.977 | 0.839 | 0.903 |
| GT | 0.649 | 0.812 | 0.721 | 0.782 | 0.881 | 0.829 | 0.872 | 0.921 | 0.896 |
| HR | 0.711 | 0.738 | 0.724 | 0.686 | 0.787 | 0.733 | 0.886 | 0.938 | 0.911 |
| IA | 0.753 | 0.813 | 0.782 | 0.658 | 0.824 | 0.732 | 0.985 | 0.954 | 0.969 |
| IN | 0.668 | 0.745 | 0.704 | 0.854 | 0.761 | 0.805 | 0.901 | 0.977 | 0.937 |
| ID | 0.622 | 0.851 | 0.719 | 0.783 | 0.824 | 0.803 | 0.883 | 0.965 | 0.922 |
| LK | 0.677 | 0.751 | 0.712 | 0.852 | 0.699 | 0.768 | 0.995 | 0.951 | 0.973 |
| MD | 0.711 | 0.825 | 0.764 | 0.755 | 0.785 | 0.770 | 0.986 | 0.937 | 0.961 |
| MR | 0.787 | 0.694 | 0.738 | 0.677 | 0.823 | 0.743 | 0.967 | 0.903 | 0.934 |
| MH | 0.689 | 0.785 | 0.734 | 0.711 | 0.785 | 0.746 | 0.844 | 0.875 | 0.859 |
| MN | 0.791 | 0.839 | 0.814 | 0.816 | 0.819 | 0.817 | 0.977 | 0.839 | 0.903 |
| OP | 0.698 | 0.789 | 0.741 | 0.794 | 0.895 | 0.841 | 0.872 | 0.851 | 0.861 |
| PC | 0.655 | 0.818 | 0.727 | 0.729 | 0.852 | 0.786 | 0.886 | 0.938 | 0.911 |
| Pk | 0.785 | 0.755 | 0.770 | 0.688 | 0.815 | 0.746 | 0.985 | 0.954 | 0.969 |
| RL | 0.709 | 0.745 | 0.727 | 0.645 | 0.758 | 0.697 | 0.967 | 0.903 | 0.934 |
| RS | 0.615 | 0.698 | 0.654 | 0.731 | 0.775 | 0.752 | 0.844 | 0.875 | 0.859 |
| RF | 0.822 | 0.739 | 0.778 | 0.779 | 0.881 | 0.827 | 0.977 | 0.839 | 0.903 |
| RV | 0.746 | 0.699 | 0.722 | 0.745 | 0.721 | 0.733 | 0.872 | 0.921 | 0.896 |
| RT | 0.699 | 0.811 | 0.751 | 0.654 | 0.819 | 0.727 | 0.886 | 0.938 | 0.911 |
| RN | 0.775 | 0.782 | 0.778 | 0.697 | 0.754 | 0.724 | 0.985 | 0.954 | 0.969 |
| SI | 0.716 | 0.757 | 0.736 | 0.725 | 0.688 | 0.706 | 0.901 | 0.977 | 0.937 |
| SH | 0.883 | 0.765 | 0.82 | 0.811 | 0.669 | 0.733 | 0.883 | 0.965 | 0.922 |
| SB | 0.788 | 0.801 | 0.794 | 0.735 | 0.715 | 0.725 | 0.995 | 0.951 | 0.973 |
| SR | 0.811 | 0.735 | 0.771 | 0.824 | 0.689 | 0.750 | 0.986 | 0.937 | 0.961 |
| SD | 0.699 | 0.619 | 0.657 | 0.755 | 0.745 | 0.751 | 0.967 | 0.903 | 0.934 |
| ST | 0.754 | 0.785 | 0.769 | 0.846 | 0.778 | 0.811 | 0.844 | 0.875 | 0.859 |
| TC | 0.768 | 0.838 | 0.801 | 0.661 | 0.829 | 0.736 | 0.977 | 0.839 | 0.903 |
| TR | 0.872 | 0.721 | 0.789 | 0.693 | 0.818 | 0.75 | 0.872 | 0.921 | 0.896 |
| TP | 0.689 | 0.738 | 0.713 | 0.778 | 0.736 | 0.756 | 0.886 | 0.938 | 0.911 |
| WD | 0.661 | 0.654 | 0.657 | 0.688 | 0.744 | 0.715 | 0.985 | 0.954 | 0.969 |
| Mean | 0.735 | 0.794 | 0.761 | 0.763 | 0.813 | 0.784 | 0.947 | 0.939 | 0.942 |
| Classes | ANN | DBN | FCN (Ours) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | Precision | Recall | F1 Score | |
| AG | 0.837 | 0.658 | 0.737 | 0.699 | 0.899 | 0.787 | 0.967 | 0.903 | 0.934 |
| AP | 0.755 | 0.788 | 0.811 | 0.815 | 0.875 | 0.844 | 0.844 | 0.875 | 0.860 |
| BD | 0.792 | 0.753 | 0.815 | 0.741 | 0.819 | 0.787 | 0.977 | 0.839 | 0.903 |
| BH | 0.873 | 0.707 | 0.781 | 0.784 | 0.944 | 0.857 | 0.872 | 0.921 | 0.896 |
| BG | 0.799 | 0.791 | 0.795 | 0.785 | 0.859 | 0.821 | 0.886 | 0.938 | 0.912 |
| CP | 0.701 | 0.825 | 0.758 | 0.667 | 0.769 | 0.715 | 0.985 | 0.954 | 0.970 |
| DR | 0.766 | 0.811 | 0.788 | 0.719 | 0.688 | 0.704 | 0.901 | 0.977 | 0.938 |
| FR | 0.783 | 0.711 | 0.746 | 0.883 | 0.965 | 0.923 | 0.809 | 0.951 | 0.881 |
| FW | 0.699 | 0.764 | 0.731 | 0.792 | 0.881 | 0.835 | 0.995 | 0.951 | 0.973 |
| GC | 0.715 | 0.795 | 0.753 | 0.763 | 0.896 | 0.825 | 0.986 | 0.937 | 0.961 |
| HB | 0.855 | 0.801 | 0.828 | 0.648 | 0.821 | 0.725 | 0.967 | 0.903 | 0.934 |
| IS | 0.785 | 0.815 | 0.828 | 0.791 | 0.798 | 0.795 | 0.844 | 0.875 | 0.860 |
| MR | 0.821 | 0.802 | 0.83 | 0.737 | 0.809 | 0.772 | 0.977 | 0.839 | 0.903 |
| MP | 0.787 | 0.655 | 0.715 | 0.783 | 0.898 | 0.837 | 0.872 | 0.921 | 0.896 |
| OP | 0.845 | 0.669 | 0.747 | 0.897 | 0.762 | 0.825 | 0.886 | 0.938 | 0.912 |
| PG | 0.769 | 0.759 | 0.764 | 0.799 | 0.711 | 0.753 | 0.985 | 0.954 | 0.970 |
| RV | 0.811 | 0.661 | 0.729 | 0.675 | 0.855 | 0.755 | 0.967 | 0.903 | 0.934 |
| RW | 0.845 | 0.716 | 0.776 | 0.795 | 0.789 | 0.79 | 0.844 | 0.875 | 0.860 |
| SR | 0.775 | 0.797 | 0.806 | 0.819 | 0.773 | 0.796 | 0.977 | 0.839 | 0.903 |
| ST | 0.771 | 0.824 | 0.797 | 0.719 | 0.898 | 0.799 | 0.872 | 0.921 | 0.896 |
| TC | 0.786 | 0.891 | 0.836 | 0.801 | 0.795 | 0.798 | 0.886 | 0.938 | 0.912 |
| Mean | 0.789 | 0.777 | 0.783 | 0.768 | 0.835 | 0.801 | 0.919 | 0.913 | 0.916 |
| Author/Method | Mean Accuracy % | ||
|---|---|---|---|
| AID Dataset | UCM Dataset | RESIEC Dataset | |
| SAFENet [52] | 86.91 + 0.44 | 86.79 + 0.33 | 81.32 + 0.62 |
| ResNet18 + LA + KL [53] | 96.52 | 99.21 | 95.26 |
| DBSNet [59] | 92.93 | 97.90 | -- |
| CaffeNet [49] | 89.53 ± 0.31 | 95.02 ± 0.81 | -- |
| GoogLeNet [49] | 86.39 ± 0.55 | 94.31 ± 0.89 | -- |
| VGG-VD1-16 [49] | 89.64 ± 0.36 | 95.21 ± 1.20 | -- |
| Deep Fusion [56] | 94.58 | 98.02 | -- |
| Fusion by Addition [57] | 91.87 | 97.42 | -- |
| Siamse ResNet50 [58] | -- | 94.29 | 95.95 |
| Proposed | 97.73 | 98.75 | 96.57 |
| Algorithm/Method | Dataset | FCM | FCM + MRF | CNN |
|---|---|---|---|---|
| Average computation time (s) | UCM | 57.7 × 21 = 1211.7 | 85.1 × 21 = 1787.1 | 86.9 × 21 = 1824.9 |
| AID | 61.5 × 30 = 1845.0 | 87.9 × 30 = 2637.0 | 88.5 × 30 = 2655.0 | |
| RESISC45 | 67.1 × 45 = 3019.5 | 91.5 × 45 = 4117.5 | 92.8 × 45 = 4176.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghadi, Y.Y.; Rafique, A.A.; al Shloul, T.; Alsuhibany, S.A.; Jalal, A.; Park, J. Robust Object Categorization and Scene Classification over Remote Sensing Images via Features Fusion and Fully Convolutional Network. Remote Sens. 2022, 14, 1550. https://doi.org/10.3390/rs14071550
Ghadi YY, Rafique AA, al Shloul T, Alsuhibany SA, Jalal A, Park J. Robust Object Categorization and Scene Classification over Remote Sensing Images via Features Fusion and Fully Convolutional Network. Remote Sensing. 2022; 14(7):1550. https://doi.org/10.3390/rs14071550
Chicago/Turabian StyleGhadi, Yazeed Yasin, Adnan Ahmed Rafique, Tamara al Shloul, Suliman A. Alsuhibany, Ahmad Jalal, and Jeongmin Park. 2022. "Robust Object Categorization and Scene Classification over Remote Sensing Images via Features Fusion and Fully Convolutional Network" Remote Sensing 14, no. 7: 1550. https://doi.org/10.3390/rs14071550
APA StyleGhadi, Y. Y., Rafique, A. A., al Shloul, T., Alsuhibany, S. A., Jalal, A., & Park, J. (2022). Robust Object Categorization and Scene Classification over Remote Sensing Images via Features Fusion and Fully Convolutional Network. Remote Sensing, 14(7), 1550. https://doi.org/10.3390/rs14071550