1. Introduction
Stereo matching, estimating disparities from stereo image pairs, is one of the most fundamental problems in computer vision tasks and remote sensing applications such as earth observation [
1,
2], autonomous driving [
3], robot navigation [
4], SLAM [
5], etc. [
6]. Owing to the increasing resolution and volume of remote sensing images, precise 3D reconstruction using multi-view VHR remote sensing images becomes possible, providing a new way to observe on-ground targets. As the fundamental task of 3D reconstruction, stereo matching finds pixelwise correspondences from rectified stereo image pairs and estimates horizontal disparities, which can be further used to calculate elevation and construct 3D models. Typically, large-scene remote sensing images contain objects of various sizes and heights, such as skyscrapers, residential buildings, and woods. Multi-scale objects result in different disparity ranges, which make stereo matching methods difficult to extract accurate correspondences.
Traditional stereo matching algorithms can be implemented using a four-step pipeline: matching cost computation, cost aggregation, disparity computation, and refinement [
7]. Numerous methods were proposed during past decades, they are mainly divided into three categories, i.e., global, local, and semi-global methods. Global methods usually solve an optimization problem by minimizing a global objective function containing some regularization terms [
8,
9], suffering from an expensive time cost. On the contrary, local methods make themselves much faster than global methods by only considering neighbor information [
7,
10,
11,
12], but they often lose estimating accuracy. Lastly, the semi-global methods trade off the time cost and accuracy by proposing more robust cost functions [
13,
14]. On behalf of the widely used semi-global cost aggregation methods, the Semi-Global-Matching (SGM) algorithm [
15] optimizes the global energy function with the aggregation in many directions. Although many significant algorithms have been proposed in traditional ways, they still suffer in textureless, occluded, and repetitive situations.
Benefiting from the strong representations of the convolutional neural network (CNN-based method), deep model has achieved promising results in those challenging areas. Generally, these deep networks are classified into two categories, non-end-to-end and end-to-end networks. The first category combines traditional steps to improve disparity estimation accuracy. They leveraged CNN to match the points with deep feature representation. Some of them aggregated traditional algorithms with CNN to calculate precise matching cost. For example, CNNs have been applied to learn how to match corresponding points in MC-CNN [
16]. Another approach [
17] using CNNs treated the problem of correspondence estimation as similarity computation, where CNNs compute the similarity score for a pair of image patches. Displets [
18] utilized object information by modeling 3D vehicles to resolve ambiguities in stereo matching. In addition, ResMatchNet [
19] learned to measure reflective confidence for the disparity maps to improve performance in challenging areas.
Nowadays, the end-to-end stereo matching networks are widely applied because the methods combining CNNs and traditional cost aggregation and disparity refinement often obtain satisfactory results in some challenging areas. The end-to-end methods are able to incorporate the four traditional steps to gather perception features more efficiently. The construction of cost volume is an indispensable step which is typically a 4D tensor with a size of [height × width × disparity × feature]. Existing state-of-the-art stereo matching networks can be categorized into two categories based on the cost volume construction ways: 2D and 3D convolution-based networks. The 2D methods usually leverage full correlation operation [
20] of the left and right feature maps to construct 3D cost volume, which include the first end-to-end trainable stereo matching network DispNet [
20], MADNet [
21], and AANet [
22]. The second category mostly uses direct feature concatenation without the decimation of feature channels, which generate a 4D cost volume. For example, GC-Net [
23] took a different approach by directly concatenating left and right features, and thus 3D convolutions were required to aggregate the resulting 4D cost volume. In addition, PSMNet [
24] further improved GC-Net by introducing more 3D convolutions for cost aggregation and accordingly obtains better accuracy. GANet [
25] noticed the drawbacks of 3D convolutions and replaced them with two guided aggregation layers to further improve the performances. Actually, the 3D methods usually outperform 2D methods a lot on computer vision benchmarks, though they always require higher computational complexity and memory consumption. An exception to those concatenation methods, the GWCNet [
26] is proposed to trade off the loss of full correlation and concatenation, in which group-wise correlation is applied to balance that problem.
Aiming at alleviating the expensive computational and time cost in 4D cost volumes, multi-stage methods based on multi-scale pyramidal towers [
8,
21,
27] are proposed. These methods used cascade cost volumes to narrow down the disparity search range and progressively refine the estimated disparity from coarse to fine. Recently, CasStereo [
28] extended such framework in multi-view stereo, which generates the next scale’s disparity search space by uniformly sampling a predefined range. In addition, UCSNet [
29] proposed adaptive thin volumes by constructing uncertainty-aware cost volume in multi-view stereo. Most recently, CFNet [
30] shared similarities with [
28,
29], which generates the next-stage search range with learned parameters. Considering the multi-modality of disparity probability distributions, ACFNet [
31] directly supervised the cost volume with unimodal ground truth distributions. In addition [
30], adopted from [
29,
31], defined an uncertainty estimation to quantify the degree of the cost volume tending to be multi-modal distribution. Consequently, our proposed method aims to improve the stereo matching accuracy of remote sensing images by absorbing the advantages of multi-stage methods and making them suitable for the characteristics of remote sensing images.
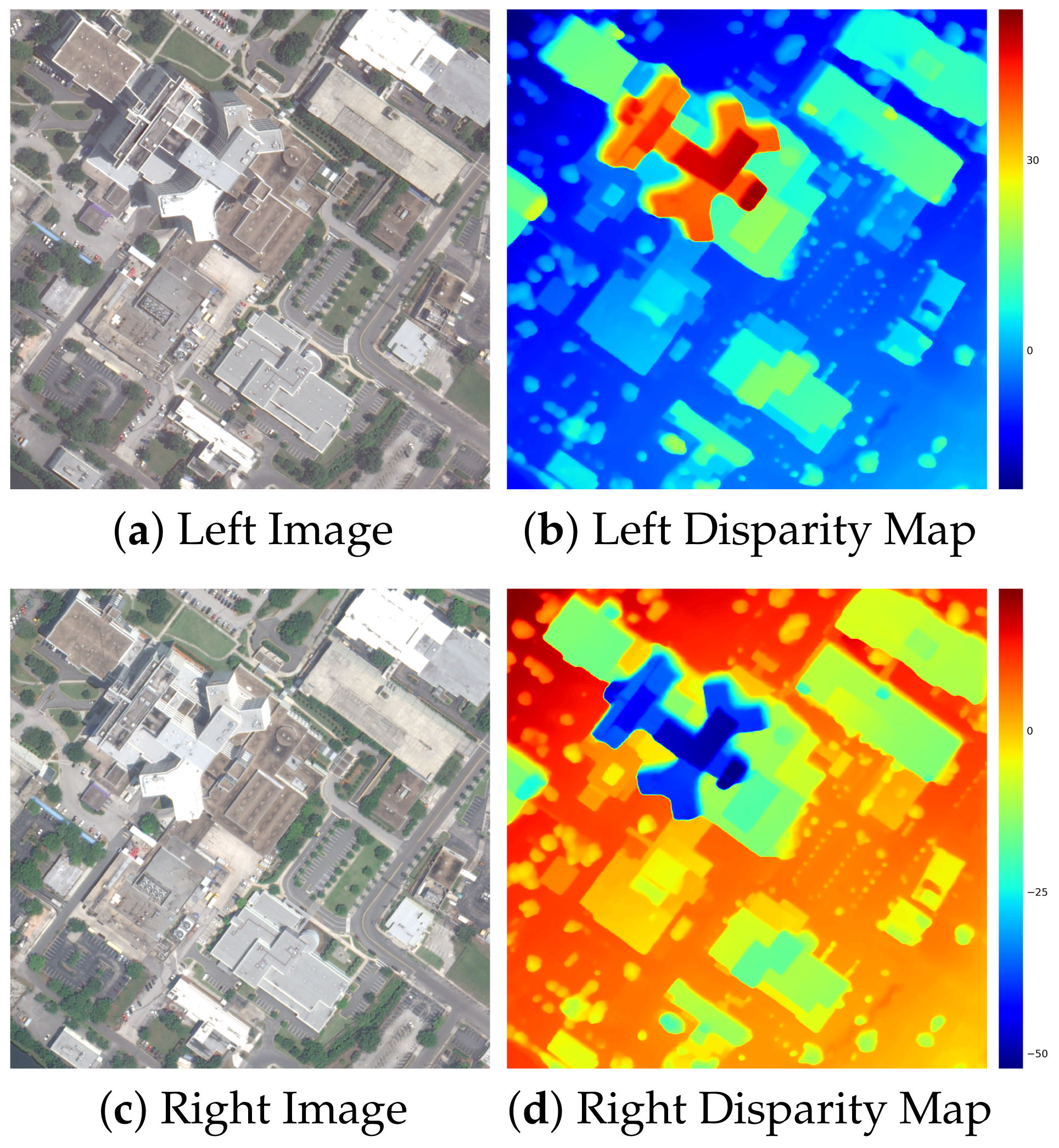
Multi-view VHR remote sensing images acquired from pushbroom cameras can be applied to precise 3D reconstruction due to the growing resolution [
32]. However, compared to the natural images, there are more difficult scenes in VHR remote sensing images [
33]. First, the disparities in remote sensing stereo pairs can be both positive and negative according to the complicated viewing conditions. We illustrate the disparity range (in
Figure 1) of each ground truth DSP (disparity map) in IGARSS2019 [
34] data fusion contest dataset US3D [
34,
35]. Second, a lot of challenging areas exist which easily produce ambiguous disparity estimation results, including occluded areas and textureless areas with repetitive patterns which cause difficulties in obtaining accurate correspondences. In addition, the disparity probability distributions in those areas are susceptible to multi-modal. Last, multi-scale objects in remote sensing images, which contain various disparities, further increase the difficulty to find the suitable disparity search range. As shown in
Figure 2, comparing with the proposed network, the CFNet [
30] fails to produce good results on US3D.
To this end, two motivating and challenging problems in terms of remote sensing images arise: how to estimate precise disparities for multi-scale objects in large scenes and how to regularize the multi-modality probability distributions in such challenging areas. In this paper, we propose a novel confidence-aware unimodal cascade and fusion pyramid network for multi-scale stereo matching of VHR remote sensing images. Specifically, toward the characteristics of various disparity search ranges in remote sensing images, we modify the group-wise cost volume to cover the whole disparity search range. As for the multi-scale cost aggregation problems, existing cross-scale aggregation algorithms [
22,
36] adaptively combine the results of cost aggregation at multiple scales. Different from those methods, we build cross-scale cost volume interaction in a cascade framework for remote sensing images. Last but not least, considering the multi-modality of disparity probability distributions, we propose a multi-scale module to generate learnable confidence maps, which are used to generate the next stage search range, and a multi-scale unimodal distribution loss is applied to regularize cost distribution.
The rest of this paper is organized as follows.
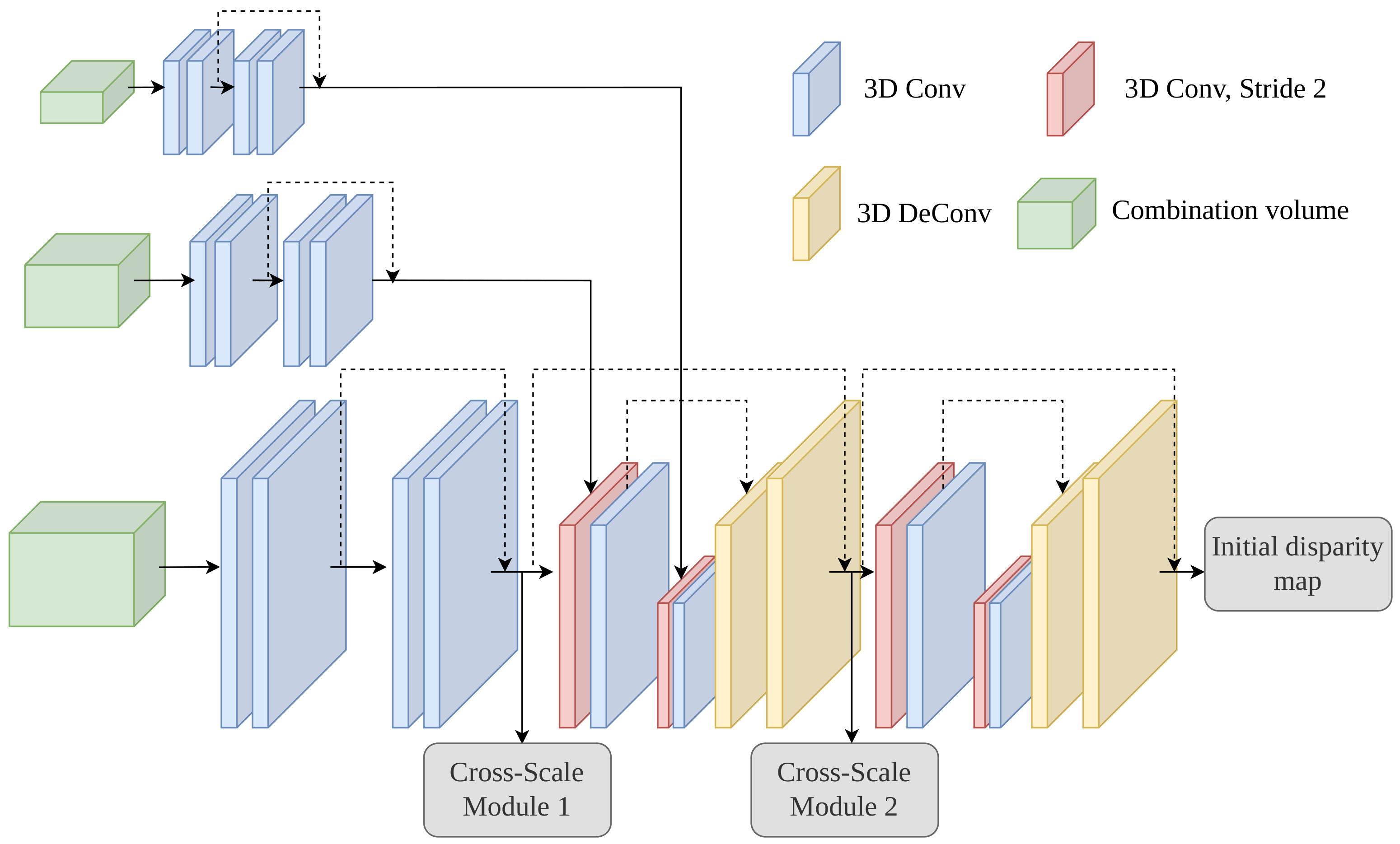
Section 2 first illustrates the overall framework of the proposed confidence-aware cascade network and then introduces each module of the network in detail. In
Section 3, the experimental results of stereo matching for multi-scale objects in remote sensing images are shown, then both qualitative and quantitative analyses demonstrate the superiority of the proposed network. In
Section 4, ablation experiments on different settings are conducted to prove the effectiveness of each module in the proposed network. Finally, the conclusions are drawn in
Section 5.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}