1. Introduction
Information on cropland extent is fundamental for crop monitoring and management [
1]. Remote sensing technology can supply effective and accurate information about agricultural activity because of its characteristic of repeatability, timeliness, and high coverage [
2], making it a primary data source for agricultural crop recognition [
3,
4]. Existing middle- or coarse-resolution remote sensing data have the disadvantage that the limited spatial resolution is insufficient to precisely classify patches with small agricultural crop size distributions [
5]. Very-high-resolution (VHR) images have detailed textural and spatial information, providing an improved opportunity for precise classification of small croplands [
6]. The object-based classification considers both spectral and also morphological, contextual, and proximity features in VHR images; therefore, many previous studies have indicated that object-oriented image analysis approaches outperformed pixel-based classifications when comparing accuracy metrics [
7,
8]. Numerous studies have used various object-oriented supervised machine learning classifiers for crop identification based on VHR satellite datasets [
9,
10]. The common machine learning algorithms include random forest (RF) [
7], support vector machine (SVM) [
8], classification and regression tree (CART), K-nearest neighbors (KNN) [
11], adaptive boosting (AdaBoost) [
12], neural networks, etc.
Object-based classification can lead to better performance using a high number of features generated from spectral, spatial, and contextual properties in VHR images [
13]. Alternatively, to further improve classification accuracy, increasing amounts of auxiliary features (e.g., geometry, texture, and vegetation index) is used to recognize land cover types [
14]. However, not all features have a positive influence on land cover classification. Several studies have found that excessive input features may reduce the classification accuracy and increase the computation time [
15,
16]. The feature selection (FS) technique is very effective in reducing redundant information, which aims to find the optimal subset of features with minimal redundancy and maximal relevance to the objects. Several FS methods have been widely used in object-based classification. For example, Laliberte et al. [
17] compared three FS methods for object-based vegetation classification, and pointed out that classification tree analysis was most suited for mapping arid rangelands with UltraCam-L imagery. Cánovas-García and Alonso-Sarría [
18] indicated that the Gini index was the most appropriate FS method for identifying agricultural landscape by Z/I-imaging DMC imagery. Ma et al. [
19] showed that support vector machine-recursive feature elimination (SVM-RFE) could provide more useful features to perform better classification accuracy for an agricultural area mapping using unmanned aerial vehicle imagery. Overall, there is no general FS method available to obtain optimal features for various machine learning classifiers, regions with different climatic conditions, and different types of remote sensing data. Therefore, further studies of the utility and efficiency of the FS methods need to be conducted according to different research purposes.
Betel palms and mango plantations are two important cultivated commercial crops in tropical and sub-tropical areas, such as Africa, China, India, Malaysia, and Thailand [
20]. China is the world’s dominant producer of both betel nuts and mango, and the island of Hainan in southern China is the main production area of the two crops. The acreages of betel palms and mango plantations in Hainan grew from 26,944 and 36,076 ha, respectively, in 2000 to 115,171 and 56,934 ha, respectively, in 2019. Moreover, the total outputs of betel nuts and mango increased from 101,220 and 35,598 tons, respectively, in 2000 to 675,805 and 287,043 tons, respectively, in 2019 [
21]. The industries of betel palms and mango plantations play a critical role in tropical rural economic development in Hainan due to their high profit margins and strong market demand [
22]. To ensure a scientifically informed management policy relating to tropical crops, it is necessary to regularly monitor the accurate extents of betel palms and mango plantations. Compared with the temperate zone, the planting regions of tropical crops are relatively scattered and small, and more abundant crops present in a small area could reduce the spectral separability of different classes [
23]. In addition, as two perennial evergreen trees, betel palms and mango plantations have no significant defoliation phase, unlike rubber plantations [
24], which is another common tropical crop. Thus, it is a complex and challenging task to recognize betel palms and mango plantations in heterogeneous agricultural regions.
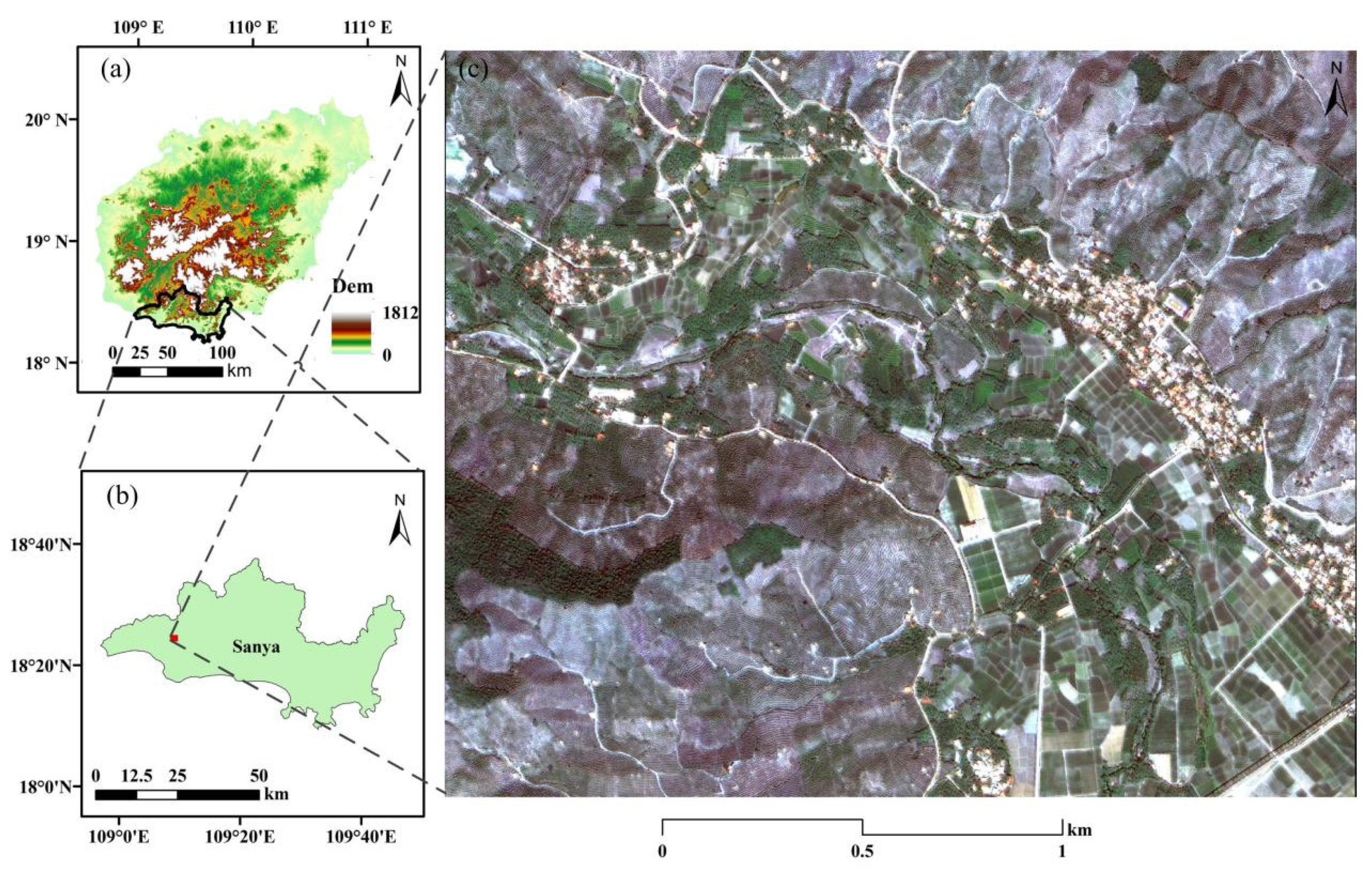
The Gaofen-2 satellite was launched from the Taiyuan Satellite Launch Centre on 19 August 2014, and is also the first civilian satellite with sub-meter spatial resolution and a 5-day repetition cycle in China [
25]. The excellent spatial and temporal resolution of Gaofen-2 could provide more accurate spectral and textural information for detailed land cover mapping. In addition, compared with other foreign commercial satellites, Gaofen-2 data has the advantage of low cost, and some sectors (such as Chinese forestry, land, and resources) could obtain free satellite data [
15]. Therefore, Gaofen-2 images have been widely used in agricultural monitoring [
26,
27]; however, these studies have mainly focused on a single crop type in temperate regions, such as wheat and maize. To the best of our knowledge, mapping tropical crops, especially for betel palms and mango plantations with Gaofen-2 imagery, has rarely been reported in previous literature. Whether Gaofen-2 data can accurately recognize tropical crops in complex heterogeneous agricultural regions is a topic which still needs in-depth research.
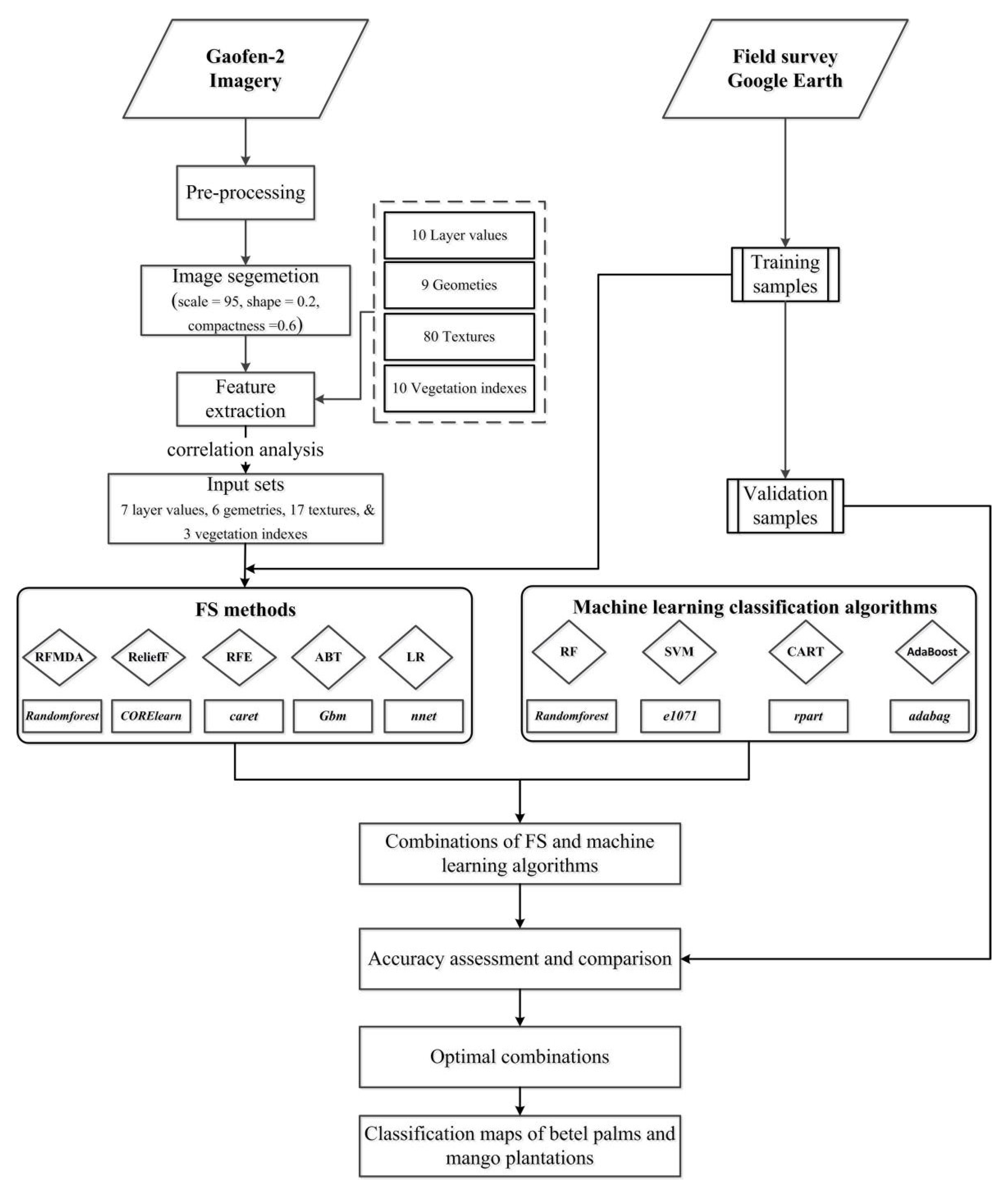
Our research aims to develop a framework for recognizing betel palms and mango plantations in complex tropical agricultural regions using Gaofen-2 imagery. The detailed objectives of this study are to: (1) evaluate the potential of GaoFen-2 imagery for mapping betel palms and mango plantations in complex tropical agricultural regions, (2) assess and compare the relative importance of different FS methods, and (3) explore the optimal combination of FS methods and machine learning classifiers for identifying betel palms and mango plantations.
4. Results
4.1. Selected Features Using Different FS Methods
To explore the sorting of relevant variables,
Table 5 listed the top 15 features derived from different FS methods, which have proven to be the most important for mapping betel palms and mango plantations (see
Section 4.2). The proportion of different types of features among the different subsets is shown in
Table 6. The results show that the most relevant variables from each FS method had significant differences. Although the prediction of one single variable may be limited, it could increase classification accuracy by its interaction with other variables [
16,
63]. Overall, textural features made up a large proportion of the top 15 features. Surprising, the vegetation index of GI was the top-ranking feature.
ReliefF concentrated on information from vegetation indexes and layer values, such as standard deviation and max. diff. In addition, we observed that the selected features of ReliefF had more consistency with RFMDA, compared with the other three FS methods. For example, GLCM contrast_blue was selected by RFMDA and ReliefF, while it was not presented in the top 15 features of RFE, ABT, and LR. ABT presented more sophisticated types, including texture, layer values, and geometrical feature. Significantly, more geometrical and texture features appeared in LR, such as density, asymmetry, and roundness. Among the top 15 features, the percentages of geometry and texture were 26.67% and 53.33% by LR, respectively, which were higher than the other four FS methods.
4.2. The OA Trends with Different Combinations
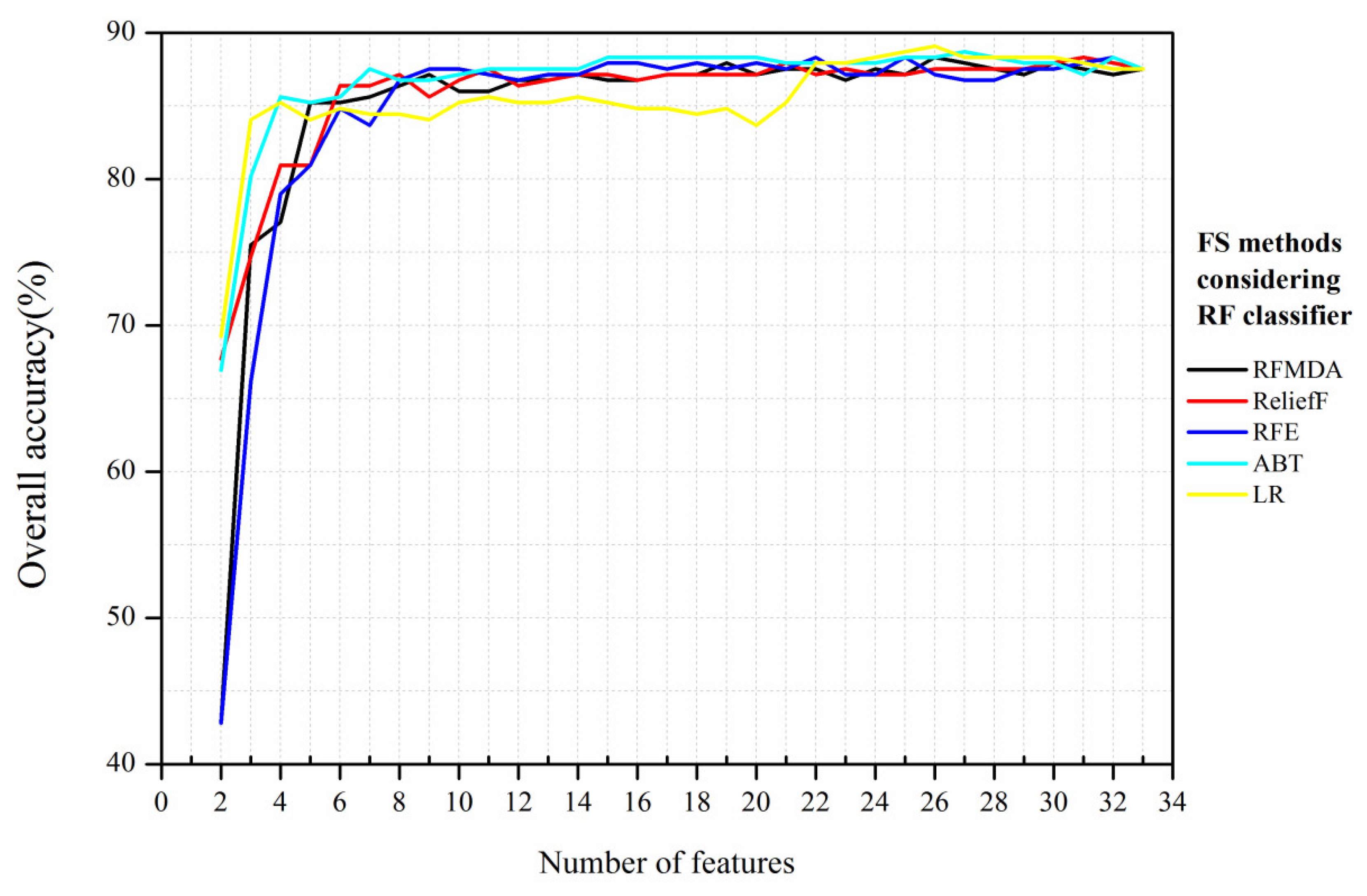
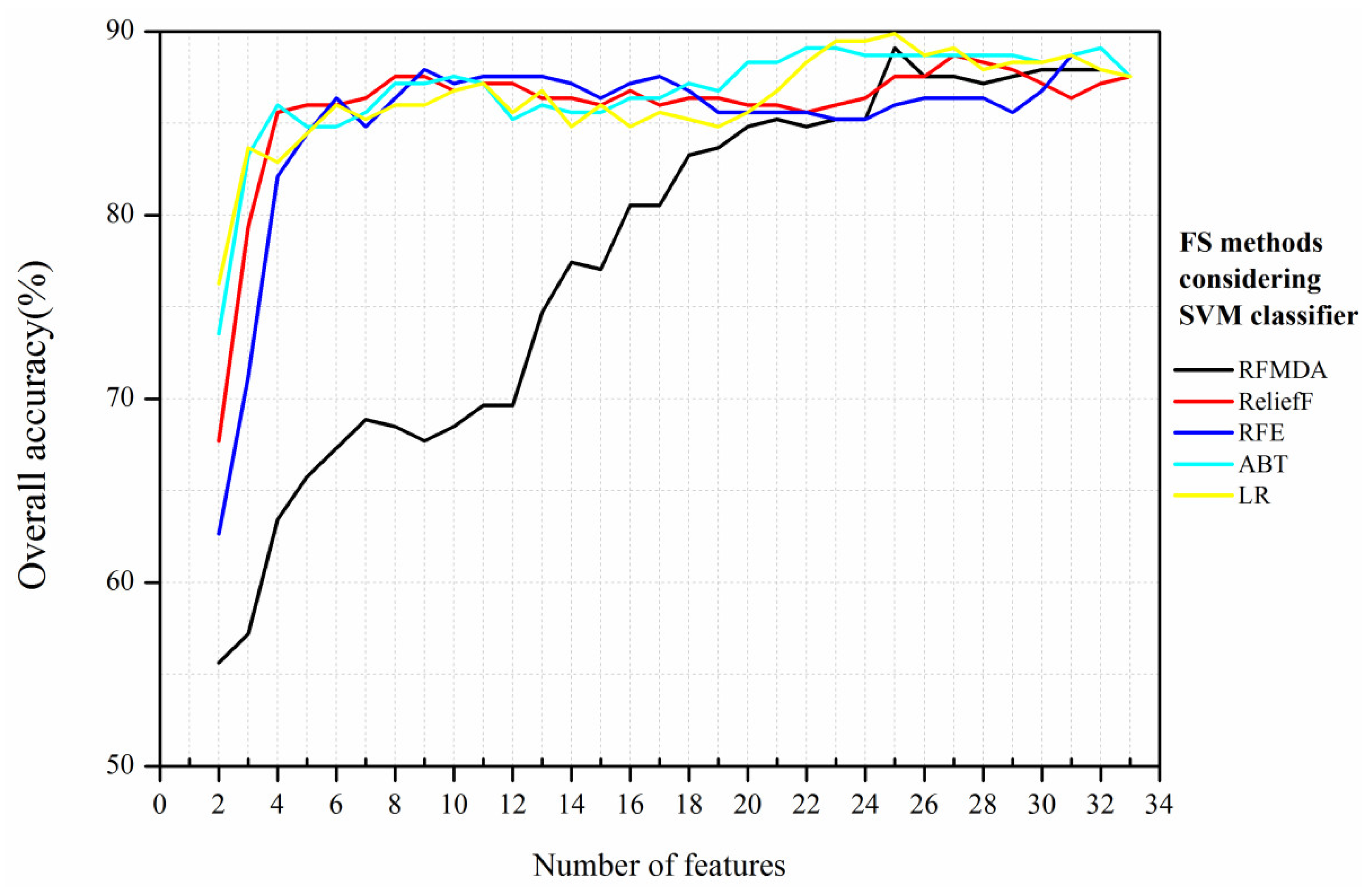
The OA was computed for all four classifiers, using a different number of features ranked by the abovementioned five FS methods.
Figure 5,
Figure 6,
Figure 7 and
Figure 8 show the change patterns of OA using various FS methods and machine learning algorithms. In general, the OA of each classifier increased rapidly with the number of features increasing in the initial stage. When certain thresholds were reached, the curves of OA remained stable, even though more features were selected.
The RF classifier produced no significant changes in OA after the number of features exceeded 5 (
Figure 5), regardless of the FS method used. This may indicate that the RF classifier is a robust algorithm that is insensitive to the addition of redundant and irrelevant features [
16,
18]. Here, LR had a higher classification accuracy (89.1%, 26 features) than the other FS methods (
Table 7). However, the OA between 7 and 21 in LR was lower than that of the other four FS methods. The OAs of RFMDA and ReliefF were virtually the same between 12 and 22 features. For ABT, the OA value achieved 85.6% using only four features, and remained almost stable subsequently.
Compared with the RF classifier, the SVM classifier indicated slightly greater sensitivity to high dimensionality but this advantage was not significant. Notably, the LR method achieved the highest OA (89.88%) with 25 features, which was the maximum accuracy in all classification combinations with five FS methods and four machine learning classifiers. The curve obtained from the RFMDA method was quite different from the other FS methods; in general, OA increased steadily as features were added (
Figure 6). Importantly, the RFMDA reached a maximum value (89.11%) with 25 features, and the result was approximate to that acquired by the LR method. As shown in
Table 7, using ABT and LR, there were statistically significant differences (
p < 0.05) compared with applying all features.
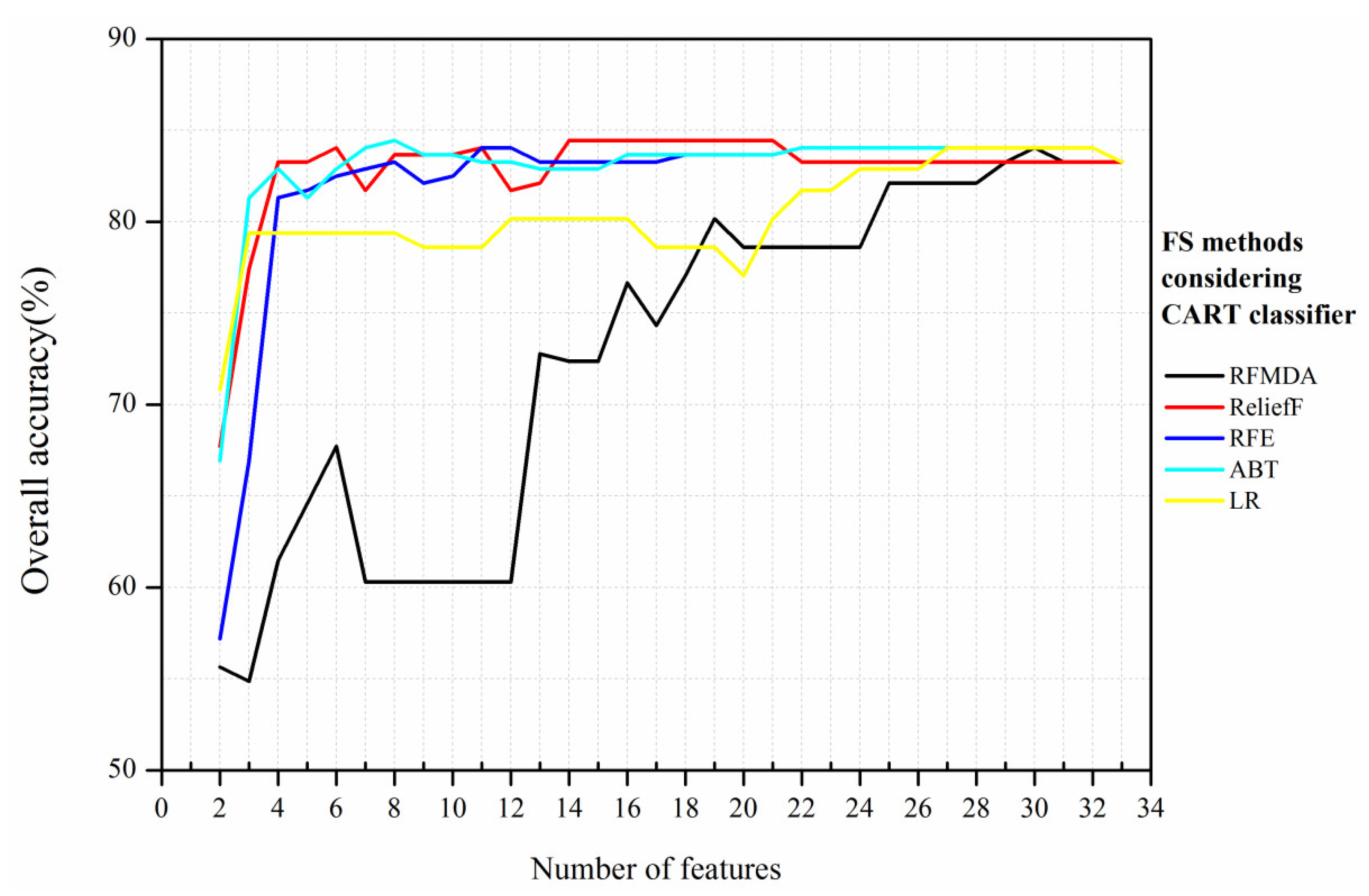
For the CART classifier, the highest OA (84.43%) was achieved with ABT and eight features, forming a parsimonious classification model because it needed the minimum number of features.
Figure 7 shows that ABT, ReliefF, and RFE had almost the same curve between 14 and 22 features. For LR, the OA showed no obvious variations between 3 and 19 features. Apart from RFMDA, the remaining four FS methods presented relatively high OA accuracy (>80%) when there were more than three input features. The curve of RFMDA fluctuated greatly, indicating that dimensionality reduction did not cause the OA to increase. This may be because the important features that suit the CART classifier were eliminated.
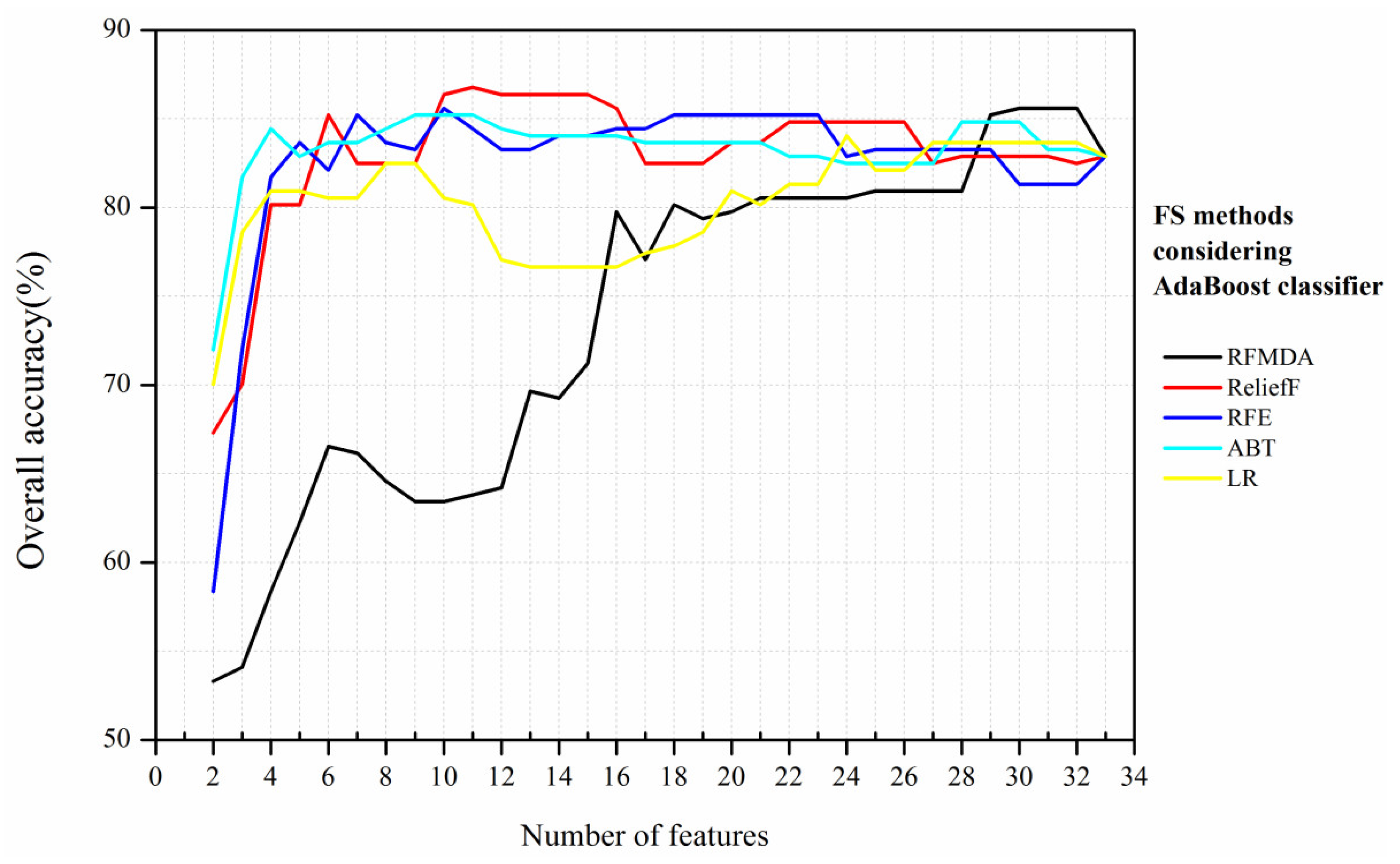
For the AdaBoost classifier, the ReliefF method obtained the best classification accuracy (86.77%) with 11 features. Moreover, ReliefF produced a ~4% improvement in OA compared with that containing all feature variables, and McNemar’s test indicated that the variation was statistically significant (
p < 0.05) (
Table 7). These findings show that FS is quite useful for the AdaBoost classifier.
Figure 8 shows a clear fluctuation in the OA curves with the AdaBoost classifier regardless of the FS method. In addition, RFMDA and RFE showed the same maximum classification accuracy (85.6%); however, RFE required fewer features than RFMDA to achieve the same value.
4.3. Classification Results
For a further specific analysis, we mainly compared classification accuracies of different classes based on the four machine learning algorithms. It should be noted that each classifier used the corresponding optimal feature set obtained from respective most appropriate FS method (see
Section 4.2). Ultimately, there were four optimal combinations: RF-LR (with 26 features), SVM-LR (with 25 features), CART-ABT (with 8 features), and AdaBoost-ReliefF (with 11 features). In general, although all four approaches produced considerable salt-and-pepper speckled noise (
Figure 9), the interesting land cover types of the study region could be reasonably identified. Accuracy indicators were calculated including producer’s accuracy (PA), user’s accuracy (UA), F1 score, kappa coefficients, and overall accuracy (OA) for all six types (
Table 8).
The F1 scores of mango plantations were 95.68%, 96.07%, 97.33%, and 96.69% for RF-LR, SVM-LR, CART-ABT, and AdaBoost-ReliefF, respectively. Among them, CART-ABT achieved maximum F1 score (97.33%) with only eight features. In addition, both producer’s accuracies and user’s accuracies with four combinations exceeded 90%. These results demonstrated that mango plantations can be precisely identified whether on the ground or on the map based on the four optimal combinations. When mapping the betel palms, RF-LR presented a higher F1 score (88.89%) than other classification schemes. The confusion mistakes were encountered with types such as betel palm-cultivated land. Meanwhile, RF-LR was the only scheme in which the user’s accuracy was more than 80%. Compared to the other machine learning classifiers, the SVM-LR for recognizing cultivated land and built up produced the highest classification accuracy (F1 score is 92.91% for cultivated land and 94.74% for built up). In all classification schemes, the others classes performed poor classification results, and the F1 scores were generally in the range of 50–60%, which might be induced by the similar spectral structure between others and built up. The second lowest F1 score was produced by forest, and there were some signature confusion among forest and betel palms.
Based on the visual interpretation from the classification maps, the mango plantations and betel palms were the principal tropical crops in the study region, and mango plantations were located throughout the surrounding betel palms and cultivated land (
Figure 9). The classification results were close to our previous field survey data. There were slight differences in the specific depictions under different classification schemes when the same tropical crops were compared. For example, the confusion of mango plantations and forest in the northeastern corner of the study region was more apparent in machine learning classifications that utilized the RF-LR and AdaBoost-ReliefF methods when compared with classifications using other approaches. However, the maps based on the two aforementioned approaches produced fewer jagged edges along narrow forest areas in the southeastern corner of the study region. The RF-LR method produced a more accurate visual depiction of betel palms than any classification approaches, although there remained some misclassification among forest and cultivated land and betel palm regions because of the similar spectral characteristics [
30]. Moreover, the boundary between betel palms and built-up land was not well distinguished for all classification schemes.
6. Conclusions
Mapping of tropical agricultural land cover types is incredibly difficult due to their complexity and heterogeneity in finer resolution imagery. In this study, our specific objectives were to assess the appropriate combinations of FS methods and machine learning classifiers, and evaluate the capability of sub-meter resolution Gaofen-2 imagery for identifying betel palms and mango plantations based on object-oriented classification. The SVM and RF classifiers based exclusively on classification accuracy results showed a slight advantage for the purposes of mapping tropical crops relative to the other machine learning classifiers. Furthermore, we also found that all classifiers presented better performance after FS methods were used to choose the optimal subsets of features. Compared with classification results without the FS method, different classifiers with an optimal features subset could increase the overall accuracy by 1–4%. Moreover, different FS methods showed adaptability to various machine learning classifiers. In general, RF and SVM classifiers applying the LR method showed higher overall accuracies. For the CART classifier, ABT was identified as the most suitable FS method for identifying tropical crops. The AdaBoost classifier with ReliefF was also a suitable option for classifying tropical crops under a comprehensive consideration of classification precision and computation time. When evaluating classification results based both on the ground and on the map, this study indicated that all four optimal combinations of FS methods and classifiers could correctly recognize mango plantation regions, whereas betel palms were best depicted by using the RF-LR method with 26 features. Even though the classification accuracy of AdaBoost-ReliefF was not the highest, we suggested it was a practical scheme if identifying betel palms and mango plantations in large study regions.
Our research confirmed the utility of Gaofen-2 for mapping betel palms and mango plantations in complex tropical agricultural regions with heterogeneous planting structure and a high degree of fragmentation. These findings provide an effective technical approach for accurate tropical crop identification, which is the foundation for tropical agricultural regional planning and management.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}