
Few-Shot SAR-ATR Based on Instance-Aware Transformer

 , and
, and
Abstract
:1. Introduction
- Different from present FSL methods, we make an attempt to utilize the transformer to solve the problem for SAR-ATR under the data-limited situation. To the best of our knowledge, we are the first to adopt the transformer into few-shot SAR-ATR.
- The proposed IAT aims to exploit every instance’s power to strengthen the representation of the query images. It adjusts the query representations based on their comparable similarities to all the support images. The support representations, meanwhile, will be refined along with the query in the feedforward networks.
- The experimental results of the few-shot SAR-ATR datasets demonstrate the effectiveness of IAT and the few-shot accuracy of IAT can surpass most of the state-of-the-art methods.
2. Related Works
2.1. SAR-ATR with DCNNs
2.2. Few-Shot Learning Methods
2.3. SAR-ATR Based on Few-Shot Learning
3. Materials and Methods
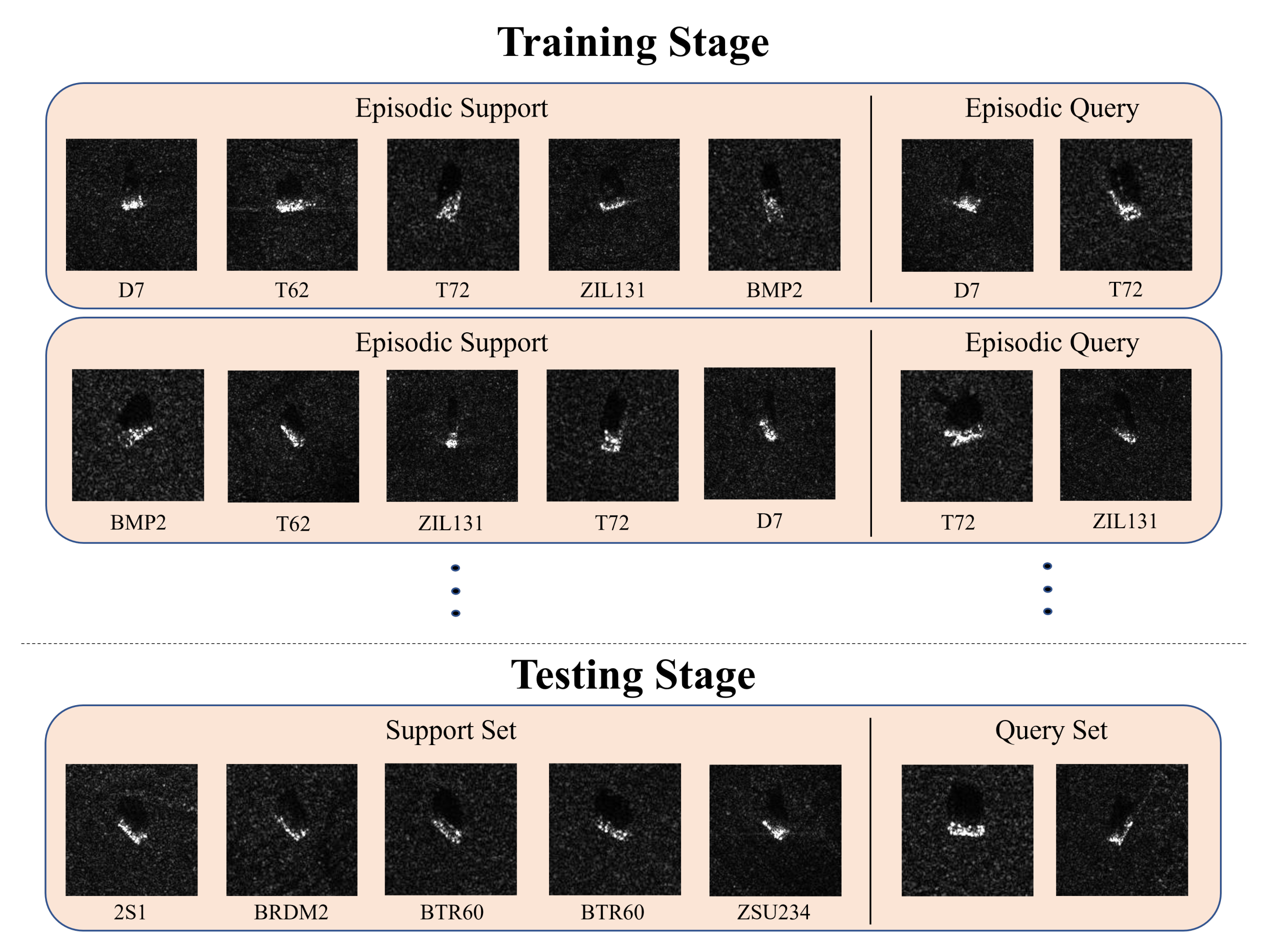
3.1. Problem Definition
3.2. Overall Architecture
3.3. Shared Cross-Transformer Module
3.4. DCNN Backbone
3.5. Loss
4. Experiments
4.1. Implementations
4.1.1. Dataset
4.1.2. Implementation Details
4.1.3. Accuracy Metric
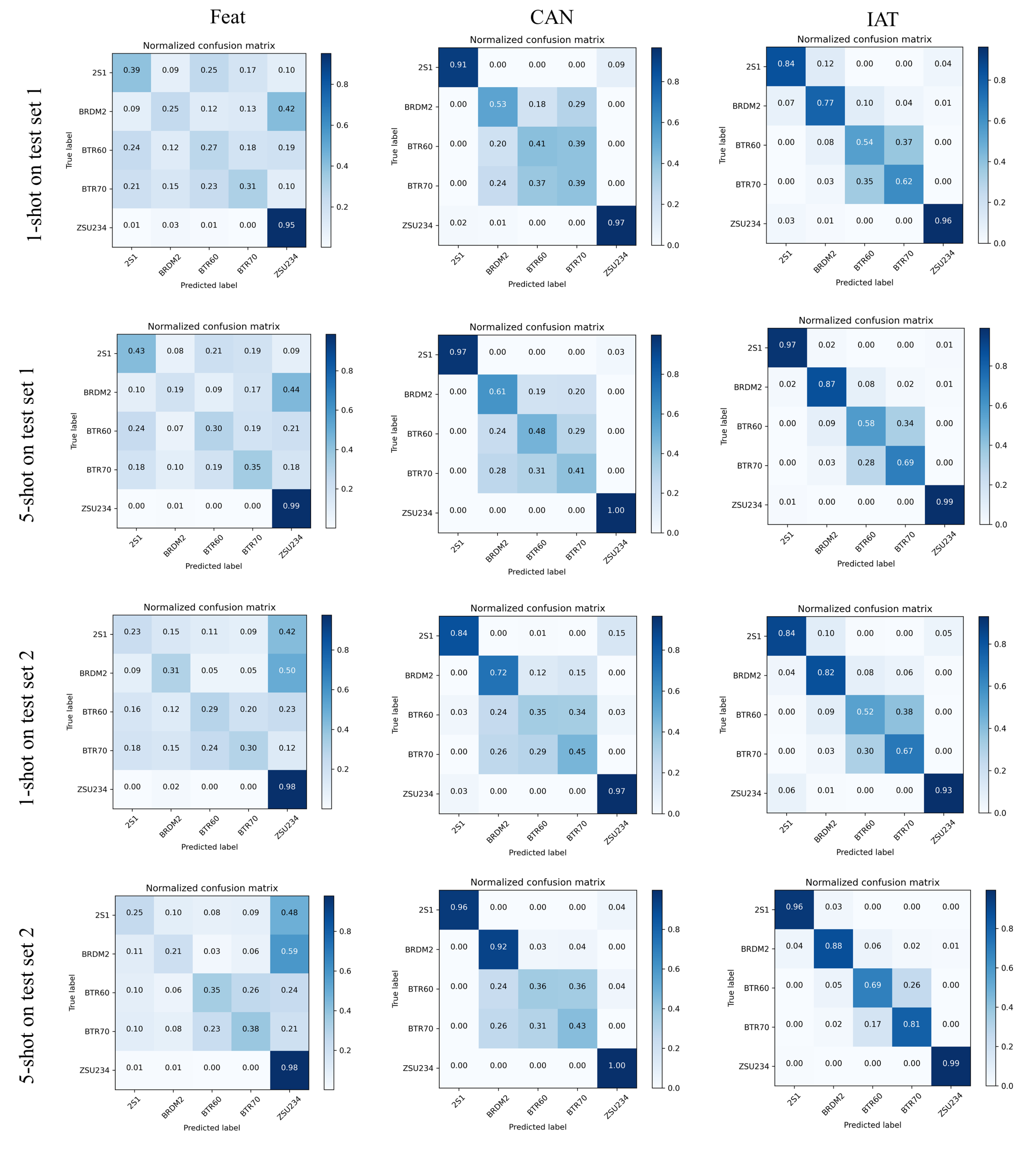
4.2. Results
4.3. Ablation Studies
4.3.1. Distance Calculation
4.3.2. Shared Cross Transformer Module
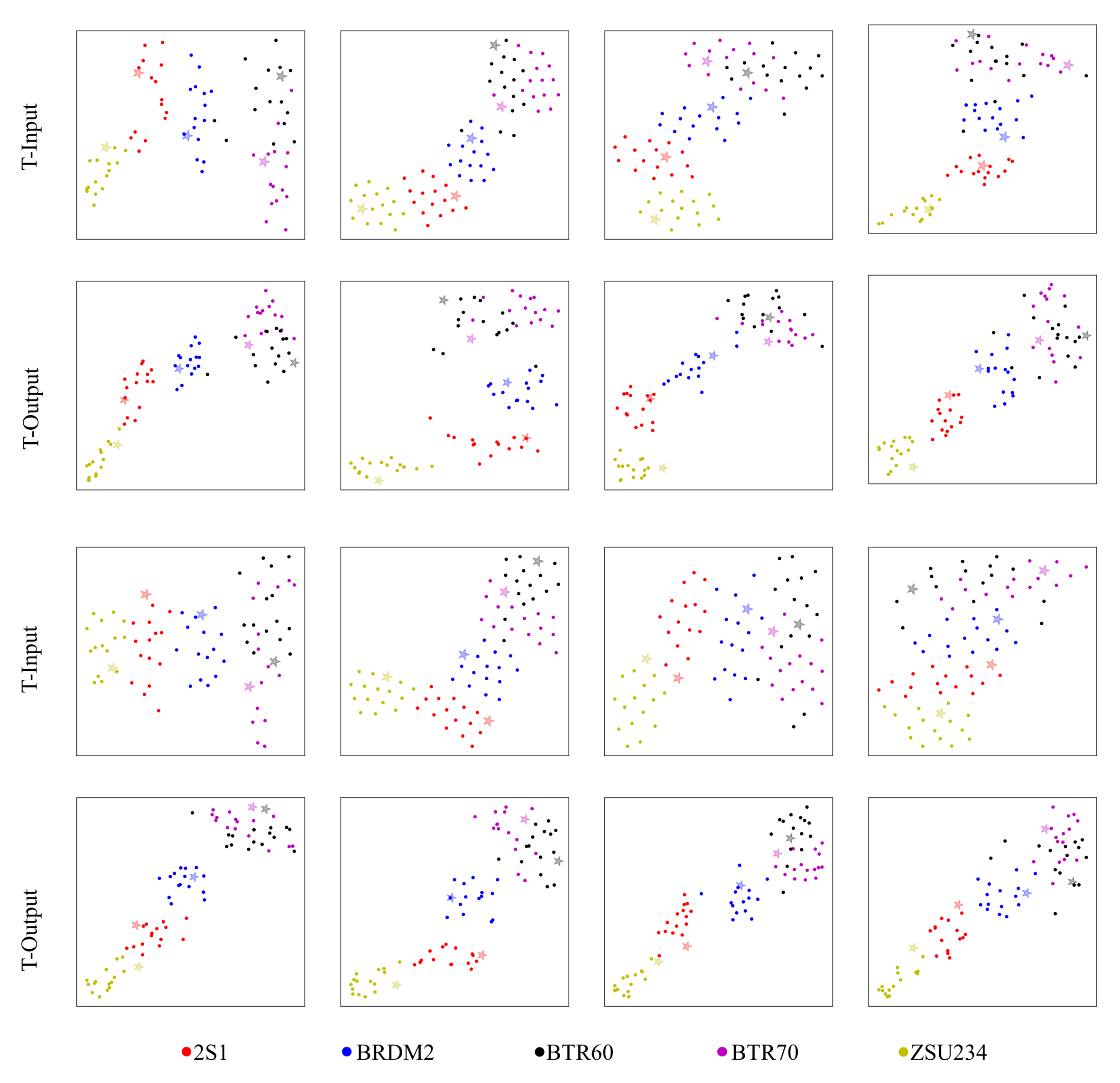
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SAR-ATR | Synthetic Aperture Radar Automatic Target Recognition |
| FSL | Few-Shot Learning |
| DCNN | Deep Convolutional Neural Network |
| IAT | Instance-Aware Transformer |
| MSTAR | The Moving and Stationary Target Acquisition and Recognition |
References
- Morgan, D.A. Deep convolutional neural networks for ATR from SAR imagery. In Algorithms for Synthetic Aperture Radar Imagery XXII; International Society for Optics and Photonics: Baltimore, MD, USA, 2015; Volume 9475, p. 94750F. [Google Scholar]
- Shao, J.; Qu, C.; Li, J. A performance analysis of convolutional neural network models in SAR target recognition. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.Q. Target classification using the deep convolutional networks for SAR images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Zhang, J.; Xing, M.; Xie, Y. FEC: A feature fusion framework for SAR target recognition based on electromagnetic scattering features and deep CNN features. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2174–2187. [Google Scholar] [CrossRef]
- Shijie, J.; Ping, W.; Peiyi, J.; Siping, H. Research on data augmentation for image classification based on convolution neural networks. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 4165–4170. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 113–123. [Google Scholar]
- Ratner, A.J.; Ehrenberg, H.R.; Hussain, Z.; Dunnmon, J.; Ré, C. Learning to compose domain-specific transformations for data augmentation. Adv. Neural Inf. Process. Syst. 2017, 30, 3239. [Google Scholar] [PubMed]
- Guo, J.; Lei, B.; Ding, C.; Zhang, Y. Synthetic Aperture Radar Image Synthesis by Using Generative Adversarial Nets. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1111–1115. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Liu, L.; Pan, Z.; Qiu, X.; Peng, L. SAR target classification with CycleGAN transferred simulated samples. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4411–4414. [Google Scholar]
- Cui, Z.; Zhang, M.; Cao, Z.; Cao, C. Image data augmentation for SAR sensor via generative adversarial nets. IEEE Access 2019, 7, 42255–42268. [Google Scholar] [CrossRef]
- Cao, C.; Cao, Z.; Cui, Z. LDGAN: A synthetic aperture radar image generation method for automatic target recognition. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3495–3508. [Google Scholar] [CrossRef]
- Auer, S.J. 3D Synthetic Aperture Radar Simulation for Interpreting Complex Urban Reflection Scenarios. Ph.D. Thesis, Technische Universität München, Munich, Germany, 2011. [Google Scholar]
- Hammer, H.; Schulz, K. Coherent simulation of SAR images. In Image and Signal Processing for Remote Sensing XV; International Society for Optics and Photonics: Baltimore, MD, USA, 2009; Volume 7477, p. 74771G. [Google Scholar]
- Malmgren-Hansen, D.; Kusk, A.; Dall, J.; Nielsen, A.A.; Engholm, R.; Skriver, H. Improving SAR automatic target recognition models with transfer learning from simulated data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1484–1488. [Google Scholar] [CrossRef] [Green Version]
- Zhong, C.; Mu, X.; He, X.; Wang, J.; Zhu, M. SAR target image classification based on transfer learning and model compression. IEEE Geosci. Remote Sens. Lett. 2018, 16, 412–416. [Google Scholar] [CrossRef]
- Huang, Z.; Pan, Z.; Lei, B. What, where, and how to transfer in SAR target recognition based on deep CNNs. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2324–2336. [Google Scholar] [CrossRef] [Green Version]
- Tang, J.; Zhang, F.; Zhou, Y.; Yin, Q.; Hu, W. A fast inference networks for SAR target few-shot learning based on improved siamese networks. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1212–1215. [Google Scholar]
- Lu, D.; Cao, L.; Liu, H. Few-Shot Learning Neural Network for SAR Target Recognition. In Proceedings of the 2019 6th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Xiamen, China, 26–29 November 2019; pp. 1–4. [Google Scholar]
- Wang, L.; Bai, X.; Zhou, F. Few-Shot SAR ATR Based on Conv-BiLSTM Prototypical Networks. In Proceedings of the 2019 6th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Xiamen, China, 26–29 November 2019; pp. 1–5. [Google Scholar]
- Yan, Y.; Sun, J.; Yu, J. Prototype metric network for few-shot radar target recognition. In Proceedings of the IET International Radar Conference (IET IRC 2020), Online, 4–6 November 2020; Volume 2020, pp. 1102–1107. [Google Scholar]
- Ye, H.J.; Hu, H.; Zhan, D.C.; Sha, F. Few-shot learning via embedding adaptation with set-to-set functions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8808–8817. [Google Scholar]
- Hou, R.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Cross attention network for few-shot classification. arXiv 2019, arXiv:1910.07677. [Google Scholar]
- Li, W.; Wang, L.; Huo, J.; Shi, Y.; Gao, Y.; Luo, J. Asymmetric Distribution Measure for Few-shot Learning. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI 2020), Yokohama, Japan, 7–15 January 2020; pp. 2957–2963. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762v2. [Google Scholar]
- Li, W.; Dong, C.; Tian, P.; Qin, T.; Yang, X.; Wang, Z.; Huo, J.; Shi, Y.; Wang, L.; Gao, Y.; et al. LibFewShot: A Comprehensive Library for Few-shot Learning. arXiv 2021, arXiv:2109.04898. [Google Scholar]
- Chen, W.Y.; Liu, Y.C.; Kira, Z.; Wang, Y.C.F.; Huang, J.B. A closer look at few-shot classification. arXiv 2019, arXiv:1904.04232. [Google Scholar]
- Dhillon, G.S.; Chaudhari, P.; Ravichandran, A.; Soatto, S. A baseline for few-shot image classification. arXiv 2019, arXiv:1909.02729. [Google Scholar]
- Yang, S.; Liu, L.; Xu, M. Free lunch for few-shot learning: Distribution calibration. arXiv 2021, arXiv:2101.06395. [Google Scholar]
- Liu, B.; Cao, Y.; Lin, Y.; Li, Q.; Zhang, Z.; Long, M.; Hu, H. Negative margin matters: Understanding margin in few-shot classification. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 438–455. [Google Scholar]
- Rusu, A.A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; Hadsell, R. Meta-learning with latent embedding optimization. arXiv 2018, arXiv:1807.05960. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning (ICML 2017), Sydney, NSW, Australia, 6–11 August 2017; PMLR: Westminster, UK, 2017; pp. 1126–1135. [Google Scholar]
- Bertinetto, L.; Henriques, J.F.; Torr, P.H.; Vedaldi, A. Meta-learning with differentiable closed-form solvers. arXiv 2018, arXiv:1805.08136. [Google Scholar]
- Lee, K.; Maji, S.; Ravichandran, A.; Soatto, S. Meta-learning with differentiable convex optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10657–10665. [Google Scholar]
- Xu, W.; Wang, H.; Tu, Z. Attentional Constellation Nets for Few-Shot Learning. In Proceedings of the International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021; Available online: OpenReview.net (accessed on 7 March 2022).
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical networks for few-shot learning. arXiv 2017, arXiv:1703.05175. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Wang, L.; Bai, X.; Gong, C.; Zhou, F. Hybrid Inference Network for Few-Shot SAR Automatic Target Recognition. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9257–9269. [Google Scholar] [CrossRef]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2020, arXiv:1606.08415. [Google Scholar]
- Keydel, E.R.; Lee, S.W.; Moore, J.T. MSTAR extended operating conditions: A tutorial. Proc. Spie 1996, 2757, 228–242. [Google Scholar]
- Gordon, J.; Bronskill, J.; Bauer, M.; Nowozin, S.; Turner, R.E. Meta-Learning Probabilistic Inference for Prediction. In Proceedings of the 7th International Conference on Learning Representations (ICLR 2019), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Raghu, A.; Raghu, M.; Bengio, S.; Vinyals, O. Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML. In Proceedings of the 8th International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Li, W.; Xu, J.; Huo, J.; Wang, L.; Gao, Y.; Luo, J. Distribution Consistency Based Covariance Metric Networks for Few-Shot Learning. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI 2019), Honolulu, HI, USA, 27 January–1 February 2019; pp. 8642–8649. [Google Scholar] [CrossRef]
- Rajasegaran, J.; Khan, S.; Hayat, M.; Khan, F.S.; Shah, M. Self-supervised Knowledge Distillation for Few-shot Learning. arXiv 2020, arXiv:2006.09785. [Google Scholar]
- Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting Local Descriptor Based Image-To-Class Measure for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; pp. 7260–7268. [Google Scholar] [CrossRef] [Green Version]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set | Class | Depression | No. Image |
|---|---|---|---|
| Train | D7 | 299 | |
| T62 | 299 | ||
| T72 | 232 | ||
| ZIL131 | 299 | ||
| BMP2 | 233 | ||
| Test 1 | 2S1 | 299 | |
| BRDM2 | 298 | ||
| ZSU234 | 299 | ||
| BTR60 | 256 | ||
| BTR70 | 233 | ||
| Test 2 | 2S1 | 274 | |
| BRDM2 | 274 | ||
| ZSU234 | 274 | ||
| BTR60 | 195 | ||
| BTR70 | 196 |
| Methods | Test Set 1 | Test Set 2 | ||
|---|---|---|---|---|
| 1 Shot | 5 Shot | 1 Shot | 5 Shot | |
| ProtoNet [36] | ||||
| RelationNet [37] | ||||
| Feat [22] | ||||
| CAN [23] | ||||
| Adm [24] | ||||
| MAML [32] | ||||
| Versa [42] | ||||
| ANIL [43] | ||||
| ConvmNet [44] | ||||
| SKD [45] | ||||
| DN4 [46] | ||||
| IAT | ||||
| Train Setting | Test Setting | Test Set 1 | Test Set 2 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Ins_Cos | Eucidean | Cosine | Ins_Cos | Eucidean | Cosine | 1 Shot | 5 Shot | 1 Shot | 5 Shot |
| ✓ | ✓ | 74.68 | 76.11 | 75.95 | 76.76 | ||||
| ✓ | ✓ | 74.68 | 78.44 | 75.89 | 78.75 | ||||
| ✓ | ✓ | 64.45 | 64.20 | 64.45 | 65.35 | ||||
| ✓ | ✓ | 64.43 | 69.29 | 64.43 | 71.40 | ||||
| ✓ | ✓ | 75.35 | 80.99 | 77.01 | 83.72 | ||||
| ✓ | ✓ | 75.28 | 82.77 | 76.93 | 86.91 | ||||
| ✓ | ✓ | 75.26 | 82.76 | 76.96 | 86.92 | ||||
| Test Set 1 | Test Set 2 | ||||
|---|---|---|---|---|---|
| O-Support | S-Projection | 1 Shot | 5 Shot | 1 Shot | 5 Shot |
| 61.44 | 57.33 | 63.17 | 58.60 | ||
| ✓ | 67.85 | 76.20 | 66.89 | 77.67 | |
| ✓ | 61.29 | 55.32 | 59.59 | 59.51 | |
| ✓ | ✓ | 75.28 | 82.77 | 76.93 | 86.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Lv, X.; Cai, J.; Guo, J.; Zhang, Y.; Qiu, X.; Wu, Y. Few-Shot SAR-ATR Based on Instance-Aware Transformer. Remote Sens. 2022, 14, 1884. https://doi.org/10.3390/rs14081884
Zhao X, Lv X, Cai J, Guo J, Zhang Y, Qiu X, Wu Y. Few-Shot SAR-ATR Based on Instance-Aware Transformer. Remote Sensing. 2022; 14(8):1884. https://doi.org/10.3390/rs14081884
Chicago/Turabian StyleZhao, Xin, Xiaoling Lv, Jinlei Cai, Jiayi Guo, Yueting Zhang, Xiaolan Qiu, and Yirong Wu. 2022. "Few-Shot SAR-ATR Based on Instance-Aware Transformer" Remote Sensing 14, no. 8: 1884. https://doi.org/10.3390/rs14081884