
Method for Identifying Litchi Picking Position Based on YOLOv5 and PSPNet


Abstract
:
1. Introduction
2. Materials and Methods
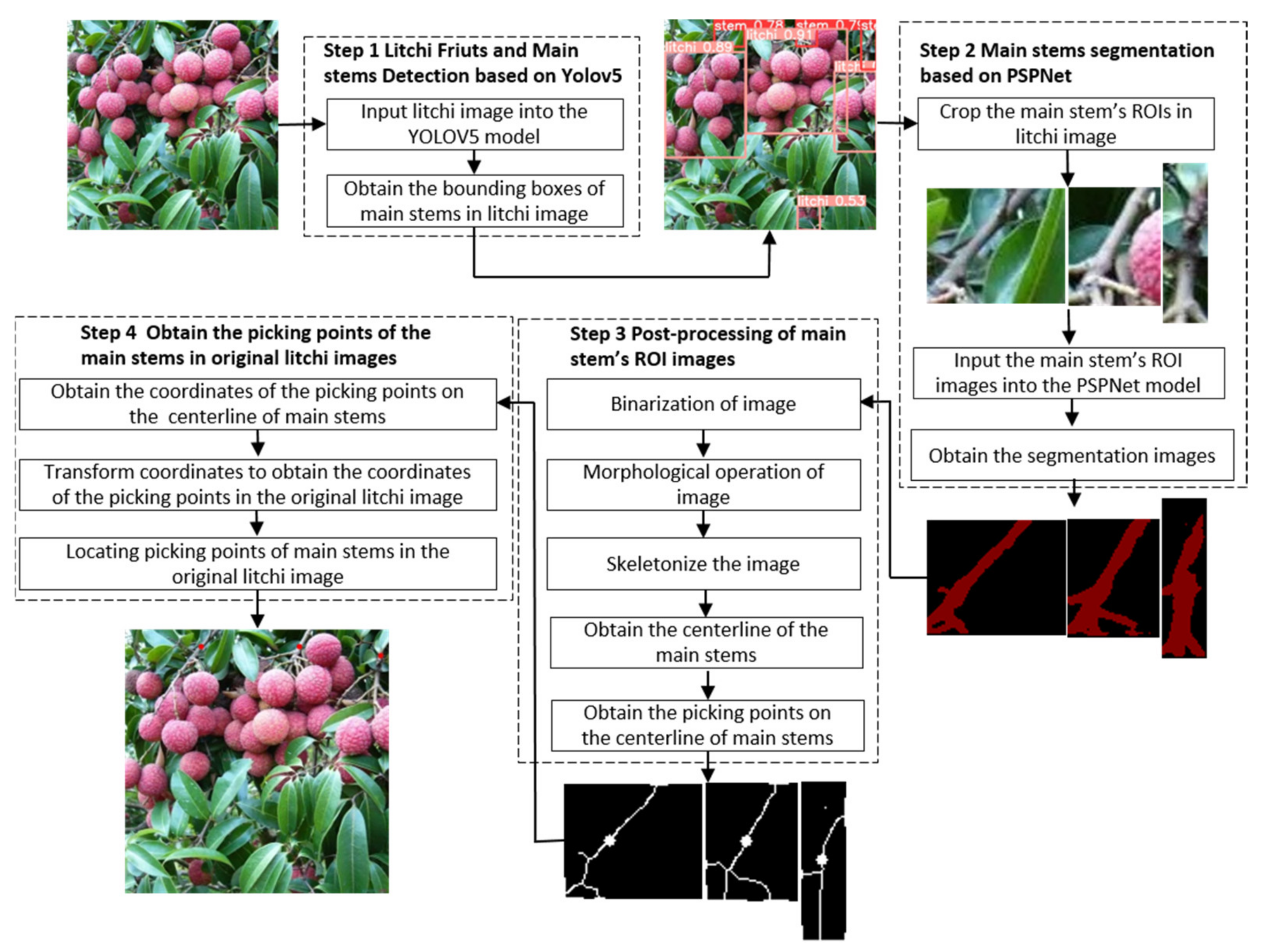
2.1. Overview of Acquisition Process of Picking Points of the Litchi Clusters
- (1)
- Step 1: Import the collected litchi image into the trained YOLOv5 model to detect the litchi fruits and main stems in the litchi image.
- (2)
- Step 2: According to the location information file of the litchi main stem detection boxes, extract the litchi main stem ROI images from the litchi image, and then import the extracted main stem ROI images into the trained PSPNet [25] semantic segmentation model, and perform semantic segmentation on the main stem ROI images.
- (3)
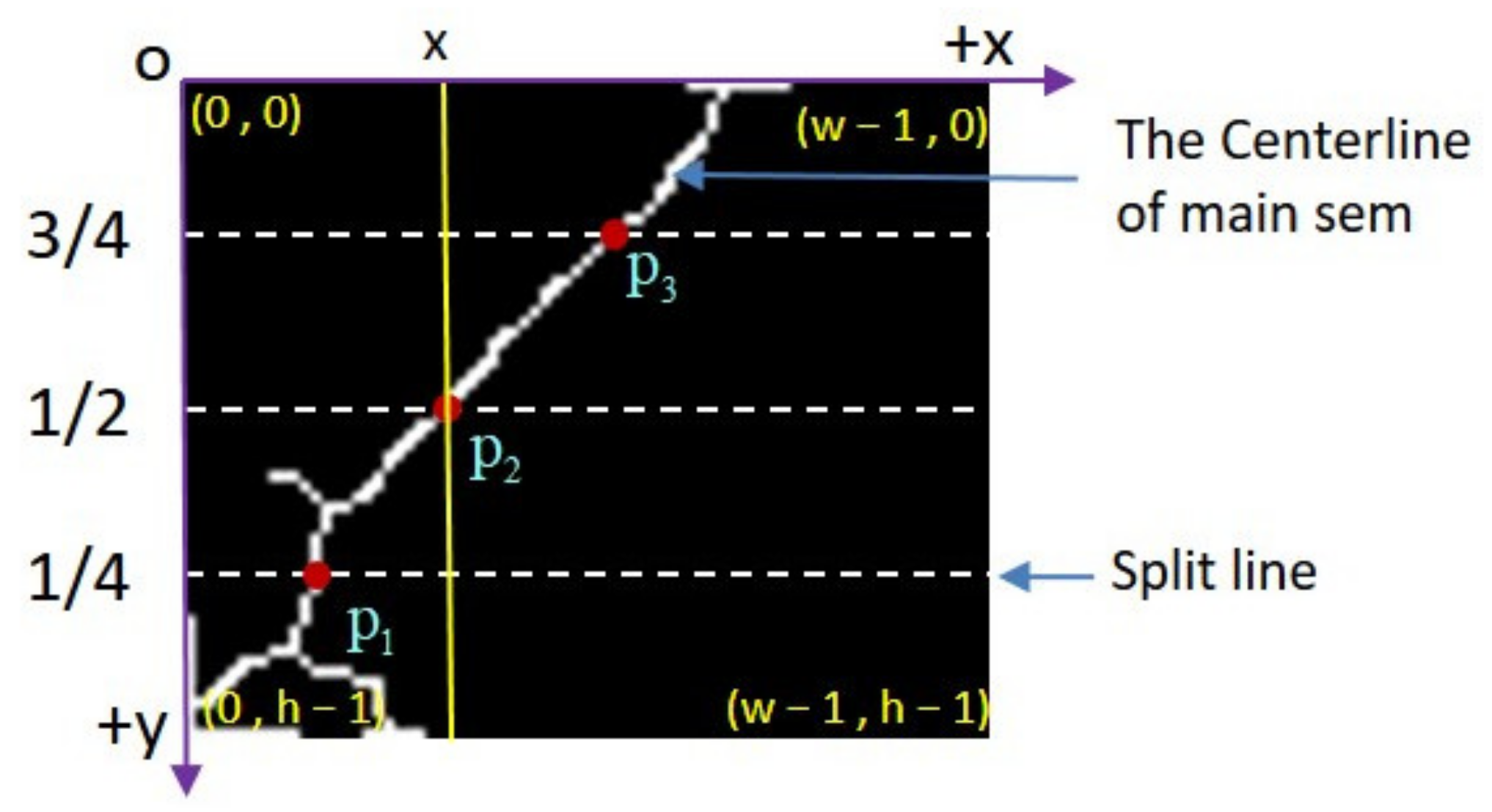
- Step 3: Binarize the segmented ROI image of the main stem, convert the ROI color image of the main stem into a binary image, and carry out a morphological opening operation on the binary image of the main stem, so as to eliminate the holes in the main stem, remove isolated small patches and smooth the surface of the main stem, and then skeletonize the main stem to extract the centerline of the main stem, Then select the picking point on the centerline of the main stem.
- (4)
- Step 4: Obtain the pixel coordinates of the picking point in the main stem ROI image, and convert the coordinates to obtain the pixel coordinates of the corresponding picking point in the original litchi string image. Then the specific position of the picking point in the original litchi image can be located according to the pixel coordinates of the picking point.
2.2. Image Acquisition
2.3. Experimental Environment
2.4. Algorithm for Detecting Litchi Cluster Fruit and Main Stem
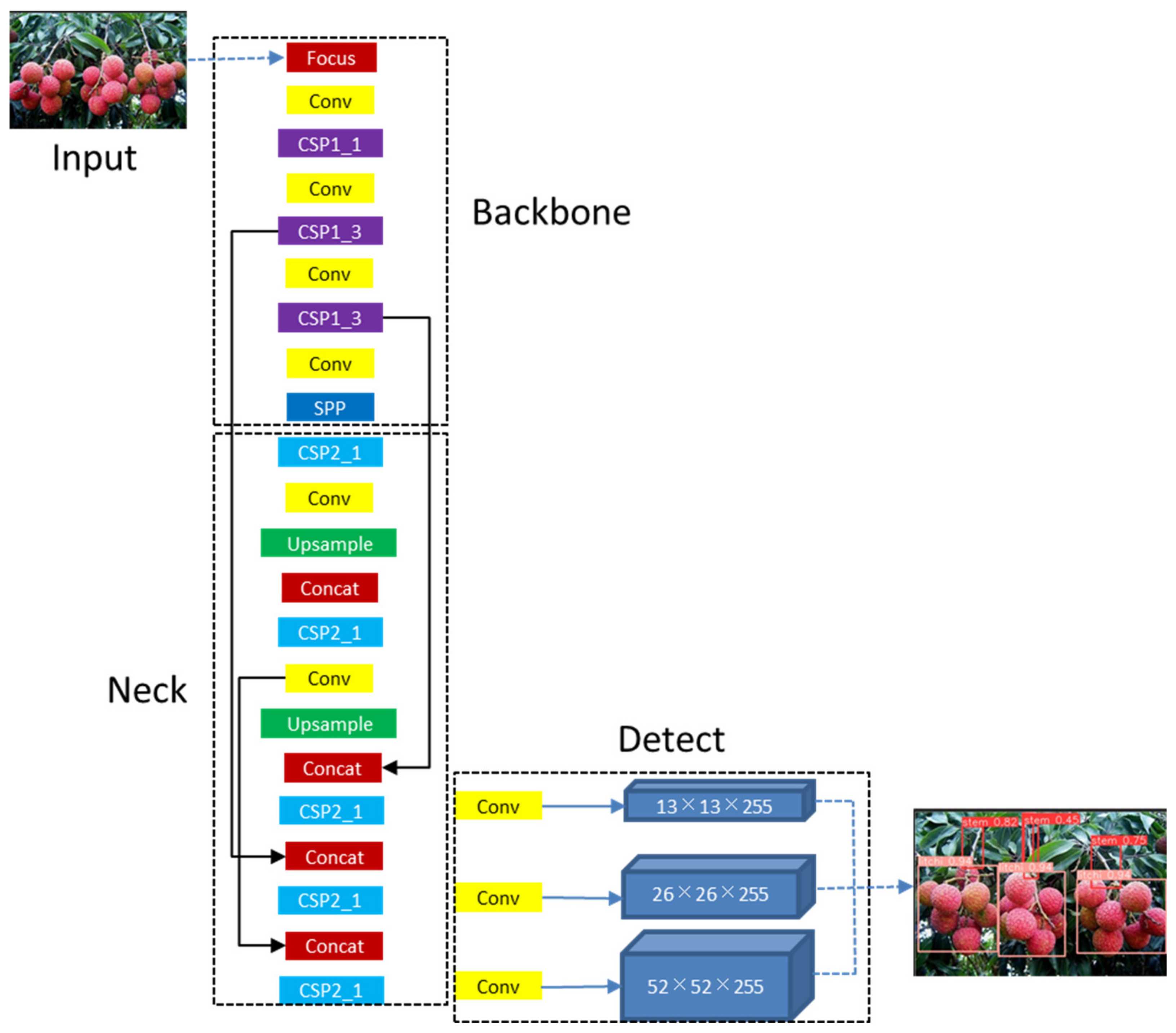
2.4.1. Network Structure of YOLOv5
2.4.2. Evaluation Index of Object Detection Model
2.4.3. Training of Litchi Fruit and Main Stem Detection Model
2.5. Semantic Segmentation Algorithm of Litchi Main Stem
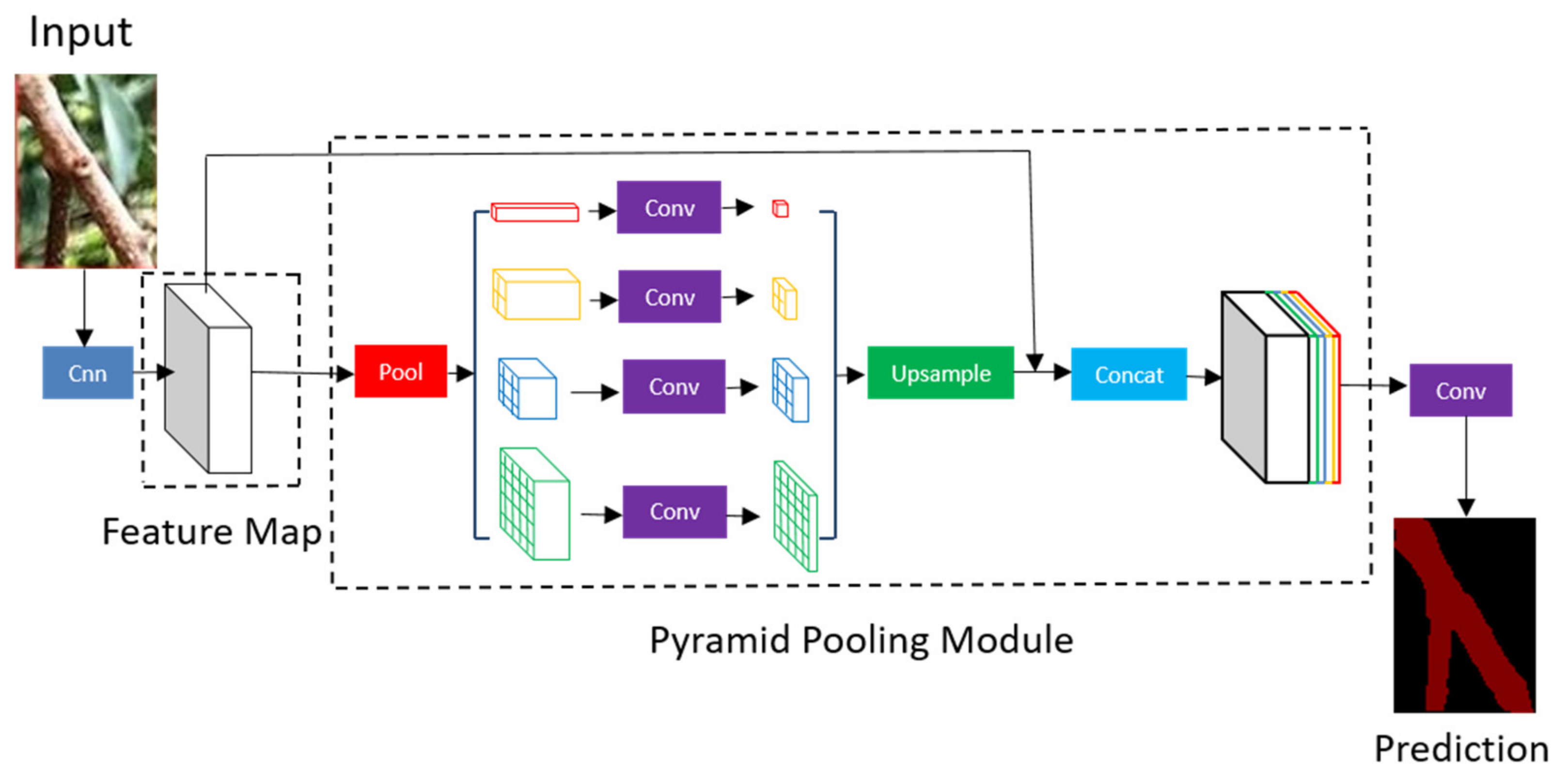
2.5.1. Network Structure of PSPNet
2.5.2. Evaluation Index of Semantic Segmentation Model
2.5.3. Training of Semantic Segmentation Model of Main Stem ROI Image
2.6. Semantic Segmentation Image Post-Processing Algorithm
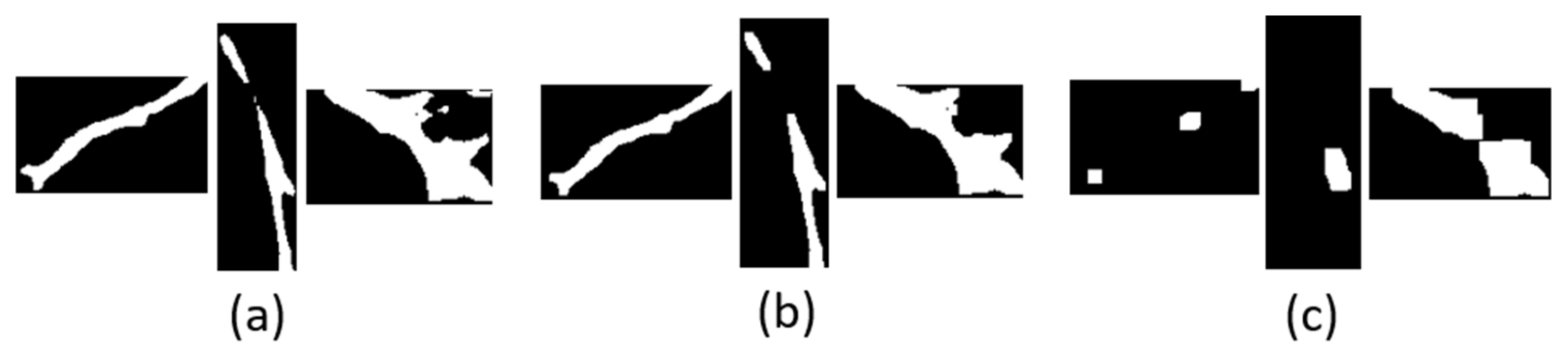
2.6.1. Morphological Open Operation Processing of Binary Graph of Main Stem ROI Image
2.6.2. Skeletonization of Main Stem
2.6.3. Location of the Picking Point of the Main Stem
3. Results
3.1. Detection Results of Litchi Fruit and Main Stem with Different Detection Models
3.2. Results of Semantic Segmentation of Main Stem ROI Image
3.3. Performance Evaluation of the Proposed Algorithm for Locating Litchi Picking Points
3.3.1. Location Results of Picking Points on the Main Stem of Litchi Cluster
3.3.2. Description of Manually Counting Picking Points
4. Discussion
4.1. Discussion on Detection Method of Picking Point
4.2. Some Limitations in Our Whole Work Should Be Discussed and Reduced
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Computer Code
References
- Huang, Y. 2018 China litchi Summit. World Trop. Agric. Inf. 2018, 56, 34. [Google Scholar]
- Zhu, Q.; Lu, R.; Lu, J.; Li, F. Research status and development trend of litchi picking machinery. For. Mach. Woodwork. Equip. 2021, 49, 11–19. [Google Scholar]
- Davidson, J.R.; Hohimer, C.J.; Mo, C.; Karkee, M. Dual robot coordination for apple harvesting. In Proceedings of the 2017 ASABE Annual International Meeting, Spokane, WA, USA, 16–19 June 2017. [Google Scholar]
- Liu, J.; Yuan, Y.; Gao, Y.; Tang, S.; Li, Z. Virtual model of grip-and-cut picking for simulation of vibration and falling of grape clusters. Trans. ASABE 2019, 62, 603–614. [Google Scholar] [CrossRef]
- Dai, N.; Xie, H.; Yang, X.; Zhan, K.; Liu, J. Recognition of cutting region for pomelo picking robot based on machine vision. In Proceedings of the 2019 ASABE Annual International Meeting, Boston, MA, USA, 7–10 June 2019. [Google Scholar] [CrossRef]
- Liang, C.; Xiong, J.; Zheng, Z.; Zhong, Z.; Li, Z.; Chen, S.; Yang, Z. A visual detection method for nighttime litchi fruits and fruiting stems. Comput. Electron. Agric. 2020, 169, 105192. [Google Scholar] [CrossRef]
- Xiong, J.; He, Z.; Lin, R.; Liu, Z.; Bu, R.; Yang, Z.; Peng, H.; Zou, X. Visual positioning technology of picking robots for dynamic litchi clusters with disturbance. Comput. Electron. Agric. 2018, 151, 226–237. [Google Scholar] [CrossRef]
- Xiong, J.; Lin, R.; Liu, Z.; He, Z.; Tang, L.; Yang, Z.; Zou, X. The recognition of litchi clusters and the calculation of picking point in a nocturnal natural environment. Biosyst. Eng. 2018, 166, 44–57. [Google Scholar] [CrossRef]
- Deng, J.; Li, J.; Zou, X. Extraction of litchi stem based on computer vision under natural scene. In Proceedings of the 2011 International Conference on Computer Distributed Control and Intelligent Environmental Monitoring, Changsha, China, 19–20 February 2011; pp. 832–835. [Google Scholar]
- Wang, C.; Zou, X.; Tang, Y.; Luo, L.; Feng, W. Localisation of litchi in an unstructured environment using binocular stereo vision. Biosyst. Eng. 2016, 145, 39–51. [Google Scholar] [CrossRef]
- Zhuang, J.; Hou, C.; Tang, Y.; He, Y.; Guo, Q.; Zhong, Z.; Luo, S. Computer vision-based localisation of picking points for automatic litchi harvesting applications towards natural scenarios. Biosyst. Eng. 2019, 187, 1–20. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Apolo-Apolo, O.; Martínez-Guanter, J.; Egea, G.; Raja, P.; Pérez-Ruiz, M. Deep learning techniques for estimation of the yield and size of citrus fruits using a UAV. Eur. J. Agron. 2020, 115, 126030. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Koirala, A.; Walsh, K.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Xiong, J.; Liu, Z.; Chen, S.; Liu, B.; Zheng, Z.; Zhong, Z.; Yang, Z.; Peng, H. Visual detection of green mangoes by an unmanned aerial vehicle in orchards based on a deep learning method. Biosyst. Eng. 2020, 194, 261–272. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, D.; Jia, W.; Ruan, C.; Tang, S.; Shen, T. A method of segmenting apples at night based on color and position information. Comput. Electron. Agric. 2016, 122, 118–123. [Google Scholar] [CrossRef]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. Deepfruits: A fruit detection system using deep neural networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [Green Version]
- Guo, A.; Zou, X.; Zou, H. Recognition on image of lychee fruits and their main fruit bearing based on twin-threshold method. Comput. Eng. Des. 2014, 35, 557–561. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhong, Z.; Xiong, J.; Zheng, Z.; Liu, B.; Liao, S.; Huo, Z.; Yang, Z. A method for litchi picking points calculation in natural environment based on main fruit bearing branch detection. Comput. Electron. Agric. 2021, 189, 106398. [Google Scholar] [CrossRef]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9157–9166. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Padilla, R.; Netto, S.L.; Da Silva, E.A. A survey on performance metrics for object-detection algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic understanding of scenes through the ade20k dataset. Int. J. Comput. Vis. 2019, 127, 302–321. [Google Scholar] [CrossRef] [Green Version]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Las Vegas, NV, USA, 27–30 June 2016, pp. 770–778.
- Theckedath, D.; Sedamkar, R. Detecting affect states using VGG16, ResNet50 and SE-ResNet50 networks. SN Comput. Sci. 2020, 1, 79. [Google Scholar] [CrossRef] [Green Version]
- Torrey, L.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Zhang, T.Y.; Suen, C.Y. A fast parallel algorithm for thinning digital patterns. Commun. ACM 1984, 27, 236–239. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Litchi Cluster | Number of Training Sets | Number of Test Sets | Total Number |
|---|---|---|---|
| Single cluster | 31 | 25 | 56 |
| Multiple cluster | 109 | 35 | 144 |
| Models | Precision | Recall | AP50 | 1 mAP50 | F1 |
|---|---|---|---|---|---|
| YOLOV5 | 84.44% | 75.25% | 72.52% | 79.60% | 0.80 |
| YOLOV4 | 78.43% | 39.60% | 49.85% | 66.22% | 0.53 |
| YOLOV3 | 75.32% | 57.43% | 65.55% | 75.30% | 0.65 |
| SSD | 92.86% | 25.74% | 54.32% | 70.26% | 0.40 |
| FRCN | 43.66% | 61.39% | 57.75% | 70.30% | 0.51 |
| Models | Precision | PA | IoU | 1 MIoU |
|---|---|---|---|---|
| PSPNet | 80.64% | 69.80% | 59.78% | 74.08% |
| U-Net | 83.58% | 64.22% | 57.02% | 72.61% |
| DeepLab_v3+ | 76.11% | 67.82% | 55.92% | 71.38% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, X.; Dong, J.; Lan, Y.; Zhu, H. Method for Identifying Litchi Picking Position Based on YOLOv5 and PSPNet. Remote Sens. 2022, 14, 2004. https://doi.org/10.3390/rs14092004
Qi X, Dong J, Lan Y, Zhu H. Method for Identifying Litchi Picking Position Based on YOLOv5 and PSPNet. Remote Sensing. 2022; 14(9):2004. https://doi.org/10.3390/rs14092004
Chicago/Turabian StyleQi, Xiaokang, Jingshi Dong, Yubin Lan, and Hang Zhu. 2022. "Method for Identifying Litchi Picking Position Based on YOLOv5 and PSPNet" Remote Sensing 14, no. 9: 2004. https://doi.org/10.3390/rs14092004
APA StyleQi, X., Dong, J., Lan, Y., & Zhu, H. (2022). Method for Identifying Litchi Picking Position Based on YOLOv5 and PSPNet. Remote Sensing, 14(9), 2004. https://doi.org/10.3390/rs14092004