1. Introduction
Remote sensing is the process of obtaining information about an object, area, or phenomenon through the analysis of data acquired by a measurement device that is physically separated from the object, area, or phenomenon itself [
1]. This process and its resultant information products have immense scientific, practical, and military value. An extension of this process, multimodal remote sensing, involves the use of multiple measurement devices to simultaneously collect various modalities of data. The motivation behind multimodal remote sensing is that a single acquisition modality rarely provides a complete understanding of the phenomenon under study [
2]. Whereas unimodal sensing is always limited by the acquisition mode’s disadvantages, the data provided by multimodal sensing are complementary and overcome individual mode disadvantages.
An example of the complementary aspect of using multiple modalities is in the combination of hyperspectral and lidar data. Hyperspectral imagery provides spatially organized spectral data. Each pixel represents the intensity of emittance or reflectance at a specific electromagnetic wavelength. Hundreds or even thousands of wavelengths are simultaneously imaged. This results in a data product with two spatial dimensions in and one wavelength dimension . On the other hand, lidar imagery provides spatially organized structural data. Each pixel or point represents, after some coordinate transformation, the height above ground of a specific point on an object at a given location in the scene. There are various collection approaches, but the general resulting data product is a point cloud represented as an unordered set of millions or billions of points with irregular spacing. Another common data representation is a 2D projection and discretization of the point cloud into a lidar digital surface map (DSM). This data product has two spatial dimensions where each pixel is the average height above the ground of points in the pixel’s area. Hyperspectral and lidar data are then complementary in their spectral and structural content.
A common exploitation task of such multimodal hyperspectral and lidar data is semantic segmentation. Unlike classification which aims to apply a label to all pixels in an image collectively, semantic segmentation aims to apply a label to each pixel individually. The resulting semantic map from such exploitation can inform various decisions tasks such as land use land cover (LULC) [
3,
4,
5], railway center line reconstruction [
6], vegetation mapping [
7], and landslide detection [
8]. While these works focus their efforts towards the joint processing of multimodal hyperspectral and lidar data, they utilize methods developed for unimodal processing. This adoption is important when working with multimodal data sets because the methods for unimodal processing still exhibit meaningful performance. For example, the recent work presented by Li et al. [
9] processes only the hyperspectral component of the IEEE Geoscience and Remote Sensing Society 2018 Data Fusion Contest data set (GRSS18) [
10]. Its two-staged energy functional optimization feature extraction method, a traditional image processing technique, predicts a reasonably accurate (82.16%) semantic map. This represents an ∼2% improvement over the winner of the contest Xu et al. [
10] who achieved 80.8% accuracy while utilizing both modalities. On the other hand, Sukhanov et al. [
11] process only the multispectral lidar component of the same data set. Their method of an ensemble of neural networks also produces a considerable result (69.01%) even in light of utilizing the less information dense lidar DSM. By embracing methods implemented in the unimodal processing domain, the joint processing of multimodal data sets for semantic segmentation can be greatly improved.
A considerable subset of multimodal processing methods towards this task are convolutional neural network (CNN) based and implement feature level fusion. These approaches borrow from the advancements made for the unimodal processing of image type data. Mohla et al. [
12] and Wang et al. [
13] present two remarkably similar CNN-based approaches FusAtNet and MAHiDFNet. Both networks implement self-attention mechanisms [
14] during single modal processing along with shared/cross attention during multimodal processing. FusAtNet specifically relies on the work of Mou et al. [
15] who present a method of spectral attention for the unimodal processing of hyperspectral data. Whereas FusAtNet employs a single layer of feature fusion, MAHiDFNet implements multiple localized fusion layers (dense fusion [
13]) within the classification stage of the network. These fusion CNN-based methods achieve high accuracy (∼90%) against the GRSS 2013 data set [
16].
While these recent works are high-performing they may still offer two potential areas of improvement. First, no previous works utilize and ingest the lidar modality in point cloud format. Point-cloud data are more information-dense than those of derived lidar DSMs and contain a richer variety of raw features from which structural information may be obtained. Second, all previous works implement either a single layer or a relatively localized region of feature fusion within their architectures. This presents the challenge of selecting where the fusion operation occurs. If this takes place too early in the network, the usefulness of the unimodal features suffers; if it takes place too late in the network, the usefulness of multimodal and fused features suffers. As Piramanayagam et al. [
17] and Karpathy et al. [
18] described, a composite style architecture overcomes the challenge of selecting this single fusion location by incorporating multiple layers of fusion throughout the network.
Following from the motivation of utilizing unimodal processing advances in the multimodal processing domain, we look towards the ever-increasing number of methods for ingestion and learning from point cloud data [
19]. Many unique ideas vie for attention within the field and convolution-based methods are specifically of interest. Provided these types of approaches are motivated by pixel-based convolutions, they provide a natural fit into a CNN-based fusion network. Of specific interest is the kernel point convolution (KPConv) introduced by Thomas et al. [
20]. KPConv identified that during conventional pixel convolution, the features are localized by pixels. This idea was extended to allow features to be localized by points. Thus, as each pixel may localize many spectral features KPConv learns many structural features localized at each point location. The comparison between the pixel and point convolution provided by Thomas et al. is shown in
Figure 1. KPConv internally represents features as the original point location and feature vector at each point location. This must be done to account for the irregular spacing and unordered nature of point cloud data. Pixel-based CNNs rely on the discrete structure of pixel-based imagery to organize the features learned at each pixel location. Thus, to generate multimodal features and learn fused features from hyperspectral and lidar data, the transformation must be implemented to make the internal feature representations compatible for concatenation-based feature fusion. In
Section 2.2.3, we introduce such a transformation for the generation of multimodal features.
In summary, our work makes the following claim. The ingestion and processing of lidar point cloud data with point-based CNNs will result in more useful learned features leading to a higher performance as measured by pixel accuracy. This will hold in both the unimodal and multimodal network cases. To gather evidence supporting these claims, we provide a proof of concept which implements the topics discussed as potential areas for improvement, resulting in the following contributions:
Introduction of two composite style multimodal fusion network architectures. The first ingests hyperspectral and lidar DSM data. The second ingests hyperspectral and lidar point cloud data. This establishes a comparative performance between the unimodal lidar feature learning from pixel and point convolutional layers within multimodal networks. The hyperspectral and lidar processing sections of these networks are trained independently, and as a result, this also establishes a comparative performance between the unimodal lidar feature learning from the pixel and point convolutional layers in the unimodal network case.
Introduction of a novel point-to-pixel feature discretization method. The method conserves both local and global spatial alignment between features enabling natural concatenation-based fusion between the pixel and point-based convolutional neural networks. This method presents a solution to the challenge of generating multimodal features within a multimodal pixel and point convolutional network.
3. Results
The pixel accuracy metric results of all network trainings performed are provided in
Table 3. These values were calculated from the combined test sample predictions depicted in
Figure 9. With respect to the unimodal networks, the relative under performance of the lidar processing networks in terms of pixel accuracy in relation to H2D is attributed to the lower information content in their input compared to the hyperspectral data; a hyperspectral image with 786 k individual spectral pixels, versus 40–90 k lidar points (each with an x, y, and z coordinate) versus a lidar DSM with 16,384 pixels. As predicted, the L3D network outperformed the L2D network, and did so utilizing roughly half the number of parameters. This result is attributed to L3D’s utilization of point-based convolutional layers (KPConv) and the ingestion of raw point cloud data. KPConv provides greater flexibility in the filters it can learn because of its ability to alter the influence of point features based on their spatial distance (
in
Figure 1 right) to filter (kernel) points.
Both of the multimodal fusion networks outperformed all of the unimodal networks for all but the human path class. This result is directly attributable to their ability to fuse information from both modalities of data. We provide further evidence of this ability in the next subsection. Contrary to initial conjecture, the H2D_L2D outperformed H2D_L3D by nearly 5%. As further conjecture with regard to this result, it is attributed to H2D_L3D’s utilization of the point feature discretization method and usage of L3D’s point features. As noted, a side-effect of the discretization method is that it loses some feature information through the final reduction operation applied to combine the point feature vectors occupying the same target grid cell. Furthermore, the point features provided from L3D were generated based on the semantic labeling transferred from the 2D to 3D domain which is an underdetermined process. Both of these are noted as areas for future investigation in the subsequent section.
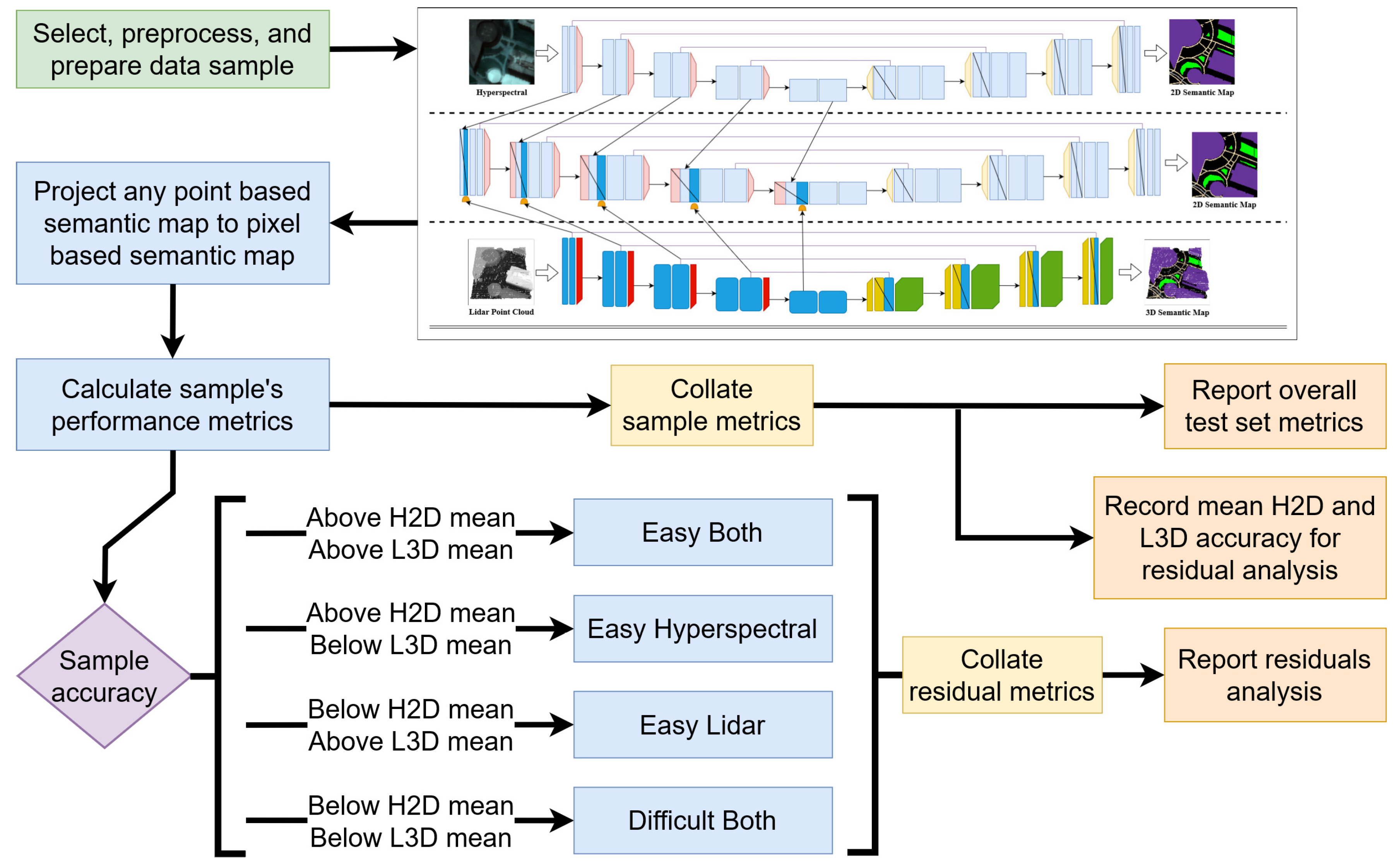
3.1. Residuals Analysis
To further elicit the performance gains of the multimodal models, a more granular metric was warranted. A residuals analysis of the test sample accuracies for all models with respect to the mean test sample accuracy from the H2D and L3D models was performed. First, the mean accuracy for the H2D and L3D models were computed and all test samples were categorized by whether they fall above or below each mean value. Samples falling above the mean value for a given model were categorized as easier to predict (“easy”) for that model and those falling below the mean were categorized as harder to predict (“hard”) for that model.
Figure 10 depicts a visualization of the process using histograms to identify the easier and harder samples, which also depicts the easiest and hardest to predict samples for either model.
This categorization process resulted in four distinct categories of multimodal test samples based on the combination of easiness or hardness with respect to both H2D and L3D models:
Easy Hyperspectral (EH): Contains samples that were easy for H2D to predict accurately but hard for L3D to predict accurately.
Easy Lidar (EL): Contains samples that were hard for H2D to predict accurately but easy for L3D to predict accurately.
Easy Both (EB): Contains samples that were easy for both H2D and L3D to predict accurately.
Difficult Both (DB): Contains samples that were hard for both H2D and L3D to predict accurately.
Figure 11 provides a matrix depicting the categorization process and statistics for the test data set samples. The 112 total test samples consisted of 23 EH, 30 EL, 44 EB, and 15 DB sample types. By computing and comparing the mean accuracy of each model against these sample types, it is possible to further outline the performance gains multimodal models made over unimodal models.
3.2. Residuals Analysis Results
In
Table 3, it was shown that the unimodal networks achieved the lowest pixel accuracies while the multimodal networks achieved the highest pixel accuracies. However, this does not provide direct evidence that this increased performance is a result of actually fusing information from both modalities rather than more efficiently exploiting a single modality. To investigate this claim, we present the mean test sample accuracy for each model against the four identified sample types as described in
Section 3.1 in
Table 4. Unsurprisingly, the unimodal networks achieved higher mean test sample accuracy against sample types which are categorized as easy for their given input modality. Consequently, the unimodal networks achieved lower accuracy against samples types which are categorized as hard for their given input modality. For example, the H2D model achieved a higher EH accuracy than both lidar-based unimodal networks L2D and L3D. The lidar-based networks achieved a higher EL accuracy than the hyperspectral-based unimodal network H2D. Together, all three unimodal networks achieved a high EB and low DB accuracy. Thus, the scheme segregates test samples based on the subjective difficulty, as viewed by the unimodal networks collectively.
In
Table 4, we find that the multimodal networks collectively outperformed all unimodal networks for the EB and DB test sample types. Furthermore, to some extent, both networks performed either on par with or outperformed all unimodal networks on the EH and EL sample types. These findings provide strong evidence that both multimodal models made their performance gains over unimodal models by fusing information. Note that the unimodal and multimodal architectures share the same components and technology, are provided the same set of test data, and the multimodal networks only have access to weight-frozen unimodal network features. Thus, the only difference between the unimodal and multimodal networks that accounts for the increased mean DB test sample type accuracy is the multimodal models’ ability to fuse information. With all other metrics held constant, there is no other explanation for this increased accuracy against the hardest-to-classify sample type. Had it been the case that the multimodal models only saw improvement in either the EH, EL, or EB sample types, this would indicate that they simply learned a more efficient means of exploiting the corresponding data modality; this could then be traced back to their increased parameter count.
4. Conclusions
The main research goal of this work was the implementation of two proof of concept network architectures which exhibited the strengths of previous neural network-based approaches while improving upon weaknesses. As a result of the composite style architecture, the multimodal networks were able to generate both low- and high-level unimodal and multimodal features without making a trade-off for either. Furthermore, it was assumed that the ingestion of point cloud data and the use of point convolution-based layers would result in a more performant model in both the single and multimodal case. We found this assumption to hold in the unimodal case, but failed for the multimodal case. We are left with the claim that this is a result of the proposed point-to-pixel feature discretization method and its lossy process of discretizing localized groups of point features. This claim is open to future study. In the reported results, we found that regardless of this assumption failing, both multimodal models were able to outperform their unimodal counterparts. Notably, they were able to achieve anywhere from 10 to 40% higher mean accuracy towards hard-to-classify samples (DB) while maintaining performance across other sample types (EH, EL, EB). This result not only provides strong evidence that the composite style architecture generated useful features but also that the act of jointly processing the multimodal data can provide a considerable performance increase over singular processing.
While these results are promising and outlining the novel contributions of this work, future work is still needed. The proposed architectures utilized some of the least complex convolutional network layer technologies for both the pixel and point data. A great deal of research exists into more complex layer types and architectures [
20,
29,
30,
31] which may provide additional benefits to both the single and multimodal architectures. It was noted that the data set for this work was modified to produce a more idealized form to separate the effects of more challenging data scenarios such as differing co-, geo-, and temporal registrations and differing viewing geometries and resolutions. Furthermore, while the data set was adequately sized to characterize the network architectures, a larger data set may provide an opportunity to observe the networks’ performance against a larger and more diverse problem instance. The proposed point-to-pixel discretization method needs further study. Many possible alterations exist which may improve its efficacy. For example, the imputation of zero-valued cells during the discretization process may not have yielded meaningful results against this data set, though it may be necessary when working with differing resolutions between modalities. Finally, as noted in
Section 1, many works exist which make great effort towards unimodal semantic segmentation. The methods described in these works may be borrowed to further increase the performance of the unimodal network streams. Specifically, the dimensionality reduction and band selection from the hyperspectral modality may provide a considerable pruning of redundant information. This would have a great effect when working with hyperspectral data sets that have hundreds or even thousands of spectral bands.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}