
Hyperspectral Image Super-Resolution Method Based on Spectral Smoothing Prior and Tensor Tubal Row-Sparse Representation



Abstract
:1. Introduction
1.1. Fusion Based on Pan-Sharpening
1.2. Fusion Based on Matrix Decomposition
1.3. Fusion Based on Deep Learning
1.4. Fusion Based on Tensor Decomposition
- We approach the fusion problem in a patch-wise way instead of directly processing the images. Specifically, to fully exploit the spatial self-similarity of HSI, we use a clustering method on the source image and construct multiple nonlocal tensor patches. On this basis, we apply the tensor sparse representation model to the reconstruction of each nonlocal tensor patch. In this way, the efficiency of our method is improved.
- Furthermore, based on the tensor sparse representation model, we focus more on the properties of hyperspectral images. To make the reconstructed image closer to the original properties of HSI, we impose a spectral smoothing constraint on the tensor dictionaries to promote the spectral smoothness of reconstructed images. Meanwhile, it was noted that we use the norm [46] to characterize the tubal row-sparsity exhibited by the coefficient tensor.
- We perform effective convex approximation for each term of the model and use ADMM [47] to optimize the solution of the model. Comparative experiments conducted on multiple simulated data sets and one real data set validate that the proposed method is superior to the current advanced competitors.
2. Materials and Methods
2.1. Notions and Definitions
- is equivalent to, thus, we have,
2.2. Preliminaries
2.2.1. Problem Formulation
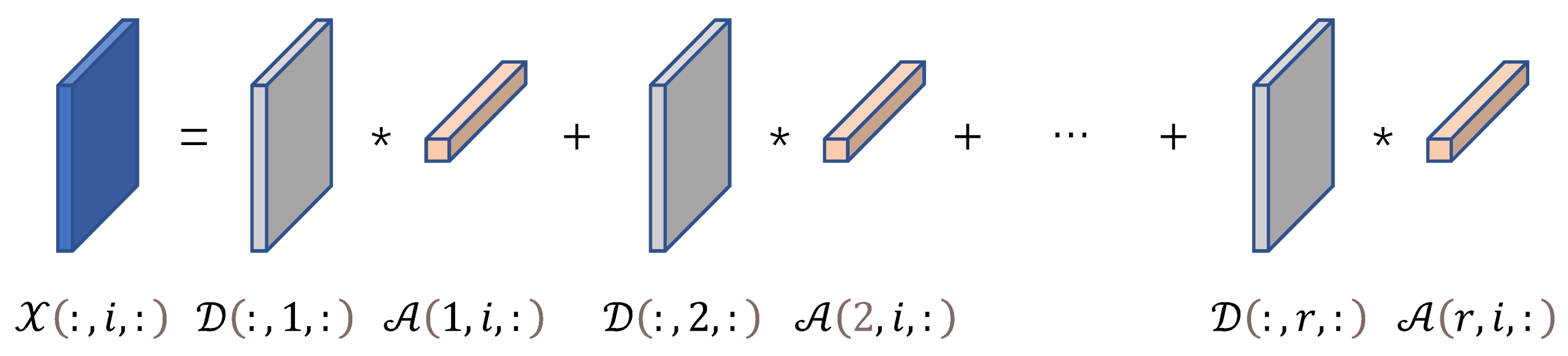
2.2.2. Tensor Sparse Representation Based on t-Product
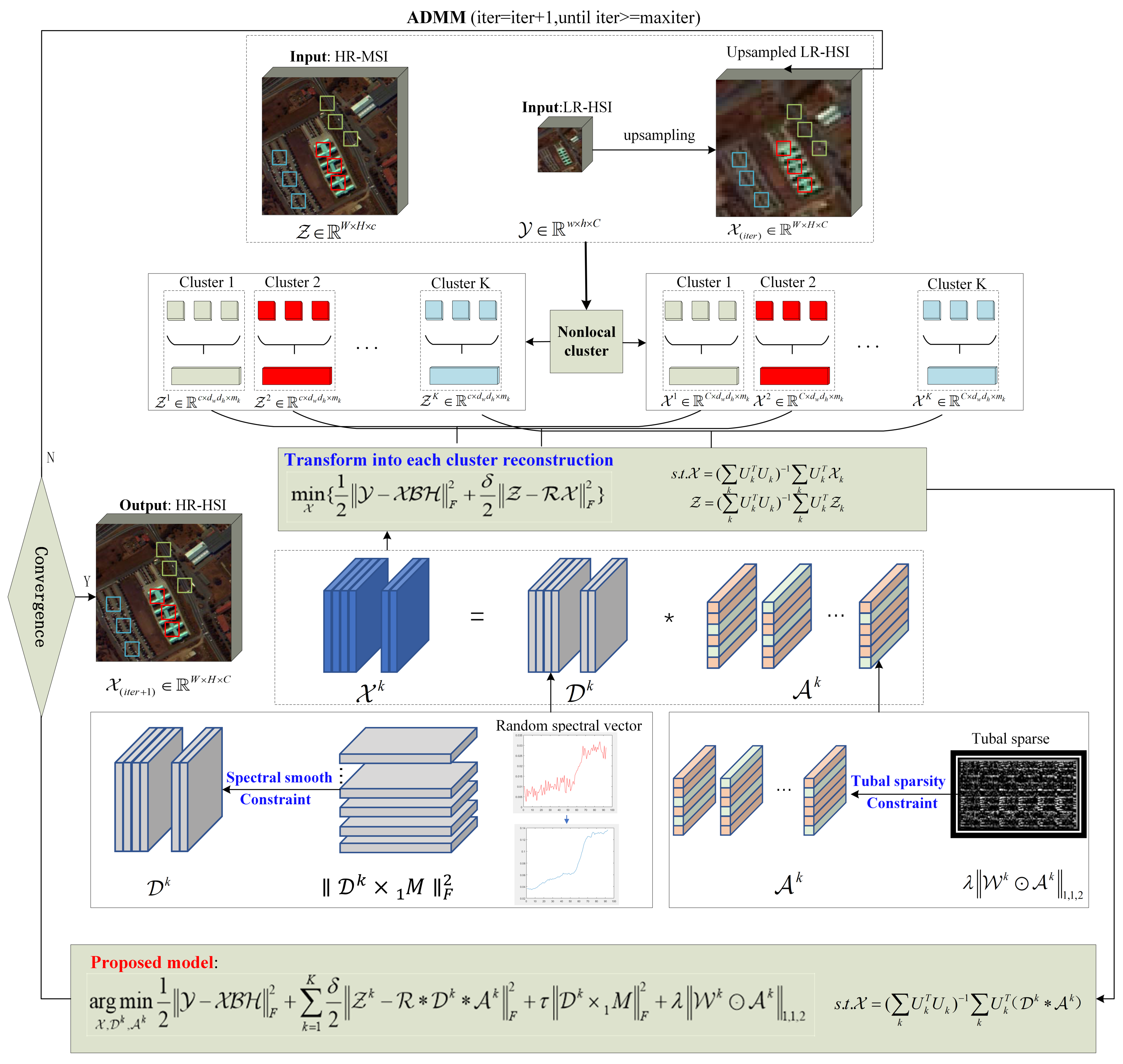
2.3. Proposed Method
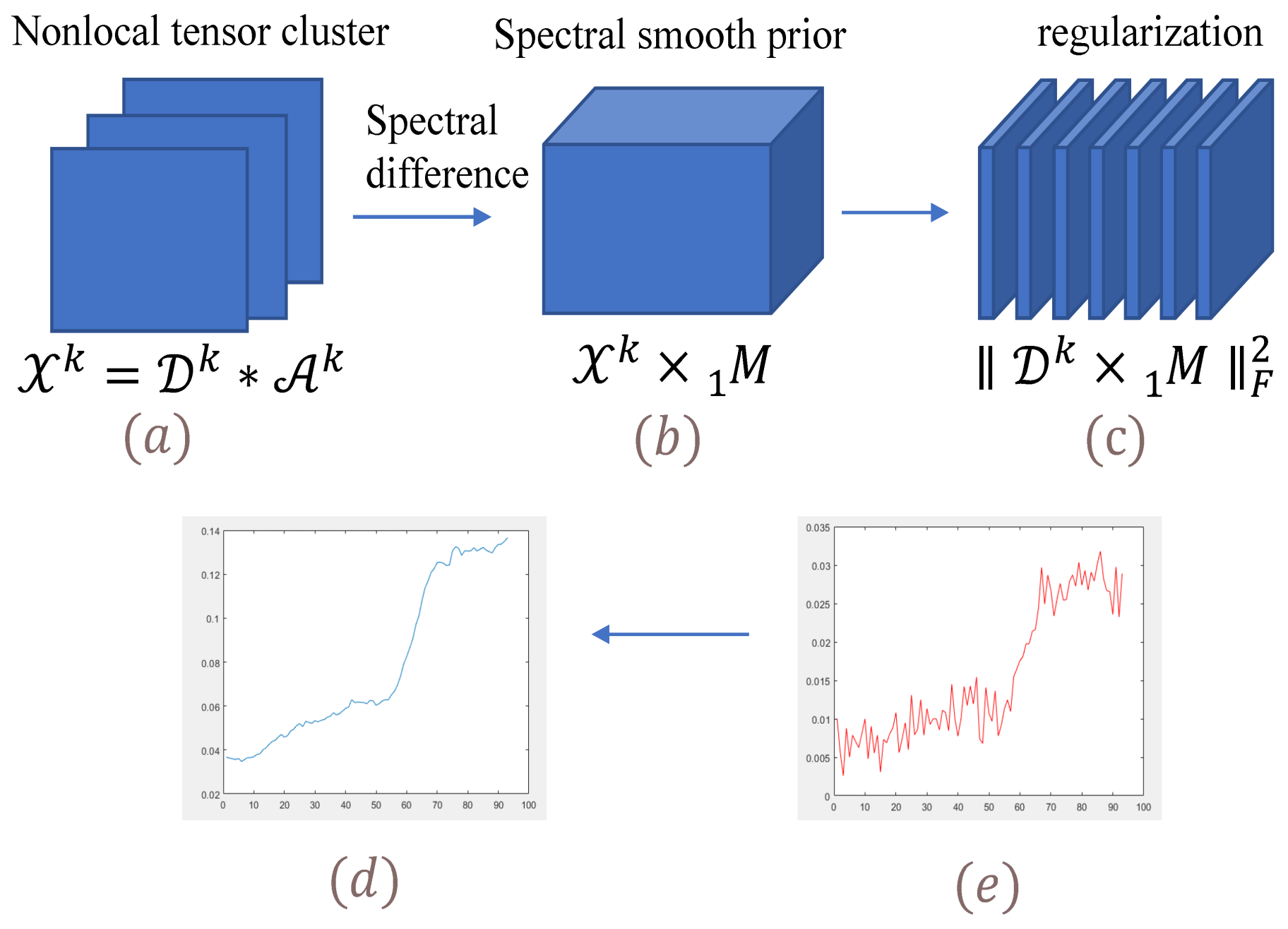
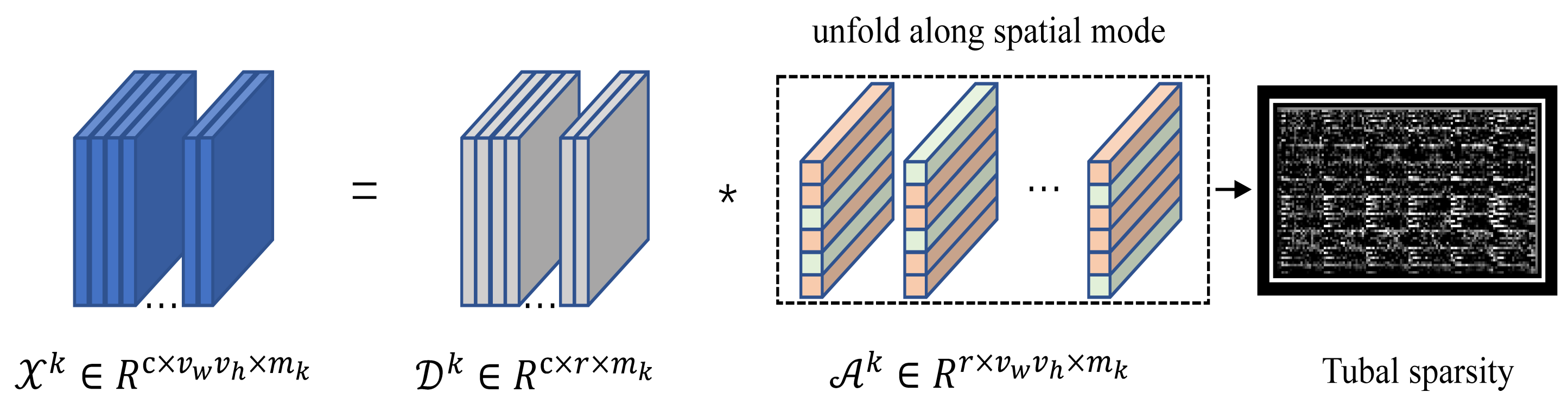
2.3.1. Nonlocal Cluster Tensor
2.3.2. Spectral Smooth Prior on Nonlocal Cluster Tensor
2.3.3. Tubal Sparsity Constraint with Sparse Representation Model for Nonlocal Cluster Tensor
3. Optimization Algorithm
- (1)
- Update
- (2)
- Update
- (3)
- Update
- (4)
- Update
- (5)
- Update
- (6)
- Update Lagrange multipliers
| Algorithm 1 The proposed SSTSR method for HSI super-resolution. |
|
4. Results
4.1. Synthetic Dataset
4.2. Quantitative Metrics
4.3. Compared Methods
4.4. Experimental Results on Synthetic Datasets
- (1)
- Visual effects of reconstructed images. Figure 5, Figure 6 and Figure 7 list the fusion results of different methods on three datasets, i.e., PU, WDC, and HOS, respectively. To deepen the visual effect, we pseudo-color the experimental results while magnifying the representative local information. In addition, with the aid of ground truth, the comparison of residual images is supplemented, in which the dark blue residual image indicates better reconstruction effect. As can be seen from Figure 5, Figure 6 and Figure 7, the results of CSTF, LTMR, LTTR, and NLSTF all show color distortion compared with the ground truth. From the residual image, the result of our method is bluer and smoother. It fully verifies that our proposed method can obtain images with better spatial structure details.
- (2)
- Spectral curve and spectral curve residual. In addition, we also compare the spectral quality of the reconstructed images. Figure 8a shows the spectral curve of the reconstructed image at pixel (90, 90) of the PU dataset and the residual spectral curve of the reconstructed image with the ground truth. Similarly, Figure 8b,c also compare the spectral curves at the pixel (100, 200) of the WDC and the pixel (100, 100) of the HOS, respectively. It is clear from Figure 8 that the spectral curves of the reconstructed images of our method on the three datasets are closer to the ground truth spectral curves, and the residual curves are also closer to the zero-horizontal line. This also demonstrates the effectiveness of the spectral smoothing constraints imposed in our method. Compared with other methods, our proposed SSTSR method can obtain images with higher spectral quality.
- (3)
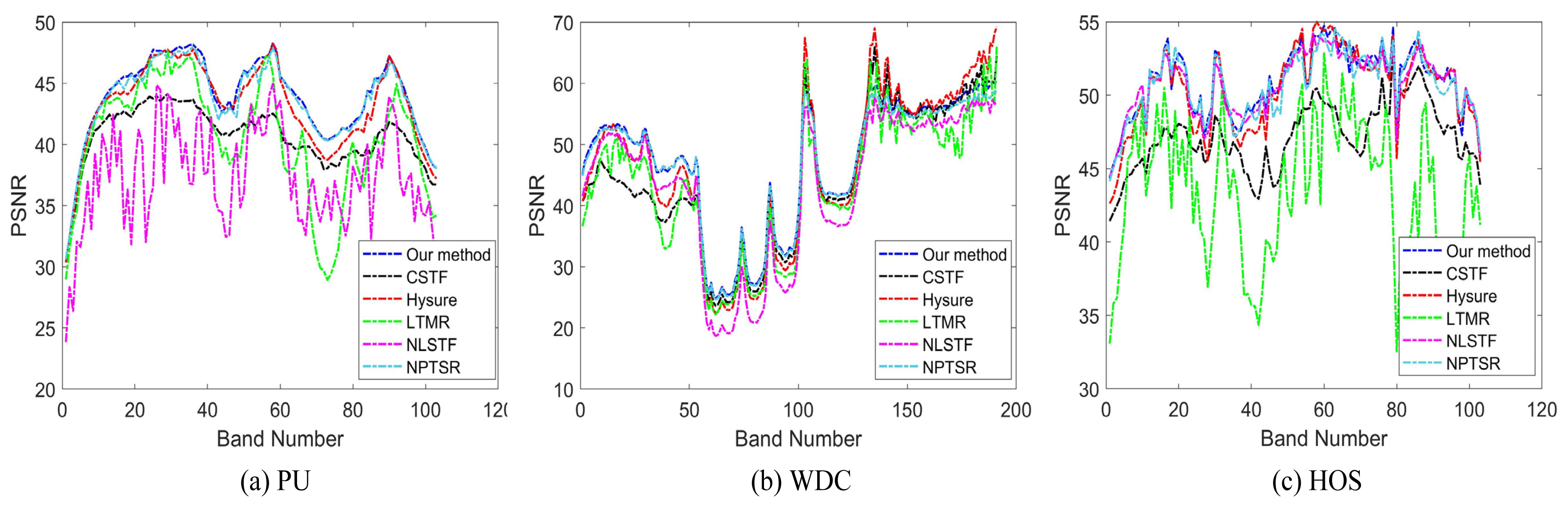
- Quantitative indicators and time complexity comparison. As can be seen from Table 1, on the PU dataset, our method achieves a leading position in all indicators, and on the WDC dataset, although the three indicators of SAM, CC, and ERGAS slightly lag behind Hysure and NPTSR, our PSNR, SSIM, UIQI values are still leading, and on the HOS dataset, all indicators of our method once again rank first. It needs to be mentioned that all methods have similar SSIM values on HOS dataset, so the results of this indicator are not listed. Taken together, the average PSNR of our method on the three datasets is 0.63 dB, 2.85 dB, 4.53 dB, 9.84 dB, 2.33 dB, 0.33 dB higher than Hysure, CSTF, LTMR, LTTR, NLSTF, NPTSR, respectively, which verifies the superiority of our method. In addition, we also give a comparison of PSNR in each band for all methods on the three datasets in Figure 9. As can be seen from Figure 9, our method outperforms other methods in most bands. Besides, the measurement of the ERGAS index indicates the spectral quality of the reconstructed image and the smaller the value, the better the spectral quality. The ERGAS value of our method is also state-of-the-art on three datasets. Although the designed regular terms can improve the performance of the method, they also consume more computing time. Our method has no advantage in the comparison of time complexity, so in future work, we will focus on optimizing our method to reduce the time complexity.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Index | Best Values | Hysure [17] | CSTF [37] | LTMR [42] | LTTR [41] | NLSTF [38] | NPTSR [45] | SSTSR |
|---|---|---|---|---|---|---|---|---|---|
| PU | PSNR | +∞ | 43.26 | 40.76 | 40.71 | 35.53 | 40.70 | 43.55 | 43.84 |
| SAM | 0 | 2.5971 | 2.7189 | 3.7590 | 5.6304 | 2.8811 | 2.4149 | 2.4080 | |
| CC | 1 | 0.9946 | 0.9943 | 0.9868 | 0.9769 | 0.9915 | 0.9950 | 0.9951 | |
| ERGAS | 0 | 1.1519 | 1.2062 | 1.6003 | 2.3986 | 1.5421 | 1.1248 | 1.1071 | |
| SSIM | 1 | 0.9379 | 0.9308 | 0.9053 | 0.8261 | 0.9390 | 0.9438 | 0.9444 | |
| UIQI | 1 | 0.9257 | 0.9165 | 0.8896 | 0.8017 | 0.9271 | 0.9328 | 0.9335 | |
| TIME | 0 | 43 | 37 | 220 | 176 | 20 | 280 | 371 | |
| WDC | PSNR | +∞ | 46.05 | 44.64 | 43.32 | 36.77 | 43.28 | 46.43 | 46.81 |
| SAM | 0 | 6.6306 | 6.0177 | 6.8458 | 8.2989 | 10.5458 | 5.0079 | 5.0167 | |
| CC | 1 | 0.9177 | 0.9115 | 0.8417 | 0.6580 | 0.8167 | 0.9097 | 0.9150 | |
| ERGAS | 0 | 5.7105 | 7.4531 | 12.6333 | 30.8024 | 10.6421 | 9.0399 | 6.4304 | |
| SSIM | 1 | 0.7302 | 0.6652 | 0.5595 | 0.3564 | 0.6451 | 0.7576 | 0.7703 | |
| UIQI | 1 | 0.6797 | 0.7113 | 0.5006 | 0.3289 | 0.6105 | 0.7192 | 0.7286 | |
| TIME | 0 | 43 | 48 | 210 | 352 | 25 | 489 | 673 | |
| HOS | PSNR | +∞ | 50.24 | 47.19 | 43.81 | 39.63 | 50.46 | 50.49 | 50.80 |
| SAM | 0 | 1.4110 | 1.2761 | 3.4890 | 5.1802 | 1.3703 | 1.2914 | 1.2746 | |
| CC | 1 | 0.9980 | 0.9981 | 0.9890 | 0.9779 | 0.9982 | 0.9982 | 0.9983 | |
| ERGAS | 0 | 0.6727 | 0.6437 | 1.7494 | 2.2988 | 0.6246 | 0.6173 | 0.6111 | |
| SSIM | 1 | - | - | - | - | - | - | - | |
| UIQI | 1 | 0.9819 | 0.9810 | 0.9289 | 0.8562 | 0.9831 | 0.9838 | 0.9835 | |
| TIME | 0 | 43 | 35 | 80 | 174 | 25 | 271 | 341 |
| Dataset | Method | PSNR | SAM | ERGAS | SSIM |
|---|---|---|---|---|---|
| PU (260 × 340 × 103) | HAMMFN [54] | 40.8632 | 2.5308 | 1.8052 | 0.9776 |
| SSTSR | 44.0746 | 2.3627 | 1.1156 | 0.9428 | |
| Dataset | Method | PSNR | SAM | UIQI | SSIM |
| PU (610 × 340 × 103) | CNN-Fus [55] | 43.0170 | 2.2350 | 0.9920 | 0.9870 |
| SSTSR | 43.6980 | 2.4149 | 0.9932 | 0.9607 |
| Constraints | PSNR | SAM | ERGAS | CC | UIQI | SSIM |
|---|---|---|---|---|---|---|
| Spectral Smooth | 46.57 | 5.1505 | 6.6625 | 0.9131 | 0.7243 | 0.7621 |
| ine Tubal Sparsity | 46.50 | 5.0497 | 8.7855 | 0.9076 | 0.7164 | 0.7511 |
| ine Both Constraints | 46.81 | 5.0167 | 6.3404 | 0.9150 | 0.7286 | 0.7703 |
4.5. Experimental Results on Real Dataset
5. Discussion
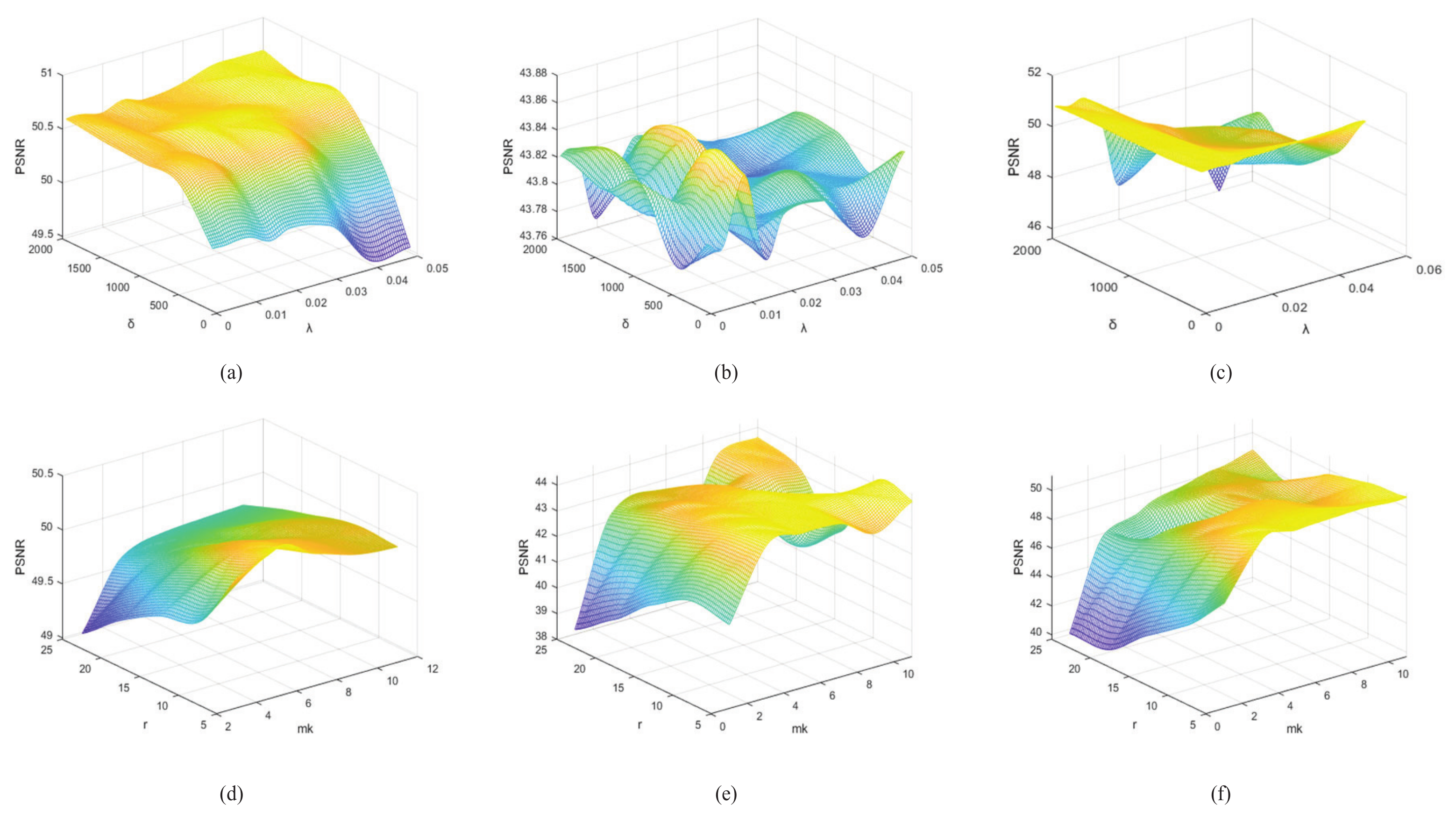
5.1. Parameters Selection
5.2. Convergence Behavior
5.3. Effectiveness of the Spectral Smooth Prior and Tubal Sparsity Constraint
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, L.; He, C. Hyperspectral Image Mixed Denoising Using Difference Continuity-Regularized Nonlocal Tensor Subspace Low-Rank Learning. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Drumetz, L.; Meyer, T.R.; Chanussot, J.; Bertozzi, A.L.; Jutten, C. Hyperspectral Image Unmixing With Endmember Bundles and Group Sparsity Inducing Mixed Norms. IEEE Trans. Image Process. 2019, 28, 3435–3450. [Google Scholar] [CrossRef] [PubMed]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral-Spatial Feature Tokenization Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- He, N.; Paoletti, M.E.; Haut, J.M.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Feature Extraction with Multiscale Covariance Maps for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 755–769. [Google Scholar] [CrossRef]
- Song, X.; Zou, L.; Wu, L. Detection of Subpixel Targets on Hyperspectral Remote Sensing Imagery Based on Background Endmember Extraction. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2365–2377. [Google Scholar] [CrossRef]
- Xu, Q.; Li, B.; Zhang, Y.; Ding, L. High-Fidelity Component Substitution Pansharpening by the Fitting of Substitution Data. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7380–7392. [Google Scholar] [CrossRef]
- Jiao, J.; Wu, L. Image Restoration for the MRA-Based Pansharpening Method. IEEE Access 2020, 8, 13694–13709. [Google Scholar] [CrossRef]
- Leung, Y.; Liu, J.; Zhang, J. An Improved Adaptive Intensity–Hue–Saturation Method for the Fusion of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2014, 11, 985–989. [Google Scholar] [CrossRef]
- Duran, J.; Buades, A. Restoration of Pansharpened Images by Conditional Filtering in the PCA Domain. IEEE Geosci. Remote Sens. Lett. 2019, 16, 442–446. [Google Scholar] [CrossRef] [Green Version]
- Restaino, R.; Dalla Mura, M.; Vivone, G.; Chanussot, J. Context-Adaptive Pansharpening Based on Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2017, 55, 753–766. [Google Scholar] [CrossRef] [Green Version]
- Restaino, R.; Vivone, G.; Addesso, P.; Chanussot, J. A Pansharpening Approach Based on Multiple Linear Regression Estimation of Injection Coefficients. IEEE Geosci. Remote Sens. Lett. 2020, 17, 102–106. [Google Scholar] [CrossRef]
- Vivone, G.; Marano, S.; Chanussot, J. Pansharpening: Context-Based Generalized Laplacian Pyramids by Robust Regression. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6152–6167. [Google Scholar] [CrossRef]
- Dong, W.; Liang, J.; S, X. Saliency Analysis and Gaussian Mixture Model-Based Detail Extraction Algorithm for Hyperspectral Pansharpening. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5462–5476. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, J.; Li, Y.; Guo, J.; Wu, X.; Chanussot, J. Hyperspectral Pansharpening Using Deep Prior and Dual Attention Residual Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8059–8076. [Google Scholar] [CrossRef]
- Huck, A.; Guillaume, M.; Blanc-Talon, J. Minimum Dispersion Constrained Nonnegative Matrix Factorization to Unmix Hyperspectral Data. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2590–2602. [Google Scholar] [CrossRef]
- Yokoya, N.; Yairi, T.; Iwasaki, A. Coupled Nonnegative Matrix Factorization Unmixing for Hyperspectral and Multispectral Data Fusion. IEEE Trans. Geosci. Remote Sens. 2012, 50, 528–537. [Google Scholar] [CrossRef]
- Simões, M.; Bioucas-Dias, J.; Almeida, L.; Chanussot, J. A Convex Formulation for Hyperspectral Image Superresolution via Subspace-Based Regularization. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3373–3388. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Wang, M.; Yang, S. Multispectral and Hyperspectral Image Fusion Based on Group Spectral Embedding and Low-Rank Factorization. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1363–1371. [Google Scholar] [CrossRef]
- Akhtar, N.; Shafait, F.; Mian, A. Bayesian sparse representation for hyperspectral image super resolution. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3631–3640. [Google Scholar] [CrossRef]
- Dong, W.; Fu, F.; Shi, G.; Cao, X.; Wu, J.; Li, G.; Li, X. Hyperspectral Image Super-Resolution via Non-Negative Structured Sparse Representation. IEEE Trans. Image Process. 2016, 25, 2337–2352. [Google Scholar] [CrossRef]
- Han, X.; Wang, J.; Shi, B.; Zheng, Y.; Chen, Y. Hyper-spectral Image Super-resolution Using Non-negative Spectral Representation with Data-Guided Sparsity. In Proceedings of the 2017 IEEE International Symposium on Multimedia (ISM), 11–13 December 2017; pp. 500–506. [Google Scholar] [CrossRef]
- Han, X.; Yu, J.; Xue, J.H.; Sun, W. Hyperspectral and Multispectral Image Fusion Using Optimized Twin Dictionaries. IEEE Trans. Image Process. 2020, 29, 4709–4720. [Google Scholar] [CrossRef]
- Han, X.; Shi, B.; Zheng, Y. Self-Similarity Constrained Sparse Representation for Hyperspectral Image Super-Resolution. IEEE Trans. Image Process. 2018, 27, 5625–5637. [Google Scholar] [CrossRef] [PubMed]
- Wei, Q.; Bioucas-Dias, J.; Dobigeon, N.; Tourneret, J. Hyperspectral and Multispectral Image Fusion Based on a Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3658–3668. [Google Scholar] [CrossRef] [Green Version]
- Ye, Q.; Huang, P.; Zhang, Z.; Zheng, Y.; Fu, L.; Yang, W. Multiview Learning With Robust Double-Sided Twin SVM. IEEE Trans. Cybern. 2021, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Xue, J.; Zhao, Y.Q.; Bu, Y.; Liao, W.; Chan, J.C.W.; Philips, W. Spatial-Spectral Structured Sparse Low-Rank Representation for Hyperspectral Image Super-Resolution. IEEE Trans. Image Process. 2021, 30, 3084–3097. [Google Scholar] [CrossRef]
- Sun, L.; Wu, F.; He, C.; Zhan, T.; Liu, W.; Zhang, D. Weighted Collaborative Sparse and L1/2 Low-Rank Regularizations With Superpixel Segmentation for Hyperspectral Unmixing. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Palsson, F.; Sveinsson, J.; Ulfarsson, M. Multispectral and Hyperspectral Image Fusion Using a 3-D-Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 639–643. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Huang, W.; Wang, Q.; Li, X. SSR-NET: Spatial–Spectral Reconstruction Network for Hyperspectral and Multispectral Image Fusion. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5953–5965. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.; Chan, J.W. Hyperspectral and Multispectral Image Fusion via Deep Two-branches Convolutional Neural Network. Remote Sens. 2018, 10, 800. [Google Scholar] [CrossRef] [Green Version]
- Wei, W.; Nie, J.; Li, Y.; Zhang, L.; Zhang, Y. Deep Recursive Network for Hyperspectral Image Super-Resolution. IEEE Trans. Comput. Imaging 2020, 6, 1233–1244. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, B.; Lu, R.; Zhang, H.; Liu, H.; Varshney, P.K. FusionNet: An Unsupervised Convolutional Variational Network for Hyperspectral and Multispectral Image Fusion. IEEE Trans. Image Process. 2020, 29, 7565–7577. [Google Scholar] [CrossRef]
- Hu, J.; Tang, Y.; Fan, S. Hyperspectral Image Super Resolution Based on Multiscale Feature Fusion and Aggregation Network With 3-D Convolution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5180–5193. [Google Scholar] [CrossRef]
- Zheng, K.; Gao, L.; Liao, W.; Hong, D.; Zhang, B.; Cui, X.; Chanussot, J. Coupled Convolutional Neural Network With Adaptive Response Function Learning for Unsupervised Hyperspectral Super Resolution. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2487–2502. [Google Scholar] [CrossRef]
- He, C.; Sun, L.; Huang, W.; Zhang, J.; Jeon, B. TSLRLN: Tensor Subspace Low-Rank Learning with Non-local Prior for Hyperspectral Image Mixed Denoising. Signal Process. 2021, 184, 108060. [Google Scholar] [CrossRef]
- Li, S.; Dian, R.; Fang, L.; Bioucas-Dias, J. Fusing Hyperspectral and Multispectral Images via Coupled Sparse Tensor Factorization. IEEE Trans. Image Process. 2018, 27, 4118–4130. [Google Scholar] [CrossRef] [PubMed]
- Dian, R.; Li, S.; Fang, L.; Lu, T.; Bioucas-Dias, J. Nonlocal Sparse Tensor Factorization for Semiblind Hyperspectral and Multispectral Image Fusion. IEEE Trans. Cybern. 2020, 50, 4469–4480. [Google Scholar] [CrossRef]
- Wan, W.; Guo, W.; Huang, H.; Liu, J. Nonnegative and Nonlocal Sparse Tensor Factorization-Based Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8384–8394. [Google Scholar] [CrossRef]
- Kanatsoulis, C.I.; Fu, X.; Sidiropoulos, N.D.; Ma, W.K. Hyperspectral Super-Resolution: A Coupled Tensor Factorization Approach. IEEE Trans. Signal Process. 2018, 66, 6503–6517. [Google Scholar] [CrossRef] [Green Version]
- Dian, R.; Li, S.; Fang, L. Learning a Low Tensor-Train Rank Representation for Hyperspectral Image Super-Resolution. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2672–2683. [Google Scholar] [CrossRef]
- Dian, R.; Li, S. Hyperspectral Image Super-Resolution via Subspace-Based Low Tensor Multi-Rank Regularization. IEEE Trans. Image Process. 2019, 28, 5135–5146. [Google Scholar] [CrossRef]
- Xu, H.; Qin, M.; Chen, S.; Zheng, Y.; Zheng, J. Hyperspectral-Multispectral Image Fusion via Tensor Ring and Subspace Decompositions. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8823–8837. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Martin, C.D. Factorization Strategies for Third-order Tensors. Linear Algebra Its Appl. 2011, 435, 641–658. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Wu, Z.; Chanussot, J.; Wei, Z. Nonlocal Patch Tensor Sparse Representation for Hyperspectral Image Super-Resolution. IEEE Trans. Image Process. 2019, 28, 3034–3047. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Aeron, S. Denoising and Completion of 3D Data via Multidimensional Dictionary Learning. arXiv 2015, arXiv.1512.09227. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Braman, K.; Hao, N.; Hoover, R.C. Third-order Tensors as Operators on Matrices: A Theoretical and Computational Framework with applications in imaging. SIAM J. Matrix Anal. Appl. 2013, 34, 148–172. [Google Scholar] [CrossRef] [Green Version]
- Ram, I.; Elad, M.; I, C. Image Processing Using Smooth Ordering of its Patches. IEEE Trans. Image Process. 2013, 22, 2764–2774. [Google Scholar] [CrossRef] [Green Version]
- Ye, Q.; Yang, J.; Liu, F.; Zhao, C.; Ye, N.; Yin, T. L1-Norm Distance Linear Discriminant Analysis based on an Effective Iterative Algorithm. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 114–129. [Google Scholar] [CrossRef]
- Ye, Q.; Zhao, H.; Li, Z.; Yang, X.; Gao, S.; Yin, T.; Ye, N. L1-Norm Distance Minimization-Based Fast Robust Twin Support Vector k -Plane Clustering. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 4494–4503. [Google Scholar] [CrossRef]
- Liu, L.; Peng, G.; Wang, P.; Zhou, S.; Wei, Q.; Yin, S.; Wei, S. Energy-and Area-efficient Recursive-conjugate-gradient-based MMSE detector for Massive MIMO Systems. IEEE Trans. Signal Process. 2020, 68, 573–588. [Google Scholar] [CrossRef]
- Yokoya, N.; Grohnfeldt, C.; Chanussot, J. Hyperspectral and Multispectral Data Fusion: A comparative review of the recent literature. IEEE Geosci. Remote Sens. Mag. 2017, 5, 29–56. [Google Scholar] [CrossRef]
- Xu, S.; Amira, O.; Liu, J.; Zhang, C.X.; Zhang, J.; Li, G. HAM-MFN: Hyperspectral and Multispectral Image Multiscale Fusion Network With RAP Loss. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4618–4628. [Google Scholar] [CrossRef]
- Dian, R.; Li, S.; Kang, X. Regularizing Hyperspectral and Multispectral Image Fusion by CNN Denoiser. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1124–1135. [Google Scholar] [CrossRef] [PubMed]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, L.; Cheng, Q.; Chen, Z. Hyperspectral Image Super-Resolution Method Based on Spectral Smoothing Prior and Tensor Tubal Row-Sparse Representation. Remote Sens. 2022, 14, 2142. https://doi.org/10.3390/rs14092142
Sun L, Cheng Q, Chen Z. Hyperspectral Image Super-Resolution Method Based on Spectral Smoothing Prior and Tensor Tubal Row-Sparse Representation. Remote Sensing. 2022; 14(9):2142. https://doi.org/10.3390/rs14092142
Chicago/Turabian StyleSun, Le, Qihao Cheng, and Zhiguo Chen. 2022. "Hyperspectral Image Super-Resolution Method Based on Spectral Smoothing Prior and Tensor Tubal Row-Sparse Representation" Remote Sensing 14, no. 9: 2142. https://doi.org/10.3390/rs14092142
APA StyleSun, L., Cheng, Q., & Chen, Z. (2022). Hyperspectral Image Super-Resolution Method Based on Spectral Smoothing Prior and Tensor Tubal Row-Sparse Representation. Remote Sensing, 14(9), 2142. https://doi.org/10.3390/rs14092142