

Off-Road Drivable Area Detection: A Learning-Based Approach Exploiting LiDAR Reflection Texture Information

Abstract
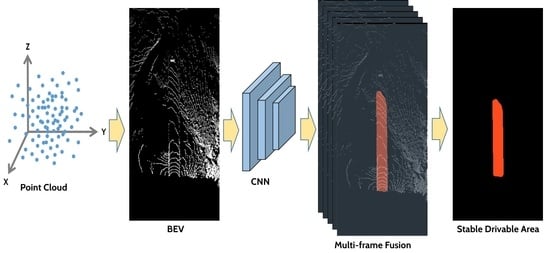
:
1. Introduction
2. Related Works
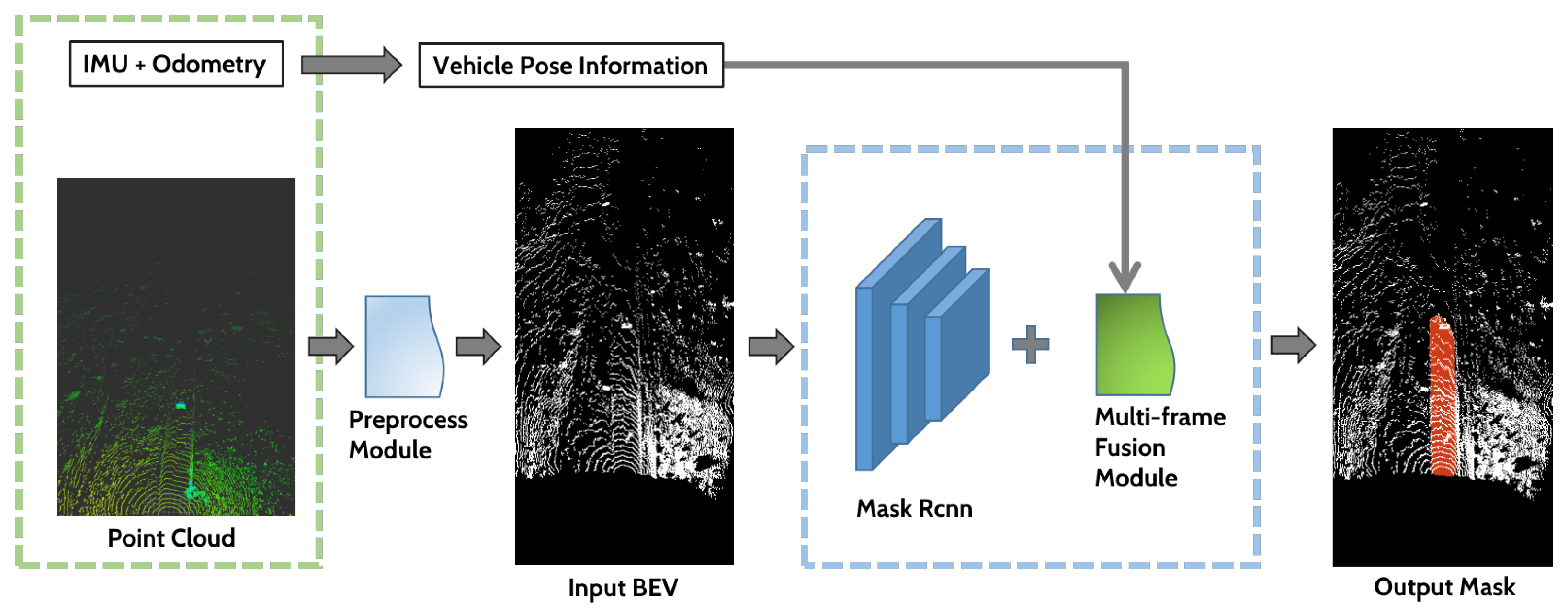
3. Methodology
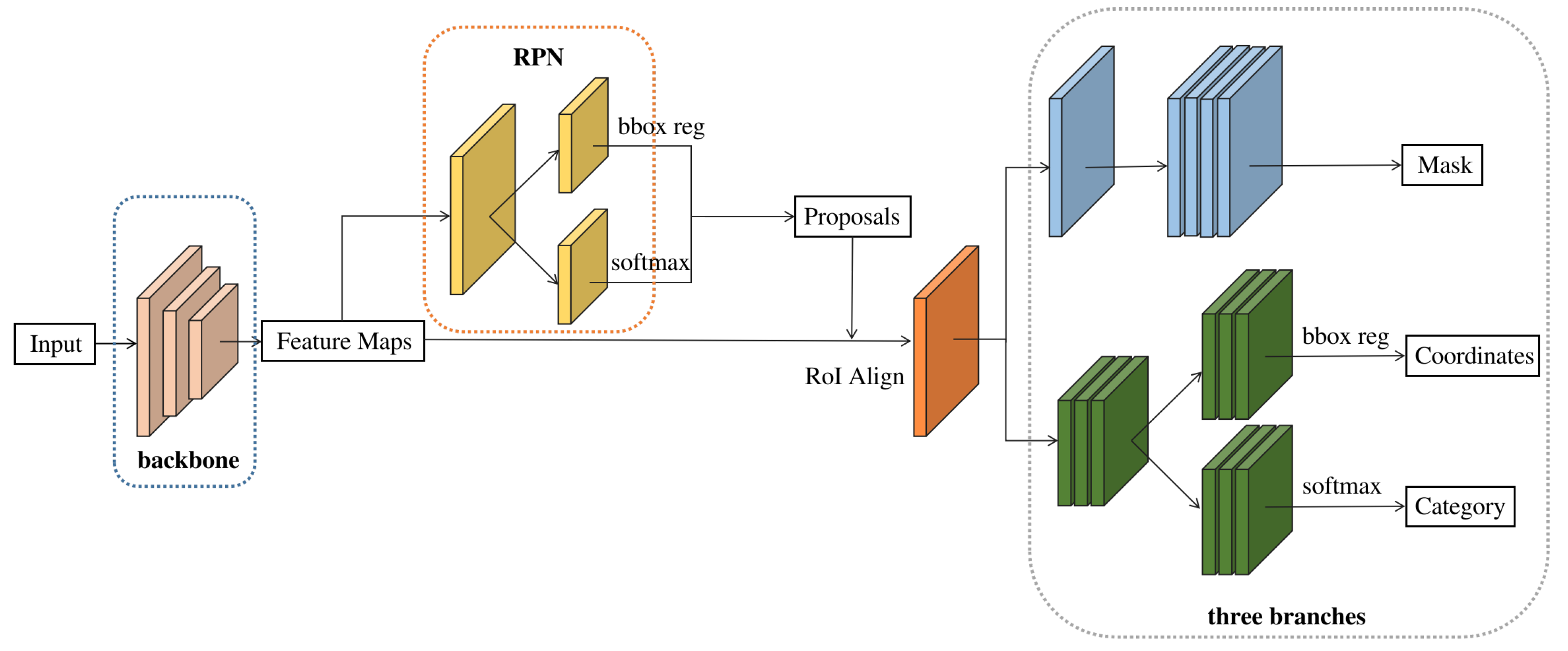
3.1. Network Architecture
3.2. Dataset Preparation
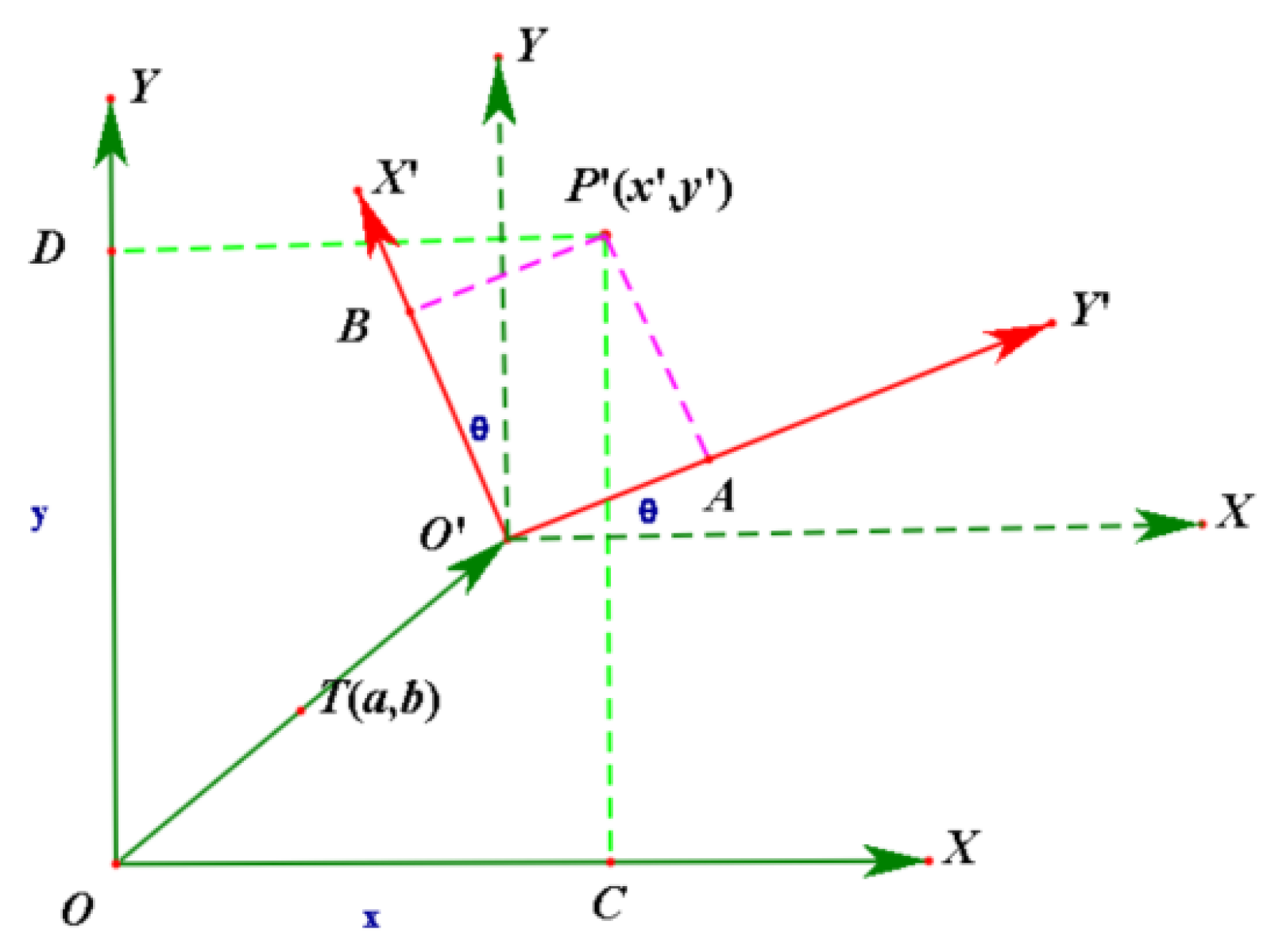
3.3. Multi-Frame Fusion
4. Experimental Results
4.1. Evaluation Metrics
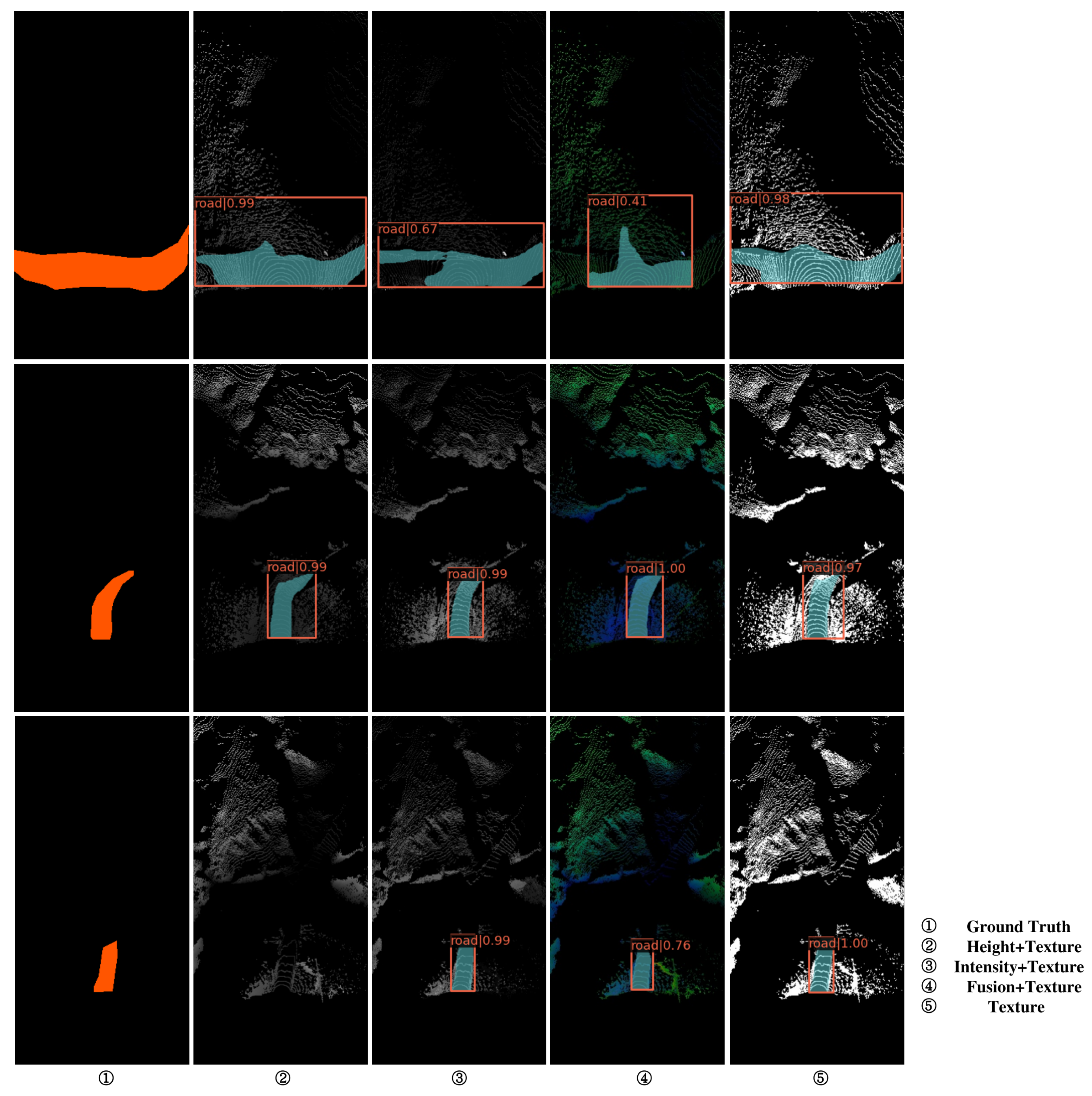
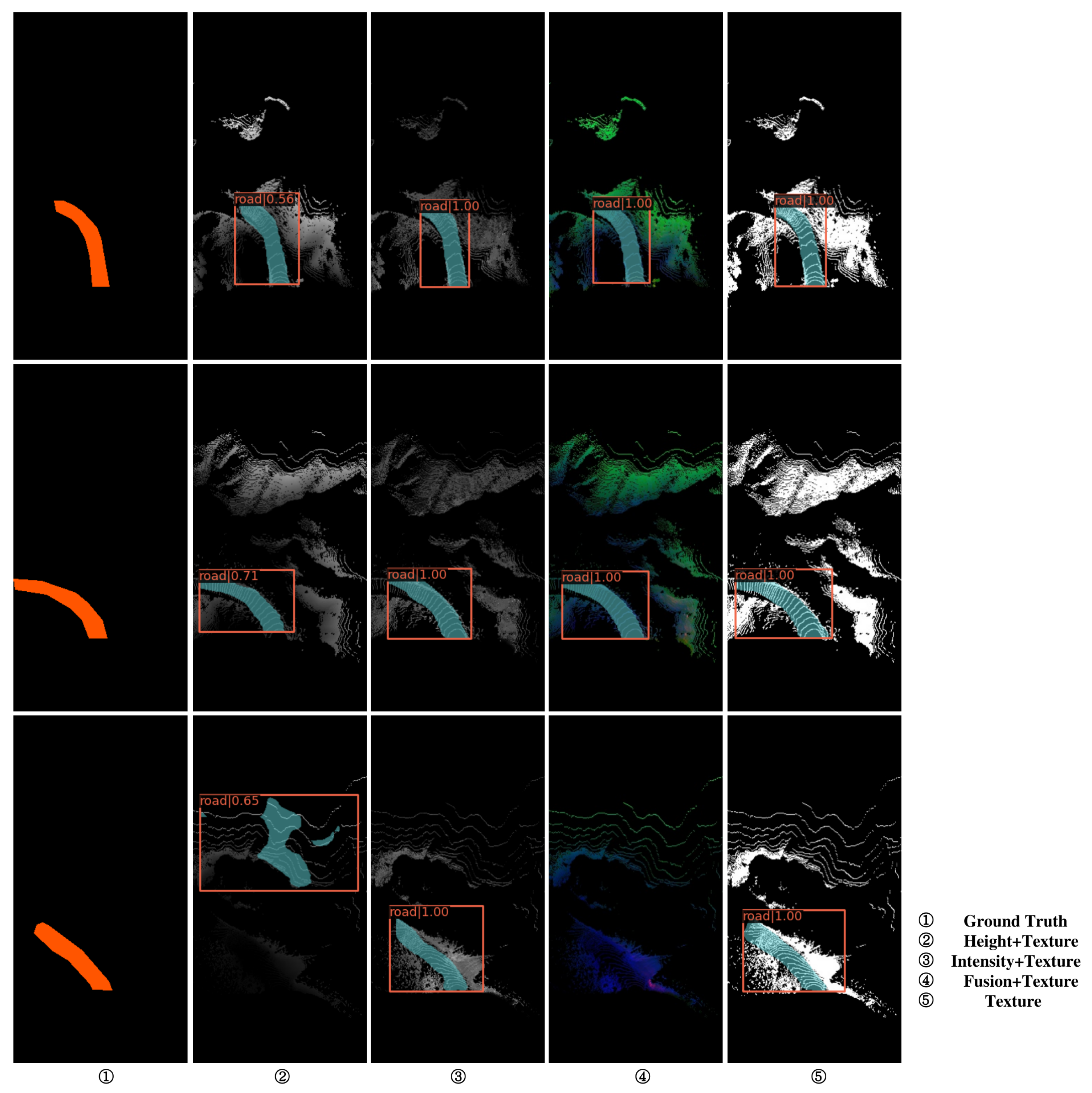
4.2. Results of Ablation Experiment
4.3. Multi-Frame Fusion Result
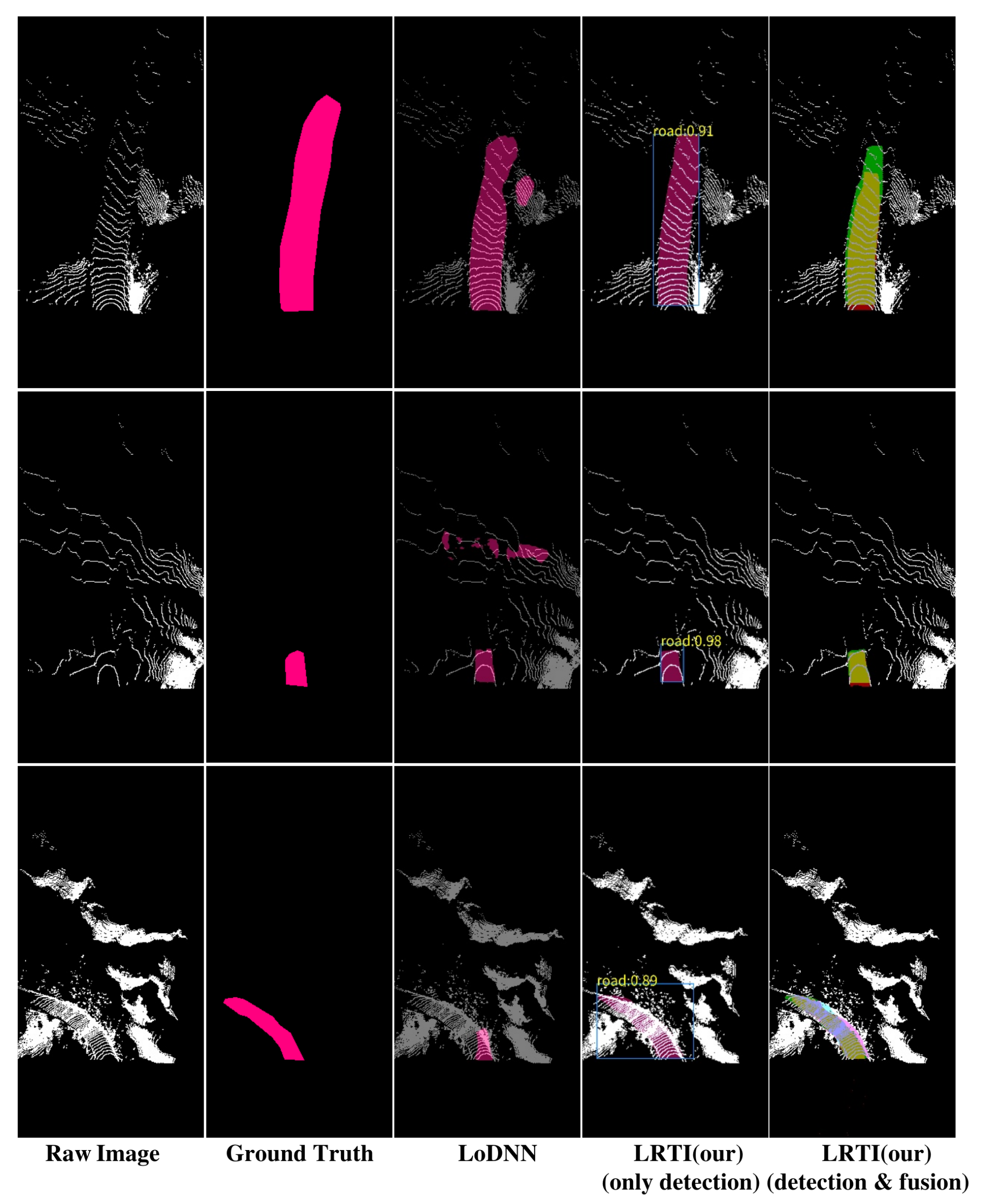
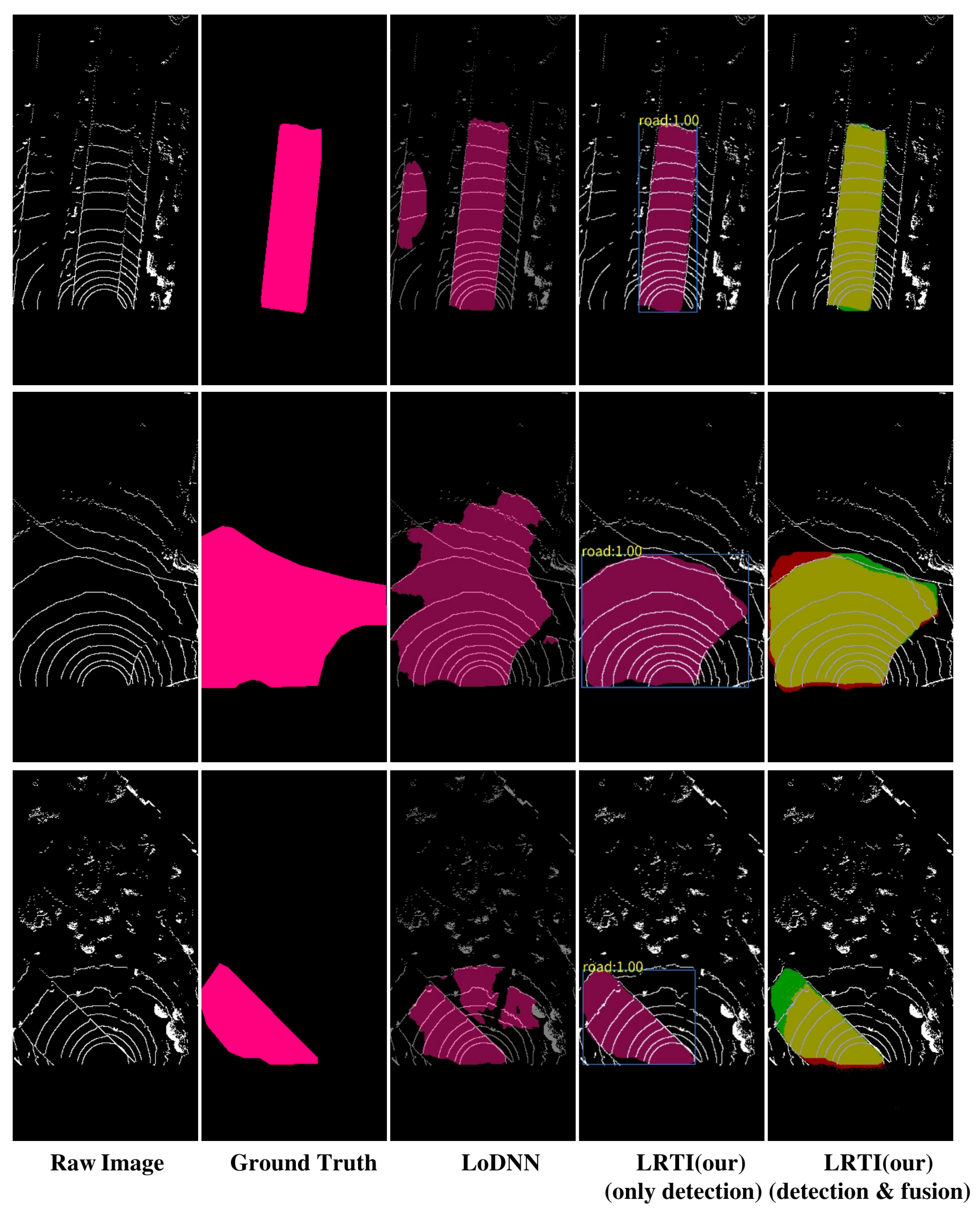
4.4. Comparison Results of Different Methods
4.5. Result of Dust Scene
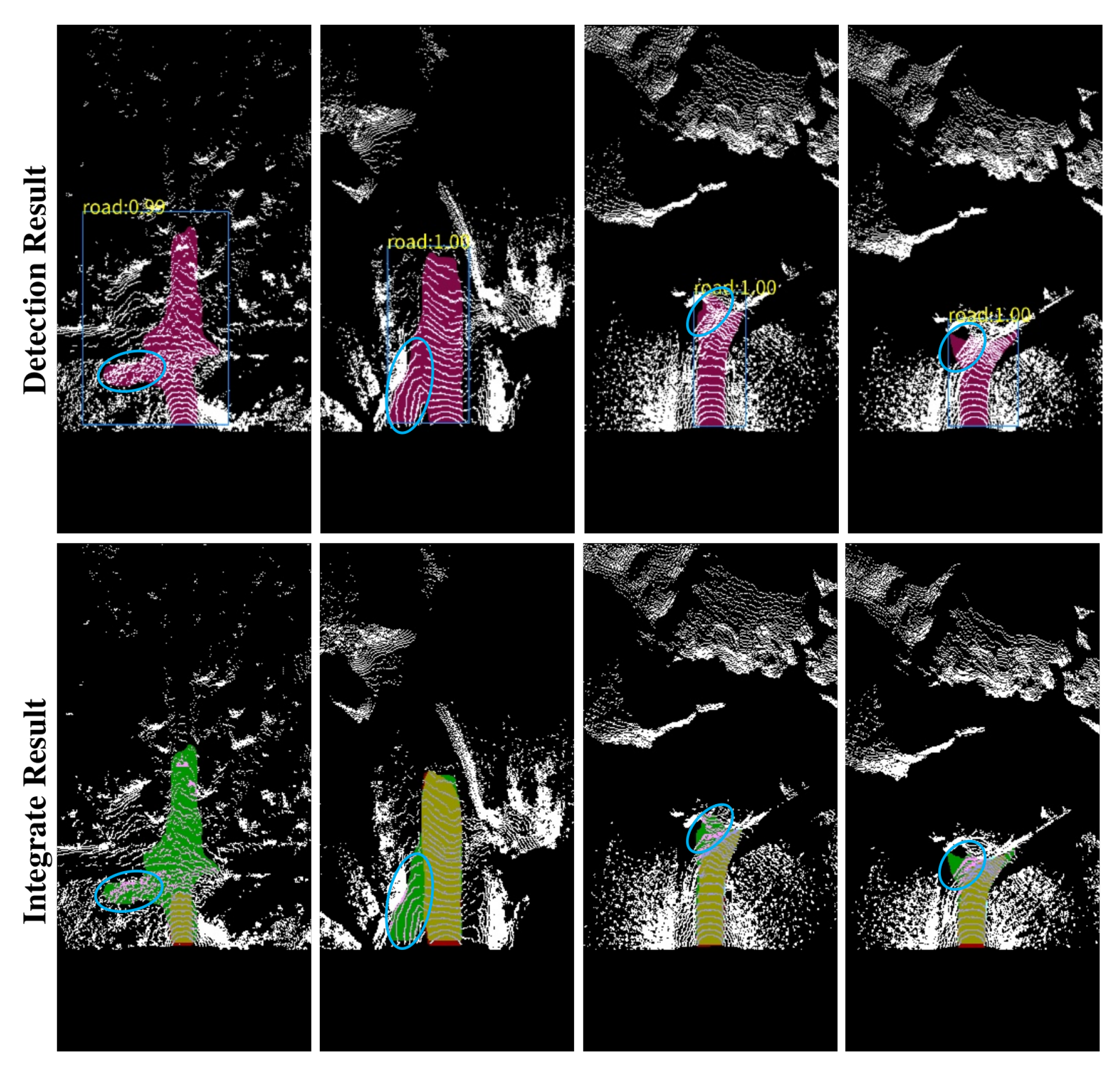
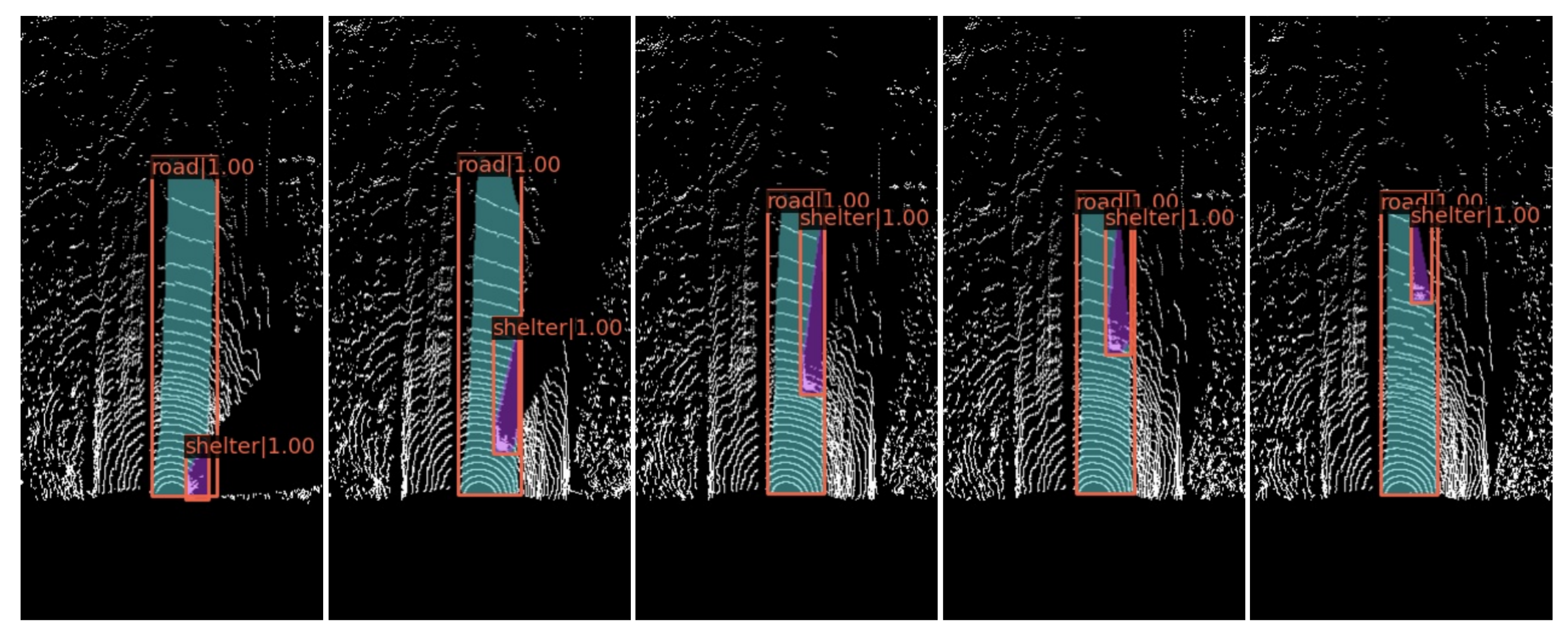
4.6. Occlusion Processing Results
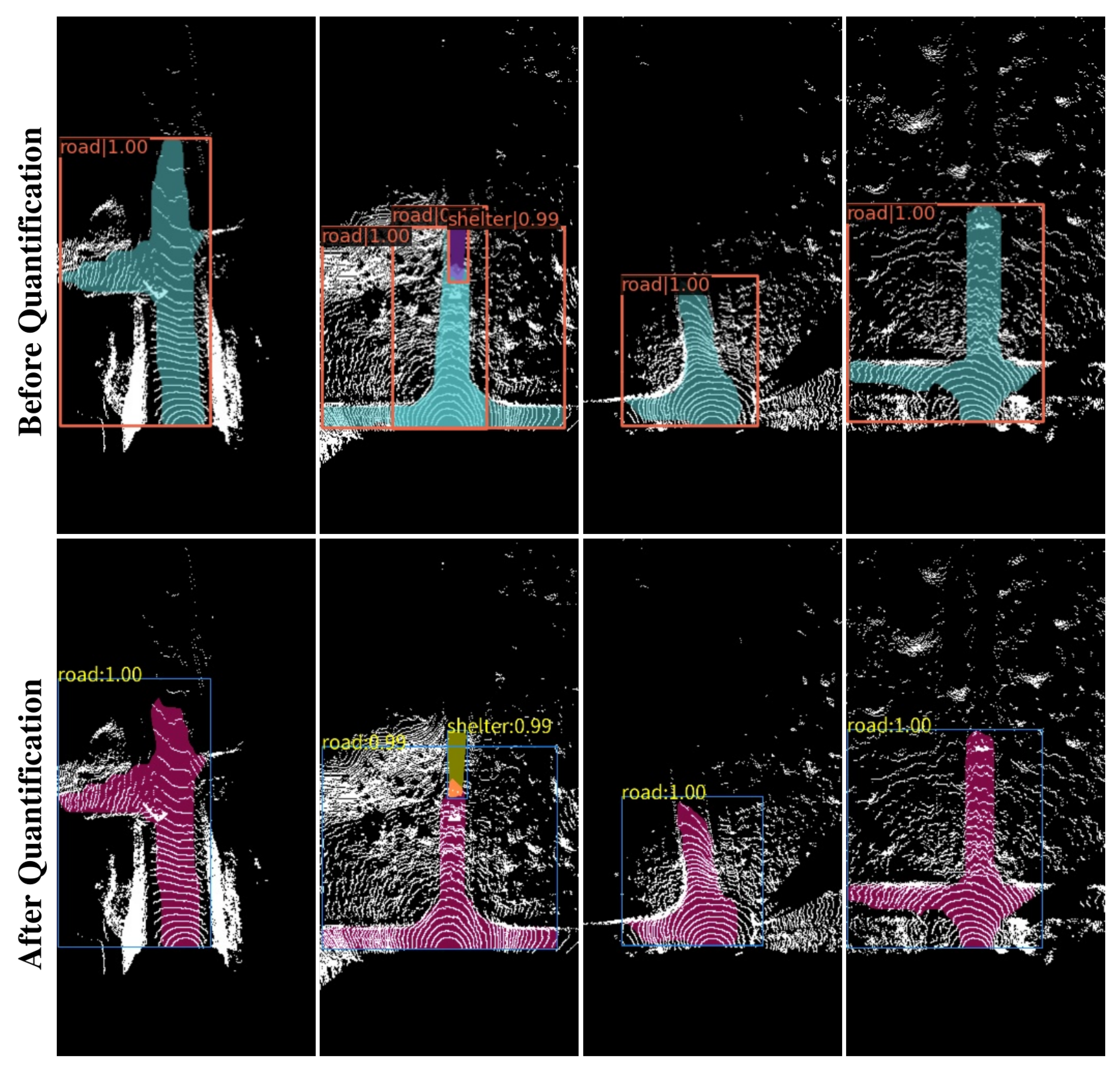
4.7. Model Quantification Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| GAN | Generative Adversarial Network |
| GCN | Graph Convolutional Networks |
| RCNN | Region Convolutional Neural Network |
| BEV | Bird’s Eye View |
| 3D | Three-dimensional |
| ROS | Robot Operating System |
| GPS | Global Positioning System |
| GPU | Graphic Processing Units |
| UGV | Unmanned Ground Vehicle |
References
- Gao, B.; Zhao, X.; Zhao, H. An Active and Contrastive Learning Framework for Fine-Grained Off-Road Semantic Segmentation. arXiv 2022, arXiv:2202.09002. [Google Scholar] [CrossRef]
- Pizzati, F.; García, F. Enhanced free space detection in multiple lanes based on single CNN with scene identification. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2536–2541. [Google Scholar]
- Sanberg, W.P.; Dubbleman, G. Free-Space detection with self-supervised and online trained fully convolutional networks. Electron. Imaging 2017, 2017, 54–61. [Google Scholar] [CrossRef] [Green Version]
- Holder, C.J.; Breckon, T.P.; Wei, X. From on-road to off: Transfer learning within a deep convolutional neural network for segmentation and classification of off-road scenes. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 149–162. [Google Scholar]
- Hamandi, M.; Asmar, D.; Shammas, E. Ground segmentation and free space estimation in off-road terrain. Pattern Recognit. Lett. 2018, 108, 1–7. [Google Scholar] [CrossRef]
- Neto, N.A.F.; Ruiz, M.; Reis, M.; Cajahyba, T.; Oliveira, D.; Barreto, A.C.; Simas Filho, E.F.; de Oliveira, W.L.; Schnitman, L.; Monteiro, R.L. Low-latency perception in off-road dynamical low visibility environments. Expert Syst. Appl. 2022, 201, 117010. [Google Scholar] [CrossRef]
- Jin, Y.; Han, D.; Ko, H. Memory-Based Semantic Segmentation for Off-road Unstructured Natural Environments. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September –1 October 2021; pp. 24–31. [Google Scholar]
- Viswanath, K.; Singh, K.; Jiang, P.; Sujit, P.; Saripalli, S. Offseg: A semantic segmentation framework for off-road driving. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 354–359. [Google Scholar]
- Sharma, S.; Ball, J.E.; Tang, B.; Carruth, D.W.; Doude, M.; Islam, M.A. Semantic segmentation with transfer learning for off-road autonomous driving. Sensors 2019, 19, 2577. [Google Scholar] [CrossRef] [Green Version]
- Alvarez, J.M.; López, A.M.; Gevers, T.; Lumbreras, F. Combining priors, appearance, and context for road detection. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1168–1178. [Google Scholar] [CrossRef] [Green Version]
- Kong, H.; Audibert, J.Y.; Ponce, J. General road detection from a single image. IEEE Trans. Image Process. 2010, 19, 2211–2220. [Google Scholar] [CrossRef]
- Asvadi, A.; Premebida, C.; Peixoto, P.; Nunes, U. 3D Lidar-based static and moving obstacle detection in driving environments: An approach based on voxels and multi-region ground planes. Robot. Auton. Syst. 2016, 83, 299–311. [Google Scholar] [CrossRef]
- Hu, X.; Rodriguez, F.S.A.; Gepperth, A. A multi-modal system for road detection and segmentation. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium, Dearborn, MI, USA, 8–11 June 2014; pp. 1365–1370. [Google Scholar]
- Zhang, W. Lidar-based road and road-edge detection. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010; pp. 845–848. [Google Scholar]
- Wijesoma, W.S.; Kodagoda, K.S.; Balasuriya, A.P. Road-boundary detection and tracking using ladar sensing. IEEE Trans. Robot. Autom. 2004, 20, 456–464. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Wang, X.; Dolan, J.M. Road-segmentation-based curb detection method for self-driving via a 3D-LiDAR sensor. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3981–3991. [Google Scholar] [CrossRef]
- Nagy, I.; Oniga, F. Free Space Detection from Lidar Data Based on Semantic Segmentation. In Proceedings of the 2021 IEEE 17th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 28–30 October 2021; pp. 95–100. [Google Scholar]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Yu, Q.; Dai, J. BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers. arXiv 2022, arXiv:2203.17270. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.; Han, S. BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. arXiv 2022, arXiv:2205.13542. [Google Scholar]
- Shaban, A.; Meng, X.; Lee, J.; Boots, B.; Fox, D. Semantic Terrain Classification for Off-Road Autonomous Driving. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 619–629. [Google Scholar]
- Gao, B.; Xu, A.; Pan, Y.; Zhao, X.; Yao, W.; Zhao, H. Off-road drivable area extraction using 3D LiDAR data. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1505–1511. [Google Scholar]
- Yuan, Y.; Jiang, Z.; Wang, Q. Video-based road detection via online structural learning. Neurocomputing 2015, 168, 336–347. [Google Scholar] [CrossRef]
- Aly, M. Real time detection of lane markers in urban streets. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 7–12. [Google Scholar]
- Kim, Z. Robust lane detection and tracking in challenging scenarios. IEEE Trans. Intell. Transp. Syst. 2008, 9, 16–26. [Google Scholar] [CrossRef] [Green Version]
- Uchiyama, H.; Deguchi, D.; Takahashi, T.; Ide, I.; Murase, H. 3-D line segment reconstruction using an in-vehicle camera for free space detection. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 290–295. [Google Scholar]
- Oana, I. Disparity image segmentation for free-space detection. In Proceedings of the 2016 IEEE 12th International Conference on Intelligent Computer Communication And Processing (ICCP), Cluj-Napoca, Romania, 8–10 September 2016; pp. 217–224. [Google Scholar]
- Neumann, L.; Vanholme, B.; Gressmann, M.; Bachmann, A.; Kählke, L.; Schüle, F. Free space detection: A corner stone of automated driving. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; pp. 1280–1285. [Google Scholar]
- Mou, L.; Lu, X.; Li, X.; Zhu, X.X. Nonlocal graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8246–8257. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. Acm Trans. Graph. (tog) 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5966–5978. [Google Scholar] [CrossRef]
- Basavaraju, A.; Du, J.; Zhou, F.; Ji, J. A machine learning approach to road surface anomaly assessment using smartphone sensors. IEEE Sens. J. 2019, 20, 2635–2647. [Google Scholar] [CrossRef]
- Yang, X.; Hu, L.; Ahmed, H.U.; Bridgelall, R.; Huang, Y. Calibration of smartphone sensors to evaluate the ride quality of paved and unpaved roads. Int. J. Pavement Eng. 2022, 23, 1529–1539. [Google Scholar] [CrossRef]
- Aboah, A.; Boeding, M.; Adu-Gyamfi, Y. Mobile sensing for multipurpose applications in transportation. J. Big Data Anal. Transp. 2022, 4, 171–183. [Google Scholar] [CrossRef]
- Krichen, M. Anomalies detection through smartphone sensors: A review. IEEE Sens. J. 2021, 21, 7207–7217. [Google Scholar] [CrossRef]
- Sattar, S.; Li, S.; Chapman, M. Road surface monitoring using smartphone sensors: A review. Sensors 2018, 18, 3845. [Google Scholar] [CrossRef] [PubMed]
- Patra, S.; Maheshwari, P.; Yadav, S.; Banerjee, S.; Arora, C. A joint 3d-2d based method for free space detection on roads. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 643–652. [Google Scholar]
- Chang, Y.; Xue, F.; Sheng, F.; Liang, W.; Ming, A. Fast Road Segmentation via Uncertainty-aware Symmetric Network. arXiv 2022, arXiv:2203.04537. [Google Scholar]
- Yu, B.; Lee, D.; Lee, J.S.; Kee, S.C. Free Space Detection Using Camera-LiDAR Fusion in a Bird’s Eye View Plane. Sensors 2021, 21, 7623. [Google Scholar] [CrossRef] [PubMed]
- Leung, T.H.Y.; Ignatyev, D.; Zolotas, A. Hybrid Terrain Traversability Analysis in Off-road Environments. In Proceedings of the 2022 8th International Conference on Automation, Robotics and Applications (ICARA), Prague, Czech Republic, 18–20 February 2022; pp. 50–56. [Google Scholar]
- Chen, Z.; Zhang, J.; Tao, D. Progressive lidar adaptation for road detection. IEEE/CAA J. Autom. Sin. 2019, 6, 693–702. [Google Scholar] [CrossRef] [Green Version]
- Zhou, S.; Xi, J.; McDaniel, M.W.; Nishihata, T.; Salesses, P.; Iagnemma, K. Self-supervised learning to visually detect terrain surfaces for autonomous robots operating in forested terrain. J. Field Robot. 2012, 29, 277–297. [Google Scholar] [CrossRef]
- Lei, G.; Yao, R.; Zhao, Y.; Zheng, Y. Detection and modeling of unstructured roads in forest areas based on visual-2D lidar data fusion. Forests 2021, 12, 820. [Google Scholar] [CrossRef]
- Caltagirone, L.; Scheidegger, S.; Svensson, L.; Wahde, M. Fast LIDAR-based road detection using fully convolutional neural networks. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1019–1024. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Tang, H.; Wu, T.; Dai, B. SmogNet: A point cloud smog segmentation network for unmanned vehicles. In Proceedings of the 2021 5th CAA International Conference on Vehicular Control and Intelligence (CVCI), Tianjin, China, 29–31 October 2021; pp. 1–6. [Google Scholar]
- Hong, D.; Yokoya, N.; Ge, N.; Chanussot, J.; Zhu, X.X. Learnable manifold alignment (LeMA): A semi-supervised cross-modality learning framework for land cover and land use classification. ISPRS J. Photogramm. Remote Sens. 2019, 147, 193–205. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Sharma, S.; Dabbiru, L.; Hannis, T.; Mason, G.; Carruth, D.W.; Doude, M.; Goodin, C.; Hudson, C.; Ozier, S.; Ball, J.E.; et al. CaT: CAVS Traversability Dataset for Off-Road Autonomous Driving. IEEE Access 2022, 10, 24759–24768. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3, p. 5. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Traditional Method | Camera-based | [10,11,22,23,24,25,26] | Low-level manual features; Weak adaptability; Poor robustness |
| LiDAR-based | [12,13,14,15,16] | ||
| LiDAR-Camera | [27] | ||
| Learning Method | Camera-based | [1,2,3,4,5,6,7,8,9,31,32,33] | Strong learning ability and adaptability; Large annotation data requirements; More computing resource requirements |
| LiDAR-based | [17,20,21,43,47] | ||
| LiDAR-Camera | [36,37,38,39,40,41,42] |
| Test List | Average Precision | |||
|---|---|---|---|---|
| mAP bbox | mAP_s bbox | mAP_m bbox | mAP_l bbox | |
| Texture | 0.952 | 0.920 | 0.954 | 0.969 |
| Texture + Intensity | 0.945 | 0.926 | 0.946 | 0.959 |
| Texture + Height | 0.938 | 0.920 | 0.937 | 0.962 |
| Texture + Fusion | 0.953 | 0.925 | 0.956 | 0.959 |
| Test List | Average Precision | |||
| mAP segm | mAP_s segm | mAP_m segm | mAP_l segm | |
| Texture | 0.951 | 0.936 | 0.971 | 0.861 |
| Texture + Intensity | 0.947 | 0.925 | 0.968 | 0.847 |
| Texture + Height | 0.954 | 0.922 | 0.975 | 0.859 |
| Texture + Fusion | 0.948 | 0.915 | 0.966 | 0.858 |
| CPA | Recall | IoU | Dice | |
|---|---|---|---|---|
| PointNet++-ssg [55] | 92.29 | - | 80.24 | - |
| PointNet++-msg [55] | 92.63 | - | 80.08 | - |
| DGCNN [29] | 92.96 | - | 81.24 | - |
| LoDNN [43] | 92.56 | 94.10 | 87.48 | 93.32 |
| LRTI (our) |
| CPA | Recall | IoU | Dice | |
|---|---|---|---|---|
| road | 99.03 | 83.79 | 83.11 | 90.78 |
| road + shelter |
| CPA | Recall | IoU | Dice | Inference (ms) | FPS | |
|---|---|---|---|---|---|---|
| Raw model (RTX1660ti) | 111 | 9 | ||||
| FP16 quantization (RTX1660ti) | 96.36 | 91.04 | 88.02 | 93.63 |
| Inference (ms) | FPS | |
|---|---|---|
| FP16 quantization (RTX1660ti) | 38 | 26 |
| FP16 quantization (RTX2080ti) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, C.; Li, B.; Wu, T. Off-Road Drivable Area Detection: A Learning-Based Approach Exploiting LiDAR Reflection Texture Information. Remote Sens. 2023, 15, 27. https://doi.org/10.3390/rs15010027
Zhong C, Li B, Wu T. Off-Road Drivable Area Detection: A Learning-Based Approach Exploiting LiDAR Reflection Texture Information. Remote Sensing. 2023; 15(1):27. https://doi.org/10.3390/rs15010027
Chicago/Turabian StyleZhong, Chuanchuan, Bowen Li, and Tao Wu. 2023. "Off-Road Drivable Area Detection: A Learning-Based Approach Exploiting LiDAR Reflection Texture Information" Remote Sensing 15, no. 1: 27. https://doi.org/10.3390/rs15010027
APA StyleZhong, C., Li, B., & Wu, T. (2023). Off-Road Drivable Area Detection: A Learning-Based Approach Exploiting LiDAR Reflection Texture Information. Remote Sensing, 15(1), 27. https://doi.org/10.3390/rs15010027