


Gas Plume Target Detection in Multibeam Water Column Image Using Deep Residual Aggregation Structure and Attention Mechanism

Abstract
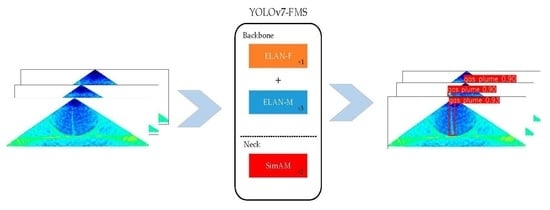
:
1. Introduction
- ELAN-M and ELAN-F modules are designed to reduce model parameters, speed up model convergence, and alleviate the problem of insignificant accuracy gains in deep residual structures.
- An ELAN-F1M3 backbone network structure is designed to fully utilize the efficiency of the ELAN-F and ELAN-M modules.
- To reduce the effect of noise, the SimAM module is introduced to evaluate the weights of the neurons in each feature map of the neck network.
- Extensive experiments show that the new model can accurately detect plume targets in complex water images, far outperforming other models in terms of accuracy.
2. Related Work
2.1. Data Augmentation
2.2. YOLOv7
2.2.1. Input Module
2.2.2. Backbone Network
2.2.3. Neck Network
2.2.4. Head Network
3. Method
3.1. MBConv and Fused-MBConv Block
3.2. ELAN-F and ELAN-M Module
3.3. SimAM Attention Block
3.4. YOLOv7 Neck Network with SimAM
4. Experiments and Discussion
4.1. Preliminary Preparation
4.1.1. Dataset Preparation
4.1.2. Experimental Environment
4.1.3. Hyperparameter Setting
4.2. Model Evaluation Metrics
4.3. Experimental Analysis
4.3.1. The Selection of the Baseline Network
4.3.2. Design of Backbone Network Based on ELAN-F and ELAN-M
4.3.3. Experimental Analysis of the Proposed Method and Other Advanced Lightweight Networks
4.3.4. Experimental Analysis of the Proposed Method and Other Attention Blocks
4.3.5. Ablation Study Based on YOLOv7
4.3.6. Experimental Analysis of the Proposed Method and Other CNN Methods
4.3.7. Result of Detection and Recognition of Gas Plume Targets in WCI
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Schimel, A.C.G.; Brown, C.J.; Ierodiaconou, D. Automated Filtering of Multibeam Water-Column Data to Detect Relative Abundance of Giant Kelp (Macrocystis pyrifera). Remote Sens. 2020, 12, 1371. [Google Scholar] [CrossRef]
- Czechowska, K.; Feldens, P.; Tuya, F.; Cosme de Esteban, M.; Espino, F.; Haroun, R.; Schönke, M.; Otero-Ferrer, F. Testing Side-Scan Sonar and Multibeam Echosounder to Study Black Coral Gardens: A Case Study from Macaronesia. Remote Sens. 2020, 12, 3244. [Google Scholar] [CrossRef]
- Guan, M.; Cheng, Y.; Li, Q.; Wang, C.; Fang, X.; Yu, J. An Effective Method for Submarine Buried Pipeline Detection via Multi-Sensor Data Fusion. IEEE Access. 2019, 7, 125300–125309. [Google Scholar] [CrossRef]
- Zhu, G.; Shen, Z.; Liu, L.; Zhao, S.; Ji, F.; Ju, Z.; Sun, J. AUV Dynamic Obstacle Avoidance Method Based on Improved PPO Algorithm. IEEE Access. 2022, 10, 121340–121351. [Google Scholar] [CrossRef]
- Logan, G.A.; Jones, A.T.; Kennard, J.M.; Ryan, G.J.; Rollet, N. Australian offshore natural hydrocarbon seepage studies, a review and re-evaluation. Mar. Pet. Geol. 2010, 27, 26–45. [Google Scholar] [CrossRef]
- Liu, H.; Yang, F.; Zheng, S.; Li, Q.; Li, D.; Zhu, H. A method of sidelobe effect suppression for multibeam water column images based on an adaptive soft threshold. Appl. Acoust. 2019, 148, 467–475. [Google Scholar] [CrossRef]
- Hou, T.; Huff, L.C. Seabed characterization using normalized backscatter data by best estimated grazing angles. In Proceedings of the International Symposium on Underwater Technology (UT04), Koto Ward, Tokyo, Japan, 7–9 April 2004; pp. 153–160. [Google Scholar] [CrossRef]
- Urban, P.; Köser, K.; Greinert, J. Processing of multibeam water column image data for automated bubble/seep detection and repeated mapping. Limnol. Oceanogr. Methods 2017, 15, 1–21. [Google Scholar] [CrossRef]
- Church, I. Multibeam sonar water column data processing tools to support coastal ecosystem science. J. Acoust. Soc. Am. 2017, 141, 3949. [Google Scholar] [CrossRef]
- Ren, X.; Ding, D.; Qin, H.; Ma, L.; Li, G. Extraction of Submarine Gas Plume Based on Multibeam Water Column Point Cloud Model. Remote Sens. 2022, 14, 4387. [Google Scholar] [CrossRef]
- Hughes, J.B.; Hightower, J.E. Combining split-beam and dual-frequency identification sonars to estimate abundance of anadromous fishes in the Roanoke River, North Carolina. N. Am. J. Fish. Manag. 2015, 35, 229–240. [Google Scholar] [CrossRef]
- Fatan, M.; Daliri, M.R.; Shahri, A.M. Underwater cable detection in the images using edge classification based on texture information. Measurement 2016, 91, 309–317. [Google Scholar] [CrossRef]
- Lu, S.; Liu, X.; He, Z.; Zhang, X.; Liu, W.; Karkee, M. Swin-Transformer-YOLOv5 for Real-Time Wine Grape Bunch Detection. Remote Sens. 2022, 14, 5853. [Google Scholar] [CrossRef]
- Li, Z.; Zeng, Z.; Xiong, H.; Lu, Q.; An, B.; Yan, J.; Li, R.; Xia, L.; Wang, H.; Liu, K. Study on Rapid Inversion of Soil Water Content from Ground-Penetrating Radar Data Based on Deep Learning. Remote Sens. 2023, 15, 1906. [Google Scholar] [CrossRef]
- Wu, J.; Xie, C.; Zhang, Z.; Zhu, Y. A Deeply Supervised Attentive High-Resolution Network for Change Detection in Remote Sensing Images. Remote Sens. 2023, 15, 45. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? NIPS 2014, 27, 3320–3328. [Google Scholar] [CrossRef]
- YOLOv5 Models. Available online: https://Github.com/Ultralytics/Yolov5 (accessed on 13 January 2023).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Wei, X. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar] [CrossRef]
- Yu, K.; Cheng, Y.; Tian, Z.; Zhang, K. High Speed and Precision Underwater Biological Detection Based on the Improved YOLOV4-Tiny Algorithm. J. Mar. Sci. Eng. 2022, 10, 1821. [Google Scholar] [CrossRef]
- Peng, F.; Miao, Z.; Li, F.; Li, Z. S-FPN: A shortcut feature pyramid network for sea cucumber detection in underwater images. ESWA 2021, 182, 115306. [Google Scholar] [CrossRef]
- Zocco, F.; Huang, C.I.; Wang, H.C.; Khyam, M.O.; Van, M. Towards More Efficient EfficientDets and Low-Light Real-Time Marine Debris Detection. arXiv 2022, arXiv:2203.07155. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE TPAMI 2015, 28, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Wang, H.; Xiao, N. Underwater Object Detection Method Based on Improved Faster RCNN. Appl. Sci. 2023, 13, 2746. [Google Scholar] [CrossRef]
- Song, P.; Li, P.; Dai, L.; Wang, T.; Chen, Z. Boosting R-CNN: Reweighting R-CNN samples by RPN’s error for underwater object detection. NEUCOM 2023, 530, 150–164. [Google Scholar] [CrossRef]
- Inoue, H. Data augmentation by pairing samples for images classification. arXiv 2018, arXiv:1801.02929. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 19–25 June 2021; pp. 13733–13742. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing Network Design Strategies Through Gradient Path Analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2820–2828. [Google Scholar] [CrossRef]
- Wu, B.; Keutzer, K.; Dai, X.; Zhang, P.; Jia, Y. FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10726–10734. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, Graz, Austria, 18–24 July 2021; pp. 10096–10106. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Zhang, C.; Lin, G.; Liu, F.; Yao, R.; Shen, C. Canet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5217–5226. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Graz, Austria, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Hendrycks, D.; Mu, N.; Cubuk, E.D.; Zoph, B.; Gilmer, J.; Lakshminarayanan, B. Augmix: A simple data processing method to improve robustness and uncertainty. arXiv 2019, arXiv:1912.02781. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. NeurIPS 2020, 33, 6256–6268. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Howard, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 9–15 June 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetV2: Enhance Cheap Operation with Long-Range Attention. arXiv 2022, arXiv:2211.12905. [Google Scholar]
- Cui, C.; Gao, T.; Wei, S.; Du, Y.; Guo, R.; Dong, S.; Lu, B.; Zhou, Y.; Lv, X.; Liu, Q.; et al. PP-LCNet: A lightweight CPU convolutional neural network. arXiv 2021, arXiv:2109.15099. [Google Scholar]
- Vasu, P.K.A.; Gabriel, J.; Zhu, J.; Tuzel, O.; Ranjan, A. MobileOne: An improved one millisecond mobile backbone. arXiv 2022, arXiv:2206.04040. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Configuration |
|---|---|
| Initial learn rate | 0.01 |
| Optimizer | SGD |
| Weight decay | 0.0005 |
| Momentum | 0.937 |
| Image size | 320 × 320 |
| Batch size | 16 |
| Epochs | 400 |
| Method | Params. (M) | FLOPs (G) | F1 (%) | mAP50 (%) | mAP50:95 (%) | FPS Batch_Size = 1 |
|---|---|---|---|---|---|---|
| YOLOv7-tiny | 6.0 | 13.0 | 82.9 | 83.0 | 38.2 | 128.2 |
| YOLOv7x | 70.8 | 188.9 | 89.1 | 90.8 | 44.1 | 78.4 |
| YOLOv7 | 36.5 | 103.2 | 90.8 | 91.0 | 46.8 | 84.7 |
| Method | Params. (M) | FLOPs (G) | F1 (%) | mAP50 (%) | mAP50:95 (%) | FPS Batch_Size = 1 |
|---|---|---|---|---|---|---|
| YOLOv7-F1M3 | 30.4 | 88.5 | 94.4 | 97.7 | 55.2 | 55.6 |
| YOLOv7-F2M2 | 30.9 | 95.1 | 89.5 | 91.5 | 46.2 | 62.9 |
| YOLOv7-F3M1 | 33.1 | 101.6 | 90.7 | 93.6 | 52.2 | 68.5 |
| Method | Params. (M) | FLOPs (G) | F1 (%) | mAP50 (%) | mAP50:95 (%) | FPS Batch_Size = 1 |
|---|---|---|---|---|---|---|
| YOLOv7-MobileNetv3 | 24.8 | 36.9 | 80.1 | 82.5 | 35.7 | 22.6 |
| YOLOv7-ShuffleNetv2 | 23.3 | 37.9 | 83.0 | 84.6 | 35.7 | 74.1 |
| YOLOv7-GhostNetv2 | 29.6 | 75.2 | 91.3 | 91.1 | 45.0 | 38.5 |
| YOLOv7-PPLCNet | 28.9 | 63.9 | 83.9 | 86.1 | 43.5 | 63.3 |
| YOLOv7-MobileOne | 23.3 | 40.1 | 87.6 | 89.4 | 39.5 | 90.9 |
| YOLOv7-F1M3 | 30.4 | 88.5 | 94.4 | 97.7 | 55.2 | 55.6 |
| Method | Block Params. | FLOPs (G) | F1 (%) | mAP50 (%) | mAP50:95 (%) | FPS Batch_Size = 1 |
|---|---|---|---|---|---|---|
| YOLOv7-SE | 163,840 | 102.9 | 77.0 | 78.7 | 33.2 | 79.4 |
| YOLOv7-ECA | 2 | 102.7 | 91.1 | 94.5 | 52.4 | 56.5 |
| YOLOv7-CBAM | 772 | 102.7 | 86.8 | 89.5 | 45.6 | 45.9 |
| YOLOv7-CA | 247,680 | 103.4 | 83.3 | 85.8 | 38.6 | 41.8 |
| YOLOv7-SimAM | 0 | 102.7 | 92.8 | 96.3 | 55.3 | 53.5 |
| Method | Params. (M) | FLOPs (G) | F1 (%) | mAP50 (%) | mAP50:95 (%) | FPS Batch_Size = 1 |
|---|---|---|---|---|---|---|
| YOLOv7 | 36.5 | 103.2 | 90.8 | 91.0 | 46.8 | 84.7 |
| YOLOv7-F1M3 (Neck) | 27.0 | 81.8 | 63.4 | 62.3 | 21.2 | 37.5 |
| YOLOv7-F1M3 | 30.4 | 88.5 | 94.4 | 97.7 | 55.2 | 55.6 |
| YOLOv7-SimAM (Backbone) | 35.4 | 102.3 | 87.7 | 89.2 | 44.5 | 51.0 |
| YOLOv7-SimAM | 36.3 | 102.7 | 92.8 | 96.3 | 55.3 | 53.5 |
| YOLOv7-FMS | 30.3 | 88.2 | 95.2 | 98.4 | 57.5 | 44.6 |
| Method | Params. (M) | FLOPs (G) | F1 (%) | mAP50 (%) | mAP50:95 (%) | FPS Batch_Size = 1 |
|---|---|---|---|---|---|---|
| YOLOv5-m | 21.1 | 12.7 | 92.0 | 96.4 | 50.2 | 70.4 |
| YOLOX-m | 25.3 | 18.4 | 92.3 | 95.1 | 48.2 | 48.7 |
| YOLOv6-m | 34.8 | 21.4 | 94.4 | 97.6 | 50.0 | 67.4 |
| SSD300 | 23.7 | 68.4 | 74.7 | 78.2 | 29.2 | 149.8 |
| RetinaNet (resnet34) | 29.9 | 38.3 | 19.8 | 22.5 | 6.1 | 53.6 |
| EfficientDet-D4 | 20.5 | 104.9 | 69.3 | 71.5 | 23.1 | 12.6 |
| Ours | 30.3 | 88.2 | 95.2 | 98.4 | 57.5 | 44.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Wang, X.; Yan, B.; Chen, J.; Jiang, T.; Sun, J. Gas Plume Target Detection in Multibeam Water Column Image Using Deep Residual Aggregation Structure and Attention Mechanism. Remote Sens. 2023, 15, 2896. https://doi.org/10.3390/rs15112896
Chen W, Wang X, Yan B, Chen J, Jiang T, Sun J. Gas Plume Target Detection in Multibeam Water Column Image Using Deep Residual Aggregation Structure and Attention Mechanism. Remote Sensing. 2023; 15(11):2896. https://doi.org/10.3390/rs15112896
Chicago/Turabian StyleChen, Wenguang, Xiao Wang, Binglong Yan, Junjie Chen, Tingchen Jiang, and Jialong Sun. 2023. "Gas Plume Target Detection in Multibeam Water Column Image Using Deep Residual Aggregation Structure and Attention Mechanism" Remote Sensing 15, no. 11: 2896. https://doi.org/10.3390/rs15112896
APA StyleChen, W., Wang, X., Yan, B., Chen, J., Jiang, T., & Sun, J. (2023). Gas Plume Target Detection in Multibeam Water Column Image Using Deep Residual Aggregation Structure and Attention Mechanism. Remote Sensing, 15(11), 2896. https://doi.org/10.3390/rs15112896