
SCM: A Searched Convolutional Metaformer for SAR Ship Classification


Abstract
:1. Introduction
- A novel mixture network, SCM, is proposed for SAR ship classification. This network is built with the help of NAS and a transformer, which have the characteristics of high accuracy and small model size.
- PDA-PC-DARTS is proposed to explore a high-performance target network in the poor quality, small sample number SAR ship dataset.
- For searching, DSCONV is replaced with MBCONV to achieve better efficiency.
- SCT is proposed by combining NAS, CNN, and a transformer, which improves the classification accuracy.
- A novel cell architecture is proposed to further enhance the accuracy by filling a searched node into a Metaformer block.
2. Related Work
2.1. CNN-Based SAR Ship Classification
2.2. Network Architecture Searching
2.3. Efficient Convolutional Blocks
2.4. Networks Related to Transformers
2.5. SAR Image
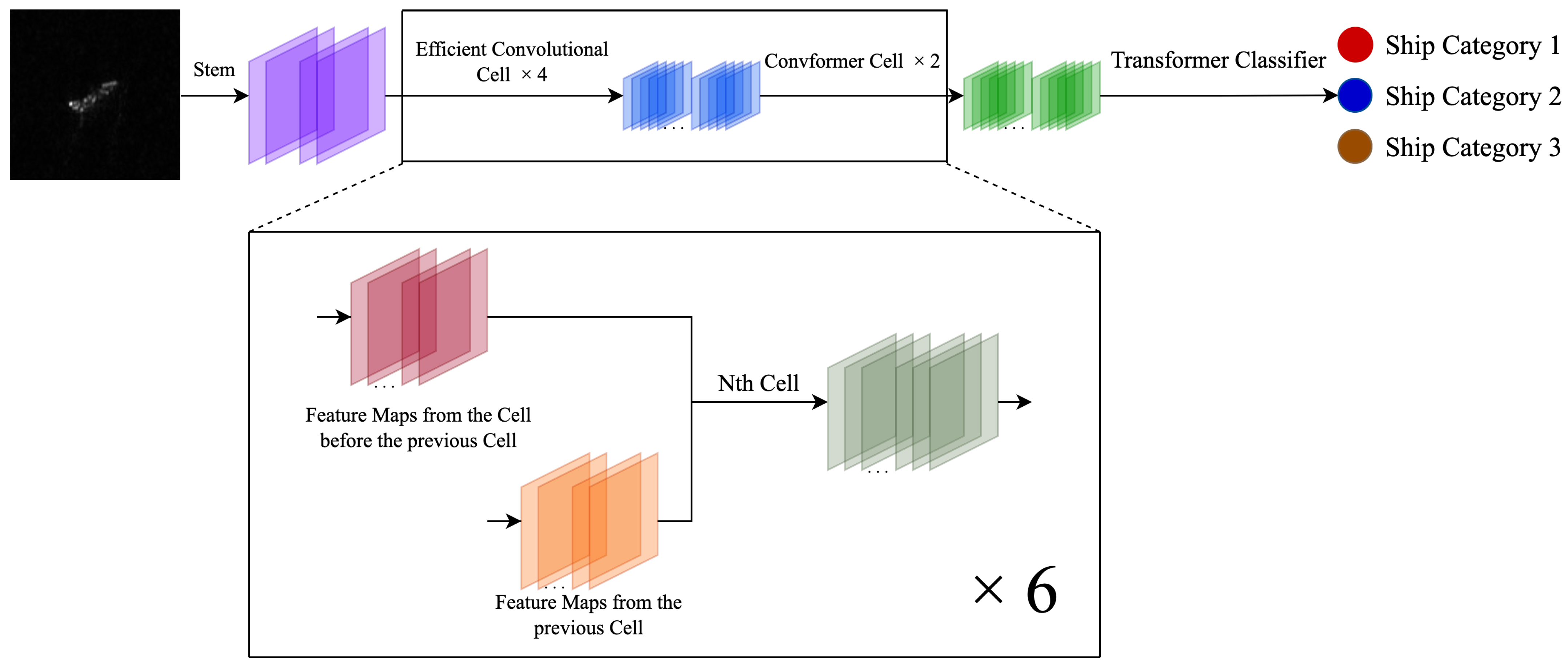
3. Searched Convolutional Metaformer
3.1. Efficient Convolutional Cells
Progressive Network Architecture Searching
3.2. Efficient Convolutional Operations
3.3. Transformer Classifier
3.4. ConvFormer
4. Experiments
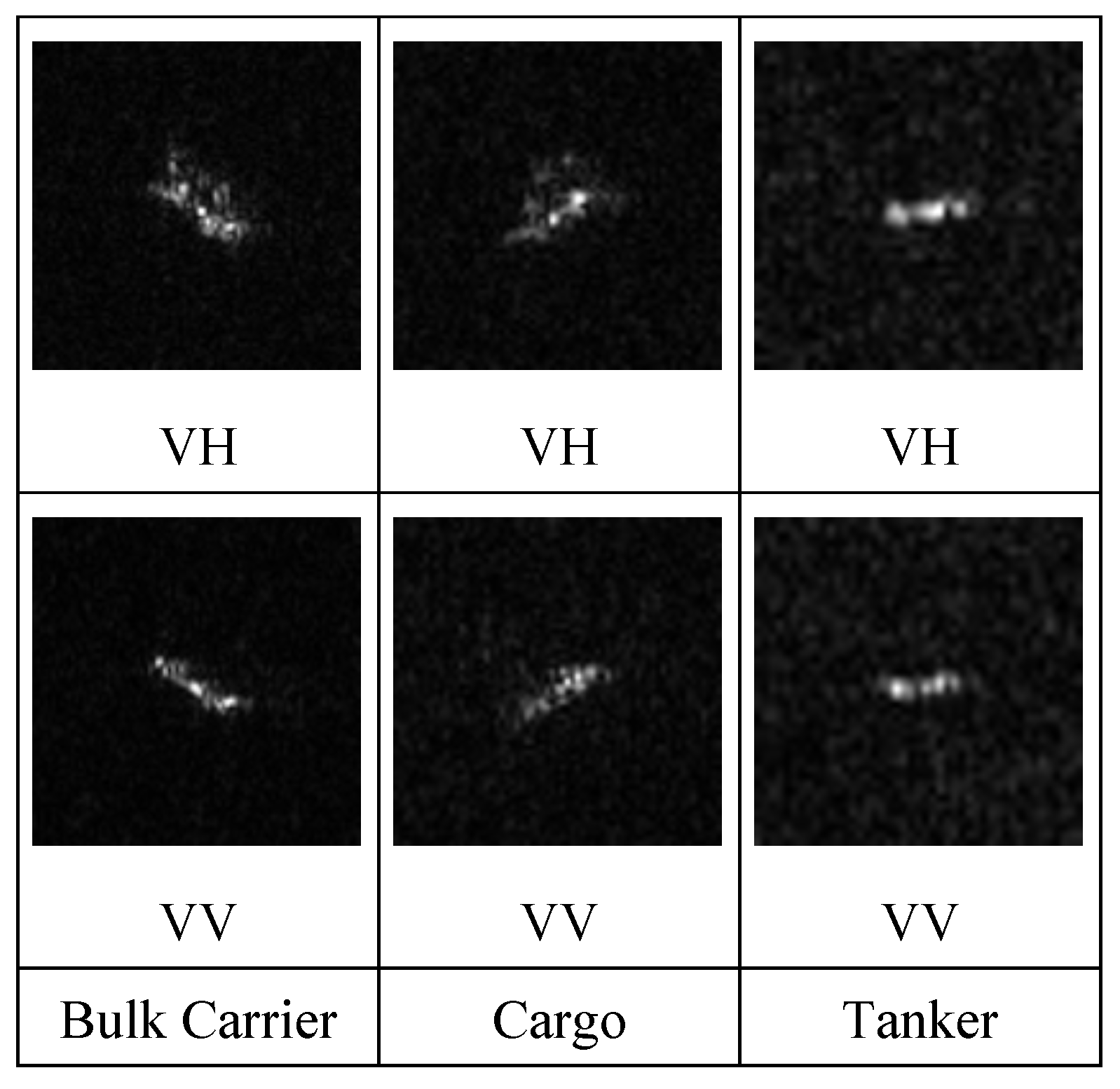
4.1. Datasets
4.1.1. OpenSARShip
4.1.2. FUSARShip
4.2. Data Preprocessing
4.3. Architecture Searching
4.4. Network Training
5. Results
5.1. Comparison with CNN-Based SAR Ship Classification Methods
5.2. Comparison with Efficient Networks from Computer Vision
5.3. Results on Dual-Polarization
5.4. Results of Generalization Capability
5.5. Ablation Study
5.5.1. Progressing Network Architecture Searching
5.5.2. MBCONV Block
5.5.3. Compact Transformer Classifier
5.5.4. ConvFormer
6. Discussion
6.1. Practical Application Scenario
6.2. Trade-Off between Accuracy, Number of Weights, and Computational Complexity
6.3. Adaptability of the ConvFormer Cell
6.4. Imbalance of Performance over Different Categories
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Petit, M.; Stretta, J.M.; Farrugio, H.; Wadsworth, A. Synthetic aperture radar imaging of sea surface life and fishing activities. IEEE Trans. Geosci. Remote Sens. 1992, 30, 1085–1089. [Google Scholar] [CrossRef] [Green Version]
- Park, J.; Lee, J.; Seto, K.; Hochberg, T.; Wong, B.A.; Miller, N.A.; Takasaki, K.; Kubota, H.; Oozeki, Y.; Doshi, S.; et al. Illuminating dark fishing fleets in North Korea. Sci. Adv. 2020, 6, eabb1197. [Google Scholar] [CrossRef] [PubMed]
- Brusch, S.; Lehner, S.; Fritz, T.; Soccorsi, M.; Soloviev, A.; van Schie, B. Ship surveillance with TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2010, 49, 1092–1103. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian network classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Abdal, R.; Qin, Y.; Wonka, P. Image2stylegan: How to embed images into the stylegan latent space? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4432–4441. [Google Scholar]
- Yasarla, R.; Sindagi, V.A.; Patel, V.M. Syn2real transfer learning for image deraining using gaussian processes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2726–2736. [Google Scholar]
- Zhong, Y.; Deng, W.; Wang, M.; Hu, J.; Peng, J.; Tao, X.; Huang, Y. Unequal-training for deep face recognition with long-tailed noisy data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7812–7821. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wang, C.; Zhang, H. Ship classification in high-resolution SAR images using deep learning of small datasets. Sensors 2018, 18, 2929. [Google Scholar] [CrossRef] [Green Version]
- Zeng, L.; Zhu, Q.; Lu, D.; Zhang, T.; Wang, H.; Yin, J.; Yang, J. Dual-polarized SAR ship grained classification based on CNN with hybrid channel feature loss. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Xiong, G.; Xi, Y.; Chen, D.; Yu, W. Dual-polarization SAR ship target recognition based on mini hourglass region extraction and dual-channel efficient fusion network. IEEE Access 2021, 9, 29078–29089. [Google Scholar] [CrossRef]
- Hou, X.; Ao, W.; Song, Q.; Lai, J.; Wang, H.; Xu, F. FUSAR-Ship: Building a high-resolution SAR-AIS matchup dataset of Gaofen-3 for ship detection and recognition. Sci. China Inf. Sci. 2020, 63, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, X.; Hui, J.; Wang, Z.; Zhang, Z. A novel group squeeze excitation sparsely connected convolutional networks for SAR target classification. Int. J. Remote Sens. 2019, 40, 4346–4360. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Liu, C.; Xu, X.; Zhan, X.; Wang, C.; Ahmad, I.; Zhou, Y.; Pan, D.; et al. HOG-ShipCLSNet: A novel deep learning network with hog feature fusion for SAR ship classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–22. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. Squeeze-and-excitation Laplacian pyramid network with dual-polarization feature fusion for ship classification in sar images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, L.; Zhang, X.; Chen, X.; Qi, G.J.; Tian, Q.; Xiong, H. Pc-darts: Partial channel connections for memory-efficient architecture search. arXiv 2019, arXiv:1907.05737. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2010, arXiv:2010.11929. [Google Scholar]
- Hassani, A.; Walton, S.; Shah, N.; Abuduweili, A.; Li, J.; Shi, H. Escaping the big data paradigm with compact transformers. arXiv 2021, arXiv:2104.05704. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10819–10829. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 June 2018; pp. 8697–8710. [Google Scholar]
- Pham, H.; Guan, M.; Zoph, B.; Le, Q.; Dean, J. Efficient neural architecture search via parameters sharing. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4095–4104. [Google Scholar]
- Xie, L.; Yuille, A. Genetic cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1379–1388. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4780–4789. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 June 2018; pp. 4510–4520. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 June 2018; pp. 7132–7141. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Touvron, H.; Bojanowski, P.; Caron, M.; Cord, M.; El-Nouby, A.; Grave, E.; Izacard, G.; Joulin, A.; Synnaeve, G.; Verbeek, J.; et al. Resmlp: Feedforward networks for image classification with data-efficient training. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5314–5321. [Google Scholar] [CrossRef]
- Singh, P.; Shree, R.; Diwakar, M. A new SAR image despeckling using correlation based fusion and method noise thresholding. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 313–328. [Google Scholar] [CrossRef]
- Singh, P.; Shankar, A.; Diwakar, M. Review on nontraditional perspectives of synthetic aperture radar image despeckling. J. Electron. Imaging 2023, 32, 021609. [Google Scholar] [CrossRef]
- Toutin, T. Geometric processing of remote sensing images: Models, algorithms and methods. Int. J. Remote Sens. 2004, 25, 1893–1924. [Google Scholar] [CrossRef]
- Choo, A.; Chan, Y.; Koo, V.; Electromagnet, A. Geometric correction on SAR imagery. In Proceedings of the Progress in Electromagnetics Research Symposium Proceedings, Kuala Lumpur, Malaysia, 27–30 March 2012. [Google Scholar]
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.P. A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for activation functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Huang, L.; Liu, B.; Li, B.; Guo, W.; Yu, W.; Zhang, Z.; Yu, W. OpenSARShip: A dataset dedicated to Sentinel-1 ship interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 195–208. [Google Scholar] [CrossRef]
- Zhang, H.; Tian, X.; Wang, C.; Wu, F.; Zhang, B. Merchant vessel classification based on scattering component analysis for COSMO-SkyMed SAR images. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1275–1279. [Google Scholar] [CrossRef]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Liu, Y.; Sangineto, E.; Bi, W.; Sebe, N.; Lepri, B.; Nadai, M. Efficient training of visual transformers with small datasets. Adv. Neural Inf. Process. Syst. 2021, 34, 23818–23830. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Use Traditional Feature | Network Architecture Designed for SAR Ships | Model Size | Computational Complexity | Dual-Polarization Only |
|---|---|---|---|---|---|
| Finetuned VGGNet [13] | × | × | Large | High | × |
| VGGNet With Hybrid Channel Feature Loss [14] | × | × | Large | High | √ |
| Mini Hourglass Region Extraction and Dual-Channel Efficient Fusion Network [15] | × | × | Moderate | Moderate | √ |
| Plain CNN [16] | × | √ | Large | High | × |
| HOG-ShipCLSNet [18] | √ | √ | Large | Low | × |
| SE-LPN-DPFF [19] | √ | √ | √ |
| Name | Type | Input(s) | Input Shape(s) | Output Shape |
|---|---|---|---|---|
| Stem | Normal Convolution | SAR Image | ||
| Cell1 | Normal Cell | Stem | ||
| Stem | ||||
| Cell2 | Reduction Cell | Stem | ||
| Cell1 | ||||
| Cell3 | Reduction Cell | Cell1 | ||
| Cell2 | ||||
| Cell4 | Normal Cell | Cell2 | ||
| Cell3 | ||||
| Cell5 | ConvFormer Cell | Cell3 | ||
| Cell4 | ||||
| Cell6 | ConvFormer Cell | Cell4 | ||
| Cell5 | ||||
| Transformer | Compact Transformer | Cell6 | 3 | |
| Classifier | Classifier |
| Original Operation | Efficient Operation | Original Block(s) | Updated Block(s) | Hyperparameters of Depth-Wise Convolution(s) |
|---|---|---|---|---|
| Conv | Efficient | DSCONV | MBCONV | Kernel , Stride 1, Dilation 1 |
| Conv | Kernel , Stride 1, Dilation 1 | |||
| Conv | Efficient | DSCONV | MBCONV | Kernel , Stride 1, Dilation 1 |
| Conv | Kernel , Stride 1, Dilation 1 | |||
| Dil_Conv | Efficient | DSCONV | MBCONV | Kernel , Stride 1, Dilation 2 |
| Dil_Conv | ||||
| Dil_Conv | Efficient | DSCONV | MBCONV | Kernel , Stride 1, Dilation 2 |
| Dil_Conv | ||||
| Reduction | Efficient Reduction | DSCONV | MBCONV | Kernel , Stride 2, Dilation 1 |
| Conv | Conv | Kernel , Stride 1, Dilation 1 | ||
| Reduction | Efficient Reduction | DSCONV | MBCONV | Kernel , Stride 2, Dilation 1 |
| Conv | Conv | Kernel , Stride 1, Dilation 1 | ||
| Reduction | Efficient Reduction | DSCONV | MBCONV | Kernel , Stride 2, Dilation 2 |
| Dil_Conv | Dil_Conv | |||
| Reduction | Efficient Reduction | DSCONV | MBCONV | Kernel , Stride 2, Dilation 2 |
| Dil_Conv | Dil_Conv |
| Ship Category | VH Samples | VV Samples | Training Samples | Test Samples |
|---|---|---|---|---|
| Bulk Carrier | 333 | 333 | 338 | 328 |
| Container Ship | 573 | 573 | 338 | 808 |
| Tanker | 242 | 242 | 338 | 146 |
| Ship Category | Total Samples | Training Samples | Test Samples |
|---|---|---|---|
| Bulk Carrier | 274 | 174 | 100 |
| Fishing | 787 | 174 | 100 |
| Cargo | 1735 | 174 | 100 |
| Tanker | 248 | 174 | 74 |
| Method | Precision | Accuracy | MAdds | Weights |
|---|---|---|---|---|
| Finetuned VGGNet [13] | ||||
| Plain CNN [16] | ||||
| GSESCNNs [17] | — | — | ||
| HOG-ShipCLSNet [18] | (Not including HOG and PCA) | |||
| SCM (ours) |
| Bulk Carrier | Container Ship | Tanker | |
|---|---|---|---|
| Bulk Carrier | |||
| Container Ship | |||
| Tanker |
| Method | Precision | Accuracy | MAdds | Weights |
|---|---|---|---|---|
| ResNet-18 [51] | ||||
| MobileNetv2 [31] | ||||
| ViT_tiny [23] | ||||
| CCT_722 [24] | ||||
| SCM (ours) |
| Method | Precision | Accuracy | MAdds | Weights |
|---|---|---|---|---|
| VGGNet With Hybrid Channel Feature Loss [14] | ||||
| Mini Hourglass Region Extraction and Dual-Channel Efficient Fusion Network [15] | ≥ (Dynamic) | |||
| SE-LPN-DPFF [19] | — | — | ||
| SCM with decision fusion (ours) |
| Method | Precision | Accuracy | MAdds | Weights |
|---|---|---|---|---|
| ResNet-18 [51] | ||||
| MobileNetv2 [31] | ||||
| ViT_tiny [23] | ||||
| CCT_722 [24] | ||||
| SCM(ours) |
| Bulk Carrier | Fishing | Cargo | Tanker | |
|---|---|---|---|---|
| Bulk Carrier | ||||
| Fishing | ||||
| Cargo | ||||
| Tanker |
| Method | Cell Type | Accuracy |
|---|---|---|
| PC-DARTS [20] (Baseline) | NNRNRN | |
| +PDA | NNRNRN | |
| +PDA +MBCONV | NNRNRN | |
| +PDA +MBCONV +Transformer Classifier | NNRNRN | |
| +PDA +MBCONV +Transformer Classifier +ConvFormer Cell | NRRNCC |
| Searching Algorithm | Accuracy |
|---|---|
| PDA-PC-DARTS | |
| PC-DARTS [20] |
| Basic Block | Accuracy |
|---|---|
| MBCONV | |
| DSCONV |
| Classifier | Accuracy |
|---|---|
| Compact transformer classifier | |
| Linear classifier |
| Network | Cell Type | Accuracy |
|---|---|---|
| SCM | NRRNCC | |
| SCT_1 | NRRNNN | |
| SCT_2 | NNRNRN |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, H.; Guo, S.; Sheng, W.; Xiao, L. SCM: A Searched Convolutional Metaformer for SAR Ship Classification. Remote Sens. 2023, 15, 2904. https://doi.org/10.3390/rs15112904
Zhu H, Guo S, Sheng W, Xiao L. SCM: A Searched Convolutional Metaformer for SAR Ship Classification. Remote Sensing. 2023; 15(11):2904. https://doi.org/10.3390/rs15112904
Chicago/Turabian StyleZhu, Hairui, Shanhong Guo, Weixing Sheng, and Lei Xiao. 2023. "SCM: A Searched Convolutional Metaformer for SAR Ship Classification" Remote Sensing 15, no. 11: 2904. https://doi.org/10.3390/rs15112904
APA StyleZhu, H., Guo, S., Sheng, W., & Xiao, L. (2023). SCM: A Searched Convolutional Metaformer for SAR Ship Classification. Remote Sensing, 15(11), 2904. https://doi.org/10.3390/rs15112904