

CBFM: Contrast Balance Infrared and Visible Image Fusion Based on Contrast-Preserving Guided Filter



Abstract
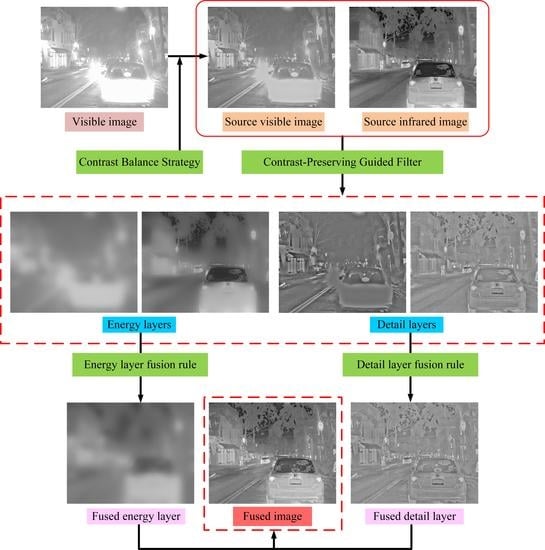
1. Introduction
- A novel IVIF algorithm based on contrast balance is proposed to effectively address the fusion challenge in complex environments, including maintaining reasonable contrast and detail fusion tasks affected by adverse phenomena such as overexposure, haze, and light diffusion.
- A novel contrast balance strategy is proposed to reduce the adverse effects of overexposure in the visible light image by decreasing the weight of the energy layers in the source image and supplementing the details.
- A contrast-preserving guided filter (CPGF) that constructs weights specifically for IVIF tasks is proposed. The IVIF outperforms the guided filter (GIF) and weighted GIF (WGF).
2. Materials and Methods
2.1. Contrast Balance Strategy
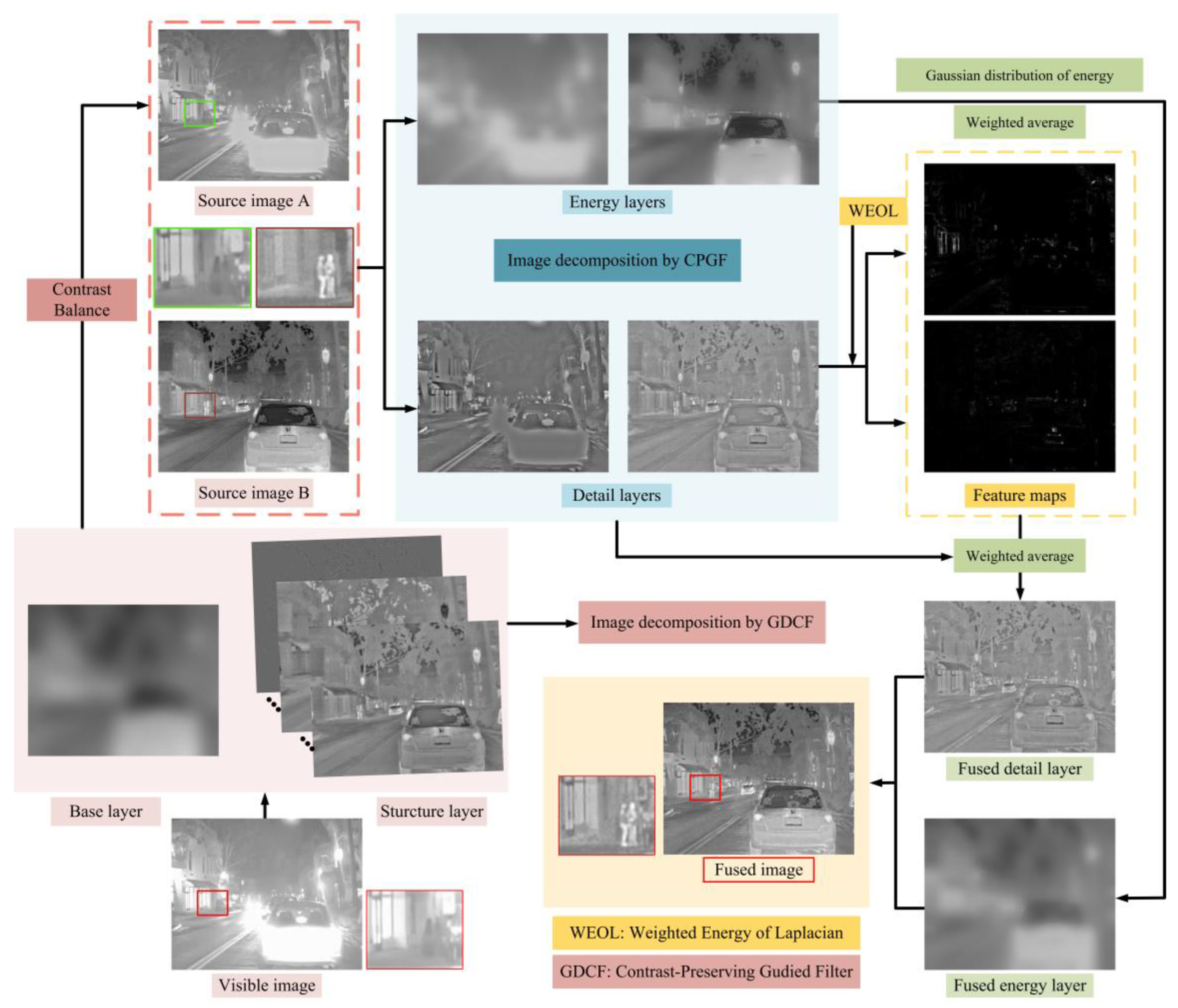
2.1.1. GDCF-based Multilayer Decomposition Strategy
2.1.2. Contrast Balance
2.2. Image Decomposition by CPGF
2.2.1. Proposed CPGF
2.2.2. Image Decomposition
2.3. Energy Layer Fusion
2.4. Detail Layer Fusion
2.5. Fusion Result Construction
3. Experiments
3.1. Experimental Setup
3.2. Parameter Analysis
3.3. Ablation Analysis
3.3.1. Ablation Analysis of Contrast Balance Strategy
3.3.2. Ablation Analysis of the Proposed Filter
3.4. Subjective Evaluation
3.5. Objective Evaluation
3.6. Computational Time
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, X.; Zhou, F.; Tan, H. Joint image fusion and denoising via three-layer decomposition and sparse representation. Knowl.-Based Syst. 2021, 224, 107087. [Google Scholar] [CrossRef]
- Li, X.; Wang, X.; Cheng, X.; Tan, H.; Li, X. Multi-Focus Image Fusion Based on Hessian Matrix Decomposition and Salient Difference Focus Detection. Entropy 2022, 24, 1527. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Gao, H.; Miao, Q.; Xi, Y.; Ai, Y.; Gao, D. MFST: Multi-Modal Feature Self-Adaptive Transformer for Infrared and Visible Image Fusion. Remote Sens. 2022, 14, 3233. [Google Scholar] [CrossRef]
- Li, H.; Cen, Y.; Liu, Y.; Chen, X.; Yu, Z. Different Input Resolutions and Arbitrary Output Resolution: A Meta Learning-Based Deep Framework for Infrared and Visible Image Fusion. IEEE Trans. Image Process. 2021, 30, 4070–4083. [Google Scholar] [CrossRef]
- Li, H.; Zhao, J.; Li, J.; Yu, Z.; Lu, G. Feature dynamic alignment and refinement for infrared–visible image fusion: Translation robust fusion. Inf. Fusion 2023, 95, 26–41. [Google Scholar] [CrossRef]
- Qi, B.; Jin, L.; Li, G.; Zhang, Y.; Li, Q.; Bi, G.; Wang, W. Infrared and visible image fusion based on co-occurrence analysis shearlet transform. Remote Sens. 2022, 14, 283. [Google Scholar] [CrossRef]
- Zhou, H.; Ma, J.; Yang, C.; Sun, S.; Liu, R.; Zhao, J. Nonrigid feature matching for remote sensing images via probabilistic inference with global and local regularizations. IEEE Geosci. Remote Sens. Lett. 2016, 13, 374–378. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J.; Durrani, T. NestFuse: An Infrared and Visible Image Fusion Architecture Based on Nest Connection and Spatial/Channel Attention Models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A general image fusion framework based on convolutional neural network. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Jiang, J.; Liu, R.; Luo, Z. Learning a Deep Multi-Scale Feature Ensemble and an Edge-Attention Guidance for Image Fusion. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 105–119. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Mei, X.; Ma, J. Infrared and visible image fusion based on target-enhanced multiscale transform decomposition. Inf. Sci. 2020, 508, 64–78. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Wu, K. Infrared and visible image fusion based on relative total variation decomposition. Infrared Phys. Technol. 2022, 123, 104112. [Google Scholar] [CrossRef]
- Nie, R.; Ma, C.; Cao, J.; Ding, H.; Zhou, D. A Total Variation With Joint Norms For Infrared and Visible Image Fusion. IEEE Trans. Multimed. 2022, 24, 1460–1472. [Google Scholar] [CrossRef]
- Mo, Y.; Kang, X.; Duan, P.; Sun, B.; Li, S. Attribute filter based infrared and visible image fusion. Inf. Fusion 2021, 75, 41–54. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J. Infrared and visible image fusion using latent low-rank representation. arXiv 2018, arXiv:1804.08992. [Google Scholar]
- Liu, X.; Wang, L. Infrared polarization and intensity image fusion method based on multi-decomposition LatLRR. Infrared Phys. Technol. 2022, 123, 104129. [Google Scholar] [CrossRef]
- Chen, Q.; Zhang, Z.; Li, G. Underwater Image Enhancement Based on Color Balance and Multi-Scale Fusion. IEEE Photonics J. 2022, 14, 3963010. [Google Scholar] [CrossRef]
- Liu, X.; Li, H.; Zhu, C. Joint Contrast Enhancement and Exposure Fusion for Real-World Image Dehazing. IEEE Trans. Multimed. 2022, 24, 3934–3946. [Google Scholar] [CrossRef]
- Raikwar, S.C.; Tapaswi, S. Lower Bound on Transmission Using Non-Linear Bounding Function in Single Image Dehazing. IEEE Trans. Image Process. 2020, 29, 4832–4847. [Google Scholar] [CrossRef]
- Li, H.; He, X.; Tao, D.; Tang, Y.; Wang, R. Joint medical image fusion, denoising and enhancement via discriminative low-rank sparse dictionaries learning. Pattern Recognit. 2018, 79, 130–146. [Google Scholar] [CrossRef]
- Tan, W.; Zhou, H.; Song, J.; Li, H.; Yu, Y.; Du, J. Infrared and visible image perceptive fusion through multi-level Gaussian curvature filtering image decomposition. Appl. Opt. 2019, 58, 3064–3073. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Kang, X.; Hu, J. Image Fusion with Guided Filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar] [CrossRef] [PubMed]
- Gong, Y.; Sbalzarini, I.F. Curvature Filters Efficiently Reduce Certain Variational Energies. IEEE Trans. Image Process. 2017, 26, 1786–1798. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Zheng, J.; Zhu, Z.; Yao, W.; Wu, S. Weighted Guided Image Filtering. IEEE Trans. Image Process. 2015, 24, 120–129. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Lin, Y.; Qu, X. An infrared and visible image fusion method based on multi-scale transformation and norm optimization. Inf. Fusion 2021, 71, 109–129. [Google Scholar] [CrossRef]
- Fang, Y.; Ma, K.; Wang, Z.; Lin, W.; Fang, Z.; Zhai, G. No-Reference Quality Assessment of Contrast-Distorted Images Based on Natural Scene Statistics. IEEE Signal Process. Lett. 2015, 22, 838–842. [Google Scholar] [CrossRef]
- Ou, F.-Z.; Wang, Y.-G.; Zhu, G. A novel blind image quality assessment method based on refined natural scene statistics. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1004–1008. [Google Scholar]
- Huang, W.; Jing, Z. Evaluation of focus measures in multi-focus image fusion. Pattern Recognit. Lett. 2007, 28, 493–500. [Google Scholar] [CrossRef]
- Fredembach, C.; Süsstrunk, S. Colouring the near infrared. In Proceedings of the IS&T/SID 16th Color Imaging Conference, Portland, OH, USA, 10–15 November 2008. [Google Scholar]
- Tang, L.; Xiang, X.; Zhang, H.; Gong, M.; Ma, J. DIVFusion: Darkness-free infrared and visible image fusion. Inf. Fusion 2023, 91, 477–493. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A Generative Adversarial Network With Multiclassification Constraints for Infrared and Visible Image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 5005014. [Google Scholar] [CrossRef]
- Zhou, H.; Wu, W.; Zhang, Y.; Ma, J.; Ling, H. Semantic-supervised Infrared and Visible Image Fusion via a Dual-discriminator Generative Adversarial Network. IEEE Trans. Multimed. 2021, 25, 635–648. [Google Scholar] [CrossRef]
- Wang, D.; Liu, J.; Fan, X.; Liu, R. Unsupervised misaligned infrared and visible image fusion via cross-modality image generation and registration. arXiv 2022, arXiv:2205.11876. [Google Scholar]
- Xydeas, C.S.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef]
- Liu, Z.; Blasch, E.; Xue, Z.; Zhao, J.; Laganiere, R.; Wu, W. Objective Assessment of Multiresolution Image Fusion Algorithms for Context Enhancement in Night Vision: A Comparative Study. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 94–109. [Google Scholar] [CrossRef]
- Estevez, P.A.; Tesmer, M.; Perez, C.A.; Zurada, J.A. Normalized Mutual Information Feature Selection. IEEE Trans. Neural Netw. 2009, 20, 189–201. [Google Scholar] [CrossRef]
- Cui, G.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Zheng, Y.; Essock, E.A.; Hansen, B.C.; Haun, A.M. A new metric based on extended spatial frequency and its application to DWT based fusion algorithms. Inf. Fusion 2007, 8, 177–192. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| QG | QM | QS | EN | AG | SF | |
|---|---|---|---|---|---|---|
| 0.05 | 0.5238 | 0.6027 | 0.7914 | 7.0539 | 4.9628 | 13.1062 |
| 0.07 | 0.5240 | 0.6123 | 0.7901 | 7.0659 | 5.0875 | 13.4770 |
| 0.1 | 0.5240 | 0.6203 | 0.7886 | 7.0770 | 5.1983 | 13.8106 |
| 0.2 | 0.5234 | 0.6296 | 0.7862 | 7.0930 | 5.3534 | 14.2851 |
| 0.3 | 0.5229 | 0.6338 | 0.7851 | 7.0994 | 5.4133 | 14.4711 |
| 0.4 | 0.5227 | 0.6345 | 0.7846 | 7.1028 | 5.4450 | 14.5696 |
| Methods | QG | QM | QS | EN | AG | SF |
|---|---|---|---|---|---|---|
| A-CBFM | 0.5333 | 0.5789 | 0.7680 | 7.1411 | 5.9602 | 15.6960 |
| B-CBFM | 0.5375 | 0.4986 | 0.7811 | 6.9772 | 4.7292 | 11.8979 |
| CBFM | 0.5327 | 0.5915 | 0.7665 | 7.1500 | 6.0415 | 15.9530 |
| Methods | QG | QM | QS | EN | AG | SF |
|---|---|---|---|---|---|---|
| LatLRR | 0.3990 | 0.4393 | 0.7786 | 6.9161 | 3.7787 | 10.1186 |
| RTVD | 0.4555 | 0.5538 | 0.7415 | 7.0207 | 4.1072 | 10.9419 |
| TEMF | 0.3657 | 0.4118 | 0.7335 | 6.9794 | 3.6752 | 9.8647 |
| MFEIF | 0.4312 | 0.4558 | 0.7832 | 7.0488 | 3.7644 | 9.5561 |
| U2Fusion | 0.4884 | 0.4514 | 0.8133 | 6.8021 | 4.6377 | 11.4237 |
| DIVFusion | 0.2883 | 0.3309 | 0.6213 | 7.5318 | 4.8050 | 11.6477 |
| GANMcC | 0.3606 | 0.4034 | 0.7126 | 7.2366 | 3.7788 | 9.0192 |
| SDDGAN | 0.3655 | 0.3946 | 0.7377 | 7.5261 | 4.3825 | 10.4413 |
| UMFusion | 0.4785 | 0.4771 | 0.8133 | 7.0474 | 4.0954 | 10.5501 |
| CBFM | 0.5489 | 0.7217 | 0.8186 | 7.1383 | 5.8674 | 15.2249 |
| Methods | QG | QM | QS | EN | AG | SF |
|---|---|---|---|---|---|---|
| LatLRR | 0.4176 | 0.3169 | 0.8251 | 7.1010 | 4.8726 | 14.0734 |
| RTVD | 0.4914 | 0.5246 | 0.7986 | 7.1284 | 5.1918 | 14.3747 |
| TEMF | 0.4268 | 0.3709 | 0.8085 | 6.8659 | 4.9588 | 14.0858 |
| MFEIF | 0.4642 | 0.3622 | 0.8330 | 7.1174 | 4.8914 | 12.8592 |
| U2Fusion | 0.4830 | 0.3106 | 0.8442 | 7.0989 | 6.3451 | 16.0479 |
| DIVFusion | 0.3029 | 0.2252 | 0.7218 | 7.5289 | 4.9692 | 12.0900 |
| GANMcC | 0.3847 | 0.2971 | 0.7791 | 7.1071 | 4.7454 | 12.6711 |
| SDDGAN | 0.3573 | 0.2654 | 0.7675 | 7.4608 | 4.3714 | 11.1505 |
| UMFusion | 0.4582 | 0.3566 | 0.8438 | 7.1387 | 5.1984 | 14.4103 |
| CBFM | 0.5246 | 0.4097 | 0.8277 | 7.1164 | 7.0740 | 20.2707 |
| Methods | Time | Methods | Time |
|---|---|---|---|
| LatLRR | 29.1462 | DIVFusion | 2.64 |
| RTVD | 0.5451 | GANMcC | 1.103 |
| TEMF | 0.01 | SDDGAN | 0.166 |
| MFEIF | 0.093 | UMFusion | 0.7692 |
| U2Fusion | 0.861 | CBFM | 8.5802 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Li, X.; Liu, W. CBFM: Contrast Balance Infrared and Visible Image Fusion Based on Contrast-Preserving Guided Filter. Remote Sens. 2023, 15, 2969. https://doi.org/10.3390/rs15122969
Li X, Li X, Liu W. CBFM: Contrast Balance Infrared and Visible Image Fusion Based on Contrast-Preserving Guided Filter. Remote Sensing. 2023; 15(12):2969. https://doi.org/10.3390/rs15122969
Chicago/Turabian StyleLi, Xilai, Xiaosong Li, and Wuyang Liu. 2023. "CBFM: Contrast Balance Infrared and Visible Image Fusion Based on Contrast-Preserving Guided Filter" Remote Sensing 15, no. 12: 2969. https://doi.org/10.3390/rs15122969
APA StyleLi, X., Li, X., & Liu, W. (2023). CBFM: Contrast Balance Infrared and Visible Image Fusion Based on Contrast-Preserving Guided Filter. Remote Sensing, 15(12), 2969. https://doi.org/10.3390/rs15122969