
Weather Radar Echo Extrapolation with Dynamic Weight Loss

 , , , , and
, , , , and
Abstract
:
1. Introduction
- (1)
- It is found that the prediction difficulty of each radar echo image in the spatiotemporal sequence prediction task is different at different training stages and that the error of the images gradually increases as the prediction time increases. Severe error accumulation leads to increasingly inaccurate extrapolation of results at a later stage. The existing MSE and MAE loss functions calculate the error directly for all images and have the same penalty weight for each prediction echo frame, so the model increasingly does not focus on the hard-to-predict images, which is a problem with how loss is calculated in the current study.
- (2)
- This study proposes a DWL method assigned to each frame. The error weights are calculated for each frame based on the model forecast results. Then, the losses are calculated for each frame, and finally, all losses are summed. We design a DWL function for radar precipitation forecasting, such that the level of attention given by the model to each frame changes dynamically and is determined by the model.
- (3)
- The Nanjing University C-band Polarimetric (NJU-CPOL) dataset is used to validate the method proposed in this study. The experimental results show that the proposed DWL method performs better compared to other loss methods, improves the performance of the ConvLSTM, ConvGRU, PredRNN and PredRNN++ models, and alleviates the error accumulation problem of radar precipitation forecasting to some extent.
2. Materials
2.1. Weather Radar Dataset
2.2. Deep Learning Model
2.2.1. ConvLSTM
2.2.2. ConvGRU
2.2.3. PredRNN
2.2.4. PredRNN++
3. Proposed Method
3.1. MSE and MAE Loss
3.2. Dynamic Weight
3.3. Dynamic Weight Loss
4. Experiment
4.1. Experimental Setup
4.2. Evaluation Metrics
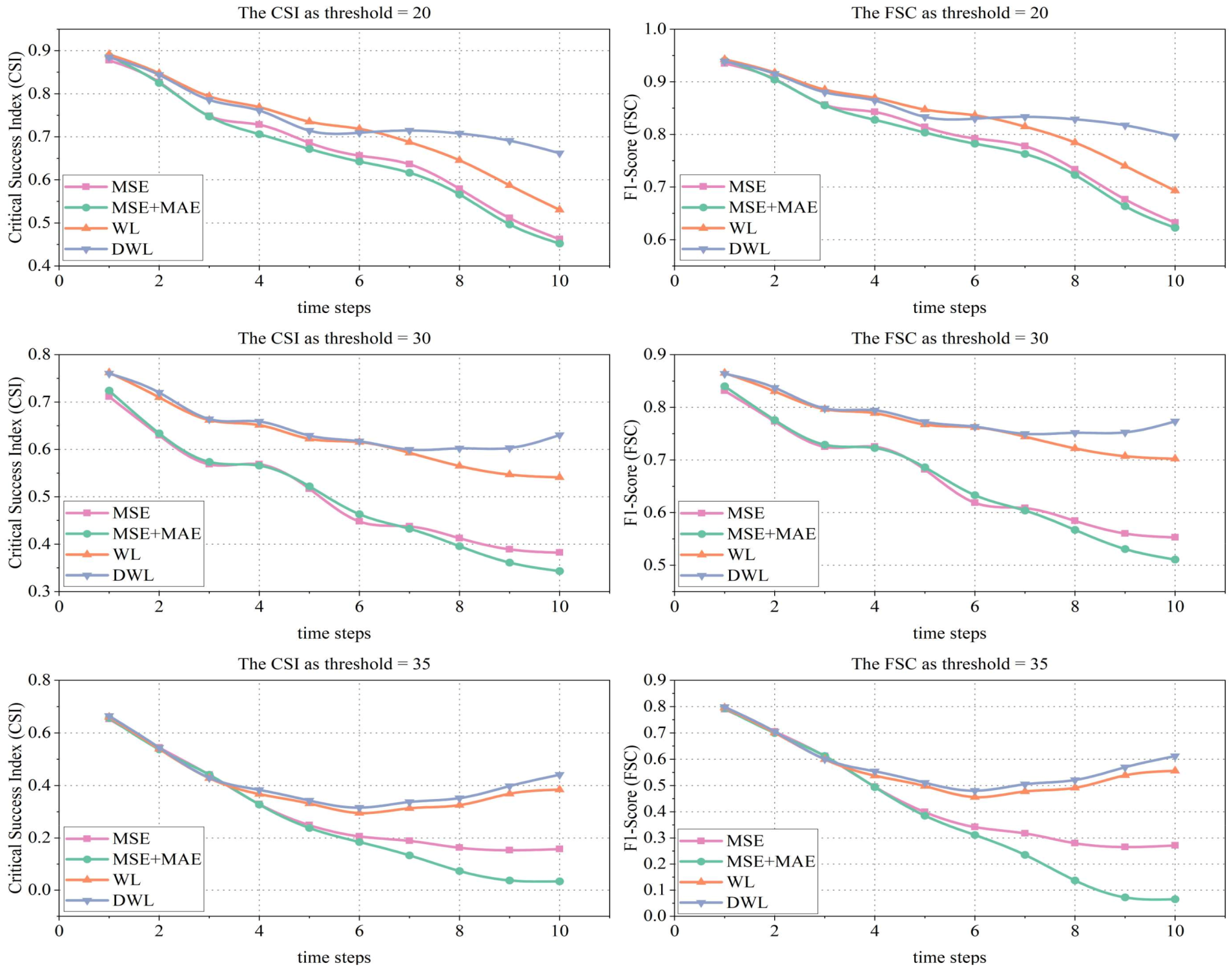
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Agrawal, S.; Barrington, L.; Bromberg, C.; Burge, J.; Gazen, C.; Hickey, J. Machine Learning for Precipitation Nowcasting from Radar Images. arXiv 2019, arXiv:191212132. [Google Scholar] [CrossRef]
- Ehsani, M.R.; Zarei, A.; Gupta, H.V.; Barnard, K.; Behrangi, A. Nowcasting-Nets: Deep Neural Network Structures for Precipitation Nowcasting Using IMERG. arXiv 2021, arXiv:210806868. [Google Scholar] [CrossRef]
- Sun, J.; Xue, M.; Wilson, J.W.; Zawadzki, I.; Ballard, S.P.; Onvlee-Hooimeyer, J.; Joe, P.; Barker, D.M.; Li, P.-W.; Golding, B.; et al. Use of NWP for Nowcasting Convective Precipitation: Recent Progress and Challenges. Bull. Am. Meteorol. Soc. 2014, 95, 409–426. [Google Scholar] [CrossRef] [Green Version]
- Woo, W.; Wong, W. Operational Application of Optical Flow Techniques to Radar-Based Rainfall Nowcasting. Atmosphere 2017, 8, 48. [Google Scholar] [CrossRef] [Green Version]
- Johnson, J.T.; Mackeen, P.L.; Witt, A.; Mitchell, E.D.W.; Stumpf, G.J.; Eilts, M.D.; Thomas, K.W. The Storm Cell Identification and Tracking Algorithm: An Enhanced WSR-88D Algorithm. Weather Forecast. 1998, 13, 263–276. [Google Scholar] [CrossRef]
- Rinehart, R.; Garvey, E. Three-Dimensional Storm Motion Detection by Conventional Weather Radar. Nature 1978, 273, 287–289. [Google Scholar] [CrossRef]
- Fang, W.; Zhang, F.; Sheng, V.S.; Ding, Y. SCENT: A New Precipitation Nowcasting Method Based on Sparse Correspondence and Deep Neural Network. Neurocomputing 2021, 448, 10–20. [Google Scholar] [CrossRef]
- Crane, R.K. Automatic Cell Detection and Tracking. IEEE Trans. Geosci. Electron. 1979, 17, 250–262. [Google Scholar] [CrossRef]
- Dixon, M.; Wiener, G. TITAN: Thunderstorm Identification, Tracking, Analysis, and Nowcasting—A Radar-Based Methodology. J. Atmos. Ocean. Technol. 1993, 10, 785–797. [Google Scholar] [CrossRef]
- Lanpher, A. Evaluation of the Storm Cell Identification and Tracking Algorithm Used by the WSR-88D. Ph.D. Thesis, Cornell University, Ithaca, NY, USA, 2012. [Google Scholar]
- Laroche, S.; Zawadzki, I. Retrievals of Horizontal Winds from Single-Doppler Clear-Air Data by Methods of Cross Correlation and Variational Analysis. J. Atmos. Ocean. Technol. 1995, 12, 721. [Google Scholar] [CrossRef]
- Zou, H.; Wu, S.; Shan, J.; Yi, X. A Method of Radar Echo Extrapolation Based on TREC and Barnes Filter. J. Atmos. Ocean. Technol. 2019, 36, 1713–1727. [Google Scholar] [CrossRef]
- Li, P.W.; Lai, E. Short-Range Quantitative Precipitation Forecasting in Hong Kong. J. Hydrol. 2004, 288, 189–209. [Google Scholar] [CrossRef]
- Bowler, N.E.; Pierce, C.E.; Seed, A. Development of a Precipitation Nowcasting Algorithm Based upon Optical Flow Techniques. J. Hydrol. 2004, 288, 74–91. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning Optical Flow with Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2758–2766. [Google Scholar]
- Ayzel, G.; Heistermann, M.; Winterrath, T. Optical Flow Models as an Open Benchmark for Radar-Based Precipitation Nowcasting (Rainymotion v0. 1). Geosci. Model Dev. 2019, 12, 1387–1402. [Google Scholar] [CrossRef] [Green Version]
- Marrocu, M.; Massidda, L. Performance Comparison between Deep Learning and Optical Flow-Based Techniques for Nowcast Precipitation from Radar Images. Forecasting 2020, 2, 194–210. [Google Scholar] [CrossRef]
- Liu, Y.; Xi, D.-G.; Li, Z.-L.; Hong, Y. A New Methodology for Pixel-Quantitative Precipitation Nowcasting Using a Pyramid Lucas Kanade Optical Flow Approach. J. Hydrol. 2015, 529, 354–364. [Google Scholar] [CrossRef]
- Hu, Y.; Chen, L.; Wang, Z.; Pan, X.; Li, H. Towards a More Realistic and Detailed Deep-Learning-Based Radar Echo Extrapolation Method. Remote Sens. 2021, 14, 24. [Google Scholar] [CrossRef]
- Jing, J.; Li, Q.; Ding, X.; Sun, N.; Tang, R.; Cai, Y. AENN: A Generative Adversarial Neural Network for Weather Radar Echo Extrapolation. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 89–94. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Q.; Li, H.; Zhang, T.; He, J.; Zhang, F.; Wang, H.; Qing, Z.; Yu, Q.; Shen, B. Prediction of Radar Echo Space-Time Sequence Based on Improving TrajGRU Deep-Learning Model. Remote Sens. 2022, 14, 5042. [Google Scholar] [CrossRef]
- Castro, R.; Souto, Y.M.; Ogasawara, E.; Porto, F.; Bezerra, E. Stconvs2s: Spatiotemporal Convolutional Sequence to Sequence Network for Weather Forecasting. Neurocomputing 2021, 426, 285–298. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU Neural Network Methods for Traffic Flow Prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- Qin, Y.; Song, D.; Chen, H.; Cheng, W.; Jiang, G.; Cottrell, G. A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction. arXiv 2017, arXiv:170402971. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.-Y.; Wong, W.; Woo, W. Deep Learning for Precipitation Nowcasting: A Benchmark and a New Model. Adv. Neural Inf. Process. Syst. 2017, 30, 5617–5627. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. Predrnn: Recurrent Neural Networks for Predictive Learning Using Spatiotemporal Lstms. Adv. Neural Inf. Process. Syst. 2017, 30, 879–888. [Google Scholar]
- Wang, Y.; Gao, Z.; Long, M.; Wang, J.; Philip, S.Y. Predrnn++: Towards a Resolution of the Deep-in-Time Dilemma in Spatiotemporal Predictive Learning. PMLR 2018, 80, 5123–5132. [Google Scholar]
- Fang, W.; Pang, L.; Yi, W.; Sheng, V.S. AttEF: Convolutional LSTM Encoder-Forecaster with Attention Module for Precipitation Nowcasting. Intell. Autom. Soft Comput. 2021, 30, 453–466. [Google Scholar] [CrossRef]
- He, W.; Xiong, T.; Wang, H.; He, J.; Ren, X.; Yan, Y.; Tan, L. Radar Echo Spatiotemporal Sequence Prediction Using an Improved Convgru Deep Learning Model. Atmosphere 2022, 13, 88. [Google Scholar] [CrossRef]
- Liu, L.; Zhen, J.; Li, G.; Zhan, G.; He, Z.; Du, B.; Lin, L. Dynamic Spatial-Temporal Representation Learning for Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 22, 7169–7183. [Google Scholar] [CrossRef]
- Ma, Z.; Zhang, H.; Liu, J. MS-RNN: A Flexible Multi-Scale Framework for Spatiotemporal Predictive Learning. arXiv 2022, arXiv:220603010. [Google Scholar] [CrossRef]
- Mathieu, M.; Couprie, C.; LeCun, Y. Deep Multi-Scale Video Prediction beyond Mean Square Error. arXiv 2015, arXiv:151105440. [Google Scholar] [CrossRef]
- Kim, B.; Han, M.; Shim, H.; Baek, J. A Performance Comparison of Convolutional Neural Network-Based Image Denoising Methods: The Effect of Loss Functions on Low-Dose CT Images. Med. Phys. 2019, 46, 3906–3923. [Google Scholar] [CrossRef] [PubMed]
- Jing, J.; Li, Q.; Peng, X.; Ma, Q.; Tang, S. HPRNN: A Hierarchical Sequence Prediction Model for Long-Term Weather Radar Echo Extrapolation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4142–4146. [Google Scholar]
- Rajkumar, S.; Malathi, G. A Comparative Analysis on Image Quality Assessment for Real Time Satellite Images. Indian J. Sci. Technol. 2016, 9, 1–11. [Google Scholar] [CrossRef]
- Hao, S.; Li, S. A Weighted Mean Absolute Error Metric for Image Quality Assessment. In Proceedings of the 2020 IEEE International Conference on Visual Communications and Image Processing (VCIP), Macau, China, 1–4 December 2020; pp. 330–333. [Google Scholar]
- Chen, H.; Chandrasekar, V.; Bechini, R. An Improved Dual-Polarization Radar Rainfall Algorithm (DROPS2. 0): Application in NASA IFloodS Field Campaign. J. Hydrometeorol. 2017, 18, 917–937. [Google Scholar] [CrossRef]
- Chen, H.; Chandrasekar, V. Estimation of Light Rainfall Using Ku-Band Dual-Polarization Radar. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5197–5208. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Yes | Predicted No | |
|---|---|---|
| Observed Yes | TP (true positive) | FN (false negative) |
| Observed No | FP (false positive) | TN (true negative) |
| ConvLSTM | CSI↑ | FSC↑ | MAE↓ | ||||
|---|---|---|---|---|---|---|---|
| Threshold | 20 | 30 | 35 | 20 | 30 | 35 | |
| MSE | 0.6713 | 0.5065 | 0.3084 | 0.7965 | 0.6661 | 0.4478 | 5.759 |
| MSE + MAE | 0.6613 | 0.5016 | 0.2665 | 0.7886 | 0.6600 | 0.3806 | 5.645 |
| WL | 0.7206 | 0.6270 | 0.4015 | 0.8331 | 0.7686 | 0.5650 | 5.616 |
| DWL | 0.7475 | 0.6485 | 0.4209 | 0.8539 | 0.7856 | 0.5856 | 5.148 |
| ConvGRU | CSI↑ | FSC↑ | MAE↓ | ||||
|---|---|---|---|---|---|---|---|
| Threshold | 20 | 30 | 35 | 20 | 30 | 35 | |
| MSE | 0.6886 | 0.5774 | 0.3722 | 0.8107 | 0.7273 | 0.5279 | 5.881 |
| MSE + MAE | 0.6259 | 0.5279 | 0.3357 | 0.7588 | 0.6806 | 0.4822 | 5.930 |
| WL | 0.7233 | 0.6345 | 0.4435 | 0.8368 | 0.7749 | 0.6088 | 5.781 |
| DWL | 0.7238 | 0.6424 | 0.4457 | 0.8374 | 0.7813 | 0.6108 | 5.569 |
| PredRNN | CSI↑ | FSC↑ | MAE↓ | ||||
|---|---|---|---|---|---|---|---|
| Threshold | 20 | 30 | 35 | 20 | 30 | 35 | |
| MSE | 0.6400 | 0.5727 | 0.3872 | 0.7731 | 0.7203 | 0.5400 | 5.899 |
| MSE + MAE | 0.6697 | 0.5734 | 0.3918 | 0.7971 | 0.7232 | 0.5452 | 5.657 |
| WL | 0.7121 | 0.6636 | 0.4620 | 0.8296 | 0.7975 | 0.6270 | 5.240 |
| DWL | 0.7293 | 0.6653 | 0.4655 | 0.8416 | 0.7987 | 0.6321 | 5.026 |
| PredRNN++ | CSI↑ | FSC↑ | MAE↓ | ||||
|---|---|---|---|---|---|---|---|
| Threshold | 20 | 30 | 35 | 20 | 30 | 35 | |
| MSE | 0.6919 | 0.6496 | 0.4824 | 0.8118 | 0.7856 | 0.6464 | 5.811 |
| MSE + MAE | 0.7254 | 0.6664 | 0.5022 | 0.8369 | 0.7986 | 0.6652 | 5.497 |
| WL | 0.7244 | 0.6730 | 0.5123 | 0.8369 | 0.8040 | 0.6739 | 5.241 |
| DWL | 0.7276 | 0.6909 | 0.5232 | 0.8383 | 0.8165 | 0.6843 | 5.019 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Geng, S.; Tian, W.; Ma, G.; Zhao, H.; Xie, D.; Lu, H.; Lim Kam Sian, K.T.C. Weather Radar Echo Extrapolation with Dynamic Weight Loss. Remote Sens. 2023, 15, 3138. https://doi.org/10.3390/rs15123138
Zhang Y, Geng S, Tian W, Ma G, Zhao H, Xie D, Lu H, Lim Kam Sian KTC. Weather Radar Echo Extrapolation with Dynamic Weight Loss. Remote Sensing. 2023; 15(12):3138. https://doi.org/10.3390/rs15123138
Chicago/Turabian StyleZhang, Yonghong, Sutong Geng, Wei Tian, Guangyi Ma, Huajun Zhao, Donglin Xie, Huanyu Lu, and Kenny Thiam Choy Lim Kam Sian. 2023. "Weather Radar Echo Extrapolation with Dynamic Weight Loss" Remote Sensing 15, no. 12: 3138. https://doi.org/10.3390/rs15123138