

Fast Frequency-Diverse Radar Imaging Based on Adaptive Sampling Iterative Soft-Thresholding Deep Unfolding Network
 , , ,
, , ,
Abstract
:1. Introduction
- (1)
- Data-driven deep reconstruction network: By training on large datasets of high-quality scene targets and measurements, the underlying non-linear relationship between the acquired measurements and the reconstructed scene targets can be directly learned by the deep neural network. The model-driven algorithm employs the network architecture’s feedforward capabilities to format images, removing iterations from the imaging process. Adaptive network parameter adjustments take place through the use of training data. The trained networks can thus be used to obtain scene targets given the echo signal, among which, particularly, the fully convolutional neural networks (FCNs) [25] and UNet [26] and deep residual networks [27] have been well utilized for image formation in sparse SAR and ISAR imaging [28,29,30].
- (2)
- Model-driven approach: Aiming at avoiding iterations optimization and sophisticated regularization parameters turning, model-driven methods [31,32,33] are built based on deep unfolding techniques that stem from the standard linear optimization algorithms, including IHT/IST [31] and ADMM networks [32] and AMP networks [33]. Each iteration of the algorithm is represented as a layer in the neural network, creating a deep network that performs a finite number of algorithm iterations when passing through. During backpropagation training, a number of model parameters of the algorithm can be converted to network parameters, resulting in a highly parameter-efficient network. In general, model-driven methods provide a promising direction for interpreting and optimizing iterative algorithms in combination with deep neural networks [34,35]. Overall, data-driven deep reconstruction neural networks are highly dependent on the abundance and multiplicity of training data, while, in comparison, data-driven methods with the unfolding technique could effectively use the training data and still maintain preferable image formation performance with limited amounts of training data.
2. Imaging Principle
3. Imaging Network Model
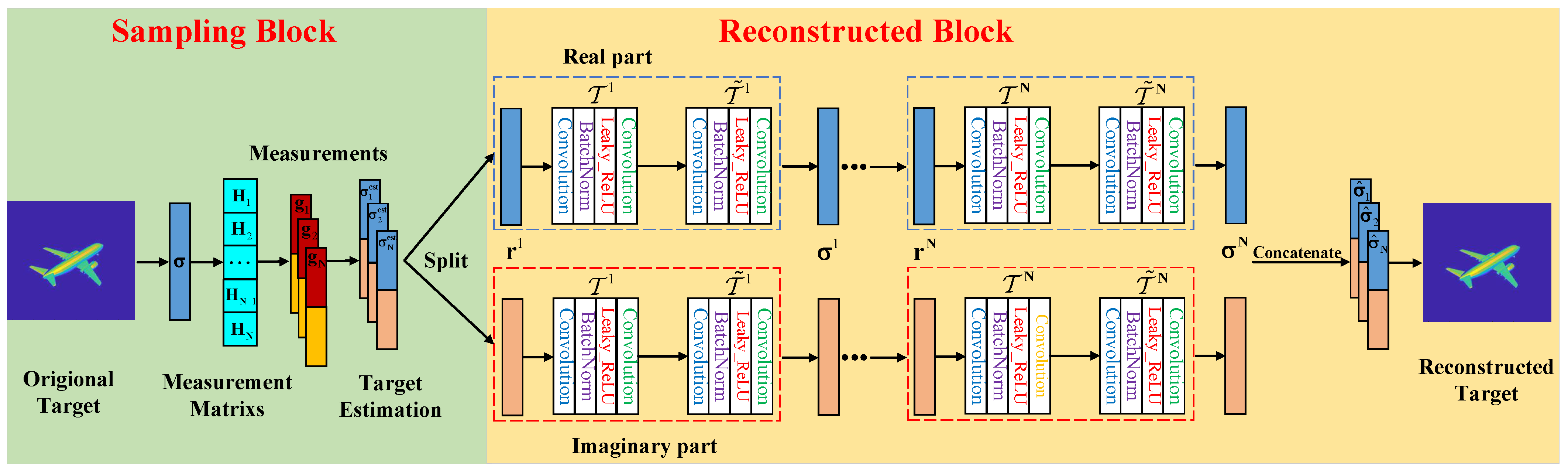
3.1. Imaging Network Framework
3.2. Imaging Reconstructed Algorithm
| Algorithm 1 ASISTA-Net training algorithm. |
Input: : measurement matrix; T: maximum training epochs; : Echo signal testing dataset; : Scene target training dataset; : Sparse transform basis; : step size; : optimization parameter.
Output: The target reflection coefficient estimate . |
4. Numerical Tests
4.1. Data Pre-Processing
4.2. Imaging Parameters
4.3. Numerical Tests
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| OEWG | Open Waveguide |
| CS | Compressed Sensing |
| SBL | Sparse Bayesian Learning |
| ISTA | Iterative Soft Thresholding Algorithm |
| VAE | Variational Autoencoders |
| MSE | Mean Squared Error |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structure Similarity Index Measure |
| SNR | Signal-to-Noise Ratio |
| FCNN | Fully Convolutional Neural Network |
| BM3D | Block Matching and 3D Filtering |
| PnP | Plug-and-Play |
| ADAM | Adaptive Momentum Estimation |
| ASISTA-Net | Adaptive Sampling Iterative Soft-Thresholding Network |
References
- Luo, Z.; Cheng, Y.; Cao, K.; Qin, Y.; Wang, H. Microwave computational imaging in frequency domain with reprogrammable metasurface. J. Electron. Imaging 2018, 27, 063019. [Google Scholar] [CrossRef]
- Wu, Z.H.; Zhang, L.; Liu, H.W. Enhancing microwave metamaterial aperture radar imaging with rotation synthesis. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 3683–3686. [Google Scholar]
- Wang, S.; Li, X.; Chen, P. ADMM-SVNet: An ADMM-Based Sparse-View CT Reconstruction Network. Photonics 2022, 9, 186. [Google Scholar] [CrossRef]
- Liu, Z.; Bicer, T.; Kettimuthu, R.; Gursoy, D.; De Carlo, F.; Foster, I. TomoGAN: Low-Dose Synchrotron X-ray Tomography with Generative Adversarial Networks:discussion. J. Opt. Soc. Am. A 2020, 37, 422–434. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, Y.; Sun, J.; Li, H.; Xu, Z. Deep ADMM-Net for Compressive Sensing MRI. In Proceedings of the 30th International Conference on Neural Information Processing Systems(NIPS), Barcelona, Spain, 5–10 December 2016; pp. 10–18. [Google Scholar]
- Han, J.Y. Research of Human Security Holographic Radar Imaging Algorithm. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2019. [Google Scholar]
- Donoho, D. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Nguyen, T.V.; Jagata, G.; Hegde, C. Provable Compressed Sensing With Generative Priors via Langevin Dynamics. IEEE Trans. Inf. Theory 2022, 68, 7410–7422. [Google Scholar] [CrossRef]
- Dong, Y. Frequency diverse array radar signal and data processing. IET Radar Sonar Navig. 2018, 12, 954–963. [Google Scholar] [CrossRef]
- Fromenteze, T.; Yurduseven, O.; Del Hougne, P.; Smith, D.R. Lowering latency and processing burden in computational imaging through dimensionality reduction of the sensing matrix. Sci. Rep. 2021, 11, 3545. [Google Scholar] [CrossRef]
- Imani, M.F.; Gollub, J.N.; Yurduseven, O.; Diebold, A.V.; Boyarsky, M.; Fromenteze, T.; Pulido-Mancera, L.; Sleasman, T.; Smith, D.R. Review of Metasurface Antennas for Computational Microwave Imaging. IEEE Trans. Antennas Propag. 2020, 68, 1860–1875. [Google Scholar] [CrossRef] [Green Version]
- Mait, J.N.; Euliss, G.W.; Athale, R.A. Computational imaging. Adv. Opt. Photonics 2018, 10, 409–483. [Google Scholar] [CrossRef]
- Dauwels, J.; Srinivasan, K. Improved compressed sensing radar by fusion with matched filtering. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 6795–6799. [Google Scholar]
- Tuo, X.; Zhang, Y.; Huang, Y. A Fast Forward-looking Super-resolution Imaging Method for Scanning Radar based on Low-rank Approximation with Least Squares. In Proceedings of the 2020 IEEE Radar Conference (RadarConf20), Florence, Italy, 21–25 September 2020; pp. 1–6. [Google Scholar]
- Yue, Y.; Liu, H.; Meng, X.; Li, Y.; Du, Y. Generation of High-Precision Ground Penetrating Radar Images Using Improved Least Square Generative Adversarial Networks. Remote Sens. 2021, 13, 4590. [Google Scholar] [CrossRef]
- Fromenteze, T.; Decroze, C.; Abid, S.; Yurduseven, O. Sparsity-Driven Reconstruction Technique for Microwave/Millimeter-Wave Computational Imaging. Sensors 2018, 18, 1536. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, J.; Hu, G.; Zhang, X.; Sun, F.; Zhou, H. Sparsity-Based Two-Dimensional DOA Estimation for Coprime Array: From Sum–Difference Coarray Viewpoint. IEEE Trans. Signal Process. 2017, 65, 5591–5604. [Google Scholar] [CrossRef]
- Cheng, Q.; Ihalage, A.; Liu, Y.; Hao, Y. Compressive Sensing Radar Imaging with Convolutional Neural Networks. IEEE Access 2020, 8, 212917–212926. [Google Scholar] [CrossRef]
- Wu, Z.; Zhao, F.; Zhang, M.; Huan, S.; Pan, X.; Chen, W.; Yang, L. Fast Near-Field Frequency-Diverse Computational Imaging Based on End-to-End Deep-Learning Network. Sensors 2022, 22, 9771. [Google Scholar] [CrossRef]
- Jin, K.; McCann, M.T.; Froustey, E.; Unser, M. Deep Convolutional Neural Network for Inverse Problems in Imaging. IEEE Trans Image Process. IEEE Trans. Image Process. 2017, 26, 4509–4522. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, J.; Kobayashi, R.; Muramatsu, S.; Jeon, G. Image Restoration with Structured Deep Image Prior. In Proceedings of the 2021 36th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Jeju, Republic of Korea, 27–30 June 2021; pp. 1–4. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef]
- Liu, S.; Wang, Y.; Yang, X.; Lei, B.; Liu, L.; Li, S.X.; Ni, D.; Wang, T. Deep Learning in Medical Ultrasound Analysis: A Review. Engineering 2019, 5, 261–275. [Google Scholar] [CrossRef]
- Hu, C.; Wang, L.; Li, Z.; Zhu, D. Inverse Synthetic Aperture Radar Imaging Using a Fully Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1203–1207. [Google Scholar] [CrossRef]
- Luo, F.; Wang, J.; Zeng, J.; Zhang, L.; Zhang, B.; Xu, K.; Luo, X. Cascaded Complex U-Net Model to Solve Inverse Scattering Problems With Phaseless-Data in the Complex Domain. IEEE Trans. Antennas Propag. 2022, 70, 6160–6170. [Google Scholar] [CrossRef]
- Yao, H.; Dai, F.; Zhang, S.; Zhang, Y.; Tian, Q.; Xu, C. DR2-Net: Deep Residual Reconstruction Network for Image Compressive Sensing. Neurocomputing 2019, 359, 483–493. [Google Scholar] [CrossRef] [Green Version]
- Yang, T.; Shi, H.Y.; Lang, M.Y.; Guo, J.W. ISAR imaging enhancement: Exploiting deep convolutional neural network for signal reconstruction. Int. J. Remote Sens. 2020, 41, 9447–9468. [Google Scholar] [CrossRef]
- Wu, Z.; Zhao, F.; Zhang, M.; Qian, J.; Yang, L. Real-Time Phaseless Microwave Frequency-Diverse Imaging with Deep Prior Generative Neural Network. Remote Sens. 2022, 14, 5665. [Google Scholar] [CrossRef]
- Li, X.; Bai, X.; Zhang, Y.; Zhou, F. High-Resolution ISAR Imaging Based on Plug-and-Play 2D ADMM-Net. Remote Sens. 2022, 14, 901. [Google Scholar] [CrossRef]
- Wang, M.; Wei, S.; Liang, J.; Zeng, X.; Wang, C.; Shi, J.; Zhang, X. RMIST-Net: Joint Range Migration and Sparse Reconstruction Network for 3-D mmW Imaging. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5205117. [Google Scholar] [CrossRef]
- Li, R.; Zhang, S.; Zhang, C.; Liu, Y.; Li, X. Deep Learning Approach for Sparse Aperture ISAR Imaging and Autofocusing Based on Complex-Valued ADMM-Net. IEEE Sens. J. 2021, 21, 3437–3451. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Y.; Liu, J.; Wen, F.; Zhu, C.; Feng, X. AMP-Net: Denoising-Based Deep Unfolding for Compressive Image Sensing. IEEE Trans. Image Process. 2021, 30, 1487–1500. [Google Scholar] [CrossRef] [PubMed]
- You, D.; Zhang, J.; Xie, J.; Chen, B.; Ma, S. COAST: COntrollable Arbitrary-Sampling NeTwork for Compressive Sensing. IEEE Trans. Image Process. 2021, 30, 6066–6080. [Google Scholar] [CrossRef] [PubMed]
- You, D.; Xie, J.; Zhang, J. ISTA-NET++: Flexible Deep Unfolding Network for Compressive Sensing. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Song, J.; Chen, B.; Zhang, J. Memory-Augmented Deep Unfolding Network for Compressive Sensing. In Proceedings of the 29th ACM International Conference on Multimedia (ACM MM), Chengdu, China, 20–24 October 2021; pp. 4249–4258. [Google Scholar]
- Chen, B.; Zhang, J. Content-Aware Scalable Deep Compressed Sensing. IEEE Trans. Image Process. 2022, 31, 5412–5426. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Operation bandwidth | 33–37 GHz |
| Antenna panel size | mm |
| Number of resonance units | |
| Frequency sampling interval | 5 MHz |
| Field of view (Azimuth) | – |
| Field of view (Elevation) | – |
| Azimuth sampling interval | |
| Elevation sampling interval | |
| Dimensions of T |
| Methods | MSE | PSNR | SSIM | Run Time |
|---|---|---|---|---|
| ISTA | 0.0035 | 24.08 | 0.65 | 3.14 |
| SBL | 0.0029 | 24.55 | 0.67 | 2.37 |
| VAE | 0.0011 | 29.58 | 0.83 | 0.35 |
| CC-Unet | 0.0009 | 30.45 | 0.85 | 0.27 |
| ASISTA-Net | 0.0006 | 32.21 | 0.91 | 0.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Z.; Zhao, F.; Zhang, L.; Cao, Y.; Qian, J.; Xu, J.; Yang, L. Fast Frequency-Diverse Radar Imaging Based on Adaptive Sampling Iterative Soft-Thresholding Deep Unfolding Network. Remote Sens. 2023, 15, 3284. https://doi.org/10.3390/rs15133284
Wu Z, Zhao F, Zhang L, Cao Y, Qian J, Xu J, Yang L. Fast Frequency-Diverse Radar Imaging Based on Adaptive Sampling Iterative Soft-Thresholding Deep Unfolding Network. Remote Sensing. 2023; 15(13):3284. https://doi.org/10.3390/rs15133284
Chicago/Turabian StyleWu, Zhenhua, Fafa Zhao, Lei Zhang, Yice Cao, Jun Qian, Jiafei Xu, and Lixia Yang. 2023. "Fast Frequency-Diverse Radar Imaging Based on Adaptive Sampling Iterative Soft-Thresholding Deep Unfolding Network" Remote Sensing 15, no. 13: 3284. https://doi.org/10.3390/rs15133284
APA StyleWu, Z., Zhao, F., Zhang, L., Cao, Y., Qian, J., Xu, J., & Yang, L. (2023). Fast Frequency-Diverse Radar Imaging Based on Adaptive Sampling Iterative Soft-Thresholding Deep Unfolding Network. Remote Sensing, 15(13), 3284. https://doi.org/10.3390/rs15133284