1. Introduction
Understanding the water cycle is crucial for various natural phenomena, such as floods, landslides, and droughts, which pose significant risks to human lives [
1]. Soil surface characteristics, particularly moisture content and surface roughness, play a vital role in water cycle monitoring [
2,
3,
4,
5,
6]. While ground measurements can accurately estimate these parameters, they are often time-consuming, labor-intensive, and limited in spatial representation [
7]. Observations collected through remote sensing from space provide effective resources for tracking and mapping changes across vast regions both spatially and over time, which is needed for reliable predictions of water cycle behaviors [
8]. In the case of plot-scale soil surface characteristics estimation, low spatial resolution measurements provided by sensors like SMOS, SMAP, and ASCAT are unsuitable [
9]. To overcome this low spatial resolution limitation, the open source and free-of-charge Sentinel-1A and -1B Synthetic Aperture Radar (SAR) sensors operating in the C-band have been introduced, offering high spatial resolution soil surface characteristics mapping [
10].
In areas with sparse vegetation cover, Synthetic Aperture Radar (SAR) data operating in the C-band have emerged as a valuable tool for estimating soil moisture. Among the models employed to simulate the SAR signal, the Integral Equation Model (IEM), a physical model developed by Fung [
11], has gained considerable attention. Fung’s IEM possesses the advantage of not requiring site-specific calibration, as it can consistently be used to simulate backscattering coefficients based on radar configuration (frequency, polarization, and incidence angle) and soil parameters (soil moisture and soil roughness). However, Fung’s IEM has shown discrepancies between simulated and observed SAR data [
12]. The IEM accurately replicates radar scatter on smooth surfaces. However, it under-performs on rough surfaces, where it predicts a more uniform response with incidence angle than what is observed in C- and X-band signals. Baghdadi et al. [
13,
14] addressed this challenge by proposing a semi-empirical calibration for the IEM. This calibration was designed to enhance the precision of simulated backscattering values by accounting for the difficulties in measuring the correlation length input parameter. Furthermore, it has been shown that for bare soil fields and at high incidence angles, surface roughness has a more significant impact on the radar signal in the C-band than soil surface moisture (SSM) [
15]. Consequently, estimating soil moisture from SAR data without considering the contribution of the root mean surface height (HRMS) would lead to imprecise soil moisture estimations with underestimation for low HRMS values and overestimation for higher values [
16].
When comparing state-of-the-art soil moisture estimation approaches, we observe notable differences among them. These variations are primarily attributed to the machine learning approach used for each soil moisture estimation model. Exploring a different approach, Nativel et al. [
17] proposed a methodology that combines their improved change detection index with an artificial neural network (ANN) trained on Sentinel-1 and Sentinel-2 data and data from the International Soil Moisture Network (ISMN) to enhance soil moisture retrieval accuracy at a 1 km scale. The findings indicate a marked enhancement in soil moisture predictions employing the hybrid algorithms, specifically, the change detection algorithm coupled with a neural network. Compared to utilizing either the neural network or the change detection alone, the hybrid approach boosts the correlation by 54% and 33%, respectively, highlighting its superior efficacy. Chung et al. [
18] trained an ANN model on Sentinel-1 SAR imagery to estimate soil moisture content Their model was trained using a variety of hydrological components, including soil texture, topography, and precipitation data using a leave-one-out approach. The ANN model that uses all the previously cited hydrological components exhibited superior performance in terms of accuracy compared to ANNs trained only on some components. In the testing phase, when only topographical factors were added, the RMSE on soil moisture improved slightly to 7.39 vol.%. With the inclusion of soil attributes, the RMSE decreased further to 6.57 vol.%. The best performance, however, was observed when all data features were used, resulting in the lowest RMSE of 5.79 vol.%. Underlining the efficacy of their approach, Hamze et al. [
7] focused on integrating L-band derived soil roughness into C-band Synthetic Aperture Radar (SAR) data to improve soil moisture retrieval. Their approach involved training different categories of neural networks on synthetic data generated by the calibrated IEM to estimate the soil roughness from PALSAR data (L-band) and the soil moisture from Sentinel-1 data (C-band) using the estimated soil roughness. The introduction of L-band-derived soil roughness into the inversion approach led to an important reduction in the RMSE of the estimated soil moisture (approximately 2.0 vol.%). Lastly, Mirsoleimani et al. [
19] investigated the potential of Sentinel-1 SAR data for estimating bare soil surface moisture over an agricultural area in Iran. Using radar backscattering models and an inversion technique based on neural networks, they found that the calibrated IEM model yielded slightly higher accuracy in estimating the soil moisture than the modified Dubois model, with an RMSE on soil moisture of 3 vol.% with the calibrated IEM and 3.3 vol.% with the modified Dubois.
One of the prevailing approaches being employed to estimate surface soil moisture from SAR data involves the inversion of backscatter simulation models using machine learning algorithms, specifically neural networks [
7,
17,
18,
19]. The backscatter models are used to build a synthetic database of simulated backscattering coefficients for various soil conditions and sensor attributes; then, neural networks are trained to estimate soil moisture on this synthetic database [
14]. A key enhancement to this approach has been the use of a priori weather information in order to partition the estimation domain into dry or wet conditions, leading to the application of one of two distinct neural networks, each specifically trained for either dry to wet (between 4 and 30 vol.%) or very wet (between 20 and 40 vol.%) soil conditions [
16].
Our study builds upon the approach introduced by El Hajj et al. [
16] and presents a fully autonomous solution based on Sentinel-1 (S1) images (without external data such as precipitation for example) to overcome the need for a priori weather information. In previous versions of the algorithm, weather data like precipitation and temperature were vital inputs used to guide the inversion algorithm in the estimation of soil moisture. The improved algorithm, proposed in this study, now relies on the average S1 radar signal, which is calculated on bare soil pixels and those with little vegetation within large areas of a few km
each (10 km × 10 km grid cells). The hypothesis is inspired by the research of Bazzi et al. [
20,
21], establishing a strong correlation between the radar signal of bare or lightly vegetated soils and precipitation, with an increase in radar signal following heavy rainfall. Thus, a high signal corresponds to high soil moisture within the study area, which is mainly due to heavy rains. By utilizing the backscattering coefficients at the grid scale (a few km
), we can deduce the weather conditions used for the estimation domain partitioning without the need for a priori weather information. The second main objective is to study the potential of incorporating soil roughness estimates into the soil moisture estimation procedure, thereby analyzing the accuracy of surface soil moisture estimation when accounting for the influence of surface roughness on radar backscattering. The added value of using grid data and soil roughness estimates was studied in comparison to the previous models on the synthetic dataset generated by the calibrated IEM [
13] and on a real dataset taken from two study sites where in situ soil moisture and soil roughness measurements are available.
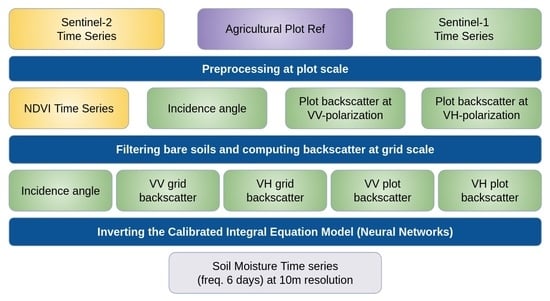
3. Methodology
In this section, we introduce our experimental setups for inverting Sentinel-1 signals in order to estimate soil moisture. First, inversion models are described. Then, the model architecture and the process of model training and optimization are presented. Finally, the different input/output configurations of the inversion model as well as the precision metrics used for the models evaluation are detailed.
3.1. Inversion Algorithm
This study focuses on estimating soil moisture content using radar backscattering coefficients as input data (inverse Equations (
2) and (
3)). Therefore, the problem is formulated as developing a model that can effectively estimate soil moisture levels based on the provided radar backscattering coefficients, enabling a better understanding and monitoring of soil moisture dynamics. In fact, the inversion model uses the neural network technique trained on the synthetic dataset described in the previous section in order to inverse the radar signal. The trained neural networks are then used to estimate soil moisture using the real backscatter computed from Sentinel-1 images.
Given an input vector of S1 radar measurements, we want to learn the function
that maps the radar measurements to soil moisture values MV. This problem can be formulated as:
where the the inputs are
—the radar backscatter coefficient (dB) at VV and VH polarizations (Sentinel-1 configuration) provided by the satellite images and spatially averaged at plot (VVp and VHp) or grid scales (VVg and VHg),
—the associated incidence angle (°), and
—the soil roughness value (if available). In the vector
,
w denotes the weights and
b denotes the bias of the neural network
.
denotes the estimation error. One of the objectives of this study is to find the best attribute configuration with the minimum
.
The adopted neural network architecture is composed of two hidden layers. The first layer is associated with a linear activation function, while the second hidden layer uses a tangent sigmoid activation function. Both hidden layers contain 20 neurons each [
16]. In fact, after comparing this neural network with other machine learning models (gradient-boosted decision tree and multi-layer perceptron), we found that the added value of changing the machine learning model can be ignored in relation to the added value of changing the machine learning model’s attributes. Let
and
be the weight matrices of dimensions
and
, respectively, and let
and
be the bias vectors of dimensions
and
, respectively. For the first hidden layer, we use a linear transfer function, which is denoted as
. For the second hidden layer, we use a tangent sigmoid transfer function, which is denoted as
, and for the last layer, we use the identity function, which is denoted as
. The forward pass can be formulated as:
- (a)
First hidden layer (linear transfer function):
- (b)
Second hidden layer (tangent sigmoid transfer function):
- (c)
Output layer:
where
x is the input vector containing the sensor attributes values and
is the estimated output.
The optimization problem aims to minimize a loss function
, where
is the estimated output and
y is the observed output. We want to find the optimal weight matrices
and bias vectors
that minimize the loss function:
with
.
This is typically achieved through an iterative process such as gradient descent, which updates the weights and biases based on the gradients of the loss function with respect to the model parameters. In our case the optimization technique used is the Levenberg–Marquardt (LM) algorithm [
26] (see
Appendix A). The Levenberg–Marquardt (LM) algorithm is a popular optimization technique that combines the features of gradient descent and the Gauss–Newton method, making it particularly suitable for solving nonlinear least-squares problems (see
Appendix A). The LM algorithm is applied to our neural networks (
) for training by minimizing the sum of squared errors (SSE) loss function. The Levenberg–Marquardt algorithm is an optimization algorithm that does not require a learning step but uses instead an adaptive damping factor, which has a default value of 1. This quasi-Newton optimization approach assumes that the function being optimized can be locally approximated by a second-order Taylor series. The process generally begins with an initial guess, employs the Jacobian matrix to determine the steepest descent direction, and utilizes the Hessian matrix to calculate the descent step to the next point. This process continues until there is no improvement in the loss value by at least
.
3.2. Evaluated Sentinel-1 Configurations
Various configurations aimed at optimizing soil moisture estimation accuracy were evaluated. These configurations involve the integration of Sentinel-1 polarizations, partitioning the estimation domain into dry and wet conditions, incorporating a Sentinel-1 large-scale signal thanks to the grid backscatter coefficients, and training neural networks with soil roughness estimates.
Three inversion Sentinel-1 configurations were tested: (1) VV polarization alone; (2) VH polarization alone; and (3) both VV and VH polarizations. In this configuration, the soil roughness parameter HRMS is ignored. They can be formulated as:
Using the same polarizations as in the previous configuration, we separate our MVp solution search domain into two domains: one with a search for a solution for dry to slightly wet soil conditions and one for a solution for wet to very wet soil conditions. This configuration needs a priori information on MVp (a priori dry to slightly wet or very wet). Partitioning the estimation domain into distinct dry and wet conditions and training dedicated neural networks for each domain may significantly enhance soil moisture estimation accuracy [
16]. By focusing on domain-specific patterns and relationships, the specialized neural networks can capture the complexities associated with soil moisture variations more effectively. In the case of a priori dry to slightly wet soil,
will be built up using the synthetic training dataset elements with MVp between 4 and 30 vol.%. Contrarily, in the case of a priori very wet soil conditions,
will be developed using the synthetic training dataset elements with MVp between 20 and 40 vol.%. An overlap of 10 vol.% on MVp is considered between the dry to slightly wet and the very wet training datasets of
. During the evaluation, the dry
is applied on attributes with MVp < 25, while the wet
is applied on attributes with MVp ≥ 25. The 25 vol.% moisture threshold is the midpoint between the two moisture ranges applied to the neural network for dry/wet and very wet conditions. Both this midpoint value and the selected ranges are grounded in field observations where soils are usually very wet following substantial rainfall, typically recording humidity between 25 and 40 vol.%. The dry to wet conditions correspond to soil after an absence of precipitation (dry for the summer following a prolonged lack of rain and wet generally in the autumn or winter after a relatively short duration without rain). In an operational context, the choice between
or
is determined by meteorological data, primarily focusing on precipitation. For example, if there has been significant rainfall one or two days before the S1 acquisition, the
would be used; otherwise, the
is applied. In this configuration, the soil roughness parameter HRMS is ignored.
In this configuration, we hypothesize that incorporating backscatter coefficients at the grid scale into the soil moisture estimation process, in addition to backscatter coefficients at the plot scale, can improve the accuracy of MVp estimation, potentially offering an alternative to the domain-separated approach which necessitates weather data for selecting the appropriate neural network (dry to slightly wet or very wet). This hypothesis assumes that integrating grid coefficients can inform
about the soil moisture status in the study area, enabling the inversion model to adapt to both dry and wet soil characteristics. We also chose to use both polarizations as its the most precise configurations. There are two subcases of configuration 3, which are formulated as:
Equation (
11) gives a detailed presentation of the neural networks and their inputs used in configuration 3. In
only
was used; this network was trained using the backscatter coefficients for VV and VH polarizations on the grid and plot scales. In
, three
were used:
is trained to estimate
using the backscatter coefficients for VV and VH on the grid scale, and the
value estimated from
will serve as a dry/wet domain separator. If the estimated
vol.%, the config will use
in order to estimate
; otherwise, it will use
. The second and third
values were trained using the backscatter coefficients for VV and VH polarizations on the grid and plot scales:
uses backscatter coefficients on
vol.% and
uses backscatter coefficients on
vol.%. In this configuration, the soil roughness parameter HRMS is ignored.
In this last configuration, we hypothesize that training neural networks with soil roughness estimates, in conjunction with incorporating grid backscatter coefficients and partitioning estimation domains, can potentially improve soil moisture estimation accuracy. This hypothesis suggests that by accounting for the complex relationships between soil moisture, surface roughness, and backscatter signals, neural networks can better capture the intricacies of soil moisture variations across various surface conditions. There are two subcases of configuration 4, which are formulated as:
In
two
values were used.
was trained to estimate the soil roughness using the backscatter coefficients for VV and VH polarizations on the grid and plot scales, while
was trained to estimate the soil moisture using the backscatter coefficients for VV and VH polarizations on the grid and plot scales in addition to soil roughness. Furthermore, to account for the uncertainties on HRMS estimated from SAR images [
7] in the training phase, a zero-mean Gaussian noise was added to HRMS with a standard deviation of 0.5. The estimated
value from
is used to estimates
.
In , five were used; like in , is used to separate the estimation domain of and into two domains: dry–wet/very wet using the same thresholds on as . Then, is estimated according to dry or wet conditions ( or ), and then, this estimate of HRMS is used in the network to estimate MVp ( or ).
Note that configurations 1 and 2 have already been tested by El Hajj et al. [
16] and that in our study, they serve as benchmarks for configurations 3 and 4.
3.3. Evaluation Metrics
The first evaluation metric used is the root mean squared error (RMSE). RMSE is a valuable metric in soil moisture estimation due to its comprehensive assessment of accuracy, emphasis on larger errors, and clear interpretability. Its consideration of larger discrepancies ensures significant errors are addressed. It can be formulated as:
with
N representing the number of data,
denoting the observed value for the
i-th data point, and
denoting the estimated value for the
i-th data point.
The second evaluation metric used is bias. The bias metric serves as an important evaluation tool due to its interpretability and ability to quantify systematic error. By measuring the average difference between estimated and observed values, the bias metric offers valuable insights into the model’s overall performance. This metric enables us to identify and understand the extent to which a model consistently overestimates or underestimates the target variable:
The third evaluation metric used is the mean absolute percentage error (MAPE). MAPE is an essential evaluation metric that provides a clear understanding of a model’s prediction accuracy in terms of relative error. It computes the average percentage differences between estimated and observed values:
5. Discussion
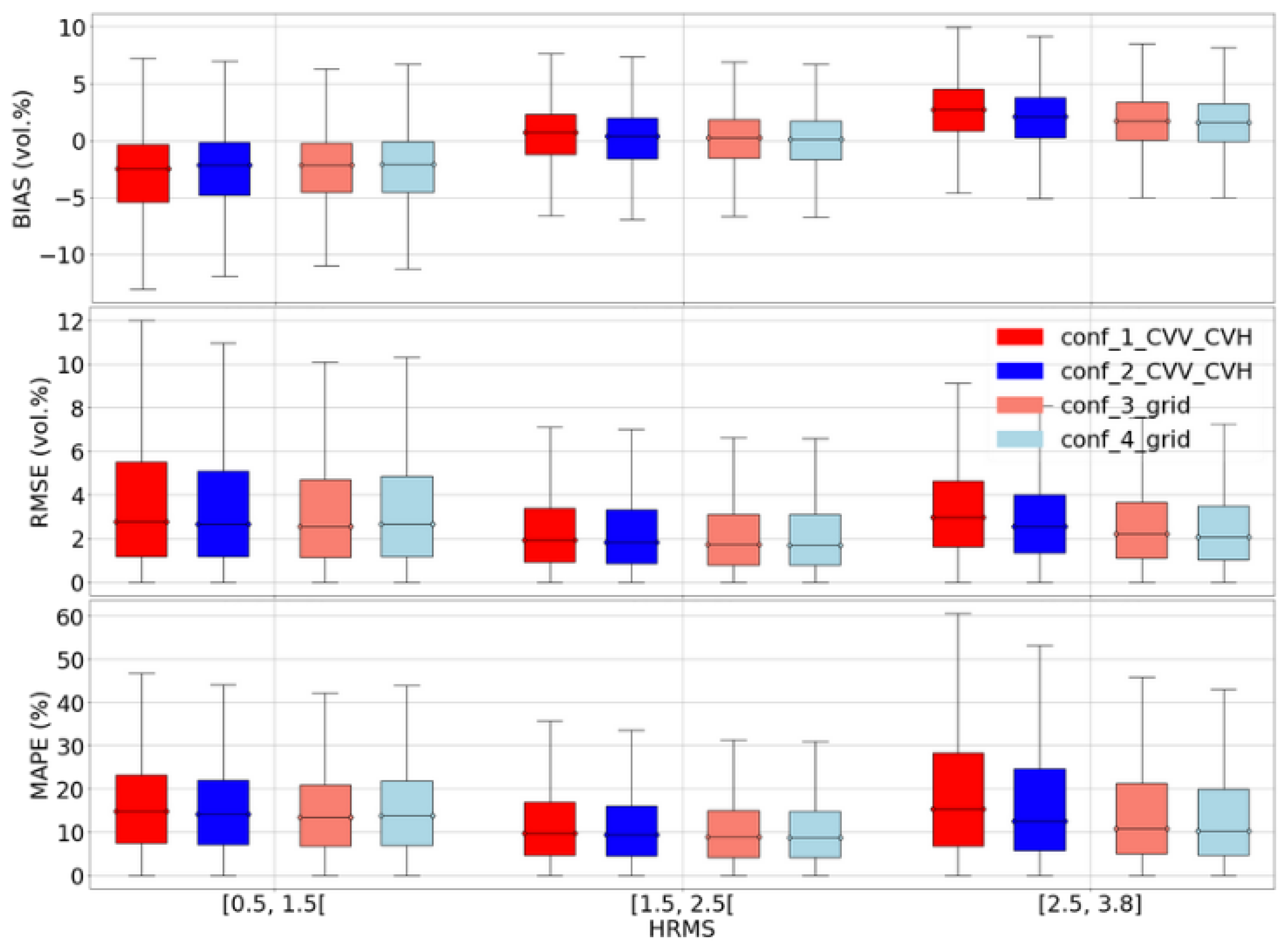
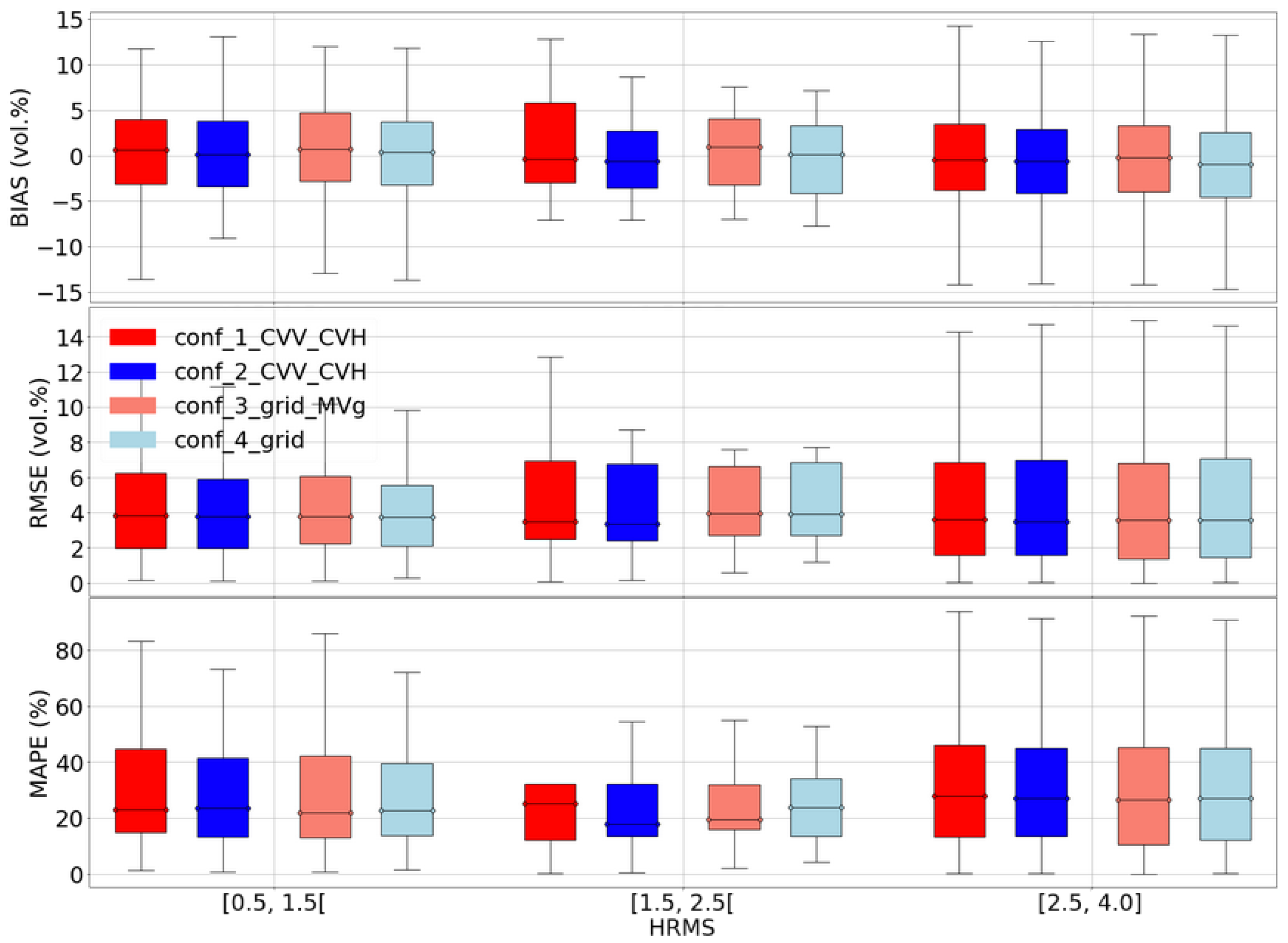
In this part, we discuss the limitations of our S1 signal inversion procedures. The first limitation concerns the accuracy of our model results, which may be due to an incorrect choice to use a dry network instead of a wet network (configurations 2, 3, and 4). This issue arises in cases where some fields are irrigated, such as in the Kairouan study site. Indeed, for an irrigated site, the moisture of a plot can be very low (if not irrigated) or very high (if the plot is irrigated), while the radar signal at the grid scale is probably low if only a few plots are irrigated or very high if most of the plots are irrigated at a very close time (this is unlikely). Thus, the soil moisture of recently irrigated plots could be underestimated during the summer. The dry NN will be used during this time of year even if some plots are irrigated because most of the other plots are not irrigated (MVg is generally lower than 20 vol.%). This underestimation will occur since the dry NN will have difficulty estimating moisture above 20 vol.%.
Figure 9 shows this underestimation of soil moisture for recently irrigated plots in the Kairouan study site, while the dry NN performs well for plots with moisture lower than 20 vol.%.
For agricultural soil, the backscattered radar signal is heavily influenced by factors such as soil roughness, dielectric properties (including moisture content and soil composition), and characteristics of the vegetation (such as biomass, vegetation water content, and geometry of vegetation elements). Following a rainfall or irrigation event, the soil moisture eventually increases, which corresponds to an increase in the radar signal. Irrigation not only alters soil moisture but also the surface roughness, as it generally leads to a slight decrease in soil roughness. However, the effect of irrigation on roughness is typically not taken into account because (1) this slight decrease in roughness is challenging to measure, and (2) this minor decrease in roughness will have a significantly smaller effect on the radar signal compared to the effect caused by the substantial increase in soil moisture. Hence, for a given S1 date where the soils are mostly dry (lack of rainfall for a long time), the dry network will be used in configurations 2, 3 and 4 in order to estimate the soil moisture even if some fields are very wet after a recent irrigation event. Similarly, for configurations 3 and 4 with the use of MVg estimates in input to
for estimating MVp, the low and medium values of estimated MVg corresponding to dry to slightly wet soil conditions even with some irrigated fields in each grid cell will inform the network that will estimate MVp that overall, we are in dry to moderately wet soil conditions (at grid scale), while for some fields, the moisture content can be very high because they have been irrigated very recently. Thus, the presence of irrigated fields could lead to a strong underestimation of MVp for irrigated fields. The bias values in
Figure 10 and
Figure 11 are stronger for Kairouan (irrigated site). For example, MVP is underestimated by about 10 vol.% in very wet conditions (MVP between 27.5 and 32.5 vol.%) for Kairouan against 7 vol.% for Montpellier (non-irrigated site). In addition,
Figure 11 shows that configurations 2, 3 and 4 demonstrate better performance on non-irrigated parcels (lower bias and RMSE with respect to the median value).
The second limitation pertains to the generation of our dataset. The data generation process involves fixing grid soil moisture (MVg) values between 4 and 40 vol.% and then generating 100 samples of soil moisture at the plot scale (MVp) for each combination of incidence angle and soil roughness. These samples are created using a bounded normal distribution with a mean value equal to the grid soil moisture and a standard deviation of 10 vol.%. The generated MVp samples are constrained within the range [MVg − 10, MVg + 10], and soil moisture at the plot scale is filtered to retain only values between 4 and 40 vol.%. Capping the values in this manner can lead to an unbalanced dataset, as MVg values below 14 and above 30 do not have MVp samples centered on MVg with a standard deviation of 10. This constraint results in a limited representation of soil moisture variability for these particular MVg ranges. Consequently, the dataset becomes skewed, with certain soil moisture ranges being underrepresented. This imbalance negatively impacts the model’s performance, particularly in scenarios where soil moisture values fall within the underrepresented ranges, potentially leading to biased or inaccurate results.
The results obtained with configuration 4 which uses an estimation of the roughness in input to
to estimate the soil moisture are not very conclusive because of the limiting Sentinel-1 sensor’s instrumental characteristics for mapping the soil roughness (C-band, VV and VH polarizations, incidence angles between 25° and 45°). Numerous results show that the radar signal in the C-band is strongly dependent on surface roughness mainly for low levels of roughness [
11,
13]. The studies showed that the sensitivity of the radar signal to surface roughness increases with the incidence angle. Baghdadi et al. [
13] have shown that high incidence angles (45°) are best suited to the discrimination between smooth and rough areas. Furthermore, when the incidence angle is low (between 20° and 35°), the backscattering coefficient rapidly attains its maximum value for roughness values around 1 cm (HRMS values of less than 1 cm are rare in agricultural areas). Therefore, for agricultural applications, soil-roughness mapping is not feasible using C-band SAR data at a low incidence angles due to the rapid saturation of the radar signal. Concerning the polarization effect, we observe theoretically and from experimental studies a higher dynamic to soil roughness for HH and VH than with VV polarization [
5,
11,
12]. This literature review shows that Sentinel-1 data are not optimal for a good estimation of soil roughness. Thus, an unreliable estimate of roughness in
does not provide an improvement in moisture estimation compared to the case where soil roughness is not considered a parameter of
.
The radar signal, which depends on various radar parameters (polarization, incidence angle, and frequency), is also correlated, for bare soils, with soil surface roughness and moisture content [
11]. In an inversion approach, we are led to estimate the two soil parameters MV and HRMS or only one of the two parameters if we have information on the second parameter. Estimating both soil parameters requires two input channels. The ideal way would be to have at least two decorrelated channels: for example, two different incidence angles (one low 25° and one high 45°) or two different radar frequencies (C and L for example). This is not possible because the available SAR sensors are mono-wavelength and acquire, on a given date, a backscattered signal at a single incidence angle. However, on a given date, Sentinel-1 acquires data at the C-band and at only one incidence (the incidence angle value depends on the position of the pixel in the image) but with two polarizations VV and VH. As VV and VH are not completely decorrelated for the estimation of soil parameters, the use of both VV and VH in the inversion approach of SAR images does not always allow a good optimization of the estimated values of MVp and HRMS. This ambiguity in the estimation of the couple (MVp, HRMS) can sometimes occur mainly in the case of soils with a low HRMS value and high MVp value or vice versa.
In this study, as in previous studies before it, the incorporation of coarse soil moisture information over a given site is of great interest to improve the estimation of soil moisture. In [
16,
29], the introduction of expert knowledge on the soil moisture (dry to wet soils or very wet soils) using meteorological data (e.g., precipitations, temperature) reduced the errors on the soil moisture estimates by one-third. By adding a priori information on the humidity, the inversion of the radar signal is performed on half of the space (MVp, HRMS), thus reducing the ambiguity in the retrieval problem. This paper has successfully tested the use of a feature computed from Sentinel-1 input data instead of using meteorological data which are not always free, open access, and available in real time, thus making the inversion chain completely independent. This feature is highly correlated with rainfall and corresponds to the average of the Sentinel-1 signal at large scale (grid cells of 5 km × 5 km). In fact, Bazzi et al. [
20,
30]) showed that the S1 backscattering signal averaged over a few km
(using the bare agricultural pixels) is strongly correlated with rainfall and can be used as an indicator for the soil moisture content at the date of passage of S1.
6. Conclusions
This study aimed to develop a fully autonomous solution (without external data such as precipitation, for example) for high-resolution soil moisture mapping in bare agricultural areas using Sentinel-1 data, while eliminating the need for a priori weather information, which is sometimes required for better accuracy on soil moisture estimates. Algorithms based on neural networks were trained on a synthetic dataset generated by the radar backscattering model IEM and validated using real data from two study sites in Montpellier (France) and Kairouan (Tunisia). The results showed that our proposed algorithms were able to estimate soil moisture with high accuracy. The use of the backscattering coefficients at plot scale as well as those at grid scale defined by the average of all bare soil pixel values within each grid cell allowed for the inference of global soil moisture conditions at a large scale.
Combining VV and VH polarizations (configuration 1) consistently improves accuracy compared to using either polarizations individually. Separating the estimation domain into dry and wet conditions (configuration 2) highlights the importance of using a priori information on the global soil moisture state in the study site, yielding even better results when both VV and VH polarizations are used, with about 14% gain using the synthetic dataset and 5% gain on the real dataset in RMSE compared to the best configuration without domain separation. Incorporating grid information (configuration 3) optimizes accuracy without the need for weather information with about an 18% gain on the synthetic dataset (slightly better than the configuration that separates the estimation domain using weather information) and a 5% gain on the real dataset in RMSE compared to the first configuration. Finally, while integrating soil roughness estimates (configuration 4) does slightly enhance estimation accuracy, the improvements are negligible as to the complexity of the architecture (five NNs compared to just one). Overall, the combined use of VV and VH polarizations and incorporating grid information offers the best soil moisture estimation accuracy. This approach led to an RMSE on soil moisture of 3.5 vol.% on the synthetic dataset and 5.9 vol.% using the real dataset. These performances are similar to accuracies obtained with the top-performing configuration that leverages a priori weather information. The use of soil roughness estimates provides a marginal contribution to the inversion process.
Our Sentinel-1 signal inversion procedures have revealed limitations. Firstly, the accuracy of the inversion model based on the use of grid information or incorporating a priori information on soil moisture (dry to slightly wet condition or very wet condition) can be compromised due to the inappropriate choice of a dry or wet network for estimating soil moisture, especially in areas with irrigation practices. Secondly, the results from configuration 4, which estimates soil roughness, are inconclusive due to the instrumental characteristics of the Sentinel-1 sensor. Indeed, the C-band of Sentinel-1 is not the optimum wavelength for soil roughness mapping as well as the incidence angles which are lower than 40–45° for a wide part of Sentinel-1 images. Lastly, the high dependence of the radar signal on both soil roughness and moisture content leads to an ambiguity in the estimation of soil moisture when the inversion model estimates only the soil moisture without taking into account roughness or when the inversion model cannot estimate correctly both soil roughness and moisture content (SAR layers in the input are insufficient). Despite these limitations, integrating coarse soil moisture information (average moisture over large areas) has been demonstrated to improve soil moisture estimation at the plot scale.
The scope of this study was purposefully limited to bare soil to ensure a streamlined analysis by eliminating the effect of vegetation on the signal radar over agricultural plots. Having successfully conducted an analysis with bare soil, the methodology could be improved by utilizing the Water Cloud Model (WCM), which incorporates not only bare soil conditions but also vegetated soil. This model efficiently caters to scenarios involving both bare and vegetated soils. With this expansion, we could potentially apply our method broadly to estimate soil moisture on agricultural plots regardless of whether they are bare or vegetated. This constitutes a promising avenue for future research and applications.



 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}