
Spectral–Temporal Transformer for Hyperspectral Image Change Detection


Abstract
:1. Introduction
- (1)
- HSIs consist of a number of spectral bands that afford detailed spectral information. CNNs are vector-based methods that process input data as collections of pixel vectors. Consequently, due to this narrow perception, CNNs are deemed unsuitable for effectively processing the rich spectral information in HSIs.
- (2)
- CNN-based methods are designed to extract features from local regions of an image and typically perform poorly when capturing long-distance sequential dependencies. This is because CNNs lack the ability to model nonlinear relationships between distant inputs and require larger receptive fields to capture such relationships.
- (3)
- The identification of subtle changes in HSIs is heavily reliant on the temporal dependency between bi-temporal features. The above methods, which employ Siamese-based networks to extract bi-temporal image features independently, are insufficient when addressing the regions of change and exploiting the temporal dependency of HSIs.
- (1)
- The STT is designed with a global spectrum–time-receptive field, enabling the joint capture of spectral information and temporal dependency. By concatenating the feature embeddings in spectral order, the STT learns different representative features between two bands, regardless of spectral or temporal distance, strengthening the utilization of temporal change information.
- (2)
- We propose a Spectral–Temporal Transformer (STT) for HSI CD, which is the first time the HSI CD task is processed from a completely sequence-based perspective. This enables us to adaptively capture the discriminative sequential properties, e.g., the correlation and variability between different spectral bands and temporal dependency.
2. Proposed Method
2.1. Vanilla Transformer
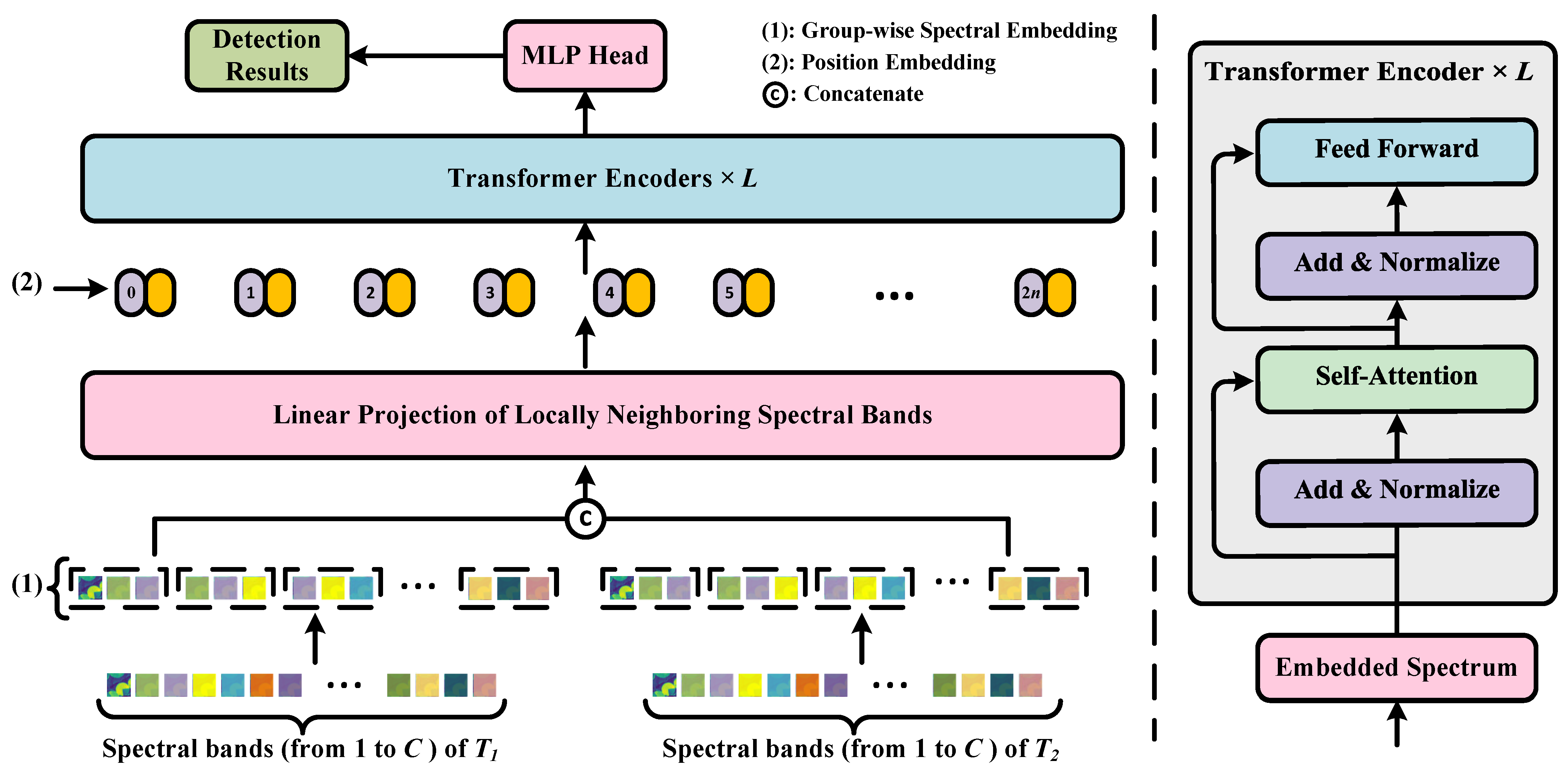
2.2. Spectral–Temporal Transformer
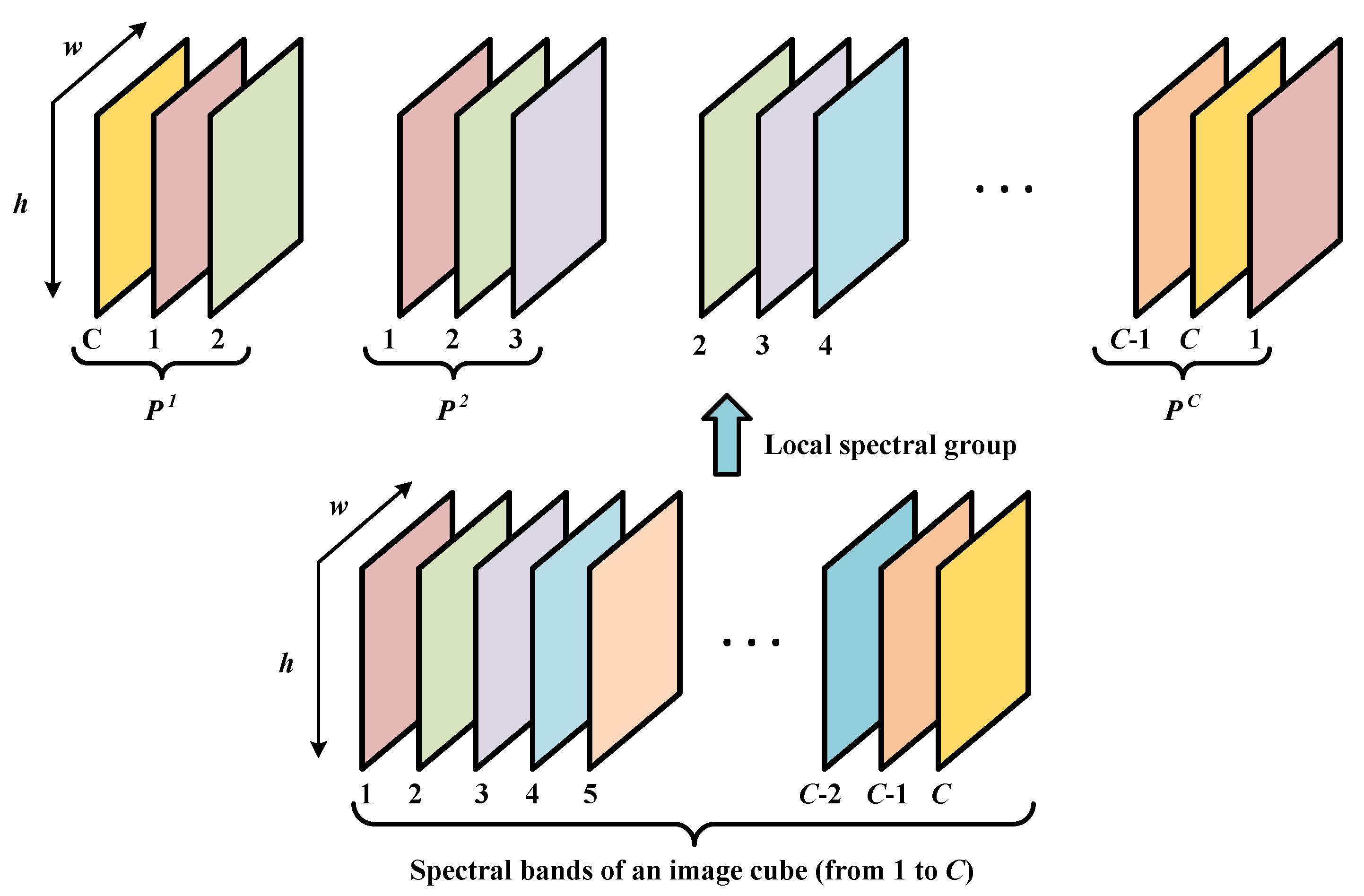
2.2.1. Global Spectral–Temporal Receptive Filed
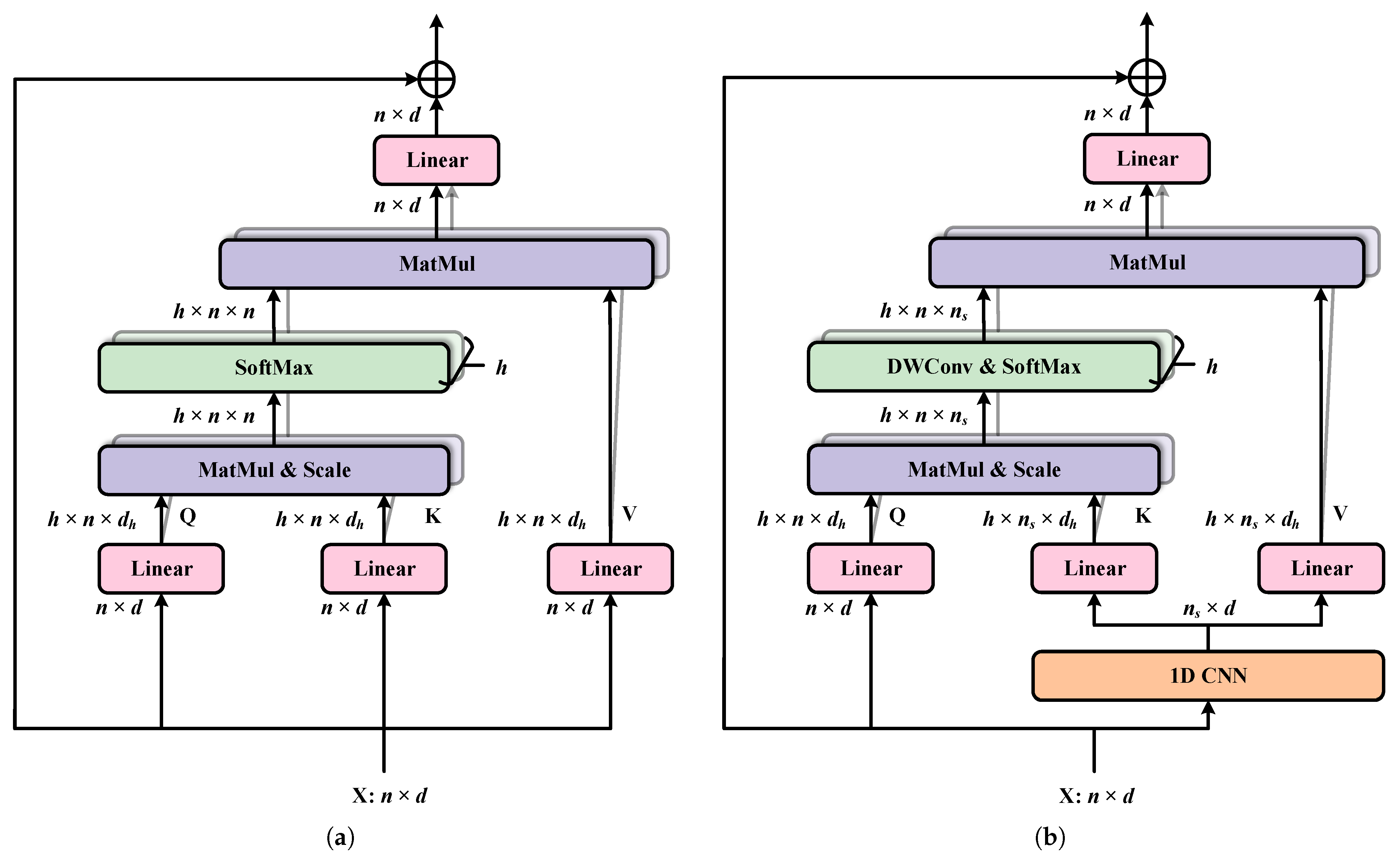
2.2.2. Efficient Multi-Head Self-Attention Block
2.3. Loss Function
3. Results
3.1. Data Description
3.1.1. Farmland
3.1.2. Hermiston
3.1.3. River
3.2. Experimental Settings
3.2.1. Evaluation Metrics
3.2.2. Comparative Methods
- (1)
- CVA [7] is a classical method for CD that measures the differences in each band to detect the change regions.
- (2)
- PCA–CVA [10] employs principal component analysis to maximize the change information, and then CVA is used to detect the change regions.
- (3)
- TDRD [13] is a tensor-based framework that exploits the high-level semantic information of hyperspectral data by tensor decomposition and reconstruction.
- (4)
- Untrained CNN (UTCNN) [23] extracts low-level semantic features with the help of CNN’s own structure, which is not trained.
- (5)
- Recurrent 3D Fully Convolutional Network (Re3FCN) [32] combines a 3D convolutional layer and a ConvLSTM layer to model the temporal change information while maintaining the spatial structure.
- (6)
- ReCNN [34] combines the strengths of both CNN and RNN to extract fused features from bi-temporal images. To expand the receptive field, dilated convolution is employed.
- (7)
- Cross-temporal interaction Symmetric Attention Network (CSANet) [49] designs an attention-enhanced symmetric network that employs cross-temporal attention to strengthen the change information obtained from different temporal features.
- (8)
- SST–Former [52] is a Transformer-based model that sequentially extracts the spatial, spectral, and temporal information of HSIs for CD.
3.2.3. Implementation Details
3.3. Experimental Results
3.3.1. Results of Farmland Dataset
3.3.2. Results of Hermiston Dataset
3.3.3. Results of River Dataset
3.4. Parameter Sensitivity Analysis
3.4.1. The Number of Neighboring Bands
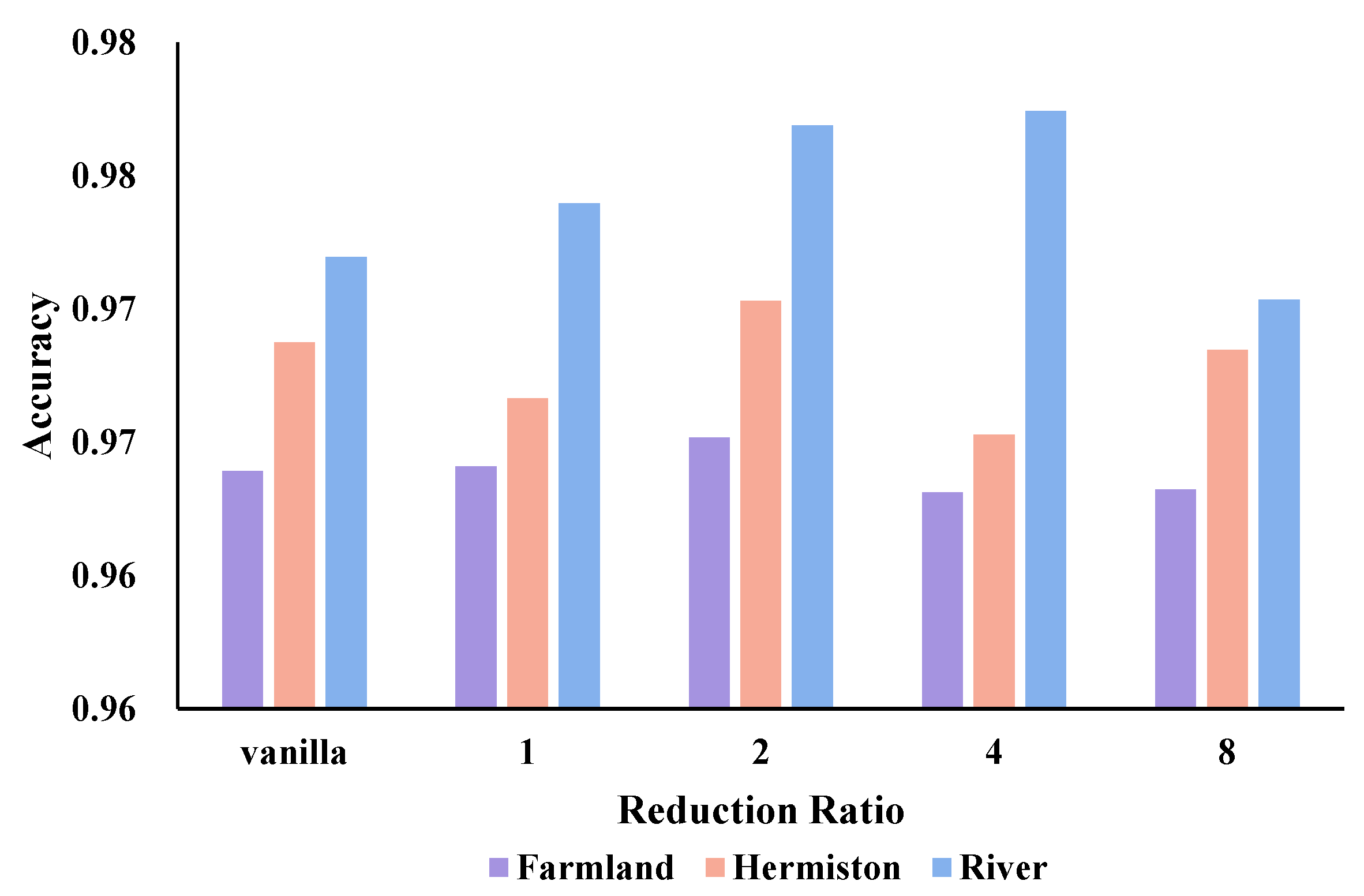
3.4.2. The Reduction Ratio of Efficient Self-Attention Design
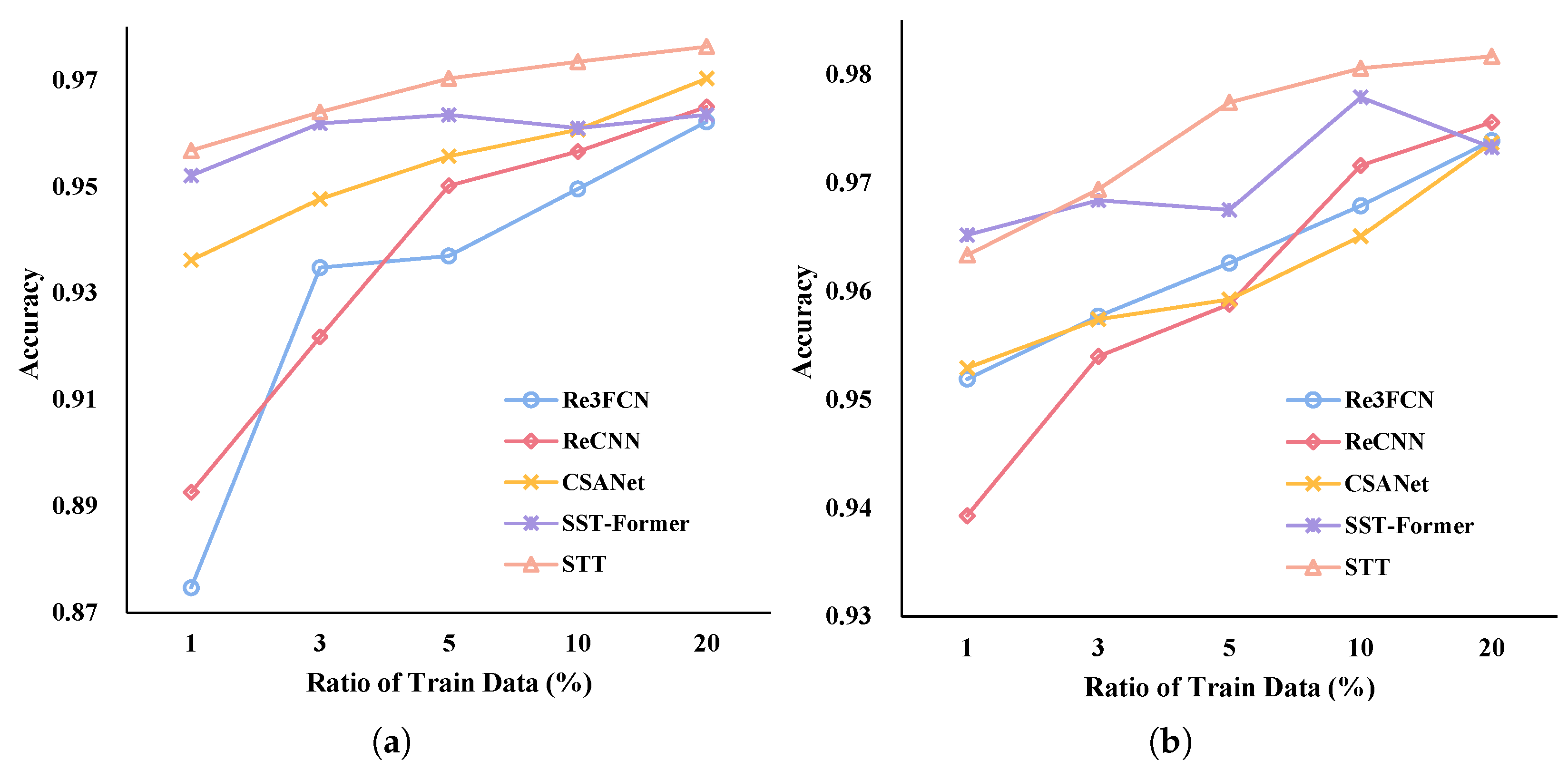
3.4.3. The Number of Training Samples
3.5. Ablation Experiments
3.5.1. Group-Wise Spectral Embedding
3.5.2. Efficient Multi-Head Self-Attention
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Borana, S.; Yadav, S.; Parihar, S. Hyperspectral Data Analysis for Arid Vegetation Species: Smart & Sustainable Growth. In Proceedings of the 2019 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS), Greater Noida, India, 18–19 October 2019; pp. 495–500. [Google Scholar]
- Chang, S.; Kopp, M.; Ghamisi, P. Multiview Subspace Learning for Hyperspectral Anomalous Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Rokni, K.; Ahmad, A.; Selamat, A.; Hazini, S. Feature Extraction and Change Detection Using Multitemporal Landsat Imagery. Remote Sens. 2014, 6, 4173–4189. [Google Scholar] [CrossRef] [Green Version]
- Hu, M.; Wu, C.; Zhang, L.; Du, B. Hyperspectral Anomaly Change Detection Based on Autoencoder. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 3750–3762. [Google Scholar] [CrossRef]
- Bruzzone, L.; Prieto, D.F. Automatic Analysis of the Difference Image for Unsupervised Change Detection. IEEE Trans. Geosci. Remote Sens. 2000, 38, 1171–1182. [Google Scholar] [CrossRef] [Green Version]
- Bazi, Y.; Bruzzone, L.; Melgani, F. An Unsupervised Approach Based on the Generalized Gaussian Model to Automatic Change Detection in Multitemporal SAR Images. IEEE Trans. Geosci. Remote Sens. 2005, 43, 874–887. [Google Scholar] [CrossRef] [Green Version]
- Bovolo, F.; Bruzzone, L. A Theoretical Framework for Unsupervised Change Detection Based on Change Vector Analysis in the Polar Domain. IEEE Trans. Geosci. Remote Sens. 2007, 45, 218–236. [Google Scholar] [CrossRef] [Green Version]
- Saha, S.; Bovolo, F.; Bruzzone, L. Unsupervised Deep Change Vector Analysis for Multiple-Change Detection in VHR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3677–3693. [Google Scholar] [CrossRef]
- Thonfeld, F.; Feilhauer, H.; Braun, M.; Menz, G.R. Change Vector Analysis (RCVA) for Multi-Sensor Very High Resolution Optical Satellite Data. Int. J. Appl. Earth Obs. Geoinf. 2016, 50, 131–140. [Google Scholar] [CrossRef]
- Baisantry, M.; Negi, D.; Manocha, O. Change Vector Analysis Using Enhanced PCA and Inverse Triangular Function-based Thresholding. Def. Sci. J. 2012, 62, 236–242. [Google Scholar] [CrossRef]
- Nielsen, A.A.; Conradsen, K.; Simpson, J.J. Multivariate Alteration Detection (MAD) and MAF Postprocessing in Multispectral, Bitemporal Image Data: New Approaches to Change Detection Studies. Remote Sens. Environ. 1998, 64, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, A.A. The Regularized Iteratively Reweighted MAD Method for Change Detection in Multi- and Hyperspectral Data. IEEE Trans. Image Process. 2007, 16, 463–478. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hou, Z.; Li, W.; Tao, R.; Du, Q. Three-Order Tucker Decomposition and Reconstruction Detector for Unsupervised Hyperspectral Change Detection. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 6194–6205. [Google Scholar] [CrossRef]
- Bovolo, F.; Bruzzone, L.; Marconcini, M. A Novel Approach to Unsupervised Change Detection Based on a Semisupervised SVM and a Similarity Measure. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2070–2082. [Google Scholar] [CrossRef] [Green Version]
- Demir, B.; Bovolo, F.; Bruzzone, L. Detection of Land-Cover Transitions in Multitemporal Remote Sensing Images with Active-Learning-Based Compound Classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1930–1941. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Zhan, T.; Gong, M.; Jiang, X.; Zhao, W. Transfer Learning-Based Bilinear Convolutional Networks for Unsupervised Change Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Ling, J.; Hu, L.; Cheng, L.; Chen, M.; Yang, X. IRA-MRSNet: A Network Model for Change Detection in High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 5598. [Google Scholar] [CrossRef]
- Lei, T.; Geng, X.; Ning, H.; Lv, Z.; Gong, M.; Jin, Y.; Nandi, A.K. Ultra-Lightweight Spatial-Spectral Feature Cooperation Network for Change Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1. [Google Scholar]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A General End-to-End 2-D CNN Framework for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3–13. [Google Scholar] [CrossRef] [Green Version]
- Saha, S.; Kondmann, L.; Song, Q.; Zhu, X. Change Detection in Hyperdimensional Images Using Untrained Models. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 11029–11041. [Google Scholar] [CrossRef]
- Zhan, T.; Song, B. TDSSC: A Three-Directions Spectral–Spatial Convolution Neural Network for Hyperspectral Image Change Detection. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 377–388. [Google Scholar] [CrossRef]
- Song, B.; Tang, Y.; Zhan, T.; Wu, Z. BRCN-ERN: A Bidirectional Reconstruction Coding Network and Enhanced Residual Network for Hyperspectral Change Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhan, T.; Song, B.; Xu, Y.; Wan, M.; Wang, X.; Yang, G.; Wu, Z. SSCNN-S: A Spectral-Spatial Convolution Neural Network with Siamese Architecture for Change Detection. Remote Sens. 2021, 13, 895. [Google Scholar] [CrossRef]
- Ou, X.; Liu, L.; Tu, B.; Zhang, G.; Xu, Z. A CNN Framework with Slow-Fast Band Selection and Feature Fusion Grouping for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Wang, L.; Wang, L.; Wang, Q.; Bruzzone, L. RSCNet: A Residual Self-Calibrated Network for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Zhao, C.; Cheng, H.; Feng, S. A Spectral–Spatial Change Detection Method Based on Simplified 3-D Convolutional Autoencoder for Multitemporal Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Seydi, S.; Shah-Hosseini, R.; Amani, M. A Multi-Dimensional Deep Siamese Network for Land Cover Change Detection in Bi-Temporal Hyperspectral Imagery. Sustainability 2022, 14, 12597. [Google Scholar] [CrossRef]
- Lyu, H.; Lu, H.; Mou, L. Learning a Transferable Change Rule from a Recurrent Neural Network for Land Cover Change Detection. Remote Sens. 2016, 8, 506. [Google Scholar] [CrossRef] [Green Version]
- Song, A.; Choi, J.; Han, Y.; Kim, Y. Change Detection in Hyperspectral Images Using Recurrent 3D Fully Convolutional Networks. Remote Sens. 2018, 10, 1827. [Google Scholar] [CrossRef] [Green Version]
- Shi, C.; Zhang, Z.; Zhang, W.; Zhang, C.; Xu, Q. Learning Multiscale Temporal–Spatial–Spectral Features via a Multipath Convolutional LSTM Neural Network for Change Detection with Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Mou, L.; Bruzzone, L.; Zhu, X. Learning Spectral-Spatial-Temporal Features via a Recurrent Convolutional Neural Network for Change Detection in Multispectral Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 924–935. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional Attention Flow for Machine Comprehension. arXiv 2016, arXiv:1611.01603. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–24 June 2018. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Gong, M.; Jiang, F.; Qin, A.K.; Liu, T.; Zhan, T.; Lu, D.; Zheng, H.; Zhang, M. A Spectral and Spatial Attention Network for Change Detection in Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1. [Google Scholar] [CrossRef]
- Wang, Z.; Jiang, F.; Liu, T.; Xie, F.; Li, P. Attention-Based Spatial and Spectral Network with PCA-Guided Self-Supervised Feature Extraction for Change Detection in Hyperspectral Images. Remote Sens. 2021, 13, 4927. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, L.; Huang, C.; Qi, W.; Song, R. Parallel Spectral–Spatial Attention Network with Feature Redistribution Loss for Hyperspectral Change Detection. Remote Sens. 2022, 15, 246. [Google Scholar] [CrossRef]
- Qu, J.; Hou, S.; Dong, W.; Li, Y.; Xie, W. A Multilevel Encoder–Decoder Attention Network for Change Detection in Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Wang, L.; Wang, L.; Wang, Q.; Atkinson, P.M. SSA-SiamNet: Spectral–Spatial-Wise Attention-Based Siamese Network for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Luo, F.; Zhou, T.; Liu, J.; Guo, T.; Gong, X.; Ren, J. Multi-Scale Diff-changed Feature Fusion Network for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1. [Google Scholar]
- Qu, J.; Xu, Y.; Dong, W.; Li, Y.; Du, Q. Dual-Branch Difference Amplification Graph Convolutional Network for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Song, R.; Ni, W.; Cheng, W.; Wang, X. CSANet: Cross-Temporal Interaction Symmetric Attention Network for Hyperspectral Image Change Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Ou, X.; Liu, L.; Tu, B.; Qing, L.; Zhang, G.; Liang, Z. CBW-MSSANet: A CNN Framework with Compact Band Weighting and Multi-Scale Spatial Attention for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1. [Google Scholar] [CrossRef]
- Ding, J.; Li, X.; Zhao, L. CDFormer: A Hyperspectral Image Change Detection Method Based on Transformer Encoders. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, Y.; Hong, D.; Sha, J.; Gao, L.; Liu, L.; Zhang, Y.; Rong, X. Spectral–Spatial–Temporal Transformers for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef] [Green Version]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking Hyperspectral Image Classification with Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Wang, W.; Liu, L.; Zhang, T.; Shen, J.; Wang, J.; Li, J. Hyper-ES2T: Efficient Spatial–Spectral Transformer for the Classification of Hyperspectral Remote Sensing Images. Int. J. Appl. Earth Obs. Geoinf. 2022, 113, 103005. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patches | Layer | Head | Training Epochs | |
|---|---|---|---|---|
| Farmland | 5 | 4 | 4 | 150 |
| Hermiston | 5 | 4 | 4 | 150 |
| River | 3 | 4 | 2 | 100 |
| CVA | PCA–CVA | TDRD | UTCNN | Re3FCN | ReCNN | CSANet | SST–Former | Proposed | |
|---|---|---|---|---|---|---|---|---|---|
| OA | 0.8749 | 0.8827 | 0.8847 | 0.8859 | 0.9626 | 0.9496 | 0.9644 | 0.9523 | |
| Kappa | 0.6998 | 0.7178 | 0.7309 | 0.7344 | 0.9130 | 0.8822 | 0.9166 | 0.8896 |
| CVA | PCA–CVA | TDRD | UTCNN | Re3FCN | ReCNN | CSANet | SST–Former | Proposed | |
|---|---|---|---|---|---|---|---|---|---|
| OA | 0.9200 | 0.9153 | 0.9285 | 0.9026 | 0.9370 | 0.9502 | 0.9557 | 0.9635 | |
| Kappa | 0.7410 | 0.7225 | 0.7778 | 0.6855 | 0.8114 | 0.8536 | 0.8700 | 0.8935 |
| CVA | PCA–CVA | TDRD | UTCNN | Re3FCN | ReCNN | CSANet | SST–Former | Proposed | |
|---|---|---|---|---|---|---|---|---|---|
| OA | 0.9267 | 0.9517 | 0.9615 | 0.8848 | 0.9626 | 0.9588 | 0.9592 | 0.9675 | |
| Kappa | 0.6575 | 0.7477 | 0.7475 | 0.4946 | 0.7381 | 0.7129 | 0.7170 | 0.7860 |
| Dataset | Metric | The Number of Neighboring Bands | ||||
|---|---|---|---|---|---|---|
| 1 | 3 | 5 | 7 | 9 | ||
| Farmland | OA | 0.9637 | 0.9645 | 0.9652 | 0.9618 | 0.9612 |
| Kappa | 0.9158 | 0.9178 | 0.9188 | 0.9115 | 0.9103 | |
| Hermiston | OA | 0.9696 | 0.9676 | 0.9703 | 0.9677 | 0.9678 |
| Kappa | 0.9126 | 0.9070 | 0.9136 | 0.9072 | 0.9070 | |
| River | OA | 0.9761 | 0.9748 | 0.9774 | 0.9778 | 0.9727 |
| Kappa | 0.8425 | 0.8445 | 0.8493 | 0.8556 | 0.8181 | |
| Model | (1) | (2) | (3) | (4) | |
|---|---|---|---|---|---|
| GSE | ✗ | ✓ | ✗ | ✓ | |
| EMHSA | ✗ | ✗ | ✓ | ✓ | |
| Farmland | OA | 0.9575 | 0.9639 | 0.9637 | 0.9652 |
| Kappa | 0.9012 | 0.9166 | 0.9158 | 0.9188 | |
| Hermiston | OA | 0.9664 | 0.9688 | 0.9696 | 0.9703 |
| Kappa | 0.9024 | 0.9097 | 0.9126 | 0.9136 | |
| River | OA | 0.9688 | 0.9719 | 0.9761 | 0.9778 |
| Kappa | 0.7932 | 0.8097 | 0.8425 | 0.8556 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Ding, J. Spectral–Temporal Transformer for Hyperspectral Image Change Detection. Remote Sens. 2023, 15, 3561. https://doi.org/10.3390/rs15143561
Li X, Ding J. Spectral–Temporal Transformer for Hyperspectral Image Change Detection. Remote Sensing. 2023; 15(14):3561. https://doi.org/10.3390/rs15143561
Chicago/Turabian StyleLi, Xiaorun, and Jigang Ding. 2023. "Spectral–Temporal Transformer for Hyperspectral Image Change Detection" Remote Sensing 15, no. 14: 3561. https://doi.org/10.3390/rs15143561
APA StyleLi, X., & Ding, J. (2023). Spectral–Temporal Transformer for Hyperspectral Image Change Detection. Remote Sensing, 15(14), 3561. https://doi.org/10.3390/rs15143561