
An Intra-Class Ranking Metric for Remote Sensing Image Retrieval
 ,
,
Abstract
:
1. Introduction
2. Related Works
2.1. Remote Sensing Image Retrieval
2.2. Loss Functions in Deep Metric Learning
2.2.1. Pair-Based Loss
2.2.2. Proxy-Based Loss
2.2.3. Other Methods
2.3. Sample Generation
2.4. Self-Supervised Learning
2.5. Intra-Class Differences
3. Proposed Method
3.1. Background and Motivation for Sample Generation and Intra-Class Ranking Loss
3.2. Image Retrieval Using the Intra-Class Ranking Loss Function Based on Sample Generation
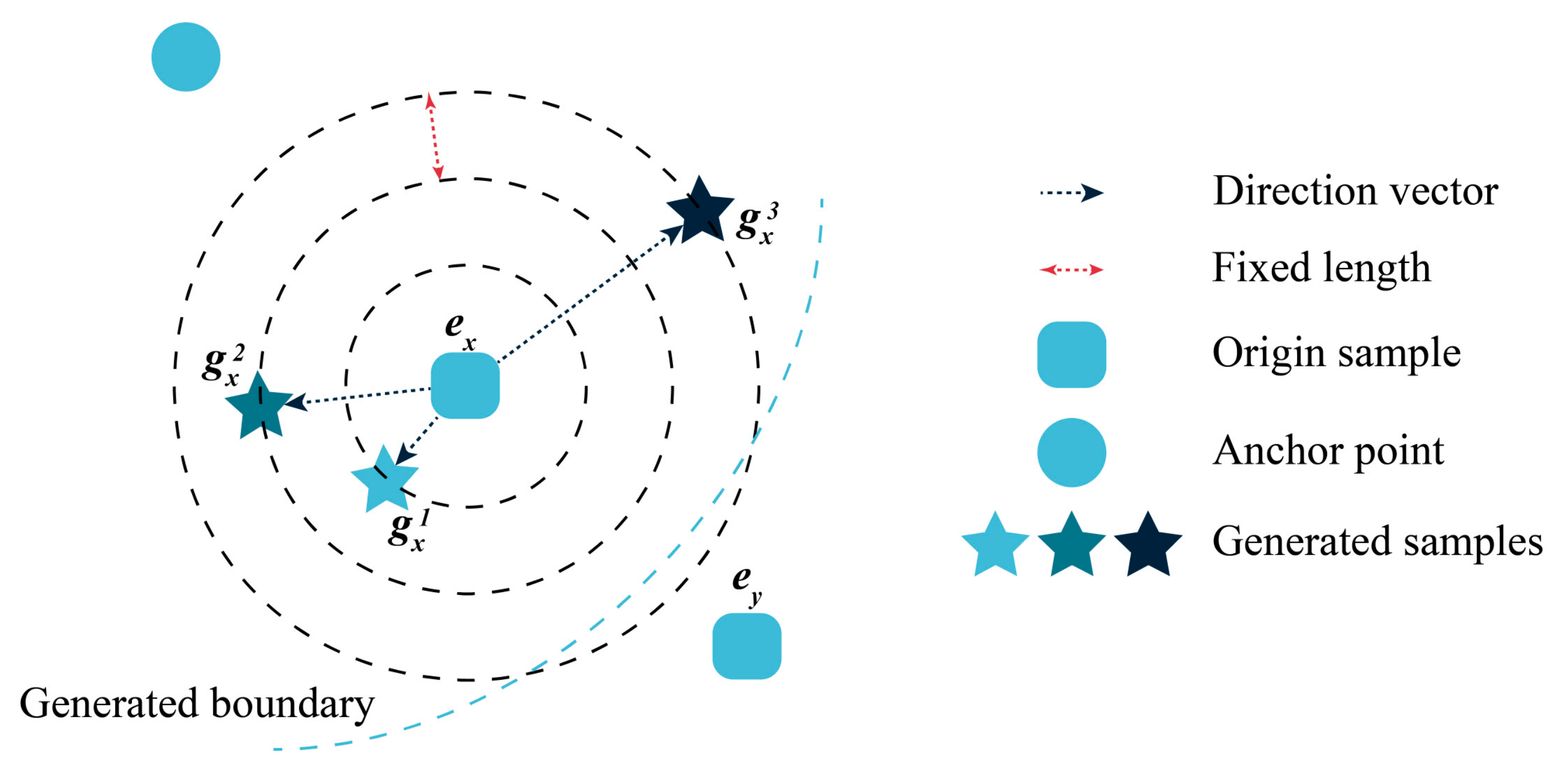
3.2.1. Sample Generation
3.2.2. Intra-Class Ranking Loss Function
3.2.3. Gradient Analysis
4. Experimental Setup
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
5. Experimental Results and Analysis
5.1. Ablation Study
5.2. Comparison Experiment
5.3. Visualization
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Smeulders, A.W.M.; Worring, M.; Santini, S.; Gupta, A.; Jain, R. Content-based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Zheng, L.; Yang, Y.; Tian, Q. SIFT meets CNN: A decade survey of instance retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1224–1244. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rui, Y.; Huang, T.S.; Chang, S.-F. Image retrieval: Past, present, and future. J. Vis. Commun. Image Represent. 1999, 10, 39–62. [Google Scholar] [CrossRef]
- Daschiel, H.; Datcu, M. Information mining in remote sensing image archives: System evaluation. IEEE Trans. Geosci. Remote Sens. 2005, 43, 188–199. [Google Scholar] [CrossRef]
- Tong, X.-Y.; Xia, G.-S.; Hu, F.; Zhong, Y.; Datcu, M.; Zhang, L. Exploiting Deep Features for Remote Sensing Image Retrieval: A Systematic Investigation. IEEE Trans. Big Data 2020, 6, 507–521. [Google Scholar] [CrossRef] [Green Version]
- Long, Y.; Zhao, F.; Zheng, M.; Jin, G.; Zhang, H.; Wang, R. A Novel Azimuth Ambiguity Suppression Method for Spaceborne Dual-Channel SAR-GMTI. IEEE Geosci. Remote Sens. Lett. 2021, 18, 87–91. [Google Scholar] [CrossRef]
- Kim, S.Y.; Myung, N.H.; Kang, M.J. Antenna Mask Design for SAR Performance Optimization. IEEE Geosci. Remote Sens. Lett. 2009, 6, 443–447. [Google Scholar]
- Kang, M.-S.; Baek, J.-M. Efficient SAR Imaging Integrated with Autofocus via Compressive Sensing. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4514905. [Google Scholar] [CrossRef]
- Long, Y.; Zhao, F.; Zheng, M.; Jin, G.; Zhang, H. An Azimuth Ambiguity Suppression Method Based on Local Azimuth Ambiguity-to-Signal Ratio Estimation. IEEE Geosci. Remote Sens. Lett. 2020, 17, 2075–2079. [Google Scholar] [CrossRef]
- Kang, M.-S.; Baek, J.-M. SAR Image Reconstruction via Incremental Imaging with Compressive Sensing. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 4450–4463. [Google Scholar] [CrossRef]
- Kim, S.Y.; Myung, N. An optimal antenna pattern synthesis for active phased array SAR based on particle swarm optimization and adaptive weighting factor. Prog. Electromagn. Res. 2009, 10, 129–142. [Google Scholar] [CrossRef] [Green Version]
- Zheng, J.; Song, X.; Yang, G.; Du, X.; Mei, X.; Yang, X. Remote Sensing Monitoring of Rice and Wheat Canopy Nitrogen: A Review. Remote Sens. 2022, 14, 5712. [Google Scholar] [CrossRef]
- Sklyar, E.; Rees, G. Assessing Changes in Boreal Vegetation of Kola Peninsula via Large-Scale Land Cover Classification between 1985 and 2021. Remote Sens. 2022, 14, 5616. [Google Scholar] [CrossRef]
- Jeon, J.; Tomita, T. Investigating the Effects of Super Typhoon HAGIBIS in the Northwest Pacific Ocean Using Multiple Observa-tional Data. Remote Sens. 2022, 14, 5667. [Google Scholar] [CrossRef]
- Heidari, A.; Jafari Navimipour, N.; Unal, M.; Zhang, G. Machine learning applications in internet-of-drones: Systematic review, recent deployments, and open issues. ACM Comput. Surv. 2023, 55, 1–45. [Google Scholar] [CrossRef]
- Darbandi, M. Proposing New Intelligence Algorithm for Suggesting Better Services to Cloud Users based on Kalman Filtering. Comput. Sci. Appl. 2017, 5, 11–16. [Google Scholar]
- Vahdat, S. The role of IT-based technologies on the management of human resources in the COVID-19 era. Kybernetes 2021, 51, 2065–2088. [Google Scholar] [CrossRef]
- Zadeh, F.A.; Bokov, D.O.; Yasin, G.; Vahdat, S.; Abbasalizad-Farhangi, M. Central obesity accelerates leukocyte telomere length (LTL) shortening in apparently healthy adults: A systematic review and meta-analysis. Crit. Rev. Food Sci. 2023, 63, 2119–2128. [Google Scholar] [CrossRef]
- Rahhal, M.M.A.; Bencherif, M.A.; Bazi, Y.; Alharbi, A.; Mekhalfi, M.L. Contrasting Dual Transformer Architectures for Multi-Modal Remote Sensing Image Retrieval. Appl. Sci. 2023, 13, 282. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hintonm, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Musgrave, K.; Belongie, S.; Lim, S.-N. A metric learning reality check. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 681–699. [Google Scholar]
- Zhang, Y.; Zheng, X.; Lu, X. Remote Sensing Image Retrieval by Deep Attention Hashing with Distance-Adaptive Ranking. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4301–4311. [Google Scholar] [CrossRef]
- Guo, J.; Guan, X. Deep Adversarial Cascaded Hashing for Cross-Modal Vessel Image Retrieval. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2205–2220. [Google Scholar] [CrossRef]
- Tan, X.; Zou, Y.; Guo, Z.; Zhou, K.; Yuan, Q. Deep Contrastive Self-Supervised Hashing for Remote Sensing Image Retrieval. Remote Sens. 2022, 14, 3643. [Google Scholar] [CrossRef]
- Sun, Y.; Ye, Y.; Li, X.; Feng, S.; Zhang, B.; Kang, J.; Dai, K. Unsupervised deep hashing through learning soft pseudo label for remote sensing image retrieval. Knowl.-Based Syst. 2022, 239, 107807. [Google Scholar] [CrossRef]
- Hou, D.; Wang, S.; Tian, X.; Xing, H. An Attention-Enhanced End-to-End Discriminative Network with Multiscale Feature Learning for Remote Sensing Image Retrieval. IEEE J. Sel. Top. Appl. Earth Obs. Remote sens. 2022, 15, 8245–8255. [Google Scholar] [CrossRef]
- Hou, D.; Wang, S.; Tian, X.; Xing, H. PCLUDA: A Pseudo-Label Consistency Learning- Based Unsupervised Domain Adaptation Method for Cross-Domain Optical Remote Sensing Image Retrieval. IEEE. Trans. Geosci. Remote. Sens. 2023, 61, 5600314. [Google Scholar] [CrossRef]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I. Signature verification using a “siamese” time delay neural network. Int. J. Pattern Recogn. 1993, 7, 669–688. [Google Scholar] [CrossRef] [Green Version]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823.
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; Wu, Y. Learning fine-grained image similarity with deep ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1386–1393. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep metric learning using triplet network. In Similarity-Based Pattern Recognition, Proceedings of the Third International Workshop, SIMBAD 2015, Copenhagen, Denmark, 12–14 October 2015; Lecture Notes in Computer Science (IncludingSubseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015; Volume 9370, pp. 84–92. [Google Scholar]
- Sohn, K. Improved deep metric learning with multi-class n-pair loss objective. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 1857–1865. [Google Scholar]
- Wang, X.; Han, X.; Huang, W.; Dong, D.; Scott, M.R. Multi-similarity loss with general pair weighting for deep metric learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5017–5025. [Google Scholar]
- Wu, C.-Y.; Manmatha, R.; Smola, A.J.; Krähenbühl, P. Sampling matters in deep embedding learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2859–2867. [Google Scholar]
- Harwood, B.; Kumar, V.; Carneiro, G.; Reid, I.; Drummond, T. Smart mining for deep metric learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2840–2848. [Google Scholar]
- Gajić, B.; Amato, A.; Gatta, C. Fast hard negative mining for deep metric learning. Pattern Recogn. 2021, 112, 107795. [Google Scholar] [CrossRef]
- Movshovitz-Attias, Y.; Toshev, A.; Leung, T.K.; Loffe, S.; Singh, S. No fuss distance metric learning using proxies. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 360–368. [Google Scholar]
- The, E.W.; Devries, T.; Taylor, G.W. Proxynca++: Revisiting and Revitalizing Proxy Neighborhood Component Analysis. In Proceedings of the Computer Vision–ECCV 2020: Glasgow, Scotland, UK, 23–28 August 2020; pp. 448–464. [Google Scholar]
- Qian, Q.; Shang, L.; Sun, B.; Hu, J.; Tacoma, T.; Li, H.; Jin, R. Softtriple loss: Deep metric learning without triplet sampling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6449–6457. [Google Scholar]
- Kim, S.; Kim, D.; Cho, M.; Kwak, S. Proxy anchor loss for deep metric learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3235–3244. [Google Scholar]
- Kan, S.; He, Z.; Cen, Y.; Li, Y.; Mladenovic, V.; He, Z. Contrastive Bayesian Analysis for Deep Metric Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 7220–7238. [Google Scholar] [CrossRef]
- Jin, Y.; Lu, H.; Zhu, W.; Huo, W. Deep learning based classification of multi-label chest X-ray images via dual-weighted metric loss. Comput. Biol. Med. 2023, 157, 106683. [Google Scholar] [CrossRef]
- Saeki, S.; Kawahara, M.; Aman, H. Multi proxy anchor family loss for several types of gradients. Comput. Vis. Image Underst. 2023, 229, 103654. [Google Scholar] [CrossRef]
- Wang, X.; Hua, Y.; Kodirov, E.; Robertson, N.M. Ranked List Loss for Deep Metric Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5414–5429. [Google Scholar]
- Ko, B.; Gu, G. Embedding expansion: Augmentation in embedding space for deep metric learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7253–7262. [Google Scholar]
- Duan, Y.; Lu, J.; Zheng, W.; Zhou, J. Deep adversarial metric learning. IEEE. Trans. Image Process. 2019, 29, 2037–2051. [Google Scholar] [CrossRef]
- Lin, X.; Duan, Y.; Dong, Q.; Lu, J.; Zhou, J. Deep variational metric learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 714–729. [Google Scholar]
- Zhao, Y.; Jin, Z.; Qi, G.-J.; Lu, H.; Hua, X.-S. An adversarial approach to hard triplet generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 508–524. [Google Scholar]
- Zheng, W.; Chen, Z.; Lu, J.; Zhou, J. Hardness-aware deep metric learning. IEEE. Trans. Pattern Anal. Mach. Intell. 2019, 34, 3214–3228. [Google Scholar]
- Gu, G.; Ko, B. Symmetrical synthesis for deep metric learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 10853–10860. [Google Scholar]
- Gu, G.; Ko, B.; Kim, H.-G. Proxy synthesis: Learning with synthetic classes for deep metric learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 1460–1468. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9726–9735. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised representation learning by predicting image rotations. In Proceedings of the International Conference on Learning Representations Vancouver Convention Center, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhai, X.; Oliver, A.; Kolesnikov, A.; Beyer, L. S4L: Self-supervised semi-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1476–1485. [Google Scholar]
- Roth, K.; Brattoli, B.; Ommer, B. Mic: Mining interclass characteristics for improved metric learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7999–8008. [Google Scholar]
- Wang, X.; Zhang, H.; Huang, W.; Scott, M.R. Cross-batch memory for embedding learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6387–6396. [Google Scholar]
- Zhu, H.; Xu, H.; Ma, X.; Bian, M. Facial Expression Recognition Using Dual Path Feature Fusion and Stacked Attention. Future Intern. 2022, 14, 258. [Google Scholar] [CrossRef]
- Lu, X.; Ding, W.; Li, H.; Yu, P.; Gu, J. Fine-grained image classification algorithm based on Attention Self-supervision. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; pp. 517–521. [Google Scholar]
- Zhang, X.; Liu, Y.; Huo, C.; Xu, N.; Wang, L.; Pan, C. PSNet: Perspective-sensitive convolutional network for object detection. Neurocomputing 2022, 468, 384–395. [Google Scholar] [CrossRef]
- Zhang, T.; Yang, L.; Gut, X.; Wang, Y. A Task-Specific Meta-Learning Framework for Few-Shot Sound Event Detection. In Proceedings of the 2022 IEEE 24th International Workshop on Multimedia Signal Processing (MMSP), Shanghai, China, 26–28 September 2022; pp. 1–6. [Google Scholar]
- Alipour, N.; Tarkhaneh, O.; Awrangjeb, M.; Tian, H. Flower Image Classification Using Deep Convolutional Neural Network. In Proceedings of the 2021 7th International Conference on Web Research (ICWR), Tehran, Iran, 19–20 May 2021; pp. 1–4. [Google Scholar]
- Zhang, Z.; Zhang, T.; Liu, Z.; Zhang, P.; Tu, S.; Li, Y.; Waqas, M. Fine-grained Ship Image Recognition Based on BCNN with Inception and AM-Softmax. Comput. Mater. Contin. 2022, 73, 1527–1539. [Google Scholar]
- Fu, Z.; Mao, Z.; Yan, C.; Liu, A.-A.; Xie, H.; Zhang, Y. Self-supervised Synthesis Ranking for Deep Metric Learning. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4736–4750. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPA-TIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Opitz, M.; Waltner, G.; Possegger, H.; Bischof, H. Deep Metric Learning with BIER: Boosting Independent Embeddings Robustly. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 276–290. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sanakoyeu, A.; Tschernezki, V.; Büchler, U.; Ommer, B. Divide and Conquer the Embedding Space for Metric Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2019; pp. 471–480. [Google Scholar]
- Sun, Y.; Cheng, C.; Zhang, Y.; Zhang, C.; Zheng, L.; Wang, Z.; Wei, Y. Circle loss: A unified perspective of pair similarity optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6397–6406. [Google Scholar]
- Wang, Y.; Liu, P.; Lang, Y.; Zhou, Q.; Shan, X. Learnable dynamic margin in deep metric learning. Pattern Recognit. 2022, 132, 108961. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UCMD | AID | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | R2 | R3 | R4 | mAP@10 | RP@10 | R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| 128 | 98.04 | 98.80 | 98.80 | 99.04 | 92.96 | 94.23 | 93.80 | 95.30 | 96.35 | 97.10 | 89.98 | 91.44 |
| 256 | 98.33 | 99.04 | 99.09 | 99.18 | 93.02 | 94.37 | 93.85 | 95.55 | 96.60 | 97.40 | 90.15 | 91.51 |
| 512 | 98.37 | 99.04 | 99.13 | 99.26 | 93.42 | 94.50 | 94.10 | 95.70 | 96.75 | 97.55 | 90.23 | 91.70 |
| 1024 | 98.53 | 99.08 | 99.27 | 99.28 | 93.62 | 94.80 | 94.30 | 95.50 | 96.90 | 97.70 | 90.48 | 91.84 |
| 2048 | 98.29 | 98.87 | 99.08 | 99.15 | 92.98 | 93.88 | 93.90 | 95.45 | 96.80 | 97.65 | 90.25 | 91.65 |
| β | UCMD | AID | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | R2 | R3 | R4 | mAP@10 | RP@10 | R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| 0.0 | 98.30 | 98.57 | 98.80 | 99.04 | 92.74 | 93.76 | 94.10 | 95.40 | 96.70 | 97.50 | 90.00 | 91.53 |
| 0.03 | 98.53 | 99.08 | 99.27 | 99.28 | 93.62 | 94.80 | 94.30 | 95.50 | 96.90 | 97.70 | 90.48 | 91.84 |
| 0.05 | 98.50 | 99.04 | 99.04 | 99.20 | 93.28 | 94.31 | 94.25 | 95.45 | 96.75 | 97.50 | 89.90 | 91.56 |
| 0.08 | 98.45 | 98.57 | 98.90 | 99.10 | 92.96 | 94.20 | 93.95 | 95.30 | 96.50 | 97.45 | 89.97 | 91.50 |
| 0.1 | 98.47 | 98.57 | 98.80 | 99.02 | 92.66 | 93.95 | 93.80 | 95.35 | 96.35 | 97.30 | 90.10 | 91.47 |
| m | UCMD | AID | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | R2 | R3 | R4 | mAP@10 | RP@10 | R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| −0.1 | 98.05 | 98.10 | 98.50 | 98.71 | 92.80 | 93.90 | 94.05 | 95.25 | 96.65 | 97.25 | 89.97 | 91.45 |
| −0.05 | 98.18 | 98.50 | 99.03 | 99.04 | 93.22 | 94.54 | 94.05 | 95.30 | 96.70 | 97.30 | 90.31 | 91.77 |
| 0 | 98.10 | 98.20 | 98.33 | 98.73 | 92.79 | 93.80 | 94.10 | 95.05 | 96.65 | 97.30 | 90.30 | 91.32 |
| 0.05 | 98.53 | 99.08 | 99.27 | 99.28 | 93.62 | 94.80 | 94.30 | 95.50 | 96.90 | 97.70 | 90.48 | 91.84 |
| 0.1 | 98.28 | 98.63 | 98.77 | 98.80 | 93.30 | 94.28 | 94.20 | 95.75 | 96.70 | 97.25 | 90.25 | 91.50 |
| λ | UCMD | AID | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | R2 | R3 | R4 | mAP@10 | RP@10 | R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| 0.0 | 97.77 | 98.57 | 98.80 | 98.80 | 92.45 | 93.81 | 93.30 | 94.90 | 96.45 | 97.20 | 89.98 | 90.87 |
| 0.3 | 98.22 | 98.60 | 98.98 | 99.08 | 93.13 | 94.20 | 93.80 | 95.30 | 96.50 | 97.35 | 90.23 | 91.40 |
| 0.5 | 98.35 | 98.67 | 98.90 | 99.18 | 93.11 | 94.11 | 93.95 | 95.40 | 96.65 | 97.45 | 90.24 | 91.56 |
| 0.8 | 98.37 | 98.84 | 99.04 | 99.24 | 93.23 | 94.38 | 94.10 | 95.40 | 96.80 | 97.60 | 90.35 | 91.67 |
| 1.0 | 98.53 | 99.08 | 99.27 | 99.28 | 93.62 | 94.80 | 94.30 | 95.50 | 96.90 | 97.70 | 90.48 | 91.84 |
| UCMD | AID | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | R2 | R4 | R8 | mAP@10 | RP@10 | R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| 3 | 98.15 | 98.73 | 99.15 | 99.19 | 92.78 | 94.02 | 94.20 | 95.35 | 96.80 | 97.50 | 90.27 | 91.45 |
| 5 | 98.53 | 99.08 | 99.27 | 99.28 | 93.62 | 94.80 | 94.30 | 95.50 | 96.90 | 97.70 | 90.48 | 91.84 |
| 8 | 98.05 | 98.57 | 99.03 | 99.16 | 92.46 | 93.69 | 94.15 | 95.80 | 96.85 | 97.70 | 89.90 | 91.32 |
| 10 | 98.37 | 98.60 | 98.88 | 99.20 | 92.97 | 94.07 | 94.10 | 96.00 | 97.03 | 97.55 | 90.25 | 91.75 |
| 15 | 98.56 | 99.04 | 99.11 | 99.20 | 93.50 | 94.80 | 93.90 | 96.10 | 97.05 | 98.00 | 90.15 | 91.70 |
| UCMD | AID | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | R2 | R4 | R8 | mAP@10 | RP@10 | R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| 0.5 | 98.23 | 98.70 | 98.95 | 99.18 | 92.93 | 93.95 | 94.15 | 95.45 | 96.87 | 97.55 | 90.35 | 91.66 |
| 1 | 98.53 | 99.08 | 99.27 | 99.28 | 93.62 | 94.80 | 94.30 | 95.50 | 96.90 | 97.70 | 90.48 | 91.84 |
| 1.5 | 98.49 | 98.70 | 99.12 | 99.20 | 93.15 | 93.98 | 94.30 | 95.75 | 96.87 | 97.57 | 90.10 | 91.65 |
| 2 | 97.82 | 98.74 | 99.03 | 99.11 | 91.05 | 92.18 | 94.40 | 95.40 | 96.65 | 97.25 | 90.27 | 91.69 |
| 2.5 | 98.54 | 99.00 | 99.10 | 99.18 | 92.57 | 93.99 | 94.50 | 95.45 | 96.55 | 97.10 | 90.19 | 91.73 |
| AID | ||||||
|---|---|---|---|---|---|---|
| R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| Linear + L2 + ReLU | 94.30 | 95.50 | 96.90 | 97.70 | 90.48 | 91.84 |
| Linear + L1 + ReLU | 94.05 | 95.65 | 96.70 | 97.40 | 90.40 | 91.78 |
| Linear + L2 + ReLU + Linear | 94.10 | 95.15 | 96.65 | 97.15 | 89.98 | 91.69 |
| Linear + L1 + ReLU + Linear | 93.85 | 95.75 | 96.80 | 97.65 | 89.95 | 91.76 |
| Linear + LN + ReLU + Linear | 3.80 | 3.80 | 3.80 | 3.80 | 3.80 | 3.80 |
| UCMD | ||||||
|---|---|---|---|---|---|---|
| R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| Linear + L2 + ReLU | 98.53 | 99.08 | 99.27 | 99.28 | 93.62 | 94.80 |
| Linear + L1 + ReLU | 97.90 | 98.12 | 98.80 | 99.06 | 92.67 | 93.51 |
| Linear + L2 + ReLU + Linear | 98.19 | 98.35 | 98.74 | 98.80 | 92.60 | 93.95 |
| Linear + L1 + ReLU + Linear | 97.84 | 97.90 | 98.53 | 99.22 | 92.20 | 93.73 |
| Linear + LN + ReLU + Linear | 4.76 | 4.76 | 4.76 | 9.52 | 3.22 | 4.76 |
| Method | AID | |||||
|---|---|---|---|---|---|---|
| R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| Contrastive [28] | 91.85 | 94.20 | 95.95 | 97.55 | 83.75 | 86.52 |
| Triplet [31] | 92.35 | 94.90 | 96.25 | 97.05 | 88.65 | 90.39 |
| N-Pair [32] | 88.05 | 92.20 | 93.95 | 95.60 | 80.85 | 83.76 |
| A-BIER [71] | 82.28 | 90.51 | 93.55 | 96.37 | 70.51 | - |
| DCES [72] | 85.39 | 91.02 | 95.27 | 96.63 | 72.53 | - |
| Circle [73] | 93.90 | 95.15 | 96.73 | 97.25 | 89.40 | 90.73 |
| MS [33] | 92.45 | 94.70 | 95.55 | 96.15 | 88.40 | 90.20 |
| SoftTriple [39] | 93.45 | 95.20 | 96.60 | 97.30 | 89.41 | 90.98 |
| Proxy-NCA [37] | 93.35 | 95.00 | 96.80 | 97.30 | 86.68 | 89.56 |
| LDM [74] | 93.20 | 94.90 | 96.00 | 96.80 | 89.94 | 90.95 |
| Proxy-Anchor [40] | 93.30 | 94.90 | 96.45 | 97.20 | 89.80 | 90.90 |
| Proxy-Anchor+gen | 94.30 | 95.50 | 96.90 | 97.70 | 90.48 | 91.84 |
| Method | UCMD | |||||
|---|---|---|---|---|---|---|
| R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| Contrastive [28] | 96.19 | 96.90 | 98.57 | 98.80 | 89.53 | 90.19 |
| Triplet [31] | 97.35 | 98.09 | 98.57 | 98.80 | 91.45 | 93.16 |
| N-Pair [32] | 94.63 | 95.23 | 96.90 | 98.09 | 83.97 | 84.80 |
| A-BIER [71] | 86.52 | 89.96 | 92.61 | 94.76 | 72.11 | - |
| DCES [72] | 87.45 | 91.02 | 94.27 | 96.32 | 78.93 | - |
| Circle [73] | 97.90 | 98.80 | 99.15 | 99.30 | 92.80 | 93.93 |
| MS [33] | 97.20 | 97.61 | 98.80 | 99.28 | 92.15 | 93.42 |
| SoftTriple [39] | 97.31 | 98.33 | 99.18 | 99.18 | 91.90 | 92.54 |
| Proxy-NCA [37] | 97.85 | 98.19 | 99.04 | 99.32 | 89.30 | 91.30 |
| LDM [74] | 97.93 | 98.67 | 99.04 | 99.28 | 92.65 | 93.71 |
| Proxy-Anchor [40] | 97.77 | 98.57 | 98.80 | 98.80 | 92.45 | 93.81 |
| Proxy-Anchor+gen | 98.53 | 99.08 | 99.27 | 99.28 | 93.62 | 94.80 |
| Method | NWPU | |||||
|---|---|---|---|---|---|---|
| R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| Contrastive [28] | 87.75 | 92.06 | 94.66 | 96.53 | 83.16 | 86.95 |
| Triplet [31] | 93.33 | 96.04 | 97.20 | 97.82 | 91.76 | 93.36 |
| N-Pair [32] | 87.80 | 91.97 | 94.50 | 96.36 | 84.02 | 87.07 |
| Circle [73] | 94.70 | 96.23 | 97.35 | 97.90 | 93.34 | 94.49 |
| SoftTriple [39] | 95.03 | 96.80 | 97.80 | 97.93 | 92.40 | 93.80 |
| MS [33] | 94.76 | 95.96 | 96.93 | 97.24 | 93.95 | 94.53 |
| Proxy-NCA [37] | 94.50 | 96.54 | 97.63 | 97.84 | 91.49 | 93.57 |
| LDM [74] | 95.06 | 96.88 | 97.50 | 97.96 | 93.58 | 94.71 |
| Proxy-Anchor [40] | 95.12 | 96.58 | 97.54 | 97.90 | 93.60 | 94.60 |
| Proxy-Anchor+gen | 95.75 | 97.12 | 97.70 | 98.05 | 94.45 | 95.51 |
| Method | Pattern-Net | |||||
|---|---|---|---|---|---|---|
| R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| Contrastive [28] | 97.24 | 98.45 | 99.12 | 99.52 | 94.59 | 94.95 |
| Triplet [31] | 98.63 | 99.25 | 99.51 | 99.67 | 97.30 | 97.71 |
| N-Pair [32] | 95.83 | 97.16 | 98.15 | 98.83 | 92.32 | 92.87 |
| Circle [73] | 98.88 | 99.47 | 99.60 | 99.78 | 97.63 | 98.03 |
| SoftTriple [39] | 98.70 | 99.50 | 99.63 | 99.79 | 97.70 | 98.10 |
| MS [33] | 98.52 | 98.96 | 99.20 | 99.41 | 96.78 | 97.33 |
| Proxy-NCA [37] | 98.45 | 99.02 | 99.07 | 99.28 | 97.34 | 97.97 |
| LDM [74] | 98.55 | 99.17 | 99.25 | 99.38 | 97.35 | 97.95 |
| Proxy-Anchor [40] | 98.50 | 99.03 | 99.04 | 99.08 | 97.51 | 97.80 |
| Proxy-Anchor+gen | 99.10 | 99.45 | 99.50 | 99.70 | 98.10 | 98.38 |
| Method | UCMD | AID | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | R2 | R4 | R8 | mAP@10 | RP@10 | R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| MS [33] | 96.00 | 97.50 | 98.10 | 98.95 | 86.70 | 89.74 | 91.70 | 95.70 | 97.75 | 98.15 | 83.84 | 87.71 |
| MS+gen | 97.25 | 98.35 | 98.80 | 99.05 | 89.38 | 92.09 | 92.80 | 95.75 | 98.35 | 99.25 | 85.97 | 88.98 |
| Proxy-NCA [37] | 96.75 | 98.00 | 98.75 | 99.00 | 88.68 | 91.67 | 92.20 | 95.70 | 97.50 | 98.35 | 87.16 | 88.06 |
| Proxy-NCA+gen | 97.50 | 98.25 | 99.25 | 99.75 | 90.78 | 92.74 | 93.85 | 97.00 | 98.55 | 99.55 | 88.73 | 90.93 |
| Proxy-Anchor [40] | 97.00 | 98.75 | 99.25 | 99.75 | 89.11 | 91.20 | 93.45 | 96.95 | 98.10 | 99.20 | 87.22 | 89.01 |
| Proxy-Anchor+gen | 98.50 | 99.00 | 99.25 | 100.00 | 91.09 | 93.20 | 94.85 | 97.10 | 98.80 | 99.75 | 89.50 | 91.29 |
| Method | UCMD(Training Set)– AID (Testing Set) | AID (Training Set)– UCMD (Testing Set) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | R2 | R4 | R8 | mAP@10 | RP@10 | R1 | R2 | R4 | R8 | mAP@10 | RP@10 | |
| MS [33] | 95.73 | 96.64 | 97.76 | 98.29 | 89.65 | 90.95 | 95.80 | 96.40 | 97.40 | 98.80 | 88.19 | 90.67 |
| MS+gen | 96.70 | 97.79 | 98.58 | 99.10 | 91.03 | 92.05 | 96.40 | 97.50 | 98.70 | 99.10 | 89.81 | 91.93 |
| Proxy-NCA [37] | 96.14 | 97.64 | 98.32 | 98.58 | 92.66 | 93.34 | 96.20 | 97.80 | 98.40 | 99.00 | 90.11 | 92.31 |
| Proxy-NCA+gen | 97.61 | 98.07 | 99.05 | 99.26 | 94.16 | 94.48 | 97.90 | 98.50 | 99.00 | 99.30 | 91.36 | 93.90 |
| Proxy-Anchor [40] | 96.30 | 97.88 | 98.29 | 99.00 | 92.51 | 94.04 | 97.20 | 97.90 | 98.70 | 99.10 | 90.50 | 91.37 |
| Proxy-Anchor+gen | 97.85 | 98.10 | 99.08 | 99.58 | 94.19 | 95.43 | 98.30 | 98.70 | 99.10 | 99.70 | 92.42 | 93.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, P.; Liu, X.; Wang, Y.; Liu, Z.; Zhou, Q.; Li, Q. An Intra-Class Ranking Metric for Remote Sensing Image Retrieval. Remote Sens. 2023, 15, 3943. https://doi.org/10.3390/rs15163943
Liu P, Liu X, Wang Y, Liu Z, Zhou Q, Li Q. An Intra-Class Ranking Metric for Remote Sensing Image Retrieval. Remote Sensing. 2023; 15(16):3943. https://doi.org/10.3390/rs15163943
Chicago/Turabian StyleLiu, Pingping, Xiaofeng Liu, Yifan Wang, Zetong Liu, Qiuzhan Zhou, and Qingliang Li. 2023. "An Intra-Class Ranking Metric for Remote Sensing Image Retrieval" Remote Sensing 15, no. 16: 3943. https://doi.org/10.3390/rs15163943