
LPMSNet: Location Pooling Multi-Scale Network for Cloud and Cloud Shadow Segmentation



Abstract
:1. Introduction
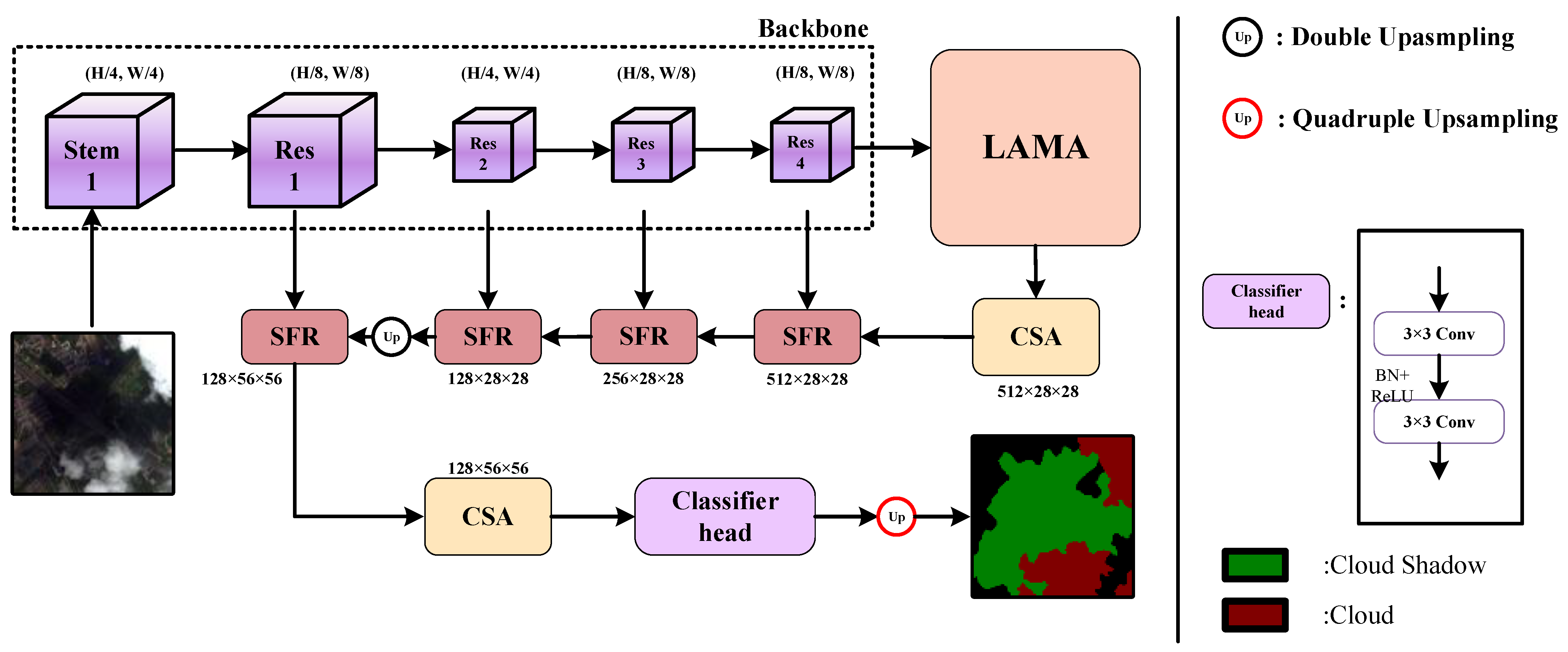
- The Location Attention Multi-Scale Aggregation Module (LAMA) aims to gather multi-scale info by pooling convolutions of different convolution kernels, thus enhancing LPMSNet’s capacity to collect semantic info across various scales. The parallel-input Location Attention Module (LA) can extract location information along the horizontal and vertical directions of the feature map through average pooling convolution, respectively. This location info can direct the network’s attention to the intended objects. Simultaneously, after horizontal and vertical position information is embedded with multi-scale information, it can complement the position code lost in multi-scale feature extraction.
- A Channel Spatial Attention Module (CSA) is created to eliminate the detrimental impact of background noise on cloud as well as cloud shade segmentation. The enhanced Non-Local Neural Networks can extract the long-distance dependencies of feature maps across the network’s shallow and deep layers. Channel Attention Module (CA) can dynamically adjust the weight of features, assisting NLNN in focusing on long-distance dependencies at different levels. The internal MLP can share weights via convolution operations, reducing the number of parameters as well as boosting the model’s generalisation capability and efficiency.
- During the downsampling process, the proposed Scale Fusion Restoration Module (SFR) could combine distinct categories of contextual info and deep semantic info. Simultaneously, SFR effectively fixes the edge info of cloud as well as cloud shade via stacked convolution operations, increasing the cloud and cloud shade segment impact.
2. Methodology
2.1. Backbone
2.2. Location Attention Multi-Scale Aggregation Module
2.3. Channel Spatial Attention Module
2.4. Scale Fusion Restoration Module
3. Experiment
3.1. Dataset Introductions
3.1.1. Cloud and Cloud Shadow Dataset
3.1.2. HRC WHU Dataset
3.1.3. L8SPARCS Dataset
3.2. Experimental Parameter Setting
3.3. Ablation Experiments on Cloud and Cloud Shadow Dataset
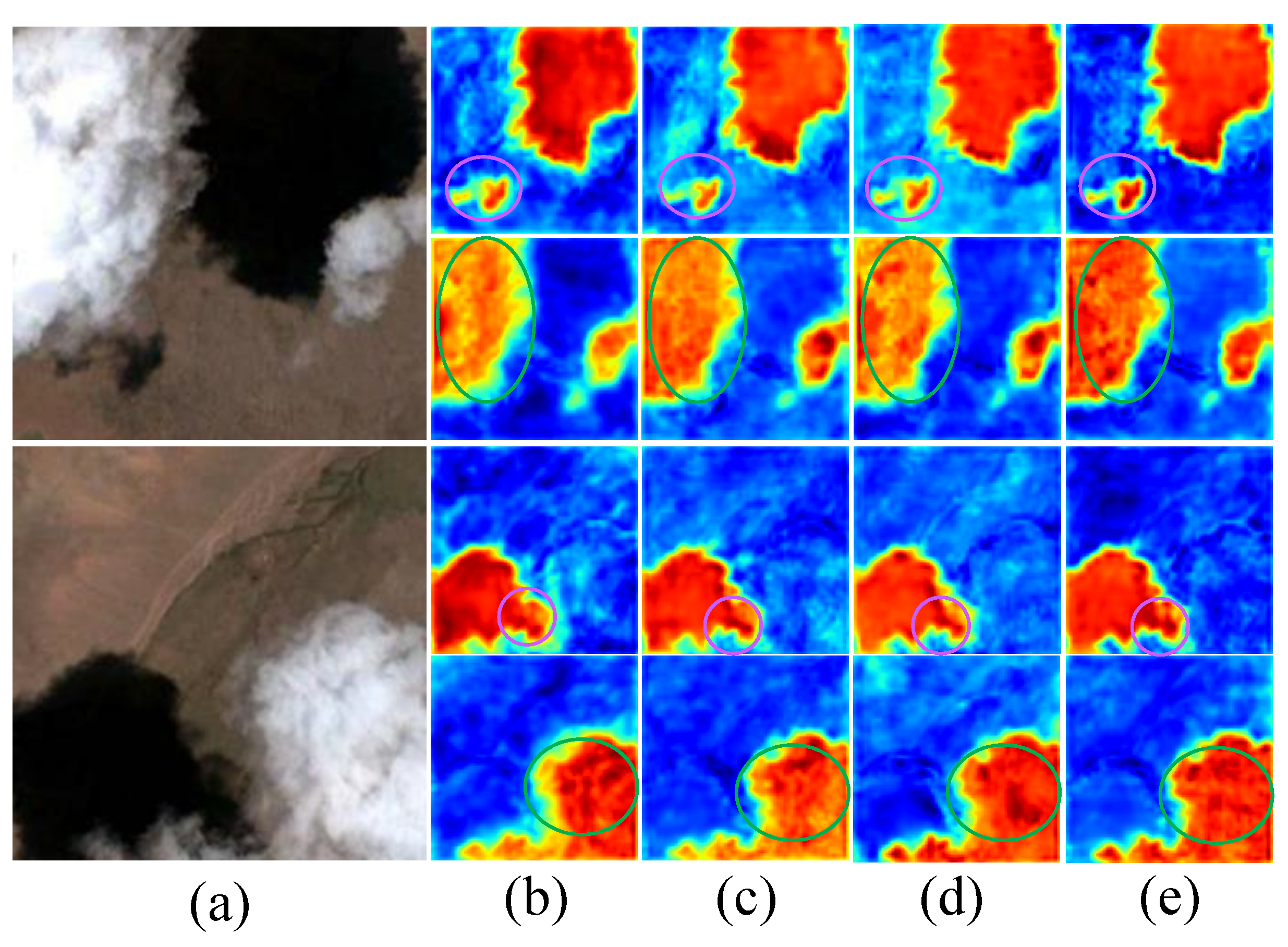
- Ablation experiments of the SFR: The Scale Fusion Restoration Module (SFR) can combine the contextual information gathered during the downsampling step with the deep semantic info obtained via LAMA. This strategy allows the two types of information to guide and fuse each other, increases the network’s ability to segment images, and perfects the feature info obtained with LPMSNet. Simultaneously, the end-stacked convolution could repair cloud as well as cloud shade edge details during the upsampling stage, boosting the segmentation effect. As shown in Table 2, SFR improves the model’s MIoU value from 92.23% to 92.63%. This data demonstrates that the module can effectively fuse multi-scale information during the upsampling stage to boost the cloud and cloud shade segmentation impact.
- Ablation Experiments of LAMA: The Location-Attention Multi-Scale Aggregation Module (LAMA) consists of a Location Attention Module and a Multi-Scale Aggregation Module. The Multi-Scale Aggregation Module efficiently recovers the feature map’s multi-scale information by pooling convolutions of multiple scales, capturing the properties of cloud and cloud shading of different sizes and better segmenting their semantic categories. The Location Attention Module retrieves the feature map’s positioning info via pooling convolution and generates attentional feature maps with the original image’s horizontal and vertical positional encodings, respectively. The attention feature map focuses on the classification information of cloud and cloud shade, which can supplement the position encoding lost in multi-scale feature extraction. In addition, in order to highlight the superiority of LAMA compared with the existing multi-scale extraction modules, we made a comparison experiment with PPM and ASPP modules in Table 2. We can clearly find that the network with the LAMA module is 0.49% and 0.34% higher in evaluation indicators than the network with the ASPP and PPM modules. Therefore, compared with the existing multi-scale extraction models, the model proposed in this paper not only is stronger than them in terms of realisation functions but also has a greater advantage in terms of segmentation index accuracy than ASPP and PPM.
- Ablation Experiment of CSA: The Channel Spatial Attention Network (CSA) can first obtain the long-distance dependence of the feature map through the improved NLNN. Design methods like residual connections can preserve the original feature information of the input. The Channel Attention Module gathers high-level characteristics via pooling operations and then feeds these high-level features into MLP to increase the model’s generalisation capability and performance. CSA could make the network dynamically focus on the long-distance dependencies between cloud and cloud shade, avoiding missed and false detection. At the same time, this module can share weights via convolution to enhance the module’s robustness. Within the entire network structure, the deep CSA can further process the deep semantic information extracted with the SAMA to capture more abstract and global dependencies, while a shallower CSA in the upsampling locations can extract more detailed and local dependencies. It can be seen from Table 2 that the CSA can effectively improve the network’s attention to cloud and cloud shade classification information. The overall evaluation index of the network with CSA increased by 0.79%, which also proves that CSA can significantly improve the segmentation effect of cloud and cloud shade.
3.4. Comparative Experiments on Different Datasets
3.4.1. Generalisation Experiment of Cloud and Cloud Shadow Dataset
3.4.2. Generalisation Experiment of HRC-WHU Dataset
3.4.3. Generalisation Experiment of L8SPARCS Dataset
4. Conclusions
4.1. Limitations and Future Research Directions
4.2. Summary
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lu, C.; Xia, M.; Qian, M.; Chen, B. Dual-branch network for cloud and cloud shadow segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5410012. [Google Scholar] [CrossRef]
- Zhang, E.; Hu, K.; Xia, M.; Weng, L.; Lin, H. Multilevel feature context semantic fusion network for cloud and cloud shadow segmentation. J. Appl. Remote Sens. 2022, 16, 046503. [Google Scholar] [CrossRef]
- Chen, K.; Xia, M.; Lin, H.; Qian, M. Multi-scale Attention Feature Aggregation Network for Cloud and Cloud Shadow Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5612216. [Google Scholar] [CrossRef]
- Qu, Y.; Xia, M.; Zhang, Y. Strip pooling channel spatial attention network for the segmentation of cloud and cloud shadow. Comput. Geosci. 2021, 157, 104940. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, E.; Xia, M.; Weng, L.; Lin, H. MCANet: A Multi-Branch Network for Cloud/Snow Segmentation in High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 1055. [Google Scholar] [CrossRef]
- Wang, D.; Weng, L.; Xia, M.; Lin, H. MBCNet: Multi-Branch Collaborative Change-Detection Network Based on Siamese Structure. Remote Sens. 2023, 15, 2237. [Google Scholar] [CrossRef]
- Chen, B.; Xia, M.; Qian, M.; Huang, J. MANet: A multi-level aggregation network for semantic segmentation of high-resolution remote sensing images. Int. J. Remote Sens. 2022, 43, 5874–5894. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Weng, L.; Lin, H.; Qian, M.; Chen, B. Axial Cross Attention Meets CNN: Bibranch Fusion Network for Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 32–43. [Google Scholar] [CrossRef]
- Gao, J.; Weng, L.; Xia, M.; Lin, H. MLNet: Multichannel feature fusion lozenge network for land segmentation. J. Appl. Remote Sens. 2022, 16, 016513. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhang, F.; Chen, Y.; Li, Z.; Hong, Z.; Liu, J.; Ma, F.; Han, J.; Ding, E. Acfnet: Attentional class feature network for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6798–6807. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Ji, H.; Xia, M.; Zhang, D.; Lin, H. Multi-Supervised Feature Fusion Attention Network for Clouds and Shadows Detection. ISPRS Int. J. Geo-Inf. 2023, 12, 247. [Google Scholar] [CrossRef]
- Xia, M.; Wang, T.; Zhang, Y.; Liu, J.; Xu, Y. Cloud/shadow segmentation based on global attention feature fusion residual network for remote sensing imagery. Int. J. Remote Sens. 2021, 42, 2022–2045. [Google Scholar] [CrossRef]
- Xia, M.; Qu, Y.; Lin, H. PANDA: Parallel asymmetric network with double attention for cloud and its shadow detection. J. Appl. Remote Sens. 2021, 15, 046512. [Google Scholar] [CrossRef]
- Miao, S.; Xia, M.; Qian, M.; Zhang, Y.; Liu, J.; Lin, H. Cloud/shadow segmentation based on multi-level feature enhanced network for remote sensing imagery. Int. J. Remote Sens. 2022, 43, 5940–5960. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, D.; Xia, M. CDUNet: Cloud detection UNet for remote sensing imagery. Remote Sens. 2021, 13, 4533. [Google Scholar] [CrossRef]
- Lu, C.; Xia, M.; Lin, H. Multi-scale strip pooling feature aggregation network for cloud and cloud shadow segmentation. Neural Comput. Appl. 2022, 34, 6149–6162. [Google Scholar] [CrossRef]
- Ma, Z.; Xia, M.; Weng, L.; Lin, H. Local Feature Search Network for Building and Water Segmentation of Remote Sensing Image. Sustainability 2023, 15, 3034. [Google Scholar] [CrossRef]
- Chen, J.; Xia, M.; Wang, D.; Lin, H. Double Branch Parallel Network for Segmentation of Buildings and Waters in Remote Sensing Images. Remote Sens. 2023, 15, 1536. [Google Scholar] [CrossRef]
- Zhang, C.; Weng, L.; Ding, L.; Xia, M.; Lin, H. CRSNet: Cloud and Cloud Shadow Refinement Segmentation Networks for Remote Sensing Imagery. Remote Sens. 2023, 15, 1664. [Google Scholar] [CrossRef]
- Chen, B.; Xia, M.; Huang, J. MFANet: A Multi-Level Feature Aggregation Network for Semantic Segmentation of Land Cover. Remote Sens. 2021, 13, 731. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Weng, L.; Pang, K.; Xia, M.; Lin, H.; Qian, M.; Zhu, C. Sgformer: A Local and Global Features Coupling Network for Semantic Segmentation of Land Cover. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 6812–6824. [Google Scholar] [CrossRef]
- Hu, K.; Wang, T.; Shen, C.; Weng, C.; Zhou, F.; Xia, M.; Weng, L. Overview of Underwater 3D Reconstruction Technology Based on Optical Images. J. Mar. Sci. Eng. 2023, 11, 949. [Google Scholar] [CrossRef]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3286–3295. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Vedaldi, A. Gather-excite: Exploiting feature context in convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Dai, X.; Xia, M.; Weng, L.; Hu, K.; Lin, H.; Qian, M. Multi-Scale Location Attention Network for Building and Water Segmentation of Remote Sensing Image. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5609519. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Lyu, X.; Tong, Y.; Xu, Z.; Zhou, J. A Synergistical Attention Model for Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5400916. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Zhang, S.; Weng, L. STPGTN—A Multi-Branch Parameters Identification Method Considering Spatial Constraints and Transient Measurement Data. Comput. Model. Eng. Sci. 2023, 136, 2635–2654. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for medium and high resolution remote sensing images of different sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef] [Green Version]
- Hughes, M.J.; Hayes, D.J. Automated detection of cloud and cloud shadow in single-date Landsat imagery using neural networks and spatial post-processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Leng, Z.; Tan, M.; Liu, C.; Cubuk, E.D.; Shi, X.; Cheng, S.; Anguelov, D. Polyloss: A polynomial expansion perspective of classification loss functions. arXiv 2022, arXiv:2204.12511. [Google Scholar]
- Li, X.; Xu, F.; Lyu, X.; Gao, H.; Tong, Y.; Cai, S.; Li, S.; Liu, D. Dual attention deep fusion semantic segmentation networks of large-scale satellite remote-sensing images. Int. J. Remote Sens. 2021, 42, 3583–3610. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Xia, R.; Li, T.; Chen, Z.; Wang, X.; Xu, Z.; Lyu, X. Encoding contextual information by interlacing transformer and convolution for remote sensing imagery semantic segmentation. Remote Sens. 2022, 14, 4065. [Google Scholar] [CrossRef]
- Elmezain, M.; Malki, A.; Gad, I.; Atlam, E.S. Hybrid Deep Learning Model–Based Prediction of Images Related to Cyberbullying. Int. J. Appl. Math. Comput. Sci. 2022, 32, 323–334. [Google Scholar]
- Ma, C.; Weng, L.; Xia, M.; Lin, H.; Qian, M.; Zhang, Y. Dual-branch network for change detection of remote sensing image. Eng. Appl. Artif. Intell. 2023, 123, 106324. [Google Scholar] [CrossRef]
- Yin, H.; Weng, L.; Li, Y.; Xia, M.; Hu, K.; Lin, H.; Qian, M. Attention-guided siamese networks for change detection in high resolution remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2023, 117, 103206. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Xia, R.; Tong, Y.; Li, L.; Xu, Z.; Lyu, X. Hybridizing Euclidean and Hyperbolic Similarities for Attentively Refining Representations in Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5003605. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 173–190. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a discriminative feature network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1857–1866. [Google Scholar]
- Hong, Y.; Pan, H.; Sun, W.; Jia, Y. Deep dual-resolution networks for real-time and accurate semantic segmentation of road scenes. arXiv 2021, arXiv:2101.06085. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Zhang, G.; Gao, X.; Yang, Y.; Wang, M.; Ran, S. Controllably deep supervision and multi-scale feature fusion network for cloud and snow detection based on medium-and high-resolution imagery dataset. Remote Sens. 2021, 13, 4805. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original | Modified | |||
|---|---|---|---|---|
| Layer | 50 layer | Size | Modified 50 layer | Size |
| Stem | 7 × 7, stride 2 | 1/2 | 1/2 | |
| L1 | 3 × 3, Max pool, stride 2 | 1/4 | 1/4 | |
| L2 | 1/8 | 1/8 | ||
| L3 | 1/16 | Dilated convolution | 1/8 | |
| L4 | 1/32 | Dilated convolution | 1/8 | |
| Method | MIoU (%) |
|---|---|
| ResNet50 | 92.23 |
| ResNet50 + SFR | 92.63 |
| ResNet50 + SFR + ASPP | 93.06 |
| ResNet50 + SFR + PPM | 93.21 |
| ResNet50 + SFR + LAMA | 93.55 |
| Swin-T + SFR + LAMA + CSA | 94.01 |
| ResNet18 + SFR + LAMA + CSA | 93.79 |
| ResNet34 + SFR + LAMA + CSA | 93.83 |
| ResNet50 + SFR + LAMA + SE | 93.79 |
| ResNet50 + SFR + LAMA + CBAM | 93.88 |
| ResNet50 + SFR + LAMA + Non-Local | 94.02 |
| ResNet50 + SFR + LAMA + CSA | 94.34 |
| Method | PA (%) | MPA (%) | MIoU (%) |
|---|---|---|---|
| UNet [49] | 95.56 | 94.74 | 90.09 |
| DeepLab V3Plus (ResNet 50) [11] | 96.11 | 95.02 | 90.87 |
| FCN-8s [48] | 96.15 | 95.22 | 91.12 |
| PSPNet (ResNet 50) [10] | 96.16 | 95.07 | 91.24 |
| HRNet [53] | 96.46 | 95.68 | 91.66 |
| DDRNet [52] | 96.67 | 95.85 | 92.12 |
| OCRNet (ResNet 101) [50] | 96.54 | 95.82 | 92.14 |
| DFN (ResNet101) [51] | 96.59 | 95.86 | 92.45 |
| CCNet (ResNet 50) [13] | 96.69 | 95.95 | 92.51 |
| ACFNet (ResNet 50) [12] | 96.92 | 96.32 | 92.81 |
| Swin-T [16] | 95.69 | 94.51 | 90.08 |
| CvT [15] | 96.31 | 95.54 | 91.68 |
| PvT [17] | 96.91 | 96.11 | 92.95 |
| GAFFNet (ResNet 18) [19] | 96.11 | 95.07 | 91.04 |
| PANDA [20] | 96.15 | 95.37 | 91.32 |
| CSDNet [54] | 97.12 | 96.32 | 93.05 |
| DBNet [1] | 97.27 | 96.41 | 93.12 |
| MSPFANet [23] | 97.41 | 96.56 | 93.27 |
| LPMSNet (ours) | 97.62 | 97.05 | 94.38 |
| Cloud | Cloud Shadow | |||||
|---|---|---|---|---|---|---|
| Method | P (%) | R (%) | (%) | P (%) | R (%) | (%) |
| UNet [49] | 96.32 | 92.71 | 94.47 | 91.68 | 94.07 | 92.89 |
| DeepLab V3Plus (ResNet 50) [11] | 94.68 | 95.45 | 95.03 | 92.92 | 93.63 | 93.31 |
| FCN-8s [48] | 95.32 | 95.15 | 95.24 | 93.21 | 93.91 | 93.58 |
| PSPNet (ResNet 50) [10] | 94.61 | 96.04 | 95.32 | 93.17 | 94.11 | 93.57 |
| HRNet [53] | 95.53 | 95.78 | 95.64 | 94.13 | 93.47 | 93.79 |
| DDRNet [52] | 96.33 | 95.45 | 95.88 | 94.51 | 93.91 | 94.21 |
| OCRNet (ResNet 101) [50] | 96.21 | 95.33 | 95.76 | 93.91 | 94.74 | 94.35 |
| DFN (ResNet101) [51] | 96.14 | 95.46 | 95.84 | 94.03 | 95.12 | 94.45 |
| CCNet (ResNet 50) [13] | 95.98 | 95.52 | 96.94 | 94.17 | 95.23 | 94.68 |
| ACFNet (ResNet 50) [12] | 96.21 | 96.08 | 96.16 | 94.34 | 95.32 | 94.84 |
| Swin-T [16] | 94.91 | 94.67 | 94.78 | 91.84 | 93.43 | 92.61 |
| CvT [15] | 95.74 | 95.56 | 95.63 | 92.45 | 93.87 | 93.94 |
| PvT [17] | 96.24 | 96.51 | 96.37 | 94.32 | 95.04 | 94.68 |
| GAFFNet (ResNet 18) [19] | 95.31 | 94.93 | 95.21 | 92.49 | 94.36 | 93.41 |
| PANDA [20] | 95.49 | 95.32 | 95.41 | 93.80 | 94.31 | 94.12 |
| CSDNet [54] | 96.12 | 96.57 | 96.31 | 94.14 | 95.95 | 95.03 |
| DBNet [1] | 96.79 | 96.56 | 96.62 | 94.89 | 94.41 | 94.58 |
| MSPFANet [23] | 96.87 | 96.63 | 96.56 | 94.21 | 94.51 | 94.35 |
| LPMSNet (ours) | 97.17 | 96.83 | 97.00 | 95.70 | 96.38 | 96.04 |
| Method | P (%) | R (%) | (%) | IoU (%) |
|---|---|---|---|---|
| UNet [49] | 90.86 | 94.88 | 92.88 | 86.68 |
| DeepLab V3Plus (ResNet 50) [11] | 92.04 | 94.69 | 93.38 | 87.54 |
| FCN-8s [48] | 92.51 | 93.48 | 92.96 | 86.97 |
| PSPNet (ResNet 50) [10] | 92.57 | 94.95 | 94.12 | 89.06 |
| HRNet [53] | 92.33 | 94.21 | 93.51 | 87.98 |
| DDRNet [52] | 93.11 | 95.27 | 94.17 | 88.98 |
| OCRNet (ResNet 101) [50] | 92.09 | 94.62 | 93.84 | 88.38 |
| DFN (ResNet101) [51] | 92.40 | 94.64 | 93.38 | 87.68 |
| CCNet (ResNet 50) [13] | 92.35 | 94.46 | 93.89 | 88.56 |
| ACFNet (ResNet 50) [12] | 93.78 | 94.99 | 93.78 | 89.65 |
| Swin-T [16] | 91.69 | 93.06 | 92.32 | 85.91 |
| CvT [15] | 91.94 | 94.94 | 93.45 | 87.76 |
| PvT [17] | 91.90 | 93.98 | 92.94 | 86.87 |
| GAFFNet (ResNet 18) [19] | 93.94 | 95.43 | 94.75 | 90.08 |
| PANDA [20] | 92.25 | 93.95 | 93.04 | 87.11 |
| CSDNet [54] | 92.14 | 94.67 | 93.38 | 87.65 |
| DBNet [1] | 93.79 | 95.08 | 94.71 | 90.02 |
| MSPFANet [23] | 93.88 | 95.32 | 94.78 | 90.11 |
| LPMSNet (ours) | 94.84 | 95.78 | 94.87 | 90.51 |
| Class Pixel Accuracy | Overall Results | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | Cloud (%) | Cloud Shadow (%) | Snow/Ice (%) | Water (%) | Land (%) | PA (%) | MPA (%) | MIoU (%) |
| UNet [49] | 88.82 | 75.81 | 93.51 | 93.76 | 93.41 | 91.67 | 89.09 | 78.82 |
| DeepLab V3Plus (ResNet 50) [11] | 87.24 | 68.94 | 91.85 | 90.07 | 93.26 | 90.41 | 86.25 | 75.81 |
| FCN-8s [48] | 89.12 | 71.57 | 91.81 | 94.27 | 93.14 | 91.23 | 87.94 | 76.47 |
| PSPNet (ResNet 50) [10] | 91.11 | 76.07 | 91.51 | 90.69 | 92.12 | 91.01 | 88.31 | 76.25 |
| HRNet [53] | 87.51 | 70.21 | 91.96 | 90.22 | 93.41 | 90.52 | 86.32 | 75.89 |
| DDRNet [52] | 88.80 | 70.03 | 88.73 | 89.84 | 92.21 | 90.13 | 85.92 | 74.58 |
| OCRNet (ResNet 101) [50] | 87.79 | 78.11 | 91.12 | 93.03 | 94.12 | 91.89 | 88.86 | 78.68 |
| DFN (ResNet101) [51] | 87.31 | 68.74 | 90.00 | 91.38 | 94.25 | 91.00 | 86.33 | 76.46 |
| CCNet (ResNet 50) [13] | 88.01 | 75.45 | 92.42 | 90.71 | 93.35 | 91.21 | 88.01 | 76.69 |
| ACFNet (ResNet 50) [12] | 90.47 | 78.49 | 93.46 | 93.25 | 92.93 | 91.81 | 89.69 | 77.78 |
| Swin-T [16] | 87.68 | 71.54 | 91.58 | 90.67 | 93.87 | 91.12 | 87.09 | 77.38 |
| CvT [15] | 85.67 | 73.85 | 91.58 | 85.21 | 94.55 | 90.96 | 86.15 | 76.91 |
| PvT [17] | 88.97 | 72.36 | 94.47 | 89.32 | 93.92 | 91.36 | 87.79 | 78.25 |
| GAFFNet (ResNet 18) [19] | 89.48 | 75.89 | 91.95 | 95.17 | 94.08 | 92.18 | 89.37 | 79.01 |
| PANDA [20] | 85.79 | 71.94 | 87.91 | 88.38 | 92.25 | 89.68 | 85.25 | 73.41 |
| CSDNet [54] | 89.12 | 76.43 | 91.41 | 90.23 | 95.68 | 92.81 | 88.56 | 80.67 |
| DBNet [1] | 90.24 | 78.56 | 93.78 | 91.14 | 95.75 | 93.01 | 89.54 | 81.21 |
| MSPFANet [23] | 89.07 | 73.18 | 91.23 | 88.91 | 93.56 | 90.89 | 87.34 | 78.02 |
| LPMSNet (ours) | 91.65 | 81.63 | 94.02 | 95.04 | 95.87 | 93.27 | 90.01 | 81.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, X.; Chen, K.; Xia, M.; Weng, L.; Lin, H. LPMSNet: Location Pooling Multi-Scale Network for Cloud and Cloud Shadow Segmentation. Remote Sens. 2023, 15, 4005. https://doi.org/10.3390/rs15164005
Dai X, Chen K, Xia M, Weng L, Lin H. LPMSNet: Location Pooling Multi-Scale Network for Cloud and Cloud Shadow Segmentation. Remote Sensing. 2023; 15(16):4005. https://doi.org/10.3390/rs15164005
Chicago/Turabian StyleDai, Xin, Kai Chen, Min Xia, Liguo Weng, and Haifeng Lin. 2023. "LPMSNet: Location Pooling Multi-Scale Network for Cloud and Cloud Shadow Segmentation" Remote Sensing 15, no. 16: 4005. https://doi.org/10.3390/rs15164005
APA StyleDai, X., Chen, K., Xia, M., Weng, L., & Lin, H. (2023). LPMSNet: Location Pooling Multi-Scale Network for Cloud and Cloud Shadow Segmentation. Remote Sensing, 15(16), 4005. https://doi.org/10.3390/rs15164005