1. Introduction
Object detection in remotely sensed images is a challenging task due to the non-cooperative imaging mode and complex imaging conditions. Although, for natural images, learning-based object detection has acquired impressive advances in the last decade, such as Faster RCNN [
1], YOLO [
2], SSD [
3], and RetinaNet [
4], their applicability to remotely sensed images is limited. This limitation arises from the massive irrelevant backgrounds under the non-cooperative imaging mode and the diversity of targets under complex imaging conditions.
Indeed, early learning models for object detection in remotely sensed images were improved from the original models for object detection in natural images by adjusting the regression strategy, such as the FR-O [
5], LR-O [
6], and DCN [
7], which were enlightening but suffered from poor detection accuracy at the same time.
Inspired by scene text detection, various object detection methods for remotely sensed images have been proposed, such as the R2CNN [
8], RRPN [
9], ICN [
10], and CAD-Net [
11], with a higher detection accuracy but also with an increase in computation complexity. Specifically, the R2CNN [
8] utilized multi-scale features and inclined non-maximum suppression (NMS) to detect oriented objects. The RRPN [
9] introduced the rotational region proposal network (RPN) and rotational region-of-interest (RoI) strategy to handle arbitrary-oriented proposals. The ICN [
10] also applied the rotational RPN, multi-scale rotational RoI, and rotational NMS for the detection of oriented objects. CAD-Net [
11] incorporated global and local features to improve the accuracy of object detection in remotely sensed images. However, these methods primarily emphasized the improvement of network structures for better feature expression rather than focusing on the properties of remotely sensed targets.
With further study of the properties of remotely sensed images, SCRDet [
12], RT [
13], Gliding Vertex [
14], BBAvector [
15], and HeatNet [
16] were proposed to tackle certain characteristics of remotely sensed targets. In these methods, SCRDet [
12] employed pixel and channel attention for the detection of small and cluttered objects. RT [
13] designed a rotated RoI learner and a rotated position-sensitive RoI align module to extract rotation-invariant features. Gliding Vertex [
14] utilized the gliding of the vertex of the horizontal bounding box on each side to denote an oriented object. BBAvector [
15] detected the center keypoints and regressed the box-boundary-aware vectors to capture the oriented objects. HeatNet [
16] addressed the cluster distribution problem of remotely sensed targets and refined an FFT-based heatmap to tackle the challenge of densely distributed targets. These methods concerned certain properties of remotely sensed targets, most of which focused on improving the representation of oriented bounding boxes. However, the relationship between the targets in different categories has not been taken into account, especially regarding the imbalance problem of sample data between different categories [
17].
In recent years, transformers have also been introduced to object detection in remotely sensed images, such as the AO2-DETR [
18], Gansformer [
19], TRD [
20], and TransConvNet [
21], to deal with the small sample problem in network training [
22]. Specifically, the AO2-DETR [
18] generated oriented proposals to modulate cross-attention in the transformer decoder. Gansformer [
19] employed a generative model to expand the sample data before the transformer backbone. The TRD [
20] combined data augmentation with a transformer to improve the detection performance. TransConvNet [
21] utilized an adaptive feature-fusion network to improve the representational ability for the remotely sensed targets. These methods focused on improving learning efficiency to deal with the small sample problem in network training [
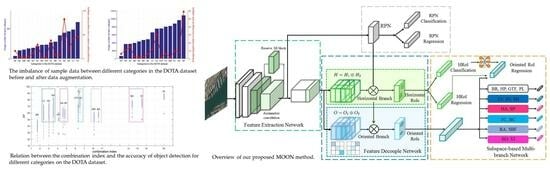
22]. However, nearly none of these methods concerned with the influence of the long-tail problem, which arises from the imbalance of sample data between different categories, as shown in
Figure 1.
Moreover, almost all of the above learning models take the entire sample space as one space, which makes the high-dimensional nonlinearity for all of the possible categories cannot be neglected, whereby the high expressing ability, with more learning parameters for this kind of high-dimensional nonlinearity, must be considered. Additionally, more training samples are required to ensure the steady learning of the network. However, due to the non-cooperative imaging mode and complex imaging conditions, the amount of sample data is difficult to meet the needs of network training [
23]. Training a universal network for the entire sample space has been confirmed by other application tasks to be much more difficult, or even impossible, compared to training several specific subnetworks for each subspace [
24,
25,
26,
27]. Specifically, to deal with this problem, GLRR [
24] combined similar image patches into one group and removed the noise in the hyperspectral images by using a group-based reconstruction with a low-rank constraint, [
25] divided the pixels in one sample image into different subspaces by using an unsupervised clustering, and learned the nonlinear relationship from the RGB to the high-spatial-resolution hyperspectral image by using a cluster-based multi-branch network for spectral super resolution. Furthermore, a fusion method for low-spatial-resolution hyperspectral and high-spatial-resolution multi-spectral images was also proposed [
26]. Apart from these, [
27] also utilized the subspace-dividing strategy for change detection in hyperspectral images. We realized that the similarity between the different categories should also be considered for the training of an object detection network. Especially, a similarity measurement method for different categories suitable for the object detection, a new subspace-dividing strategy especially for the imbalance problem between different categories, and a suitable network structure for the subspace-based object detection should be considered for remotely sensed images.
On the other hand, for the loss functions in object detection networks, two paradigms exist, i.e., learning from the sample data with category-level labels and learning from sample data with instance-level labels [
28]. The former optimized the similarity between sample data and feature expression by using category-level loss functions, such as L2-softmax [
29], large-margin softmax [
30], and AM softmax [
31]. The latter optimized the instance-level similarity through metric learning based loss functions, such as triplet loss [
32], angular loss [
33], and multi-similarity loss [
34]. Among these methods, the category-level loss function is dominant for object detection in remotely sensed images, which follows the convention of object detection in natural images. On this basis, SCRDet [
12] and RSDet [
35] introduced constraints to the loss function, i.e., the IoU Smooth L1 Loss and Modulated Loss. DCL [
36] utilized the angle distance and aspect-ratio-sensitive weighting to handle the boundary discontinuity of labels. Most of these methods primarily focused on the category-level loss function and the instance-level loss function, without thoroughly exploring the relationship between the targets of different categories.
Faced with the above problems, a subspace-dividing strategy and a subspace-based Multi-branch Object detectiOn Network (termed as MOON) is proposed in this paper to leverage the amounts of sample data in different subspaces and solve the long-tail problem for the remotely sensed images. In detail, a combination index is defined to depict this kind of similarity, a generalized category consisting of similar categories is proposed to represent the subspace by using the combination index, and a new subspace-based loss function is devised to take the relationship between targets in one subspace and across different subspaces into consideration to integrate the sample data from similar categories within a subspace and to balance the amounts of sample data between different subspaces. Moreover, a subspace-based multi-branch network is constructed to ensure the subspace-aware regression, combined with a specially designed module to decouple the shared features into a horizontal and rotated branch, and to enhance the rotated features. The novelties and the contributions of our proposed method can be summarized as follows:
To our best knowledge, this is the first time that the long-tail problem in object detection for remotely sensed images is focused to solve the high imbalance of sample data between different categories;
A new framework of subspace-based object detection for remotely sensed images is proposed, in which a new combination index is defined to quantify certain similarities between different categories, and a new subspace-dividing strategy is also proposed to divide the entire sample space and balance the amounts of sample data between different subspaces;
A new subspace-based loss function is designed to account for the relationship between targets in one subspace and across different subspaces, and a subspace-based multi-branch network is constructed to ensure the subspace-aware regression, combined with a specially designed module to decouple the learning of horizontal and rotated features.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}