
UCTNet with Dual-Flow Architecture: Snow Coverage Mapping with Sentinel-2 Satellite Imagery

 ,
,  ,
,
Abstract
:1. Introduction
- (1)
- A dual-flow architecture composed of a CNN branch and Transformer branch is proposed for the first time to solve the challenge of snow/cloud classification;
- (2)
- As the core of encoder and decoder blocks, CTIM is introduced to leverage the local and global features for better performance;
- (3)
- FIFM and AIFM are designed to fuse the two branches’ outputs for better supervision;
- (4)
- Comparative experiments are conducted on the snow/cloud Satellite dataset to validate the proposed algorithm, which shows that the proposed UCTNet outperforms both CNN- and Transformer-based networks in both accuracy and model size.
2. Materials and Dataset Collection
2.1. Satellite Image Collection
2.2. Data Labeling
3. Methodology
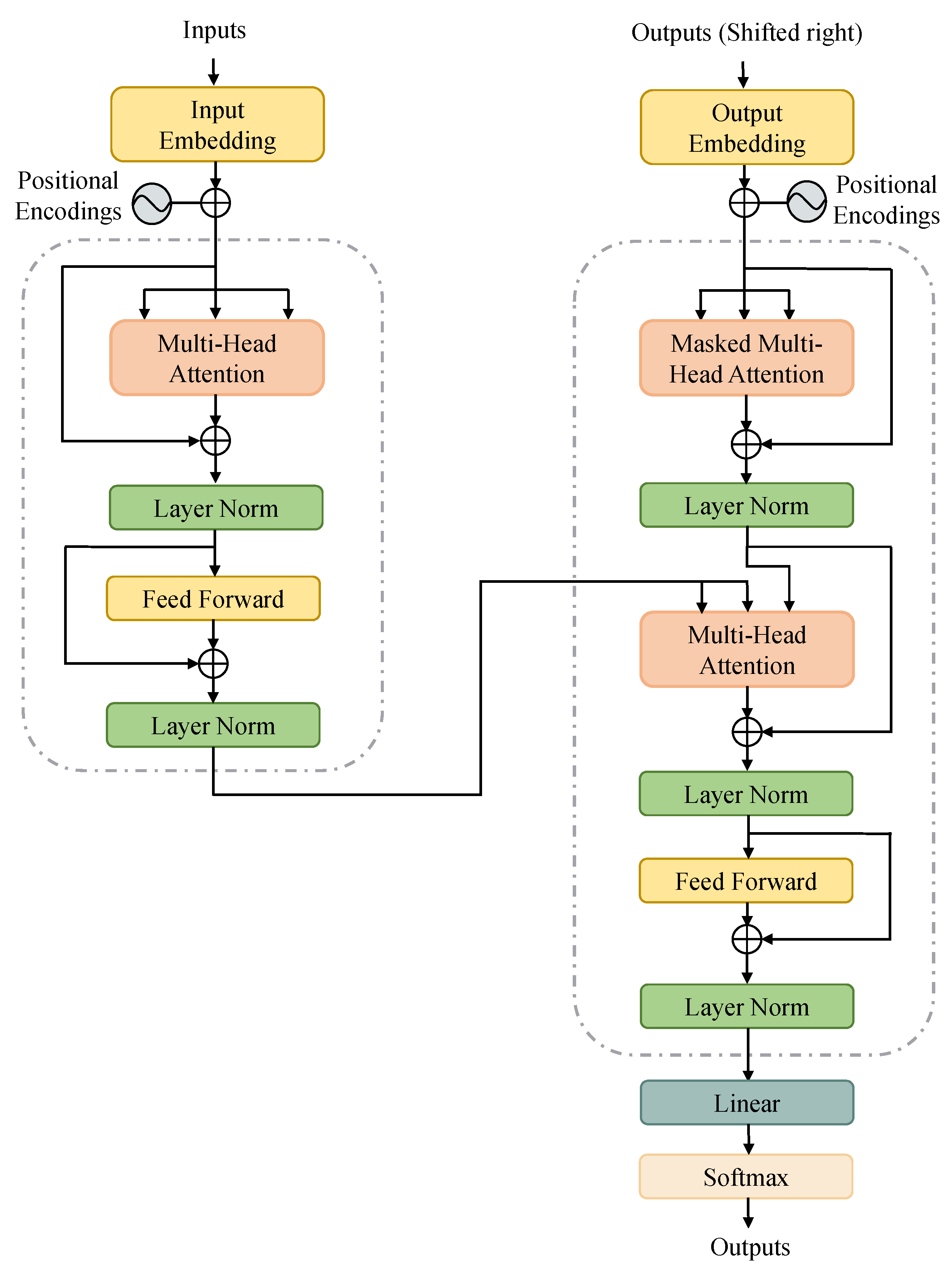
3.1. A Brief Review of Transformer
3.2. Overall Architecture of UCTNet
3.3. CNN and Transformer Integration Module Design
3.3.1. CNN Branch in CTIM
3.3.2. Transformer Branch in CTIM
3.4. Final Information Fusion Module (FIFM) Design
3.5. Auxiliary Information Fusion Head (AIFH) Design
3.6. Loss Function Design
3.7. Experimental Settings
3.8. Performance Metrics
4. Results
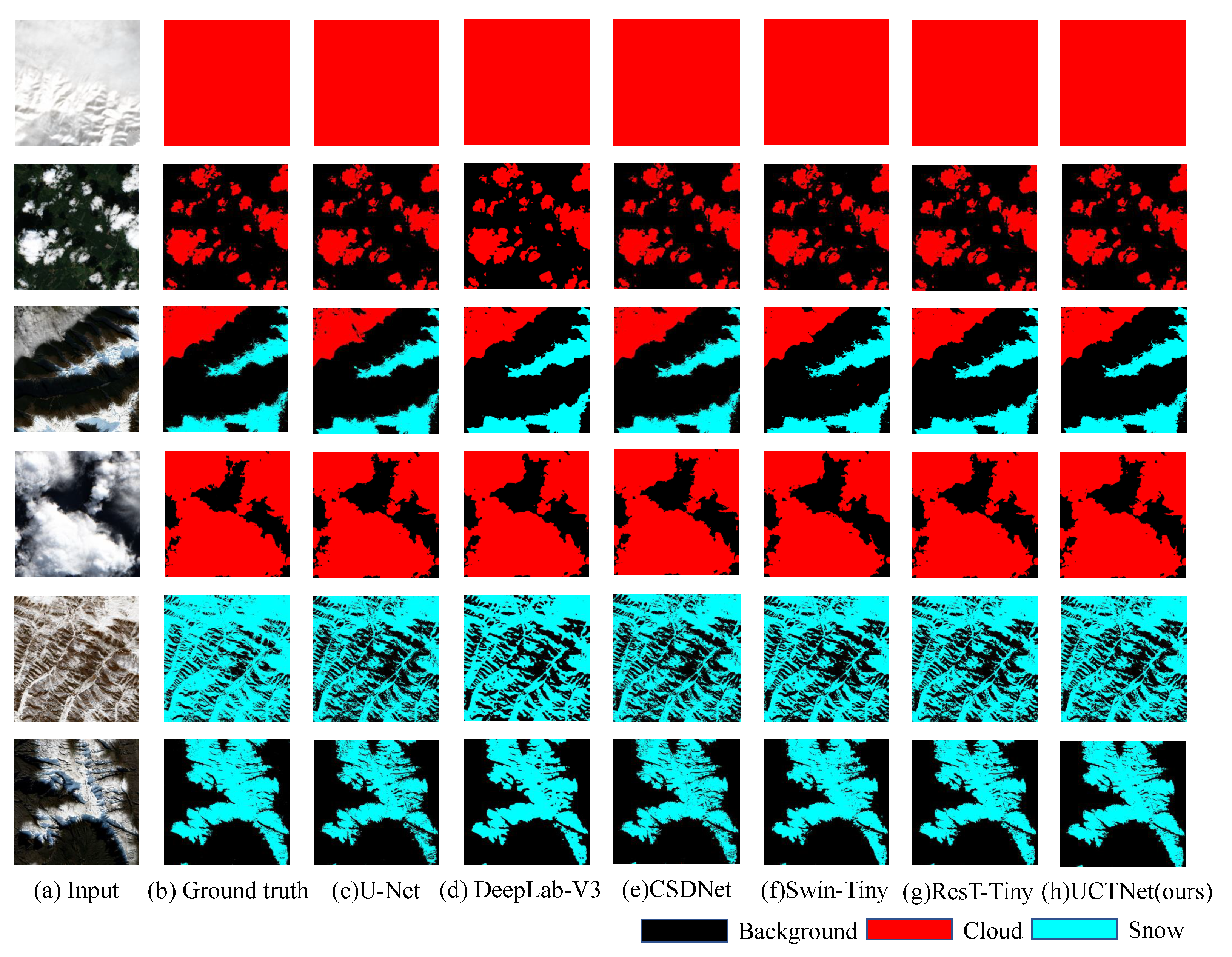
4.1. Quantitative and Qualitative Result Analysis
4.2. Exploration on the Effectiveness of Two Branches Architecture
4.3. Exploration on Location Setting of the Complex Ctim
4.4. Exploration on Position Encoding of the Transformer Branch
4.5. Exploration on the Effectiveness of AIFH
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Munawar, H.S.; Ullah, F.; Qayyum, S.; Khan, S.I.; Mojtahedi, M. Uavs in disaster management: Application of integrated aerial imagery and convolutional neural network for flood detection. Sustainability 2021, 13, 7547. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Y.; Wang, R.; Zheng, P. Modeling and evaluating land-use/land-cover change for urban planning and sustainability: A case study of Dongying city, China. J. Clean. Prod. 2018, 172, 1529–1534. [Google Scholar] [CrossRef]
- Cai, G.; Ren, H.; Yang, L.; Zhang, N.; Du, M.; Wu, C. Detailed urban land use land cover classification at the metropolitan scale using a three-layer classification scheme. Sensors 2019, 19, 3120. [Google Scholar] [CrossRef] [PubMed]
- Shi, H.; Chen, L.; Bi, F.K.; Chen, H.; Yu, Y. Accurate urban area detection in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1948–1952. [Google Scholar] [CrossRef]
- Zhang, T.; Su, J.; Xu, Z.; Luo, Y.; Li, J. Sentinel-2 satellite imagery for urban land cover classification by optimized random forest classifier. Appl. Sci. 2021, 11, 543. [Google Scholar] [CrossRef]
- Gannon, C.S.; Steinberg, N.C. A global assessment of wildfire potential under climate change utilizing Keetch-Byram drought index and land cover classifications. Environ. Res. Commun. 2021, 3, 035002. [Google Scholar] [CrossRef]
- Kumar, M.; Fadhil Al-Quraishi, A.M.; Mondal, I. Glacier changes monitoring in Bhutan High Himalaya using remote sensing technology. Environ. Eng. Res. 2020, 26, 190255. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Zhang, T.X.; Su, J.Y.; Liu, C.J.; Chen, W.H. Potential bands of sentinel-2A satellite for classification problems in precision agriculture. Int. J. Autom. Comput. 2019, 16, 16–26. [Google Scholar] [CrossRef]
- Zhang, Y.; Rossow, W.B.; Lacis, A.A.; Oinas, V.; Mishchenko, M.I. Calculation of radiative fluxes from the surface to top of atmosphere based on ISCCP and other global data sets: Refinements of the radiative transfer model and the input data. J. Geophys. Res. Atmos. 2004, 109, 19105. [Google Scholar] [CrossRef]
- Yin, M.; Wang, P.; Ni, C.; Hao, W. Cloud and Snow Detection of Remote Sensing Images Based on Improved Unet3. Sci. Rep. 2022, 12, 14415. [Google Scholar] [CrossRef]
- Wang, Y.; Su, J.; Zhai, X.; Meng, F.; Liu, C. Snow coverage mapping by learning from sentinel-2 satellite multispectral images via machine learning algorithms. Remote Sens. 2022, 14, 782. [Google Scholar] [CrossRef]
- Su, J.; Yi, D.; Su, B.; Mi, Z.; Liu, C.; Hu, X.; Xu, X.; Guo, L.; Chen, W.H. Aerial Visual Perception in Smart Farming: Field Study of Wheat Yellow Rust Monitoring. IEEE Trans. Ind. Inform. 2020, 17, 2242–2249. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Irish, R.R.; Barker, J.L.; Goward, S.N.; Arvidson, T. Characterization of the Landsat-7 ETM+ automated cloud-cover assessment (ACCA) algorithm. Photogramm. Eng. Remote Sens. 2006, 72, 1179–1188. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Automated cloud, cloud shadow, and snow detection in multitemporal Landsat data: An algorithm designed specifically for monitoring land cover change. Remote Sens. Environ. 2014, 152, 217–234. [Google Scholar] [CrossRef]
- Stillinger, T.; Roberts, D.A.; Collar, N.M.; Dozier, J. Cloud masking for Landsat 8 and MODIS Terra over snow-covered terrain: Error analysis and spectral similarity between snow and cloud. Water Resour. Res. 2019, 55, 6169–6184. [Google Scholar] [CrossRef] [PubMed]
- Bai, T.; Li, D.; Sun, K.; Chen, Y.; Li, W. Cloud detection for high-resolution satellite imagery using machine learning and multi-feature fusion. Remote Sens. 2016, 8, 715. [Google Scholar] [CrossRef]
- Nijhawan, R.; Raman, B.; Das, J. Meta-classifier approach with ANN, SVM, rotation forest, and random forest for snow cover mapping. In Proceedings of the 2nd International Conference on Computer Vision & Image Processing, Roorkee, India, 9–12 September 2017; Springer: Berlin/Heidelberg, Germany, 2018; pp. 279–287. [Google Scholar]
- Ghasemian, N.; Akhoondzadeh, M. Integration of VIR and thermal bands for cloud, snow/ice and thin cirrus detection in MODIS satellite images. In Proceedings of the Third International Conference on Intelligent Decision Science, Tehran, Iran, 16–18 May 2018; pp. 1–37. [Google Scholar]
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D., Jr.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Hughes, M.J.; Laue, B. Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef]
- Wang, L.; Chen, Y.; Tang, L.; Fan, R.; Yao, Y. Object-based convolutional neural networks for cloud and snow detection in high-resolution multispectral imagers. Water 2018, 10, 1666. [Google Scholar] [CrossRef]
- Mohapatra, M.; Gupta, P.K.; Nikam, B.R.; Thakur, P.K. Cloud segmentation in Advanced Wide Field Sensor (AWiFS) data products using deep learning approach. J. Geomat. 2022, 16, 33–44. [Google Scholar]
- Zhan, Y.; Wang, J.; Shi, J.; Cheng, G.; Yao, L.; Sun, W. Distinguishing cloud and snow in satellite images via deep convolutional network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1785–1789. [Google Scholar] [CrossRef]
- He, J.; Zhao, L.; Yang, H.; Zhang, M.; Li, W. HSI-BERT: Hyperspectral image classification using the bidirectional encoder representation from transformers. IEEE Trans. Geosci. Remote Sens. 2019, 58, 165–178. [Google Scholar] [CrossRef]
- Yu, Y.; Jiang, T.; Gao, J.; Guan, H.; Li, D.; Gao, S.; Tang, E.; Wang, W.; Tang, P.; Li, J. CapViT: Cross-context capsule vision transformers for land cover classification with airborne multispectral LiDAR data. Int. J. Appl. Earth Obs. Geoinf. 2022, 111, 102837. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Xu, Z.; Zhang, W.; Zhang, T.; Yang, Z.; Li, J. Efficient transformer for remote sensing image segmentation. Remote Sens. 2021, 13, 3585. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–15. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, G.; Gao, X.; Yang, Y.; Wang, M.; Ran, S. Controllably Deep Supervision and Multi-Scale Feature Fusion Network for Cloud and Snow Detection Based on Medium-and High-Resolution Imagery Dataset. Remote Sens. 2021, 13, 4805. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhang, Q.; Yang, Y.B. ResT: An efficient transformer for visual recognition. Adv. Neural Inf. Process. Syst. 2021, 34, 15475–15485. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band No. | Characteristic | Wavelength (m) | Resolution (m) |
|---|---|---|---|
| 1 | Coastal Aerosol | 0.443 | 60 |
| 2 | Blue | 0.490 | 10 |
| 3 | Green | 0.560 | 10 |
| 4 | Red | 0.665 | 10 |
| 5 | Near Infrared (Red Edge 1) | 0.705 | 20 |
| 6 | Near Infrared (Red Edge 2) | 0.740 | 20 |
| 7 | Near Infrared (Red Edge 3) | 0.783 | 20 |
| 8 | Near Infrared (NIR) | 0.842 | 10 |
| 8A | Near Infrared (Red Edge 4) | 0.865 | 20 |
| 9 | Water Vapor | 0.945 | 60 |
| 10 | Cirrus | 1.375 | 60 |
| 11 | Shortwave Infrared (SWIR 1) | 1.610 | 20 |
| 12 | Shortwave Infrared (SWIR 2) | 2.190 | 20 |
| Methods | Multiscale Testing | Params (M) | Precision (%) | Recall (%) | F1 (%) | ACC (%) | mIoU |
|---|---|---|---|---|---|---|---|
| U-Net | ✓ | 13.40 | 95.74 | 92.97 | 94.03 | 94.58 | 88.91 |
| DeepLab-V3 | ✓ | 16.42 | 95.41 | 93.65 | 94.38 | 94.84 | 89.51 |
| CSDNet | ✓ | 8.66 | 96.10 | 93.67 | 94.63 | 95.17 | 89.97 |
| Swin-Tiny | ✓ | 29.25 | 95.10 | 93.10 | 93.92 | 94.35 | 88.67 |
| ResT-Tiny | ✓ | 11.30 | 95.65 | 93.70 | 94.50 | 94.92 | 89.70 |
| UCTNet (ours) | ✓ | 3.93 | 96.24 | 94.68 | 95.35 | 95.72 | 91.21 |
| Methods | C → T | T → C | Precision (%) | Recall (%) | F1 (%) | ACC (%) | mIoU (%) |
|---|---|---|---|---|---|---|---|
| Only CNN | - | - | 95.47 | 92.56 | 93.66 | 94.21 | 88.28 |
| Only Trans | - | - | 95.48 | 93.81 | 94.51 | 94.9 | 89.72 |
| CNN + Trans | 95.3 | 93.06 | 93.96 | 94.39 | 88.76 | ||
| ✓ | 95.71 | 93.48 | 94.37 | 94.83 | 89.49 | ||
| ✓ | 95.42 | 93.15 | 94.05 | 94.52 | 88.93 | ||
| ✓ | ✓ | 95.94 | 94.27 | 94.97 | 95.37 | 90.56 |
| Methods | Position of the Complex CTIM | Precision (%) | Recall (%) | F1 (%) | ACC (%) | mIoU (%) | ||
|---|---|---|---|---|---|---|---|---|
| ① | ② | ③ | ||||||
| UCTNet | 95.46 | 93.4 | 94.23 | 94.75 | 89.28 | |||
| ✓ | 95.66 | 93.64 | 94.46 | 94.93 | 89.67 | |||
| ✓ | 95.94 | 94.27 | 94.97 | 95.37 | 90.56 | |||
| ✓ | ✓ | 95.78 | 93.92 | 94.69 | 95.14 | 90.07 | ||
| ✓ | 95.57 | 92.92 | 93.94 | 94.52 | 88.79 | |||
| ✓ | ✓ | 95.57 | 93.22 | 94.15 | 94.65 | 89.12 | ||
| ✓ | ✓ | 95.54 | 93.79 | 94.52 | 94.94 | 89.75 | ||
| ✓ | ✓ | ✓ | 95.36 | 93.12 | 94.01 | 94.53 | 88.89 | |
| Methods | Precision (%) | Recall (%) | F1 (%) | ACC (%) | mIoU |
|---|---|---|---|---|---|
| absolute PE | 95.84 | 94.21 | 94.9 | 95.32 | 90.44 |
| learnable PE | 95.49 | 93.43 | 94.27 | 94.75 | 89.33 |
| convolutional PE | 95.66 | 93.56 | 94.41 | 94.88 | 89.57 |
| w/o PE | 95.94 | 94.27 | 94.97 | 95.37 | 90.56 |
| Methods | AIFH | Precision (%) | Recall (%) | F1 (%) | ACC (%) | mIoU |
|---|---|---|---|---|---|---|
| UCTNet | 95.89 | 94.08 | 94.83 | 95.25 | 90.31 | |
| ✓ | 95.94 | 94.27 | 94.97 | 95.37 | 90.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, J.; Shen, H.; Cai, Y.; Zhang, T.; Su, J.; Chen, W.-H.; Li, J. UCTNet with Dual-Flow Architecture: Snow Coverage Mapping with Sentinel-2 Satellite Imagery. Remote Sens. 2023, 15, 4213. https://doi.org/10.3390/rs15174213
Ma J, Shen H, Cai Y, Zhang T, Su J, Chen W-H, Li J. UCTNet with Dual-Flow Architecture: Snow Coverage Mapping with Sentinel-2 Satellite Imagery. Remote Sensing. 2023; 15(17):4213. https://doi.org/10.3390/rs15174213
Chicago/Turabian StyleMa, Jinge, Haoran Shen, Yuanxiu Cai, Tianxiang Zhang, Jinya Su, Wen-Hua Chen, and Jiangyun Li. 2023. "UCTNet with Dual-Flow Architecture: Snow Coverage Mapping with Sentinel-2 Satellite Imagery" Remote Sensing 15, no. 17: 4213. https://doi.org/10.3390/rs15174213
APA StyleMa, J., Shen, H., Cai, Y., Zhang, T., Su, J., Chen, W.-H., & Li, J. (2023). UCTNet with Dual-Flow Architecture: Snow Coverage Mapping with Sentinel-2 Satellite Imagery. Remote Sensing, 15(17), 4213. https://doi.org/10.3390/rs15174213