1. Introduction
The acquisition of data pertaining to human mobility and presence is of critical importance within numerous fields of research for producing socioeconomic and development indicators, estimating greenhouse gas emissions, mapping urban extents, and assessing the spread, prevalence, and incidence of various human diseases, among others, driving a demand to refine the processes by which these mobility metrics are measured. With rates of human mobility increasing in their volumes and reach at both global and local scales, methods and datasets for quantifying them, particularly in data-sparse middle- and low-income settings, are becoming an important need. Moreover, with seasonal changes in human mobility that drive disease dynamics (Grenfell et al., 2001; Wesolowski et al., 2012; Wesolowski, Metcalf et al., 2015; Wesolowski, Qureshi et al., 2015) [
1,
2,
3,
4] the demand for resources (Steele et al., 2021) [
5] and impact infrastructure planning needs (Strano et al., 2018) [
6] can be particularly challenging to quantify (Lai et al., 2022; Mao et al., 2015; Song et al., 2021; Woods et al., 2022) [
7,
8,
9,
10]. Since its public distribution in recent decades, satellite-derived night-time light (NTL) imagery has proved itself a reliable proxy of human presence, where large bright areas correspond to higher populations compared to dimly lit areas (Bharti and Tatem, 2018; Bharti et al., 2011; Bustos, 2015) [
11,
12,
13]. Furthermore, NTL imagery has been used as a global indicator of anthropogenic activity and development (Elvidge et al., 2012) [
14] and, due to its historical availability and regular acquisition, enables comparative studies to be made over both short and long time periods (Doll et al., 2000; Ebener et al., 2005) [
15,
16]. As the technology has matured, so has the quality and availability of the NTL data for the scientific and operational communities with the new Visible Infrared Imaging Radiometer Suite (VIIRS) instrument, aboard the joint National Aeronautics and Space Administration (NASA) and National Oceanic and Atmospheric Administration (NOAA) Suomi National Polar-orbiting Partnership (Suomi NPP) and NOAA-20 satellites, offering several refinements compared to the older Defense Meteorological Satellite Program-Operational Linescan System (DMSP-OLS), such as increased spatial resolution of both the Ground Instantaneous Field of View (i.e., 0.55 versus 25 km
2 at Nadir) and the corresponding generated global grids (i.e., 15 versus 30 arc-second grid cell corresponding to ~500 m versus ~1 km at the equator) and temporal resolution (i.e., monthly versus annual) of cloud-free composites, as well as the full filtering of data impacted by stray light (Elvidge et al., 2013) [
17].
Previous research has highlighted the potential of multi-temporal NTL imagery for measuring changes in population presence and density over time as a result of mobility. This has included seasonal labour migration into towns and cities in the Sahel region of Africa (Lai, Farnham et al., 2019) [
18] and its impact on infectious disease dynamics (Bharti et al., 2011) [
12], net migration at NUTS III level in Europe (Chen 2020) [
19], seasonal flows of tourists (Stathakis and Baltas, 2018; Tselios and Stathakis, 2020) [
20,
21], COVID-19 lockdown in global megacities (Xu, et al., 2021) [
22], and induced displacement (Lu et al., 2016) [
23].
In each case, while the evidence is clear on NTL data capturing aspects of population presence and density changes induced by mobility, there are often other factors, such as disaster- or conflict-induced power outages (Montoya-Rincon et al., 2022) [
24], that can be hard to disentangle, and thus, translation into quantitative direct measures of mobility can be challenging. Moreover, the saturation of brightness values in highly urbanised settings can also affect the relationship between changes in brightness, or lack thereof, and mobility. To improve our understanding of the value of NTL data for assessing human mobility and the associated changes in population presence and density, comparisons with alternative datasets are required.
Data on the aggregated movements of mobile phones over time have often been shown to be a reliable and accurate source of quantitative estimates of human movement patterns from subnational to global scales (Lai, Farnham et al., 2019; Lai, zu Erbach-Schoenberg et al., 2019; Ruktanonchai et al., 2018) [
18,
25,
26]. Such data are typically obtained and derived either from Call Detail Records (CDRs), whereby anonymized and aggregated billing records of communications routed through cell towers are measured (Bengtsson et al., 2011; Buckee et al., 2013; Ruktanonchai et al., 2016) [
27,
28,
29], or from aggregations of smartphone-derived GPS location data (Lai, zu Erbach-Schoenberg et al., 2019; Ruktanonchai et al., 2018) [
25,
26]. Each has their own set of biases and uncertainties, which impact the accuracy and reliability of the assessed human mobility patterns (Lai, zu Erbach-Schoenberg et al., 2019) [
25]. The Google Aggregated Mobility Research Dataset (GAMRD) data, providing a measurement of human movements as quantized flow metrics, are principally derived from smartphones and represent the result of anonymous and aggregated phone locations for users who have opted into Google’s Location History feature, which is off by default (Ruktanonchai et al., 2018) [
26]. Previous research has indicated that there is a strong nonlinear relationship between GAMRD and NTL data (Dickinson et al., 2020) [
30]. However, these studies only obtained and analysed mobility data for a short time period (e.g., 6–12 months) in a single country. The degree to which this relationship varies across locations and degrees of urbanisation has not been explored, particularly in low- and middle-income settings and at the monthly timescale. Based on multiple-year (2018–2020) and large-scale mobility data and NTL data at fine spatial resolution across 12 African countries, the current study seeks to address this through (i) examining the NTL-GAMRD relationship across Africa for two time periods (i.e., 2018/19 and 2020) and (ii) determining how the degree of urbanisation affects the correlations.
2. Materials and Methods
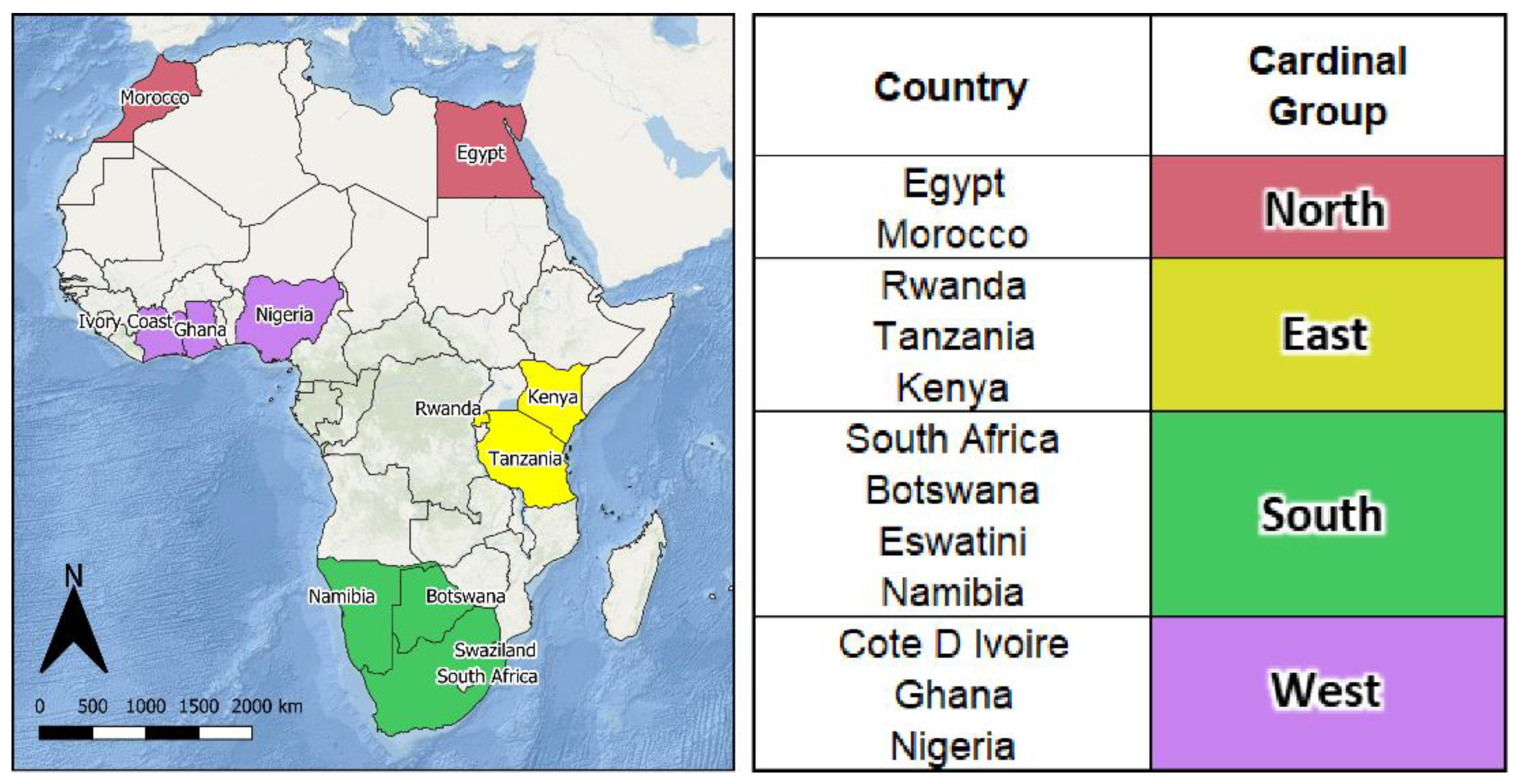
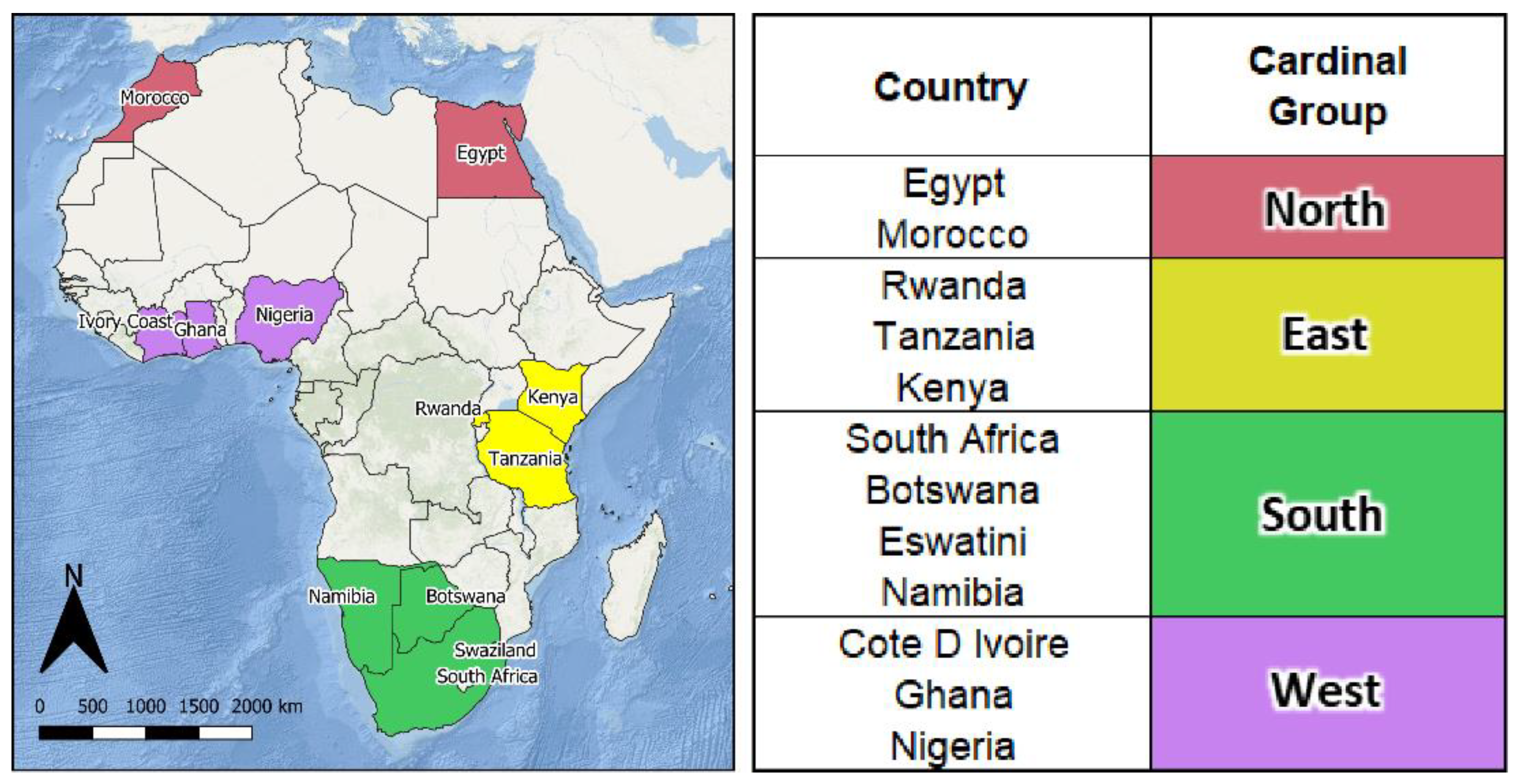
The GAMRD data contain anonymized mobility flows aggregated over users who have turned on their Location History setting that is off by default. The dataset aggregates flows between S2 cells which are here further aggregated by the level 2 administrative unit of origin and destination within and between 12 African countries (
Figure 1).
To produce this dataset, machine learning is applied to log data to automatically segment it into semantic “trips” (Bassolas et al., 2019) [
31]. To provide strong privacy guarantees, all trips are anonymized and aggregated using a differentially private mechanism (Wilson et al., 2020) [
32] to aggregate flows over time (Google, n.d.) [
33]. This research was carried out on the resulting heavily aggregated and differentially private data. No individual user data was ever manually inspected; only heavily aggregated flows of large populations were handled.
All anonymized trips are processed in aggregate to extract their origin and destination location and time. For example, if users travelled from location A to location B within time interval t, the corresponding cell (A, B, t) in the tensor would be n∓err, where err is Laplacian noise. The automated Laplace mechanism adds random noise drawn from a zero-mean Laplace distribution and yields a (𝜖, δ)-differential privacy guarantee of 𝜖 = 0.66 and δ = 2.1 × 10
−29 per metric. Specifically, for each week W and each location pair (A, B), the number of unique users who took a trip from location A to location B during week W is calculated. To each of these metrics, Laplace noise from a zero-mean distribution of scale 1/0.66 is added. All metrics for which the noisy number of users is lower than 100 are removed, following the process described in (Wilson et al., 2020) [
32], and the rest are published. This yields that each published metric satisfies (𝜖, δ)-differential privacy with values defined above. The parameter 𝜖 controls the noise intensity in terms of its variance, while δ represents the deviation from pure 𝜖-privacy. The closer they are to zero, the stronger the privacy guarantees.
The GAMRD dataset used in this study covered the years 2018, 2019, and 2020 and initially contained weekly data representing relative population flows which were subsequently aggregated to a monthly timescale to allow direct comparison with the monthly VIIRS NTL data. The GAMRD data for 2020 were initially supplied in S2 Geometry (S2 Geometry, 2018) [
34] and were then converted to the GCS-WGS84 coordinate system. Based on the origin and destination coordinates of the trips and using shapefiles representing level 2 administrative units, the relative flows were aggregated into 3 unique GAMRD-based flow metrics (i.e., internal flow, inward flow, and outward flow) as described in
Table 1. Therefore, for every level 2 administrative unit of each country of interest, three distinct GAMRD-based flow metrics were available for each month over the study period (i.e., 2018–2020).
Although it would have been preferable to combine GAMRD data from all years (i.e., 2018, 2019, and 2020), this was not possible due to the different spatial aggregation methods used to produce them, and so the study results were necessarily split into two time-periods: 2018/19 and 2020. The 2018/19 data represented flows originally calculated between S2 cells whilst the 2020 data were originally provided based on 1 km cells in WGS84. Although both groups were later reformatted to represent flows between level 2 administrative units in GCS-WGS84, the machine learning-based algorithm used to calculate the raw flows produced two unique datasets that can be justifiably compared to each other and to other data (namely, the VIIRS-NTL data in this study) but cannot be directly combined. Finally, the data referring to December 2019 were removed due to quality issues.
A Python script (Py v3.6) was created to download and extract VIIRS-NTL imagery for each country of interest and thereafter apply postprocessing stages in preparation for zonal statistics. The NTL data were provided by the Colorado School of Mines as monthly composites in geotiff format with the globe divided into 6 tiles (Elvidge et al., 2017) [
35]. Monthly composites were filtered to exclude data impacted by stray light, lightning, lunar illumination, and cloud-cover where the monthly series is run globally using two different configurations. The first excludes any data impacted by stray light. The second includes these data if the radiance values have undergone the stray-light correction procedure. These two configurations, one of which includes the stray-light corrected data, will have more data coverage toward the poles, but will be of reduced quality with the decision of which configuration to use being dependent on the context. For each of the months from 2012–2020, for the monthly non-tiled versions, the annual masks for each year were applied to all the months for that year. For example, the 2020 lit mask was applied on all the months of 2020 (Mills et al., 2013) [
36]. According to Elvidge et al. (2013) [
17], in contrast to the DMSP overpass time which is near 7.30 pm, the SNPP overpass time is near 1.30 am and peak lighting is prior to 10 pm (after which there is some decline in the quantity of outdoor lighting, but we also agree with Eldvige et al. (2013) [
17] that VIIRS data strongly indicate that there is still plenty of lighting being detected after midnight which may or may not only link to public infrastructure lights). After using the annual composites for removing ephemeral lights (unrelated to electric lighting) and background (non-lights) from monthly composites which were already processed for removing persistent gas flares, as well as the impact of sunlit, moonlit, stray lights, lightening, high energy particle, overglow, and cloud-cover, the monthly composites should only include electric lights, which may or may not be related to population presence and thus be affected by human mobility in various ways in different contexts (i.e., urban, peri-urban, vs. rural). At the time of the study design and data analysis (mid-2019), VIIRS annual composite data were not available for all three years of 2018–2020, and only the data that were available up until 2016 had been postprocessed to remove ephemeral lights, such as volcanic activity, fires, and atmospheric noise (Elvidge et al., 2017) [
35]. However, the version 1 series of the monthly composites were not filtered to screen out lights from aurora, fires, boats, and other non-residential lights, thus requiring additional postprocessing (Li et al., 2013; Wang et al., 2017) [
37,
38]. The downloaded files were composed of a primary radiance raster (*rade9.tif) containing floating-point radiance values with units in nanoWatts/cm
2/sr and a corresponding coverage raster (*cvg.tif) of integer values representing the number of observations made on each pixel in each month to be used for quality control.
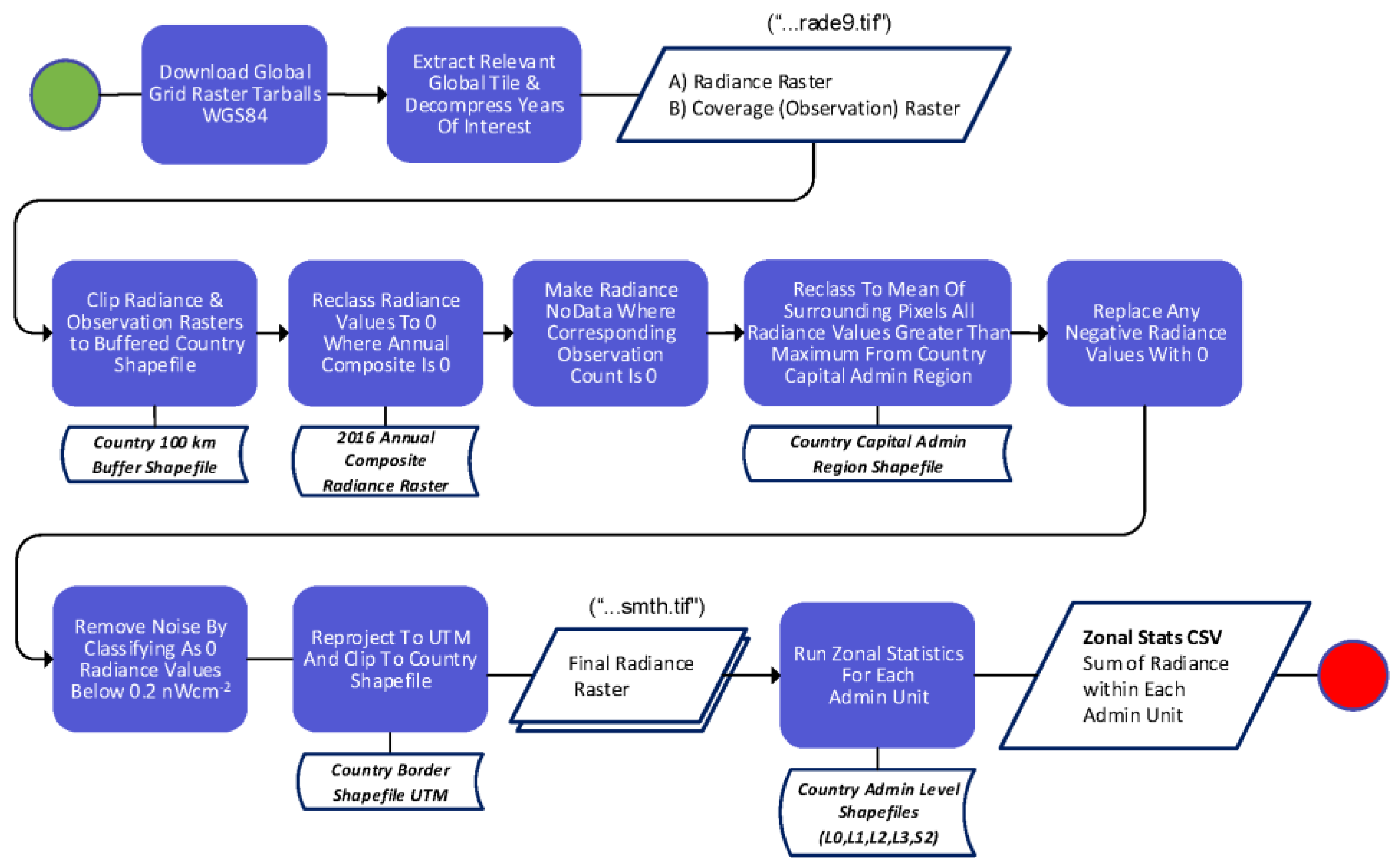
After the NTL rasters were downloaded, the postprocessing steps illustrated in
Figure 2 were implemented following the recommendations set out in previous studies using VIIRS-NTL data (Li et al., 2013; Wang et al., 2017) [
37,
38]: firstly, the respective radiance and coverage rasters were clipped to the extent of each country of interest then buffered to 100 km to allow the preservation of pixels when projecting from WGS84 to UTM. Radiance pixels were then converted to zero if their values were either negative or zero in the 2016 annual composite raster. In cases where the coverage raster indicated that no observations were made in a particular pixel, the corresponding radiance pixel was converted to no data.
To remove any signals created by non-residential lights (such as gas flares), the maximum pixel value in the capital city region of each country for each month was determined. Working under the assumption that no residential lights would be brighter than these radiance values outside of the capital city, any pixels outside of the capital region greater than these values were converted to the mean of the surrounding pixels. The final step was to remove background noise from the data by removing all values lower than 0.2 nWcm
−2 (between 50 degrees north and south) (Elvidge et al., 2017) [
35]. All rasters were then projected to UTM Albers and clipped using country shapefiles. The postprocessed and smoothed radiance rasters were labelled with an appropriate suffix (*smth.tif) ready for zonal statistics. Shapefiles representing level 2 administrative units, as provided by the GADM v3.6 (Warmerdam, 2008) [
39], were used in conjunction with the postprocessed radiance rasters for zonal statistics. The “Sum” metric was used to determine the total radiance (Sum of Lights or SoL) per month within each level 2 administrative unit, with results eventually exported to a CSV file for further analysis.
Whilst the current study would ideally include all African countries, the geographical and temporal range was limited by the availability of the GAMRD data. The criteria by which countries were determined to have sufficient GAMRD data were that the data should have an average spatial coverage per country of more than 85% and that less than 10% of all administrative regions of each country have no data. By following these criteria, twelve countries for 2018, 2019, and 2020 were selected for a correlative analysis between the three GAMRD flow metrics and the corresponding NTL SoL values calculated for each level 2 administrative unit. In addition, a previous global study (Dickinson et al., 2020) [
30] found that in different parts of the world, the relationship between mobility and light production differed considerably, and analyses should account for such regional variations. The twelve selected countries spanned a broad geographic range across the African continent and provided a convenient means for grouping for subsequent analysis according to the United Nations Geoscheme for Africa (UN Statistics Division, 2022) [
40] which separates African countries according to cardinal direction as shown in
Figure 1.
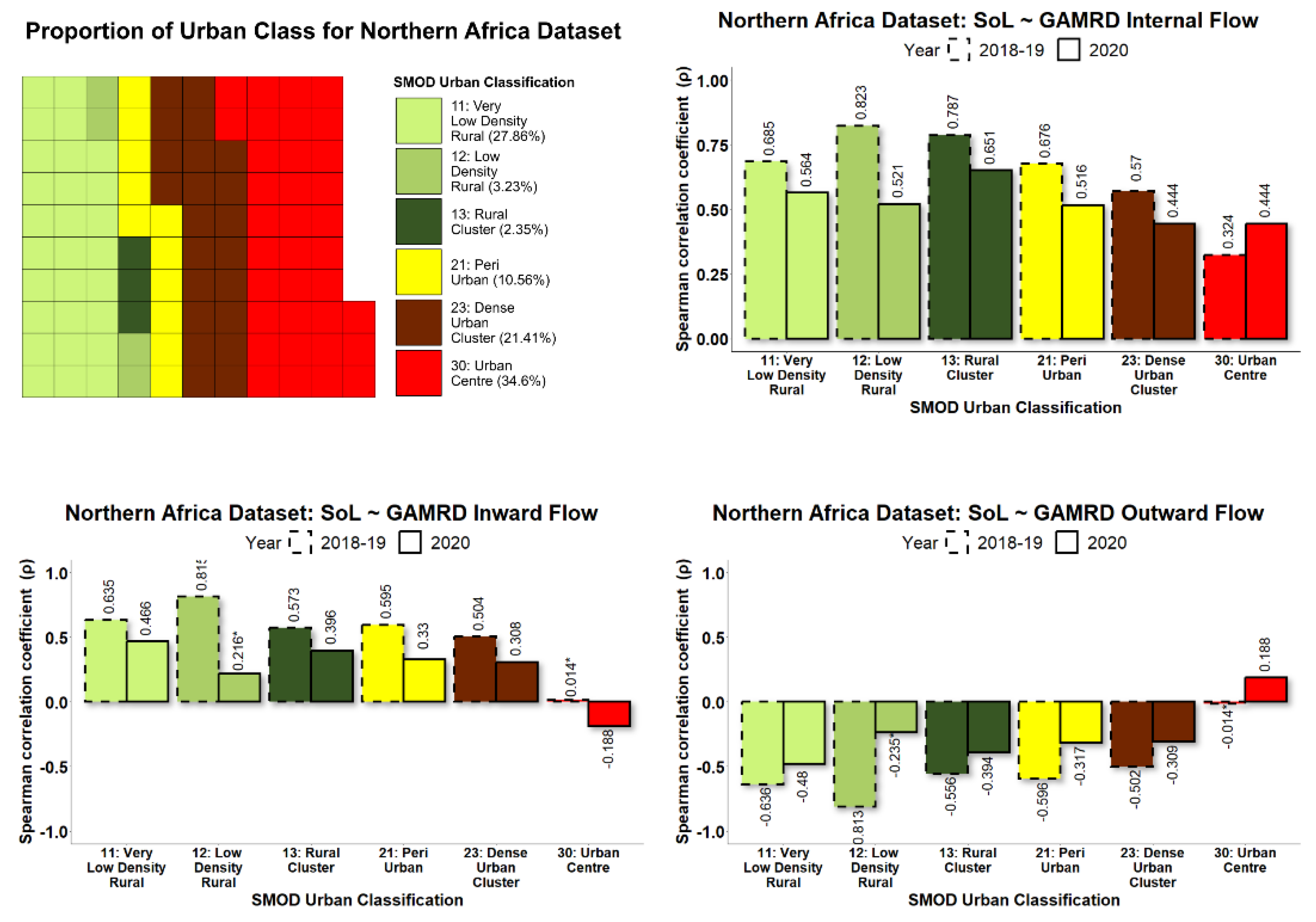
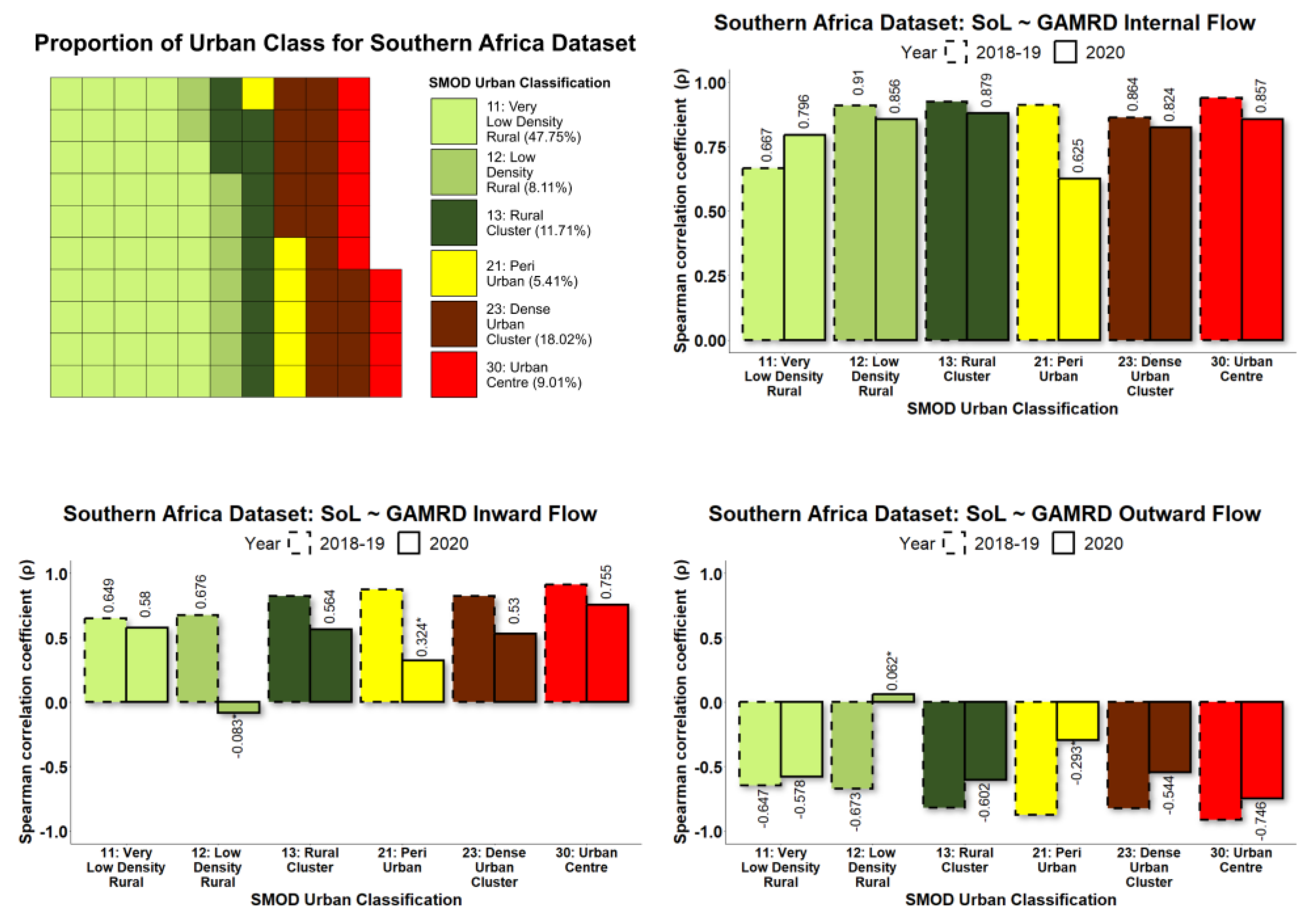
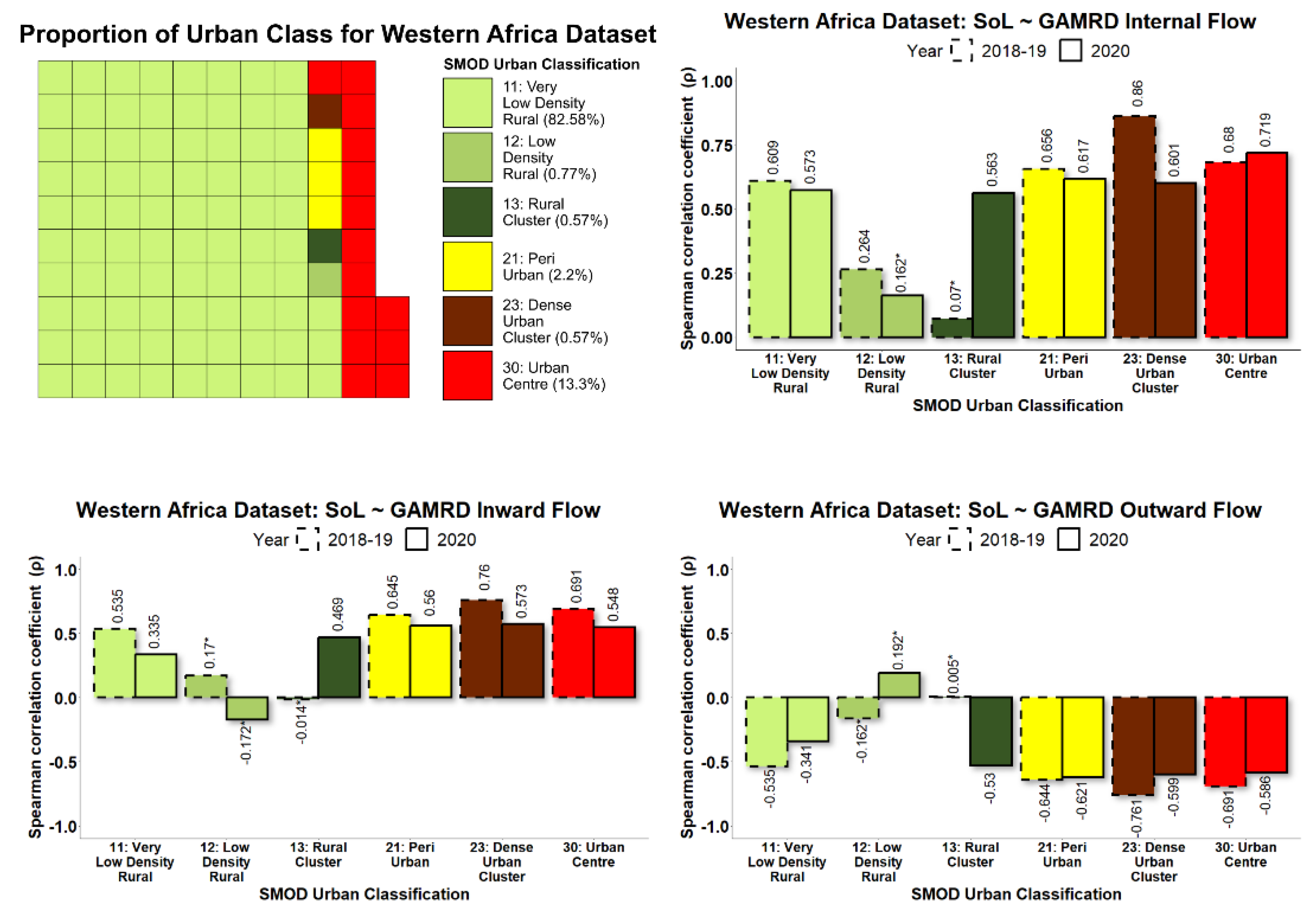
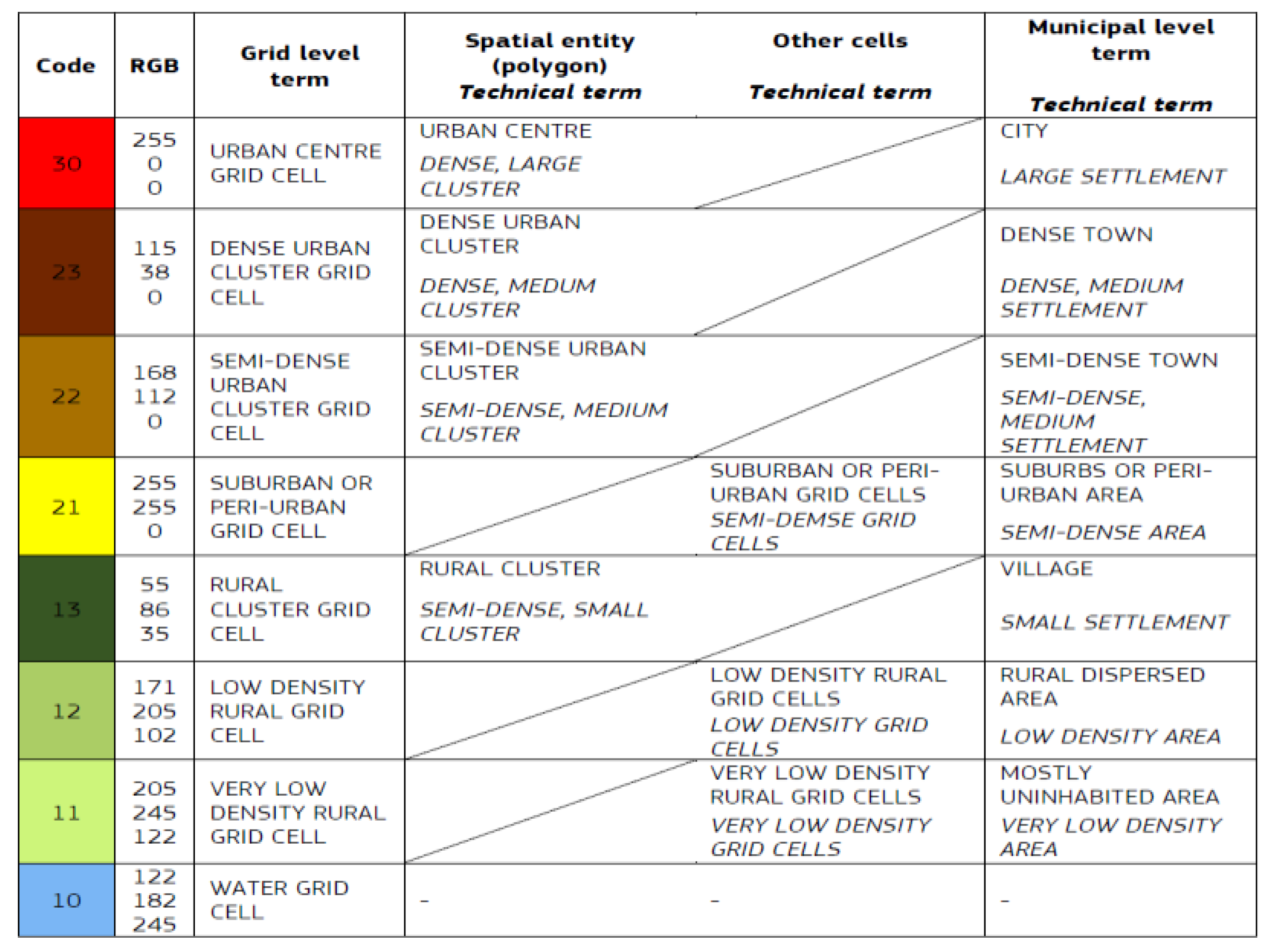
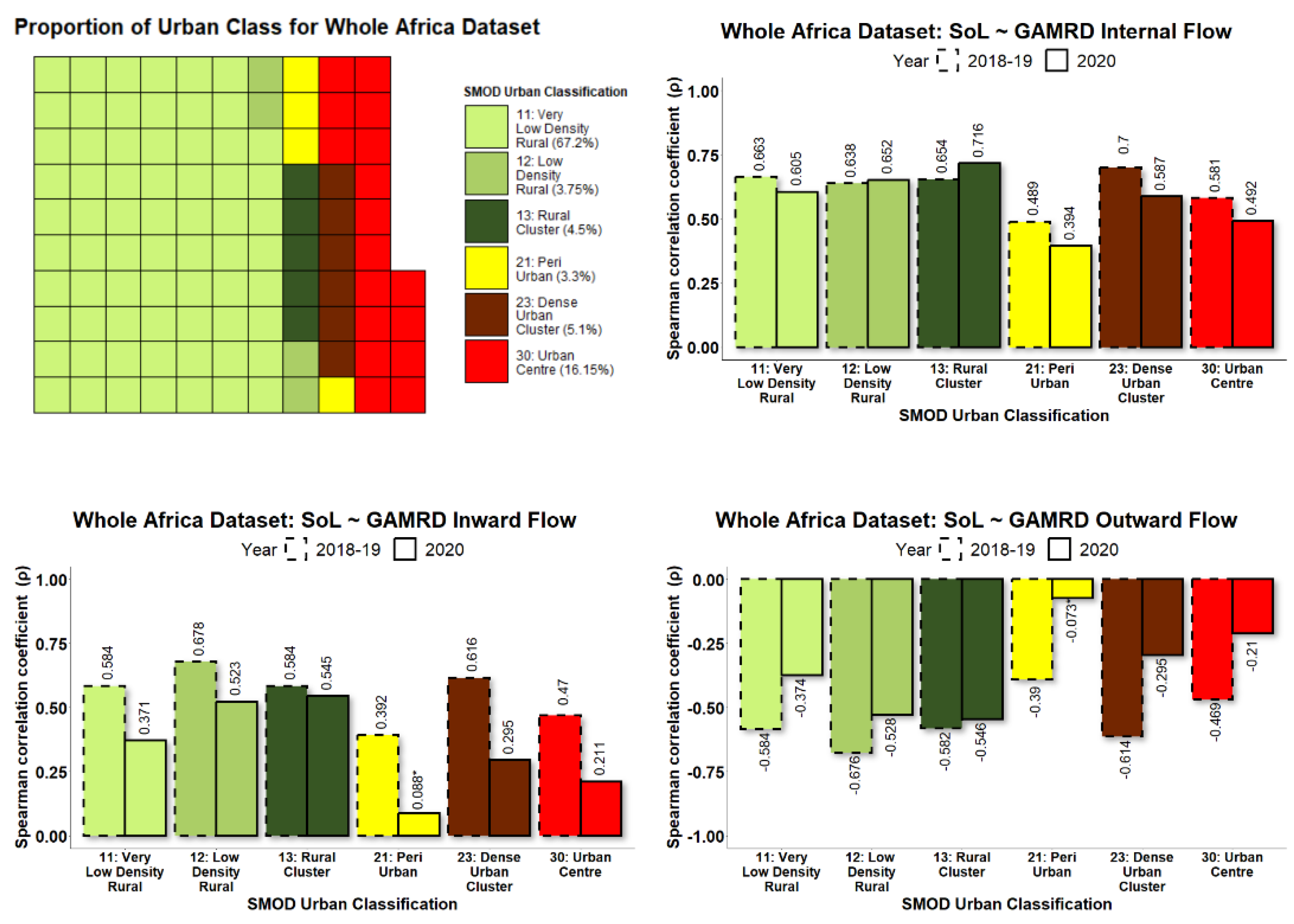
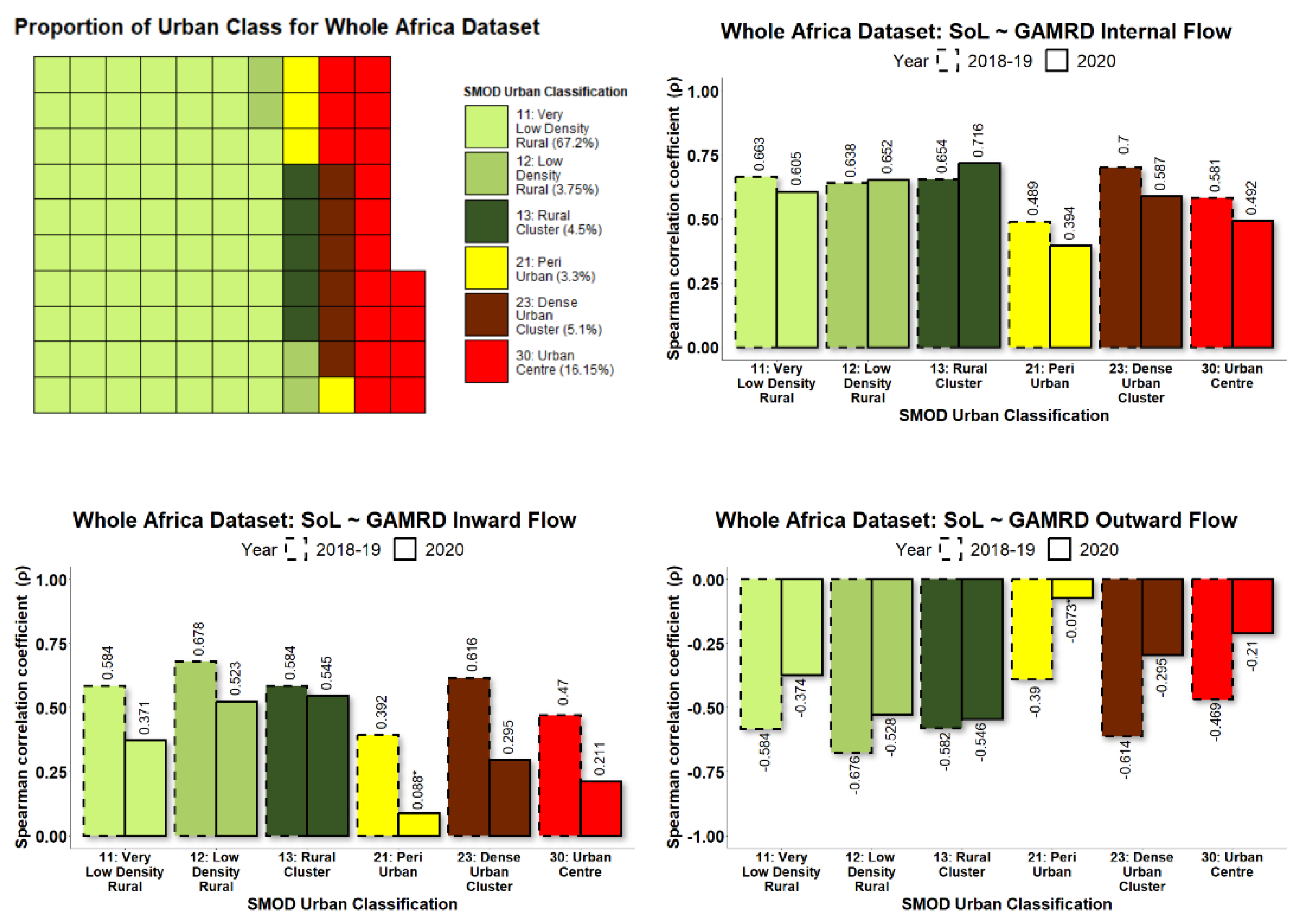
To allow collective analysis over multiple countries, each level 2 administrative unit within each country was categorised according to its degree of urbanisation. By grouping administrative units in this manner, it was possible to demonstrate how NTL and GAMRD correlations vary according to the degree of urbanisation, such as highly populated urban areas vs. sparsely populated rural areas. The GHS Settlement Model (GHS-SMOD) raster provides a classification raster of global coverage that gives for every 1 km
2 raster pixel a value corresponding to one of eight possible rural/urban classifications (Florczyk et al., 2019) [
41] as illustrated in
Figure 3.
As the GHS-SMOD raster provides rural/urban classifications at the 1 km
2 pixel level, an aggregation procedure is required to determine the “overall” degree of urbanisation of each level 2 administrative unit. An R-Script (R v4.0.3) was created for this purpose and took as input: the GHS-SMOD raster as provided by the GHSL-SMOD Project (Florczyk et al., 2019) [
41], the 2020 Population Raster as provided by WorldPop (WorldPop-School of Geography and Environmental Science, University of Southampton; Department of Geography and Geosciences, University of Louisville; Departement de Geographie, Universite de Namur; and the Center for International Earth Science Information, n.d.) [
42] and the level 2 administrative unit shapefiles for the country of interest. The GHS-SMOD raster was extracted into eight separate rasters for each rural/urban classification and converted to binary format (i.e., 0.1). The WorldPop population raster was then multiplied for each of the eight binary rural/urban classification rasters. The resultant product rasters therefore contained the population count in each rural/urban classification, with the corresponding final level 2 administrative unit values obtained through summation via Zonal Statistics. The eight rural/urban classifications were combined into 3 groups: Group 1 (Classes 10, 11, 12, 13), Group 2 (Classes 21, 22, 23), and Group 3 (Class 30). The final classification was then determined via a nested hierarchy and majority approach whereby each unit was assigned to: Group 1 if Group 1 > 50% total country population, Group 2 if Group 1 < 50% and Group 3 < 50% total country population, or Group 3 if Group 3 > 50% total country population. Within the highest group, the individual highest classification value provided the final rural/urban classification for each administrative unit. A simplified illustration of the procedure using Kenya as an example is shown in
Figure 4.
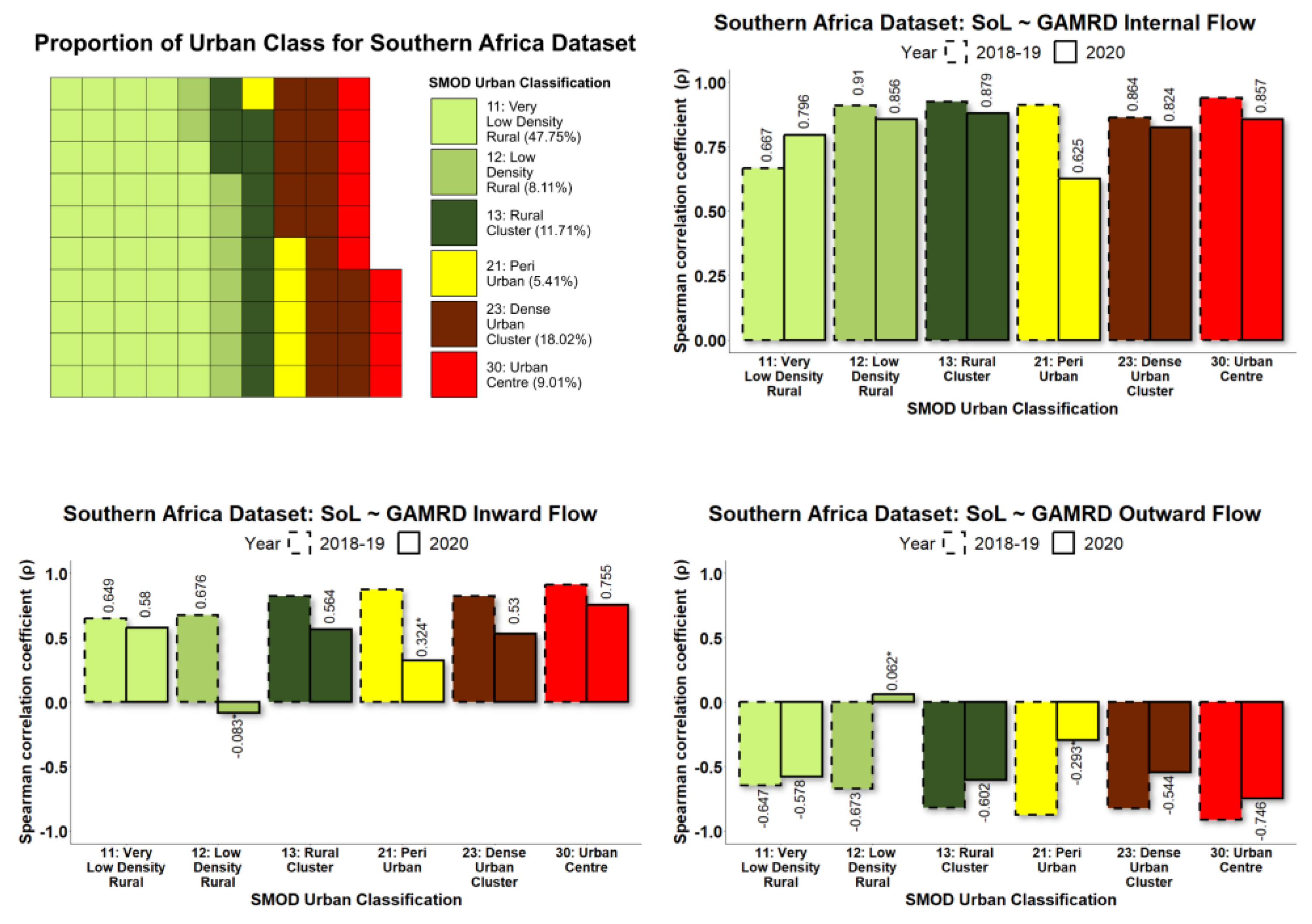
For each administrative unit during the study period 2018–2019 and 2020, NTL data were used to calculate the SoL value per month, while the GAMRD data provided the anonymized and aggregated flows per month. To determine the relationship between GAMRD and NTL data, their monthly values were used as input for a correlation test using the Spearman’s product-moment correlation coefficient (ρ) and its corresponding p-value. By grouping administrative units together according to the rural/urban classification, a high sample size was available for the correlation tests.
Furthermore, we examined the relationship between GAMRD and NTL data in a Gaussian Regression model-based framework to understand the amount of variation in the GAMRD data that could be explained by the NTL data. Both variables were log-transformed to improve the relationship between them and to improve normality. Two models were fitted: (i) a full model that includes NTL and degree of urbanisation as covariates and also accounts for temporal correlation and random variation between countries, and (ii) a reduced model that includes NTL as the only covariate. The reduced model was fitted in a frequentist framework while the full model was fitted in a Bayesian framework using the INLA package in R (Lindgren and Rue, 2015) [
43]. The predictive ability of both models was evaluated using a hold-out cross-validation exercise in which we used 80% of the data for model fitting and 20% for validation. The Pearson’s correlation coefficient and the R-squared statistic were then computed using the observed and predicted values. Both the full and reduced models were fitted for each GAMRD-based flow metric (i.e., internal flow, inward flow, and outward flow) separately.
4. Discussion
NTL has been widely used for population spatial distribution mapping, and a strong correlation between NTL and GAMRD data has been demonstrated in previous studies (Dickinson et al., 2020) [
30]; however, the variation of this relationship according to the degree of urbanisation was previously unexplored. The longitudinal Google Aggregated Mobility Research Dataset (GAMRD) and the VIIR NTL data for Africa in 2018–2020, according to the degree of urbanisation, provide a good opportunity to improve our understanding of the value of NTL data for assessing human mobility and the associated changes in population presence in low- and middle-income countries. The diversity of the study’s countries in different regions does ensure that this study contains wide variance in socioeconomic, geographic, and demographic contexts. Our study, conducted from 2019–2021, has demonstrated the high variability in correlations between administrative-unit-level NTL radiance values and GAMRD flow metrics across a broad geographic range and within different rural/urban classifications. Administrative units classified as rural and semi-rural were shown to have on average the highest NTL-GAMRD correlation whilst administrative units classified as “urban centres” had the lowest (not including the peri-urban class, which had several low
p-values). This is likely due to the saturation and greater stability of lighting and NTL brightness values within urban centres/areas. Indeed, large urban centres/areas in Sub-Saharan Africa and elsewhere tend to be more consistently lit throughout the year and are often bright enough in their core to saturate NTL brightness values (Zhao et al., 2019) [
45]. This means that changes in brightness due to human mobility and the associated population presence and density changes are less likely to occur in urban centres/areas than in small towns/rural and peri-urban areas, where population arrivals may lead to an increase in brightness due to electric lighting or fires in residential areas (Bharti et al., 2011) [
12].
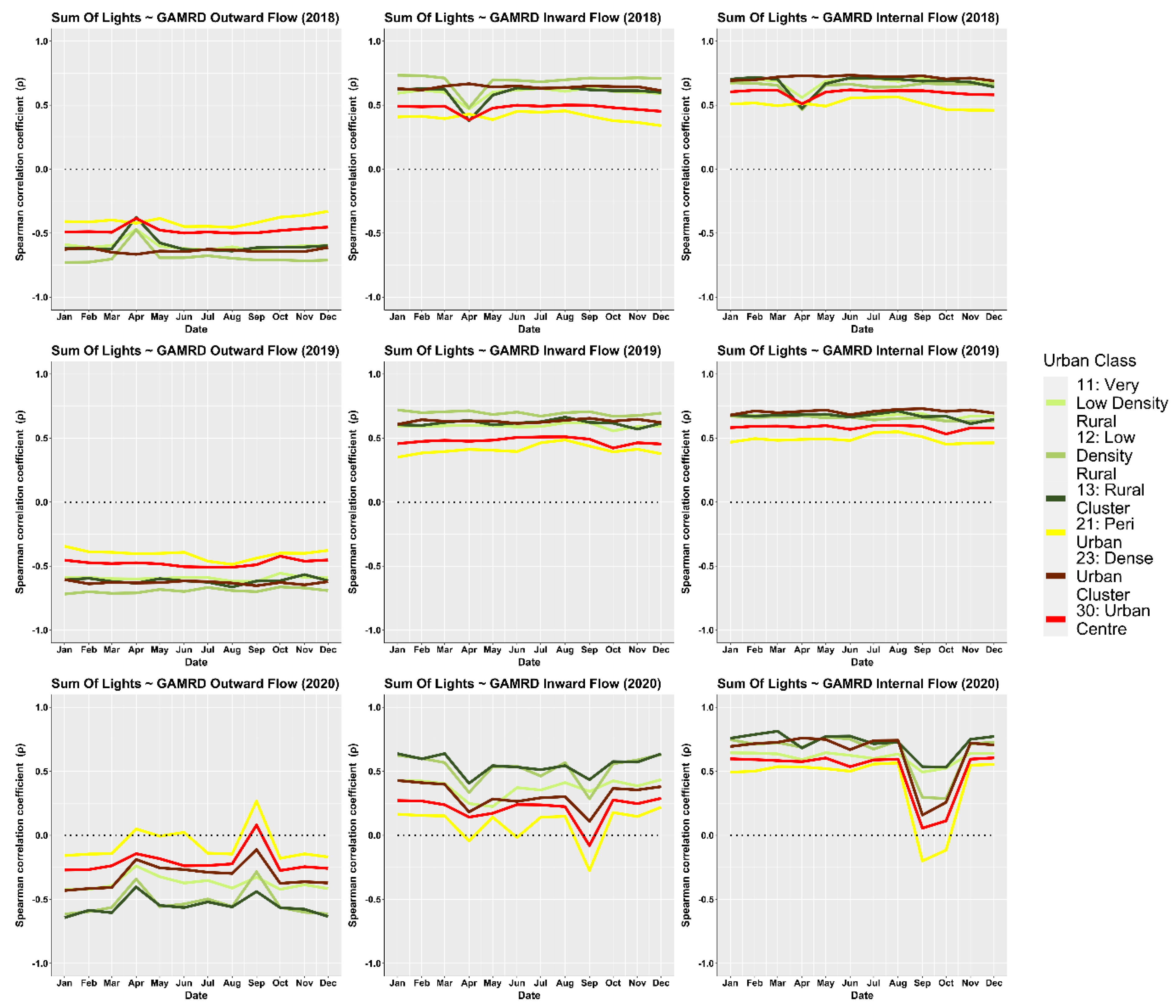
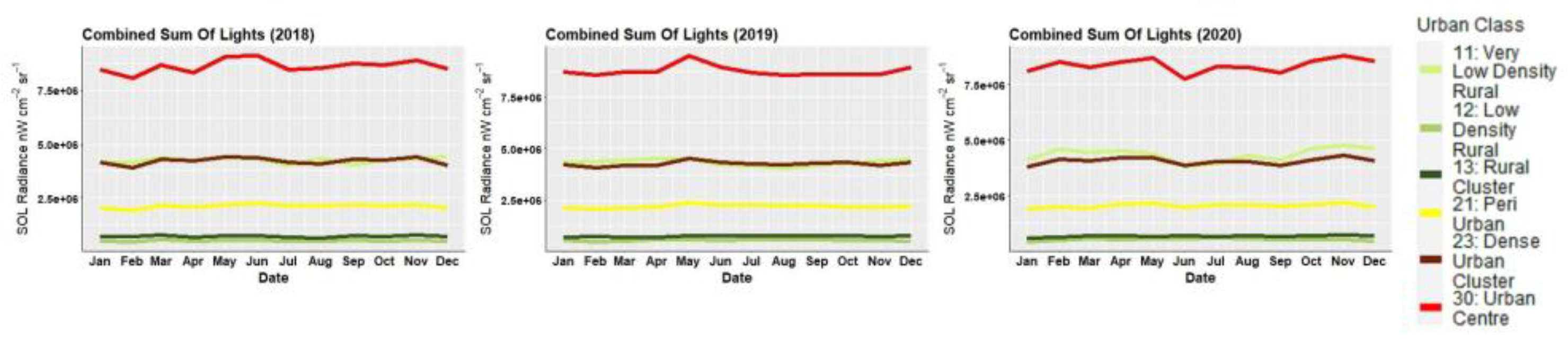
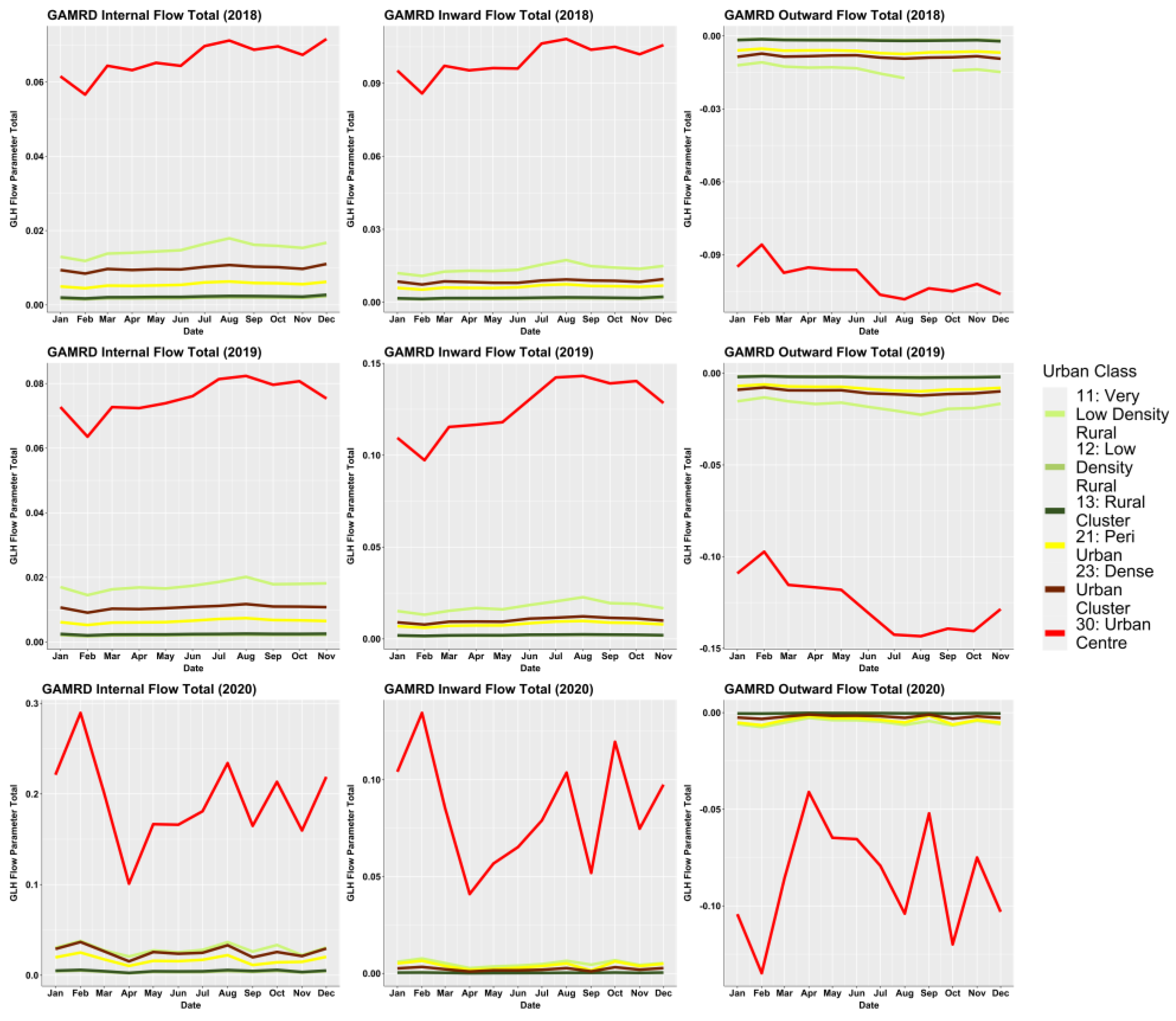
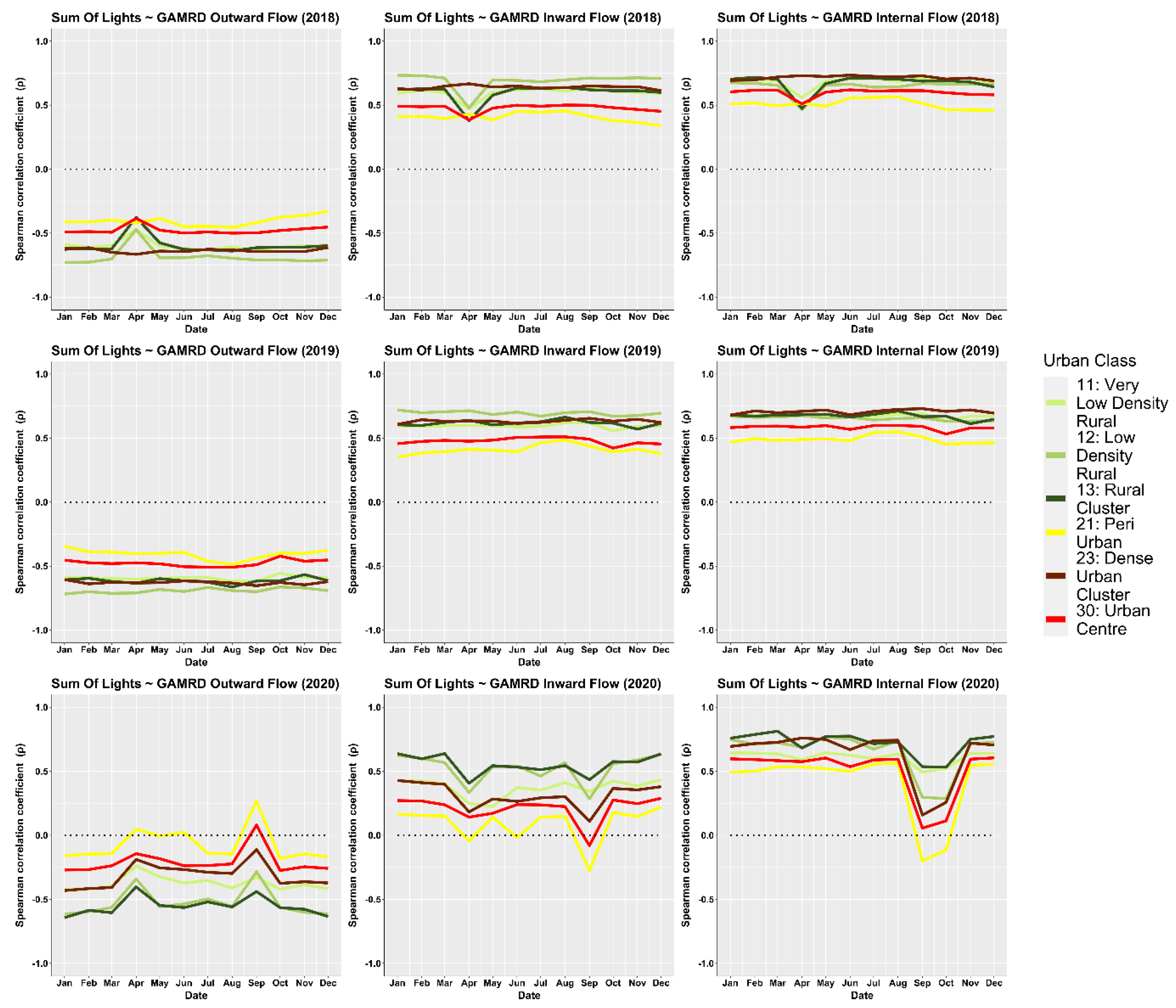
What was most noticeable in the study was the significant difference in correlation strength between the two time periods of 2018–2019 and 2020. Correlations across most rural/urban classifications and particularly “urban centres” were considerably lower in 2020 than in 2018–2019. Whilst the variation of the NTL SoL radiance values across all urban classes remained relatively stable throughout the year, the GHL flow metrics referring to 2020 showed that the corresponding flow values were far more erratic than those in 2018–2019, with the months of April and September being most prominent in their deviation, creating a consequential effect for the NTL-GAMRD correlations during these months. These changes might be attributed to the implementation of lockdown measures during the COVID-19 pandemic, with the first wave in March–April (Haider et al., 2020) [
46] and the second wave in September–October (Kuehn, 2021) [
47]. This has implications for the reliability of NTL data as a proxy for human mobility during periods of unusual human activity, such as lockdown periods. In addition, NTL data have several drawbacks such as delayed access to real-time data, low light detection thresholds, and the requirement for additional postprocessing; however, these are expected to continue to be addressed as the technology further develops and novel data sources become available (Zhao et al., 2019) [
45].
In addition, we only found one similar study conducted by Dickinson et al., 2020 [
30]. Based on linear regression and random forest models, they used Google’s human mobility data in 2016 to predict VIIRS satellite imagery and then assessed how accurately this simulated global NTL imagery could be used to predict GDP across regions in 2015–2016. They demonstrated that the relationship between human mobility and VIIRS NTL was nonlinear and varied considerably around the globe. The differences across regions were made clear by the improvement in the model performance when modelling each region independently rather than constructing a single global model. Our study further measured the degree to which this relationship varied across locations with different levels of urbanisation and development in 2018–2020. However, we found that compared with urban settings, there was a higher association between NTL data and mobility changes in rural and peri-urban areas. In addition, a reduced NTL-GAMRD correlation strength in 2020 was observed, especially in urban settings, most probably because of the monthly NTL SoL radiance values remaining relatively similar in 2018–2019 and 2020 but the human mobility significantly decreasing in 2020 with respect to the previous considered period. Our study provides new insights about changes in mobility and NTL as well as their association across settings during a global crisis such as the pandemic.
Furthermore, it is important to highlight that GAMRD data present several limitations and potential biases as well. Indeed, such data are limited to mobile internet coverage and smartphone users who have opted into Google’s Location History feature, which is off by default, and thus, they may not be representative of the population as a whole. Similarly, their representativeness may vary by location and be particularly low in rural areas characterised by low population densities. Additionally, GAMRD data are still likely to be biased towards educated males living in urban areas (Lai, zu Erbach-Schoenberg et al., 2019) [
25]. Moreover, comparisons across rather than within locations are only descriptive, since these regions can differ in substantial ways. Another primary drawback of GAMRD data is the difficulty of obtaining them due to the restrictive data sharing policies implemented to protect individual privacy and GAMRD data being subject to differential privacy algorithms designed to protect user’s anonymity, which obscure fine details. However, considering potential biases of representativeness among populations across regions, it is important to include subnational and up-to-date statistics on smart-device ownership and internet penetration in future research where possible. Mobile phone subscribers and smartphone adoption are expected to continue growing in low- and middle-income countries, and surveys for measuring mobile phone/smartphone penetration and social media coverage may be necessary to obtain more precise metrics for each country and subnational region (e.g., administrative unit level 1 or 2). In addition, considering the potential biases of representativeness among populations, rather than grouping countries together, it may be of interest to analyse each country separately to avoid generalisations in the future.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}