



Detection Method of Infected Wood on Digital Orthophoto Map–Digital Surface Model Fusion Network

 ,
,  , , , and
, , , and
Abstract
:
1. Introduction
- We construct a large-scale PWD dataset acquired by UAVs equipped with RGB digital cameras, which contains a total of 7379 DOM-DSM image pairs (600 pixels × 600 pixels, 0.05 m resolution) and 23,235 PWD targets. To the best of our knowledge, this is the first publicly accessible dataset for PWD detection tasks.
- We propose a flexible and embedded branching network for DSM feature extraction. Alongside this, we intricately design a novel DOM-DSM multi-modal fusion approach, introducing innovative ideas for both the fusion stage and the fusion method. Building upon these foundations, we propose a novel detection framework named DDNet.
- Extensive experiments demonstrate the effectiveness of our network and achieve SOTA results on our proposed dataset. In addition, we conduct numerous ablation experiments to validate the effectiveness of our design choices in aspects such as the incorporation of DSM data, the DOM-DSM cross-modality attention module and varifocal loss.
2. Materials and Methods
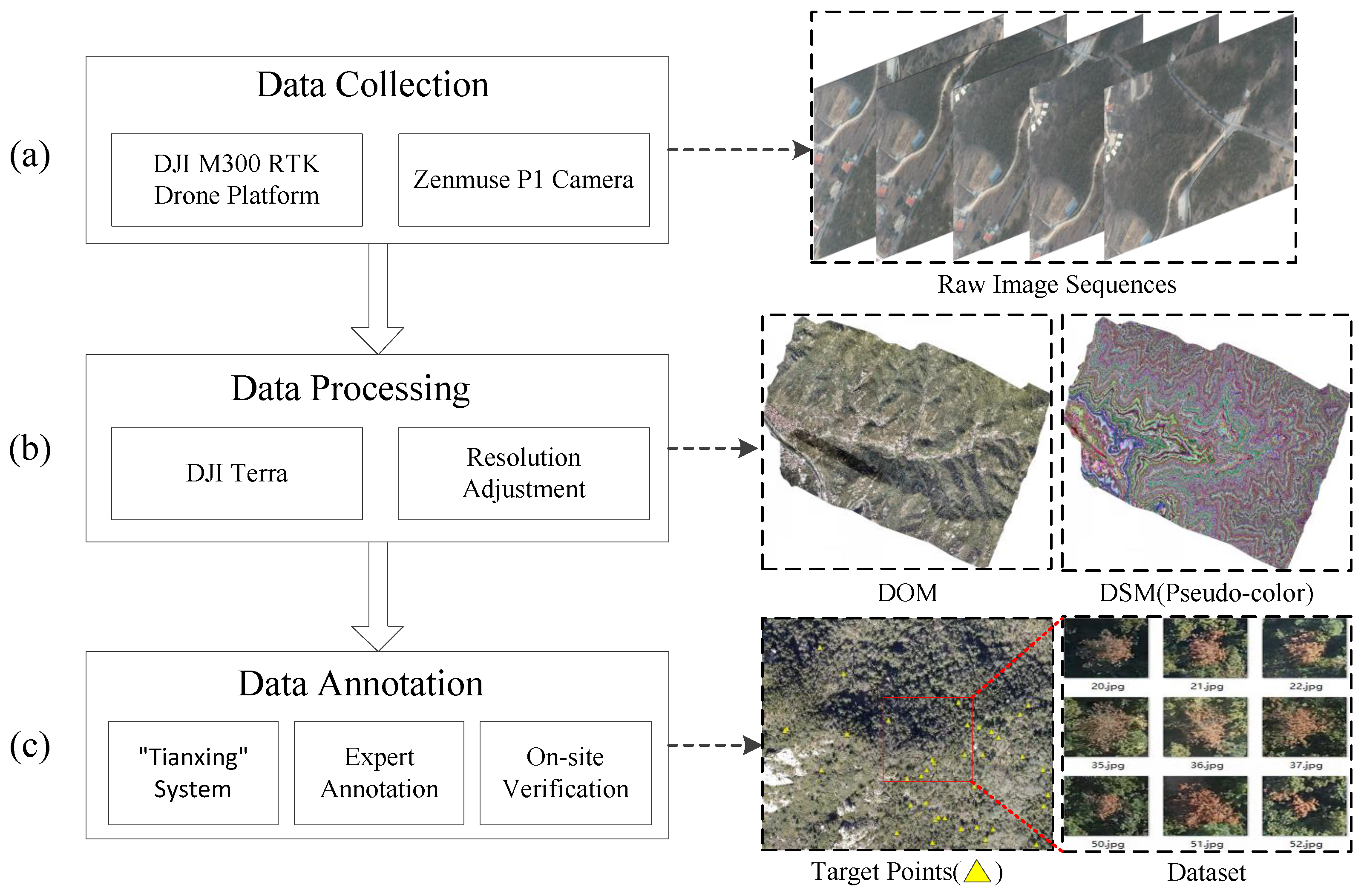
2.1. PWD Dataset
2.1.1. Data Acquisition Area
2.1.2. Dataset Production Process
2.1.3. Introduction of PWD Dataset
2.2. Network Structure
2.2.1. DDNet: DOM-DSM Fusion Network
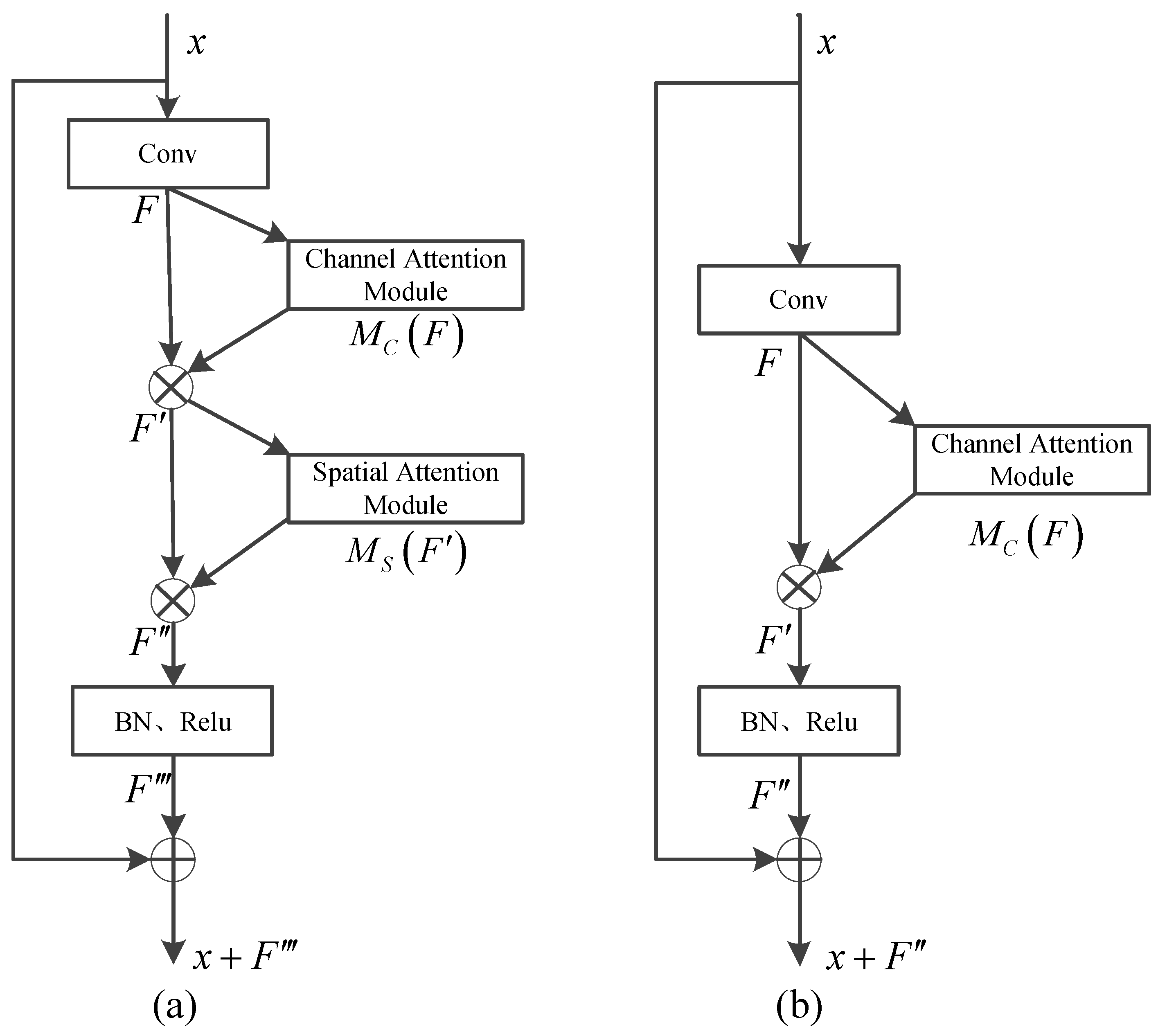
2.2.2. DOM-DSM Cross-Modality Attention Module
2.2.3. Optimize DDNet with Varifocal Loss
2.3. Evaluation Metrics
3. Results
3.1. Implementation Details
3.1.1. Dataset
3.1.2. Experimental Setting
3.2. Experimental Results
3.3. Fusion Stage Experiment
3.4. Visualization Experiment
3.5. Ablation Study
3.6. Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Futai, K. Pine wood nematode, Bursaphelenchus xylophilus. Annu. Rev. Phytopathol. 2013, 51, 61–83. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Li, H.; Ding, X.; Wang, L.; Wang, X.; Chen, F. The detection of pine wilt disease: A literature review. Int. J. Mol. Sci. 2022, 23, 10797. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Zhang, Z.; Zheng, L.; Han, C.; Wang, X.; Xu, J.; Wang, X. Research progress on the early monitoring of pine wilt disease using hyperspectral techniques. Sensors 2020, 20, 3729. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1106–1114. [Google Scholar] [CrossRef]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R.B. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Lee, S.H.; Cho, H.K.; Lee, W.K. Detection of the pine trees damaged by pine wilt disease using high resolution satellite and airborne optical imagery. 대한원격탐사학회지 2007, 23, 409–420. [Google Scholar]
- Yu, R.; Luo, Y.; Zhou, Q.; Zhang, X.; Wu, D.; Ren, L. Early detection of pine wilt disease using deep learning algorithms and UAV-based multispectral imagery. For. Ecol. Manag. 2021, 497, 119493. [Google Scholar] [CrossRef]
- Zhan, Z.; Yu, L.; Li, Z.; Ren, L.; Gao, B.; Wang, L.; Luo, Y. Combining GF-2 and Sentinel-2 images to detect tree mortality caused by red turpentine beetle during the early outbreak stage in North China. Forests 2020, 11, 172. [Google Scholar] [CrossRef]
- Zhang, B.; Ye, H.; Lu, W.; Huang, W.; Wu, B.; Hao, Z.; Sun, H. A Spatiotemporal Change Detection Method for Monitoring Pine Wilt Disease in a Complex Landscape Using High-Resolution Remote Sensing Imagery. Remote Sens. 2021, 13, 2083. [Google Scholar] [CrossRef]
- Li, X.; Tong, T.; Luo, T.; Wang, J.; Rao, Y.; Li, L.; Jin, D.; Wu, D.; Huang, H. Retrieving the Infected Area of Pine Wilt Disease-Disturbed Pine Forests from Medium-Resolution Satellite Images Using the Stochastic Radiative Transfer Theory. Remote Sens. 2022, 14, 1526. [Google Scholar] [CrossRef]
- Qin, J.; Wang, B.; Wu, Y.; Lu, Q.; Zhu, H. Identifying Pine Wood Nematode Disease Using UAV Images and Deep Learning Algorithms. Remote Sens. 2021, 13, 162. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Deng, X.; Zejing, T.; Yubin, L.; Huang, Z. Detection and Location of Dead Trees with Pine Wilt Disease Based on Deep Learning and UAV Remote Sensing. AgriEngineering 2020, 2, 294–307. [Google Scholar] [CrossRef]
- Xu, X.; Tao, H.; Li, C.; Cheng, C.; Guo, H.; Zhou, J. Detection and location of pine wilt disease induced dead pine trees based on Faster R-CNN. Trans. Chin. Soc. Agric. Mach. 2020, 51, 228–236. [Google Scholar]
- You, J.; Zhang, R.; Lee, J. A deep learning-based generalized system for detecting pine wilt disease using RGB-based UAV images. Remote Sens. 2021, 14, 150. [Google Scholar] [CrossRef]
- Pádua, L.; Vanko, J.; Hruška, J.; Adão, T.; Sousa, J.J.; Peres, E.; Morais, R. UAS, sensors, and data processing in agroforestry: A review towards practical applications. Int. J. Remote Sens. 2017, 38, 2349–2391. [Google Scholar] [CrossRef]
- Sun, Z.; Wang, Y.; Pan, L.; Xie, Y.; Zhang, B.; Liang, R.; Sun, Y. Pine wilt disease detection in high-resolution UAV images using object-oriented classification. J. For. Res. 2022, 33, 1377–13893. [Google Scholar] [CrossRef]
- Wu, B.; Liang, A.; Zhang, H.; Zhu, T.; Zou, Z.; Yang, D.; Tang, W.; Li, J.; Su, J. Application of conventional UAV-based high-throughput object detection to the early diagnosis of pine wilt disease by deep learning. For. Ecol. Manag. 2021, 486, 118986. [Google Scholar] [CrossRef]
- Li, F.; Liu, Z.; Shen, W.; Wang, Y.; Wang, Y.; Ge, C.; Sun, F.; Lan, P. A remote sensing and airborne edge-computing based detection system for pine wilt disease. IEEE Access 2021, 9, 66346–66360. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More Diverse Means Better: Multimodal Deep Learning Meets Remote Sensing Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4340–4354. [Google Scholar] [CrossRef]
- Huang, Y.; Du, C.; Xue, Z.; Chen, X.; Zhao, H.; Huang, L. What Makes Multimodal Learning Better than Single (Provably). Adv. Neural Inf. Process. Syst. 2021, 34, 10944–10956. [Google Scholar]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph Convolutional Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5966–5978. [Google Scholar] [CrossRef]
- Zhang, P.; Du, P.; Lin, C.; Wang, X.; Li, E.; Xue, Z.; Bai, X. A Hybrid Attention-Aware Fusion Network (HAFNet) for Building Extraction from High-Resolution Imagery and LiDAR Data. Remote Sens. 2020, 12, 3764. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Lecture Notes in Computer Science, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Liu, T.; Gong, M.; Lu, D.; Zhang, Q.; Zheng, H.; Jiang, F.; Zhang, M. Building Change Detection for VHR Remote Sensing Images via Local-Global Pyramid Network and Cross-Task Transfer Learning Strategy. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4704817. [Google Scholar] [CrossRef]
- Lewis, Q.W.; Edmonds, D.A.; Yanites, B.J. Integrated UAS and LiDAR reveals the importance of land cover and flood magnitude on the formation of incipient chute holes and chute cutoff development. Earth Surf. Process. Landf. 2020, 45, 1441–1455. [Google Scholar] [CrossRef]
- Olmanson, L.G.; Bauer, M.E. Land cover classification of the Lake of the Woods/Rainy River Basin by object-based image analysis of Landsat and lidar data. Lake Reserv. Manag. 2017, 33, 335–346. [Google Scholar] [CrossRef]
- Zhao, Q.; Ma, Y.; Lyu, S.; Chen, L. Embedded Self-Distillation in Compact Multibranch Ensemble Network for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Zhao, Q.; Lyu, S.; Li, Y.; Ma, Y.; Chen, L. MGML: Multigranularity Multilevel Feature Ensemble Network for Remote Sensing Scene Classification. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 2308–2322. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, X. Object-Based Tree Species Classification Using Airborne Hyperspectral Images and LiDAR Data. Forests 2019, 11, 32. [Google Scholar] [CrossRef]
- Lucena, F.; Breunig, F.M.; Kux, H. The Combined Use of UAV-Based RGB and DEM Images for the Detection and Delineation of Orange Tree Crowns with Mask R-CNN: An Approach of Labeling and Unified Framework. Future Internet 2022, 14, 275. [Google Scholar] [CrossRef]
- Hao, Z.; Lin, L.; Post, C.J.; Mikhailova, E.A.; Li, M.; Chen, Y.; Yu, K.; Liu, J. Automated tree-crown and height detection in a young forest plantation using mask region-based convolutional neural network (Mask R-CNN). ISPRS J. Photogramm. Remote Sens. 2021, 178, 112–123. [Google Scholar] [CrossRef]
- Cheng, G.; Huang, Y.; Li, Y.; Lyu, S.; Xu, Z.; Zhao, Q.; Xiang, S. Change Detection Methods for Remote Sensing in the Last Decade: A Comprehensive Review. arXiv 2023, arXiv:2305.05813. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Lv, Z.; Huan, H.; Jia, M.; Benediktsson, J.; Chen, F. Iterative Training Sample Augmentation for Enhancing Land Cover Change Detection Performance With Deep Learning Neural Network. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–14. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. VarifocalNet: An IoU-Aware Dense Object Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference Computer Vision, Zurich, Switzerland, 6–12 September 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Hong, D.; Yokoya, N.; Chanussot, J.; Zhu, X.X. An augmented linear mixing model to address spectral variability for hyperspectral unmixing. IEEE Trans. Image Process. 2018, 28, 1923–1938. [Google Scholar] [CrossRef]
- Zhao, Q.; Liu, B.; Lyu, S.; Wang, C.; Zhang, H. TPH-YOLOv5++: Boosting Object Detection on Drone-Captured Scenarios with Cross-Layer Asymmetric Transformer. Remote Sens. 2023, 15, 1687. [Google Scholar] [CrossRef]
- Wang, Q.; Feng, W.; Yao, L.; Zhuang, C.; Liu, B.; Chen, L. TPH-YOLOv5-Air: Airport Confusing Object Detection via Adaptively Spatial Feature Fusion. Remote Sens. 2023, 15, 3883. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | AP50 | AP75 | AP | FPS |
|---|---|---|---|---|
| Faster RCNN | 0.872 | 0.734 | 0.624 | 6.582 |
| RetinaNet | 0.891 | 0.735 | 0.613 | 12.336 |
| YOLOv5 | 0.884 | 0.703 | 0.628 | 14.354 |
| Faster RCNN-DSM | 0.889 | 0.741 | 0.629 | 4.359 |
| RetinaNet-DSM | 0.907 | 0.736 | 0.628 | 10.455 |
| YOLOv5-DSM | 0.893 | 0.715 | 0.631 | 12.119 |
| DDNet | 0.915 | 0.751 | 0.632 | 8.759 |
| Fusion Stage | AP50 | AP75 | AP | FPS |
|---|---|---|---|---|
| Early fusion (data level) | 0.893 | 0.736 | 0.618 | 11.054 |
| Middle fusion (feature level) | 0.915 | 0.751 | 0.632 | 8.759 |
| Late fusion (decision level) | 0.896 | 0.737 | 0.626 | 6.254 |
| Structure A | Structure B | Focal Loss | Varifocal Loss | AP50 | AP75 | AP |
|---|---|---|---|---|---|---|
| ✓ | ✘ | ✓ | ✘ | 0.912 | 0.746 | 0.628 |
| ✘ | ✓ | ✓ | ✘ | 0.909 | 0.741 | 0.626 |
| ✓ | ✘ | ✘ | ✓ | 0.915 | 0.751 | 0.632 |
| ✘ | ✓ | ✘ | ✓ | 0.911 | 0.748 | 0.629 |
| RandomFlip | Pad | Mosaic | AP50 | AP75 | AP |
|---|---|---|---|---|---|
| ✘ | ✘ | ✘ | 0.901 | 0.727 | 0.613 |
| ✓ | ✘ | ✘ | 0.908 | 0.731 | 0.621 |
| ✘ | ✓ | ✘ | 0.907 | 0.728 | 0.619 |
| ✘ | ✘ | ✓ | 0.910 | 0.732 | 0.622 |
| ✓ | ✓ | ✘ | 0.913 | 0.745 | 0.627 |
| ✓ | ✘ | ✓ | 0.912 | 0.741 | 0.625 |
| ✘ | ✓ | ✓ | 0.913 | 0.747 | 0.629 |
| ✓ | ✓ | ✓ | 0.915 | 0.751 | 0.632 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Zhao, H.; Chang, Q.; Lyu, S.; Liu, B.; Wang, C.; Feng, W. Detection Method of Infected Wood on Digital Orthophoto Map–Digital Surface Model Fusion Network. Remote Sens. 2023, 15, 4295. https://doi.org/10.3390/rs15174295
Wang G, Zhao H, Chang Q, Lyu S, Liu B, Wang C, Feng W. Detection Method of Infected Wood on Digital Orthophoto Map–Digital Surface Model Fusion Network. Remote Sensing. 2023; 15(17):4295. https://doi.org/10.3390/rs15174295
Chicago/Turabian StyleWang, Guangbiao, Hongbo Zhao, Qing Chang, Shuchang Lyu, Binghao Liu, Chunlei Wang, and Wenquan Feng. 2023. "Detection Method of Infected Wood on Digital Orthophoto Map–Digital Surface Model Fusion Network" Remote Sensing 15, no. 17: 4295. https://doi.org/10.3390/rs15174295
APA StyleWang, G., Zhao, H., Chang, Q., Lyu, S., Liu, B., Wang, C., & Feng, W. (2023). Detection Method of Infected Wood on Digital Orthophoto Map–Digital Surface Model Fusion Network. Remote Sensing, 15(17), 4295. https://doi.org/10.3390/rs15174295