

Generalizing Spacecraft Recognition via Diversifying Few-Shot Datasets in a Joint Trained Likelihood

Abstract
:1. Introduction
- (1)
- We investigate a generative re-sampling scheme for representation learning. The sampled representation is used to condition an amortized strategy and universal backbone in adapting the embedding extractor function to multiple datasets;
- (2)
- From a self-supervised perspective, we propose a data encoding function based on neural process variational inference;
- (3)
- We present a comparable out-of-distribution performance against methods with a specific design on BUAA dataset and with universal representation on the Meta-dataset.
2. Background
2.1. Meta-Learning Approaches in a Few-Shot Setting
2.2. Neural Processes Family
2.2.1. The Conditional Neural Process Family
2.2.2. Latent Neural Process Family
2.3. The Generative Family in Learning Representation
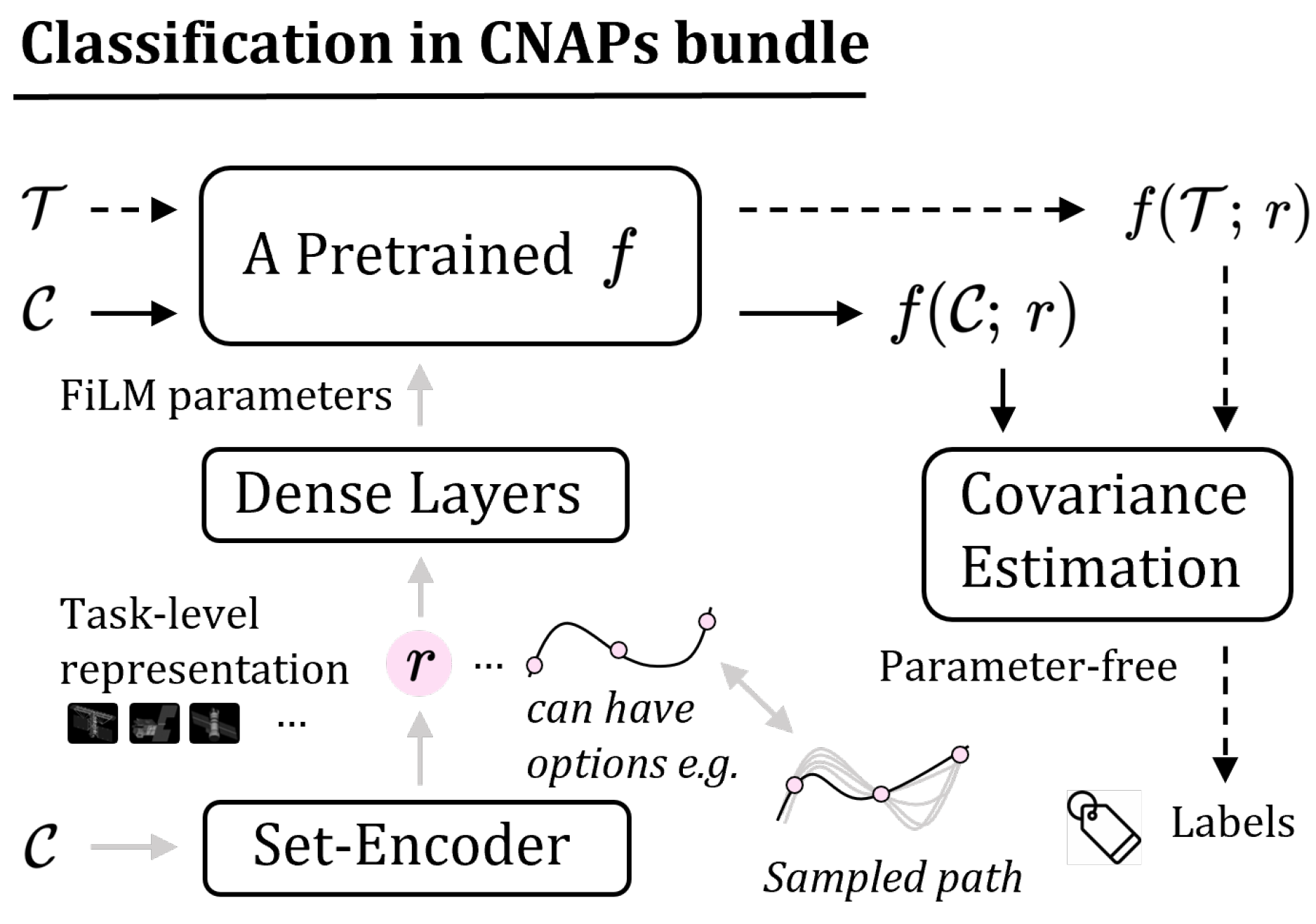
3. Methods
3.1. Reformulated Representation Learning
3.1.1. Formulation (1), Directly Resampling Task-Representation from Generative Density
3.1.2. Formulation (2), a Resample Embedding Function from Grid Density
3.2. Building Estimated Classifier
3.3. Training Objects
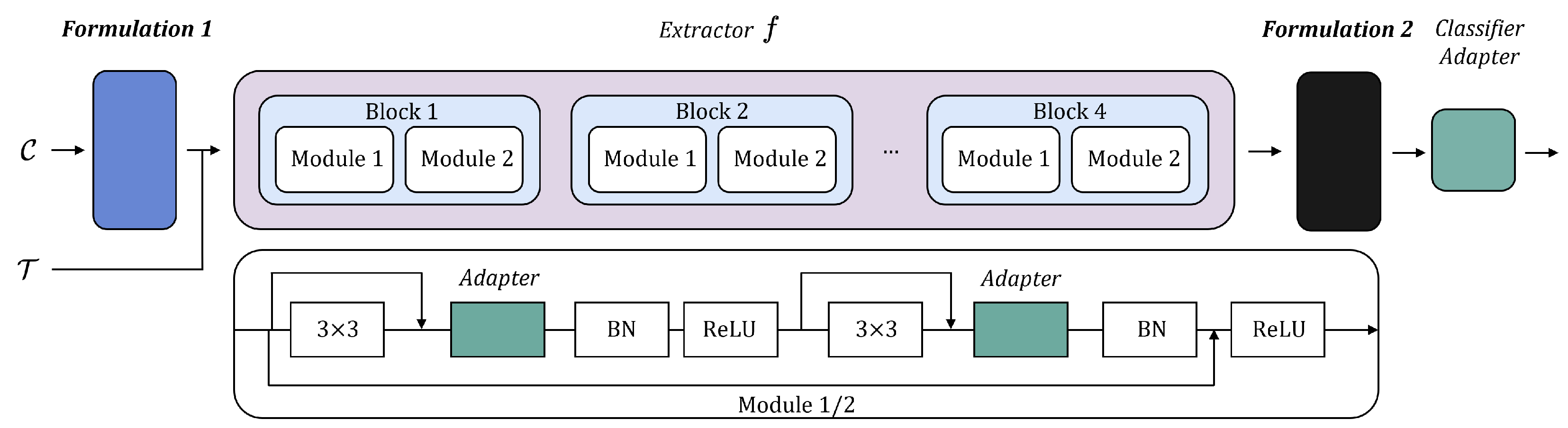
3.4. Architecture with Formulation
| Algorithm 1: Example Maximum Likelihood Training for Simple CNAPs |
 |
4. Experiments
4.1. Dataset Format
4.2. Implementation Details
4.2.1. Dataset Setting
4.2.2. Training
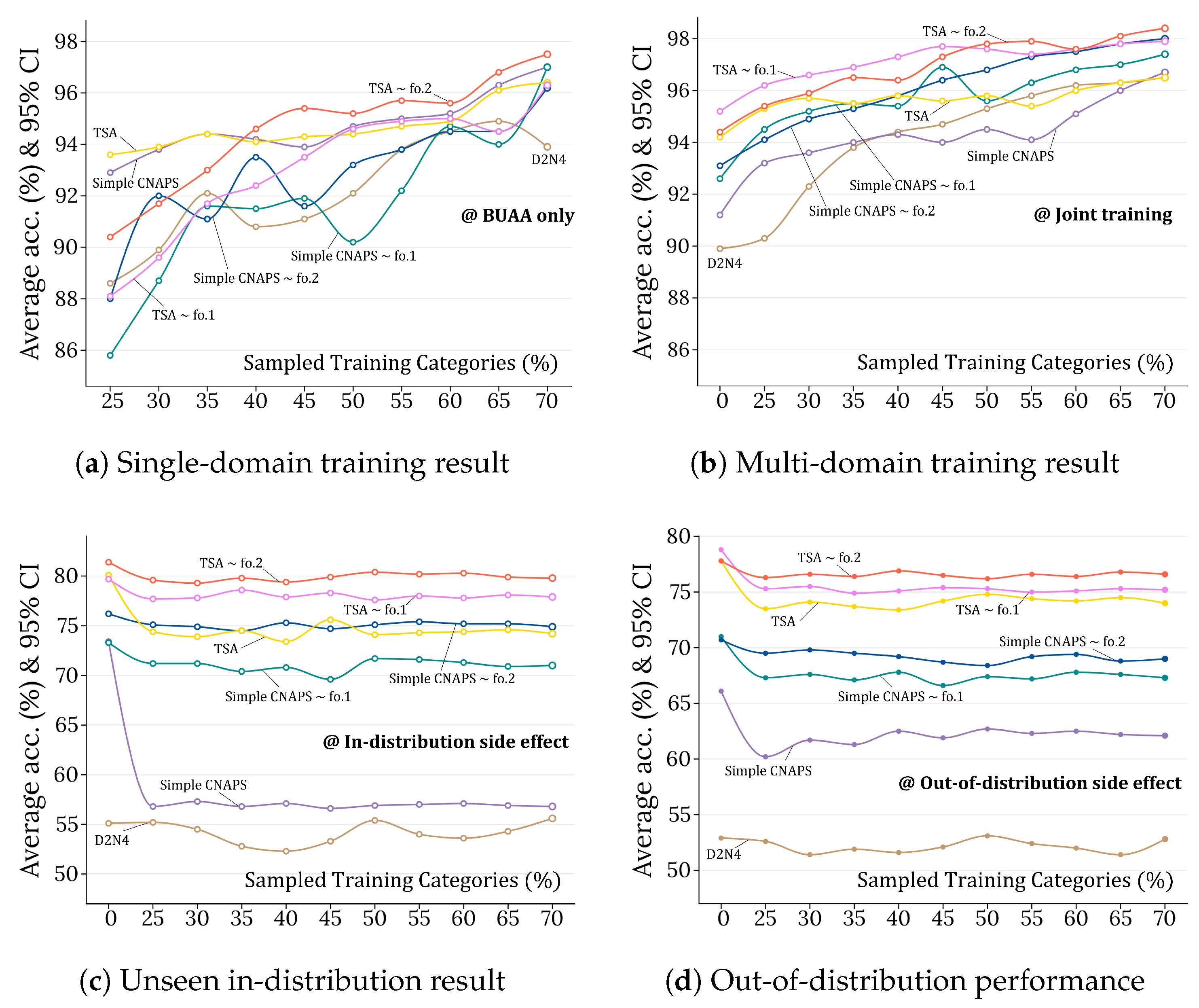
4.3. Results and Extendable Discussion
4.3.1. Benchmarking Spacecraft Dataset
4.3.2. Benchmarking Meta-Dataset
4.4. Ablation Study
5. Conclusions and Limitations
Author Contributions
Funding
Conflicts of Interest
References
- Zhao, Z.; Xu, G.; Zhang, N.; Zhang, Q. Performance analysis of the hybrid satellite-terrestrial relay network with opportunistic scheduling over generalized fading channels. IEEE Trans. Veh. Technol. 2022, 71, 2914–2924. [Google Scholar] [CrossRef]
- Heidari, A.; Jafari Navimipour, N.; Unal, M.; Zhang, G. Machine learning applications in internet-of-drones: Systematic review, recent deployments, and open issues. ACM Comput. Surv. 2023, 55, 1–45. [Google Scholar] [CrossRef]
- Zeng, H.; Xia, Y. Space target recognition based on deep learning. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017. [Google Scholar]
- Yang, X.; Nan, X.; Song, B. D2N4: A Discriminative Deep Nearest Neighbor Neural Network for Few-shot Space Target Recognition. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3667–3676. [Google Scholar] [CrossRef]
- Peng, R.; Zhao, W.; Li, K.; Ji, F.; Rong, C. Continual Contrastive Learning for Cross-Dataset Scene Classification. Remote Sens. 2022, 14, 5105. [Google Scholar] [CrossRef]
- Gordon, J.; Bronskill, J.; Bauer, M.; Nowozin, S.; Turner, R. Meta-Learning Probabilistic Inference for Prediction. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Chen, W.Y.; Liu, Y.C.; Kira, Z.; Wang, Y.C.F.; Huang, J.B. A Closer Look at Few-shot Classification. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Rostami, M.; Kolouri, S.; Eaton, E.; Kim, K. Deep transfer learning for few-shot SAR image classification. Remote Sens. 2019, 11, 1374. [Google Scholar] [CrossRef]
- Bai, X.; Huang, M.; Xu, M.; Liu, J. Reconfiguration Optimization of Relative Motion between Elliptical Orbits Using Lyapunov-Floquet Transformation. IEEE Trans. Aerosp. Electron. Syst. 2022, 59, 923–936. [Google Scholar] [CrossRef]
- Yang, S.; Liu, L.; Xu, M. Free Lunch for Few-shot Learning: Distribution Calibration. In Proceedings of the International Conference on Learning Representations, Online, 26–30 April 2020. [Google Scholar]
- Huang, W.; Yuan, Z.; Yang, A.; Tang, C.; Luo, X. TAE-net: Task-adaptive embedding network for few-shot remote sensing scene classification. Remote Sens. 2022, 14, 111. [Google Scholar] [CrossRef]
- Dvornik, N.; Schmid, C.; Mairal, J. Selecting Relevant Features from A Universal representation for few-shot classification. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 29 September–4 October 2020. [Google Scholar]
- Liu, L.; Hamilton, W.; Long, G.; Jiang, J.; Larochelle, H. A Universal Representation Transformer Layer for Few-Shot Image Classification. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4–8 May 2021. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 11–158 August 2017. [Google Scholar]
- Triantafillou, E.; Larochelle, H.; Zemel, R.; Dumoulin, V. Learning a Universal Template for Few-shot Dataset Generalization. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021. [Google Scholar]
- Zhang, H.; Liu, Z.; Jiang, Z.; An, M.; Zhao, D. BUAA-SID1.0 Space object Image Dataset. Spacecr. Recovery Remote Sens. 2010, 31, 65–71. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from A Few Examples: A Survey on Few-shot Learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, UK, 2006. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as A Model for Few-shot Learning. In Proceedings of the International Conference on Learning Representations, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Triantafillou, E.; Zhu, T.; Dumoulin, V.; Lamblin, P.; Evci, U.; Xu, K.; Goroshin, R.; Gelada, C.; Swersky, K.; Manzagol, P.A.; et al. Meta-dataset: A Dataset of Datasets for Learning to Learn from Few Examples. In Proceedings of the International Conference on Learning Representations, Online, 26–30 April 2020. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Garnelo, M.; Schwarz, J.; Rosenbaum, D.; Viola, F.; Rezende, D.J.; Eslami, S.; Teh, Y.W. Neural Processes. arXiv 2018, arXiv:1807.01622. [Google Scholar]
- Requeima, J.; Gordon, J.; Bronskill, J.; Nowozin, S.; Turner, R.E. Fast and Flexible Multi-task Classification Using Conditional Neural Adaptive Processes. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, QC, Canada, 8–14 December 2019. [Google Scholar]
- Garnelo, M.; Rosenbaum, D.; Maddison, C.; Ramalho, T.; Saxton, D.; Shanahan, M.; Teh, Y.W.; Rezende, D.; Eslami, S.A. Conditional Neural Processes. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Perez, E.; Strub, F.; De Vries, H.; Dumoulin, V.; Courville, A. Film: Visual reasoning with a general conditioning layer. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Petersen, J.; Köhler, G.; Zimmerer, D.; Isensee, F.; Jäger, P.F.; Maier-Hein, K.H. GP-ConvCNP: Better Generalization for Conditional Convolutional Neural Processes on Time Series Data. In Proceedings of the Thirty-Seventh Conference on Uncertainty in Artificial Intelligence, Online, 27–29 July 2021. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Bateni, P.; Goyal, R.; Masrani, V.; Wood, F.; Sigal, L. Improved Few-shot Visual Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zaheer, M.; Kottur, S.; Ravanbakhsh, S.; Poczos, B.; Salakhutdinov, R.R.; Smola, A.J. Deep Sets. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Cremer, C.; Li, X.; Duvenaud, D. Inference Suboptimality in Variational Autoencoders. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Kim, H.; Mnih, A.; Schwarz, J.; Garnelo, M.; Eslami, A.; Rosenbaum, D.; Vinyals, O.; Teh, Y.W. Attentive Neural Processes. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Andrychowicz, M.; Denil, M.; Gomez, S.; Hoffman, M.W.; Pfau, D.; Schaul, T.; Shillingford, B.; De Freitas, N. Learning to Learn by Gradient Gescent by Gradient Descent. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical Networks for Few-shot Learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zeng, Q.; Geng, J.; Huang, K.; Jiang, W.; Guo, J. Prototype calibration with feature generation for few-shot remote sensing image scene classification. Remote Sens. 2021, 13, 2728. [Google Scholar] [CrossRef]
- Nichol, A.; Achiam, J.; Schulman, J. On First-order Meta-learning Algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. In Proceedings of the International Conference on Learning Representations, Banff, AB, USA, 14–16 April 2014. [Google Scholar]
- Ghahramani, Z. Probabilistic Machine Learning and Artificial Intelligence. Nature 2015, 521, 452–459. [Google Scholar] [CrossRef] [PubMed]
- Sohn, K.; Lee, H.; Yan, X. Learning Structured Output Representation Using Deep Conditional Generative Models. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 11–12 December 2015. [Google Scholar]
- Gordon, J.; Bruinsma, W.P.; Foong, A.Y.K.; Requeima, J.; Dubois, Y.; Turner, R.E. Convolutional Conditional Neural Processes. In Proceedings of the International Conference on Learning Representations, Online, 26–30 April 2020. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhang, H.; Luo, G.; Li, J.; Wang, F.Y. C2FDA: Coarse-to-fine domain adaptation for traffic object detection. IEEE Trans. Intell. Transp. Syst. 2021, 23, 12633–12647. [Google Scholar] [CrossRef]
- Zhao, K.; Jia, Z.; Jia, F.; Shao, H. Multi-scale integrated deep self-attention network for predicting remaining useful life of aero-engine. Eng. Appl. Artif. Intell. 2023, 120, 105860. [Google Scholar] [CrossRef]
- Gao, H.; Shou, Z.; Zareian, A.; Zhang, H.; Chang, S.F. Low-shot Learning via Covariance-Preserving Adversarial Augmentation Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Wang, Z.; Lan, L.; Vucetic, S. Mixture Model for Multiple Instance Regression and Applications in Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2012, 50, 2226–2237. [Google Scholar] [CrossRef]
- Li, W.H.; Liu, X.; Bilen, H. Cross-domain Few-shot Learning with Task-specific Adapters. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022. [Google Scholar]
- Li, W.H.; Liu, X.; Bilen, H. Universal Representation Learning from Multiple Domains for Few-shot Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Bateni, P.; Barber, J.; van de Meent, J.W.; Wood, F. Enhancing Few-Shot Image Classification with Unlabelled Examples. In Proceedings of the IEEE Workshop on Applications of Computer Vision, Snowmass Village, CO, USA, 4–8 January 2022. [Google Scholar]
- Yang, M.; Wang, Y.; Wang, C.; Liang, Y.; Yang, S.; Wang, L.; Wang, S. Digital twin-driven industrialization development of underwater gliders. IEEE Trans. Ind. Inform. 2023, 19, 9680–9690. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Avg. Rank | 25%. | 30%. | 35%. | 40%. | 45%. | 50%. | 55%. | 60%. | 65%. | 70% Categories | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| D2N4 [4] | 5.7 | 88.6 ± 0.7 | 89.9 ± 0.6 | 92.1 ± 0.5 | 90.8 ± 0.6 | 91.1 ± 0.6 | 92.1 ± 0.6 | 93.8 ± 0.5 | 94.5 ± 0.5 | 94.9 ± 0.4 | 93.9 ± 0.4 |
| Simple CNAPs [29] | 2.0 | 92.9 ± 0.6 | 93.8 ± 0.5 | 94.4 ± 0.6 | 94.2 ± 0.6 | 93.9 ± 0.4 | 94.7 ± 0.6 | 95.0 ± 0.5 | 95.2 ± 0.6 | 96.3 ± 0.5 | 97.0 ± 0.4 |
| TSA [46] | 3.0 | 93.6 ± 0.5 | 93.9 ± 0.5 | 94.4 ± 0.4 | 94.1 ± 0.5 | 94.3 ± 0.5 | 94.4 ± 0.4 | 94.7 ± 0.5 | 94.9 ± 0.3 | 96.1 ± 0.4 | 96.4 ± 0.3 |
| Sim. CNAPs∼fo. 1 | 5.9 | 85.8 ± 0.7 | 88.7 ± 0.6 | 91.6 ± 0.5 | 91.5 ± 0.6 | 91.9 ± 0.7 | 90.2 ± 0.7 | 92.2 ± 0.6 | 94.7 ± 0.5 | 94.0 ± 0.5 | 97.0 ± 0.3 |
| Sim. CNAPs∼fo. 2 | 5.1 | 88.0 ± 0.6 | 92.0 ± 0.5 | 91.1 ± 0.6 | 93.5 ± 0.6 | 91.6 ± 0.7 | 93.2 ± 0.5 | 93.8 ± 0.5 | 94.5 ± 0.6 | 94.5 ± 0.4 | 96.3 ± 0.3 |
| TSA∼fo. 1 | 4.1 | 88.1 ± 0.4 | 89.6 ± 0.5 | 91.7 ± 0.6 | 92.4 ± 0.4 | 93.5 ± 0.4 | 94.6 ± 0.5 | 94.9 ± 0.4 | 95.0 ± 0.5 | 94.5 ± 0.5 | 96.1 ± 0.4 |
| TSA∼fo. 2 | 2.1 | 90.4 ± 0.4 | 91.7 ± 0.6 | 93.0 ± 0.5 | 94.6 ± 0.4 | 95.4 ± 0.6 | 95.2 ± 0.5 | 95.7 ± 0.3 | 95.6 ± 0.4 | 96.8 ± 0.5 | 97.5 ± 0.4 |
| Avg. Rank | Test Only | 25%. | 30%. | 35%. | 40%. | 45%. | 50%. | 55%. | 60%. | 65%. | 70% Categories | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| D2N4 [4] | 6.1 | 89.9 ± 0.6 | 90.3 ± 0.6 | 92.3 ± 0.5 | 93.8 ± 0.5 | 94.4 ± 0.5 | 94.7 ± 0.5 | 95.3 ± 0.4 | 95.8 ± 0.5 | 96.2 ± 0.4 | 96.3 ± 0.4 | 96.5 ± 0.4 |
| Simple CNAPs [29] | 6.4 | 91.2 ± 0.7 | 93.2 ± 0.6 | 93.6 ± 0.6 | 94.0 ± 0.6 | 94.3 ± 0.6 | 94.0 ± 0.5 | 94.5 ± 0.6 | 94.1 ± 0.5 | 95.1 ± 0.6 | 96.0 ± 0.5 | 96.7 ± 0.5 |
| TSA [46] | 4.1 | 94.2 ± 1.0 | 95.3 ± 0.7 | 95.7 ± 0.7 | 95.5 ± 0.6 | 95.8 ± 0.6 | 95.6 ± 0.7 | 95.8 ± 0.6 | 95.4 ± 0.7 | 96.0 ± 0.5 | 96.3 ± 0.6 | 96.5 ± 0.6 |
| Sim. CNAPs∼fo. 1 | 4.3 | 92.6 ± 0.5 | 94.5 ± 0.4 | 95.2 ± 0.4 | 95.5 ± 0.5 | 95.4 ± 0.4 | 96.9 ± 0.4 | 95.6 ± 0.4 | 96.3 ± 0.4 | 96.8 ± 0.3 | 97.0 ± 0.3 | 97.4 ± 0.3 |
| Sim. CNAPs∼fo. 2 | 3.3 | 93.1 ± 0.6 | 94.1 ± 0.5 | 94.9 ± 0.5 | 95.3 ± 0.4 | 95.8 ± 0.4 | 96.4 ± 0.3 | 96.8 ± 0.4 | 97.3 ± 0.4 | 97.5 ± 0.3 | 97.8 ± 0.4 | 98.2 ± 0.3 |
| TSA∼fo. 1 | 1.7 | 95.2 ± 0.8 | 96.2 ± 0.6 | 96.6 ± 0.7 | 96.9 ± 0.6 | 97.3 ± 0.5 | 97.7 ± 0.5 | 97.6 ± 0.6 | 97.4 ± 0.6 | 97.6 ± 0.5 | 97.8 ± 0.4 | 97.9 ± 0.4 |
| TSA∼fo. 2 | 2.0 | 94.4 ± 1.0 | 95.4 ± 0.5 | 95.9 ± 0.4 | 96.5 ± 0.5 | 96.4 ± 0.5 | 97.3 ± 0.3 | 97.8 ± 0.4 | 97.9 ± 0.4 | 97.6 ± 0.5 | 98.1 ± 0.4 | 98.4 ± 0.3 |
| Avg. Rank | ILSVRC | Omniglot | Aircraft | Birds | Textures | QuickDraw | Fungi | Flower | |
|---|---|---|---|---|---|---|---|---|---|
| D2N4 [4] | 15.3 | 26.1 ± 0.8 | 82.8 ± 0.9 | 72.8 ± 0.9 | 34.6 ± 1.0 | 52.7 ± 0.7 | 66.6 ± 0.9 | 32.3 ± 0.9 | 72.8 ± 0.8 |
| fo-MAML [20] | 14.6 | 37.8 ± 1.0 | 83.9 ± 0.9 | 76.4 ± 0.7 | 62.4 ± 1.1 | 64.2 ± 0.8 | 59.7 ± 1.1 | 33.5 ± 1.1 | 80.0 ± 0.8 |
| ProtoNet [34] | 14.3 | 44.5 ± 1.0 | 79.6 ± 1.1 | 71.1 ± 0.9 | 67.0 ± 1.0 | 65.2 ± 0.8 | 64.9 ± 0.9 | 40.3 ± 1.1 | 86.8 ± 0.7 |
| Proto-MAML [20] | 12.6 | 46.5 ± 1.0 | 82.7 ± 1.0 | 75.2 ± 0.8 | 69.9 ± 1.0 | 68.2 ± 0.8 | 66.8 ± 0.9 | 42.0 ± 1.1 | 88.7 ± 0.7 |
| CNAPs [24] | 11.1 | 51.0 ± 1.0 | 90.7 ± 0.6 | 72.3 ± 0.8 | 73.0 ± 0.8 | 54.8 ± 0.7 | 74.2 ± 0.6 | 50.2 ± 1.0 | 88.5 ± 0.6 |
| Simple CNAPs [29] | 9.0 | 56.5 ± 1.0 | 91.7 ± 0.6 | 82.4 ± 0.7 | 74.9 ± 0.9 | 67.8 ± 0.7 | 77.5 ± 0.8 | 46.9 ± 1.0 | 89.7 ± 0.6 |
| SUR [12] | 8.3 | 56.1 ± 1.1 | 93.1 ± 0.5 | 84.6 ± 0.7 | 70.6 ± 1.0 | 71.0 ± 0.8 | 81.3 ± 0.6 | 64.2 ± 1.1 | 82.8 ± 0.8 |
| FLUTE [15] | 7.5 | 51.8 ± 1.0 | 93.2 ± 0.5 | 87.2 ± 0.5 | 79.2 ± 0.8 | 68.8 ± 0.8 | 79.5 ± 0.7 | 58.1 ± 1.1 | 91.6 ± 0.6 |
| Transductive CNAPs [48] | 6.9 | 57.9 ± 1.1 | 94.3 ± 0.4 | 84.7 ± 0.5 | 78.8 ± 0.7 | 66.2 ± 0.8 | 77.9 ± 0.6 | 48.9 ± 1.2 | 92.3 ± 0.4 |
| URT [13] | 6.7 | 55.7 ± 1.0 | 94.4 ± 0.4 | 85.8 ± 0.6 | 76.3 ± 0.8 | 71.8 ± 0.7 | 82.5 ± 0.6 | 63.5 ± 1.0 | 88.2 ± 0.6 |
| URL [47] | 3.1 | 57.5 ± 1.1 | 94.5 ± 0.4 | 88.6 ± 0.5 | 80.5 ± 0.7 | 76.2 ± 0.7 | 81.8 ± 0.6 | 68.7 ± 1.0 | 92.1 ± 0.5 |
| TSA [46] | 2.8 | 57.3 ± 1.0 | 95.0 ± 0.4 | 89.3 ± 0.4 | 81.4 ± 0.7 | 76.7 ± 0.7 | 82.0 ± 0.6 | 67.4 ± 1.0 | 92.2 ± 0.5 |
| Simple CNAPs∼fo. 1 | 9.5 | 52.5 ± 1.1 | 88.2 ± 0.8 | 74.5 ± 0.8 | 73.2 ± 0.9 | 74.0 ± 0.8 | 80.5 ± 0.7 | 53.4 ± 1.1 | 90.2 ± 0.6 |
| Simple CNAPs∼fo. 2 | 7.8 | 55.1 ± 1.1 | 92.2 ± 0.6 | 81.4 ± 0.6 | 78.1 ± 0.8 | 72.9 ± 0.9 | 80.4 ± 0.7 | 59.4 ± 1.0 | 89.7 ± 0.6 |
| TSA∼fo. 1 | 4.0 | 54.1 ± 0.8 | 93.8 ± 0.6 | 85.8 ± 1.0 | 78.4 ± 1.0 | 80.1 ± 0.8 | 84.2 ± 0.8 | 68.7 ± 0.7 | 93.1 ± 0.8 |
| TSA∼fo. 2 | 2.3 | 56.6 ± 0.6 | 96.4 ± 0.8 | 88.4 ± 0.5 | 83.1 ± 0.8 | 78.6 ± 1.0 | 84.4 ± 0.8 | 69.5 ± 1.0 | 92.8 ± 0.7 |
| Avg. Rank | Traffic Signs | MSCOCO | Mnist | Cifar10 | Cifar100 | |
|---|---|---|---|---|---|---|
| fo-MAML [20] | 15.8 | 42.9 ± 1.3 | 29.4 ± 1.1 | - | - | - |
| ProtoNet [34] | 14.3 | 46.5 ± 1.0 | 39.9 ± 1.0 | - | - | - |
| D2N4 [4] | 11.5 | 60.7 ± 1.1 | 28.2 ± 0.9 | 92.9 ± 0.5 | 44.0 ± 0.7 | 39.0 ± 1.0 |
| Proto-MAML [20] | 11.2 | 52.4 ± 1.1 | 41.7 ± 1.1 | - | - | - |
| CNAPs [24] | 10.8 | 56.5 ± 1.1 | 39.4 ± 1.0 | 92.7 ± 0.4 | 61.5 ± 0.7 | 50.1 ± 1.0 |
| SUR [12] | 10.0 | 53.4 ± 1.0 | 50.1 ± 1.0 | 94.3 ± 0.4 | 66.8 ± 0.9 | 56.6 ± 1.0 |
| URT [13] | 9.6 | 51.1 ± 1.1 | 52.2 ± 1.1 | 94.8 ± 0.4 | 67.3 ± 0.8 | 56.9 ± 1.0 |
| Simple CNAPs [29] | 9.2 | 59.2 ± 1.0 | 42.4 ± 1.1 | 93.9 ± 0.4 | 74.3 ± 0.7 | 60.5 ± 1.0 |
| Transductive CNAPs [48] | 7.1 | 59.7 ± 1.1 | 42.5 ± 1.1 | 95.7 ± 0.3 | 75.7 ± 0.7 | 62.9 ± 1.0 |
| FLUTE [15] | 6.6 | 58.4 ± 1.1 | 50.0 ± 1.0 | 95.6 ± 0.5 | 78.6 ± 0.7 | 67.1 ± 1.0 |
| URL [47] | 6.7 | 63.3 ± 1.2 | 54.0 ± 1.0 | 94.7 ± 0.4 | 74.2 ± 0.8 | 63.5 ± 1.0 |
| TSA [46] | 2.3 | 83.5 ± 0.9 | 55.7 ± 1.1 | 96.7 ± 0.4 | 82.9 ± 0.7 | 70.4 ± 0.9 |
| Simple CNAPs∼fo. 1 | 6.4 | 69.5 ± 0.8 | 52.6 ± 0.7 | 93.6 ± 0.4 | 70.5 ± 0.8 | 69.0 ± 1.0 |
| Simple CNAPs∼fo. 2 | 6.5 | 67.4 ± 1.0 | 55.3 ± 0.7 | 92.5 ± 0.5 | 68.4 ± 0.8 | 69.8 ± 0.9 |
| TSA∼fo. 1 | 1.8 | 85.4 ± 0.8 | 58.7 ± 1.0 | 95.1 ± 0.6 | 81.5 ± 0.6 | 73.3 ± 0.8 |
| TSA∼fo. 2 | 2.4 | 84.1 ± 0.6 | 56.6 ± 0.8 | 96.4 ± 0.6 | 80.3 ± 0.8 | 71.7 ± 0.7 |
| Simple CNAPs [29] | Simple CNAPs∼fo. 1 | Simple CNAPs∼fo. 2 | TSA [46] | TSA∼fo. 1 | TSA∼fo. 2 | |
|---|---|---|---|---|---|---|
| Mahalanobis distance (test only) | 91.2 ± 0.7 | 92.6 ± 0.5 | 93.1 ± 0.6 | 94.2 ± 1.0 | 95.2 ± 0.5 | 94.4 ± 1.0 |
| European distance (test only) | 90.7 ± 0.8 | 91.2 ± 0.4 | 92.4 ± 0.6 | 93.4 ± 0.8 | 94.5 ± 0.3 | 94.6 ± 0.9 |
| Mahalanobis distance (70% for training) | 96.7 ± 0.5 | 97.4 ± 0.3 | 98.2 ± 0.3 | 96.5 ± 0.6 | 97.9 ± 0.4 | 98.4 ± 0.3 |
| European distance (70% for training) | 96.6 ± 0.5 | 97.6 ± 0.5 | 97.9 ± 0.8 | 96.8 ± 0.3 | 97.7 ± 0.7 | 98.2 ± 0.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Kong, D.; Lin, R.; Yang, D. Generalizing Spacecraft Recognition via Diversifying Few-Shot Datasets in a Joint Trained Likelihood. Remote Sens. 2023, 15, 4321. https://doi.org/10.3390/rs15174321
Yang X, Kong D, Lin R, Yang D. Generalizing Spacecraft Recognition via Diversifying Few-Shot Datasets in a Joint Trained Likelihood. Remote Sensing. 2023; 15(17):4321. https://doi.org/10.3390/rs15174321
Chicago/Turabian StyleYang, Xi, Dechen Kong, Ren Lin, and Dong Yang. 2023. "Generalizing Spacecraft Recognition via Diversifying Few-Shot Datasets in a Joint Trained Likelihood" Remote Sensing 15, no. 17: 4321. https://doi.org/10.3390/rs15174321
APA StyleYang, X., Kong, D., Lin, R., & Yang, D. (2023). Generalizing Spacecraft Recognition via Diversifying Few-Shot Datasets in a Joint Trained Likelihood. Remote Sensing, 15(17), 4321. https://doi.org/10.3390/rs15174321