

Siamese Multi-Scale Adaptive Search Network for Remote Sensing Single-Object Tracking

Abstract
:1. Introduction
- First, the multi-scale cross correlation is proposed, making use of several image features to achieve the complementary advantages of multiple features and obtain a discriminative model and comprehensive feature representation. The performance of the model is improved, and better tracking results are achieved;
- Second, an adaptive search module is introduced into the network for object tracking. The adaptive search module uses a partition search strategy to assist the Kalman filter in object motion estimation. It can correct the coordinate position of the object when the network is unable to accurately track the object;
- Finally, experiments on remote sensing videos have verified the superiority of the proposed SiamMAS tracker when compared with state-of-the-art tracking methods. This tracker can effectively handle complex backgrounds in remote sensing videos, such as background clutter, occlusion, and scale variation.
2. Related Work
2.1. Trackers with Siamese Architecture
2.2. Trackers for Remote Sensing Videos
2.3. Trackers under Complex Backgrounds
3. Methods
3.1. Multi-Scale Cross Correlation
3.2. Region-Proposal Adaptive Selection
3.2.1. Kalman Filter
3.2.2. Partition Search Strategy
3.3. Tracking Algorithm
| Algorithm 1 Proposed SiamMAS tracking algorithm. |
| Input: Frames ; Initial bounding box of the object , , , ; Output: Predicted bounding boxes of the object , , , ;
|
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
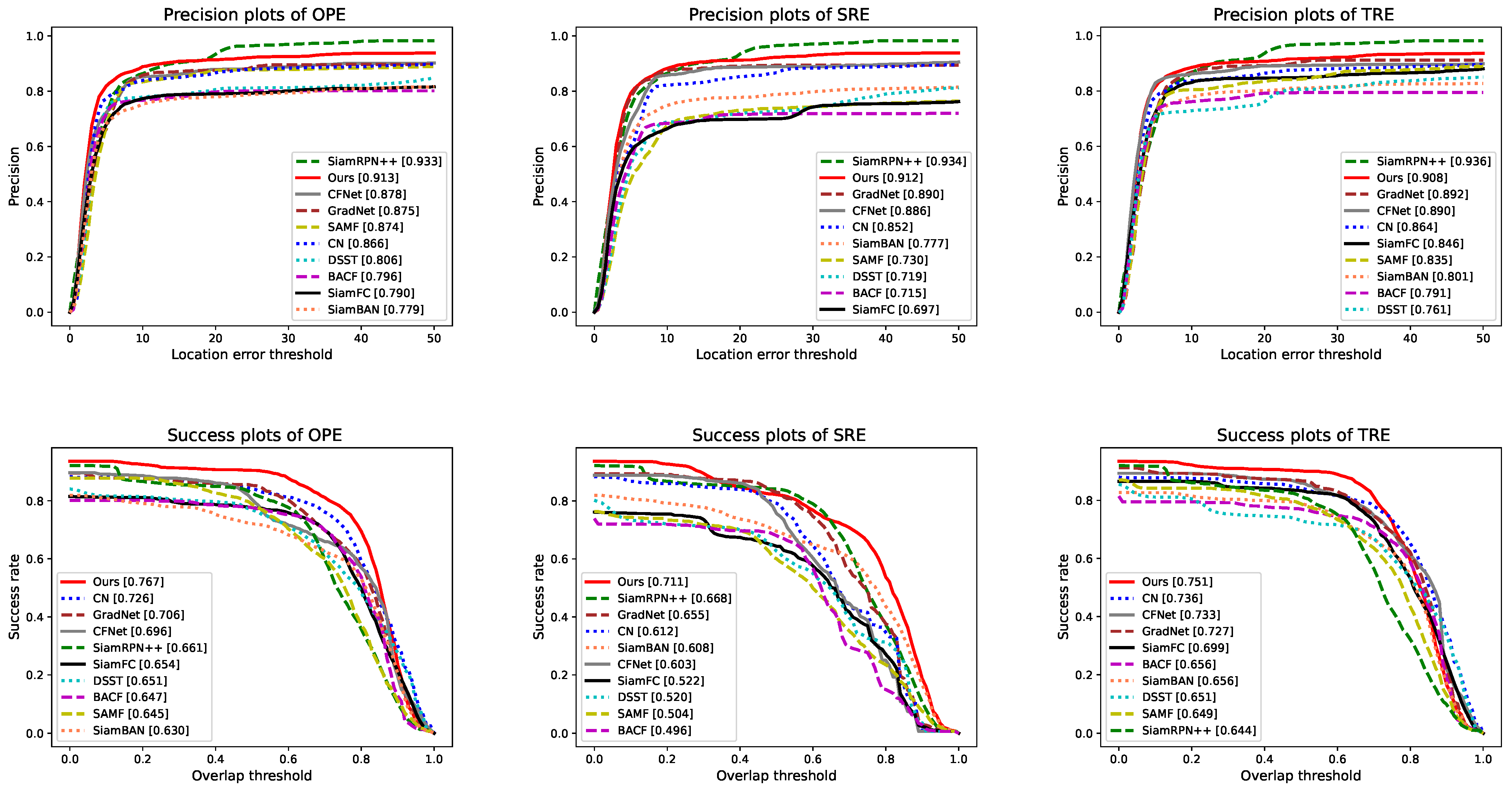
4.2. Comparison with Existing Techniques
4.2.1. Comparison for Complex Backgrounds
4.2.2. Comparison with State-of-the-Art Trackers
4.3. Ablation Study
4.3.1. Discussion on Multi-Scale Cross Correlation
4.3.2. Discussion on Adaptive Search Module
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, Y.; Lim, J.; Yang, M.H. Object Tracking Benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Marvasti-Zadeh, S.M.; Cheng, L.; Ghanei-Yakhdan, H.; Kasaei, S. Deep Learning for Visual Tracking: A Comprehensive Survey. IEEE Trans. Intell. Transport. Syst. 2021, 23, 3943–3968. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar] [CrossRef]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 702–715. [Google Scholar]
- Danelljan, M.; Shahbaz Khan, F.; Felsberg, M.; Van de Weijer, J. Adaptive color attributes for real-time visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1090–1097. [Google Scholar]
- Li, Y.; Zhu, J. A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Asha, C.S.; Narasimhadhan, A.V. Adaptive Learning Rate for Visual Tracking Using Correlation Filters. Procedia Comput. Sci. 2016, 89, 614–622. [Google Scholar] [CrossRef]
- Danelljan, M.; Hager, G.; Khan, F.S.; Felsberg, M. Discriminative Scale Space Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1561–1575. [Google Scholar] [CrossRef] [PubMed]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary learners for real-time tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1401–1409. [Google Scholar]
- Galoogahi, H.K.; Fagg, A.; Lucey, S. Learning Background-Aware Correlation Filters for Visual Tracking. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lukei, A.; Vojí, T.; Ehovinzajc, L.; Matas, J.; Kristan, M. Discriminative Correlation Filter with Channel and Spatial Reliability. Int. J. Comput. Vis. 2018, 126, 671–688. [Google Scholar]
- Wang, N.; Zhou, W.; Tian, Q.; Hong, R.; Li, H. Multi-Cue Correlation Filters for Robust Visual Tracking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, F.; Tian, C.; Zuo, W.; Zhang, L.; Yang, M.H. Learning Spatial-Temporal Regularized Correlation Filters for Visual Tracking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Jain, M.; Tyagi, A.; Subramanyam, A.V.; Denman, S.; Sridharan, S.; Fookes, C. Channel Graph Regularized Correlation Filters for Visual Object Tracking. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 715–729. [Google Scholar] [CrossRef]
- Moorthy, S.; Joo, Y.H. Adaptive Spatial-Temporal Surrounding-Aware Correlation Filter Tracking via Ensemble Learning. Pattern Recognit. 2023, 139, 109457. [Google Scholar] [CrossRef]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H.S. End-to-End Representation Learning for Correlation Filter Based Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5000–5008. [Google Scholar] [CrossRef]
- Danelljan, M.; Robinson, A.; Shahbaz Khan, F.; Felsberg, M. Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9909, pp. 472–488. [Google Scholar] [CrossRef]
- Nam, H.; Han, B. Learning Multi-domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar] [CrossRef]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar] [CrossRef]
- Nam, H.; Baek, M.; Han, B. Modeling and Propagating CNNs in a Tree Structure for Visual Tracking. arXiv 2016, arXiv:1608.07242. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Computer Vision—ECCV 2016 Workshops; Hua, G., Jégou, H., Eds.; Springer: Cham, Switzerland, 2016; pp. 850–865. [Google Scholar] [CrossRef]
- Li, P.; Chen, B.; Ouyang, W.; Wang, D.; Yang, X.; Lu, H. GradNet: Gradient-Guided Network for Visual Object Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2019. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast Online Object Tracking and Segmentation: A Unifying Approach. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1328–1338. [Google Scholar] [CrossRef]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4277–4286. [Google Scholar] [CrossRef]
- Zhang, Y.; Hittawe, M.M.; Katterbauer, K.; Marsala, A.F.; Knio, O.M.; Hoteit, I. Joint seismic and electromagnetic inversion for reservoir mapping using a deep learning aided feature-oriented approach. In Proceedings of the SEG Technical Program Expanded Abstracts, Houston, TX, USA, 13 October 2020; pp. 2186–2190. [Google Scholar]
- Fang, J.; Liu, G. Visual Object Tracking Based on Mutual Learning Between Cohort Multiscale Feature-Fusion Networks with Weighted Loss. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1055–1065. [Google Scholar] [CrossRef]
- Dong, X.; Shen, J.; Porikli, F.; Luo, J.; Shao, L. Adaptive Siamese Tracking With a Compact Latent Network. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 8049–8062. [Google Scholar] [CrossRef]
- Li, X.; Jiao, L.; Zhu, H.; Liu, F.; Yang, S.; Zhang, X.; Wang, S.; Qu, R. A Collaborative Learning Tracking Network for Remote Sensing Videos. IEEE Trans. Cybern. 2023, 53, 1954–1967. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for Small Object Detection. In Computer Vision—ACCV 2016; Lai, S.H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10115, pp. 214–230. [Google Scholar] [CrossRef]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for Small Object Detection. arXiv 2019, arXiv:cs/1902.07296. [Google Scholar]
- Long, M.; Cong, S.; Shanshan, H.; Zoujian, W.; Xuhao, W.; Yanxi, W. SDDNet: Infrared small and dim target detection network. CAAI Trans. Intell. Technol. 2023, in press. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric contextual modulation for infrared small target detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 950–959. [Google Scholar]
- Pham, M.T.; Courtrai, L.; Friguet, C.; Lefèvre, S.; Baussard, A. YOLO-Fine: One-stage detector of small objects under various backgrounds in remote sensing images. Remote Sens. 2020, 12, 2501. [Google Scholar] [CrossRef]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese Box Adaptive Network for Visual Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6667–6676. [Google Scholar] [CrossRef]
- Shao, J.; Du, B.; Wu, C.; Gong, M.; Liu, T. HRSiam: High-Resolution Siamese Network, Towards Space-Borne Satellite Video Tracking. IEEE Trans. Image Process. 2021, 30, 3056–3068. [Google Scholar] [CrossRef] [PubMed]
- Jiang, M.; Zhao, Y.; Kong, J. Mutual Learning and Feature Fusion Siamese Networks for Visual Object Tracking. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3154–3167. [Google Scholar] [CrossRef]
- Dong, X.; Shen, J.; Wu, D.; Guo, K.; Jin, X.; Porikli, F. Quadruplet Network With One-Shot Learning for Fast Visual Object Tracking. IEEE Trans. Image Process. 2019, 28, 3516–3527. [Google Scholar] [CrossRef]
- Bi, F.; Sun, J.; Han, J.; Wang, Y.; Bian, M. Remote Sensing Target Tracking in Satellite Videos Based on a Variable-angle-adaptive Siamese Network. IET Image Proc. 2021, 15, 1987–1997. [Google Scholar] [CrossRef]
- Zhang, T.; Liu, X.; Zhang, Q.; Han, J. SiamCDA: Complementarity- and Distractor-Aware RGB-T Tracking Based on Siamese Network. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1403–1417. [Google Scholar] [CrossRef]
- Shi, F.; Qiu, F.; Li, X.; Tang, Y.; Zhong, R.; Yang, C. A Method to Detect and Track Moving Airplanes from a Satellite Video. Remote Sens. 2020, 12, 2390. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, C.; Song, J.; Xu, Y. Object Tracking Based on Satellite Videos: A Literature Review. Remote Sens. 2022, 14, 3674. [Google Scholar] [CrossRef]
- Shao, J.; Du, B.; Wu, C.; Zhang, L. Tracking Objects From Satellite Videos: A Velocity Feature Based Correlation Filter. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7860–7871. [Google Scholar] [CrossRef]
- Xuan, S.; Li, S.; Han, M.; Wan, X.; Xia, G.S. Object Tracking in Satellite Videos by Improved Correlation Filters With Motion Estimations. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1074–1086. [Google Scholar] [CrossRef]
- Song, W.; Jiao, L.; Liu, F.; Liu, X.; Li, L.; Yang, S.; Hou, B.; Zhang, W. A Joint Siamese Attention-Aware Network for Vehicle Object Tracking in Satellite Videos. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Cui, Y.; Hou, B.; Wu, Q.; Ren, B.; Wang, S.; Jiao, L. Remote Sensing Object Tracking with Deep Reinforcement Learning Under Occlusion. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Li, K.; Kong, Y.; Fu, Y. Visual Object Tracking Via Multi-Stream Deep Similarity Learning Networks. IEEE Trans. Image Process. 2020, 29, 3311–3320. [Google Scholar] [CrossRef]
- Xiong, F.; Zhou, J.; Qian, Y. Material Based Object Tracking in Hyperspectral Videos. IEEE Trans. Image Process. 2020, 29, 3719–3733. [Google Scholar] [CrossRef]
- Liu, S.; Liu, D.; Muhammad, K.; Ding, W. Effective Template Update Mechanism in Visual Tracking with Background Clutter. Neurocomputing 2021, 458, 615–625. [Google Scholar] [CrossRef]
- Danelljan, M.; Häger, G.; Shahbaz Khan, F.; Felsberg, M. Accurate Scale Estimation for Robust Visual Tracking. In Proceedings of the British Machine Vision Conference 2014, Nottingham, UK, 1–5 September 2014; pp. 1–11. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, J. A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration. In Computer Vision—ECCV 2014 Workshops; Agapito, L., Bronstein, M.M., Rother, C., Eds.; Springer International Publishing: Cham, Switzerland, 2015; Volume 8926, pp. 254–265. [Google Scholar] [CrossRef]
- Ruan, W.; Chen, J.; Wu, Y.; Wang, J.; Liang, C.; Hu, R.; Jiang, J. Multi-Correlation Filters with Triangle-Structure Constraints for Object Tracking. IEEE Trans. Multimed. 2019, 21, 1122–1134. [Google Scholar] [CrossRef]
- He, Z.; Yi, S.; Cheung, Y.M.; You, X.; Tang, Y.Y. Robust Object Tracking via Key Patch Sparse Representation. IEEE Trans. Cybern. 2016, 47, 354–364. [Google Scholar] [CrossRef]
- Dong, X.; Shen, J.; Yu, D.; Wang, W.; Liu, J.; Huang, H. Occlusion-Aware Real-Time Object Tracking. IEEE Trans. Multimed. 2017, 19, 763–771. [Google Scholar] [CrossRef]
- Guo, Q.; Han, R.; Feng, W.; Chen, Z.; Wan, L. Selective Spatial Regularization by Reinforcement Learned Decision Making for Object Tracking. IEEE Trans. Image Process. 2020, 29, 2999–3013. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Zhang, S.; Zhang, L. Towards Occlusion Handling: Object Tracking With Background Estimation. IEEE Trans. Cybern. 2018, 48, 2086–2100. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lu, T.; Wang, J.; Zhang, Y.; Wang, Z.; Jiang, J. Satellite Image Super-Resolution via Multi-Scale Residual Deep Neural Network. Remote Sens. 2019, 11, 1588. [Google Scholar] [CrossRef]
- Shen, J.; Tang, X.; Dong, X.; Shao, L. Visual Object Tracking by Hierarchical Attention Siamese Network. IEEE Trans. Cybern. 2020, 50, 3068–3080. [Google Scholar] [CrossRef] [PubMed]
- Funk, N. A Study of the Kalman Filter Applied to Visual Tracking; University of Alberta, Project for CMPUT; University of Alberta: Edmonton, AB, Canada, 2003; Volume 652, pp. 1–26. [Google Scholar]
- Weng, S.K.; Kuo, C.M.; Tu, S.K. Video Object Tracking Using Adaptive Kalman Filter. J. Vis. Commun. Image Represent. 2006, 17, 1190–1208. [Google Scholar] [CrossRef]
- Gunjal, P.R.; Gunjal, B.R.; Shinde, H.A.; Vanam, S.M.; Aher, S.S. Moving Object Tracking Using Kalman Filter. In Proceedings of the 2018 International Conference On Advances in Communication and Computing Technology (ICACCT), Sangamner, India, 8–9 February 2018; pp. 544–547. [Google Scholar] [CrossRef]
- Feng, S.; Hu, K.; Fan, E.; Zhao, L.; Wu, C. Kalman Filter for Spatial-Temporal Regularized Correlation Filters. IEEE Trans. Image Process. 2021, 30, 3263–3278. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. LaSOT: A High-Quality Benchmark for Large-Scale Single Object Tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5369–5378. [Google Scholar] [CrossRef]
- Real, E.; Shlens, J.; Mazzocchi, S.; Pan, X.; Vanhoucke, V. YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7464–7473. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar] [CrossRef]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A Benchmark. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar] [CrossRef]
- Yun, S.; Choi, J.; Yoo, Y.; Yun, K.; Choi, J.Y. Action-Driven Visual Object Tracking with Deep Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2239–2252. [Google Scholar] [CrossRef]
- Babenko, B.; Yang, M.H.; Belongie, S. Robust Object Tracking with Online Multiple Instance Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1619–1632. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Mu, X. Dynamic Siamese Network with Adaptive Kalman Filter for Object Tracking in Complex Scenes. IEEE Access 2020, 8, 222918–222930. [Google Scholar] [CrossRef]
- Possegger, H.; Mauthner, T.; Bischof, H. In defense of color-based model-free tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2113–2120. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A Benchmark and Simulator for UAV Tracking. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 445–461. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trackers | Background Clutter | Occlusion | Scale Variation | FPS | |||
|---|---|---|---|---|---|---|---|
| Precision | AUC | Precision | AUC | Precision | AUC | ||
| AD-OHNet | 0.471 | 0.419 | 0.926 | 0.645 | 0.639 | 0.491 | 4.232 |
| Ours | 0.990 | 0.686 | 0.873 | 0.712 | 0.932 | 0.740 | 37.528 |
| Trackers | OPE | SRE | TRE | |||
|---|---|---|---|---|---|---|
| Precision | AUC | Precision | AUC | Precision | AUC | |
| GradNet [23] | 0.875 | 0.706 | 0.890 | 0.655 | 0.892 | 0.727 |
| CFNet [17] | 0.878 | 0.696 | 0.886 | 0.603 | 0.890 | 0.733 |
| Staple [10] | 0.793 | 0.648 | 0.778 | 0.538 | 0.811 | 0.664 |
| DSST [9] | 0.806 | 0.651 | 0.719 | 0.520 | 0.761 | 0.651 |
| CN [5] | 0.866 | 0.726 | 0.852 | 0.612 | 0.864 | 0.736 |
| SAMF [6] | 0.874 | 0.645 | 0.730 | 0.504 | 0.835 | 0.649 |
| KCF_CN [8] | 0.581 | 0.445 | 0.411 | 0.306 | 0.506 | 0.407 |
| BACF [11] | 0.796 | 0.647 | 0.715 | 0.496 | 0.791 | 0.656 |
| CSK [4] | 0.810 | 0.667 | 0.762 | 0.550 | 0.811 | 0.658 |
| CSR-DCF [12] | 0.795 | 0.645 | 0.795 | 0.548 | 0.788 | 0.666 |
| DAT [73] | 0.567 | 0.422 | 0.548 | 0.373 | 0.550 | 0.381 |
| KCF_HOG [7] | 0.676 | 0.511 | 0.639 | 0.455 | 0.754 | 0.618 |
| STRCF [14] | 0.642 | 0.524 | 0.642 | 0.467 | 0.628 | 0.521 |
| MCCT-H [13] | 0.792 | 0.657 | 0.796 | 0.550 | 0.785 | 0.666 |
| MOSSE [3] | 0.756 | 0.587 | 0.757 | 0.544 | 0.748 | 0.582 |
| AD-OHNet [46] | 0.687 | 0.492 | 0.688 | 0.426 | 0.626 | 0.469 |
| SiamFC [22] | 0.790 | 0.654 | 0.697 | 0.522 | 0.846 | 0.699 |
| SiamBAN [35] | 0.779 | 0.630 | 0.777 | 0.608 | 0.801 | 0.656 |
| SiamMask [24] | 0.919 | 0.713 | 0.905 | 0.714 | 0.935 | 0.721 |
| SiamRPN++ [25] | 0.933 | 0.661 | 0.934 | 0.668 | 0.936 | 0.644 |
| Ours | 0.913 | 0.767 | 0.912 | 0.711 | 0.908 | 0.751 |
| DSST [9] | SAMF [6] | SiamFC [22] | SiamBAN [35] | SiamRPN++ [25] | Ours | |
|---|---|---|---|---|---|---|
| Precision | 0.586 | 0.592 | 0.648 | 0.833 | 0.807 | 0.802 |
| AUC | 0.356 | 0.395 | 0.485 | 0.631 | 0.613 | 0.637 |
| ECO [20] | MDNet [19] | SiamFC [22] | SiamBAN [35] | SiamRPN++ [25] | Ours | |
|---|---|---|---|---|---|---|
| Precision | 0.338 | 0.460 | 0.420 | 0.598 | 0.569 | 0.604 |
| AUC | 0.324 | 0.397 | 0.336 | 0.514 | 0.496 | 0.535 |
| Multi-Scale Cross Correlation | Adaptive Search Module | Precision |
|---|---|---|
| - | - | 0.779 |
| ✓ | - | 0.825 |
| - | ✓ | 0.863 |
| ✓ | ✓ | 0.913 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, B.; Cui, Y.; Ren, Z.; Li, Z.; Wang, S.; Jiao, L. Siamese Multi-Scale Adaptive Search Network for Remote Sensing Single-Object Tracking. Remote Sens. 2023, 15, 4359. https://doi.org/10.3390/rs15174359
Hou B, Cui Y, Ren Z, Li Z, Wang S, Jiao L. Siamese Multi-Scale Adaptive Search Network for Remote Sensing Single-Object Tracking. Remote Sensing. 2023; 15(17):4359. https://doi.org/10.3390/rs15174359
Chicago/Turabian StyleHou, Biao, Yanyu Cui, Zhongle Ren, Zhihao Li, Shuang Wang, and Licheng Jiao. 2023. "Siamese Multi-Scale Adaptive Search Network for Remote Sensing Single-Object Tracking" Remote Sensing 15, no. 17: 4359. https://doi.org/10.3390/rs15174359