
Remote Sensing Image Target Detection and Recognition Based on YOLOv5


Abstract
:1. Introduction
- (1)
- The introduction of K-Means++ clustering in the input stage to generate anchor frames can improve the drawbacks of the K-Means clustering algorithm, effectively suppress the influence of noise points and outliers on the clustering of anchor frames, so as to obtain more accurate results, and can reduce the difficulty of model convergence, thus better meeting the needs of remote sensing target detection.
- (2)
- The attention mechanism is similar to the processing of information by the human brain, which is mainly derived from the study of human vision. Humans will accept all information acquired by the eyes without thinking, but the human brain will often automatically filter out irrelevant information that is not relevant to the task at hand, and focus cognitive attention on the main information, so as to make rational use of the limited visual information. Therefore, the attention mechanism was added to YOLOv5’s DarkNet53 backbone network to achieve the model’s improved accuracy for target recognition of small targets, in complex background scenes, and in mutual occlusion.
- (3)
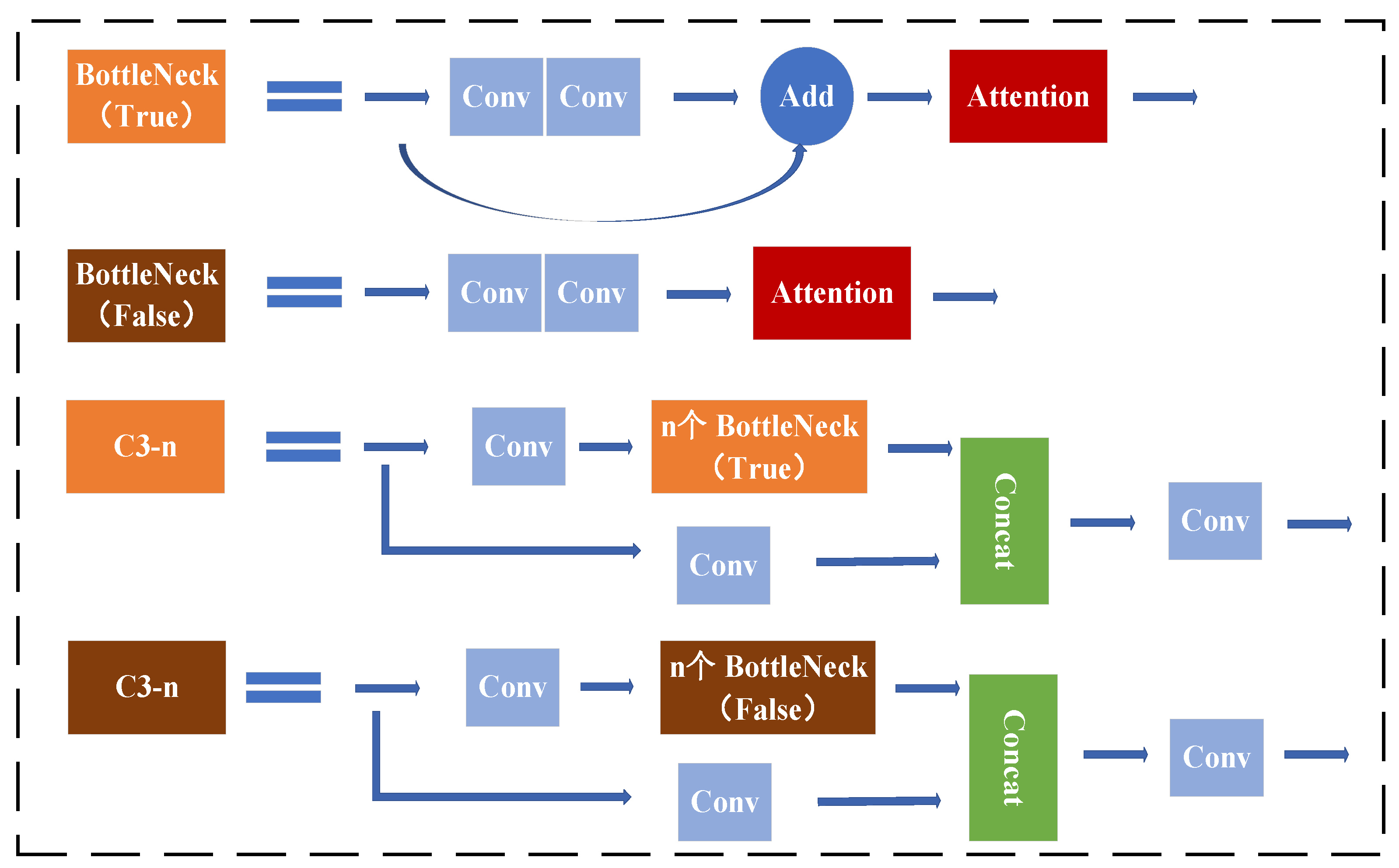
- The original YOLOv5 used a coupled yolo head for predicting confidence, classification scores, and localisation regression results. However, the feature information focused on the localisation task and the classification task are different, and the coupled detection head, by sharing the convolution kernel and thus sharing parameters, will in turn affect the final results between the different tasks. At the same time, the separation of the localisation and classification tasks will lead to a mismatch between the final localisation accuracy and the classification accuracy, thus compromising the final accuracy of the model. The improvement solution uses the introduction of the double IoU-aware decoupled head to decouple the detection head classification task from the regression task into two branches, while redesigning the confidence level to improve the correlation between classification accuracy and localization accuracy, thus improving the detection effect and convergence speed of the model.
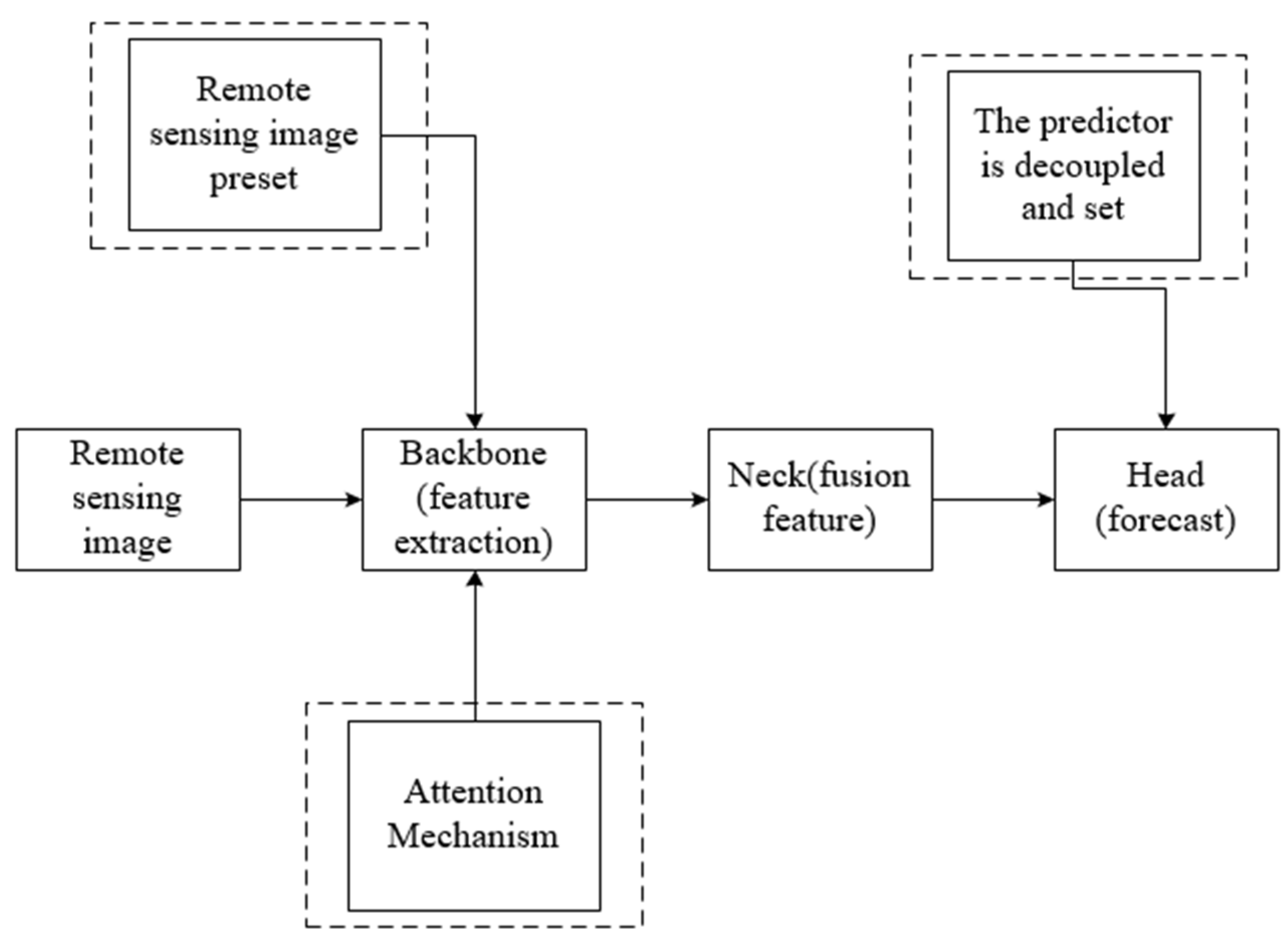
2. Methods
2.1. YOLOv5 Target Detection Algorithm
2.2. YOLOv5 Input Stage Improvements
2.3. Backbone Network Improvements
- (1)
- In the backbone network stage of YOLOv5, a large number of convolution operations are used to make the pixels of small targets in the feature map smaller and smaller, and the feature information containing small targets is less and less. For image feature information, multi-layer convolution will lose a lot of feature information, which will affect the detection effect of small targets.
- (2)
- In the remote sensing image, the proportion of the target pixel relative to the entire image is very small, and there is complex background information. However, the YOLOv5 algorithm does not focus on important information, and cannot distinguish irrelevant background information from noise and important information, which leads to the incomplete and insufficient extraction of the feature information of the remote sensing target by the detection model.
- (1)
- Principle of SENet
- (2)
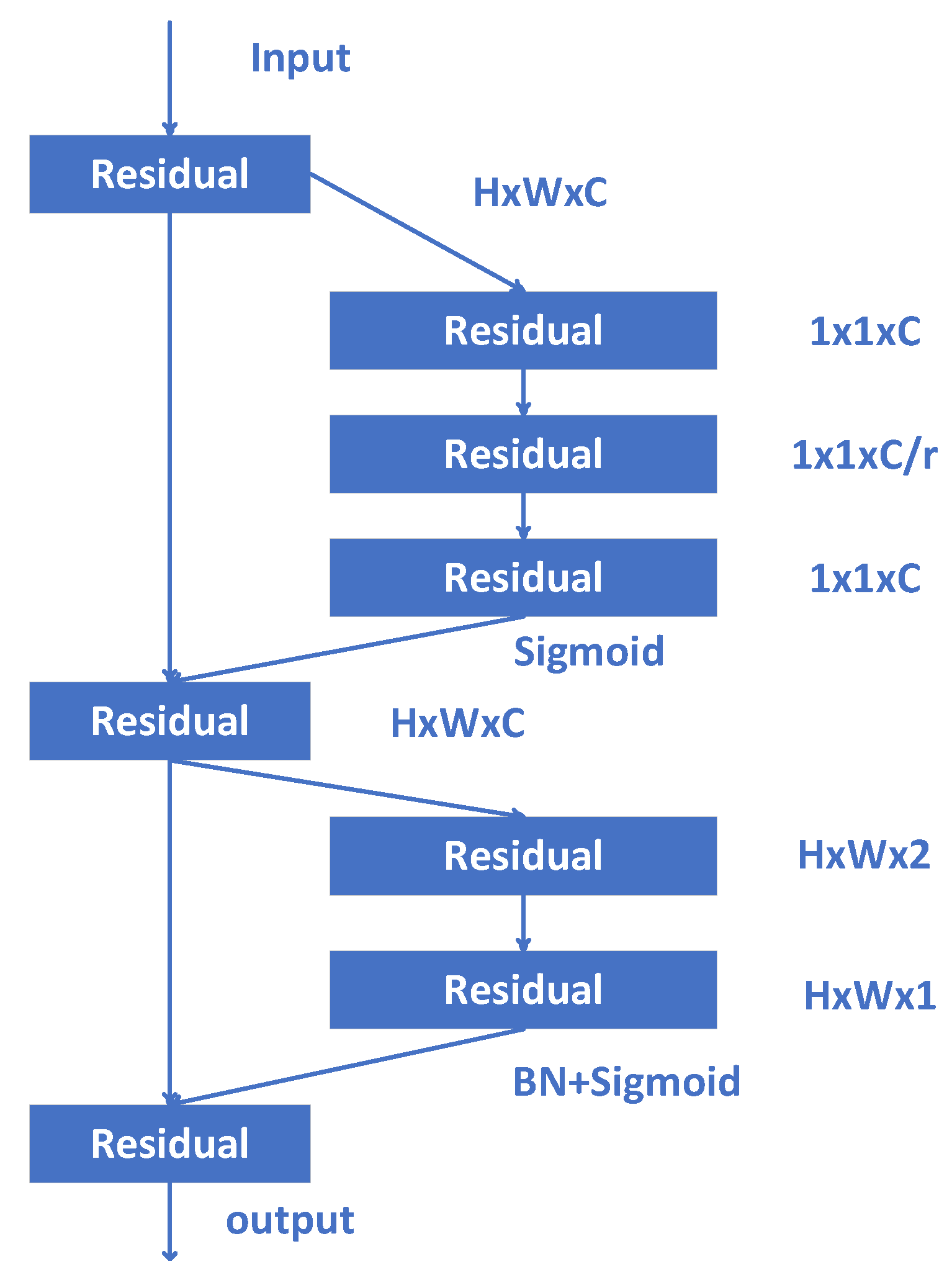
- CBAM
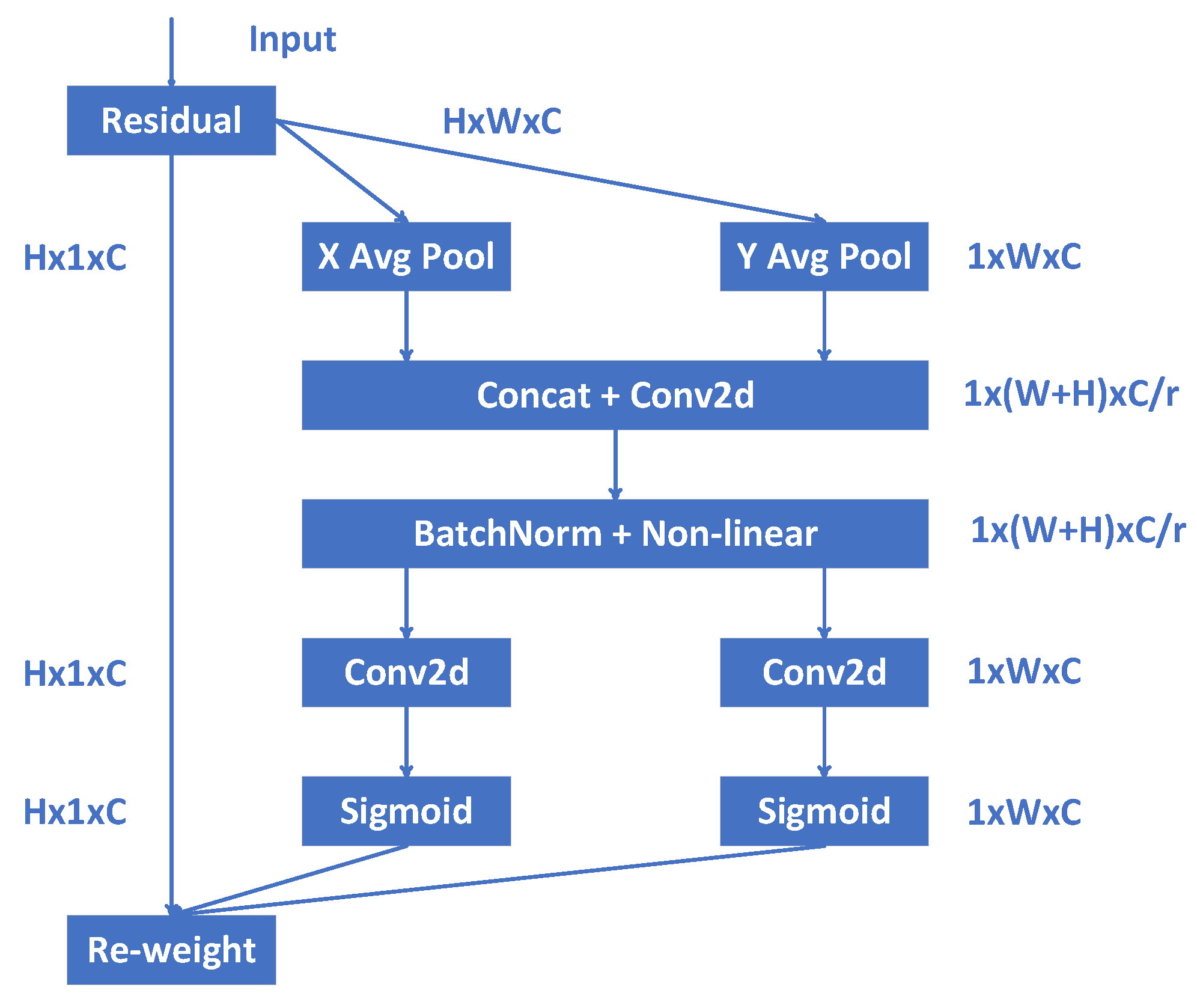
- (3)
- CA
2.4. Output Improvements
3. Experiment and Result Analysis
3.1. Experimental Setup
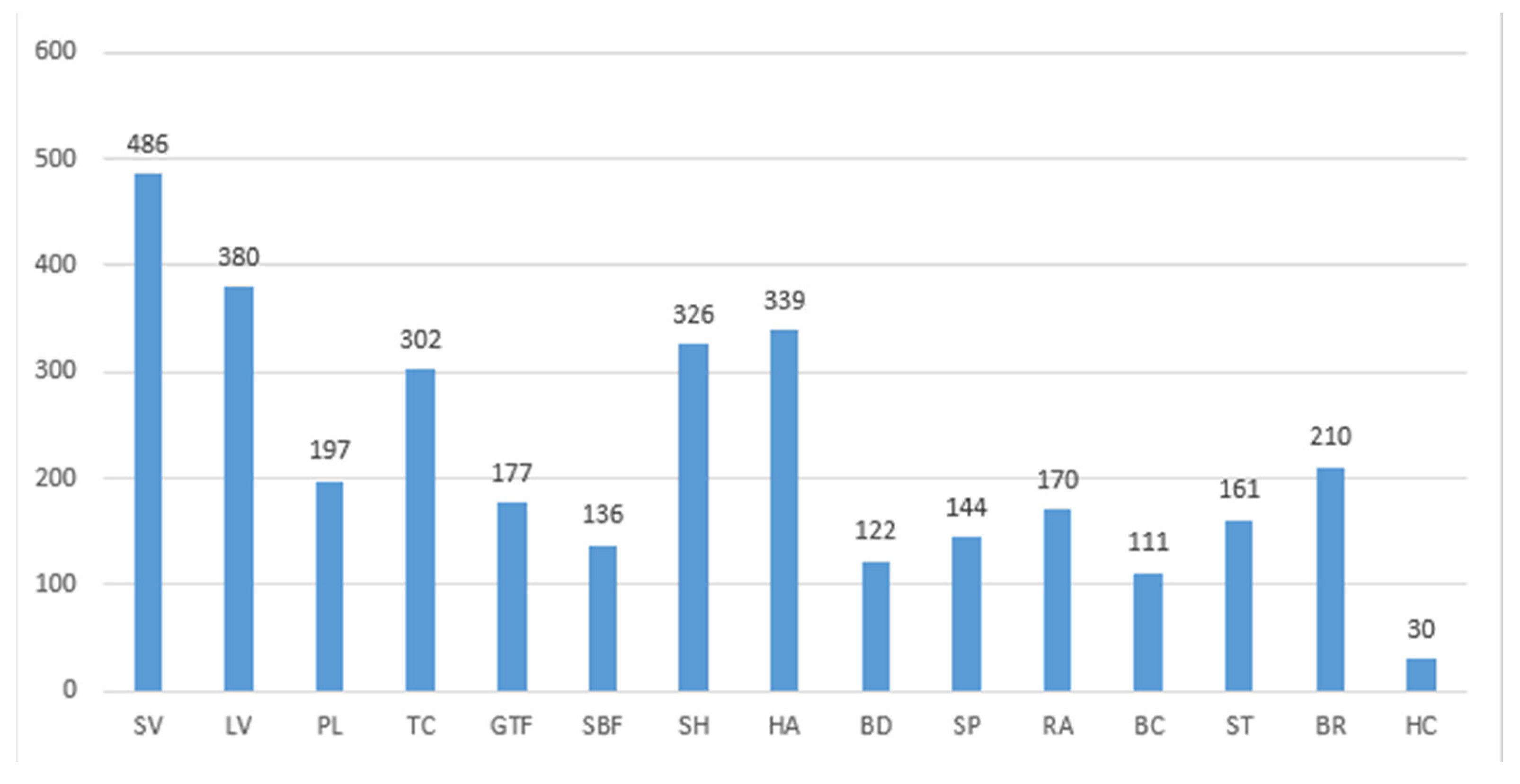
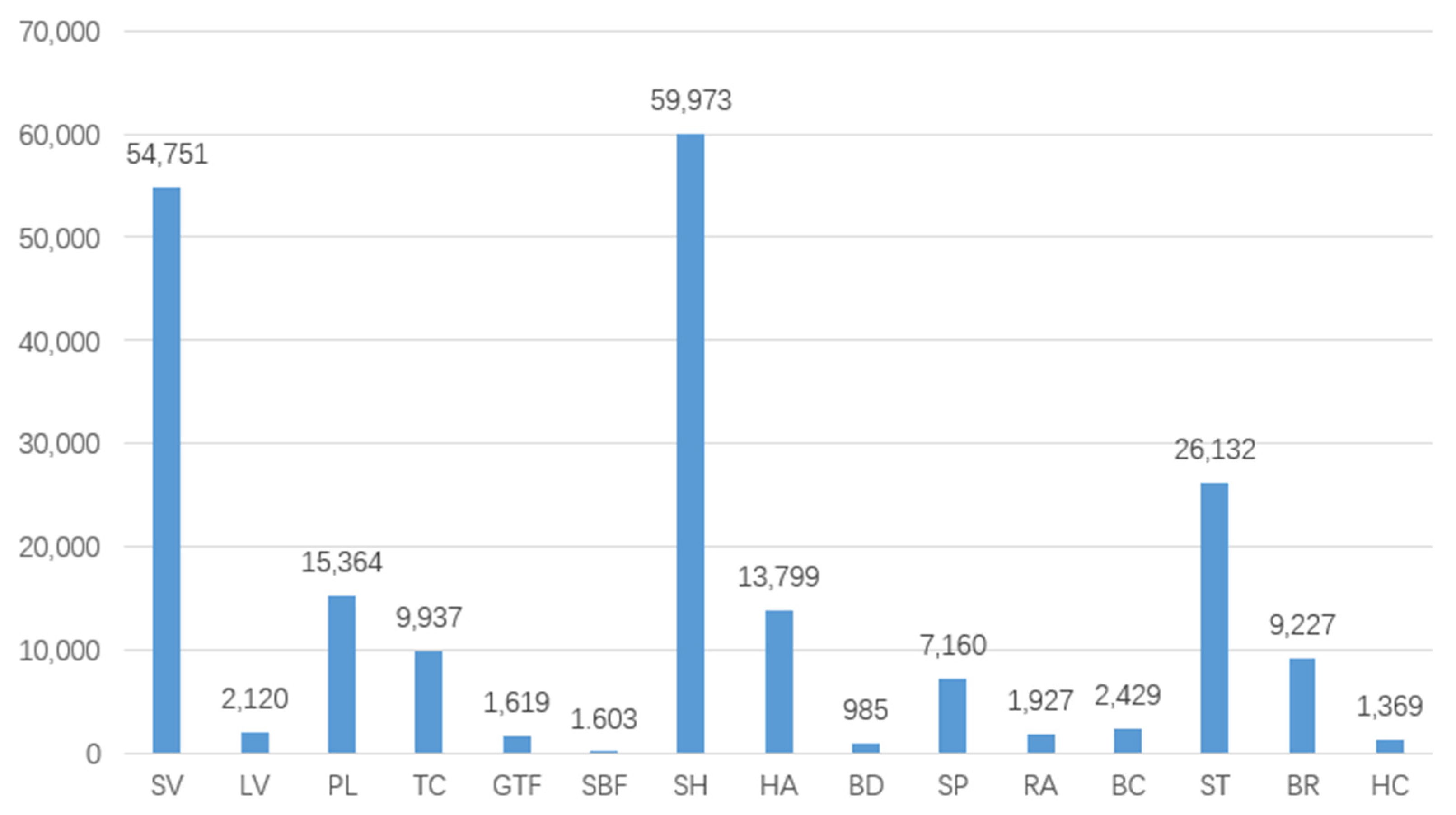
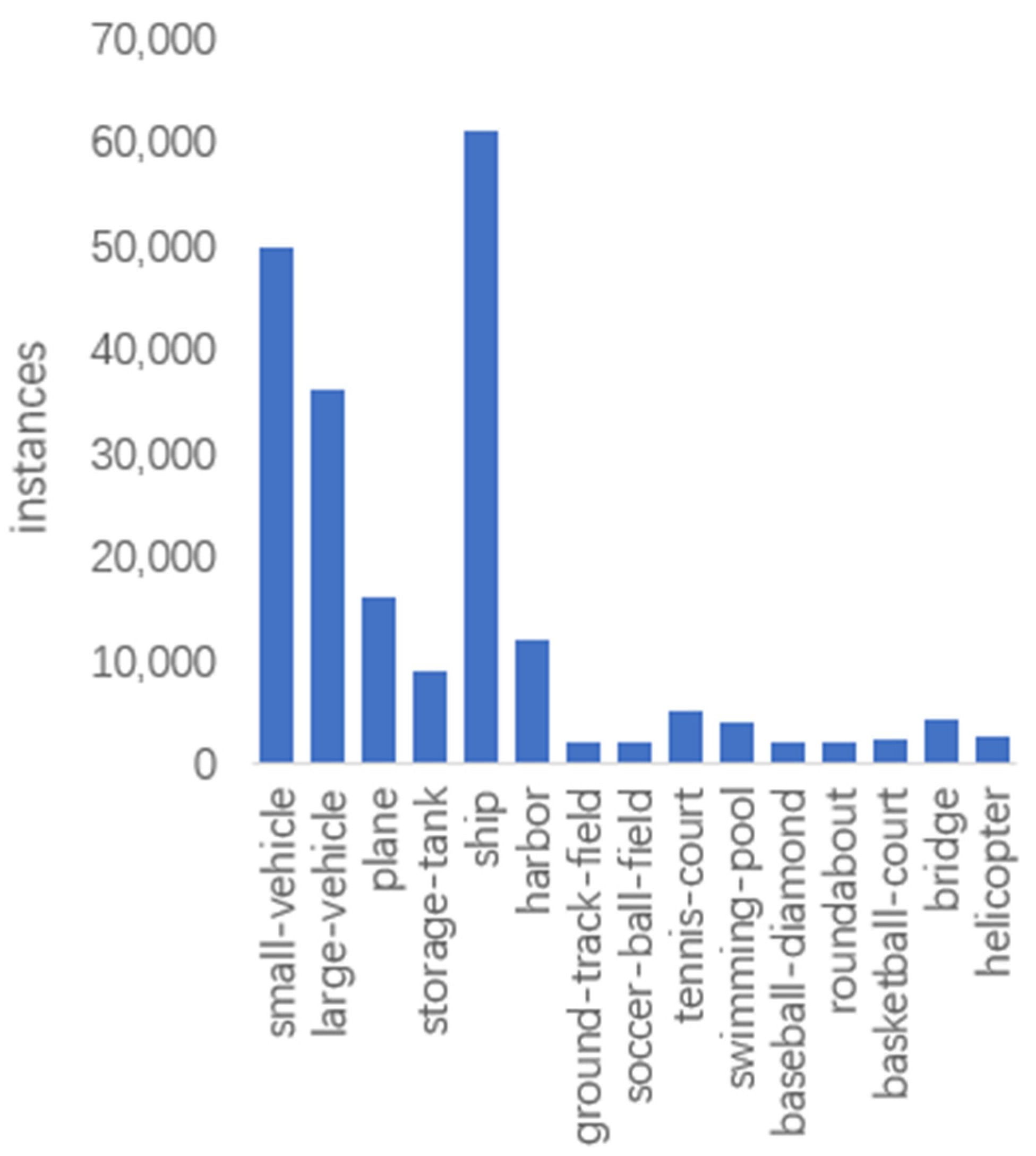
3.1.1. Dataset
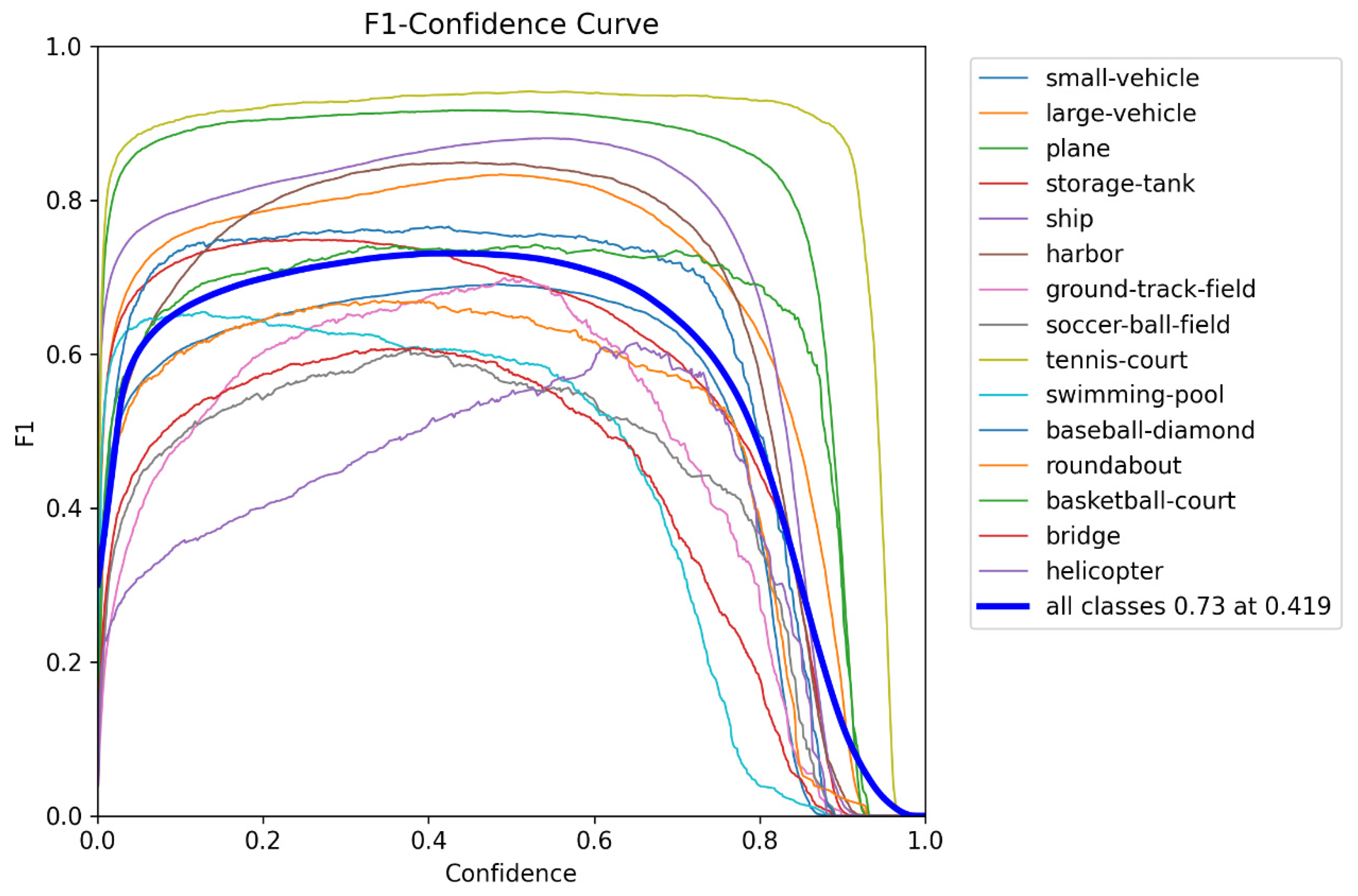
3.1.2. Evaluating Indicator
- (1)
- Accuracy
- (2)
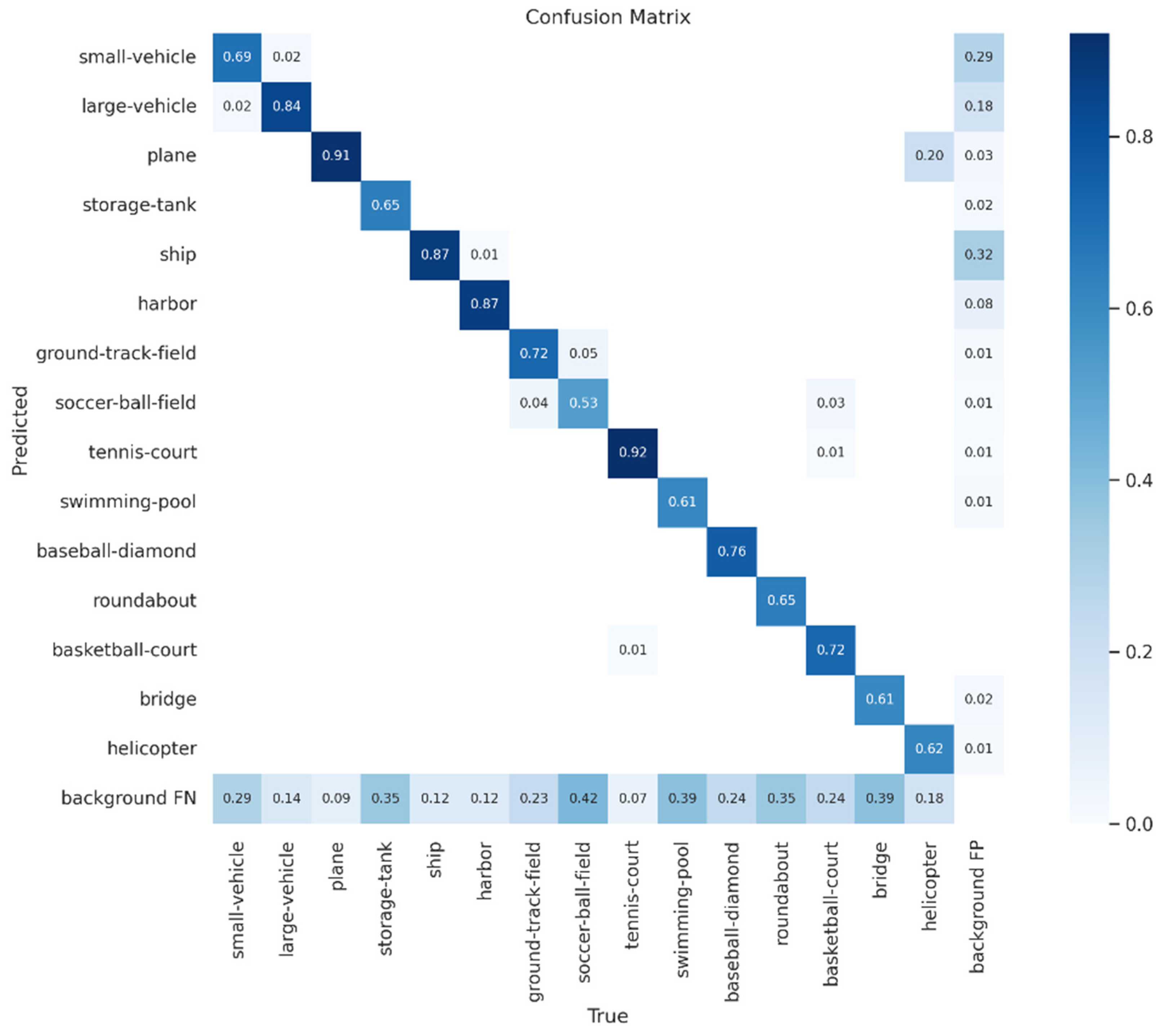
- TP, FP, TN, and FN
- (3)
- Recall rate and precision rate
- (4)
- AP and mAP
- (5)
- FPS
3.1.3. Experimental Environment
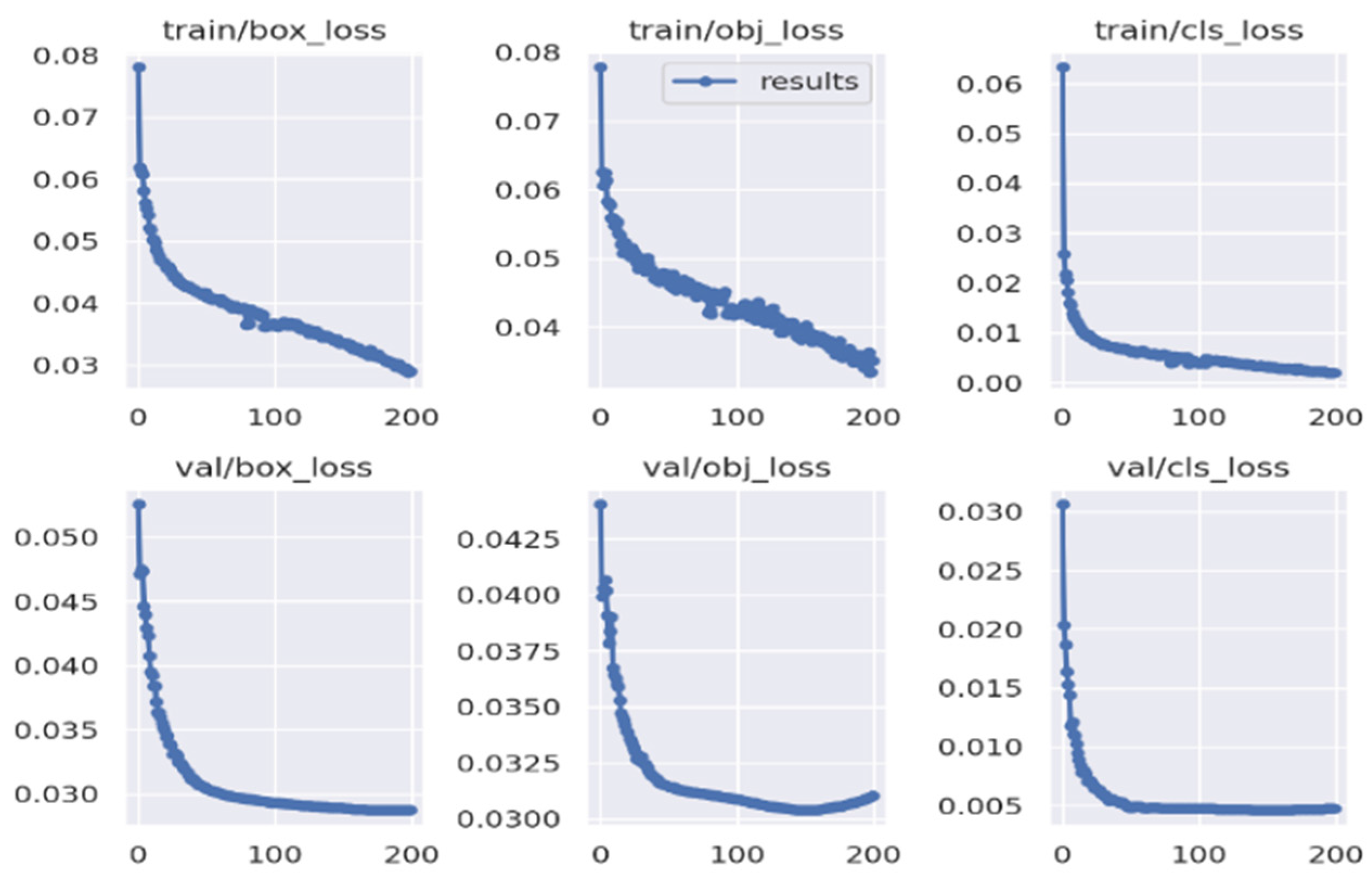
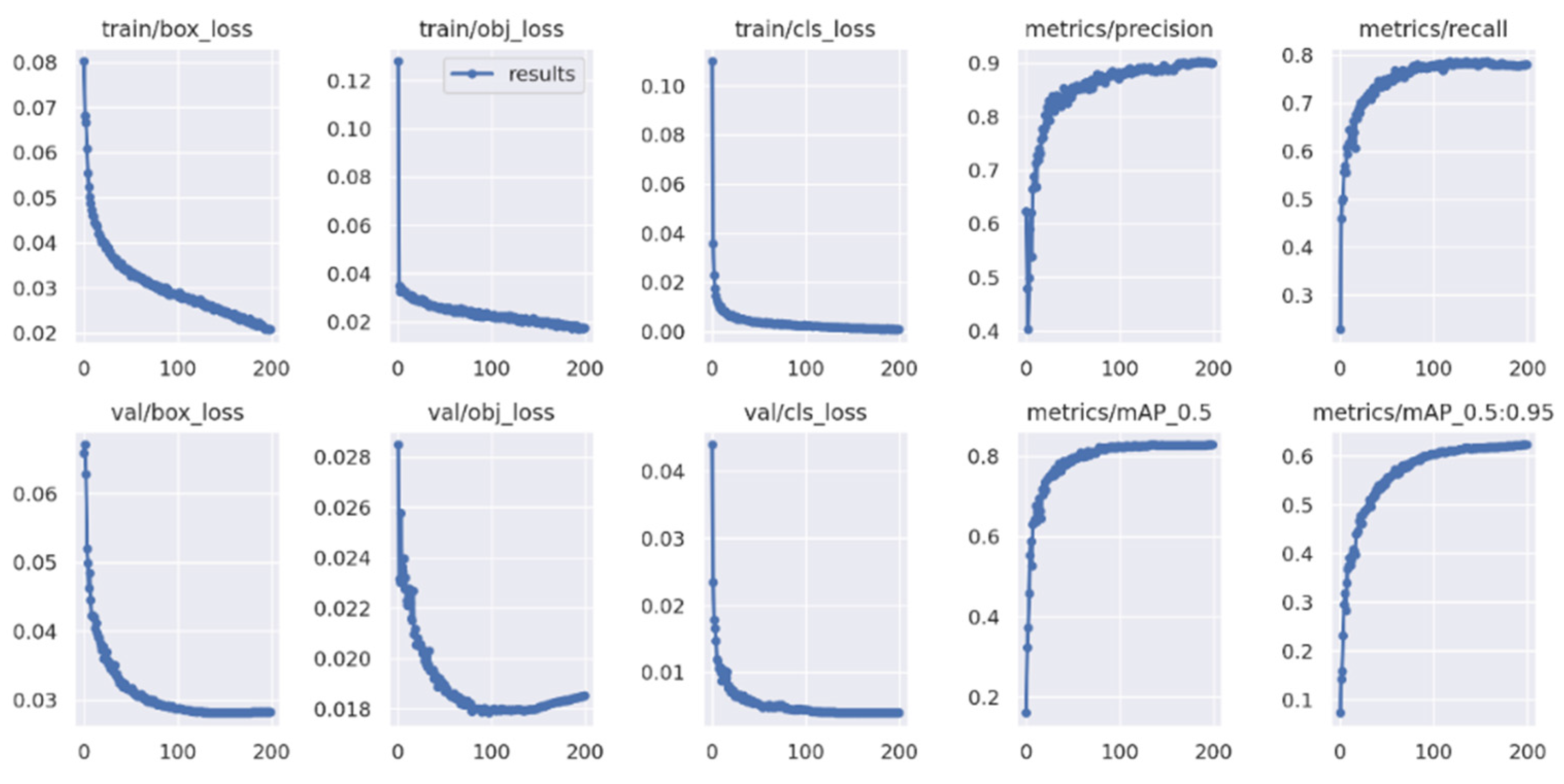
3.1.4. Experimental Parameters
3.2. Analysis and Comparison of Results
- (1)
- Input stage improvement
- (2)
- Output-side improvement comparison experiments
- (3)
- Backbone network improvement comparison experiments
3.3. Other Comparative Experiments
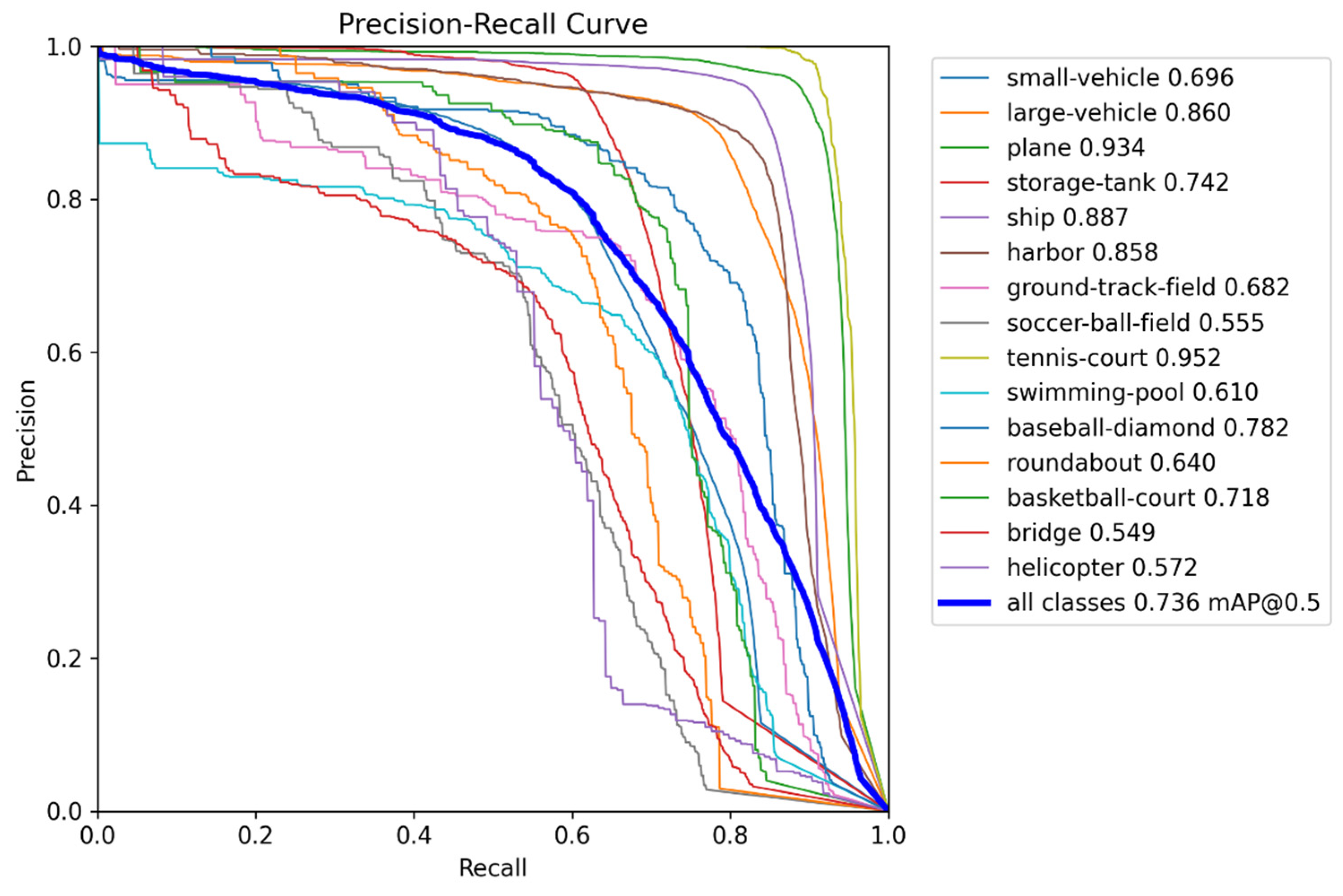
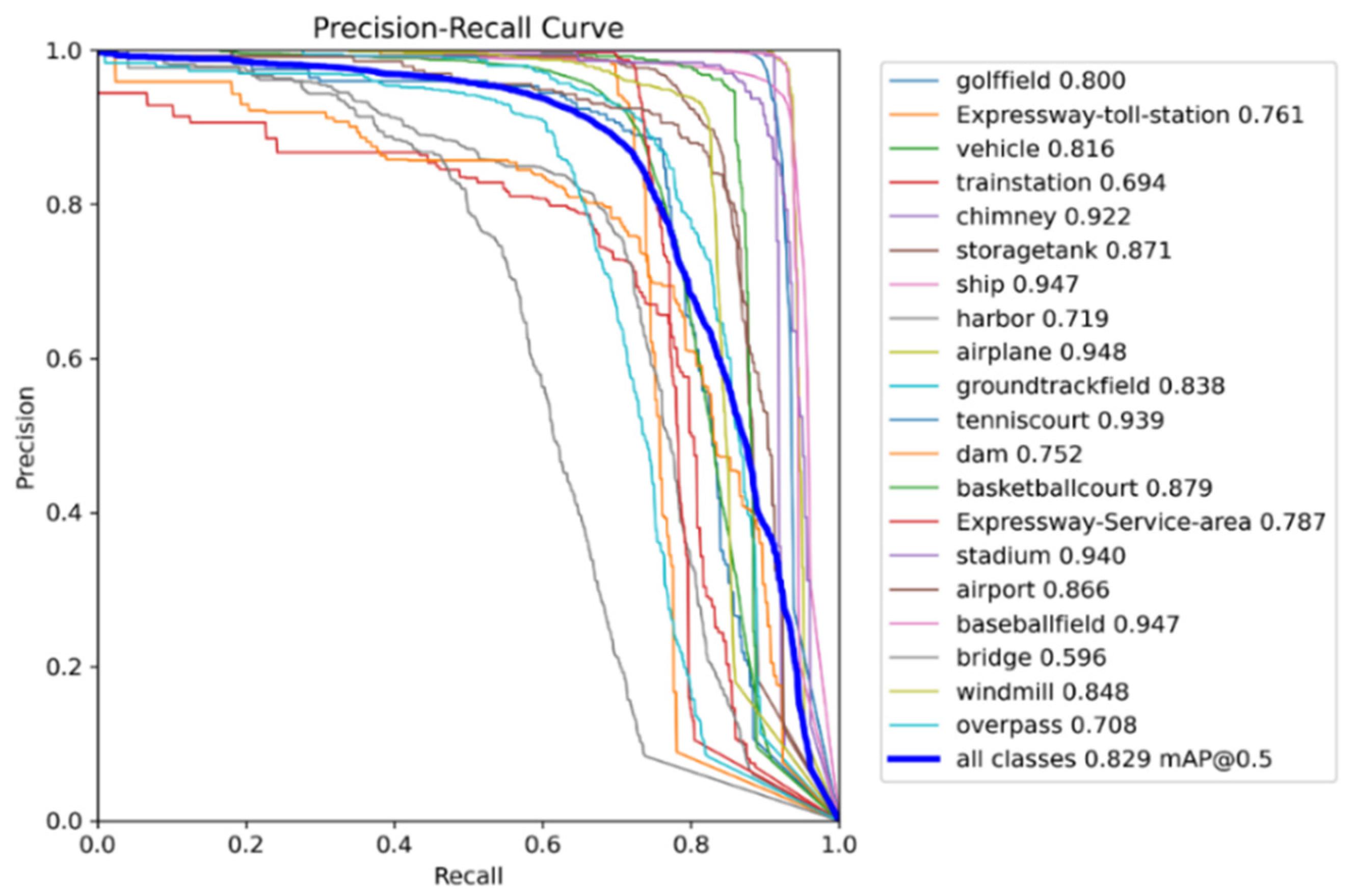
3.4. Comparison of Test Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: New York, NY, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Viola, P.; Jones, M. Rapid Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition CVPR 2001, Kauai, HI, USA, 8–14 December 2001; IEEE: New York, NY, USA, 2001; Volume 1, p. I. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, H.; Jin, Y.; Ke, H.; Zhang, X. DDH-YOLOv5: Improved YOLOv5 Based on Double IoU-Aware Decoupled Head for Object Detection. J. Real-Time Image Process. 2022, 19, 1023–1033. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ho, Y.; Wookey, S. The Real-World-Weight Cross-Entropy Loss Function: Modeling the Costs of Mislabeling. IEEE Access 2019, 8, 4806–4813. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-Means++ the Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wu, S.; Li, X.; Wang, X. IoU-Aware Single-Stage Object Detector for Accurate Localization. Image Vis. Comput. 2020, 97, 103911. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Zhao, W.Q.; Kang, B.J.; Zhao, Z.B. Improving YOLOv5s for remote sensing image target detection. J. Intell. Syst. 2022, 18, 86–95. [Google Scholar]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H.; et al. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Output Layer | Size | Size | Size |
|---|---|---|---|
| P3 | [11, 11] | [14, 23] | [26, 13] |
| P4 | [24, 25] | [26, 47] | [47, 31] |
| P5 | [54, 55] | [94, 115] | [190, 192] |
| Initial Learning Rate | Recurrent Learning Rate | Learning Rate Momentum | Weight Decay Factor | Warm-Up Learning Rounds | Warm-Up Learning Momentum | Warm-Up Initial Learning Rate |
|---|---|---|---|---|---|---|
| 0.01 | 0.2 | 0.937 | 0.0005 | 3.0 | 0.8 | 0.1 |
| Output Layer | Size | Size | Size |
|---|---|---|---|
| P3 | [11, 11] | [14, 23] | [26, 13] |
| P4 | [24, 25] | [26, 47] | [47, 31] |
| P5 | [54, 55] | [94, 115] | [190, 192] |
| Models | YOLOv5 | YOLOv5 + K-Means++ |
|---|---|---|
| plane | 85.2 | 86.0 |
| baseball-diamond | 75.2 | 75.3 |
| bridge | 42.1 | 43.0 |
| ground-track-field | 57.2 | 56.8 |
| small-vehicle | 53.2 | 54.3 |
| large-vehicle | 75.2 | 78.1 |
| ship | 79.3 | 81.0 |
| tennis-court | 89.3 | 87.7 |
| basketball-court | 56.6 | 55.8 |
| storage-tank | 66.3 | 64.9 |
| soccer-ball-field | 50.3 | 47.1 |
| roundabout | 54.1 | 55.8 |
| harbour | 72.6 | 73.3 |
| swimming-pool | 53.3 | 60.2 |
| helicopter | 52.2 | 44.7 |
| [email protected] | 64.2 | 64.8 |
| Models | YOLOv5 | Ours (YOLOv5 + DDH) |
|---|---|---|
| plane | 85.2 | 91.0 |
| baseball-diamond | 75.2 | 71.2 |
| bridge | 42.1 | 44.9 |
| ground-track-field | 57.2 | 57.7 |
| small-vehicle | 53.2 | 57.1 |
| large-vehicle | 75.2 | 82.6 |
| ship | 79.3 | 83.1 |
| tennis-court | 89.3 | 92.4 |
| basketball-court | 56.6 | 59.9 |
| storage-tank | 66.3 | 67.9 |
| soccer-ball-field | 50.3 | 47.1 |
| roundabout | 54.1 | 55.8 |
| harbour | 72.6 | 82.0 |
| swimming-pool | 53.3 | 60.2 |
| helicopter | 52.2 | 38.2 |
| [email protected] | 64.2 | 67.6 |
| Models Attention Mechanisms | YOLOv5 + DDH No | SENet | YOLOv5 + DDH CBAM | CA |
|---|---|---|---|---|
| plane | 91.0 | 90.9 | 93.4 | 91.3 |
| baseball-diamond | 71.2 | 75.8 | 78.2 | 78.7 |
| bridge | 44.9 | 46.1 | 54.9 | 47.6 |
| ground-track-field | 57.7 | 64.8 | 68.2 | 67.5 |
| small-vehicle | 57.1 | 58.2 | 69.6 | 59.2 |
| large-vehicle | 82.6 | 80.4 | 86.0 | 83.2 |
| ship | 83.1 | 84.3 | 88.7 | 85.7 |
| tennis-court | 92.4 | 92.1 | 91.2 | 89.2 |
| basketball-court | 59.9 | 66.3 | 71.8 | 67.1 |
| storage-tank | 67.9 | 65.3 | 74.2 | 68.9 |
| soccer-ball-field | 47.1 | 54.6 | 55.5 | 55.6 |
| roundabout | 55.8 | 58.0 | 64.0 | 57.6 |
| harbour | 82.0 | 73.8 | 85.8 | 74.9 |
| swimming-pool | 60.2 | 60.7 | 61.0 | 58.6 |
| helicopter | 38.2 | 55.4 | 57.2 | 57.6 |
| [email protected] | 67.6 | 69.3 | 73.2 | 71.1 |
| Category | YOLOv5 | YOLOv5 for This Article |
|---|---|---|
| Aircraft | 79.9 | 95.1 |
| Airport | 73.3 | 87.9 |
| Baseball field | 72.1 | 94.9 |
| Basketball courts | 89.9 | 87.4 |
| Bridges | 46.4 | 60.3 |
| Chimneys | 80.7 | 92.0 |
| Service areas | 63.0 | 77.7 |
| Tollbooths | 66.6 | 77.8 |
| Dam | 48.9 | 75.8 |
| Golf course | 76.8 | 80.7 |
| Athletic fields | 73.5 | 84.4 |
| Ports | 57.2 | 70.7 |
| Highways | 58.8 | 70.9 |
| Boats | 91.1 | 95.0 |
| Stadiums | 60.3 | 93.3 |
| Storage Tanks | 79.6 | 86.4 |
| Tennis courts | 88.7 | 93.5 |
| Train station | 62.2 | 68.2 |
| Car | 61.5 | 81.9 |
| Windmill | 72.3 | 85.5 |
| [email protected] | 70.0 | 82.9 |
| Methods | mAP | Param (M) |
|---|---|---|
| RetinaNet | 0.675 | 36.7 |
| YOLOv5m | 0.642 | 21.2 |
| YOLOv5l | 0.740 | 46.5 |
| YOLOXm | 0.694 | 25.3 |
| Swin-YOLOv5 | 0.732 | - |
| SPH-YOLOv5 | 0.716 | - |
| Improved YOLOv5m for this article | 0.736 | 28.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Gong, W.; Shang, L.; Li, X.; Gong, Z. Remote Sensing Image Target Detection and Recognition Based on YOLOv5. Remote Sens. 2023, 15, 4459. https://doi.org/10.3390/rs15184459
Liu X, Gong W, Shang L, Li X, Gong Z. Remote Sensing Image Target Detection and Recognition Based on YOLOv5. Remote Sensing. 2023; 15(18):4459. https://doi.org/10.3390/rs15184459
Chicago/Turabian StyleLiu, Xiaodong, Wenyin Gong, Lianlian Shang, Xiang Li, and Zixiang Gong. 2023. "Remote Sensing Image Target Detection and Recognition Based on YOLOv5" Remote Sensing 15, no. 18: 4459. https://doi.org/10.3390/rs15184459
APA StyleLiu, X., Gong, W., Shang, L., Li, X., & Gong, Z. (2023). Remote Sensing Image Target Detection and Recognition Based on YOLOv5. Remote Sensing, 15(18), 4459. https://doi.org/10.3390/rs15184459