1. Introduction
The semantic segmentation of multiple objects in remote sensing images is of great significance in the field of remote sensing, which provides help for such work as urban planning, agricultural monitoring, and satellite navigation [
1]. Remote sensing images can provide information on segmented objects in different aspects, such as spectral latitude and spatial latitude. Therefore, remote sensing images often contain rich material, geometry, and spectral reflection information of target objects [
2]. On the one hand, these characteristics make it more difficult for semantic segmentation scholars to deal with remote sensing image information. On the other hand, they make the semantic segmentation of multi-place objects based on remote sensing images from multiple perspectives.
In the realm of remote sensing image semantic segmentation, numerous advanced techniques rooted in deep learning have been developed [
3]. Among these, U-Net, initially proposed by Olaf Ranneberger et al. [
4], stands out for its distinctive U-shaped structure and encoder–decoder concept. U-Net is renowned for its efficiency and high performance, serving as a foundational model upon which subsequent methods have been built. One such method is SegNet [
5], which employs a specialized decoder architecture incorporating maximum index information from the encoder. This innovation has yielded exceptional segmentation results, particularly on cost-effective hardware. Deeplab [
6], on the other hand, focuses on an encoder–decoder architecture that substantially expands the model’s receptive field. It enhances segmentation precision by introducing advanced components such as void convolution and spatial feature pyramids. Semantic segmentation often necessitates the extraction of global features. To address this need, researchers have proposed various methods. Zhou et al. [
7] introduced D-Linknet, which aggregates contextual information using multi-scale expansion rates. Eff-Unet++ [
8] adopted the EfficientNet-B4 architecture to replace U-Net’s encoder, along with redesigning the decoder’s jumping connections and residual components. This adaptation has improved feature extraction capabilities. For very-high-resolution (VHR) remote sensing images, Qiu et al. [
9] devised a refined U-Net with a specialized thinning jump connection scheme that incorporates an atrous spatial convolution pyramid pool (ASPP) module and several improved depth separable convolution (IDSC) modules. Jiao et al. [
10] developed Unet-V4, an end-to-end edge-accurate segmentation network tailored for capturing regions of interest with tight edges and potential shadow regions with blurred boundaries. References [
11,
12,
13] introduce the transformer into U-Net, showcasing the universality of the U-Net structure.
Attention mechanisms have played a pivotal role in effectively distinguishing and utilizing information, akin to the human visual attention system. SENet [
14] represents a notable application of attention mechanisms in computer vision. SENet introduces an SE module that predicts weight coefficients for each input channel, establishing a channel-wise attention module. This approach has delivered promising results, inspiring subsequent advancements. The integration of attention mechanisms in image segmentation has witnessed significant progress. Models like PSAnet [
15] incorporate spatial location-based attention modules, enabling better utilization of location-based information. The evolution of attention mechanisms continues, with DANet [
16] introducing dual self-attention, combining spatial and channel self-attention for enhanced global information acquisition. CBAM [
17] presents a lightweight, adaptable attention mechanism, while DA-Roadnet [
18] tailors attention mechanisms to the unique characteristics of road-related imagery. In the context of multispectral remote sensing images, particularly hyperspectral data, attention mechanisms have been leveraged to address the challenge of distinguishing between useful and irrelevant information. In hyperspectral imagery with high spectral but low spatial resolution, researchers have proposed spectral attention methods based on global convolution and spectral threshold weights [
19]. Multi-scale spectral attention (MSA) modules have been designed to reduce spectral redundancy and enhance discrimination capabilities [
20]. Furthermore, in multispectral image semantic segmentation, both spatial and spectral resolutions are frequently leveraged. Researchers have innovated by designing attention mechanisms tailored to spectral and spatial characteristics, effectively suppressing unnecessary information and focusing on critical details [
21,
22,
23,
24,
25]. Additionally, building spatial–spectral bidirectional networks using attention mechanisms has gained prominence [
26,
27]. In conclusion, this research underscores the critical role of attention mechanisms in advancing the accuracy of multiple object semantic segmentation in remote sensing imagery. These mechanisms have enabled the efficient extraction and utilization of information, thereby contributing to the development of sophisticated and high-performing models for a range of applications in this domain.
However, the construction of both the U-Net structure and self-attention mechanism depends on the extraction and processing of the internal information of the feature map, and the combination of input features to obtain the output features. This brings about the following two problems: Firstly, the output feature completely depends on the quality of the input feature extraction. If the input feature extraction is poor, the output feature cannot make up for it. Secondly, the self-attention mechanism is a characteristic dimension of attention, which cannot be visualized intuitively and has poor interpretability.
In order to improve the accuracy of semantic segmentation, another idea is to introduce external information. In a convolutional neural network, there are two main ways to introduce external information. One is to increase the input channel and directly input the external information into the model. The second is to add the loss function and introduce the additional loss function during the training of the model to calculate the distance between the intermediate quantity of the model and the external information. Y Zhang et al. [
28] segmented remote sensing images from the perspective of knowledge transfer and introduced semantic word vectors to help different styles of data achieve domain adaptation. The introduction of external information brings additional information to the model, which helps the model learn more general features. However, the external information is usually difficult to express and fully integrate into the existing deep learning model. In order to solve the above problems, Li et al. [
29] introduced label information by building LAM, transformed semantic labels into multi-channel binary semantic labels through one-hot code transformation, and calculated loss with the feature map. LAM is different from the self-attention mechanism in that it introduces external label information to optimize the generation of an attention probability map.
In addition to the improvement of network structure, many scholars have studied and discussed the remote sensing image data enhancement methods used in semantic segmentation. In common methods, remote sensing images are generally enhanced in spatial information, such as image rotation, cropping, scaling, adding noise, or HSV transformation. References [
30,
31,
32] introduced transpose, rotation, and other enhancement operations. In addition to the conventional enhancement operations, reference [
33] also uses enhancement methods such as mixup and cutup to further enhance the data diversity. However, the above image enhancement methods have such problems: Firstly, the general remote sensing image data enhancement is often only for the spatial dimension of the remote sensing image, ignoring the enhancement in the spectral dimension; Secondly, the parameters of remote sensing image rotation, HSV change, and other enhancement methods are often preset or randomly generated by random number function, which is independent of the deep learning network. Based on these problems, the idea is to build an adaptive and learnable spectral dimension data enhancement method to improve the robustness and accuracy of the network. This paper uses convolution to construct an adaptive spectral enhancement method. The original image of four channels is enhanced to 196 channel images, and the generated spectral enhancement results are constrained by LAM.
Reducing human–computer interaction is a critical research direction in various aspects, including image enhancement and the integration of additional information. However, there is still room for improvement in the accuracy of current deep learning multi-object segmentation methods. This limitation is primarily attributed to the insufficient utilization of spectral dimension information and external data. To enhance the accuracy of multi-objective semantic segmentation, fully exploit the spectral and spatial information present in remote sensing images, and integrate external information, we aim to develop an adaptive spectral enhancement method that enhances the network’s ability to explore diverse spectral information. Additionally, we adopt a comprehensive strategy of incorporating attention mechanisms into all aspects of the network to enhance its segmentation capabilities for different objects.
The main contributions of this paper are as follows:
The Channel Creator module (CCM) is creatively constructed. By imitating the means of image enhancement, an adaptive spectral enhancement method is introduced. CCM can expand the number of channels in the feature map and build spectral attention to give weight to the feature map, stimulate the channels containing useful information, suppress the channels with useless information, and enhance the ability of the network to extract and use the channel features.
Innovative use of attention mechanism and dense connection to build a two-way encoder. The Dual-Path Encoder is divided into two parts: channel encoder and spatial encoder. The channel encoder uses the channel attention mechanism to focus on the channel information of the feature map. The spatial encoder uses dense connection and spatial attention mechanism to extract multi-scale features. The two-way encoder improves the ability of the network to extract features of different scales and channels.
We optimized MQANet using the CCM and Dual-Path Encoder and built CD-MQANet. We also tested CD-MQANet on two public datasets. The experiment shows that the evaluation metrics of CD-MQANet are greatly improved compared with the baseline model MQANet, especially for low vegetation and tree types. The attention mechanism of CD-MQANet and some intermediate results are also visualized and interpretable.
2. Methods
Li et al. [
29] introduced MQANet, a network architecture that primarily focused on optimizing the decoder part of U-Net. They achieved this by replacing the original decoder with a multitasking decoder, which incorporated label attention, channel attention, spatial attention, and edge attention mechanisms. Compared to the traditional U-Net, MQANet demonstrated a significant improvement in segmentation accuracy. However, MQANet also exhibited certain shortcomings:
MQANet did not address optimization in the encoder part of the network, leading to a mismatch in the scales of the encoder and decoder components. As a result, the encoder failed to fully extract information from the original image, indicating a pressing need to enhance the network’s ability to extract valuable information from the input image.
The contribution of the edge attention mechanism in MQANet towards improving network accuracy was found to be relatively insignificant, and its implementation introduced complexity, requiring additional label preprocessing. Consequently, there is an urgent requirement for more effective attention mechanisms.
Based on the strengths and weaknesses of MQANet, this paper introduces the Channel Creator module (CCM) and the Dual-Path Encoder module, with a primary focus on optimizing the encoder part of the network to enhance segmentation accuracy.
2.1. Architecture of CD-MQANet
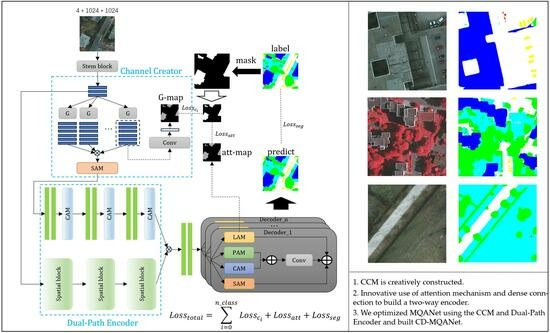
To fully exploit and utilize spectral feature information and focus on the information contained in multispectral images from both spatial and spectral dimensions, we constructed CD-MQANet, where “C” represents the Channel Creator module, and “D” represents the Dual-Path Encoder.
The network structure of CD-MQANet is shown in
Figure 1. First of all, in order to save the information of the feature map as much as possible and reduce the size of the feature map, we first send the original image to the stem block. The structure of the stem block is one layer of
convolution (stride size is 2), two layers of
convolution (stride size is 1), and one layer of average pooling. The main purpose of stem block is to perform a preliminary feature extraction on the original image and reduce the size of the feature map to 1/4 of the original size, saving the calculation cost. After passing through stem block, the original image will become a 16-channel feature map, which will enter two different branches. One of the branches will enter the Channel Creator module (CCM). The CCM mainly includes two parts: spectral generator and spectral attention module. The spectral generator aims to generate spectral channels that can expand the spectral characteristics of different types of ground objects. Each type will generate 32-channel feature maps according to the original category, and then the generated feature maps will calculate loss with the labels of this type of ground objects to constrain the generation of feature maps. The main task of the spectral attention module is to generate a spectral threshold, enhance useful spectral channels, and suppress useless spectral channels. The spectral-enhanced feature map will enter the Dual-Path Encoder together with the original feature map extracted by stem block. The spectral-enhanced feature map will enter the channel feature extraction branch of the Dual-Path Encoder, and the original feature map will enter the spatial feature extraction branch of the Dual-Path Encoder. The features extracted by the two-way encoder will be sent to the multi-head attention decoder for decoding after fusion. Finally, the overall loss of the network will consist of three parts: the
generated by G-map and label,
generated by LAM in decoder part, and
generated by prediction results and label calculation.
2.2. Channel Creator Module
Figure 2 shows the structure of the Channel Creator module (CCM). The CCM mainly consists of two parts. The first part is composed of N generator blocks (n is the type of objects in the remote sensing image), and the second part is spectral attention. The CCM hopes to generate the corresponding enhanced spectral channels according to different types of objects through the generator block and suppress the generated useless information and enhance the useful information through spectral attention.
Generator block has such an idea. In fact, multispectral images are superimposed by gray images of multiple bands in the channel direction. The main difference between gray images of different bands is that the gray values of different pixels are different. Therefore, we consider generating different bands through the change in gray values. The generate operation can be defined as the equation:
where
represents the original feature map and α, β, γ are three parameters. It should be noted that, the three parameters in
can be optimized by back propagation. The generator block first generates a new layer for each layer of the input feature map according to the
transform, and then performs two times of double convolution to obtain the feature map after spectral enhancement for this kind of ground object. In order to constrain the bands generated by the generator, we also convolute the generated bands to 1 channel and calculate the cross-entropy loss with the label of this category object. Generator block is constructed to enhance the channel information of different types of objects by using the above methods and make the enhanced information relatively reliable by calculating loss.
The generator block of the n classes feature map will generate times the number of channels of the original feature map. Although we have used the loss function to constrain the spectral enhancement, we still cannot guarantee that such a large number of spectral channels all contain useful information. In order to solve this problem, we constructed spectral attention. Spectral attention hopes to generate a spectral threshold weight from the global information of the feature map to screen the spectral channels, gain the channels with effective information, and suppress the channels with invalid or even interfering information. Spectral attention consists of a max pooling, a global 2-D convolution layer, and two 1-D convolution layers. In order to reduce the amount of calculation, spectral attention first pools the maximum value of the feature map, and then performs 2-D global convolution, that is, the size of the convolution kernel is consistent with the H and W of the feature map. After global convolution, the feature map will become one-dimensional, which corresponds to the thresholds of different spectral channels. After two one-dimensional convolutions, the spectral threshold is multiplied by the feature map of input spectral attention to obtain the constrained feature map.
2.3. Dual-Path Encoder
The Dual-Path Encoder is mainly composed of two parts. The first part is the channel encoder including the channel attention and double conv, and the second part is the spatial encoder including the spatial attention mechanism and dense block. The Dual-Path Encoder hopes to explore the channel dimension feature information to a greater extent on the basis of the feature map after spectral expansion and retain the spatial dimension feature information of the original feature map. Based on this idea, the input of each branch of the Dual-Path Encoder is also different: the input of the channel encoder is the output result of the CCM. The input of the spatial encoder is the original feature map output by stem block.
The channel encoder receives the spectral-enhanced feature map output by the CCM, so we use the structure of superimposed three-layer double convolution and channel attention module on this branch to further extract and enhance the channel information. The structure of the channel attention module is shown in
Figure 3. In CAM, the input feature map passes through two branches, one of which will be used as Q and K to generate C× C attention probability map. In the other branch, it is used as V. Among them, V, Q, and K represent value features, query features, and key features, respectively; C, H, and W, respectively, represent the channel, height, and width of the feature map. The overall structure of cam can be expressed by the following Equations (2) and (3):
where subscript represents the shape of corresponding graph,
represents the weight chart of the last output,
represents the original feature map of input channel self-attention,
represents changes to the characteristic diagram shape of
.
The main function of the spatial encoder is to retain the original feature map information and extract more spatial information at the same time. Therefore, the structure of the channel encoder is three-layer spatial block that contains dense block and spatial attention mechanism. The structure of the spatial block is shown in
Figure 4. In the dense block, the structure of the first n layers is set to BN-relu-conv (1 × 1) -bn-relu-conv (3 × 3, stride = 1). After that, an additional three-layer dilated convolution is added, and the structure of the three-layer dilated convolution is set as: BN-relu-conv (1 × 1) -bn-relu-Dconv (3 × 3, stride = 2, or 4, or 8). After passing through a dense block, the number of channels in the characteristic graph will increase by
layers. Among them, K is called growth rate. Dense block encourages feature reuse, sends the feature map extracted from the previous convolution layer to the subsequent convolution layer for operation, and introduces three-layer dilated convolution to enhance the receptive field of the network. The spatial encoder hopes to use the combination of ordinary convolution and dilated convolution to improve the ability of the network to obtain local and global spatial information and use the mechanism of feature reuse to improve the ability of the network to obtain and use spatial information at different scales.
In PAM, the input characteristic graph passes through two branches, one of which will be generated as Q and K (H × W) × (H × W) Attention probability map. In the other branch, it is used as v. Among them, V, Q, and K represent value features, query features, and key features, respectively; C. H and W, respectively, represent the channel, height, and width of the feature map. The spatial encoder combines the dense block and spatial attention to fully extract the spatial feature information of different scales in the feature map while maintaining the original feature information, so as to improve the ability of the network to extract local and global spatial features.
2.4. Multi-Task Decoder and Label Attention
Self-attention mechanism helps to improve the accuracy of large-scale goals. However, there are some similarities in color features and texture features between some ground object types. For example, some leafless trees are very similar to low vegetation, which is easy to cause misjudgment of the network. In order to reduce the miscarriage of justice between similar objects, it is necessary to find the causes of miscarriage of justice. After analyzing the structure of the network model, it is found that in the traditional encoder–decoder structure, a decoder generates multiple outputs through the softmax function. However, the characteristics of different categories differ greatly, and each category will contribute to the parameter update during training, but the parameter optimization directions of different categories may be different, resulting in competition and mutual restriction between categories. In order to solve this problem, this paper introduces multitask learning, which transforms a multi-classification semantic segmentation problem into a multi-binary classification semantic segmentation problem, so as to avoid the competition between different categories of parameters.
Aiming at the problem of multi-classification feature extraction in this paper, the decoder part of the multitask learning model is modified, and a multi-decoder quadruple attention model based on multitasking is constructed, which transforms a multi-classification semantic segmentation problem into a multi-binary classification semantic segmentation problem. Each category constructs a decoder separately. The decoder is composed of multiple attention modules, and each decoder only focuses on the corresponding category, there is no need to consider the characteristics of other categories, thus reducing the competitive relationship between categories. We construct the decoder to echo the attention mechanism used by the encoder: in the encoder, the spatial, channel, and spectral dimensions are weighted with attention, and we hope to build a similar weighting mechanism in the decoder. In order to introduce the external label information, it is necessary to construct additional attention mechanism, so as to form a quadruple attention decoder together with the first three attention.
In addition, another important way to solve the problem of misjudgment is to introduce external information. This paper chooses to use the method of introducing label attention to build the external information acquisition module of the network. In the common attention mechanism, the attention probability map can be expressed as a two-dimensional matrix, while in the label attention mechanism, in order to introduce additional semantic information, the attention probability map is expressed as a multi-channel two-dimensional matrix, and the number of channels is consistent with the number of semantic categories. Because the final task is to complete the semantic segmentation of the image, each semantic channel pays attention to different information, and the information that each channel pays most attention to is the area covered by the channel’s feature types. Therefore, when the attention probability map is more similar to the semantic labels, the final semantic classification results can also be more similar to the labels. The semantic label is transformed into a multi-channel binary semantic label from a single-channel gray-scale semantic label through one-hot code transformation. The number of channels is the same as the number of categories. The two-dimensional matrix and the attention map are kept the same size through down-sampling, and the loss function of the generated attention probability map and the real down-sampling label can be calculated.
Based on the above ideas, combined with the attention mechanism, the following modules can be constructed, as shown in
Figure 5 structure of LAM. As the number of channels in the attention probability map increases, the attention probability map is no longer obtained by the multiplication of Q and K points, but by the direct convolution of input features. Similarly, the calculation method of the output result is also changed. The final output result is obtained by convolution of the attention output and the original input.
2.5. Loss Function
General deep learning segmentation methods often only calculate the loss for the segmentation results and labels and use this loss to update the parameters of the deep learning network. Unlike general deep learning multi-object segmentation models, the final loss of this article consists of three parts: the G-map generated by the CCM and the loss 1 calculated by the single class object label, the loss 2 calculated by the LAM and label unique heat code, and the final segmentation result and the loss 3 calculated by the label. The calculation method is as Equations (4)–(7):
It can be seen from the above formula that the cross-entropy loss is used in the loss function constructed by each part. Among them, stands for GMap, label generated by class i figure CCM, stands for the label of class i figure. Att-map is the attention map generated by LAM. is the one-hot form of the label.
6. Conclusions
To enhance the accuracy of multi-objective semantic segmentation in remote sensing images, we proposed CD-MQANet. To fully exploit the distinctions in channel information among different features, we introduced the CCM module. CCM aims to establish an adaptive channel dimension augmentation method that combines traditional digital image processing techniques and convolutions. This enhancement enhances the network’s capacity to discover channel dimension features and information. Additionally, we constructed a spectral attention mechanism within CCM, employing global convolution to generate spectral threshold weights. This mechanism enhances valuable spectral information while suppressing irrelevant spectral data.
Furthermore, we designed a Dual-Path Encoder to balance the extraction of channel and spatial information. The Dual-Path Encoder comprises a channel encoder and a spatial encoder. The channel encoder utilizes the channel attention mechanism to further extract channel information from feature maps. The spatial encoder employs dense connections and spatial attention to enhance the network’s ability to utilize multi-scale spatial features, improving the network’s capability to capture spatial information at various scales. This Dual-Path Encoder enhances the network’s ability to extract and utilize information from the different scales and dimensions of feature maps.
Based on these two modules, we constructed CD-MQANet, and experimental results demonstrated its superiority. We used two datasets to verify the model’s accuracy. In the Vaihingen dataset, CD-MQANet outperformed the baseline MQANet by increasing mean F1 and OA by 2.03% and 2.49%, respectively. In the Potsdam dataset, CD-MQANet improved mean F1 and OA by 1.25% and 1.42%, respectively, compared to the baseline MQANet. Extensive experiments showed that CD-MQANet surpassed other methods in terms of evaluation metrics on the Vaihingen and Potsdam datasets. These results highlight the substantial accuracy improvements of the proposed model (CD-MQANet) in both F1 and OA metrics. The CCM and Dual-Path Encoder contribute significantly to the semantic segmentation of remote sensing images. We also generated an attention heatmap and analyzed the role of the attention mechanism in the network. The results demonstrated that the introduced attention mechanism correctly focuses on different terrain objects and to some extent corrects misclassified terrain objects. Finally, we analyzed the intermediate results generated by CCM and LAM, showcasing their interpretability by calculating loss with labels.
However, it should be noted that CD-MQANet, as proposed in this article, is designed for classifying remote sensing images of six types of land objects and may lack universality across datasets. Additionally, the loss function used by CCM is simply determined as cross-entropy. In future research, we plan to explore more effective loss functions.



 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}