
Estimation and Mapping of Soil Organic Matter Content Using a Stacking Ensemble Learning Model Based on Hyperspectral Images

Abstract
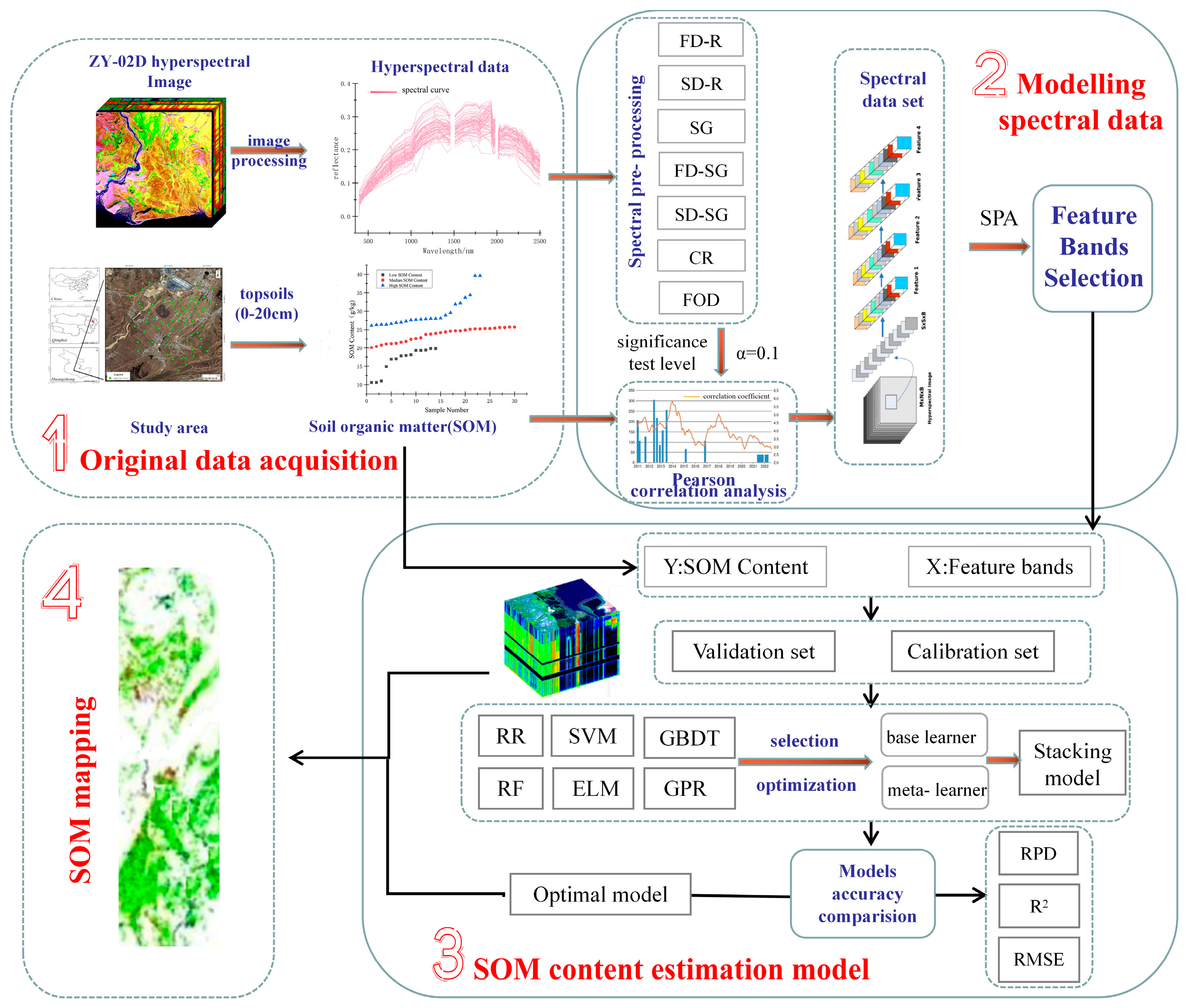
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data Processing
2.2.1. Soil Sample Selection and Chemical Analysis
2.2.2. Image Data Pre-Processing
2.2.3. Boundary Extraction of Farmland
2.3. Methods
2.3.1. Feature Selection
2.3.2. Estimation Model
2.3.3. Estimation Accuracy Indexes
3. Results
3.1. Spectral Pre-Processing and Acquisition of Modeling Data
3.2. SOM Content Estimation Based on the Stacking Model
3.3. SOM Estimation Result and Analyze
3.4. SOM Estimation from the Hyperspectral Images
4. Discussion
4.1. Comparison of Different Spectral Pre-Processing Treatments
4.2. Analysis of the Effect of Combining Multiple Learning Models
4.3. Estimation Model Accuracy Improvement and the Uncertainty Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, T.; Mu, T.; Liu, G.; Yang, X.; Zhu, G.; Shang, C. A Method of Soil Moisture Content Estimation at Various Soil Organic Matter Conditions Based on Soil Reflectance. Remote Sens. 2022, 14, 2411. [Google Scholar] [CrossRef]
- Yuan, Y.; Li, B.; Yu, W.; Gao, X. Estimation and Mapping of Soil Organic Matter Content at a National Scale Based on Grid Soil Samples, a Soil Map and DEM Data. Ecol. Inform. 2021, 66, 101487. [Google Scholar] [CrossRef]
- Hu, W.; Shen, Q.; Zhai, X.; Du, S.; Zhang, X. Impact of Environmental Factors on the Spatiotemporal Variability of Soil Organic Matter: A Case Study in a Typical Small Mollisol Watershed of Northeast China. J. Soils Sediments 2021, 21, 736–747. [Google Scholar] [CrossRef]
- Liu, X.; Dou, S.; Zheng, S. Effects of Corn Straw and Biochar Returning to Fields Every Other Year on the Structure of Soil Humic Acid. Sustainability 2022, 14, 15946. [Google Scholar] [CrossRef]
- Gao, L.; Zhu, X.; Han, Z.; Wang, L.; Zhao, G.; Jiang, Y. Spectroscopy-Based Soil Organic Matter Estimation in Brown Forest Soil Areas of the Shandong Peninsula, China. Pedosphere 2019, 29, 810–818. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, J.; Liu, G.; Yang, Y.; Liu, Z.; Deng, H. Hyperspectral Estimation Model of Forest Soil Organic Matter in Northwest Yunnan Province, China. Forests 2019, 10, 217. [Google Scholar] [CrossRef]
- Mulla, D.J. Twenty Five Years of Remote Sensing in Precision Agriculture: Key Advances and Remaining Knowledge Gaps. Biosyst. Eng. 2013, 114, 358–371. [Google Scholar] [CrossRef]
- Wang, F.; Gao, J.; Zha, Y. Hyperspectral Sensing of Heavy Metals in Soil and Vegetation: Feasibility and Challenges. ISPRS J. Photogramm. 2018, 136, 73–84. [Google Scholar] [CrossRef]
- Mehl, P.M.; Chen, Y.-R.; Kim, M.S.; Chan, D.E. Development of Hyperspectral Imaging Technique for the Detection of Apple Surface Defects and Contaminations. J. Food Eng. 2004, 61, 67–81. [Google Scholar] [CrossRef]
- Galvão, L.S.; Vitorello, Í. Variability of Laboratory Measured Soil Lines of Soils from Southeastern Brazil. Remote Sens. Environ. 1998, 63, 166–181. [Google Scholar] [CrossRef]
- Serbin, G.; Daughtry, C.S.T.; Hunt, E.R.; Reeves, J.B.; Brown, D.J. Effects of Soil Composition and Mineralogy on Remote Sensing of Crop Residue Cover. Remote Sens. Environ. 2009, 113, 224–238. [Google Scholar] [CrossRef]
- Choe, E.; van der Meer, F.; van Ruitenbeek, F.; van der Werff, H.; de Smeth, B.; Kim, K.-W. Mapping of Heavy Metal Pollution in Stream Sediments Using Combined Geochemistry, Field Spectroscopy, and Hyperspectral Remote Sensing: A Case Study of the Rodalquilar Mining Area, SE Spain. Remote Sens. Environ. 2008, 112, 3222–3233. [Google Scholar] [CrossRef]
- Sun, W.; Liu, S.; Zhang, X.; Li, Y. Estimation of Soil Organic Matter Content Using Selected Spectral Subset of Hyperspectral Data. Geoderma 2022, 409, 115653. [Google Scholar] [CrossRef]
- Angelopoulou, T.; Chabrillat, S.; Pignatti, S.; Milewski, R.; Karyotis, K.; Brell, M.; Ruhtz, T.; Bochtis, D.; Zalidis, G. Evaluation of Airborne HySpex and Spaceborne PRISMA Hyperspectral Remote Sensing Data for Soil Organic Matter and Carbonates Estimation. Remote Sens. 2023, 15, 1106. [Google Scholar] [CrossRef]
- Guo, L.; Zhang, H.; Shi, T.; Chen, Y.; Jiang, Q.; Linderman, M. Prediction of Soil Organic Carbon Stock by Laboratory Spectral Data and Airborne Hyperspectral Images. Geoderma 2019, 337, 32–41. [Google Scholar] [CrossRef]
- Nanni, M.R.; Demattê, J.M.; Rodrigues, M.; Santos, G.L.; Reis, A.S.; de Oliveira, K.M.; Cezar, E.; Furlanetto, R.H.; Crusiol, L.G.T.; Sun, L. Mapping Particle Size and Soil Organic Matter in Tropical Soil Based on Hyperspectral Imaging and Non-Imaging Sensors. Remote Sens. 2021, 13, 1782. [Google Scholar] [CrossRef]
- Zhao, L.; Tan, K.; Wang, X.; Ding, J.; Liu, Z.; Ma, H.; Han, B. Hyperspectral Feature Selection for SOM Prediction Using Deep Reinforcement Learning and Multiple Subset Evaluation Strategies. Remote Sens. 2022, 15, 127. [Google Scholar] [CrossRef]
- Reis, A.S.; Rodrigues, M.; Alemparte Abrantes Dos Santos, G.; Mayara De Oliveira, K.; Furlanetto, R.; Teixeira Crusiol, L.G.; Cezar, E.; Nanni, M.R. Detection of Soil Organic Matter Using Hyperspectral Imaging Sensor Combined with Multivariate Regression Modeling Procedures. Remote Sens. Appl. 2021, 22, 100492. [Google Scholar] [CrossRef]
- Meng, X.; Bao, Y.; Ye, Q.; Liu, H.; Zhang, X.; Tang, H.; Zhang, X. Soil Organic Matter Prediction Model with Satellite Hyperspectral Image Based on Optimized Denoising Method. Remote Sens. 2021, 13, 2273. [Google Scholar] [CrossRef]
- Yanli, L.; Youlu, B.; Liping, Y.; Hongjuan, W. Hyperspectral Extraction of Soil Organic Matter Content Based on Principal Component Regression. N. Z. J. Agric. Res. 2007, 50, 1169–1175. [Google Scholar] [CrossRef]
- Gomez, C.; Lagacherie, P.; Coulouma, G. Regional Predictions of Eight Common Soil Properties and Their Spatial Structures from Hyperspectral Vis–NIR Data. Geoderma 2012, 189–190, 176–185. [Google Scholar] [CrossRef]
- Tan, K.; Wang, H.; Chen, L.; Du, Q.; Du, P.; Pan, C. Estimation of the Spatial Distribution of Heavy Metal in Agricultural Soils Using Airborne Hyperspectral Imaging and Random Forest. J. Hazard. Mater. 2020, 382, 120987. [Google Scholar] [CrossRef]
- Rocha Neto, O.; Teixeira, A.; Leão, R.; Moreira, L.; Galvão, L. Hyperspectral Remote Sensing for Detecting Soil Salinization Using ProSpecTIR-VS Aerial Imagery and Sensor Simulation. Remote Sens. 2017, 9, 42. [Google Scholar] [CrossRef]
- Arif, M.; Qi, Y.; Dong, Z.; Wei, H. Rapid Retrieval of Cadmium and Lead Content from Urban Greenbelt Zones Using Hyperspectral Characteristic Bands. J. Clean. Prod. 2022, 374, 133922. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Latifi, H.; Ghosh, A.; Joshi, P.K.; Koch, B. Assessing the Potential of Hyperspectral Imagery to Map Bark Beetle-Induced Tree Mortality. Remote Sens. Environ. 2014, 140, 533–548. [Google Scholar] [CrossRef]
- Chang, R.; Chen, Z.; Wang, D.; Guo, K. Hyperspectral Remote Sensing Inversion and Monitoring of Organic Matter in Black Soil Based on Dynamic Fitness Inertia Weight Particle Swarm Optimization Neural Network. Remote Sens. 2022, 14, 4316. [Google Scholar] [CrossRef]
- Lin, N.; Jiang, R.; Li, G.; Yang, Q.; Li, D.; Yang, X. Estimating the Heavy Metal Contents in Farmland Soil from Hyperspectral Images Based on Stacked AdaBoost Ensemble Learning. Ecol. Indic. 2022, 143, 109330. [Google Scholar] [CrossRef]
- Wu, M.; Lin, N.; Li, G.; Liu, H.; Li, D. Hyperspectral Estimation of Petroleum Hydrocarbon Content in Soil Using Ensemble Learning Method and LASSO Feature Extraction. Environ. Pollut. Bioavail. 2022, 34, 308–320. [Google Scholar] [CrossRef]
- Vicente, L.E.; de Souza Filho, C.R. Identification of Mineral Components in Tropical Soils Using Reflectance Spectroscopy and Advanced Spaceborne Thermal Emission and Reflection Radiometer (ASTER) Data. Remote Sens. Environ. 2011, 115, 1824–1836. [Google Scholar] [CrossRef]
- Sun, X.; Qu, Y.; Gao, L.; Sun, X.; Qi, H.; Zhang, B.; Shen, T. Ensemble-Based Information Retrieval with Mass Estimation for Hyperspectral Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5508123. [Google Scholar] [CrossRef]
- Krawczyk, B.; Minku, L.L.; Cheng, J.; Stefanowski, J.; Woźniak, M. Ensemble Learning for Data Stream Analysis: A Survey. Inform. Fusion 2017, 37, 132–156. [Google Scholar] [CrossRef]
- Wang, G.; Hao, J.; Ma, J.; Jiang, H. A Comparative Assessment of Ensemble Learning for Credit Scoring. Expert Syst. Appl. 2011, 38, 223–230. [Google Scholar] [CrossRef]
- Shu, C.; Burn, D.H. Artificial Neural Network Ensembles and Their Application in Pooled Flood Frequency Analysis: Artificial Neural Network Ensembles. Water Resour. Res. 2004, 40, W09301. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Schmidt, K.; Amirian-Chakan, A.; Rentschler, T.; Zeraatpisheh, M.; Sarmadian, F.; Valavi, R.; Davatgar, N.; Behrens, T.; Scholten, T. Improving the Spatial Prediction of Soil Organic Carbon Content in Two Contrasting Climatic Regions by Stacking Machine Learning Models and Rescanning Covariate Space. Remote Sens. 2020, 12, 1095. [Google Scholar] [CrossRef]
- Tan, K.; Ma, W.; Chen, L.; Wang, H.; Du, Q.; Du, P.; Yan, B.; Liu, R.; Li, H. Estimating the Distribution Trend of Soil Heavy Metals in Mining Area from HyMap Airborne Hyperspectral Imagery Based on Ensemble Learning. J. Hazard. Mater. 2021, 401, 123288. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, X.; Sun, W.; Wang, J.; Ding, S.; Liu, S. Effects of Hyperspectral Data with Different Spectral Resolutions on the Estimation of Soil Heavy Metal Content: From Ground-Based and Airborne Data to Satellite-Simulated Data. Sci. Total Environ. 2022, 838, 156129. [Google Scholar] [CrossRef]
- Han, T. Design and Application of Multicolor Image Identification in Soil Pollution Component Detection. Arab. J. Geosci. 2020, 13, 905. [Google Scholar] [CrossRef]
- Zhang, S.; Shen, Q.; Nie, C.; Huang, Y.; Wang, J.; Hu, Q.; Ding, X.; Zhou, Y.; Chen, Y. Hyperspectral Inversion of Heavy Metal Content in Reclaimed Soil from a Mining Wasteland Based on Different Spectral Transformation and Modeling Methods. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 211, 393–400. [Google Scholar] [CrossRef]
- Chen, T.; Chang, Q.; Clevers, J.G.P.W.; Kooistra, L. Rapid Identification of Soil Cadmium Pollution Risk at Regional Scale Based on Visible and Near-Infrared Spectroscopy. Environ. Pollut. 2015, 206, 217–226. [Google Scholar] [CrossRef]
- Cui, Y.; Meng, F.; Fu, P.; Yang, X.; Zhang, Y.; Liu, P. Application of Hyperspectral Analysis of Chlorophyll a Concentration Inversion in Nansi Lake. Ecol. Inform. 2021, 64, 101360. [Google Scholar] [CrossRef]
- Hasan, U.; Jia, K.; Wang, L.; Wang, C.; Shen, Z.; Yu, W.; Sun, Y.; Jiang, H.; Zhang, Z.; Guo, J.; et al. Retrieval of Leaf Chlorophyll Contents (LCCs) in Litchi Based on Fractional Order Derivatives and VCPA-GA-ML Algorithms. Plants 2023, 12, 501. [Google Scholar] [CrossRef]
- Shen, L.; Gao, M.; Yan, J.; Li, Z.; Leng, P.; Yang, Q.; Duan, S. Hyperspectral Estimation of Soil Organic Matter Content Using Different Spectral Preprocessing Techniques and PLSR Method. Remote Sens. 2020, 12, 1206. [Google Scholar] [CrossRef]
- Yan, B.; Wang, R.; Gan, F.; Wang, Z. Minerals Mapping of the Lunar Surface with Clementine UVVIS/NIR Data Based on Spectra Unmixing Method and Hapke Model. Icarus 2010, 208, 11–19. [Google Scholar] [CrossRef]
- Qiu, B.; Zhang, K.; Tang, Z.; Chen, C.; Wang, Z. Developing Soil Indices Based on Brightness, Darkness, and Greenness to Improve Land Surface Mapping Accuracy. GISci. Remote Sens. 2017, 54, 759–777. [Google Scholar] [CrossRef]
- Vaudour, E.; Gomez, C.; Lagacherie, P.; Loiseau, T.; Baghdadi, N.; Urbina-Salazar, D.; Loubet, B.; Arrouays, D. Temporal Mosaicking Approaches of Sentinel-2 Images for Extending Topsoil Organic Carbon Content Mapping in Croplands. Int. J. Appl. Earth Obs. 2021, 96, 102277. [Google Scholar] [CrossRef]
- Zhao, H.; Chen, X.; Zhang, Z.; Zhou, Y. Exploring an Efficient Sandy Barren Index for Rapid Mapping of Sandy Barren Land from Landsat TM/OLI Images. Int. J. Appl. Earth Obs. 2019, 80, 38–46. [Google Scholar] [CrossRef]
- Zou, X.; Zhao, J.; Povey, M.J.W.; Mel, H.; Mao, H. Variables Selection Methods in Near-Infrared Spectroscopy. Anal. Chim. Acta 2010, 667, 14–32. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.-W.; Han, Z.; Pham, B.T. Improved Landslide Assessment Using Support Vector Machine with Bagging, Boosting, and Stacking Ensemble Machine Learning Framework in a Mountainous Watershed, Japan. Landslides 2020, 17, 641–658. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Soft. 2010, 33, 1–22. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From Local Explanations to Global Understanding with Explainable AI for Trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Tang, J.; Liang, J.; Han, C.; Li, Z.; Huang, H. Crash Injury Severity Analysis Using a Two-Layer Stacking Framework. Accident Anal. Prev. 2019, 122, 226–238. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Liu, M.; Sima, Z. A Novel Cryptocurrency Price Trend Forecasting Model Based on LightGBM. Financ. Res. Lett. 2020, 32, 101084. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random Forests for Classification in Ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef] [PubMed]
- Svetnik, V.; Liaw, A.; Tong, C.; Culberson, J.C.; Sheridan, R.P.; Feuston, B.P. Random Forest: A Classification and Regression Tool for Compound Classification and QSAR Modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random Forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Huang, G.; Huang, G.; Song, S.; You, K. Trends in Extreme Learning Machines: A Review. Neural Netw. 2015, 61, 32–48. [Google Scholar] [CrossRef]
- Zhu, Q.; Qin, A.K.; Suganthan, P.N.; Huang, G. Evolutionary Extreme Learning Machine. Pattern Recogn. 2005, 38, 1759–1763. [Google Scholar] [CrossRef]
- Huang, G.; Zhu, Q.; Siew, C.-K. Extreme Learning Machine: Theory and Applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Rossel, R.A.V.; Behrens, T. Using Data Mining to Model and Interpret Soil Diffuse Reflectance Spectra. Geoderma 2010, 158, 46–54. [Google Scholar] [CrossRef]
- Marquand, A.; Howard, M.; Brammer, M.; Chu, C.; Coen, S.; Mourão-Miranda, J. Quantitative Prediction of Subjective Pain Intensity from Whole-Brain FMRI Data Using Gaussian Processes. NeuroImage 2010, 49, 2178–2189. [Google Scholar] [CrossRef]
- Verrelst, J.; Rivera, J.P.; Veroustraete, F.; Muñoz-Marí, J.; Clevers, J.G.P.W.; Camps-Valls, G.; Moreno, J. Experimental Sentinel-2 LAI Estimation Using Parametric, Non-Parametric and Physical Retrieval Methods—A Comparison. ISPRS J. Photogramm. 2015, 108, 260–272. [Google Scholar] [CrossRef]
- Frank, I.E.; Friedman, J.H. A Statistical View of Some Chemometrics Regression Tools. Technometrics 1993, 35, 109–135. [Google Scholar] [CrossRef]
- Hong, Y.; Liu, Y.; Chen, Y.; Liu, Y.; Yu, L.; Liu, Y.; Cheng, H. Application of Fractional-Order Derivative in the Quantitative Estimation of Soil Organic Matter Content through Visible and near-Infrared Spectroscopy. Geoderma 2019, 337, 758–769. [Google Scholar] [CrossRef]
- Gu, X.; Wang, Y.; Sun, Q.; Yang, G.; Zhang, C. Hyperspectral Inversion of Soil Organic Matter Content in Cultivated Land Based on Wavelet Transform. Comput. Electron. Agric. 2019, 167, 105053. [Google Scholar] [CrossRef]
- Zhang, Z.; Ding, J.; Zhu, C.; Wang, J. Combination of Efficient Signal Pre-Processing and Optimal Band Combination Algorithm to Predict Soil Organic Matter through Visible and near-Infrared Spectra. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 240, 118553. [Google Scholar] [CrossRef]
- Davari, M.; Karimi, S.; Bahrami, H.; Taher Hossaini, S.M.; Fahmideh, S. Simultaneous Prediction of Several Soil Properties Related to Engineering Uses Based on Laboratory Vis-NIR Reflectance Spectroscopy. CATENA 2021, 197, 104987. [Google Scholar] [CrossRef]
- Cui, S.; Yin, Y.; Wang, D.; Li, Z.; Wang, Y. A Stacking-Based Ensemble Learning Method for Earthquake Casualty Prediction. Appl. Soft. Comput. 2021, 101, 107038. [Google Scholar] [CrossRef]
- He, Y.; Xiao, J.; An, X.; Cao, C.; Xiao, J. Short-Term Power Load Probability Density Forecasting Based on GLRQ-Stacking Ensemble Learning Method. Int. J. Electr. Power. 2022, 142, 108243. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 | Number Minimum Maximum Mean value Standard Deviation Variation Coefficient | 67 10.6 (g/kg) 39.6 (g/kg) 24.16 (g/kg) 5.57 22.94% |
| Transformation | -- | FD-R | SD-R | SG | FD-SG | SD-SG | CR | FOD |
|---|---|---|---|---|---|---|---|---|
| Pearson calculation result | Maximum | −0.659 | 0.662 | −0.581 | 0.715 | 0.682 | 0.633 | −0.783 |
| Corresponding band | 1947 | 1964 | 1812 | 1964 | 1930 | 1274 | 2434 | |
| Number of sensitive bands | 16 | 10 | 18 | 17 | 16 | 8 | 25 |
| Model | Hyperparameters | RMSE |
|---|---|---|
| RF | n_estimators = 100, max_depth = 5 | 2.671 |
| GBDT | learning_rate = 0.01, subsample = 0.9, n_estimators = 200, max_depth = 3 | 3.091 |
| ELM | number of neuron nodes = 10, wi = 3 | 3.023 |
| SVM | kernel = ‘rbf’, gamma = auto, C = 10 | 3.222 |
| GPR | kernel = ‘rbf’, alpha = fioat, random_satate = int | 3.165 |
| RR | alpha = 1.0 | 3.239 |
| Model | RC2 | RMSEC | RP2 | RMSEP | RPD | |
|---|---|---|---|---|---|---|
| SOM estimation result | RF | 0.902 | 1.55 | 0.785 | 2.671 | 2.09 |
| GBDT | 0.831 | 1.945 | 0.734 | 3.091 | 1.85 | |
| ELM | 0.763 | 2.004 | 0.683 | 3.023 | 1.84 | |
| SVM | 0.754 | 2.154 | 0.657 | 3.222 | 1.73 | |
| GPR | 0.683 | 3.365 | 0.545 | 3.165 | 1.76 | |
| RR | 0.691 | 1.032 | 0.513 | 3.239 | 1.72 | |
| Stacking | 0.882 | 0.608 | 0.829 | 1.953 | 2.85 |
| Spectral Transformation | Algorithm | Bands | RC2 | RMSEC | RP2 | RMSEP | RPD |
|---|---|---|---|---|---|---|---|
| FD-R | Stacking | 16 | 0.861 | 1.365 | 0.741 | 2.611 | 2.13 |
| SD-R | Stacking | 10 | 0.804 | 1.442 | 0.725 | 2.862 | 1.95 |
| SG | Stacking | 18 | 0.754 | 2.158 | 0.553 | 3.855 | 1.44 |
| FD-SG | Stacking | 17 | 0.854 | 1.156 | 0.753 | 2.652 | 2.10 |
| SD-SG | Stacking | 16 | 0.857 | 1.952 | 0.736 | 2.493 | 2.23 |
| CR | Stacking | 8 | 0.835 | 1.789 | 0.713 | 4.112 | 1.35 |
| FOD | Stacking | 25 | 0.878 | 0.896 | 0.802 | 2.323 | 2.40 |
| Combination | Base Learner | Meta-Learner | Rc2 | RMSEc | RP2 | RMSEP |
|---|---|---|---|---|---|---|
| 01 | RF, GBDT, ELM | RR | 0.865 | 1.455 | 0.763 | 2.837 |
| 02 | RF, GPR, ELM | RR | 0.874 | 1.348 | 0.774 | 2.565 |
| 03 | RF, GBDT, ELM, SVM | RR | 0.859 | 1.525 | 0.755 | 2.944 |
| 04 | RF, ELM, SVM, GPR | RR | 0.862 | 1.438 | 0.765 | 2.749 |
| 05 | RF, GBDT, ELM, SVM, GPR | RR | 0.861 | 1.484 | 0.761 | 2.832 |
| 06 | RF, GBDT, ELM, SVM, GPR, RR | RR | 0.852 | 1.654 | 0.749 | 2.986 |
| 07 | RF, ELM, GPR, RR | RR | 0.882 | 0.608 | 0.829 | 1.953 |
| 08 | RF, ELM, GPR, RR | RF | 0.903 | 0.584 | 0.754 | 2.063 |
| 09 | RF, ELM, GPR, RR | ELM | 0.892 | 0.711 | 0.747 | 2.611 |
| 10 | RF, ELM, GPR, RR | GPR | 0.867 | 0.719 | 0.804 | 2.105 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, M.; Dou, S.; Lin, N.; Jiang, R.; Zhu, B. Estimation and Mapping of Soil Organic Matter Content Using a Stacking Ensemble Learning Model Based on Hyperspectral Images. Remote Sens. 2023, 15, 4713. https://doi.org/10.3390/rs15194713
Wu M, Dou S, Lin N, Jiang R, Zhu B. Estimation and Mapping of Soil Organic Matter Content Using a Stacking Ensemble Learning Model Based on Hyperspectral Images. Remote Sensing. 2023; 15(19):4713. https://doi.org/10.3390/rs15194713
Chicago/Turabian StyleWu, Menghong, Sen Dou, Nan Lin, Ranzhe Jiang, and Bingxue Zhu. 2023. "Estimation and Mapping of Soil Organic Matter Content Using a Stacking Ensemble Learning Model Based on Hyperspectral Images" Remote Sensing 15, no. 19: 4713. https://doi.org/10.3390/rs15194713