1. Introduction
With advancements in science and technology, the quality of remote sensing images has significantly improved. Due to their low cost, small size, and flexibility, UAVs are increasingly utilized in various tasks, such as maritime searching and rescuing [
1], parking vehicle searching, and specific person recognition [
2,
3]. However, UAV aerial images pose unique challenges, including shooting angles, numerous small and overlapping targets, and onerous manual recognition. To address these challenges, deep-learning-based object detection methods are widely used. While object detection algorithms have made significant progress in the fields of face and pedestrian detection, their application to UAV aerial photography is relatively limited, particularly for accurately detecting small targets. Hence, the aim of this study was to explore and develop a small object detection algorithm specifically tailored to UAV aerial images, highlighting its importance and serving as the motivation for this research [
4,
5].
Traditional object detection algorithms use sliding windows, of different sizes, to traverse the image [
6,
7]. This method is time-consuming and not robust; it has difficulty meeting the requirements of object detection in UAV images with complex scenes. In recent years, deep-learning-based methods, especially convolutional neural networks (CNNs), have achieved good results in several areas of computer vision research [
8,
9]. In object detection algorithms, there are two main categories: two-stage detection algorithms, such as R-CNN [
10], Fast R-CNN [
11], and Faster R-CNN [
12], and single-stage detection algorithms, such as YOLO [
13,
14,
15,
16,
17,
18,
19,
20,
21] and SSD [
22]. The two-stage detection algorithm is divided into two subtasks, which first determine the candidate regions of possible objects and then perform regression and classification for each candidate region. The two-stage detector has higher accuracy, but the detection speed is slower. The one-stage detection algorithm removes the step of identifying candidate frames, and it directly performs object classification and regression. Compared to the two-stage detection algorithm, the one-stage detection algorithm has a faster detection speed, but its detection accuracy is relatively low, especially in the UAV aerial image detection task.
In recent years, with the development of deep learning, convolutional neural networks have been dominant in the field of object detection. CSADet [
23] uses deformable convolution to construct a context-aware block that can extract both local high-frequency information and global semantic features. The semantic and location information of feature maps at different scales is shared using a multi-scale feature optimization block. Parallel extended convolution, to learn the contextual information of different objects at multiple scales, is used by mSODANet [
24]. It has been experimentally demonstrated that the introduced hierarchical extension network captures the semantic information in the images more effectively. Ref. [
25] designed a backbone network based on cross-stage and residual segmentation attention (CSP-ResNeSt) and a multiscale bidirectional feature pyramid with a simple attention module (Bi-SimAM-FPN). Experiments showed that the network can improve the recognition accuracy of small targets in images. Ref. [
26] constructed a feature enhancement module (RFA), which consists of a pooling layer of deformable regions of interest and location attention. The spatial information of small objects is enriched by fusing the region of interest features at different scales. Ref. [
27] used dilated convolution to study the contextual information of small objects. A module that dilated ResNet (DRM) was proposed, which was highly adaptable to scale variations of small objects at low altitude. Ref. [
28] introduced the DDMA module, which incorporates coordinate attention, channel attention, and space attention, into the neck of YOLOv5s. By integrating local and global features with the DDMA module, the problem of missing error detection for small targets is reduced. Ref. [
29] enhanced modeling capability by integrating deformable convolution within the network. Ref. [
30] designed a global context (GC) block that can efficiently model the global context. The network showed excellent performance in various recognition tasks.
Since the vision transformer (ViT) introduced the transformer to the field of computer vision, transformer architecture has been continuously optimized [
31,
32,
33,
34]. Ref. [
35] proposed a general transformer structure, MaxViT. MaxViT is composed of local and global attention that can fuse local and global features at each stage of the network. The effectiveness of MaxViT has been demonstrated by a large number of ablation experiments. Ref. [
36] proposed a novel contextual transformer (CoT) module. The CoT enhances the learning capability of the attention module by using contextual information between the key and value. Ref. [
37] built a new backbone network, by using the multi-head self-attention module of pyramid pooling (pyramid pooling transformer, P2T), which can extract the context features of the network. Ref. [
38] disintegrated the self-attention mechanism into horizontal and vertical, which can be computed in parallel in both directions. At the same time, local enhanced position coding (LePE) was introduced, and the experiment proved that the CSWin transformer has a good effect in the field of vision. Ref. [
39] constructed a vision transformer that alternately stacks the scalable attention mechanism and the windowed self-attention mechanism. This structure allows the network to achieve a good balance between accuracy and speed. Ref. [
40] used overlapping convolutions with different kernel sizes as patch embedding to obtain patches of the same length. These patches are passed to the transformer. Finally, the output features are aggregated to represent the features at different granularity.
Recent work has shown that combining a CNN and a transformer allows the network to take advantage of the strengths of both architectures. Ref. [
41] proposed an efficient hybrid architecture, EdgeNeXt. In EdgeNeXt, a slice-depth-transposed attention module is introduced, which can split features into multiple groups and use depth convolution and channel self-attention to increase receptive field and fuse multi-scale information.
Ref. [
42] used a bidirectional bridge to connect MobileNet to the transformer. This design can integrate the local features of a CNN and the global features of a transformer, which can achieve higher computational efficiency and stronger feature extraction ability. Ref. [
43] have discovered the potential relationship between the CNN and transformer by analyzing their operation principles. A transformer and a CNN have been cleverly combined to design a hybrid architecture called ACmix. Ref. [
44] designed a parallel structure using a transformer and deep convolution, which makes the channel dimension and spatial dimension complementary through the interaction structure. The combination of the two designs achieves a deep fusion of local and global features. Ref. [
45] enhanced the global perception capability of the CNN by fusing the global information of the transformer. Experimental results show that the conformer outperforms the CNN and ViT architectures alone with the same number of parameters. Ref. [
46] proposed a convolutional transformer block (CTB) and a convolutional multi-head self-attention block (CMHSA). This design can improve the algorithm’s ability to recognize obscured objects by aggregating context information.
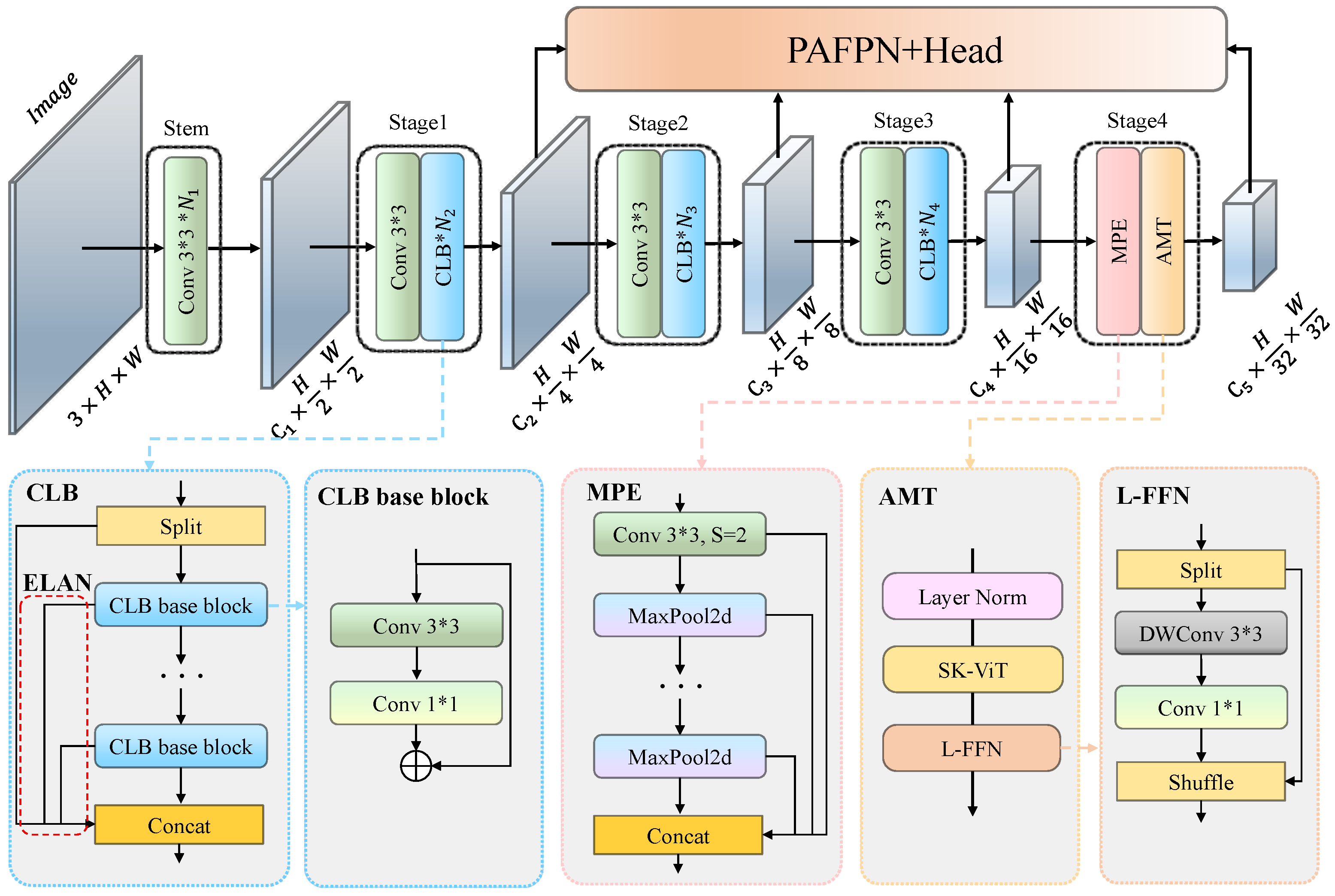
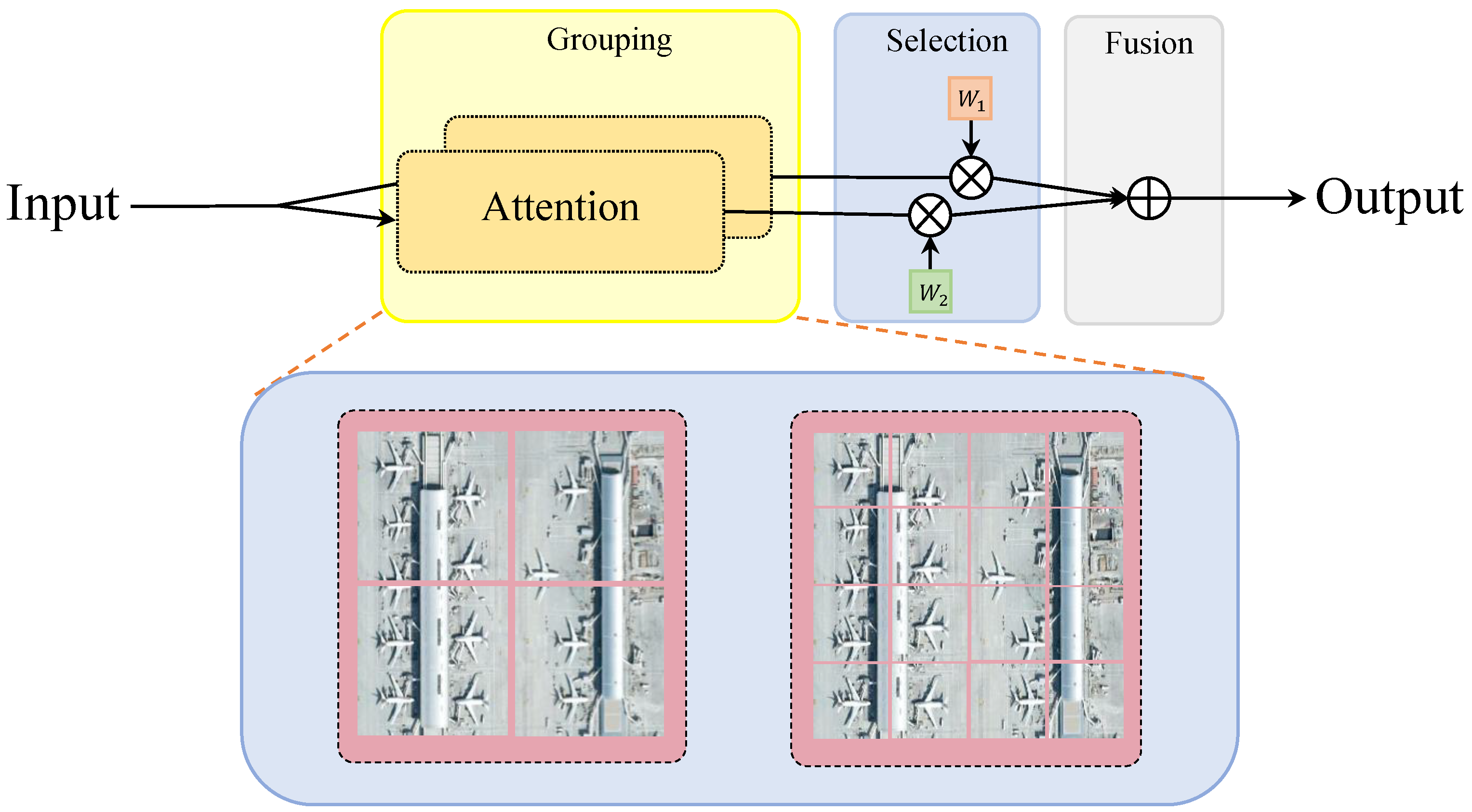
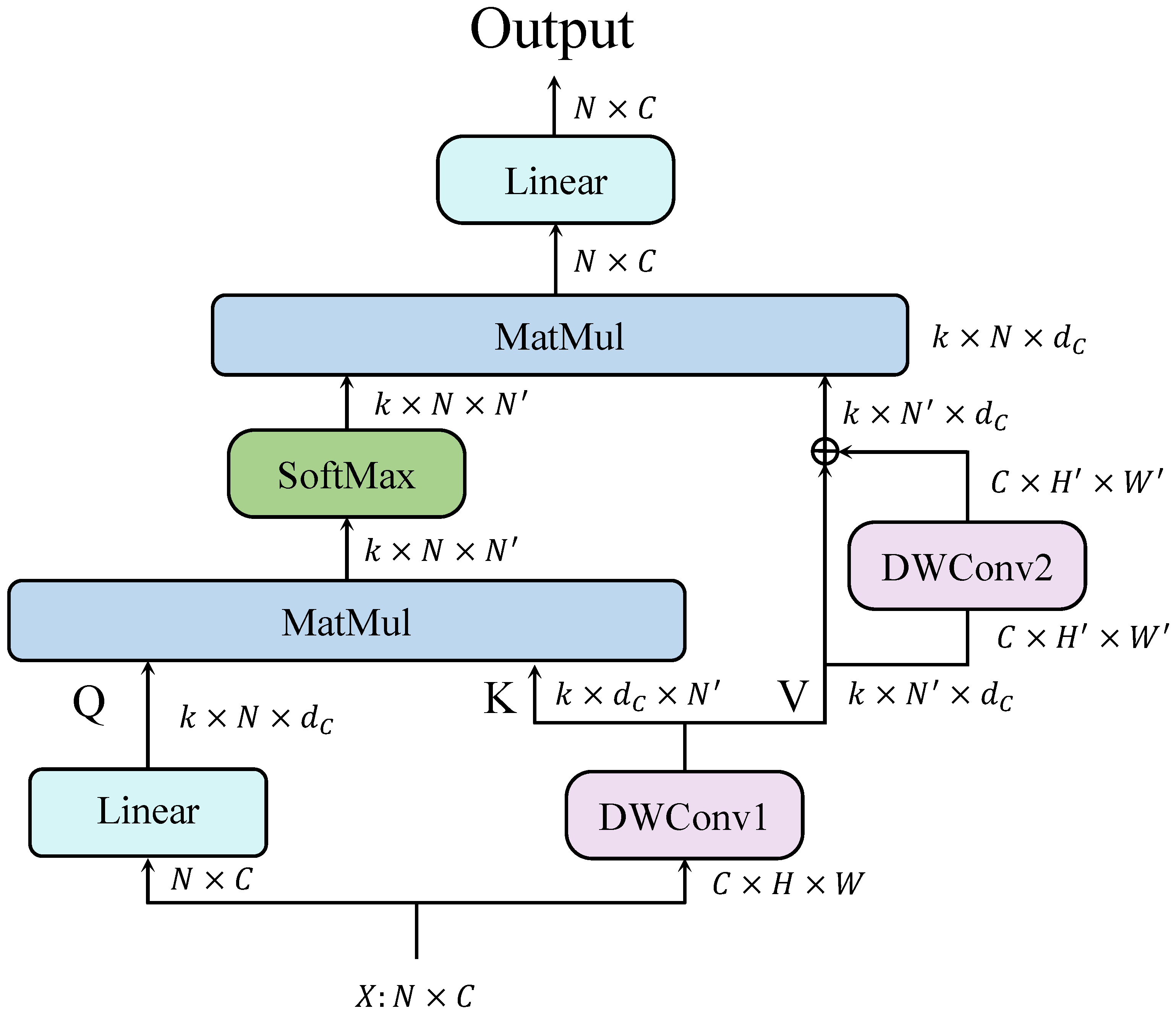
To achieve high accuracy and fast detection methods, this paper proposes a hybrid adaptive multi-scaled transformer network (HAM-Transformer Network) for UAV aerial photography, which consists of three basic blocks: the convolutional local feature extraction block (CLB), multi-scale position embedding block (MPE), and adaptive multi-scale transformer block (AMT). Specifically, we use the CLB to extract local texture features in the initial three stages of HAM-Transformer Net. The CLB borrows the overall architectural idea of efficient layer aggregation network (ELAN) [
47] but differs from the ELAN in that we redesigned the basic blocks. The MPE introduces the idea of multi-scale feature fusion into the overlapping embedding module by stacking max pooling layers. The AMT merges adjacent embedding blocks by using deep convolution with different kernel sizes and uses multi-branch adaptive fusion to balance features at different scales. Experiments demonstrate that the HAM-Transformer network outperforms state-of-the-art target detection methods. With the same number of parameters, HAM-Transformer improves 4.1% mAP over YOLOv8-S and 5.9% mAP over YOLOv6-S on the remote sensing-UAV aerial photography dataset.
The contributions of this study can be summarized as follows:
We propose three efficient blocks, namely a convolutional local feature extraction block, multi-scale position embedding block and adaptive multi-scale transformer block, which can be easily inserted into any network without adjusting the overall architecture.
We designed a novel efficient feature extraction backbone network, HAM-Transformer, which cleverly fuses the CNN and transformer. It can adaptively adjust the feature contribution for different receptive fields in the last stage of the network.
We have combined existing UAV aerial photography and remote sensing datasets to enrich the diversity of our datasets, which include urban, maritime, and natural landscapes.
We have carried out extensive experimental validation, and the experimental results show that HAM-Transformer Net balances speed and accuracy and outperforms the existing single-stage object detection feature extraction backbone network with similar parameter quantity.
The rest of this article is structured as follows. We introduce the overall structure of HAM-Transformer Net and the details of each block in
Section 2. In
Section 3, we describe the dataset used in the experiments and the implementation of the comparisons. We discuss the methodology proposed in this paper in
Section 4. We summarize this work in
Section 5.
4. Discussion
UAV aerial images are affected by the shooting angle, resulting in a large number of small and overlapping targets. This brings great challenges to the object detection algorithm of UAV aerial images. To overcome the above challenges, we propose a novel object detection method called HAM-Transformer, which combines both a CNN and transformer. The method uses convolutional local feature extraction blocks to refine the information of feature maps and adopts adaptive multi-scale transformer blocks to adaptively fuse features for different receptive fields. Experimental results have shown that this method represents a great improvement compared to current advanced methods.
Traditional object detection methods require extensive manual feature design, which not only consumes time but also cannot guarantee robustness, which makes it difficult to meet the requirements of UAV image target detection in complex scenes. In the past two years, many scholars have combined transformer methods originating from natural language processing with CNNs and achieved a new level of performance. Different from previous work, we propose a novel CNN–transformer feature extraction backbone network. As shown in
Table 2, the proposed method in this paper exhibits a 4.1% improvement compared to YOLOv8-s and has similar speed. In addition, in order to prove the effectiveness of our proposed blocks, we conducted a large number of ablation experiments in experiments. As can be seen from
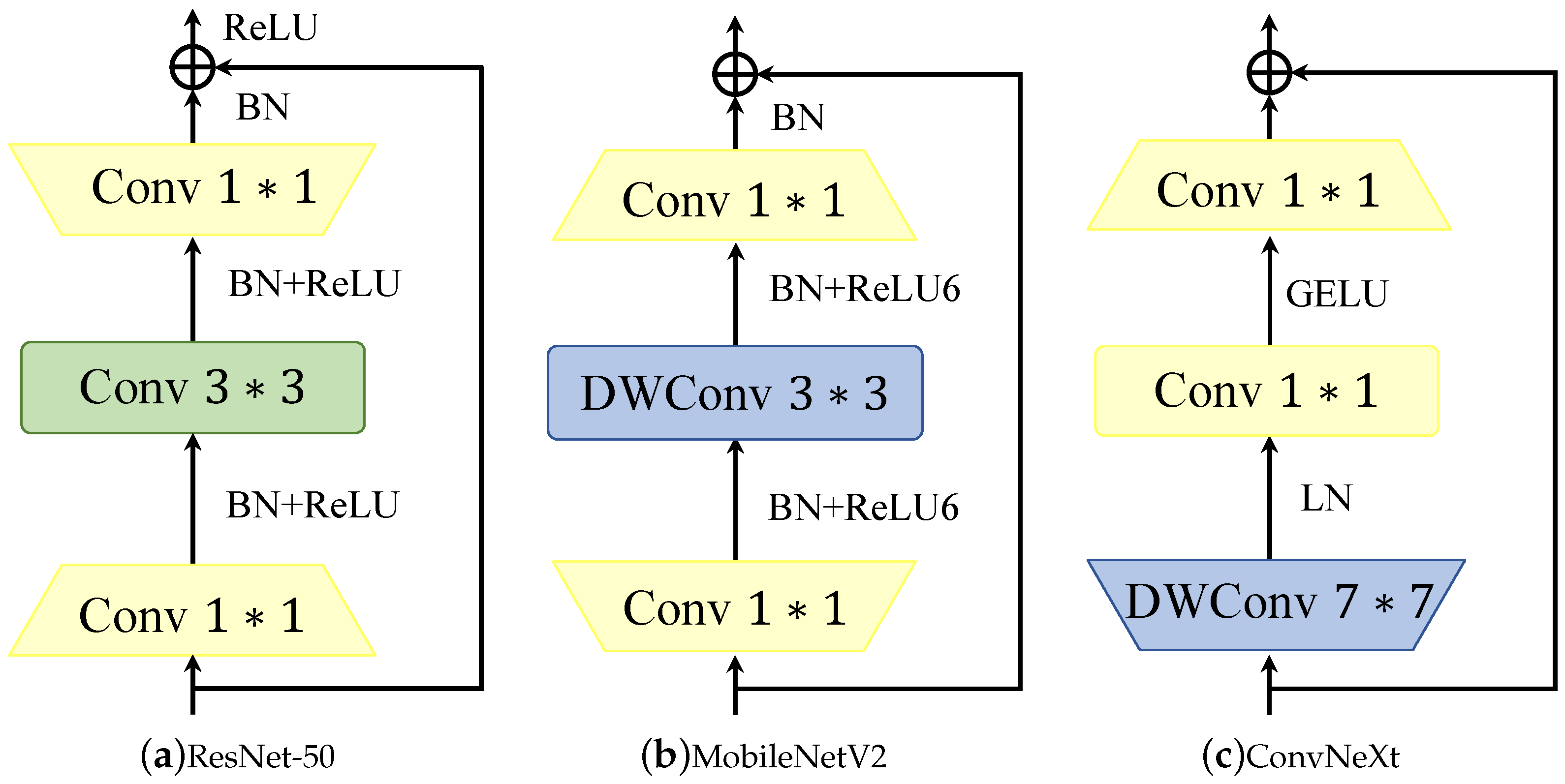
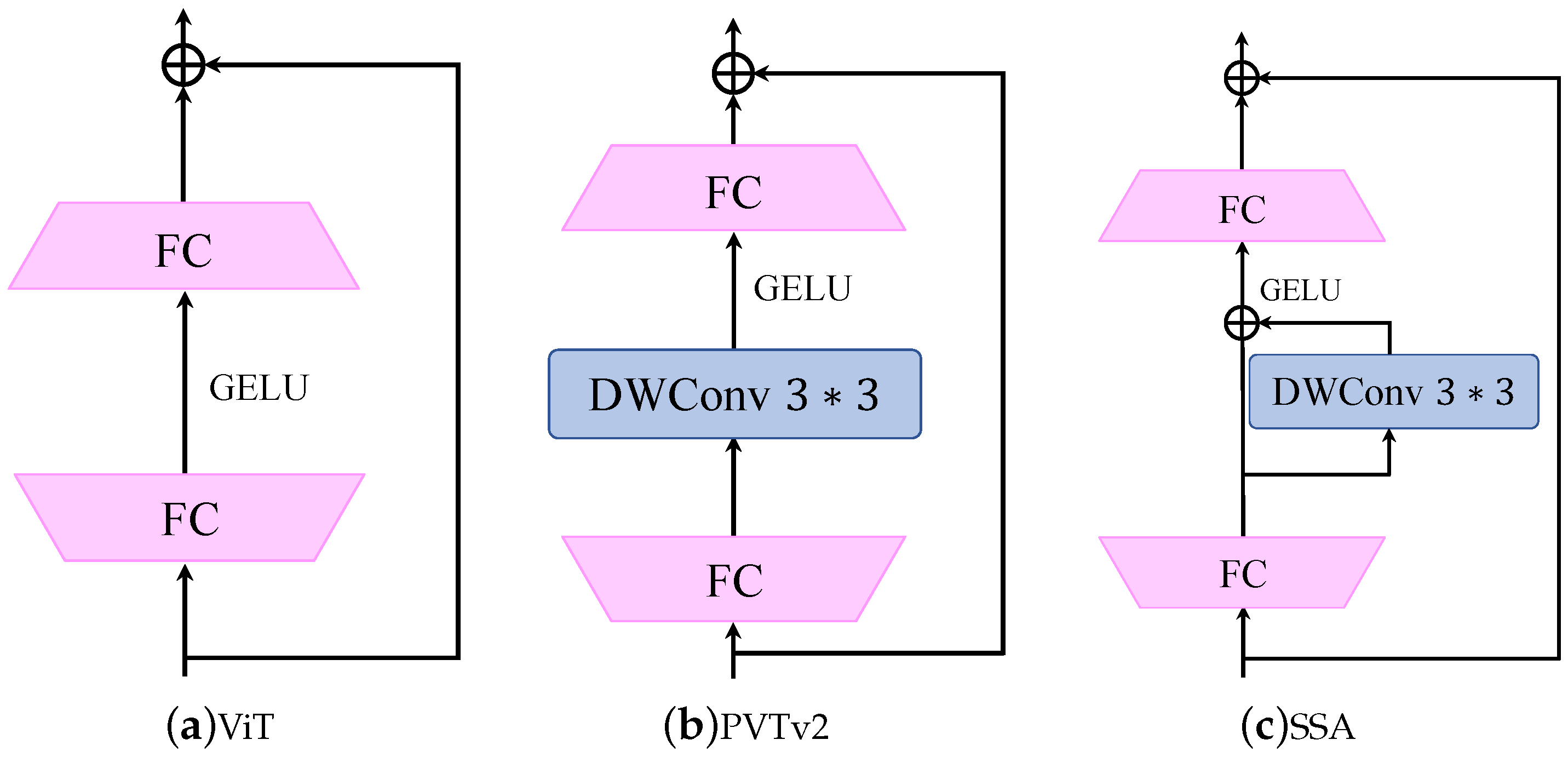
Table 3, the CLB proposed by us has higher accuracy than other classical convolution modules. As can be seen from
Table 7, the L-FFN proposed by us not only has fewer parameters but also higher precision than other methods.
Due to the limitations of the hardware environment, we limited the input format of the model to 640 × 640 pixels. This is unfavorable for large-sized aerial images. Our approach is based on images for object recognition, but for UAV remote sensing object recognition other forms of data are also crucial. Therefore, in the future, we will further investigate how to use the image form in conjunction with other forms of object detection data to compensate for the deficiencies in images.
In summary, in this study, we propose a novel hybrid feature extraction backbone network with the CNN–transformer method. After a large number of experiments, it was proved that the method proposed in this paper has better performance compared to other methods. HAM-Transformer can also be easily applied to other fields such as remote sensing object tracking and object segmentation.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}