
Effect of the Synergetic Use of Sentinel-1, Sentinel-2, LiDAR and Derived Data in Land Cover Classification of a Semiarid Mediterranean Area Using Machine Learning Algorithms



Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Datasets
2.2.1. Sentinel-2 Data
- Tasseled cap brightness (TCB) [66] tries to emphasize spectral information from satellite imagery. Spectral bands from the visible and infrared (both near and shortwave) are used to obtain a matrix that highlights brightness, greenness, yellowness, nonesuch [66] and wetness [67] coefficients. In this case, we used the brightness equation, also known as the soil brightness index (SBI), which detects variations in soil reflectance. The equation for S2 is:where , and are the blue (B), green (G) and red (R) bands, respectively; is the NIR band; and and are the SWIR from S2A MSI.
- The Soil Adjusted Vegetation Index (SAVI) [68]: Due to the NDVI’s sensitivity to the proportion of soil and vegetation, this index is added to the NDVI a soil factor. In semiarid areas, this is a way to fit the index to background average reflectance. The equation is:where is the NIR band, is the R band and L is a factor for soil brightness with a value of 0.5 to fit with the majority of covers.
- The Modified Normalized Difference Water Index (MNDWI) [70] was proposed to detect superficial water. However, due to the relation between SWIR and wetness in soils, it can be also used to detect water in surfaces of vegetation or soil. The index is calculated with Equation (5):where is the G band and the SWIR band.
2.2.2. Sentinel-1 Data
2.2.3. LiDAR Metrics
2.2.4. Training Datasets
2.3. Training Areas and Classification Scheme
2.4. Image Classification
2.4.1. Random Forest
2.4.2. Support Vector Machines
2.4.3. Multilayer Perceptron
2.5. Validation
2.6. Feature Selection
3. Results
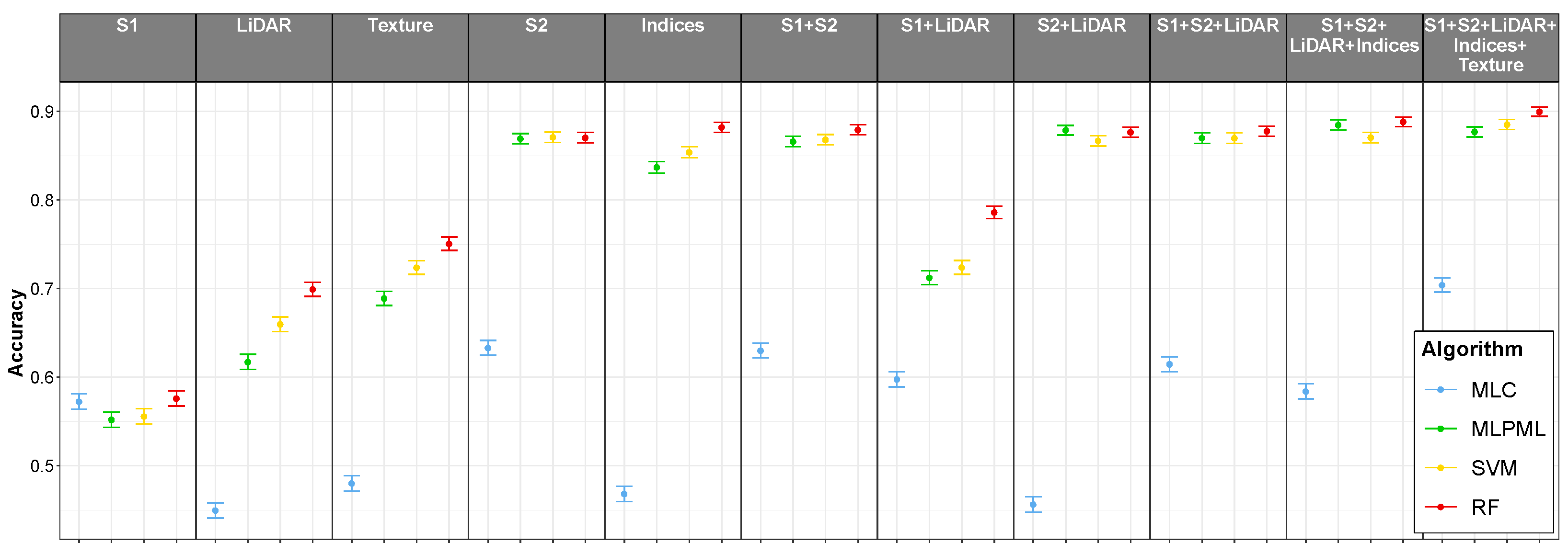
3.1. Classifications with Multisensor and Derived Predictors
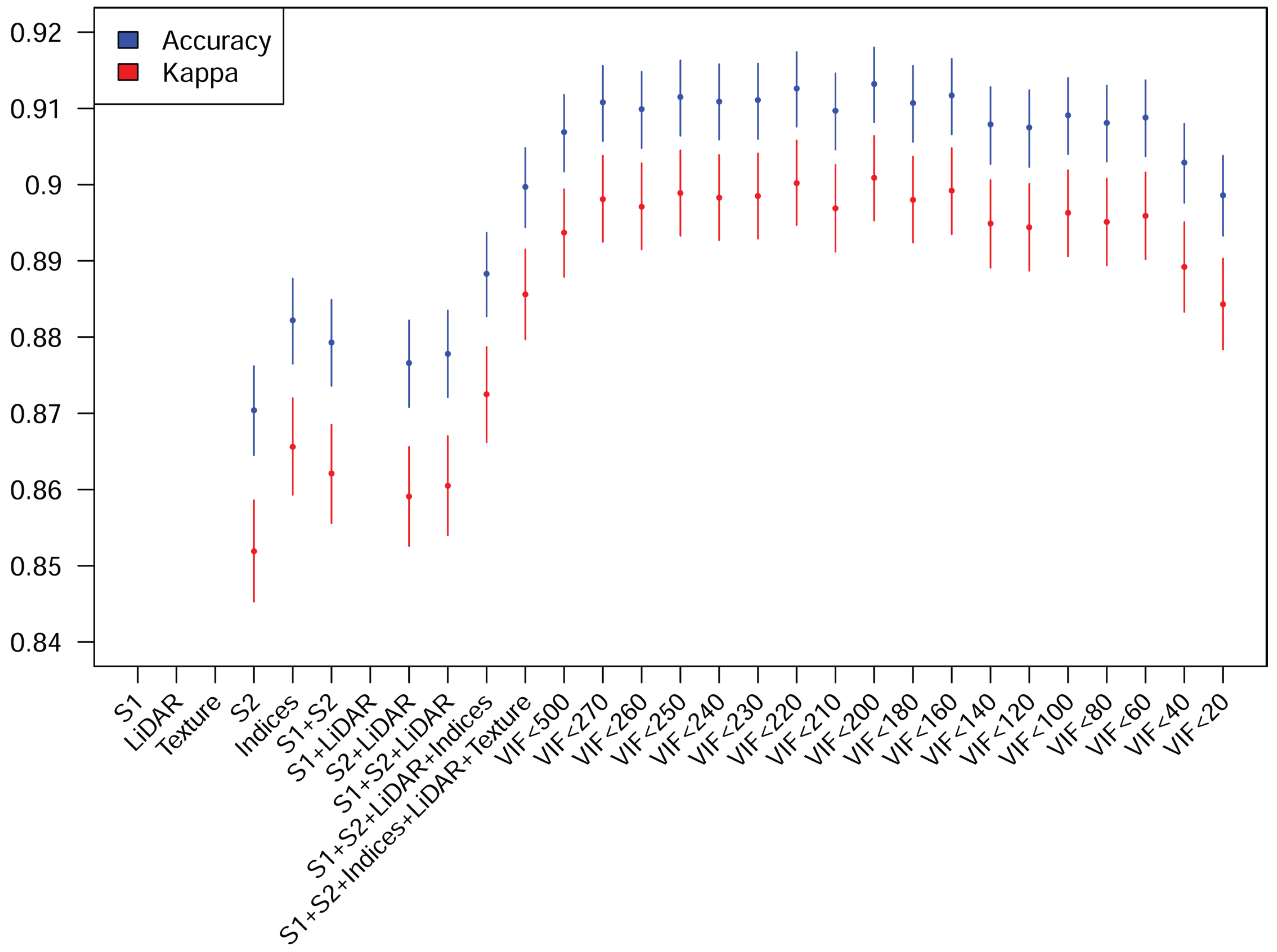
3.2. Feature Selection
3.3. Final Classification and Errors
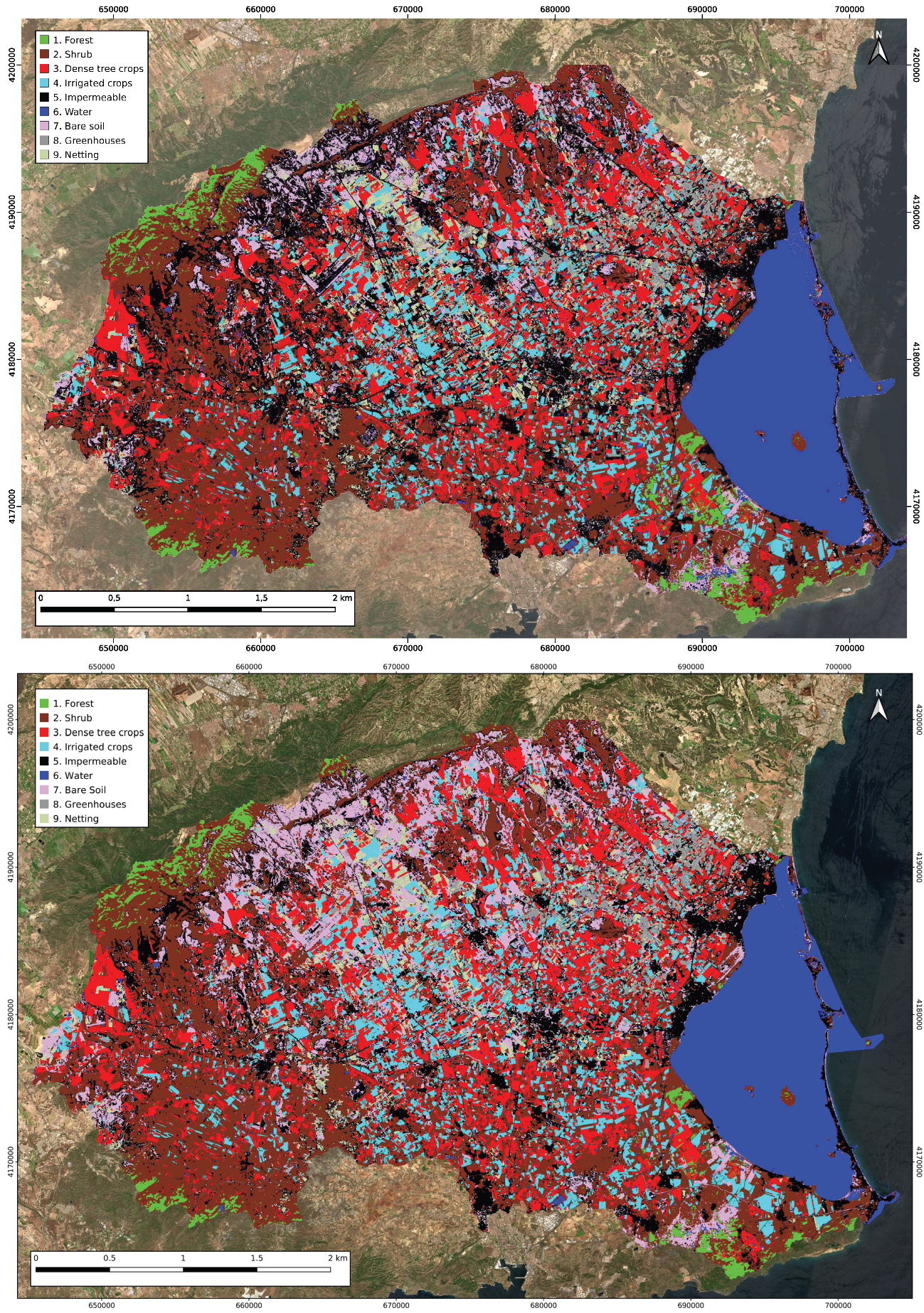
3.4. Land Cover Maps
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASPRS | American Society for Photogrammetry and Remote Sensing |
| DEM | Digital Elevation Model |
| DPSVI | Dual Polarization SAR Vegetation Index |
| ESA | European Spatial Agency |
| GLCM | Grey Level Coocurrence Matrix |
| GRD | Ground Range Detection |
| IW | Interferometric Wide |
| LiDAR | Light Detection and Ranging |
| LOO-CV | Leave One Out Cross Validation |
| ML | Machine Learning |
| MLC | Maximum Likelihood Classifier |
| MLP | Multilayer Perceptron |
| MNDWI | Modified Normalized Difference Water Index |
| MSI | MultiSpectral Instrument |
| mZB | average height of small vegetation |
| mZM | average height of medium size vegetation |
| mZA | average height of high vegetation |
| mZE | average height of building points |
| mZG | average height of ground points |
| NDBI | Normalized Difference Building Index |
| NDVI | Normalized Difference Vegetation Index |
| NIR | Near Infrared |
| Nvv | number of medium or high vegetation points whose nearest neighbor is a medium or high vegetation point |
| OD-Nature | Operational Directorate Natural Environment |
| OOB-CV | Out Of Bag Cross Validation |
| PNOA | National Aerial Orthophotography Plan |
| ppB | Proportion of points of low vegetation |
| ppM | Proportion of points of medium size vegetation |
| ppA | Proportion of points of high vegetation |
| ppE | Proportion of points of buildings |
| ppH | Proportion of points of water |
| REMSEM | Remote Sensing and Ecosystem Modelling |
| RBINS | Royal Belgian Institute of Natural Science |
| S1 | Sentinel 1 |
| S2 | Sentinel 2 |
| SAR | Synthetic Aperture Radar |
| SAVI | Soil Adjusted Vegetation Index |
| SBI | Soil Brightness Index |
| SVM | Support Vector Machine |
| SWIR | Short Wave Infrared |
| sZB | standard deviation of small vegetation height |
| sZM | standard deviation of medium size vegetation height |
| sZA | standard deviation of high vegetation |
| sZE | standard deviation of building points |
| sZG | standard deviation of ground points |
| TCB | Tasselled Cap Brightness |
| TOA | Top Of the Atmosphere |
| TOPSAR | Terrain Observation by Progresssive Scans SAR |
| VIF | Variance Inflation Factor |
| wCv | Maximum value of the Ripley’s K function |
| wDv | Minimum value of the Ripley’s K function |
| wCd | Distance of the maximum value of the Ripley’s K function |
| wDd | Distance of the minimum value of the Ripley’s K function |
References
- Berberoglu, S.; Curran, P.J.; Lloyd, C.D.; Atkinson, P.M. Texture classification of Mediterranean land cover. Int. J. Appl. Earth Obs. Geoinf. 2007, 9, 322–334. [Google Scholar] [CrossRef]
- Ezzine, H.; Bouziane, A.; Ouazar, D. Seasonal comparisons of meteorological and agricultural drought indices in Morocco using open short time-series data. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 36–48. [Google Scholar] [CrossRef]
- Haralick, R.M. Statistical and structural approaches to texture. Proc. IEEE 1979, 67, 786–804. [Google Scholar] [CrossRef]
- Zhou, P.; Han, J.; Cheng, G.; Zhang, B. Learning compact and discriminative stacked autoencoder for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4823–4833. [Google Scholar] [CrossRef]
- Kupidura, P. The comparison of different methods of texture analysis for their efficacy for land use classification in satellite imagery. Remote Sens. 2019, 11, 1233. [Google Scholar] [CrossRef] [Green Version]
- Denize, J.; Hubert-Moy, L.; Betbeder, J.; Corgne, S.; Baudry, J.; Pottier, E. Evaluation of using sentinel-1 and-2 time-series to identify winter land use in agricultural landscapes. Remote Sens. 2019, 11, 37. [Google Scholar] [CrossRef] [Green Version]
- Campos-Taberner, M.; García-Haro, F.J.; Martínez, B.; Sánchez-Ruíz, S.; Gilabert, M.A. A Copernicus Sentinel-1 and Sentinel-2 classification framework for the 2020+ European common agricultural policy: A case study in València (Spain). Agronomy 2019, 9, 556. [Google Scholar] [CrossRef] [Green Version]
- Gomariz-Castillo, F.; Alonso-Sarría, F.; Cánovas-García, F. Improving classification accuracy of multi-temporal landsat images by assessing the use of different algorithms, textural and ancillary information for a mediterranean semiarid area from 2000 to 2015. Remote Sens. 2017, 9, 1058. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Brandt, M.; Wang, Q.; Prishchepov, A.V.; Tucker, C.J.; Li, Y.; Lyu, H.; Fensholt, R. From woody cover to woody canopies: How Sentinel-1 and Sentinel-2 data advance the mapping of woody plants in savannas. Remote Sens. Environ. 2019, 234, 111465. [Google Scholar] [CrossRef]
- Mandal, D.; Kumar, V.; Bhattacharya, A.; Rao, Y.S.; Siqueira, P.; Bera, S. Sen4Rice: A processing chain for differentiating early and late transplanted rice using time-series Sentinel-1 SAR data with Google Earth engine. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1947–1951. [Google Scholar] [CrossRef]
- Arias, M.; Campo-Bescós, M.Á.; Álvarez-Mozos, J. Crop Classification Based on Temporal Signatures of Sentinel-1 Observations over Navarre Province, Spain. Remote Sens. 2020, 12, 278. [Google Scholar] [CrossRef] [Green Version]
- Mandal, D.; Kumar, V.; Ratha, D.; Dey, S.; Bhattacharya, A.; Lopez-Sanchez, J.M.; McNairn, H.; Rao, Y.S. Dual polarimetric radar vegetation index for crop growth monitoring using sentinel-1 SAR data. Remote Sens. Environ. 2020, 247, 111954. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Marais-Sicre, C. Improved early crop type identification by joint use of high temporal resolution SAR and optical image time series. Remote Sens. 2016, 8, 362. [Google Scholar] [CrossRef] [Green Version]
- Veloso, A.; Mermoz, S.; Bouvet, A.; Le Toan, T.; Planells, M.; Dejoux, J.F.; Ceschia, E. Understanding the temporal behavior of crops using Sentinel-1 and Sentinel-2-like data for agricultural applications. Remote Sens. Environ. 2017, 199, 415–426. [Google Scholar] [CrossRef]
- Periasamy, S. Significance of dual polarimetric synthetic aperture radar in biomass retrieval: An attempt on Sentinel-1. Remote Sens. Environ. 2018, 217, 537–549. [Google Scholar] [CrossRef]
- Kumar, P.; Prasad, R.; Gupta, D.; Mishra, V.; Vishwakarma, A.; Yadav, V.; Bala, R.; Choudhary, A.; Avtar, R. Estimation of winter wheat crop growth parameters using time series Sentinel-1A SAR data. Geocarto Int. 2018, 33, 942–956. [Google Scholar] [CrossRef]
- Vreugdenhil, M.; Wagner, W.; Bauer-Marschallinger, B.; Pfeil, I.; Teubner, I.; Rüdiger, C.; Strauss, P. Sensitivity of Sentinel-1 backscatter to vegetation dynamics: An Austrian case study. Remote Sens. 2018, 10, 1396. [Google Scholar] [CrossRef] [Green Version]
- Topaloğlu, R.H.; Sertel, E.; Musaoğlu, N. Assessment of Classification Accuracies of SENTINEL-2 and LANDSAT-8 Data for Land Cover/Use Mapping. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2016, XLI-B8, 1055–1059. [Google Scholar] [CrossRef] [Green Version]
- Borrás, J.; Delegido, J.; Pezzola, A.; Pereira, M.; Morassi, G.; Camps-Valls, G. Clasificación de usos del suelo a partir de imágenes Sentinel-2. Rev. De Teledetección 2017, 48, 55–66. [Google Scholar] [CrossRef] [Green Version]
- Thanh Noi, P.; Kappas, M. Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using Sentinel-2 imagery. Sensors 2018, 18, 18. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Brinkhoff, J.; Vardanega, J.; Robson, A.J. Land cover classification of nine perennial crops using sentinel-1 and-2 data. Remote Sens. 2020, 12, 96. [Google Scholar] [CrossRef] [Green Version]
- Haas, J.; Ban, Y. Sentinel-1A SAR and sentinel-2A MSI data fusion for urban ecosystem service mapping. Remote Sens. Appl. Soc. Environ. 2017, 8, 41–53. [Google Scholar] [CrossRef]
- Tavares, P.A.; Beltrão, N.E.S.; Guimarães, U.S.; Teodoro, A.C. Integration of sentinel-1 and sentinel-2 for classification and LULC mapping in the urban area of Belém, eastern Brazilian Amazon. Sensors 2019, 19, 1140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amoakoh, A.O.; Aplin, P.; Awuah, K.T.; Delgado-Fernandez, I.; Moses, C.; Alonso, C.P.; Kankam, S.; Mensah, J.C. Testing the Contribution of Multi-Source Remote Sensing Features for Random Forest Classification of the Greater Amanzule Tropical Peatland. Sensors 2021, 21, 3399. [Google Scholar] [CrossRef] [PubMed]
- Masiza, W.; Chirima, J.G.; Hamandawana, H.; Pillay, R. Enhanced mapping of a smallholder crop farming landscape through image fusion and model stacking. Int. J. Remote. Sens. 2020, 41, 8736–8753. [Google Scholar] [CrossRef]
- Dobrinić, D.; Medak, D.; Gašparović, M. Integration of multitemporal Sentinel-1 and Sentinel-2 imagery for land-cover classification using machine learning methods. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2020, XLIII-B1-2, 91–98. [Google Scholar] [CrossRef]
- De Luca, G.; MN Silva, J.; Di Fazio, S.; Modica, G. Integrated use of Sentinel-1 and Sentinel-2 data and open-source machine learning algorithms for land cover mapping in a Mediterranean region. Eur. J. Remote Sens. 2022, 55, 52–70. [Google Scholar] [CrossRef]
- De Fioravante, P.; Luti, T.; Cavalli, A.; Giuliani, C.; Dichicco, P.; Marchetti, M.; Chirici, G.; Congedo, L.; Munafò, M. Multispectral Sentinel-2 and SAR Sentinel-1 Integration for Automatic Land Cover Classification. Land 2021, 10, 611. [Google Scholar] [CrossRef]
- Kleeschulte, S.; Banko, G.; Smith, G.; Arnold, S.; Scholz, J.; Kosztra, B.; Maucha, G. Technical Specifications for Implementation of a New Land-Monitoring Concept Based on EAGLE, D5: Design Concept and CLC+ Backbone, Technical Specifications, CLC+ Core and CLC+ Instances Draft Specifications, Including Requirements Review; Technical Report; European Environment Agency: Copenhagen, Denmark, 2020. [Google Scholar]
- Wang, Y.; Liu, H.; Sang, L.; Wang, J. Characterizing Forest Cover and Landscape Pattern Using Multi-Source Remote Sensing Data with Ensemble Learning. Remote Sens. 2022, 14, 5470. [Google Scholar] [CrossRef]
- Han, Y.; Guo, J.; Ma, Z.; Wang, J.; Zhou, R.; Zhang, Y.; Hong, Z.; Pan, H. Habitat Prediction of Northwest Pacific Saury Based on Multi-Source Heterogeneous Remote Sensing Data Fusion. Remote Sens. 2022, 14, 5061. [Google Scholar] [CrossRef]
- Marais-Sicre, C.; Fieuzal, R.; Baup, F. Contribution of multispectral (optical and radar) satellite images to the classification of agricultural surfaces. Int. J. Appl. Earth Obs. Geoinf. 2020, 84, 101972. [Google Scholar] [CrossRef]
- Wuyun, D.; Sun, L.; Sun, Z.; Chen, Z.; Hou, A.; Teixeira Crusiol, L.G.; Reymondin, L.; Chen, R.; Zhao, H. Mapping fallow fields using Sentinel-1 and Sentinel-2 archives over farming-pastoral ecotone of Northern China with Google Earth Engine. Giscience Remote. Sens. 2022, 59, 333–353. [Google Scholar] [CrossRef]
- Berger, K.; Machwitz, M.; Kycko, M.; Kefauver, S.C.; Van Wittenberghe, S.; Gerhards, M.; Verrelst, J.; Atzberger, C.; Tol, C.v.d.; Damm, A.; et al. Multi-sensor spectral synergies for crop stress detection and monitoring in the optical domain: A review. Remote. Sens. Environ. 2022, 280, 113198. [Google Scholar] [CrossRef] [PubMed]
- Andalibi, L.; Ghorbani, A.; Darvishzadeh, R.; Moameri, M.; Hazbavi, Z.; Jafari, R.; Dadjou, F. Multisensor Assessment of Leaf Area Index across Ecoregions of Ardabil Province, Northwestern Iran. Remote Sens. 2022, 14, 5731. [Google Scholar] [CrossRef]
- Zhang, N.; Chen, M.; Yang, F.; Yang, C.; Yang, P.; Gao, Y.; Shang, Y.; Peng, D. Forest Height Mapping Using Feature Selection and Machine Learning by Integrating Multi-Source Satellite Data in Baoding City, North China. Remote Sens. 2022, 14, 4434. [Google Scholar] [CrossRef]
- Guerra-Hernandez, J.; Narine, L.L.; Pascual, A.; Gonzalez-Ferreiro, E.; Botequim, B.; Malambo, L.; Neuenschwander, A.; Popescu, S.C.; Godinho, S. Aboveground biomass mapping by integrating ICESat-2, SENTINEL-1, SENTINEL-2, ALOS2/PALSAR2, and topographic information in Mediterranean forests. Giscience Remote. Sens. 2022, 59, 1509–1533. [Google Scholar] [CrossRef]
- Kabisch, N.; Selsam, P.; Kirsten, T.; Lausch, A.; Bumberger, J. A multi-sensor and multi-temporal remote sensing approach to detect land cover change dynamics in heterogeneous urban landscapes. Ecol. Indic. 2019, 99, 273–282. [Google Scholar] [CrossRef]
- Heinzel, J.; Koch, B. Investigating multiple data sources for tree species classification in temperate forest and use for single tree delineation. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 101–110. [Google Scholar] [CrossRef]
- Montesano, P.; Cook, B.; Sun, G.; Simard, M.; Nelson, R.; Ranson, K.; Zhang, Z.; Luthcke, S. Achieving accuracy requirements for forest biomass mapping: A spaceborne data fusion method for estimating forest biomass and LiDAR sampling error. Remote Sens. Environ. 2013, 130, 153–170. [Google Scholar] [CrossRef]
- Chen, L.; Ren, C.; Bao, G.; Zhang, B.; Wang, Z.; Liu, M.; Man, W.; Liu, J. Improved Object-Based Estimation of Forest Aboveground Biomass by Integrating LiDAR Data from GEDI and ICESat-2 with Multi-Sensor Images in a Heterogeneous Mountainous Region. Remote. Sens. 2022, 14, 2743. [Google Scholar] [CrossRef]
- Morin, D.; Planells, M.; Baghdadi, N.; Bouvet, A.; Fayad, I.; Le Toan, T.; Mermoz, S.; Villard, L. Improving Heterogeneous Forest Height Maps by Integrating GEDI-Based Forest Height Information in a Multi-Sensor Mapping Process. Remote. Sens. 2022, 14, 2079. [Google Scholar] [CrossRef]
- Torres de Almeida, C.; Gerente, J.; Rodrigo dos Prazeres Campos, J.; Caruso Gomes Junior, F.; Providelo, L.; Marchiori, G.; Chen, X. Canopy Height Mapping by Sentinel 1 and 2 Satellite Images, Airborne LiDAR Data, and Machine Learning. Remote Sens. 2022, 14, 4112. [Google Scholar] [CrossRef]
- Zhong, Y.; Cao, Q.; Zhao, J.; Ma, A.; Zhao, B.; Zhang, L. Optimal decision fusion for urban land-use/land-cover classification based on adaptive differential evolution using hyperspectral and LiDAR data. Remote Sens. 2017, 9, 868. [Google Scholar] [CrossRef] [Green Version]
- Feng, Q.; Zhu, D.; Yang, J.; Li, B. Multisource hyperspectral and LiDAR data fusion for urban land-use mapping based on a modified two-branch convolutional neural network. ISPRS Int. J. Geo-Inf. 2019, 8, 28. [Google Scholar] [CrossRef] [Green Version]
- Rittenhouse, C.; Berlin, E.; Mikle, N.; Qiu, S.; Riordan, D.; Zhu, Z. An Object-Based Approach to Map Young Forest and Shrubland Vegetation Based on Multi-Source Remote Sensing Data. Remote Sens. 2022, 14, 1091. [Google Scholar] [CrossRef]
- Ali, A.; Abouelghar, M.; Belal, A.; Saleh, N.; Yones, M.; Selim, A.; Amin, M.; Elwesemy, A.; Kucher, D.; Maginan, S.; et al. Crop Yield Prediction Using Multi Sensors Remote Sensing (Review Article). Egypt. J. Remote Sens. Space Sci. 2022, 25, 711–716. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Mack, B.; Conrad, C. Crop Type Classification Using Fusion of Sentinel-1 and Sentinel-2 Data: Assessing the Impact of Feature Selection, Optical Data Availability, and Parcel Sizes on the Accuracies. Remote. Sens. 2020, 12, 2779. [Google Scholar] [CrossRef]
- Wu, F.; Ren, Y.; Wang, X. Application of Multi-Source Data for Mapping Plantation Based on Random Forest Algorithm in North China. Remote Sens. 2022, 14, 4946. [Google Scholar] [CrossRef]
- CARM. Estadística Agraria Regional. 2021. Available online: https://www.carm.es/web/pagina?IDCONTENIDO=1174&RASTRO=c1415$m&IDTIPO=100 (accessed on 15 April 2021).
- Martínez, J.; Esteve, M.; Martínez-Paz, J.; Carreño, F.; Robledano, F.; Ruiz, M.; Alonso-Sarría, F. Simulating management options and scenarios to control nutrient load to Mar Menor, Southeast Spain. Transitional Waters Monogr. 2007, 1, 53–70. [Google Scholar] [CrossRef]
- Giménez-Casalduero, F.; Gomariz-Castillo, F.; Alonso-Sarria, F.; Cortés, E.; Izquierdo-Muñoz, A.; Ramos-Esplá, A. Pinna nobilis in the Mar Menor coastal lagoon: A story of colonization and uncertainty. Mar. Ecol. Prog. Ser. 2020, 652, 77–94. [Google Scholar] [CrossRef]
- European Commission. Copernicus Open Access Hub. 2021. Available online: https://scihub.copernicus.eu/ (accessed on 15 April 2021).
- Vanhellemont, Q.; Ruddick, K. Acolite for Sentinel-2: Aquatic applications of MSI imagery. In Proceedings of the 2016 ESA Living Planet Symposium, Prague, Czech Republic, 9–13 May 2016; pp. 9–13. [Google Scholar]
- Vanhellemont, Q.; Ruddick, K. Atmospheric correction of metre-scale optical satellite data for inland and coastal water applications. Remote Sens. Environ. 2018, 216, 586–597. [Google Scholar] [CrossRef]
- Vanhellemont, Q. Adaptation of the dark spectrum fitting atmospheric correction for aquatic applications of the Landsat and Sentinel-2 archives. Remote Sens. Environ. 2019, 225, 175–192. [Google Scholar] [CrossRef]
- Main-Knorn, M.; Pflug, B.; Louis, J.; Debaecker, V.; Müller-Wilm, U.; Gascon, F. Sen2Cor for Sentinel-2. In Proceedings of the Image and Signal Processing for Remote Sensing XXIII; Bruzzone, L., Ed.; SPIE: Warsaw, Poland, 2017. [Google Scholar] [CrossRef] [Green Version]
- Lonjou, V.; Desjardins, C.; Hagolle, O.; Petrucci, B.; Tremas, T.; Dejus, M.; Makarau, A.; Auer, S. MACCS-ATCOR joint algorithm (MAJA). In Proceedings of the Remote Sensing of Clouds and the Atmosphere XXI, Edinburgh, UK, 28–29 September 2016; Comerón, A., Kassianov, E.I., Schäfer, K., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2016; Volume 10001, pp. 25–37. [Google Scholar] [CrossRef]
- Valdivieso-Ros, M.; Alonso-Sarria, F.; Gomariz-Castillo, F. Effect of Different Atmospheric Correction Algorithms on Sentinel-2 Imagery Classification Accuracy in a Semiarid Mediterranean Area. Remote Sens. 2021, 13, 1770. [Google Scholar] [CrossRef]
- Klein, I.; Gessner, U.; Dietz, A.J.; Kuenzer, C. Global WaterPack–A 250 m resolution dataset revealing the daily dynamics of global inland water bodies. Remote Sens. Environ. 2017, 198, 345–362. [Google Scholar] [CrossRef]
- Mostafiz, C.; Chang, N.B. Tasseled cap transformation for assessing hurricane landfall impact on a coastal watershed. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 736–745. [Google Scholar] [CrossRef]
- Yang, X.; Qin, Q.; Grussenmeyer, P.; Koehl, M. Urban surface water body detection with suppressed built-up noise based on water indices from Sentinel-2 MSI imagery. Remote Sens. Environ. 2018, 219, 259–270. [Google Scholar] [CrossRef]
- Hong, C.; Jin, X.; Ren, J.; Gu, Z.; Zhou, Y. Satellite data indicates multidimensional variation of agricultural production in land consolidation area. Sci. Total Environ. 2019, 653, 735–747. [Google Scholar] [CrossRef]
- Rouse, J.; Haas, R.; Schell, J.; Deering, D. Monitoring the vernal advancement and retrogradation (green wave effect) of natural vegetation. Prog. Rep. RSC 1978-1. Remote Sens. Center Tex. A&M Univ. Coll. Stn. 1973, 93. [Google Scholar]
- Kauth, R.J.; Thomas, G.S. The Tasselled-Cap—A Graphic Description of the Spectral-Temporal Development of Agricultural Crops as Seen by Landsat. In Proceedings of the Symposium on Machine Processing of Remotely Sensed Data, West Lafayette, IN, USA, 29 June–1 July 1976; Purdue University: West Lafayette, IN, USA, 1976; pp. 41–51. [Google Scholar]
- Crist, E.P. A TM tasseled cap equivalent transformation for reflectance factor data. Remote Sens. Environ. 1985, 17, 301–306. [Google Scholar] [CrossRef]
- Huete, A.R. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Chen, X.L.; Zhao, H.M.; Li, P.X.; Yin, Z.Y. Remote sensing image-based analysis of the relationship between urban heat island and land use/cover changes. Remote Sens. Environ. 2006, 104, 133–146. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalized difference water index (NDWI) to enhanced open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Hall-Beyer, M. Practical guidelines for choosing GLCM textures to use in landscape classification tasks over a range of moderate spatial scales. Int. J. Remote Sens. 2017, 38, 1312–1338. [Google Scholar] [CrossRef]
- Filipponi, F. Sentinel-1 GRD preprocessing workflow. Multidiscip. Digit. Publ. Inst. Proc. 2019, 18, 11. [Google Scholar]
- Dong, P.; Chen, Q. LiDAR Remote Sensing and Applications; CRC Press Taylor & Francis Group: Boca Raton, FL, USA, 2018; p. 200. [Google Scholar] [CrossRef]
- IGN. Plan Nacional de Ortofotografía. 2019. Available online: https://pnoa.ign.es/ (accessed on 15 April 2021).
- IGN. Centro de Descargas del Centro Nacional de Información Geográfica. 2021. Available online: https://centrodedescargas.cnig.es/CentroDescargas/index.jsp (accessed on 2 November 2022).
- IGN. Modelo Digital del Terreno Con Paso de Malla de 5 m. 2020. Available online: https://centrodedescargas.cnig.es/CentroDescargas/documentos/MDT05_recursos.zip (accessed on 1 February 2021).
- Hopkins, B.; Skellam, J. A new method for determining the type of distribution of plant individuals. Ann. Bot. 1954, 18, 213–227. [Google Scholar] [CrossRef]
- YiLan, L.; RuTong, Z. Clustertend: Check the Clustering Tendency; R Package Version 1.4. 2015. Available online: https://cran.r-project.org/web/packages/clustertend/ (accessed on 31 December 2021).
- Charrad, M.; Ghazzali, N.; Boiteau, V.; Niknafs, A. NbClust: An R package for Determining the Relevant Number of Clusters in a Data Set. J. Stat. Softw. 2014, 61, 36. [Google Scholar] [CrossRef] [Green Version]
- Lloyd, C. Spatial Data Analysis: An Introduction for GIS Users; Oxford University Press: Oxford, UK, 2010; p. 206. [Google Scholar]
- Baddeley, A.; Rubak, E.; Turner, R. Spatial Point Patterns: Methodology and Applications with R; Chapman and Hall/CRC Press: London, UK, 2015; p. 810. [Google Scholar] [CrossRef]
- Alonso-Sarria, F.; Valdivieso-Ros, C.; Gomariz-Castillo, F. Isolation Forests to Evaluate Class Separability and the Representativeness of Training and Validation Areas in Land Cover Classification. Remote Sens. 2019, 11, 3000. [Google Scholar] [CrossRef]
- Hamamura, C. tabularMLC: Tabular Maximum Likelihood Classifier; R Package Version 0.0.3; 2021. Available online: https://cran.r-project.org/web/packages/tabularMLC/ (accessed on 31 December 2021).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer Texts in Statistics; Springer New York: New York, NY, USA, 2013; Volume 103, p. 426. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. The randomforest package. R News 2002, 2, 18–22. [Google Scholar]
- Ghimire, B.; Rogan, J.; Rodríguez-Galiano, V.; Panday, P.; Neeti, N. An Evaluation of Bagging, Boosting, and Random Forests for Land-Cover Classification in Cape Cod, Massachusetts, USA. GIScience Remote Sens. 2012, 49, 623–643. [Google Scholar] [CrossRef]
- Rodríguez-Galiano, V.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J. An Assessment of the Effectiveness of a Random Forest Classifier for Land-Cover Classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Cánovas-García, F.; Alonso-Sarría, F.; Gomariz-Castillo, F.; Oñate-Valdivieso, F. Modification of the random forest algorithm to avoid statistical dependence problems when classifying remote sensing imagery. Comput. Geosci. 2017, 103, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Maxwell, A.; Warner, T.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Camps-Valls, G.; Bruzzone, L.E. Kernel Methods for Remote Sensing Data Analysis; John Wiley & Sons, Ltd.: Chichester, UK, 2009. [Google Scholar]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Karatzoglou, A.; Smola, A.; Hornik, K.; Zeileis, A. kernlab—An S4 Package for Kernel Methods in R. J. Stat. Softw. 2004, 11, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Caputo, B.; Sim, K.; Furesjo, F.; Smola, A. Appearance–Based Object Recognition Using SVMs: Which Kernel Should I Use? In Proceedings of the NIPS Workshop on Statistical Methods for Computational Experiments in Visual Processing and Computer Vision; dos Santos, E.M., Gomes, H.M., Eds.; IEEE Computer Society: Los Alamitos, CA, USA, 2002. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Bergmeir, C.; Benítez, J.M. Neural Networks in R Using the Stuttgart Neural Network Simulator: RSNNS. J. Stat. Softw. 2012, 46, 1–26. [Google Scholar] [CrossRef]
- Kuhn, M. Caret: Classification and Regression Training; R Package Version 6.0-93. 2022. Available online: https://cran.r-project.org/web/packages/caret/ (accessed on 31 December 2022).
- Stehman, S.V.; Foody, G.M. Key issues in rigorous accuracy assessment of land cover products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Foody, G. Explaining the unsuitability of the kappa coefficient in the assessment and comparison of the accuracy of thematic maps obtained by image classification. Remote Sens. Environ. 2020, 239, 111630. [Google Scholar] [CrossRef]
- Stehman, S.; Wickham, J. A guide for evaluating and reporting map data quality: Affirming Shao et al. “Overselling overall map accuracy misinforms about research reliability”. Landsc. Ecol. 2020, 35, 1263–1267. [Google Scholar] [CrossRef] [PubMed]
- O’brien, R.M. A caution regarding rules of thumb for variance inflation factors. Qual. Quant. 2007, 41, 673–690. [Google Scholar] [CrossRef]
- Murray, L.; Nguyen, H.; Lee, Y.F.; Remmenga, M.D.; Smith, D.W. Variance inflation factors in regression models with dummy variables. In Proceedings of the 24th Conference on Applied Statistics in Agriculture, Manhattan, KS, USA, 29 April–1 May 2012; Song, W., Gadbury, G.L., Eds.; Kansas State University, New Prairie Press: Manhattan, KS, USA, 2012; pp. 161–177. [Google Scholar] [CrossRef] [Green Version]
- Chatziantoniou, A.; Psomiadis, E.; Petropoulos, G. Co-Orbital Sentinel 1 and 2 for LULC Mapping with Emphasis on Wetlands in a Mediterranean Setting Based on Machine Learning. Remote Sens. 2017, 9, 1259. [Google Scholar] [CrossRef] [Green Version]
- Singh, K.K.; Vogler, J.B.; Shoemaker, D.A.; Meentemeyer, R.K. LiDAR-Landsat data fusion for large-area assessment of urban land cover: Balancing spatial resolution, data volume and mapping accuracy. ISPRS J. Photogramm. Remote Sens. 2012, 74, 110–121. [Google Scholar] [CrossRef]
- Peña-Barragán, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef]
- Carreño Fructuoso, M.F. Seguimiento de los Cambios de Usos y su Influencia en las Comunidades y Hábitats Naturales en la Cuenca del Mar Menor, 1988–2009. con el uso de SIG y Teledetección. Ph.D. Thesis, Universidad de Murcia, Murcia, Spain, 2015. [Google Scholar]
- Ruiz, J.; Albentosa, M.; Aldeguer, B.; Álvarez-Rogel, J.; Antón, J.; Belando, M.; Bernardeau, J.; Campillo, J.; Domínguez, J.; Ferrera, I.; et al. Informe de Evolución y Estado Actual del Mar Menor en Relación al Proceso de Eutrofización y Sus Causas; Technical Report; Instituto Español de Oceanografía, Ministerio de Ciencia e Innovación, Gobierno de España: Madrid, Spain, 2020. [Google Scholar]
- Buitrago, M. Las Sanciones por Riego Ilegal Junto al Mar Menor Afectan ya a Más de 4.200 Hectáreas. La Verdad de Murcia. 2021. Available online: https://www.laverdad.es/murcia/sanciones-riego-ilegal-mar-menor-20210716193152-nt.html?ref=https%3A%2F%2Fwww.google.com%2F (accessed on 31 December 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Season | Date | File |
|---|---|---|---|
| S1 (SAR) | Autumn | 8 Nov 2018 | S1B_IW_GRDH_1SDV_20181108T060953_20181108T061018_013509_018FF3_AD05 |
| S1 (SAR) | Winter | 24 Mar 2019 | S1B_IW_GRDH_1SDV_20190224T060950_20190224T061015_015084_01C30C_24BF |
| S1 (SAR) | Early spring | 13 April 2019 | S1B_IW_GRDH_1SDV_20190413T060951_20190413T061016_015784_01DA0A_1C2E |
| S1 (SAR) | Late spring | 19 May 2019 | S1B_IW_GRDH_1SDV_20190519T060952_20190519T061017_016309_01EB1A_8F1C |
| S2 (MSI) | Autumn | 7 Nov 2018 | S2A_MSIL1C_20181107T105231_N0207_R051_T30SXG_20181107T130405 |
| S2 (MSI) | Winter | 25 Feb 2019 | S2A_MSIL1C_20190225T105021_N0207_R051_T30SXG_20190225T125616 |
| S2 (MSI) | Early spring | 11 April 2019 | S2B_MSIL1C_20190411T105029_N0207_R051_T30SXG_20190411T130806 |
| S2 (MSI) | Late spring | 10 June 2019 | S2B_MSIL1C_20190610T105039_N0207_R051_T30SXG_20190610T125046 |
| Band | Central Wavelength S2A (nm) | Bandwidth (nm) | Resolution (m) |
|---|---|---|---|
| B1 AOT | 442.7 | 21 | 60 |
| B2 Blue | 492.4 | 66 | 10 |
| B3 Green | 559.8 | 36 | 10 |
| B4 Red | 664.6 | 31 | 10 |
| B5 NIR | 704.1 | 15 | 20 |
| B6 NIR | 740.5 | 15 | 20 |
| B7 NIR | 782.8 | 20 | 20 |
| B8 NIR | 832.8 | 106 | 10 |
| B8A NIR | 864.7 | 21 | 20 |
| B11 SWIR | 1613.7 | 91 | 20 |
| B12 SWIR | 2202.4 | 175 | 20 |
| Dataset | Variables | Dates |
|---|---|---|
| S1 | VV VH | 8 Nov 2018, 24 Mar 2019, 13 Apr 2019, 19 May 2019 |
| S1 indices | DPSVI | 8 Nov 2018, 24 Mar 2019, 13 Apr 2019, 19 May 2019 |
| S2 | B01 B02 B03 B04 B05 B07 B08 B08A B11 B12 | 7 Nov 2018, 25 Feb 2019, 11 Apr 2019, 10 Jun 2019 |
| S2 indices | NDVI SAVI NDBI MNDWI | 7 Nov 2018, 25 Feb 2019, 11 Apr 2019, 10 Jun 2019 |
| S2 texture | PC1 NDVI Entropy Contrast | 7 Nov 2018, 25 Feb 2019, 11 Apr 2019, 10 Jun 2019 |
| Second angular moment | ||
| LiDAR | ppA ppM ppB ppH ppE mZG mZB mZM | Aug 2018 |
| mZH mZA mZE sZG sZB sZM sZA sZE sZH | ||
| Hv He Nk Nke NvvwCv wCd wDv wDd |
| Id | Class | Description | Polygons | Pixels |
|---|---|---|---|---|
| 1 | Forest | Mediterranean forest | 10 | 1000 |
| 2 | Scrub | Scrubland | 12 | 1200 |
| 3 | Dense tree crops | Fruit and citrus trees | 18 | 1800 |
| 4 | Irrigated grass crops | Mainly horticultural crops | 10 | 1000 |
| 5 | Impermeable | All artificial surfaces | 18 | 1639 |
| 6 | Water | Water bodies, including artificial reservoirs | 12 | 1158 |
| 7 | Bare soil | Uncovered or low-vegetation covered land | 11 | 1055 |
| 8 | Greenhouses | Irrigated crops surfaces under plastics structures | 26 | 2600 |
| 9 | Netting | Irrigated tree and vegetables crops covered by nets | 14 | 1400 |
| Predictors | Model | Accuracy | Acc. 95%CI | Kappa Index | Kappa 95%CI |
|---|---|---|---|---|---|
| S1 | MLC | 0.5725 | 0.5639, 0.5811 | 0.5115 | 0.5017, 0.5213 |
| MLP | 0.5520 | 0.5433, 0.5606 | 0.4840 | 0.4741, 0.4939 | |
| SVM | 0.5557 | 0.5471, 0.5643 | 0.4903 | 0.4804, 0.5001 | |
| RF | 0.5760 | 0.5674, 0.5846 | 0.5113 | 0.5015, 0.5211 | |
| S2 | MLC | 0.6331 | 0.6247, 0.6414 | 0.5807 | 0.5712, 0.5902 |
| MLP | 0.8693 | 0.8633, 0.8751 | 0.8509 | 0.8443, 0.8576 | |
| SVM | 0.8708 | 0.8631, 0.8747 | 0.8527 | 0.8461, 0.8593 | |
| RF | 0.8704 | 0.8645, 0.8762 | 0.8519 | 0.8453, 0.8586 | |
| LiDAR | MLC | 0.4496 | 0.441, 0.4582 | 0.3866 | 0.377, 0.3962 |
| MLP | 0.6173 | 0.6089, 0.6258 | 0.5620 | 0.5524, 0.5716 | |
| SVM | 0.6597 | 0.6515, 0.6679 | 0.6115 | 0.6022, 0.6209 | |
| RF | 0.6992 | 0.6912, 0.7071 | 0.6565 | 0.6474, 0.6655 | |
| Indices | MLC | 0.4683 | 0.4596, 0.4769 | 0.3688 | 0.3586, 0.3791 |
| MLP | 0.8370 | 0.8305, 0.8433 | 0.8141 | 0.8068, 0.8214 | |
| SVM | 0.8540 | 0.8478, 0.8601 | 0.8336 | 0.8266, 0.8405 | |
| RF | 0.8822 | 0.8765, 0.8877 | 0.8656 | 0.8593, 0.8720 | |
| Texture | MLC | 0.4802 | 0.4715, 0.4888 | 0.4161 | 0.4064, 0.4258 |
| MLP | 0.6890 | 0.6809, 0.697 | 0.6445 | 0.6353, 0.6536 | |
| SVM | 0.7238 | 0.716, 0.7315 | 0.6844 | 0.6756, 0.6933 | |
| RF | 0.7507 | 0.7431, 0.7582 | 0.7144 | 0.7058, 0.7229 | |
| S1+S2 | MLC | 0.6300 | 0.6216, 0.6384 | 0.5760 | 0.5665, 0.5856 |
| MLP | 0.8661 | 0.8601, 0.8719 | 0.8473 | 0.8406, 0.8541 | |
| SVM | 0.8682 | 0.8622, 0.874 | 0.8494 | 0.8428, 0.8561 | |
| RF | 0.8793 | 0.8736, 0.8849 | 0.8621 | 0.8556, 0.8685 | |
| S1+LiDAR | MLC | 0.5976 | 0.589, 0.6061 | 0.5475 | 0.5379, 0.557 |
| MLP | 0.7123 | 0.7044, 0.7202 | 0.6701 | 0.6611, 0.6791 | |
| SVM | 0.7239 | 0.7161, 0.7317 | 0.6847 | 0.6759, 0.6935 | |
| RF | 0.7861 | 0.7789, 0.7932 | 0.7554 | 0.7472, 0.7635 | |
| S2+LiDAR | MLC | 0.4563 | 0.4476, 0.4649 | 0.3937 | 0.3841, 0.4033 |
| MLP | 0.8789 | 0.8734, 0.8841 | 0.8611 | 0.8550, 0.8701 | |
| SVM | 0.8669 | 0.8609, 0.8727 | 0.8481 | 0.8414, 0.8548 | |
| RF | 0.8766 | 0.8708, 0.8822 | 0.8591 | 0.8526, 0.8656 | |
| S1+S2+LiDAR | MLC | 0.6147 | 0.6062, 0.6231 | 0.5660 | 0.5565, 0.5755 |
| MLP | 0.8700 | 0.864, 0.8758 | 0.8516 | 0.8449, 0.8582 | |
| SVM | 0.8699 | 0.864, 0.8757 | 0.8515 | 0.8448, 0.8581 | |
| RF | 0.8778 | 0.8721, 0.8835 | 0.8605 | 0.8540, 0.867 | |
| S1+S2+LiDAR+Indices | MLC | 0.5840 | 0.5754, 0.5925 | 0.5267 | 0.517, 0.5364 |
| MLP | 0.8848 | 0.8792, 0.8903 | 0.8686 | 0.8623, 0.8749 | |
| SVM | 0.8707 | 0.8648, 0.8764 | 0.8525 | 0.8458, 0.8591 | |
| RF | 0.8883 | 0.8827, 0.8937 | 0.8725 | 0.8662, 0.8787 | |
| S1+S2+LiDAR+Indices+Texture | MLC | 0.7040 | 0.696, 0.7119 | 0.6611 | 0.6521, 0.6702 |
| MLP | 0.8770 | 0.8712, 0.8826 | 0.8595 | 0.8531, 0.866 | |
| SVM | 0.8853 | 0.8797, 0.8908 | 0.8692 | 0.8629, 0.8755 | |
| RF | 0.8997 | 0.8944, 0.9048 | 0.8856 | 0.8797, 0.8915 |
| Sensor | Autumn | Winter | Spring | Late Spring | Single Image |
|---|---|---|---|---|---|
| S1 | VV, VH | VV, VH | VV, VH | VV, VH | |
| S2 | B01, B03, B05, B07 | B01, B03, B05, B08, B12 | B01, B05, B08, B12 | B01, B03, B06, B12 | |
| B08, B11, B12 | |||||
| indices | SAVI, NDVI | SAVI, NDVI | SAVI, NDVI | NDVI, NDBI | |
| NDBI, MNDWI | NDBI, MNDWI | NDBI, MNDWI | MNDWI | ||
| Texture | PC1_Contr, PC1_SA | NDVI_SA, PC1_SA | NDVI_SA, PC1_SA | NDVI_Contr, PC1_SA | |
| PC1_Contr | PC1_Contr | PC1_Contr | |||
| LiDAR | wDd, sZM, sZG, sZE, | ||||
| sZA, mZM, mZE, mZA |
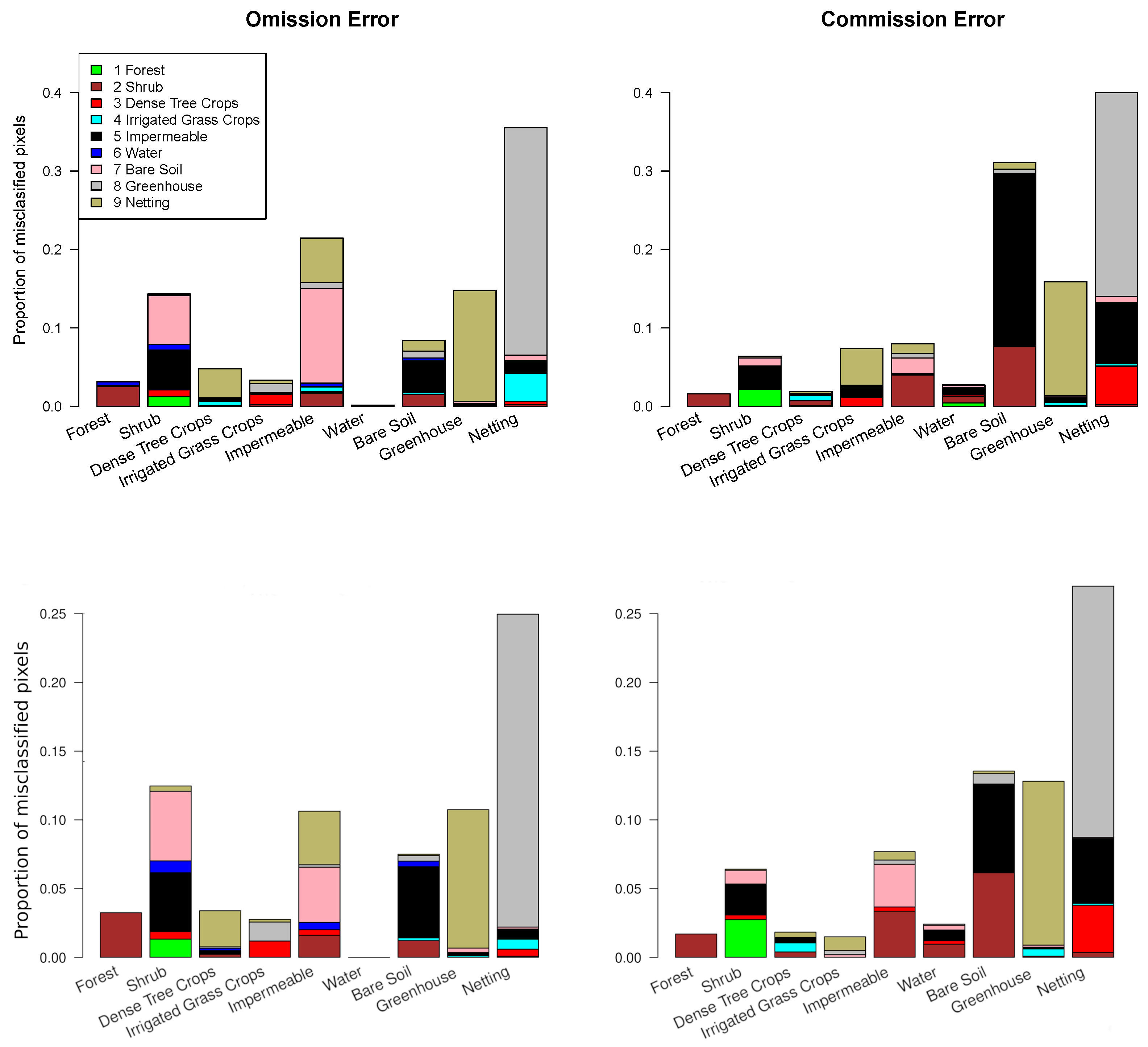
| Features | Error | Forest | Scrub | Dense Tree | Irrig. Grass | Imperm. | Water | Bare Soil | Greenh. | Netting |
|---|---|---|---|---|---|---|---|---|---|---|
| S2 | Omission | 0.032 | 0.143 | 0.048 | 0.033 | 0.215 | 0.002 | 0.084 | 0.148 | 0.355 |
| S2 | Commission | 0.016 | 0.064 | 0.019 | 0.074 | 0.08 | 0.028 | 0.311 | 0.159 | 0.4 |
| Final | Omission | 0.032 | 0.125 | 0.034 | 0.028 | 0.106 | 0.000 | 0.075 | 0.107 | 0.25 |
| Final | Commission | 0.017 | 0.064 | 0.018 | 0.015 | 0.077 | 0.024 | 0.136 | 0.128 | 0.27 |
| Classes | Precision | Recall | Balanced Accuracy |
|---|---|---|---|
| Forest | |||
| Scrub | |||
| Dense tree crops | |||
| Irrigated grass crops | |||
| Impermeable | |||
| Water | |||
| Bare soil | |||
| Greenhouses | |||
| Netting |
| Class | Ha |
|---|---|
| Forest | 2627.78 |
| Scrub | 40,362.55 |
| Dense tree crops | 23,277.19 |
| Irrigated grass crops | 10,893.35 |
| Impermeable | 22,044.31 |
| Water | 16,332.55 |
| Bare soil | 16,752.88 |
| Greenhouse | 3233.16 |
| Netting | 8165.51 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Valdivieso-Ros, C.; Alonso-Sarria, F.; Gomariz-Castillo, F. Effect of the Synergetic Use of Sentinel-1, Sentinel-2, LiDAR and Derived Data in Land Cover Classification of a Semiarid Mediterranean Area Using Machine Learning Algorithms. Remote Sens. 2023, 15, 312. https://doi.org/10.3390/rs15020312
Valdivieso-Ros C, Alonso-Sarria F, Gomariz-Castillo F. Effect of the Synergetic Use of Sentinel-1, Sentinel-2, LiDAR and Derived Data in Land Cover Classification of a Semiarid Mediterranean Area Using Machine Learning Algorithms. Remote Sensing. 2023; 15(2):312. https://doi.org/10.3390/rs15020312
Chicago/Turabian StyleValdivieso-Ros, Carmen, Francisco Alonso-Sarria, and Francisco Gomariz-Castillo. 2023. "Effect of the Synergetic Use of Sentinel-1, Sentinel-2, LiDAR and Derived Data in Land Cover Classification of a Semiarid Mediterranean Area Using Machine Learning Algorithms" Remote Sensing 15, no. 2: 312. https://doi.org/10.3390/rs15020312
APA StyleValdivieso-Ros, C., Alonso-Sarria, F., & Gomariz-Castillo, F. (2023). Effect of the Synergetic Use of Sentinel-1, Sentinel-2, LiDAR and Derived Data in Land Cover Classification of a Semiarid Mediterranean Area Using Machine Learning Algorithms. Remote Sensing, 15(2), 312. https://doi.org/10.3390/rs15020312