4.1. Datasets and Parameters
In this section, a specifically designed synthetic image and two Radarsat-2 single-look SAR images are explored for evaluation. The synthetic SAR image consists of several homogeneous regions and several texture regions. To evaluate the performance of the GCA-CNN under the high noise condition, this image also contains single-look speckle noise.
The synthetic image and the groundtruth is given in
Figure 4a,b. There are eight categories in the synthetic image. The simulated image consists of three kinds of regions: the narrow curving regions, the homogeneous regions and the textured regions. The narrow curving regions are utilized to assess the detail-preserving capability of the algorithms. The homogeneous regions, especially the textured regions, are utilized to estimate the effect of smoothing. The size of this synthetic image is 486 × 486.
To assess the performance of the GCA-CNN on real scenes, two widely used Radarsat-2 SAR images are used. These two images are obtained on the San Francisco Bay area [
16] in America and Flevoland area [
16] in the Netherlands. The formatting of the two SAR datasets is single-look-complex, which means that the speckle noise contained in these two images is single-look. The covariance matrices of these two SAR datasets are obtained and the HH components are used to perform the experiments. For the SanFrancisco-Bay data, a widely used sub-image (1010 × 1160 pixels) is selected for the experiments. There are five kinds of terrain in this sub-image. This sub-image and the ground-truth are illustrated in
Figure 4c,d. For the Flevoland data, a sub-image with the size of 1000 × 1400 pixels is selected for experiments. The sub-images of the Flevoland with the groundtruth are given in
Figure 4e,f, respectively. A TerraSAR-X high-resolution (0.6 m) sub-image obtained from the Lillestroem area is also used for evaluation. This image contains single-look speckle noise and inter-class similarity. Only the HH component is contained in this image. The sub-image and the corresponding groundtruth are given in
Figure 4g,h. The size of this sub-image is 1200 × 1600 pixels.
In the utilized images, all the labeled pixels with a fixed size of neighborhood image patch are explored as the samples. The widely used hold-out method is applied to obtain the training and the testing sets, which means that a part of the samples are randomly selected as the training samples while the other samples are used as the testing samples. In our experiments, in order to verify the performance of the proposed algorithm with a limited amount of training samples, the training set only contains 1000 samples [
28]. To avoid the overlapping of the training and the testing samples, for each dataset 1000 training samples are randomly selected from the labeled samples, while the remaining labeled samples are utilized as the testing samples.
Some parameters of the GCA-CNN network should be determined before experiments. The size of input image patches should be determined first. In the study, the size of the image patches is set to be 27 × 27 pixels according to the previous work [
28]. This size of image patches is determined by experiments in the previous work. The input image patches with too large a size will lead to high time cost and coarse classification results. However, if the size is too small the classification accuracy will be limited due to the lack of spatial neighborhood information.
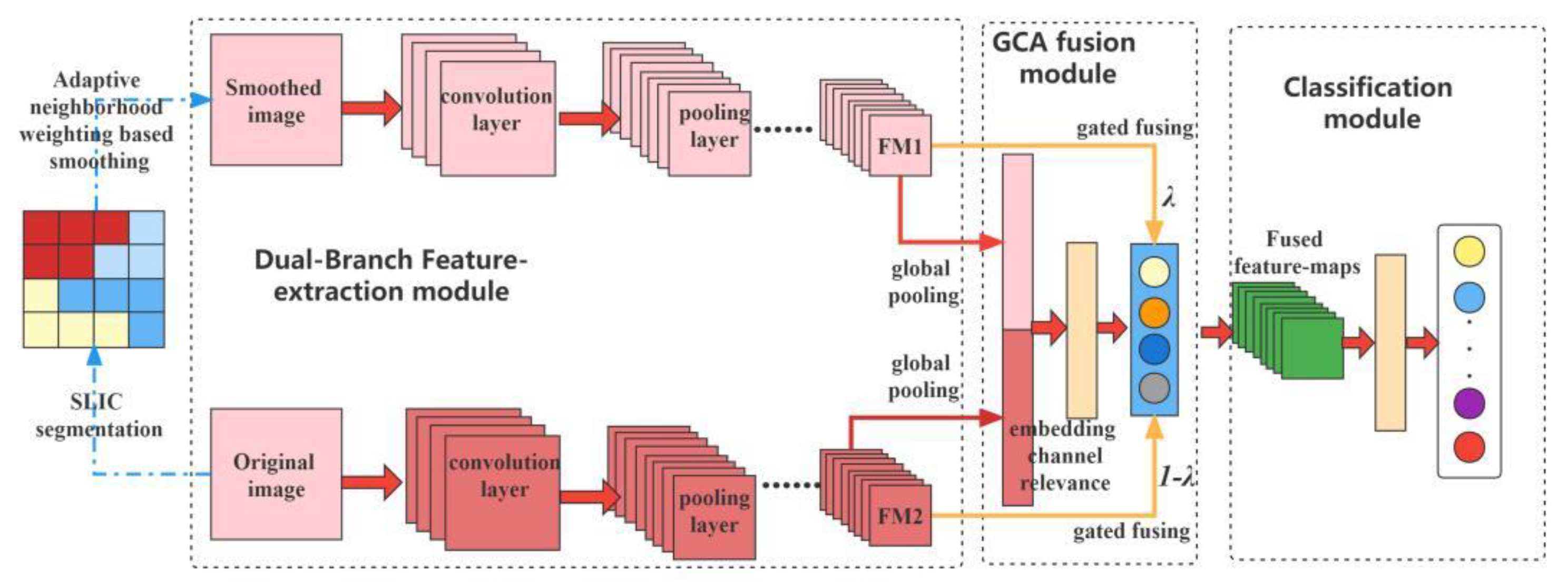
The structural parameters of the feature-extraction module [
29] and the GCA module should then be determined. Structural parameters of the feature-extraction module should be firstly discussed. The feature-extraction module is integrated with a softmax classifier for experiments. To determine how many feature-maps should be included in the convolution layer, the grid researching method is utilized for optimization. According to the work of Zhao et al. [
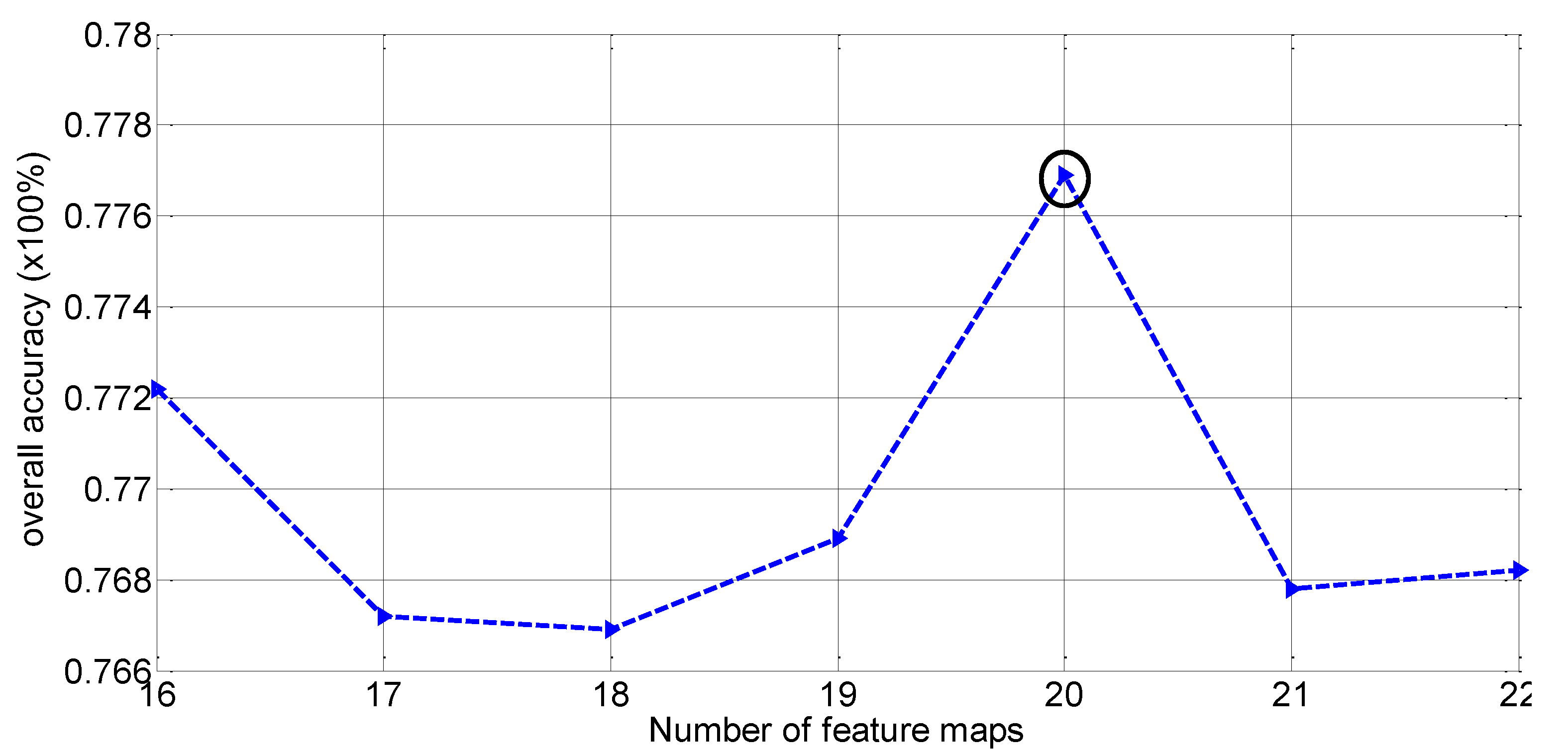
29], each layer owns the same number of feature-maps. The SanFrancisco-Bay SAR image is utilized as the dataset for an example. The results of this optimization are given in
Figure 5, where the optimized value of the number of feature-maps is 20, which indicates a tradeoff between the representing capacity and the redundancy of features. In
Figure 5 the peaks should be caused by the tradeoff between the representing ability and the redundancy of features. With increasing the number of feature-maps from 16 to 18, the redundancy of the features increases. However, the increase in representing ability cannot offset the affect of the redundancy at this time, which leads to the decrease in overall accuracy. When the number of feature-maps increases from 18 to 20, the increasing representing ability is the dominating factor, which leads to the increase in OA. As the number of feature-maps enlarges further, the redundancy plays a more important role, and the OA decreases again. This causes a peak of OA existing at point of 20.
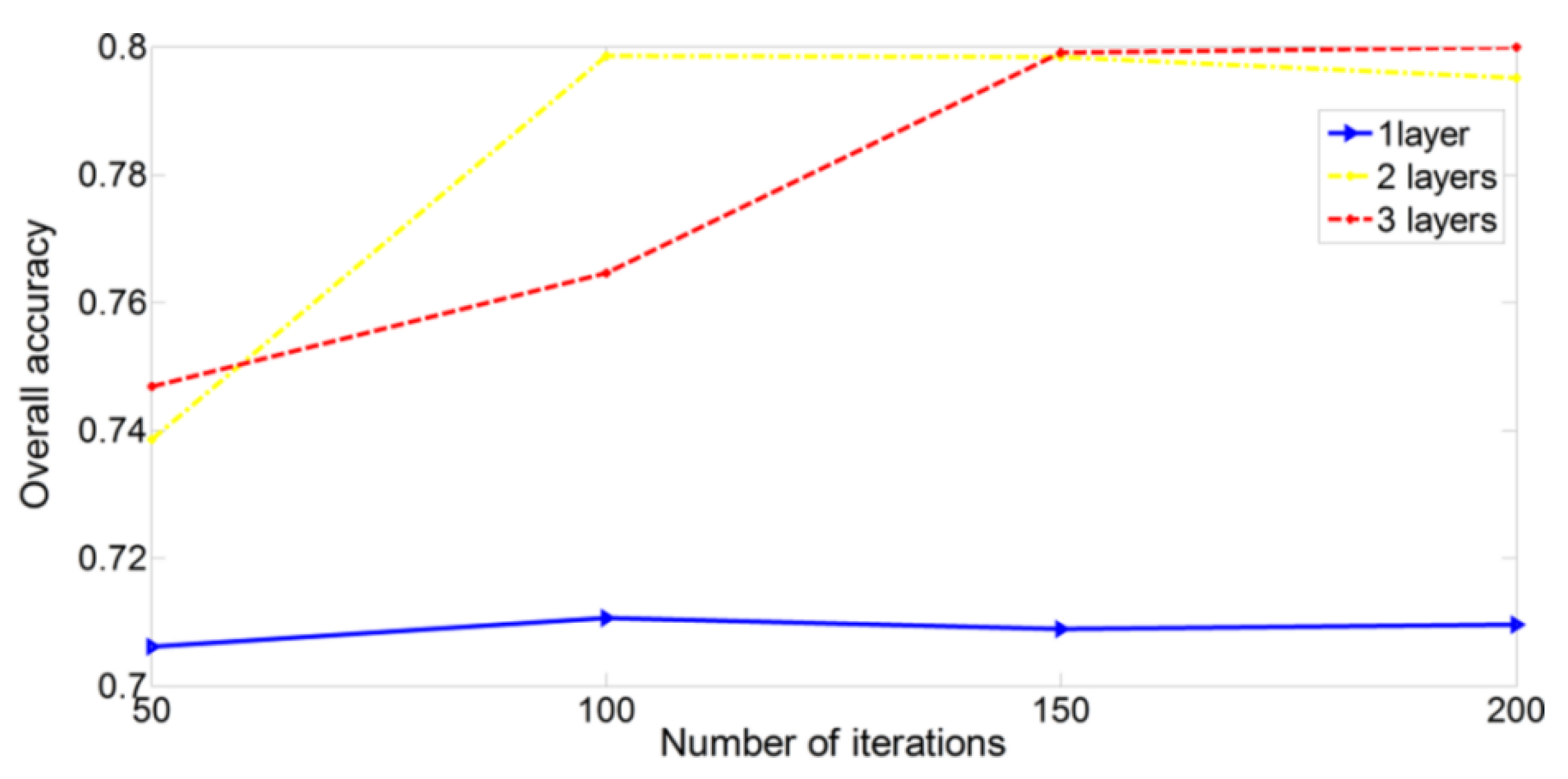
The rest other two parameters, which are the Number Of Iteration (NOI) and the Number Of Layers (NOL), are then optimized. The corresponding results are given in
Figure 6, where the optimized NOL and NOI are selected as 2 and 100 (with overall accuracy of 79.33%). Although the CNN module with 3 layers after 150 iterations can achieve a slightly higher accuracy (80.01%), the time cost is much higher. Note that the same optimizations have also been done on the other two datasets and the same optimized value can be obtained. The kernel size in the first convolution layer is set to be 4 and the kernel size in the second convolution layer is set to be 5. The subsampling scale in the pooling layers is set to be 2.
The structural parameters of the GCA module and the classification module are then optimized. For the GCA module, the number of the fully connected layers is the only structural parameter to be optimized. As the amount of training samples is limited, the number of fully connected layers in the GCA module is set to be 2. The size of the kernels in the first convolution layer is 4 and in the second convolution layer is 5.
In order to evaluate the performance of the proposed algorithm, some conventional algorithms such as the Support Vector Machine (SVM) with radial basis function, Deep Belief Network (DBN) and the Stacked Auto-Encoder (SAE) are explored. To verify the effect of the feature fusing, the CNN with the smoothed image (SI-CNN) and the original image (OI-CNN) as the input are also explored. To verify the reasonableness of using the relevance of channels in the feature fusion, the Gated Heterogeneous Fusion Module (GHFM) proposed by Li et al. [
15] is explored as the relative state-of-the-art algorithm for comparison.
To quantitatively describe the performance of the proposed and compared algorithms, some popular evaluation metrics are explored in this paper. The Overall Accuracy (OA) can be utilized to evaluate the overall classification accuracy of the algorithms. The OA is calculated as follows:
where
Ntotal means the total number of samples contained in the whole testing set, and the
Ncorrect refers to the number of testing samples which are correctly classified. The classification accuracy in each category is then utilized to evaluate the performance of algorithms in each terrain.
4.2. Results on Synthetic Image
This experiment is performed on the synthetic SAR image. The synthetic SAR image is selected because the boundaries between each two categories are known, which can be used for the evaluation of boundary-locating capability of the proposed and compared algorithms. The detail-keeping capability of the tested algorithms can also be evaluated by using the three narrow curving regions in the upper left part of the synthetic image. The right part of the synthetic image is textured regions with single-look speckle noise which can be utilized to verify the effect of super-pixel based smoothing. In this image there are 486 × 486 labeled samples.
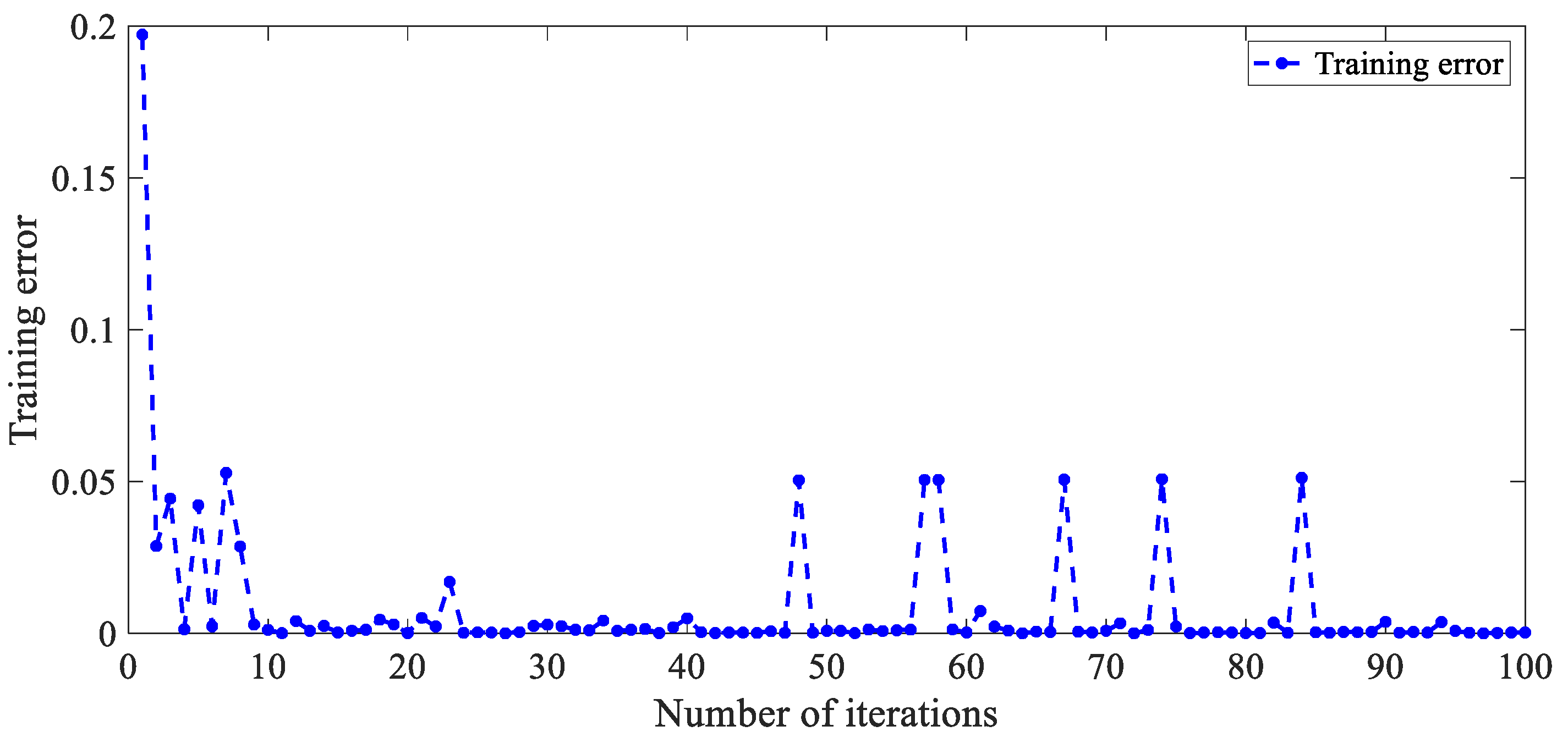
The learning rate of the dual-branches feature-extracted module is experimentally set to be 0.05. The learning rate of the GCA module and the classification module is set to be 0.01. For the DBN, SAE and SVM, the image patches are stretched into feature-vectors to feed into these classifiers. For the SVM, the gamma parameter of kernel is experimentally set to be 0.02 using grid research. The DBN exploited in this paper includes two hidden layers, and both own 100 neurons. The SAE used for comparison has three hidden layers. Each of the first two hidden layers has 200 neurons, while the third layer has 100 neurons. The size of the DBN and SAE are experimentally determined. To verify the reasonableness of the proposed gated channel attention mechanism. The convergence curve of the training error is plotted and demonstrated in
Figure 7. As illustrated in
Figure 7, the training error gradually converges to 0 (The peak values existed during the iteration number between 40 and 85 might be caused by the outlier samples). This result indicates that for an input sample, an optimized value of gated channel attention coefficients which represents the contribution of feature-maps and the relevance between channels can be obtained. The conclusion above demonstrates the existence of a suitable value of gated channel attention coefficients for an input sample, which proves the reasonableness of the gated channel attention mechanism. In
Figure 7, there are some peaks existing in the curve when the training error gradually converges to 0. This can be explained by the training mechanism and the effect of the outliner training samples which are caused by the disturbance of speckle noise. In the explored SGD method 10 samples are randomly selected to form a mini-batch to train the neural network. If the outliner samples are divided into a mini-batch, the updating of the parameters in the GCA-CNN might be wrong, which leads to a small number of peaks in the
Figure 7.
The classification accuracies corresponding to the proposed and the compared algorithms are illustrated in
Table 1. The results shown in
Table 1. The corresponding results in image form are given in
Figure 8. The classification accuracies are also illustrated in
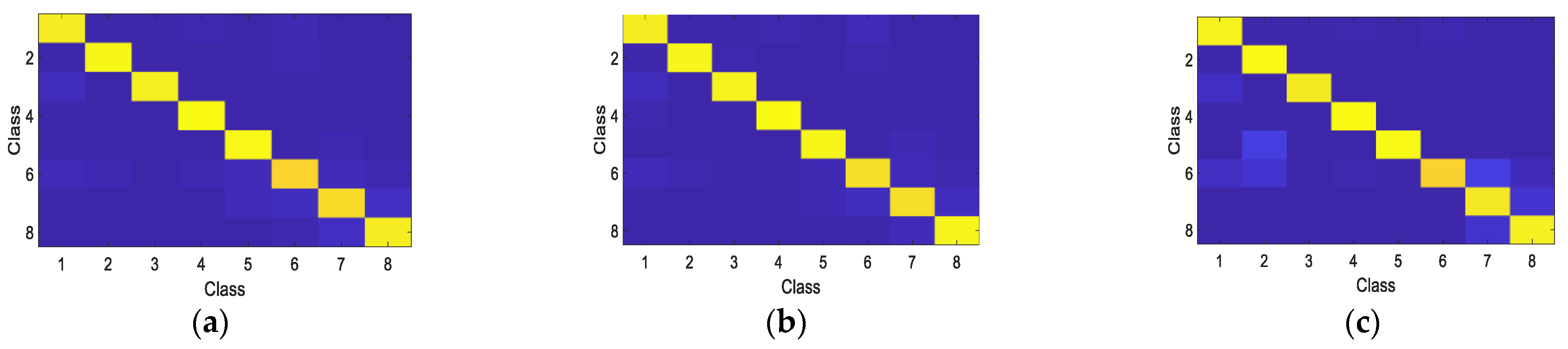
Figure 9 in the form of confusion matrices for better visualization. As shown in
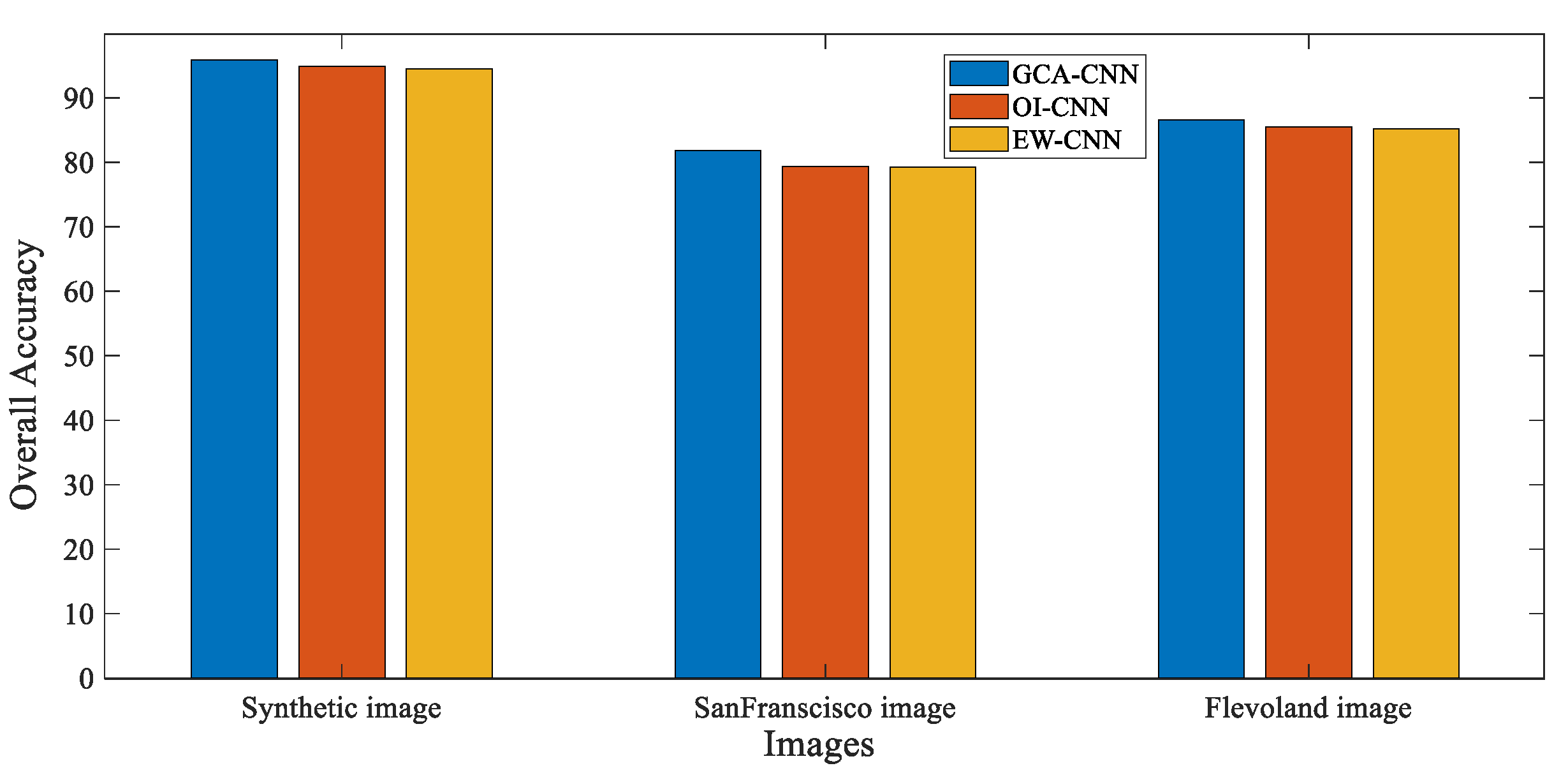
Table 1, the proposed algorithm achieves the highest OA, which demonstrates the superiority of the performance of the GCA-CNN framework.
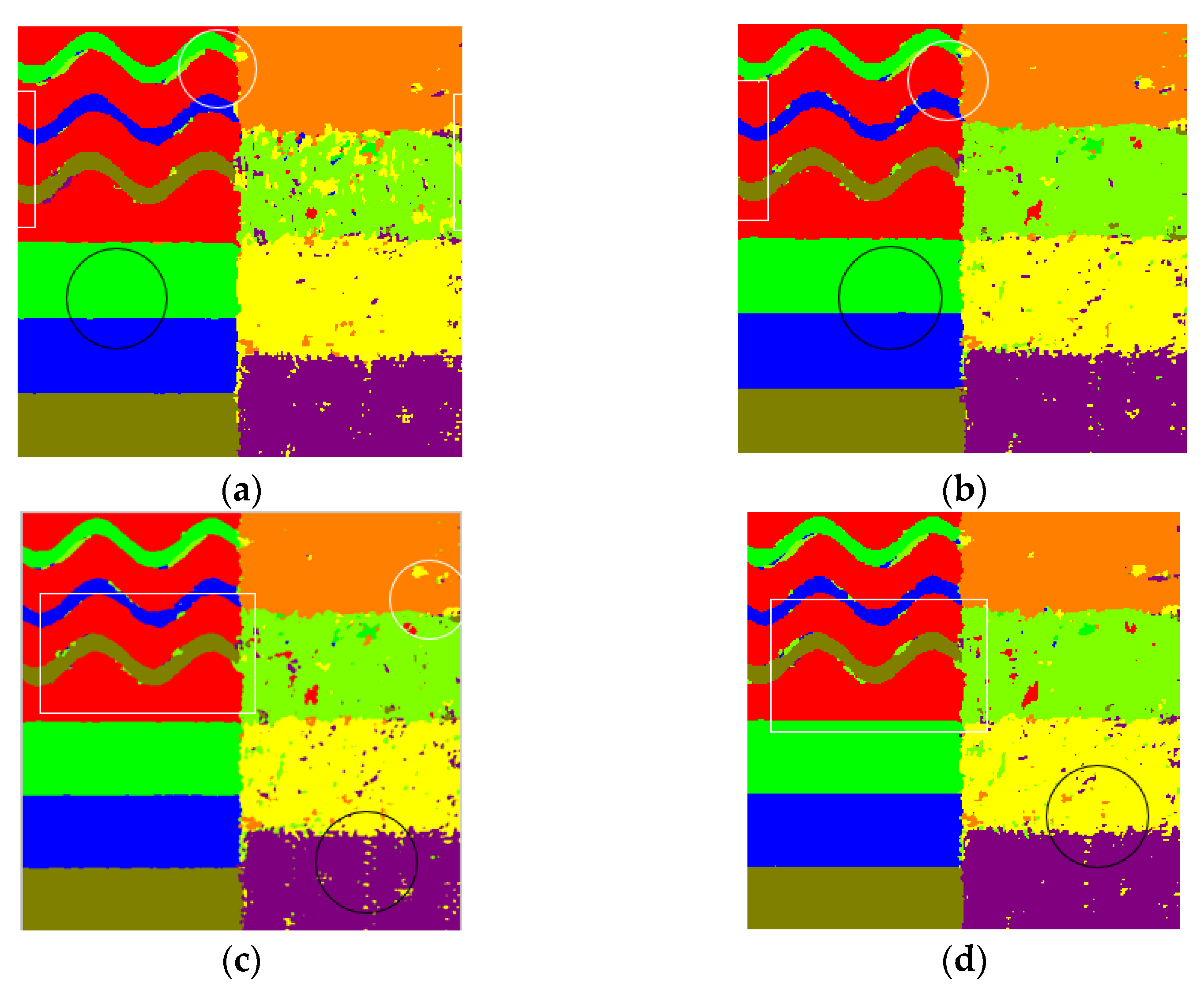
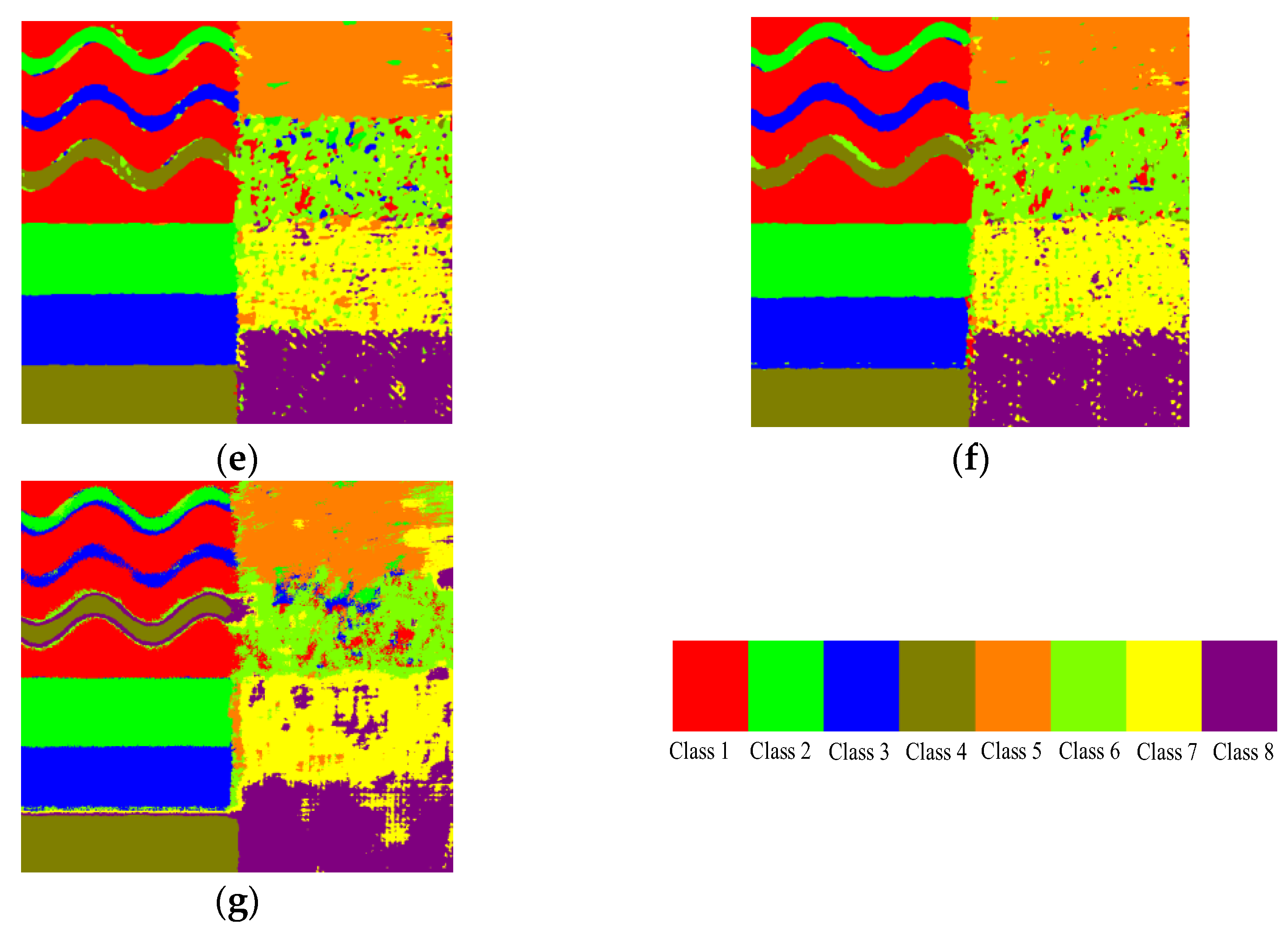
As shown by the results in
Figure 8a, the proposed algorithm shows a combination between the smoothing of misclassification and the detail preserving. Comparing
Figure 8b,c, it can be observed that some misclassification in the textured regions is eliminated by the super-pixel based smooth which takes advantage of the spatial neighborhood information (highlighted by circles). However, the detail preserving is weakened by the smoothing, as highlighted by the rectangles in white lines. By fusing the feature-maps, the smoothing of misclassification and the detail preserving can be complementary with each other to produce a better classification result. For the GHFM-CNN, the effect of fusing can be observed on the classification results. By comparing with
Figure 8b,c, the fusing of smoothing of misclassification (highlighted by circles) and the detail keeping (highlighted by rectangles) can be seen on
Figure 8d. However, by comparing
Figure 8d with
Figure 8a it can be observed that the smoothing of misclassification and the detail keeping of the GHFM-CNN are less effective than those of GCA-CNN. This result indicates that the proposed GCA fusion module is more effective than GHFM because of utilizing the relevance between channels. The DBN, SAE and SVM show much lower classification accuracy than the CNN because these classifiers are sensitive to speckle noise. The GHFM-CNN algorithm achieves the secondly highest overall accuracy, which indicates that utilizing the relevance between channels is effective for improving the classification accuracy.
In the results maps of these classifiers, there are a large number of misclassified points caused by the disturbance of speckle noise. The DBN, SAE and SVM receive the feature-vectors as input; however, the spatial correlation will be destroyed by stretching the image patches into feature-vectors which leads to the decline of immunity to noise.
However, the proposed GCA-CNN cannot outperform the compared algorithms for all categories. This can be explained by the mechanism of feature fusion. In some conditions, the feature maps extracted from the original image and the smoothed image cannot be complementary with each other. Consequently, the feature fusion will bring feature redundancy, which will lead to a reduction in classification accuracy. Because of this, the GCA-CNN cannot outperform the OI-CNN and the SI-CNN for some categories (such as class 2 and class 4). From another aspect, the training strategy in this paper tends to find the highest overall accuracy for all the explored algorithms. Consequently, the proposed GCA-CNN can outperform the other algorithms on OA but cannot achieve superiority on some categories.
4.3. Results on SanFrancisco-Bay SAR Image
To further prove the superiority of GCA-CNN, the SanFrancisco-Bay SAR image with a high level of noise is explored. For the terrains contained in this image, the homogeneous regions and the boundary regions are included. The homogeneous and boundary regions are mixed to evaluate the fusion effect of smoothing the misclassification and detail keeping. In the explored SAR image there are totally 717,099 samples labeled, and 1000 samples are used as the training samples.
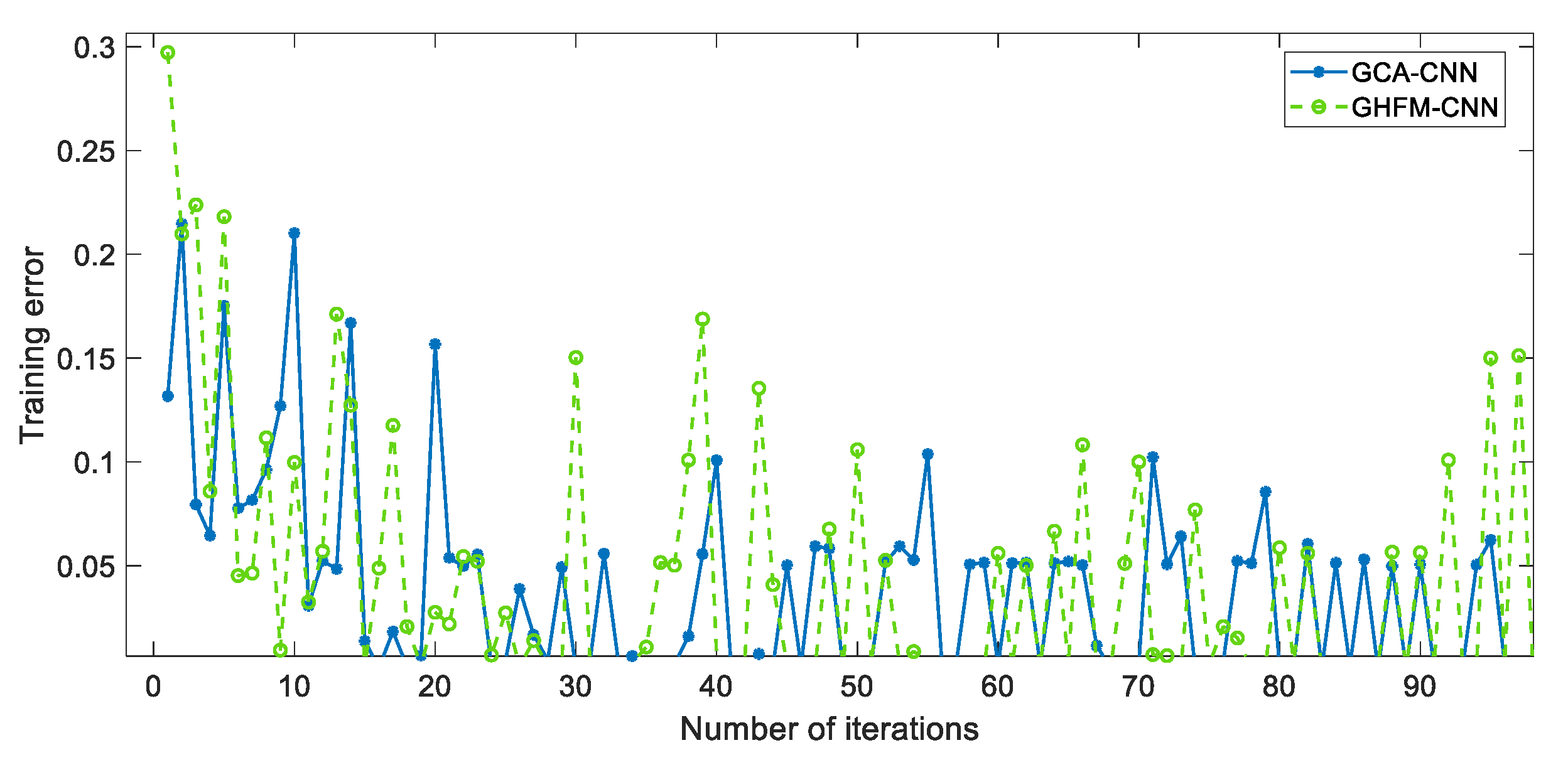
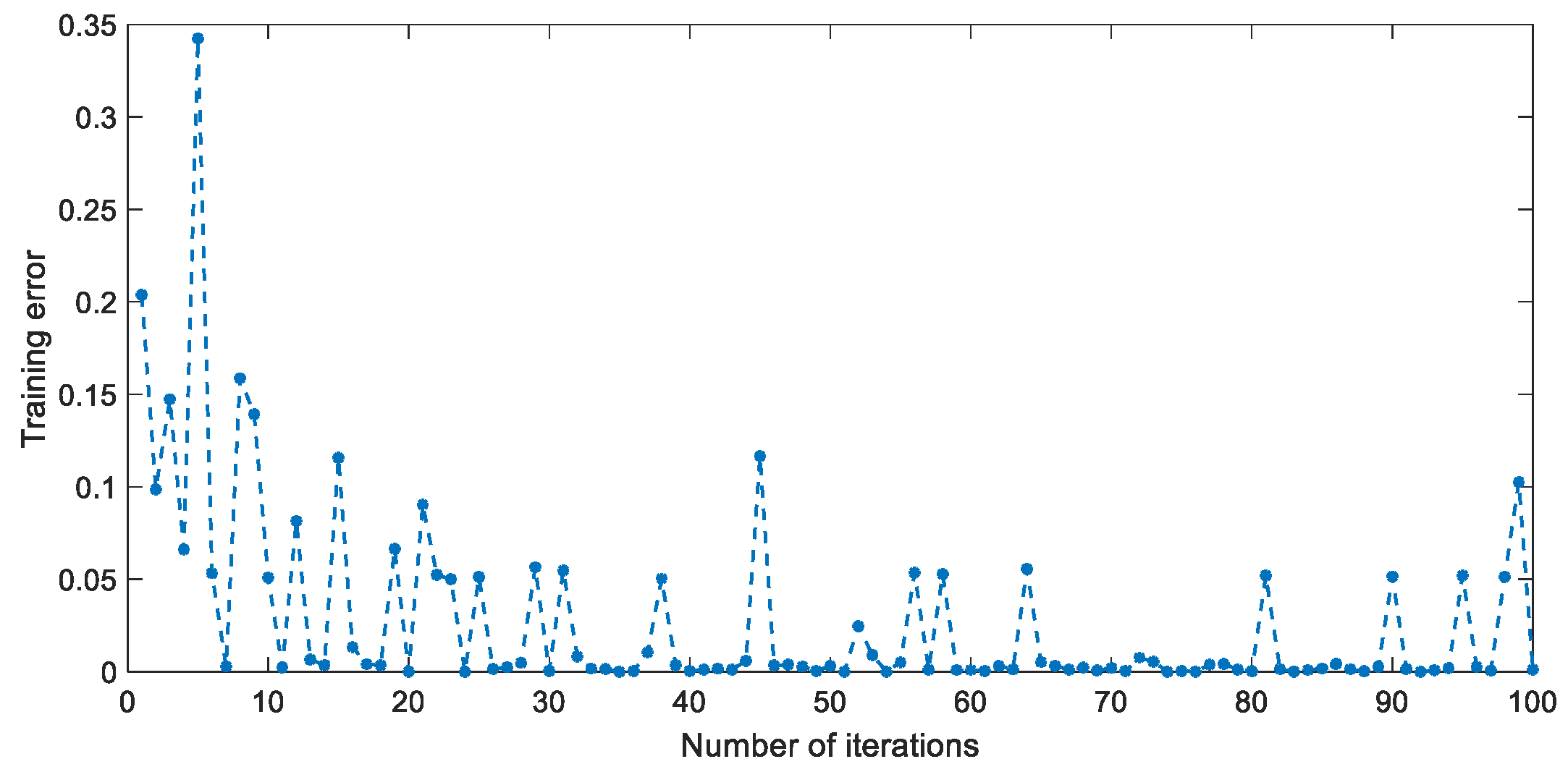
The learning rate of the feature-extraction network of GCA-CNN is also set to be 0.05, while that of the classification network is also experimentally set to be 0.01, which demonstrates the robustness of the parameters of the GCA-CNN framework. The learning rates of CNN are also set to be 0.05. To prove the reasonableness of the proposed gated channel attention coefficients on the real SAR image, the converging curve of the training error as the function of the number of iterations is shown in
Figure 10. As given in
Figure 10, that training error gradually converges to nearly zero on the real SAR image with high-level noise. This result indicates that the suitable gated channel attention coefficients can be found for a couple of input image-patches, which proves the reasonableness of the proposed gated channel attention mechanism.
For
Figure 10, there is a series of alternations of peaks and valleys in the training error curve of the GCA-CNN. This can be explained by the high level of speckle noise and the inter-class similarity on the training samples. Because of these disturbances, the parameters of the GCA cannot converge to the optimized value but wander around the optimized parameters. This mechanism leads to the massive peaks in
Figure 10. The OAs and the accuracies for each category of the proposed and compared algorithms are listed in
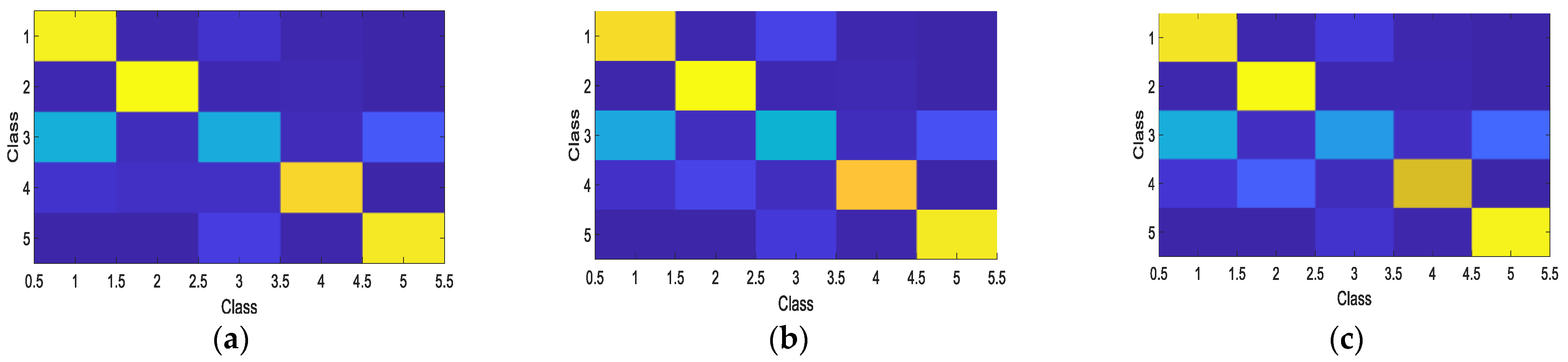
Table 2 for comparison. For better visualization, the corresponding confusion matrices of the GCA-CNN, GHFM-CNN and the OI-CNN are given in
Figure 11. In
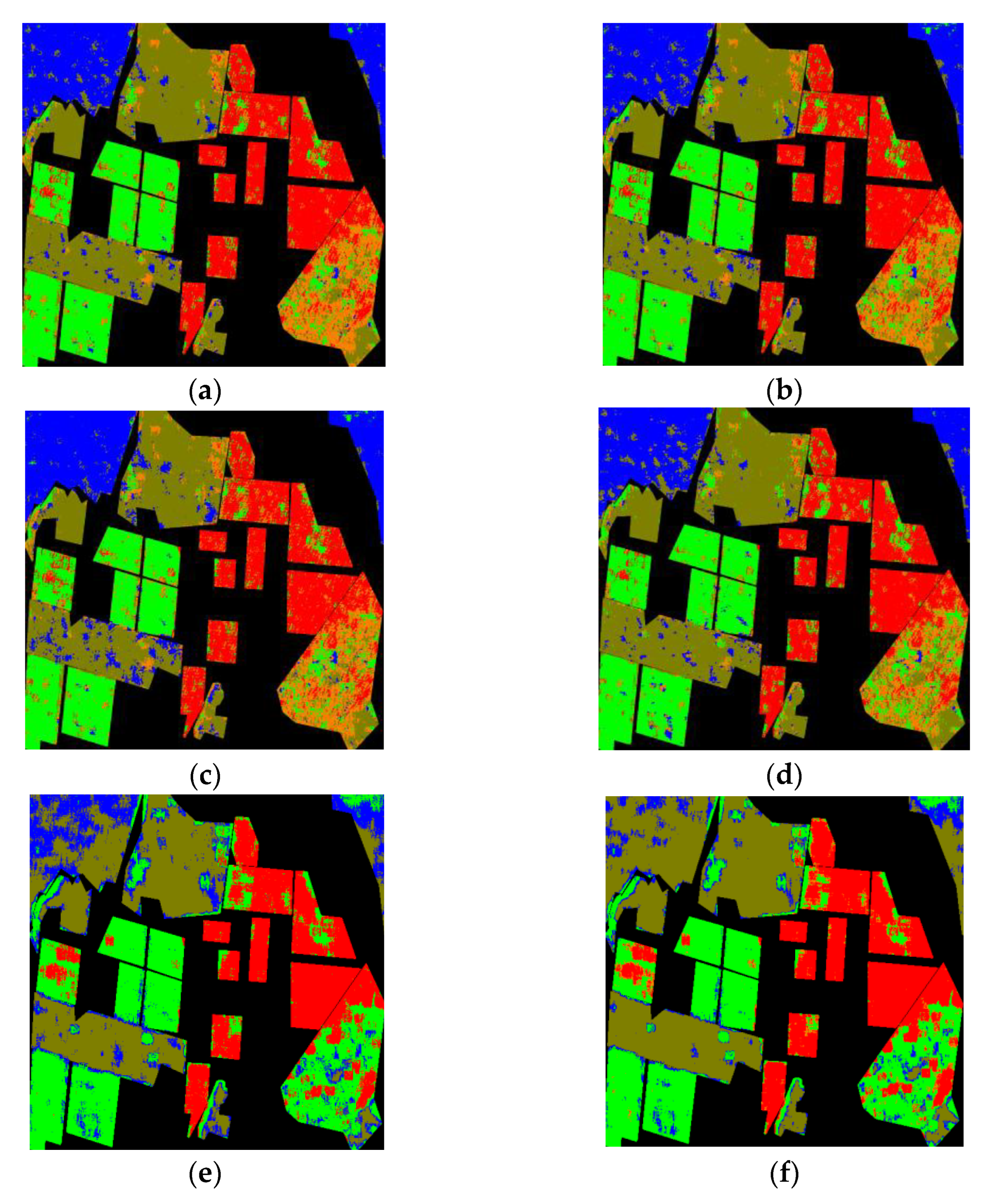
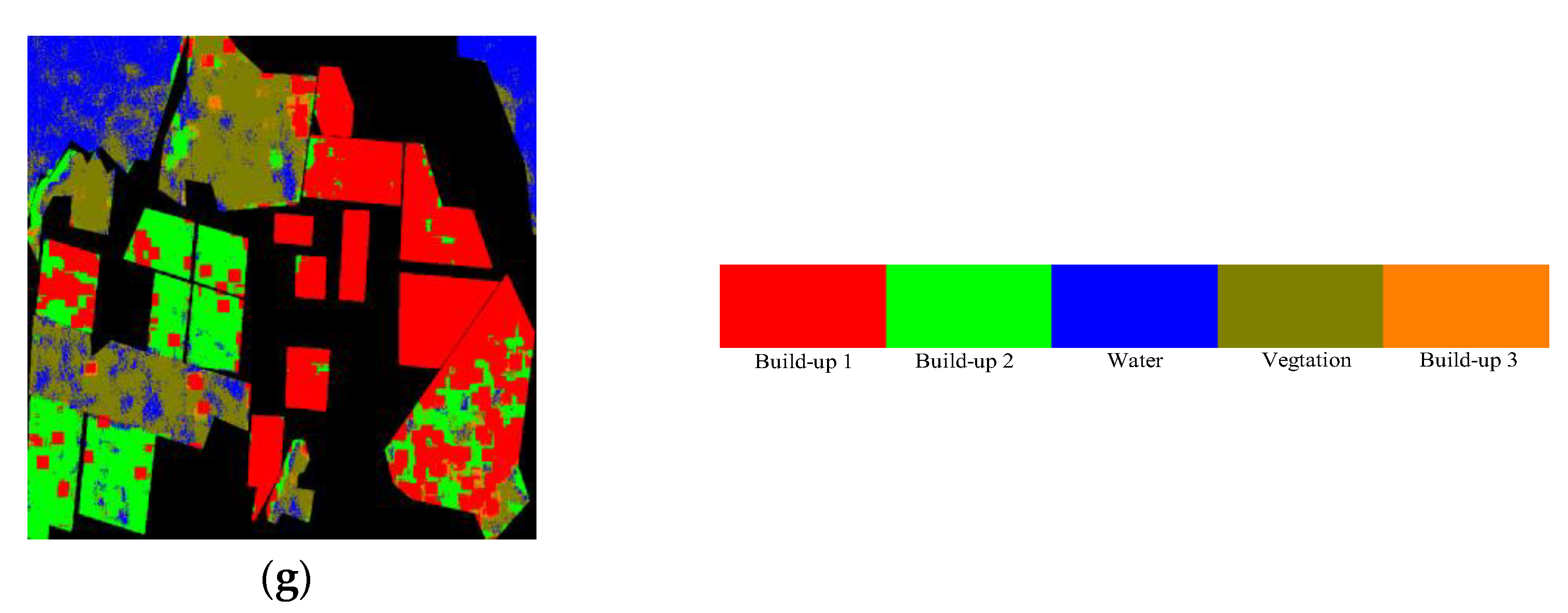
Figure 12, the result maps of all the algorithms are illustrated. In
Table 2, it can be observed that the proposed GCA-CNN still achieves the highest OA (81.38%), which demonstrates the superiority of the proposed algorithm over the compared algorithms on the real SAR image. The CNN algorithm with smoothed, and the original SAR image as the input obtains the second and third highest OAs. This result indicates that the superiority of the proposed GCA-CNN derives from the adaptive fusion of
FM1 and
FM2. However, the GHFM-CNN achieves even lower accuracy than the CNN.
This is because the GHFM-CNN contains more parameters than the GCA-CNN, which can lead to over-fitting with limited training samples. As the real SAR image contains high-level noise and more complex features of terrains than the synthetic SAR image, the limited training samples are not enough to optimize the GHFM-CNN. This conclusion can be demonstrated by the converging curve shown in
Figure 12. The superiority of GCA-CNN is supported by the classification result map of it (shown in
Figure 11a), which shows a combination between smoothing of speckle noise and detail keeping. Comparing
Figure 12a with
Figure 12b, it can be seen that some isolated misclassified pixels or regions (especially for built-up 3) are eliminated in
Figure 12a. This result proves that the smoothing within the super-pixel is effective. Comparing
Figure 12a with
Figure 12c, there is a conclusion that the superiority of the proposed algorithm derives from the detail keeping. As highlighted by the rectangles in white curves that more details are kept by the GCA-CNN. The classifcation results and the analysis above proved the reasonability of the fusion between
FM1 and
FM2.
For the algorithms which take the feature vector as the input (SAE, DBN and SVM), the corresponding OAs are much lower than those of CNN because these algorithms are vulnerable to noise. The expanding of the 2D image patch into 1D feature vector destroys the spatial correlations between the pixels, which results in lower immunity to noise. As shown in the classification result maps of these algorithms, a lot of misclassified pixels exist which demonstrates the interference of speckle noise.
It should be noted that the DBN, SAE and SVM achieve much higher accuracy on the terrain of build-up 1 than the GCA-CNN. This can be explained by the fact that these three classifiers are not capable enough to discriminate the build-up 1 and the similar terrains. It can be seen from the classification results that the build-up 1 is similar to the build-up 2 and the build-up 3. In addition, these three classifiers show a tendency to classify these terrains into build-up 1. As a result, the DBN, SAE and the SVM show much higher accuracy on build-up 1 than the GCA-CNN.
4.4. Results on Flevoland SAR Image
The Flevoland image is utilized to assess the robustness of GCA-CNN when the level of noise is lower. The terrains contained in the Radarsat-2 Flevoland SAR are less complex than those of SanFrancisco-Bay image, which leads to higher classification accuracy with limited training samples. This experiment explores the Flevoland SAR image to test whether the GCA-CNN can improve the classification accuracy on the SAR image which is easier to be classified. The Flevoland image contains five kinds of terrains. This image contains 539,507 labeled samples, and 1000 samples are selected in a random way to form the training set while the other labeled samples form the testing set.
The learning rate of the feature-extraction network is also experimentally set to be 0.05 while that of the classification network is still set to be 0.01. This result indicates that the parameters of the GCA-CNN framework are robust in different scenes. The learning rate of the CNN is experimentally optimized as 0.05. Structural parameters of the SAE and DBN are kept unchanged. The learning rates of SAE and DBN are experimentally set to be 0.03 and 0.05. To prove the robustness of the proposed GCA fusion module, the converging curve of the training error GCA-CNN on the Flevoland SAR image is illustrated in
Figure 13. It can be seen in
Figure 13 that the training error gradually converges to zero, which demonstrates the robustness and the reasonableness of the proposed GCA mechanism.
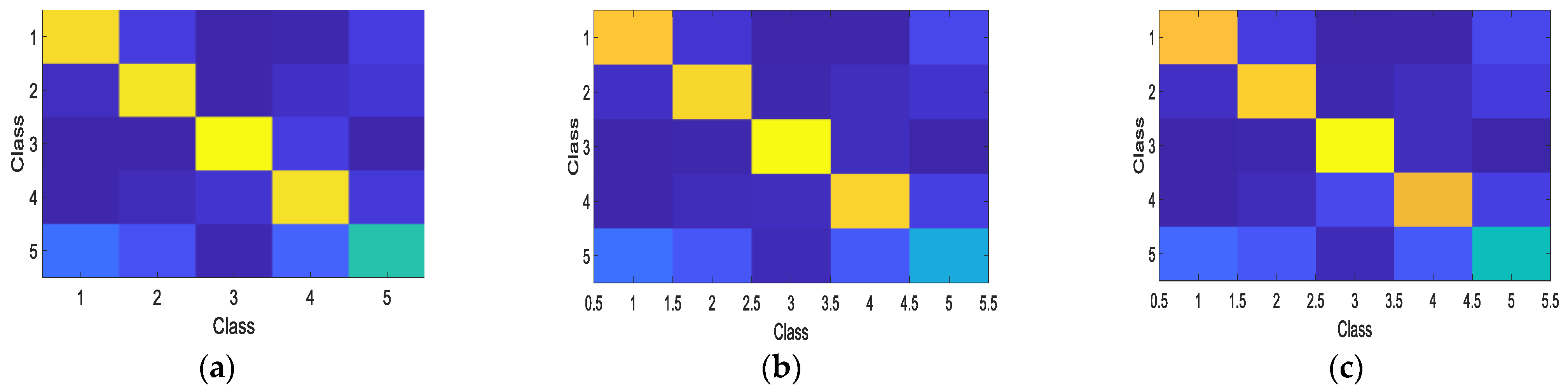
The OAs and the accuracies of all categories of terrains of the proposed and the compared algorithms are given in
Table 3. The accuracies shown in
Table 3 are illustrated in
Figure 14 in the form of confusion matrices for more intuitive visualization. The results of these algorithms are given in
Figure 15 for analysis. The GCA-CNN still achieves the highest OA. However, the improvement in OA brought by GCA-CNN is less obvious because the Flevoland SAR image is easier to be classified. The OAs obtained by the CNN with the original and smoothed SAR image as input are the second and third highest. Different from the other experiments, the CNN with the original image as the input image achieves higher OA than that with smoothed image as the input. This is because the interclass similarity caused by the speckle noise is lower than that of the synthetic SAR image and the SanFrancisco-Bay SAR image. The conclusion can be supported by the fact that the misclassified regions caused by the speckle noise existing in Flevoland image are much fewer than those in the SanFrancisco image.
As a result, in this real SAR image the detail keeping is more important than the smoothing of speckle because the noise level in this image is relatively lower. However, the super-pixel based smoothing may damage the details in the SAR image. Consequently, the CNN algorithm with the original image as the input obtains the higher OA.
The classification accuracy of GHFM-CNN is still lower than that of CNN because of the overfitting. The result demonstrates the superiority of the GCA module over the GHFM module. Firstly, the proposed GCA module explored the relevance between the channels of feature-maps, which is not considered by the GHFM. Secondly, the structure of GCA is simpler than that of GHFM, which leads to less parameters. As a result, the parameters of the GCA module can be trained with limited training samples. The DBN, SAE, SVM achieve lower overall accuracy than CNN and because of that these frameworks are vulnerable to speckle noise.
4.5. Results on TerraSAR-X SAR Image
The TerraSAR-X image with a high resolution of 0.6m is explored to evaluate the performance of the proposed GCA-CNN. This image contains three kinds of terrain, which are the forest, grass and the river. This image is used to evaluate the performance of the GCA-CNN on the high-resolution SAR image. The learning rates of the GCA module and the other parts of the GCA-CNN are set to be 0.01 and 0.05. For fair comparison, 1000 labeled samples are randomly selected for the training of GCA-CNN while the other labeled samples are left for the testing. The learning rate of the CNN is experimentally optimized as 0.05.
The experimental results of the GCA-CNN and the compared algorithms are given in
Table 4. The DBN, SAE and the SVM are vulnerable to speckle noise, which leads to low classification accuracies. The classification results of these algorithms are not listed for discussion. The corresponding confusion matrices are shown in
Figure 16a for better visualization. For the sake of comparison, the accuracies are listed on the confusion matrices. The accuracies of the explored algorithms are then discussed according to result-maps. The mechanism of the combination of gated and channel attention is also discussed. From
Table 4, it can be seen that the GCA-CNN can still achieve the highest classification accuracy among the explored algorithms in the high resolution image. As this image contains massive speckle noise and terrains with high inter-class similarity (such as the river), the proposed algorithm brings more than 3% improvement in the overall accuracy. This result demonstrates that the proposed GCA-CNN is effective for the classification of high-resolution SAR images with massive speckle noise. The GHFM-CNN based algorithms still reach the second highest overall accuracy, which demonstrates the superiority of the GCA-based fusion strategy. The super-pixel based smoothing also brings nearly 2% improvement in overall accuracy, which is caused by the high-level speckle noise in the TerraSAR-X image.
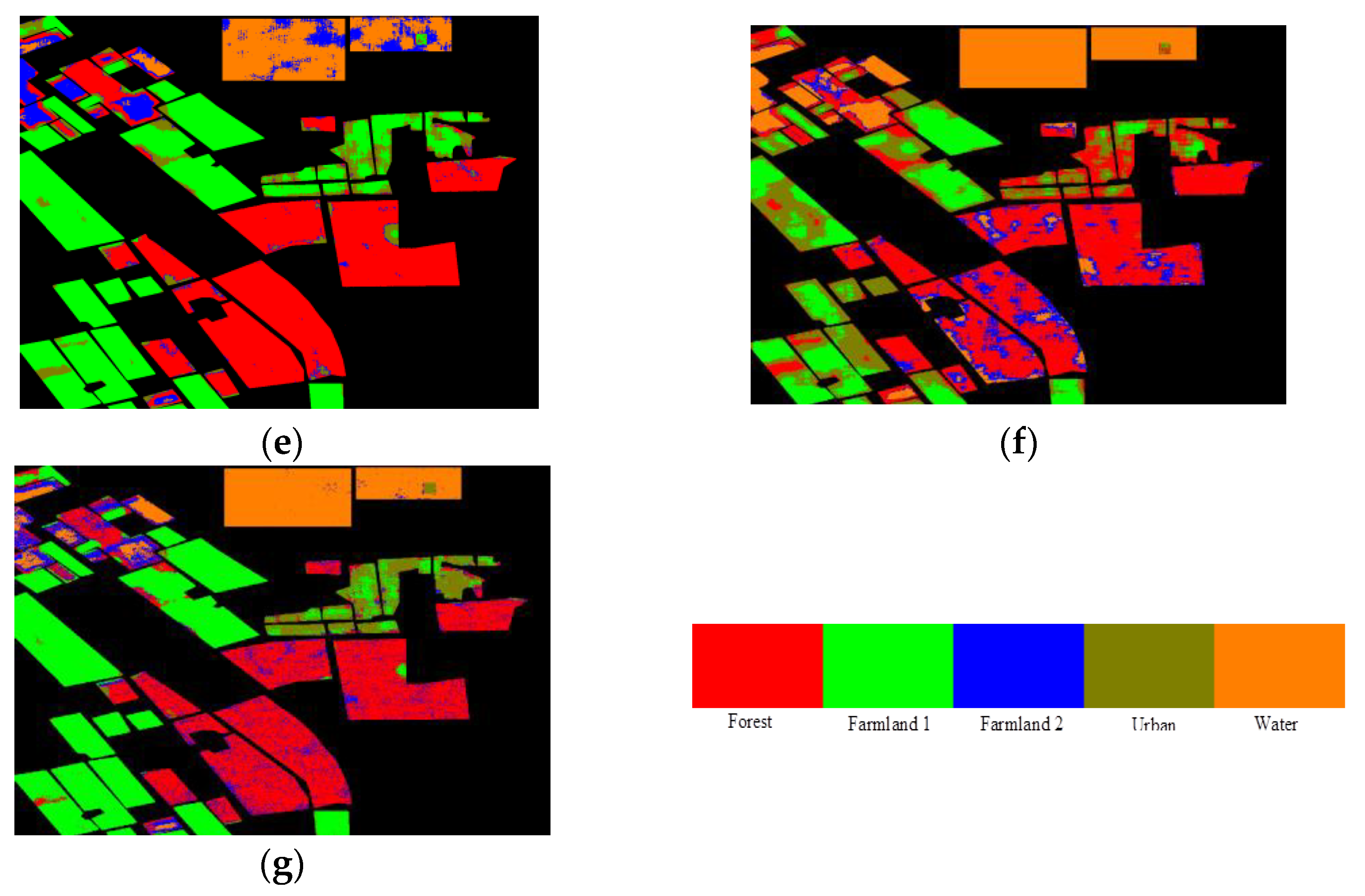
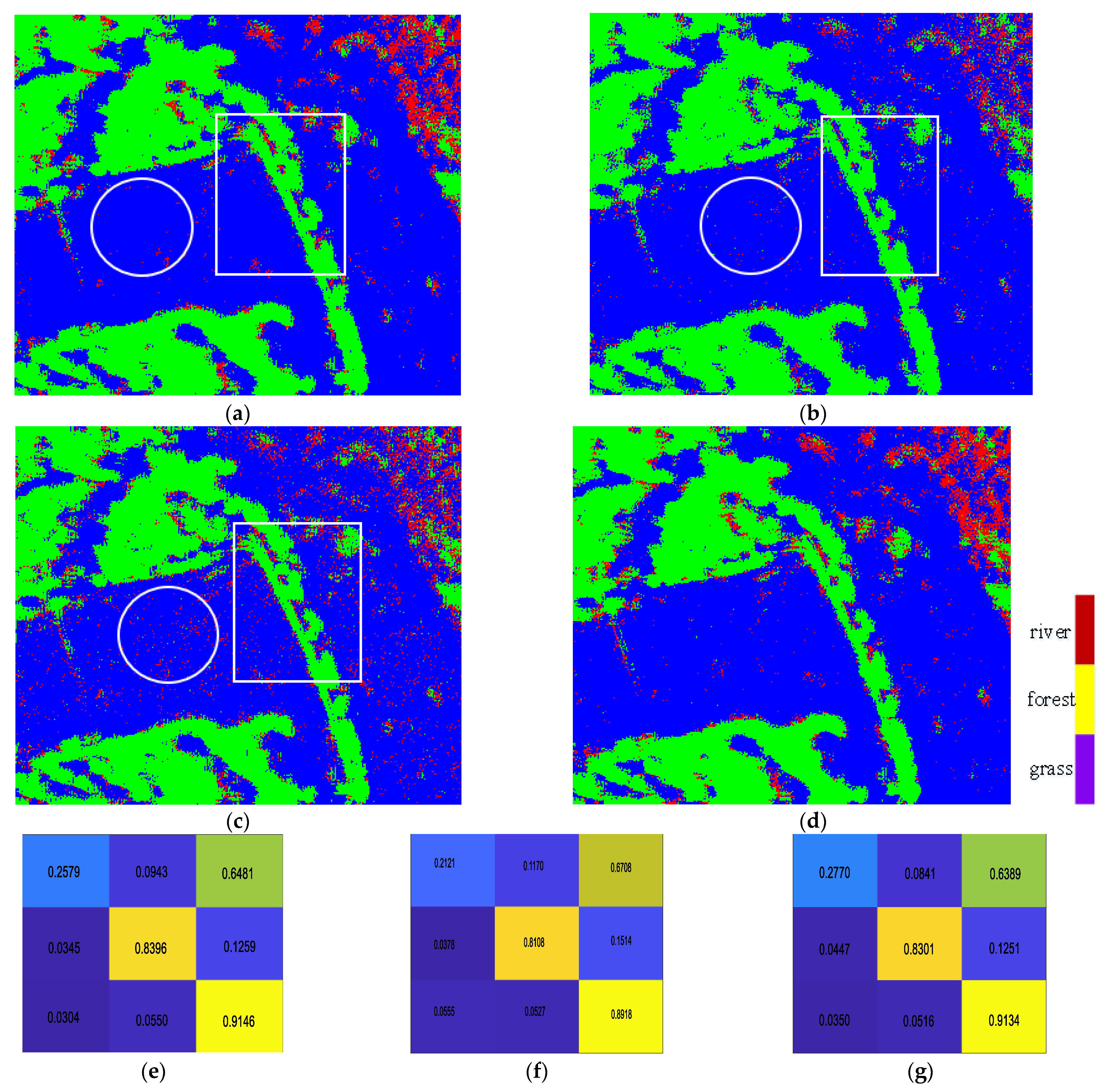
The classification results maps is shown in
Figure 16 for discussions and demonstration. By comparing
Figure 16a with
Figure 16b,c, it indicates that the GCA-CNN can adaptively fuse the features of the original image and the smoothed image and complement them. Comparing
Figure 16b,c, it can be seen that the results of the SI-CNN are much smoother than those of OI-CNN. However, the boundaries are much clearer and details (especially the ones highlighted by the white rectangle) are better preserved in
Figure 16c. For the GCA-CNN, the advantages of both OI-CNN and the SI-CNN are absorbed. From the aspect of the reduction in speckle noise, by comparing
Figure 16a with
Figure 16c it can be seen that
Figure 16a is much smoother than
Figure 16c (highlighted by the white circle). For the details keeping, the boundaries in
Figure 16a are clearer and the details (highlighted by the white rectangle) are better preserved than
Figure 16b. By investigating the classificstion results of the terrain river, which is easy to misclassify due to its inter-class similarity, it can be seen that the results in
Figure 16a make a complementary with those of
Figure 16b,c. The discussion made above can be supported by the
Figure 16e,f. The accuracy of river is obviously enhanced (about 4%) by the adaptive fusion. This conclusion indicates that the GCA fusion module can adaptively emphasize the features of the original image and the smoothed image for classifying the terrains with higher accuracy.
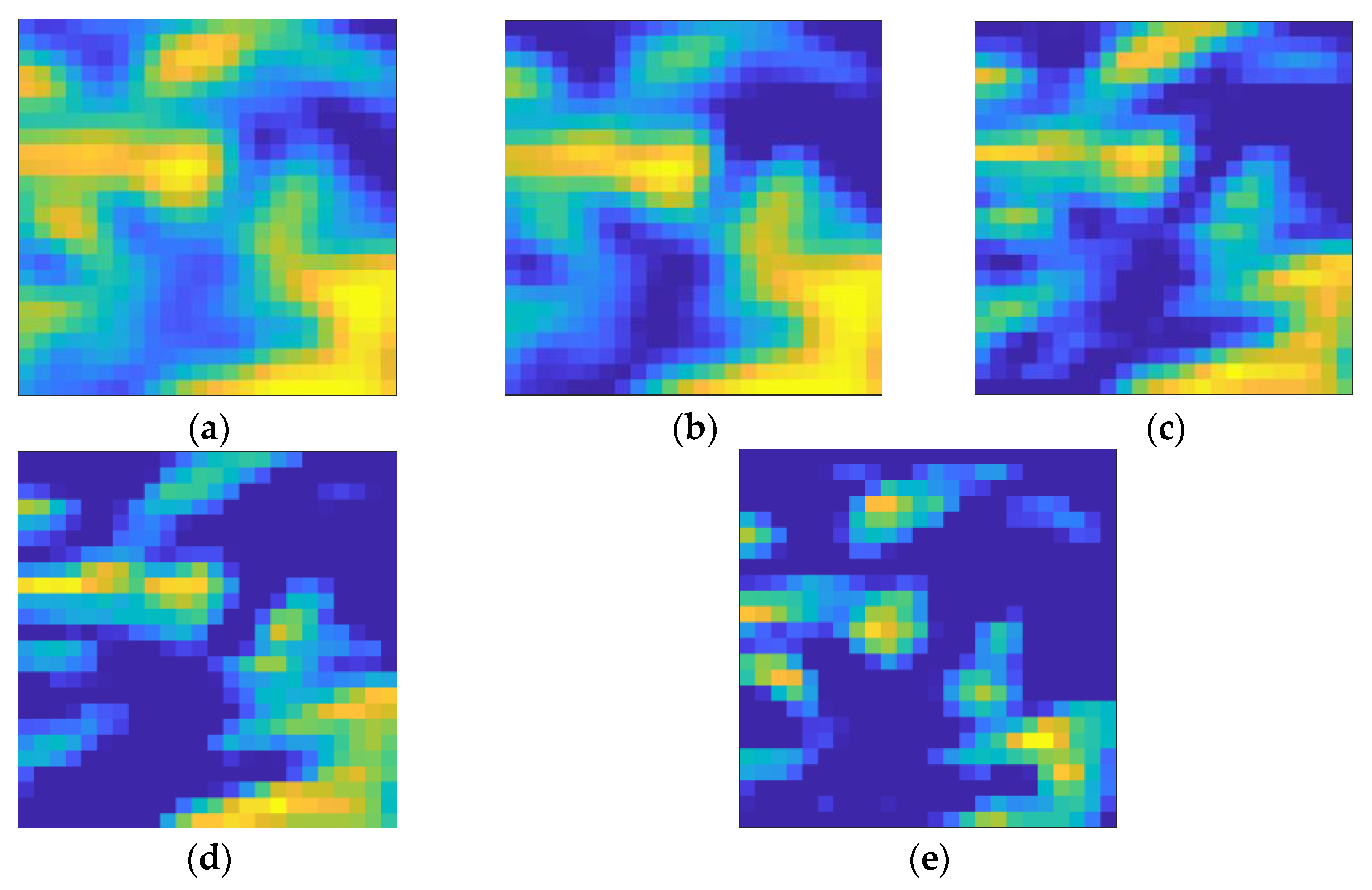
The mechanism of the GCA fusion module will be explained in a way of visualization. As the GCA is constructed by integrating the gated mechanism and the channel attention mechanism, the mechanism of GCA will be illustrated from two aspects: the emphasis of the contribution of feature-maps, and the difference in contribution between channels. An image patch containing the boundaries is cropped from the SAR image as the data resource for validation.
For the first aspect, two image patches from the original image and the smoothed image are shown in
Figure 17a,b. Two feature maps extracted separately from the original image and the smoothed image are explored for comparison. These two feature maps are illustrated in
Figure 17c,d, where it can be seen that the feature map from the original image contains more information of boundaries, while the feature map from the smoothed image contains less information on the boundaries. As calculated by the GCA module, the fusion coefficients of these two feature maps are 0.6937 and 0.3063, which gives the feature map extracted from the original image higher weight.
For the second aspect, two feature maps extracted from the original image are used for validation and these are shown in
Figure 17c,e. There are clear differences between these two feature maps because the corresponding convolution kernels are different. Consequently, the contribution of these feature maps on classification are different. As calculated by GCA, the fusion coefficients of these two feature maps are 0.6937 and 0.2582, which shows an obvious difference. This result demonstrates that the difference between channels is well considered by the GCA module.
4.7. Discussions on the Computational Complexity
The computational complexity of the proposed GCA-CNN and the compared algorithms is also discussed in this paper. The time complexity and the spatial complexity of these algorithms are discussed separately. For the conventional CNN, the time complexity can be expressed as: O(). In this expression, D and N denote the number of convolution layers and fully connected layers, respectively. The number Kl refers to the size of convolution kernels in the lth layer, Ml refers to the size of the feature-maps in the lth layer, Cl means the number of feature-maps in the lth convolution layer, while Fn refers to the number of neurons in the nth fully connected layer. Thus, for the explored CNN in this paper, the time complexity can be calculated as: O(272 × 42 × 20 + 122 × 52 × 202 + 320 × k), where k is the number of categories. For the GCA-CNN, the time complexity is calculated as O(2 × 272 × 42 × 20 + 2 × 122 × 52 × 202 + 320 × k + 20 × 40) (two branches, a fully connected layer in the GCA fusion module and a fully connected layer in the classifier module). It can be seen that the time complexity of the GCA-CNN is about twice that of CNN. However, the time cost of the GCA-CNN can be reduced by a half through the parallel computation of the two branches of GCA-CNN on two GPUs. As discussed above, the proposed GCA-CNN shows a tradeoff between the classification accuracy and the time cost. The DBN and the SAE are composed of fully connected layers, thus the time complexities of these two models are calculated as: O(272 × 100 + 1002 + 100 × k) and O(272 × 200 + 2002 + 200 × 100 + 100 × k), respectively. It can be seen that the time complexity of the GCA-CNN is larger than DBN and SAE, however, the GCA-CNN can achieve much higher classification accuracy. For the SVM the time complexity is calculated as O(272Ns), where Ns is the number of support vectors. It can be seen that the SVM achieves the lowest time complexity.
For the spatial complexity, the DBN and SAE own obviously larger spatial complexity than the GCA-CNN and CNN because of the following two reasons: firstly, the numbers of neurons in DBN and SAE are much larger than those of GCA-CNN and CNN; and secondly, the mechanisms of local connection and weights sharing in the GCA-CNN and CNN reduce the spatial complexity significantly. The SVM still obtains the lowest spatial complexity, because only the support vectors make a contribution on the optimization of the parameters of SVM.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}