
Blind Hyperspectral Image Denoising with Degradation Information Learning

Abstract
:1. Introduction
- We propose a unified Bayesian framework with degradation information learning for HSI denoising. A priority dual regression scheme is built to approximates the joint probability distribution .
- Our method leverages explicit noise intensity and implicit degradation information as joint auxiliary information, which is both beneficial to the primary denoising and dual degenerating tasks.
- The proposed method can be trained using the synthetic clean–noisy data pairs and the unlabeled HSIs with real noises. Extensive experiments demonstrate that our method achieves state-of-the-art performance both in HSI quality indexes and classification accuracy of real-world HSIs.
2. Related Work
2.1. HSI Denoising
2.1.1. Model-Based Methods
2.1.2. Learning-Based Methods
2.2. Unpaired Degradation Modeling and Unlabeled Degradation Modeling
2.3. Dual Learning vs. Priority Dual Learning
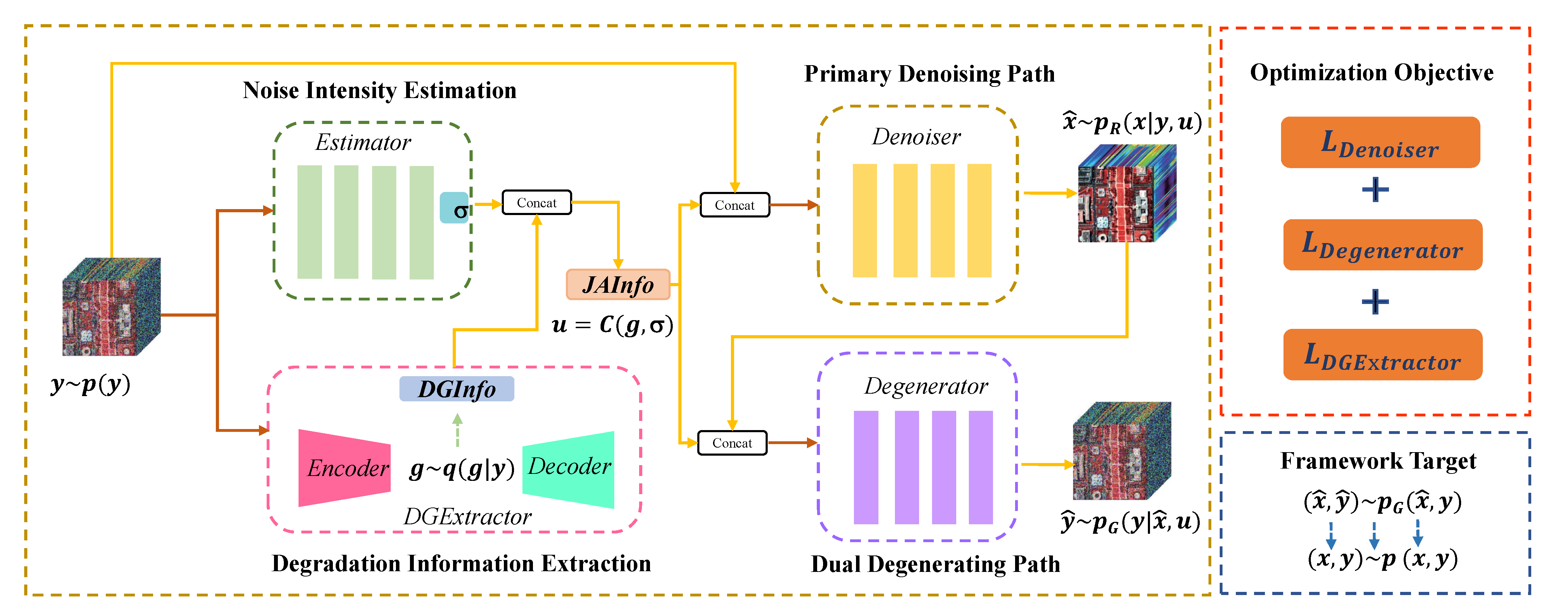
3. Proposed Method
3.1. Joint Auxiliary Information
3.2. Joint Distribution Approximation
3.3. Optimization Objective
3.3.1. DGExtrator
3.3.2. Denoiser and Degenerator
3.3.3. Overall Loss
3.4. Network Architecture
| Algorithm 1 The priority dual learning algorithm. |
Input: labeled synthetic HSIs , unlabeled real HSIs . Output: Trained model. |
1: Initialize Denoiser, Degenerator and DGExtractor. |
2: // Train the primary task preferentially. |
3: while not convergent do |
4: Sample a batch of synthetic data . |
5: Estimate noise intensity with Estimator. |
6: Get implicit degradation information with DGExtractor. |
7: Feed to Denoiser and Degenerator. |
8: Update DGExtractor and Denoiser by minimizing . |
9: end while |
10: // Train the primary and dual tasks jointly. |
11: while not convergent do |
12: Sample a batch of synthetic and real data {, }. |
13: Estimate noise intensity with Estimator. |
14: Get implicit degradation information with DGExtractor. |
15: Feed to Denoiser and Degenerator. |
16: if is synthetic data then |
17: Update DGExtractor, Denoiser, and Degenerator by minimizing . |
18: else |
19: Update DGExtractor and Degenerator by minimizing . |
20: end if |
21: end while |
4. Experiments and Discussions
4.1. Experimental Settings
4.1.1. Benchmark Datasets
4.1.2. Comparison Methods
4.1.3. Evaluation Indexes
4.1.4. Synthetic Noise Setting
- Case 1: Non-i.i.d. Gaussian Noise. The zero-mean Gaussian noise with different intensities, randomly chosen from 10 to 70, is added to each band of the HSI data. Furthermore, such noise is adopted for the other four cases similarly.
- Case 2: Non-i.i.d. Gaussian + Stripe noise. Non-i.i.d. Gaussian Noise is added as mentioned in case 1. Moreover, the stripes on the column are contaminated in one-third of the bands, randomly selected, and the range of stripes proportion of each chosen band is set to 5% to 15% randomly.
- Case 3: Non-i.i.d. Gaussian + Deadline noise. All bands are contaminated by non-i.i.d. Gaussian noise as in case 1. Furthermore, the deadline noise is added with the same strategy of stripes noise in case 2.
- Case 4: Non-i.i.d. Gaussian + Impulse noise. In addition to the non-i.i.d. Gaussian noise in case 1, one-third of bands are randomly selected to add impulse noise with different intensities. The proportion of impulse ranges from 10% to 70%.
- Case 5: Mixed Noise. The non-i.i.d. Gaussian noise in case 1, the stripe noise in case 2, the deadline noise in case 3, and the impulse noise in case 4 are mixed to contaminate the HSIs with the same strategy of each corresponding case.
4.1.5. Training Strategy
4.2. Experimental Results and Analysis
4.2.1. AWGN Removal
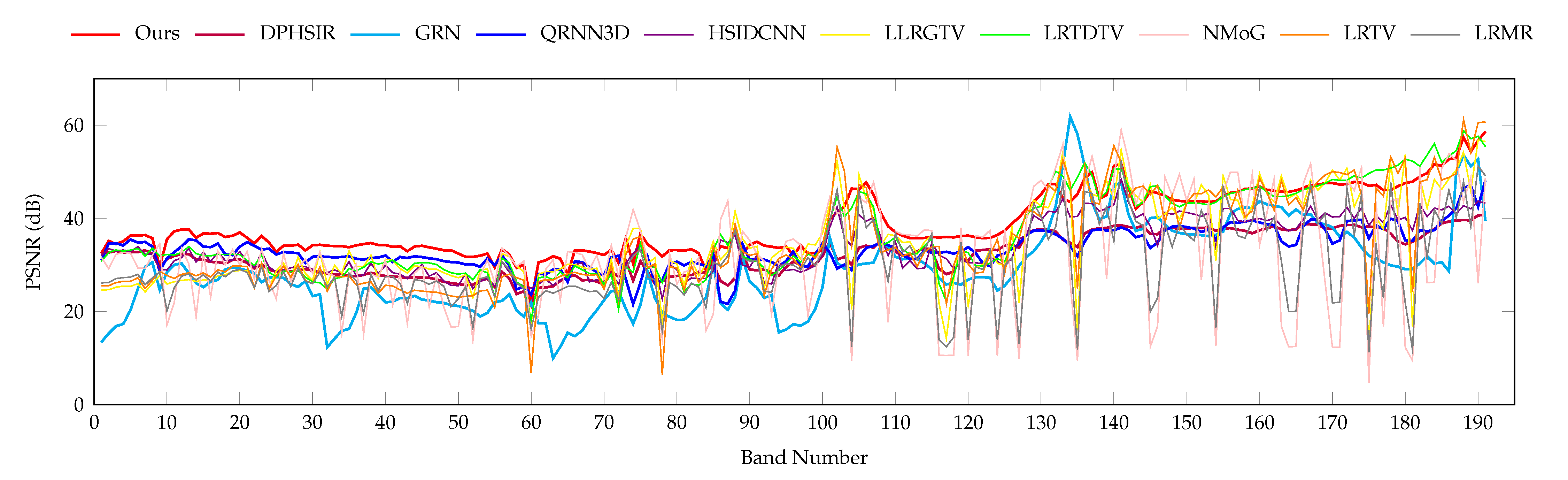
4.2.2. Complex Noise Removal
4.2.3. Real Noise Removal
4.3. Ablation Study
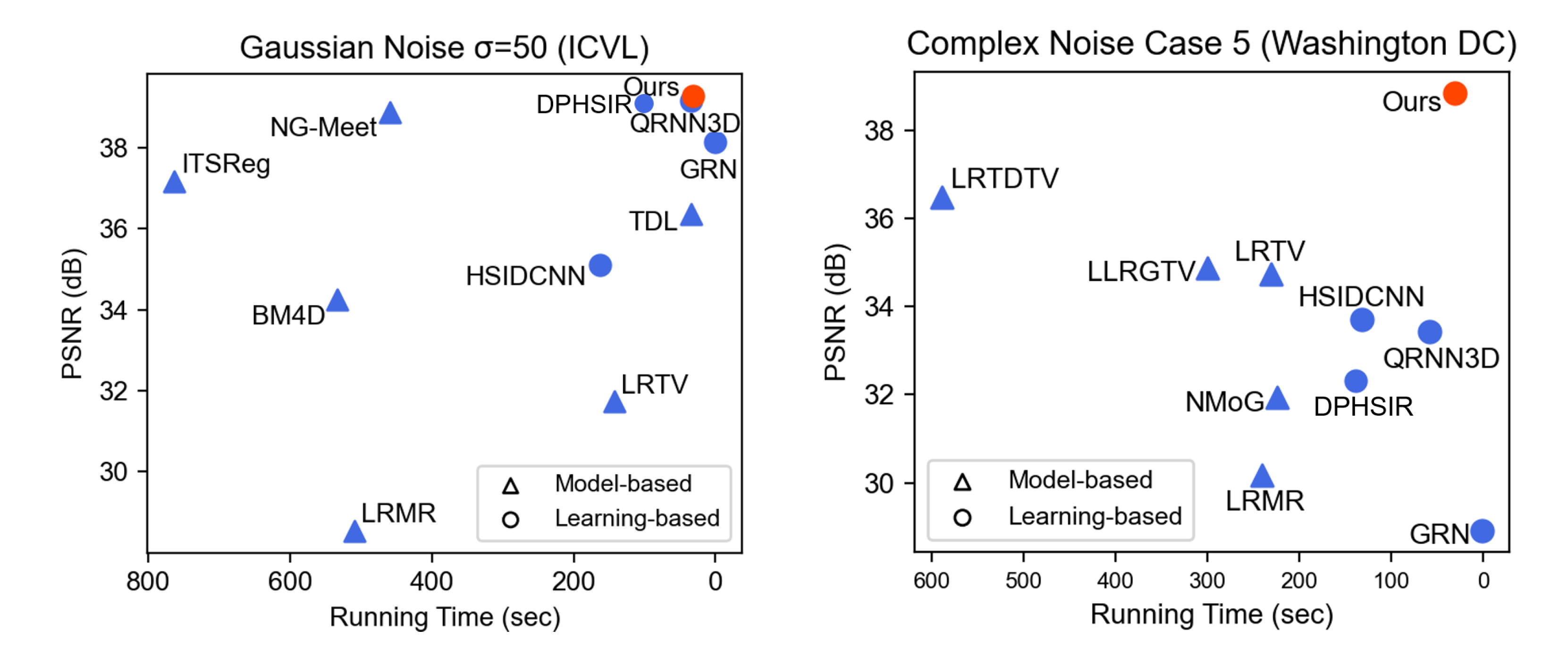
4.4. Efficiency Analysis
4.5. Limitations Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HSI | Hyperspectral image |
| CNN | Convolutional neural network |
| GAN | Generative adversarial network |
| WDC | Washington DC Mall HSI dataset |
| BM4D | Block matching with 4D filtering |
| LRMR | Low-rank matrix recovery |
| LRTV | Total variation regularized low-rank matrix factorization |
| NMoG | The non-iid mixture of Gaussian |
| LRTDTV | Total variation regularized low-rank tensor decomposition |
| LLRGTV | Local low-rank matrix recovery and global spatial–spectral total variation |
| NGMeet | Non-local meets global |
| TDL | Tensor dictionary learning |
| HSI-DeNet | Hyperspectral image restoration via convolutional neural network |
| HSIDCNN | Hyperspectral image denoising employing |
| a spatial–spectral deep residual convolutional neural network | |
| QRNN3D | 3D quasi-recurrent neural network |
| GRN | Global reasoning network |
| DPHSIR | Deep plug-and-play prior for hyperspectral image restoration |
| B | Band |
| H | Height |
| W | Width |
| PSNR | Peak signal-to-noise ratio |
| SSIM | Structural similarity |
| SAM | Spectral angle mapper |
References
- Yu, C.; Han, R.; Song, M.; Liu, C.; Chang, C.I. Feedback attention-based dense CNN for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5501916. [Google Scholar] [CrossRef]
- Sun, X.; Qu, Y.; Gao, L.; Sun, X.; Qi, H.; Zhang, B.; Shen, T. Ensemble-based information retrieval with mass estimation for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5508123. [Google Scholar] [CrossRef]
- Song, M.; Shang, X.; Chang, C.I. 3-D receiver operating characteristic analysis for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8093–8115. [Google Scholar] [CrossRef]
- Zhao, L.; Luo, W.; Liao, Q.; Chen, S.; Wu, J. Hyperspectral Image Classification with Contrastive Self-Supervised Learning Under Limited Labeled Samples. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6008205. [Google Scholar] [CrossRef]
- Ji, Y.; Jiang, P.; Guo, Y.; Zhang, R.; Wang, F. Self-paced collaborative representation with manifold weighting for hyperspectral anomaly detection. Remote Sens. Lett. 2022, 13, 599–610. [Google Scholar] [CrossRef]
- Xie, Q.; Zhao, Q.; Meng, D.; Xu, Z.; Gu, S.; Zuo, W.; Zhang, L. Multispectral images denoising by intrinsic tensor sparsity regularization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1692–1700. [Google Scholar]
- Chang, Y.; Yan, L.; Zhong, S. Hyper-laplacian regularized unidirectional low-rank tensor recovery for multispectral image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4260–4268. [Google Scholar]
- He, W.; Yao, Q.; Li, C.; Yokoya, N.; Zhao, Q. Non-local meets global: An integrated paradigm for hyperspectral denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6868–6877. [Google Scholar]
- Kong, X.; Zhao, Y.; Xue, J.; Chan, J.C.W.; Ren, Z.; Huang, H.; Zang, J. Hyperspectral image denoising based on nonlocal low-rank and TV regularization. Remote Sens. 2020, 12, 1956. [Google Scholar] [CrossRef]
- Chen, Y.; Cao, X.; Zhao, Q.; Meng, D.; Xu, Z. Denoising hyperspectral image with non-iid noise structure. IEEE Trans. Cybern. 2017, 48, 1054–1066. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Peng, J.; Zhao, Q.; Leung, Y.; Zhao, X.L.; Meng, D. Hyperspectral image restoration via total variation regularized low-rank tensor decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 1227–1243. [Google Scholar] [CrossRef] [Green Version]
- He, W.; Zhang, H.; Shen, H.; Zhang, L. Hyperspectral image denoising using local low-rank matrix recovery and global spatial–spectral total variation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 713–729. [Google Scholar] [CrossRef]
- Sun, L.; Zhan, T.; Wu, Z.; Xiao, L.; Jeon, B. Hyperspectral mixed denoising via spectral difference-induced total variation and low-rank approximation. Remote Sens. 2018, 10, 1956. [Google Scholar] [CrossRef]
- Zhuang, L.; Ng, M.K.; Fu, X. Hyperspectral Image Mixed Noise Removal Using Subspace Representation and Deep CNN Image Prior. Remote Sens. 2021, 13, 4098. [Google Scholar] [CrossRef]
- Zhang, T.; Fu, Y.; Li, C. Hyperspectral image denoising with realistic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 2248–2257. [Google Scholar]
- Yuan, Q.; Zhang, Q.; Li, J.; Shen, H.; Zhang, L. Hyperspectral image denoising employing a spatial–spectral deep residual convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1205–1218. [Google Scholar] [CrossRef] [Green Version]
- Wei, K.; Fu, Y.; Huang, H. 3-D quasi-recurrent neural network for hyperspectral image denoising. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 363–375. [Google Scholar] [CrossRef] [Green Version]
- Cao, X.; Fu, X.; Xu, C.; Meng, D. Deep spatial-spectral global reasoning network for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5504714. [Google Scholar] [CrossRef]
- Zhang, J.; Cai, Z.; Chen, F.; Zeng, D. Hyperspectral Image Denoising via Adversarial Learning. Remote Sens. 2022, 14, 1790. [Google Scholar] [CrossRef]
- Pang, L.; Gu, W.; Cao, X. TRQ3DNet: A 3D Quasi-Recurrent and Transformer Based Network for Hyperspectral Image Denoising. Remote Sens. 2022, 14, 4598. [Google Scholar] [CrossRef]
- Maffei, A.; Haut, J.M.; Paoletti, M.E.; Plaza, J.; Bruzzone, L.; Plaza, A. A single model CNN for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2516–2529. [Google Scholar] [CrossRef]
- Yuan, Y.; Ma, H.; Liu, G. Partial-DNet: A novel blind denoising model with noise intensity estimation for HSI. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5505913. [Google Scholar] [CrossRef]
- Lai, Z.; Wei, K.; Fu, Y. Deep plug-and-play prior for hyperspectral image restoration. Neurocomputing 2022, 481, 281–293. [Google Scholar] [CrossRef]
- Xiong, F.; Zhou, J.; Zhao, Q.; Lu, J.; Qian, Y. MAC-Net: Model-Aided Nonlocal Neural Network for Hyperspectral Image Denoising. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5519414. [Google Scholar] [CrossRef]
- Yue, Z.; Zhao, Q.; Zhang, L.; Meng, D. Dual adversarial network: Toward real-world noise removal and noise generation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 41–58. [Google Scholar]
- Zheng, D.; Zhang, X.; Ma, K.; Bao, C. Learn from Unpaired Data for Image Restoration: A Variational Bayes Approach. arXiv 2022, arXiv:2204.10090. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Chen, J.; Chao, H.; Yang, M. Image blind denoising with generative adversarial network based noise modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3155–3164. [Google Scholar]
- Kim, D.W.; Ryun Chung, J.; Jung, S.W. Grdn: Grouped residual dense network for real image denoising and gan-based real-world noise modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- He, D.; Xia, Y.; Qin, T.; Wang, L.; Yu, N.; Liu, T.Y.; Ma, W.Y. Dual learning for machine translation. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Guo, Y.; Chen, J.; Wang, J.; Chen, Q.; Cao, J.; Deng, Z.; Xu, Y.; Tan, M. Closed-loop matters: Dual regression networks for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5407–5416. [Google Scholar]
- Hu, X.; Cai, Y.; Liu, Z.; Wang, H.; Zhang, Y. Multi-Scale Selective Feedback Network with Dual Loss for Real Image Denoising. In Proceedings of the IJCAI, Montreal, QC, Canada, 19–27 August 2021; pp. 729–735. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1712–1722. [Google Scholar]
- Gou, Y.; Hu, P.; Lv, J.; Peng, X. Multi-Scale Adaptive Network for Single Image Denoising. arXiv 2022, arXiv:2203.04313. [Google Scholar]
- Li, B.; Gou, Y.; Gu, S.; Liu, J.Z.; Zhou, J.T.; Peng, X. You only look yourself: Unsupervised and untrained single image dehazing neural network. Int. J. Comput. Vis. 2021, 129, 1754–1767. [Google Scholar] [CrossRef]
- Maggioni, M.; Katkovnik, V.; Egiazarian, K.; Foi, A. Nonlocal transform-domain filter for volumetric data denoising and reconstruction. IEEE Trans. Image Process. 2012, 22, 119–133. [Google Scholar] [CrossRef]
- Peng, Y.; Meng, D.; Xu, Z.; Gao, C.; Yang, Y.; Zhang, B. Decomposable nonlocal tensor dictionary learning for multispectral image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2949–2956. [Google Scholar]
- Zhang, H.; He, W.; Zhang, L.; Shen, H.; Yuan, Q. Hyperspectral image restoration using low-rank matrix recovery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4729–4743. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L.; Shen, H. Total-variation-regularized low-rank matrix factorization for hyperspectral image restoration. IEEE Trans. Geosci. Remote Sens. 2015, 54, 178–188. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Fang, H.; Zhong, S.; Liao, W. HSI-DeNet: Hyperspectral image restoration via convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 667–682. [Google Scholar] [CrossRef]
- Dong, W.; Wang, H.; Wu, F.; Shi, G.; Li, X. Deep spatial–spectral representation learning for hyperspectral image denoising. IEEE Trans. Comput. Imaging 2019, 5, 635–648. [Google Scholar] [CrossRef]
- Liu, W.; Lee, J. A 3-D atrous convolution neural network for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5701–5715. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Li, B.; Liu, X.; Hu, P.; Wu, Z.; Lv, J.; Peng, X. All-In-One image restoration for unknown corruption. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 17452–17462. [Google Scholar]
- Liu, X.; Tanaka, M.; Okutomi, M. Single-image noise level estimation for blind denoising. IEEE Trans. Image Process. 2013, 22, 5226–5237. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Arad, B.; Ben-Shahar, O. Sparse recovery of hyperspectral signal from natural RGB images. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 19–34. [Google Scholar]
- Gamba, P. A collection of data for urban area characterization. In Proceedings of the IGARSS 2004, 2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; Volume 1. [Google Scholar]
- Landgrebe, D.A. Signal Theory Methods in Multispectral Remote Sensing; John Wiley & Sons: Hoboken, NJ, USA, 2003; Volume 24. [Google Scholar]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 210–223. [Google Scholar]
- Park, J.I.; Lee, M.H.; Grossberg, M.D.; Nayar, S.K. Multispectral imaging using multiplexed illumination. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio De Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Yuhas, R.H.; Boardman, J.W.; Goetz, A.F. Determination of semi-arid landscape endmembers and seasonal trends using convex geometry spectral unmixing techniques. In Proceedings of the JPL, Summaries of the 4th Annual JPL Airborne Geoscience Workshop, Washington, DC, USA, 25–28 October 1993; Volume 1. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Layers | Kernel Size | Stride | Input Size | Output Size |
|---|---|---|---|---|---|
| Block 1 | Conv3d, ReLU | 3 × 3 × 3 | 1 × 1 × 1 | 3 × B × H × W | 64 × B × H × W |
| Conv3d, ReLU | 3 × 3 × 3 | 1 × 1 × 1 | 64 × B × H × W | 64 × B × H × W | |
| Block 2 | Conv3d | 1 × 2 × 2 | 1 × 2 × 2 | 64 × B × H × W | 64 × B × × |
| Block 3 | Conv3d, ReLU | 3 × 3 × 3 | 1 × 1 × 1 | 64 × B × × | 128 × B × × |
| RDB3d | 3 × 3 × 3 | 1 × 1 × 1 | 128 × B × × | 128 × B × × | |
| Block 4 | Conv3d | 1 × 2 × 2 | 1 × 2 × 2 | 128 × B × × | 128 × B × × |
| Block 5 | Conv3d, ReLU | 3 × 3 × 3 | 1 × 1 × 1 | 128 × B × × | 256 × B × × |
| RDB3d | 3 × 3 × 3 | 1 × 1 × 1 | 256 × B × × | 256 × B × × | |
| Block 6 | ConvTranspose3d | 1 × 2 × 2 | 1 × 2 × 2 | 256 × B × × | 256 × B × × |
| Block 7 | Conv3d, ReLU | 3 × 3 × 3 | 1 × 1 × 1 | 256 × B × × | 128 × B × × |
| RDB3d | 3 × 3 × 3 | 1 × 1 × 1 | 128 × B × × | 128 × B × × | |
| Block 8 | ConvTranspose3d | 1 × 2 × 2 | 1 × 2 × 2 | 128 × B × × | 128 × B × H × W |
| Block 9 | Conv3d, ReLU | 3 × 3 × 3 | 1 × 1 × 1 | 128 × B × H × W | 64 × B × H × W |
| RDB3d | 3 × 3 × 3 | 1 × 1 × 1 | 64 × B × H × W | 64 × B × H × W | |
| Output | Conv3d | 3 × 3 × 3 | 1 × 1 × 1 | 64 × B × H × W | 1 × B × H × W |
| Module | Layers | Kernel Size | Stride | Input Size | Output Size |
|---|---|---|---|---|---|
| Conv3d, LeakyReLU | 3 × 3 × 3 | 1 × 1 × 1 | 3 × B × H × W | 32 × B × H × W | |
| Block 1 | Conv3d | 3 × 3 × 3 | 1 × 1 × 1 | 32 × B × H × W | 32 × B × H × W |
| Conv3d | 1 × 1 × 1 | 1 × 1 × 1 | 32 × B × H × W | 32 × B × H × W | |
| Conv3d, LeakyReLU | 3 × 3 × 3 | 1 × 1 × 1 | 32 × B × H × W | 32 × B × H × W | |
| Block 2 | Conv3d | 3 × 3 × 3 | 1 × 1 × 1 | 32 × B × H × W | 32 × B × H × W |
| Conv3d | 1 × 1 × 1 | 1 × 1 × 1 | 32 × B × H × W | 1 × B × H × W |
| Module | Layers | Kernel Size | Stride | Input Size | Output Size |
|---|---|---|---|---|---|
| Block 1 | Conv3d, LeakyReLU | 3 × 3 × 3 | 1 × 1 × 1 | 1 × B × H × W | 32 × B × H × W |
| Block 2 | Conv3d | 1 × 2 × 2 | 1 × 2 × 2 | 32 × B × H × W | 32 × B × × |
| Conv3d, LeakyReLU | 3 × 3 × 3 | 1 × 1 × 1 | 32 × B × × | 32 × B × × | |
| Block 3 | Conv3d | 1 × 2 × 2 | 1 × 2 × 2 | 32 × B × H × W | 32 × B × × |
| Conv3d, LeakyReLU | 3 × 3 × 3 | 1 × 1 × 1 | 32 × B × × | 32 × B × × | |
| Block 4 (a) | Conv3d, LeakyReLU | 3 × 3 × 3 | 1 × 1 × 1 | 32 × B × × | 32 × B × × |
| , input (a) | Conv3d | 1 × 2 × 2 | 1 × 2 × 2 | 32 × B × × | 1 × B × × |
| , input (a) | Conv3d | 1 × 2 × 2 | 1 × 2 × 2 | 32 × B × × | 1 × B × × |
| Module | Layers | Kernel Size | Stride | Input Size | Output Size |
|---|---|---|---|---|---|
| Block 1 | Conv3d, LeakyReLU | 3 × 3 × 3 | 1 × 1 × 1 | 1 × B × × | 32 × B × × |
| Block 2 | Conv3d, LeakyReLU | 3 × 3 × 3 | 1 × 1 × 1 | 32 × B × × | 32 × B × × |
| ConvTranspose3d | 1 × 2 × 2 | 1 × 2 × 2 | 32 × B × × | 32 × B × × | |
| Block 3 | Conv3d, LeakyReLU | 3 × 3 × 3 | 1 × 1 × 1 | 32 × B × × | 32 × B × × |
| ConvTranspose3d | 1 × 2 × 2 | 1 × 2 × 2 | 32 × B × × | 32 × B × H × W | |
| Output | Conv3d, LeakyReLU | 3 × 3 × 3 | 1 × 1 × 1 | 32 × B × H × W | 1 × B × H × W |
| Methods | Blind/Non-Blind | = 30 | = 50 | = 70 | Blind | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | SAM | PSNR | SSIM | SAM | PSNR | SSIM | SAM | PSNR | SSIM | SAM | ||
| Noisy | — | 18.59 | 0.0849 | 0.8246 | 14.15 | 0.0329 | 0.9958 | 11.23 | 0.0169 | 1.1063 | 14.21 | 0.0362 | 0.9946 |
| BM4D [39] | Non-blind | 39.36 | 0.9359 | 0.1445 | 36.51 | 0.8880 | 0.2086 | 34.58 | 0.8407 | 0.2544 | 36.50 | 0.8851 | 0.2108 |
| LRMR [41] | Blind | 34.00 | 0.7011 | 0.3134 | 30.02 | 0.5120 | 0.4151 | 27.19 | 0.3817 | 0.4998 | 30.04 | 0.5139 | 0.4129 |
| LRTV [42] | Blind | 37.95 | 0.9179 | 0.1613 | 35.67 | 0.8798 | 0.2118 | 34.12 | 0.8452 | 0.2537 | 34.55 | 0.8973 | 0.1090 |
| TDL [40] | Non-blind | 42.21 | 0.9620 | 0.0711 | 39.79 | 0.9390 | 0.1087 | 38.06 | 0.9156 | 0.1390 | 39.78 | 0.9376 | 0.1668 |
| ITSReg [6] | Non-blind | 42.28 | 0.9508 | 0.1571 | 40.01 | 0.9265 | 0.1831 | 38.21 | 0.9116 | 0.2013 | 39.98 | 0.9294 | 0.1745 |
| NG-Meet [8] | Non-blind | 43.34 | 0.9554 | 0.0540 | 40.64 | 0.9401 | 0.0668 | 39.05 | 0.9290 | 0.0769 | 40.77 | 0.9412 | 0.0674 |
| HSIDCNN [16] | Blind | 40.10 | 0.9538 | 0.1118 | 37.43 | 0.9242 | 0.1471 | 35.42 | 0.8897 | 0.1784 | 37.35 | 0.9220 | 0.1493 |
| QRNN3D [17] | Blind | 43.86 | 0.9761 | 0.0659 | 41.71 | 0.9640 | 0.0825 | 39.57 | 0.9452 | 0.1133 | 41.54 | 0.9627 | 0.0870 |
| GRN [18] | Blind | 40.97 | 0.9722 | 0.0845 | 39.76 | 0.9618 | 0.0933 | 38.38 | 0.9451 | 0.1051 | 39.63 | 0.9604 | 0.0947 |
| DPHSIR [23] | Non-blind | 44.70 | 0.9782 | 0.0574 | 42.11 | 0.9646 | 0.0776 | 38.50 | 0.9193 | 0.1519 | 39.25 | 0.8860 | 0.1310 |
| DIBD | Blind | 44.37 | 0.9771 | 0.0590 | 42.08 | 0.9649 | 0.0747 | 40.52 | 0.9539 | 0.0897 | 42.07 | 0.9648 | 0.0750 |
| Methods | Case 1 | Case 2 | Case 3 | Case 4 | Case 5 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | SAM | PSNR | SSIM | SAM | PSNR | SSIM | SAM | PSNR | SSIM | SAM | PSNR | SSIM | SAM | |
| Noisy | 17.77 | 0.1428 | 0.8678 | 17.65 | 0.1386 | 0.8684 | 17.56 | 0.1385 | 0.8806 | 14.88 | 0.1024 | 0.911 | 13.82 | 0.0792 | 0.9271 |
| LRMR | 32.98 | 0.6834 | 0.2643 | 32.89 | 0.6811 | 0.2640 | 32.22 | 0.6823 | 0.2988 | 30.68 | 0.6185 | 0.3363 | 29.75 | 0.5917 | 0.3781 |
| LRTV | 33.61 | 0.8910 | 0.1095 | 33.58 | 0.8872 | 0.1161 | 32.28 | 0.8806 | 0.1270 | 28.54 | 0.6833 | 0.4779 | 27.22 | 0.6675 | 0.4963 |
| NMoG | 35.05 | 0.8353 | 0.2268 | 33.80 | 0.7739 | 0.4284 | 32.90 | 0.7752 | 0.3985 | 29.48 | 0.6728 | 0.5562 | 27.16 | 0.5883 | 0.5677 |
| LRTDTV | 35.59 | 0.9136 | 0.1265 | 35.64 | 0.9140 | 0.1236 | 34.95 | 0.9147 | 0.1214 | 34.80 | 0.9079 | 0.1334 | 33.58 | 0.9038 | 0.1351 |
| LLRGTV | 35.76 | 0.8768 | 0.2110 | 35.75 | 0.8737 | 0.2195 | 34.29 | 0.8538 | 0.2722 | 33.82 | 0.8397 | 0.3841 | 31.87 | 0.8127 | 0.3949 |
| HSIDCNN | 39.05 | 0.9434 | 0.1079 | 38.70 | 0.9412 | 0.1049 | 38.54 | 0.9395 | 0.1049 | 36.57 | 0.9055 | 0.1404 | 35.30 | 0.8874 | 0.1532 |
| QRNN3D | 44.00 | 0.9794 | 0.0504 | 43.66 | 0.9783 | 0.0517 | 43.62 | 0.9784 | 0.0510 | 42.63 | 0.9710 | 0.0714 | 41.16 | 0.9634 | 0.0810 |
| GRN | 38.79 | 0.9598 | 0.0720 | 38.68 | 0.9590 | 0.0725 | 38.76 | 0.9586 | 0.0725 | 34.51 | 0.8891 | 0.4280 | 34.68 | 0.8950 | 0.1535 |
| DPHSIR | 44.14 | 0.9796 | 0.0458 | 43.71 | 0.9780 | 0.0480 | 43.58 | 0.9783 | 0.0470 | 42.47 | 0.9711 | 0.0641 | 39.57 | 0.9596 | 0.0797 |
| DIBD | 44.92 | 0.9823 | 0.0436 | 44.69 | 0.9815 | 0.0448 | 44.74 | 0.9816 | 0.0446 | 43.86 | 0.9776 | 0.0500 | 42.25 | 0.9702 | 0.0614 |
| Metrics | Noisy | BM4D | LRMR | LRTV | NMoG | LRTDTV | HSIDCNN | QRNN3D | GRN | DPHSIR | DIBD | DIBD-R |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
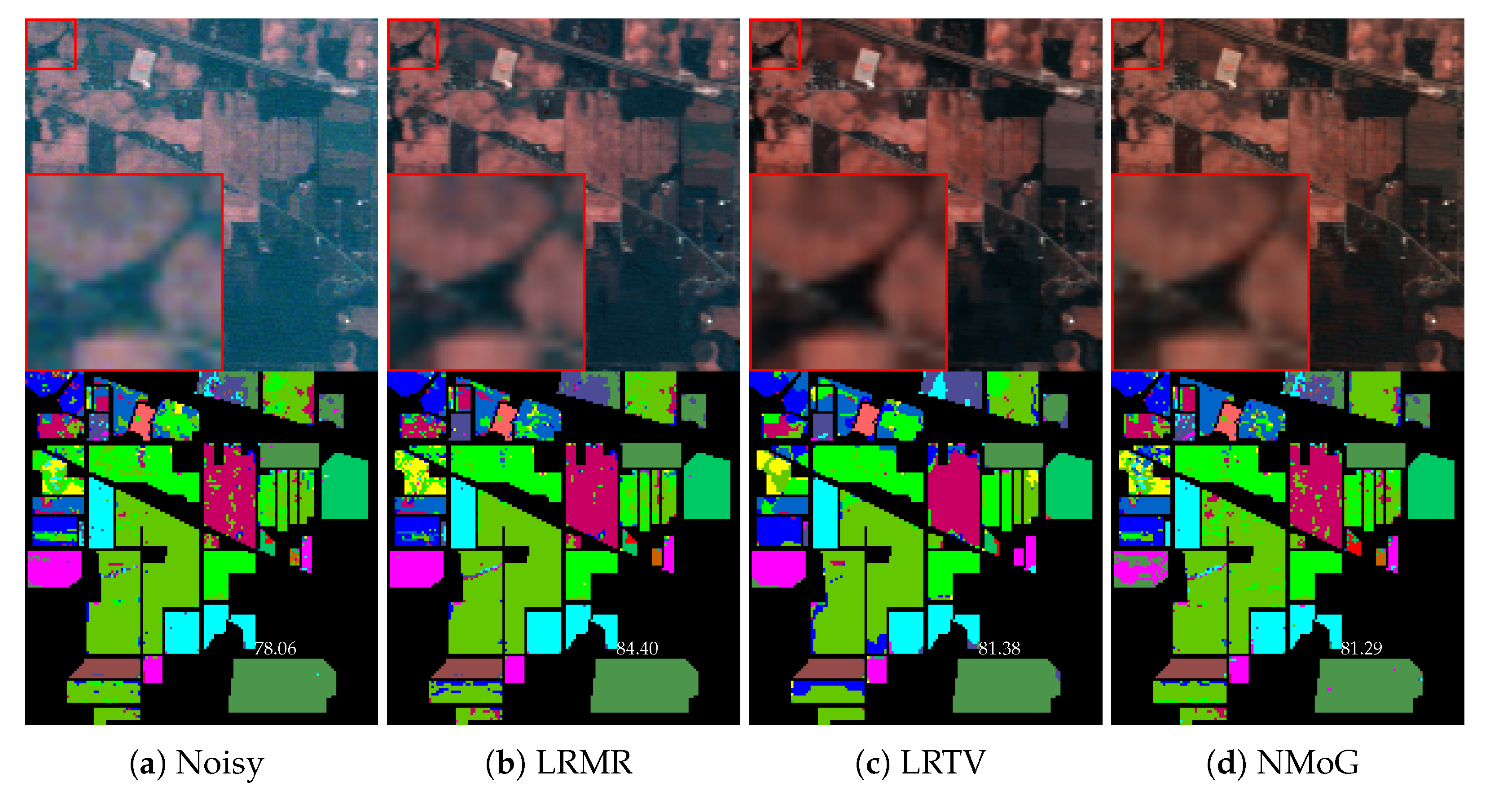
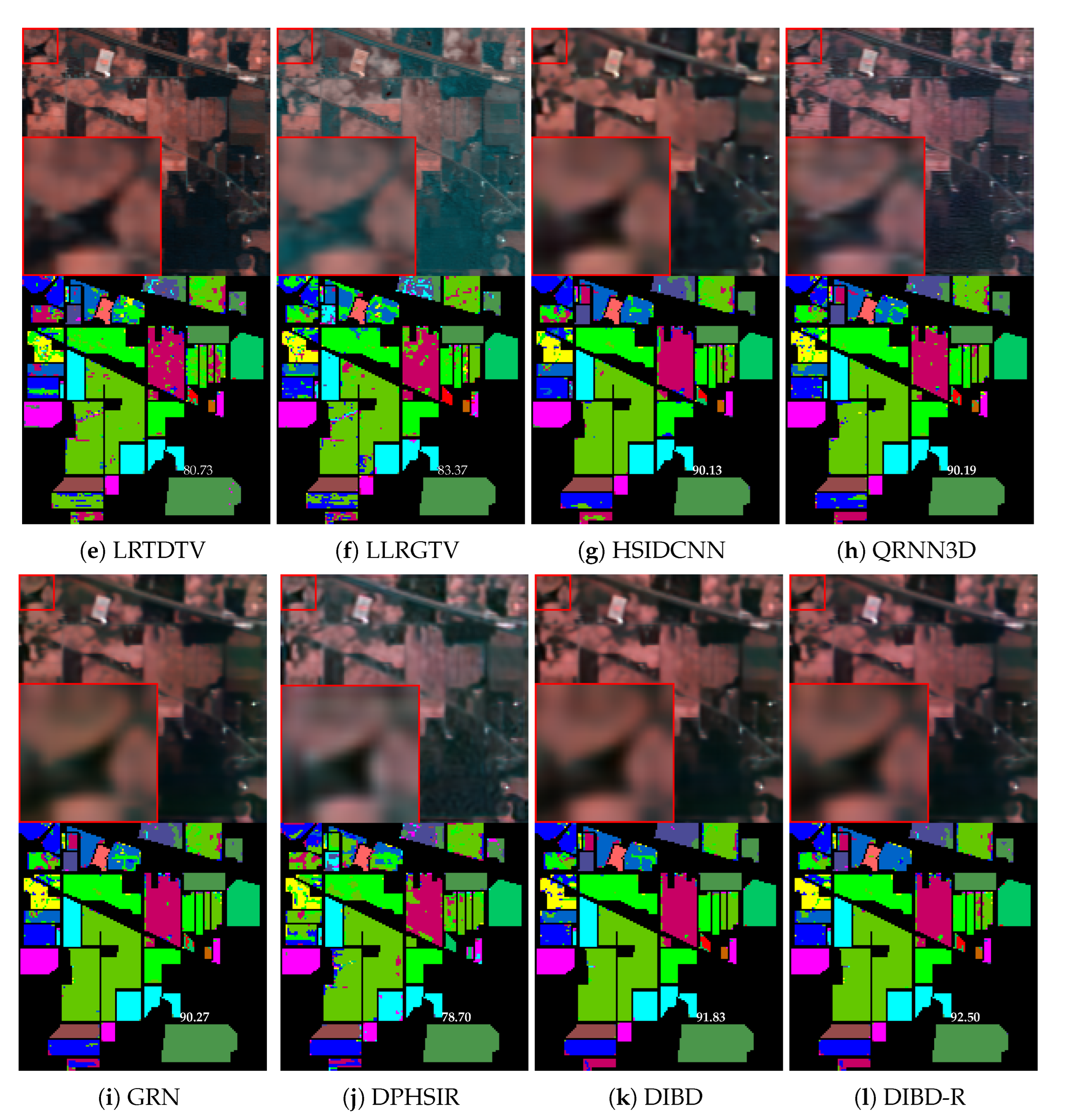
| OA | 78.06 | 84.40 | 81.38 | 81.29 | 80.73 | 83.37 | 90.13 | 90.19 | 90.27 | 78.70 | 91.83 | 92.50 |
| Kappa | 0.7463 | 0.8207 | 0.7862 | 0.7845 | 0.7787 | 0.8088 | 0.8872 | 0.8876 | 0.8887 | 0.7536 | 0.9067 | 0.9144 |
| ICVL with = 70 | CAVE with = 95 | |||||||
|---|---|---|---|---|---|---|---|---|
| Baseline | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Degenerator | ✗ | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ | ✓ |
| DGExtractor | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ |
| PSNR | 31.74 | 32.86 | 35.02 | 36.33 | 26.20 | 26.74 | 28.46 | 29.27 |
| SSIM | 0.6297 | 0.6804 | 0.7777 | 0.8430 | 0.4442 | 0.4602 | 0.6029 | 0.6361 |
| SAM | 0.2670 | 0.2245 | 0.1345 | 0.1322 | 0.6363 | 0.5116 | 0.4122 | 0.4470 |
| Params (#) | 3.16M | 3.25M | 3.32M | 3.41M | 3.16M | 3.25M | 3.32M | 3.41M |
| ICVL with = 70 | CAVE with = 95 | |||||
|---|---|---|---|---|---|---|
| Priority-DR | ✗ | ✓ | ✓ | ✗ | ✓ | ✓ |
| Degenerator-DG | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ |
| PSNR | 34.62 | 36.33 | 36.54 | 28.43 | 29.27 | 29.90 |
| SSIM | 0.7689 | 0.8430 | 0.8450 | 0.5708 | 0.6361 | 0.6832 |
| SAM | 0.1538 | 0.1322 | 0.1203 | 0.5247 | 0.4470 | 0.3796 |
| Methods | Params (M) | ICVL | WDC | ||
|---|---|---|---|---|---|
| PSNR (dB) | Time Cost (s) | PSNR (dB) | Time Cost (s) | ||
| HSIDCNN | 0.37 | 35.30 | 183.62 | 33.71 | 119.54 |
| QRNN3D | 0.86 | 41.16 | 33.25 | 33.42 | 67.14 |
| GRN | 1.06 | 34.68 | 10.43 | 28.92 | 5.41 |
| DPHSIR | 14.27 | 39.57 | 112.67 | 32.16 | 123.36 |
| DIBD | 3.41 | 42.25 | 30.83 | 38.84 | 24.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, X.; Xiao, J.; Gong, Y. Blind Hyperspectral Image Denoising with Degradation Information Learning. Remote Sens. 2023, 15, 490. https://doi.org/10.3390/rs15020490
Wei X, Xiao J, Gong Y. Blind Hyperspectral Image Denoising with Degradation Information Learning. Remote Sensing. 2023; 15(2):490. https://doi.org/10.3390/rs15020490
Chicago/Turabian StyleWei, Xing, Jiahua Xiao, and Yihong Gong. 2023. "Blind Hyperspectral Image Denoising with Degradation Information Learning" Remote Sensing 15, no. 2: 490. https://doi.org/10.3390/rs15020490